↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current large language models (LLMs) often struggle with complex reasoning tasks and require massive datasets for training. This paper addresses these challenges by focusing on data quality rather than simply scaling model size. Existing LLMs primarily rely on organic data sources, which can be noisy and biased, limiting their reasoning abilities.
The researchers introduce Phi-4, a new 14-billion parameter LLM, that uses synthetic data extensively throughout its training. This approach tackles the data quality issues by controlling the diversity and accuracy of training data. The model also uses innovative post-training techniques to fine-tune its performance, resulting in superior reasoning capabilities compared to larger models and better performance on a variety of benchmarks, especially those focused on STEM and reasoning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs), particularly those focusing on improving reasoning capabilities and data efficiency. It introduces novel techniques for generating synthetic data and refining model outputs, offering valuable insights for improving LLM performance. The results show that high-quality synthetic data can significantly enhance LLM performance, especially for complex reasoning tasks, making it extremely relevant for current research trends. The innovative post-training techniques used open up new avenues for improving the safety and reliability of LLMs.
Visual Insights#

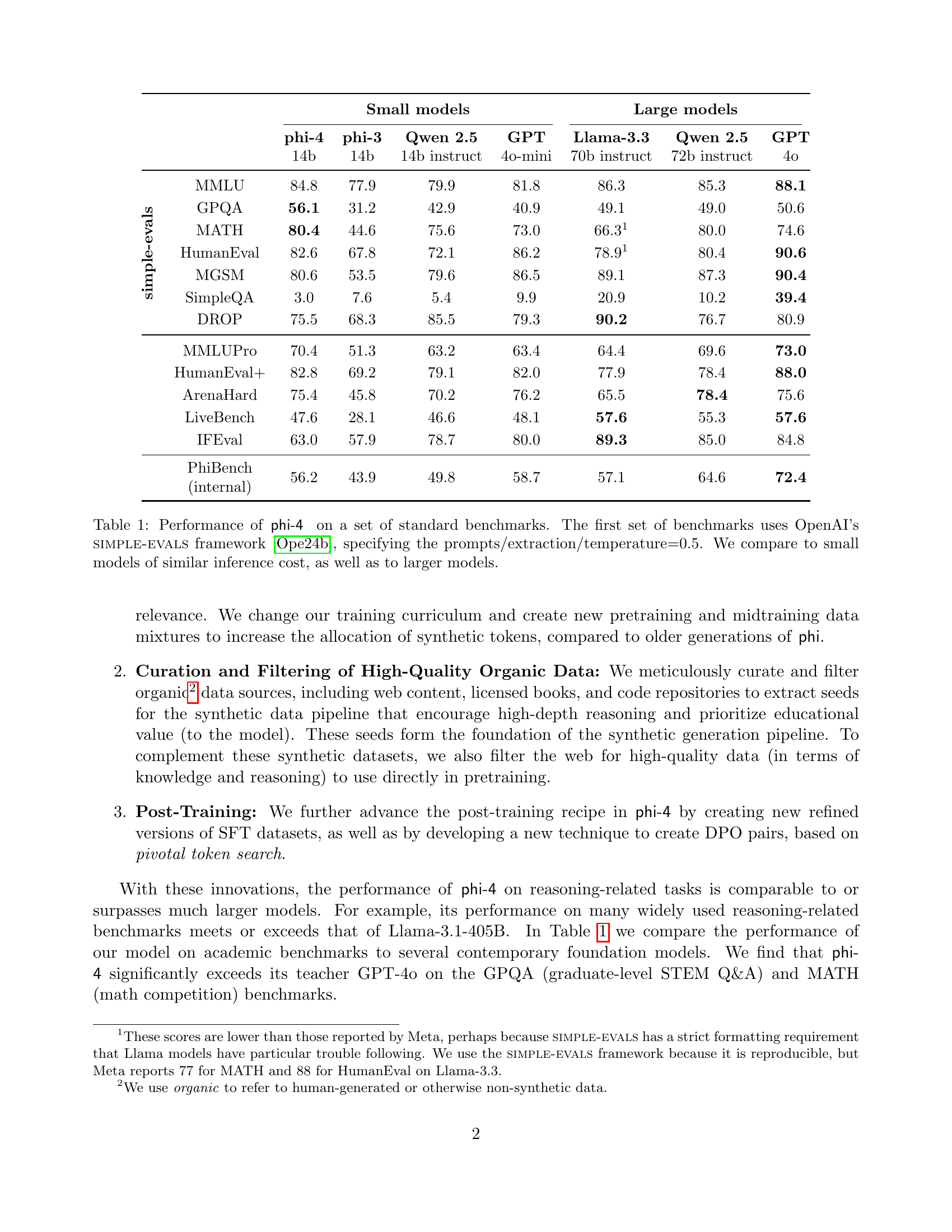
🔼 Figure 1 presents a comparison of various large language models’ performance on the November 2024 AMC 10/12 mathematics competitions. The average score (out of 150) across four tests, each run 100 times with a temperature setting of 0.5, is shown for each model. Phi-4’s performance is highlighted, showcasing its superior score relative to its size, even when compared to larger models. Error bars indicate the 2-sigma confidence interval of the average scores.
read the caption
Figure 1: Average performance of different models on the November 2024 AMC-10 and AMC-12 tests. This is the average score (with maximum score 150) over the four tests on 100 runs with temperature t=0.5𝑡0.5t=0.5italic_t = 0.5. We chose t=0.5𝑡0.5t=0.5italic_t = 0.5 to follow simple-evals [24]. Error bars are 2σ2𝜎2\sigma2 italic_σ of the estimate. On competition math, phi-4 scores well above its weight-class even compared to non–open-weight models.
| phi-4 14b | phi-3 14b | Qwen 2.5 14b instruct | GPT 4o-mini | Llama-3.3 70b instruct | Qwen 2.5 72b instruct | GPT 4o | ||
|---|---|---|---|---|---|---|---|---|
 | simple-evals | |||||||
| MMLU | 84.8 | 77.9 | 79.9 | 81.8 | 86.3 | 85.3 | 88.1 | |
| GPQA | 56.1 | 31.2 | 42.9 | 40.9 | 49.1 | 49.0 | 50.6 | |
| MATH | 80.4 | 44.6 | 75.6 | 73.0 | 66.3 | 80.0 | 74.6 | |
| HumanEval | 82.6 | 67.8 | 72.1 | 86.2 | 78.9 | 80.4 | 90.6 | |
| MGSM | 80.6 | 53.5 | 79.6 | 86.5 | 89.1 | 87.3 | 90.4 | |
| SimpleQA | 3.0 | 7.6 | 5.4 | 9.9 | 20.9 | 10.2 | 39.4 | |
| DROP | 75.5 | 68.3 | 85.5 | 79.3 | 90.2 | 76.7 | 80.9 | |
| MMLUPro | 70.4 | 51.3 | 63.2 | 63.4 | 64.4 | 69.6 | 73.0 | |
| HumanEval+ | 82.8 | 69.2 | 79.1 | 82.0 | 77.9 | 78.4 | 88.0 | |
| ArenaHard | 75.4 | 45.8 | 70.2 | 76.2 | 65.5 | 78.4 | 75.6 | |
| LiveBench | 47.6 | 28.1 | 46.6 | 48.1 | 57.6 | 55.3 | 57.6 | |
| IFEval | 63.0 | 57.9 | 78.7 | 80.0 | 89.3 | 85.0 | 84.8 | |
| PhiBench (internal) | 56.2 | 43.9 | 49.8 | 58.7 | 57.1 | 64.6 | 72.4 |
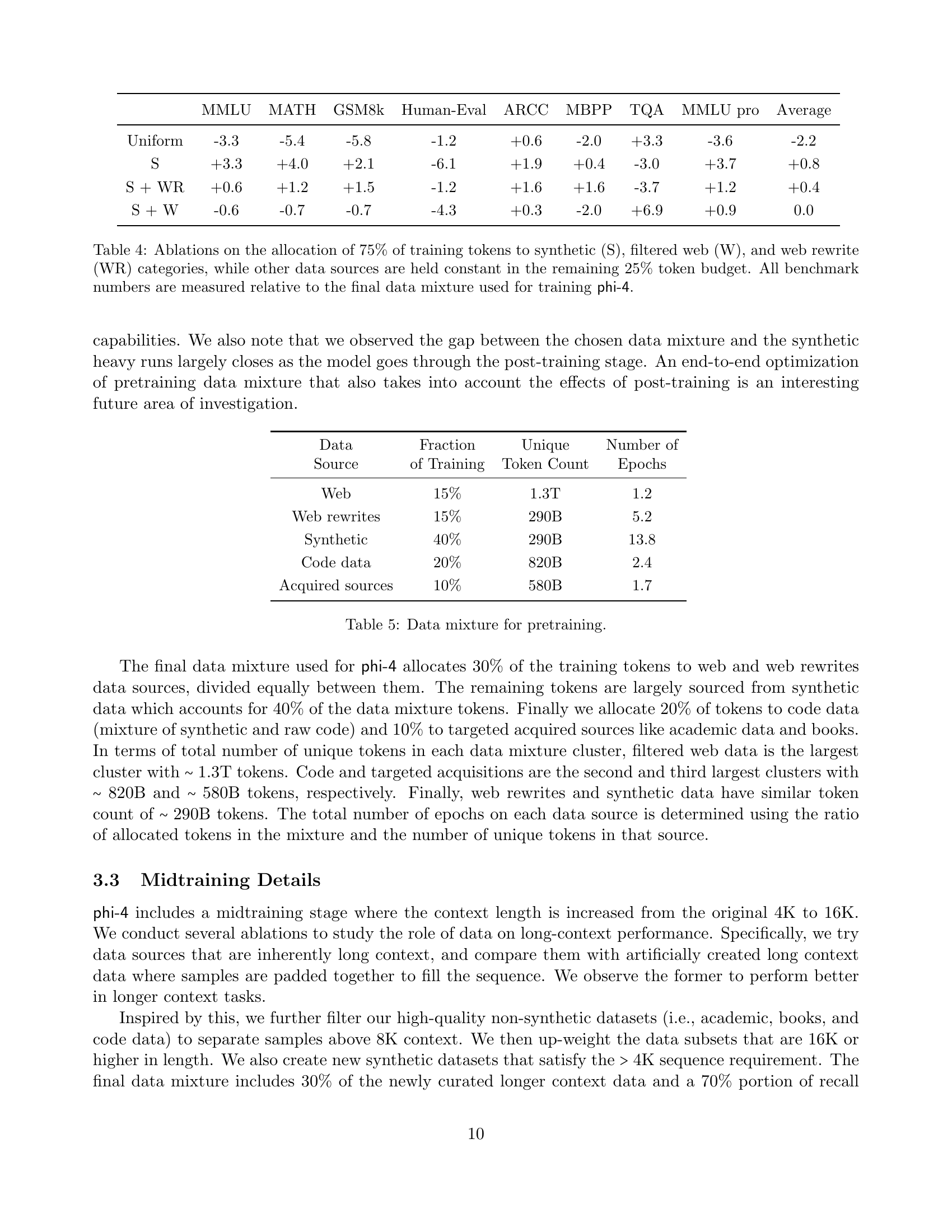
🔼 This table presents the performance of the phi-4 language model on a range of standard benchmarks, comparing it against other models with similar computational cost. The benchmarks include tasks assessing various language capabilities, such as question answering, reasoning, and code generation. The evaluation methodology uses OpenAI’s simple-evals framework, and the results are reported with specific prompt engineering and temperature settings.
read the caption
Table 1: Performance of phi-4 on a set of standard benchmarks. The first set of benchmarks uses OpenAI’s simple-evals framework [24], specifying the prompts/extraction/temperature=0.5. We compare to small models of similar inference cost, as well as to larger models.
In-depth insights#
Data Quality Focus#
A data quality focus in research is crucial for ensuring reliable and meaningful results. High-quality data minimizes bias and noise, leading to more accurate conclusions and stronger support for hypotheses. A robust methodology should address data collection methods, ensuring appropriate sampling and rigorous data cleaning procedures. Data validation techniques, such as verification, consistency checks, and outlier detection, are essential to maintain data integrity. Transparency in data processing and analysis, including clear documentation of methods and any limitations, is also vital for reproducibility and trust. By prioritizing data quality, researchers can significantly enhance the credibility and impact of their findings, thus contributing meaningfully to the field.
Synthetic Data Gen#
Generating synthetic data for training large language models offers significant advantages over relying solely on real-world data. Synthetic data allows for fine-grained control over the characteristics of the training set, enabling the creation of datasets with specific properties for addressing the model’s weaknesses, such as improving reasoning abilities. Diverse generation techniques, including multi-agent prompting, self-revision, and instruction reversal, ensure a rich and varied training experience. While synthetic data may not perfectly replicate the complexities of real-world data, its ability to complement and augment organic datasets makes it a powerful tool in the development of robust and capable LLMs. The careful curation and filtering of both synthetic and organic data sources are essential for maximizing the effectiveness of the training process and minimizing potential biases.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a comprehensive evaluation of the proposed model against existing state-of-the-art solutions. This would involve a detailed comparison across multiple established benchmarks, showcasing performance metrics like accuracy, precision, recall, and F1-score. The selection of benchmarks should be carefully justified, reflecting the specific capabilities and intended applications of the model. A thoughtful analysis would extend beyond simply reporting numerical results, interpreting the findings in relation to the model’s design choices and limitations. Visualizations such as graphs and tables are crucial for easy comprehension and comparison. Crucially, potential biases in the benchmarks themselves should be acknowledged and addressed, along with a discussion of the limitations and strengths of each benchmark used. This detailed and nuanced analysis will ultimately inform the readers’ understanding of the model’s overall performance and contribution to the field.
Hallucination Study#
A robust ‘Hallucination Study’ within a research paper would necessitate a multifaceted approach. It should begin by clearly defining what constitutes a hallucination in the specific context of the language model under investigation, moving beyond simple factual inaccuracies to encompass more nuanced issues such as logical inconsistencies, contradictions, and unjustified inferences. The study must then detail the methodology used for identifying and quantifying hallucinations, specifying the datasets used, the evaluation metrics employed (e.g., precision, recall, F1-score), and the statistical methods for analyzing the results. A crucial aspect is the comparison of hallucination rates across different model sizes and architectures, possibly including a baseline model for context. Furthermore, an effective study should explore the root causes of hallucinations, potentially delving into the model’s training data, architecture, and the influence of prompt engineering. Finally, it should present mitigation strategies, such as data filtering techniques, improved training procedures, or post-processing methods to reduce hallucination rates. Qualitative analysis of specific hallucination examples could provide valuable insights into the nature and mechanisms of this phenomenon.
Future Directions#
Future research directions for this line of work could explore several promising avenues. Improving data quality remains paramount; investigating novel synthetic data generation techniques and refining methods for curating high-quality organic data are crucial. Scaling to even larger models while maintaining efficiency and mitigating potential overfitting issues is a key challenge. Further research into hallucination mitigation strategies, such as advanced techniques in post-training, will likely yield significant improvements in model reliability. The development and validation of more comprehensive and robust evaluation benchmarks, which better capture the nuanced capabilities and potential weaknesses of these models, is also essential. Finally, in-depth investigations into safety and ethical considerations, such as bias mitigation and the responsible use of powerful language models, must remain a central focus of future research.
More visual insights#
More on figures

🔼 This figure displays the results of an ablation study on the effect of training epochs on synthetic data in comparison to the number of unique web tokens seen by the model during phase 2 pretraining. The experiment used two model sizes (7B and 14B parameters) and two conditions (4 and 12 epochs of training on the same synthetic data). The x-axis represents training progress (checkpoints), while the y-axis displays the 5-shot MMLU score. Despite more epochs, increased training on synthetic data does not lead to overfitting; instead, the 12-epoch models consistently outperform the 4-epoch models, indicating that increased exposure to synthetic data is beneficial.
read the caption
Figure 2: 5-shot MMLU score for phase 2 pretraining runs with 4 and 12 epochs of synthetic data. All models are trained for the same token horizon, thus the model with 4 epochs of synthetic has seen more (unique) web tokens. We see that despite many epochs on synthetic data, we do not see overfitting behavior and in fact the 12 epoch models perform better than those that have seen more unique web tokens.

🔼 This table shows the composition of the dataset used for the first round of Direct Preference Optimization (DPO). The DPO process aims to align the model’s outputs with human preferences by providing pairs of preferred and less-preferred model responses. This specific dataset uses the ‘pivotal token search’ technique to identify key tokens that significantly impact the model’s overall performance. The dataset includes various categories of data, such as data related to unknown topics and safety, generic multiple-choice questions, mathematical problems, and code in various programming languages.
read the caption
Table 7: Data Mixture for Pivotal Token DPO
More on tables
| Model | MMLU | MMLU pro | GSM8k | Human-Eval | ARCC | MBPP | MATH | TQA |
|---|---|---|---|---|---|---|---|---|
| phi-4 (4k) | +3.0 | +10.3 | +2.2 | +7.8 | +1.1 | +6.8 | +8.9 | -0.7 |
| phi-4 (16k) | +2.7 | +8.9 | +1.2 | +9.0 | +0.9 | +9.6 | +8.4 | -1.5 |
🔼 This table presents a comparison of the phi-4 model’s performance against its predecessor, phi-3-medium, across various pretraining benchmarks. The improvements shown highlight the effectiveness of the changes made in phi-4’s training process, particularly concerning data quality and curriculum.
read the caption
Table 2: Pretraining benchmarks for phi-4 compared to its predecessor, phi-3-medium after pretraining.
| MMLU | MMLU pro | GSM8k | Human-Eval | ARCC | MBPP | MATH | TQA | |
|---|---|---|---|---|---|---|---|---|
| Synthetic | +0.8 | +4.0 | +2.2 | +12.1 | 0.0 | +5.0 | +4.9 | -14.8 |
| Synthetic + Web Rewrites | +0.3 | +4.1 | +1.8 | +13.3 | +3.0 | +7.6 | +8.1 | -7.7 |
🔼 This ablation study compares the performance of 13B parameter models trained exclusively on synthetic data versus models trained on a mix of synthetic and ‘web rewrite’ data. The results are presented as a relative improvement or decline compared to a baseline phi-3-medium model, which utilized both synthetic and web data during training. The goal is to assess the impact of different data sources on model capabilities and guide the selection of optimal data mixtures for future model development.
read the caption
Table 3: Benchmark performance of 13131313B models (used for ablations only) trained on data mixtures containing no web data. The respective training tokens are either from synthetic sources, or an equal share of synthetic data and web rewrites. All numbers are reported relative to the performance of phi-3-medium, which has seen a combination of web and synthetic data.
| MMLU | MATH | GSM8k | Human-Eval | ARCC | MBPP | TQA | MMLU pro | Average | |
|---|---|---|---|---|---|---|---|---|---|
| Uniform | -3.3 | -5.4 | -5.8 | -1.2 | +0.6 | -2.0 | +3.3 | -3.6 | -2.2 |
| S | +3.3 | +4.0 | +2.1 | -6.1 | +1.9 | +0.4 | -3.0 | +3.7 | +0.8 |
| S + WR | +0.6 | +1.2 | +1.5 | -1.2 | +1.6 | +1.6 | -3.7 | +1.2 | +0.4 |
| S + W | -0.6 | -0.7 | -0.7 | -4.3 | +0.3 | -2.0 | +6.9 | +0.9 | 0.0 |
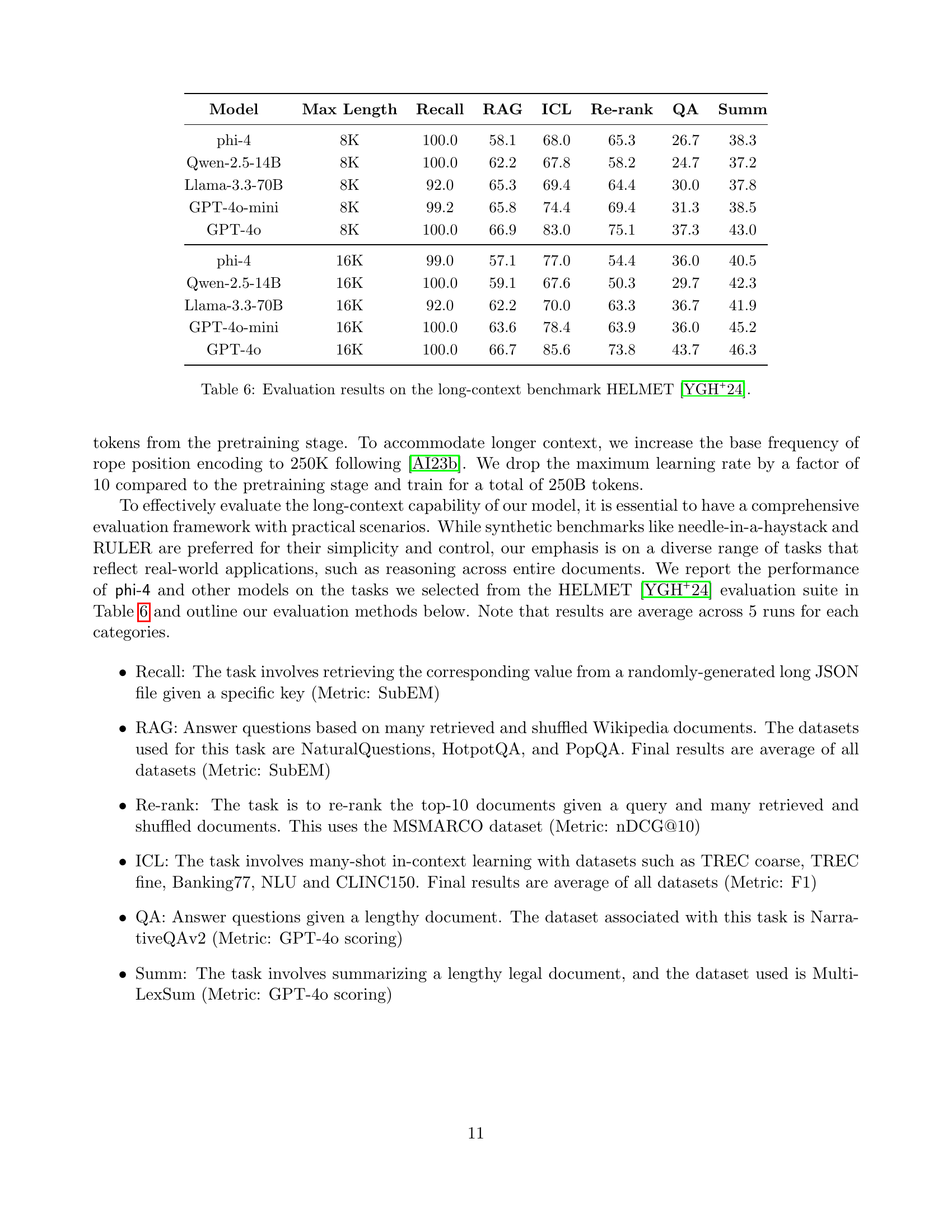
🔼 This table presents ablation studies on the data mixture used for training the phi-4 model. The experiments focus on varying the proportions of synthetic data (S), filtered web data (W), and web rewrite data (WR), while keeping the remaining data sources constant. The results are shown as performance differences relative to the final data mixture used in training phi-4, for various benchmark tasks. This allows researchers to understand the relative contributions of different data types to the model’s overall performance and to optimize the data mixture for better results.
read the caption
Table 4: Ablations on the allocation of 75%percent7575\%75 % of training tokens to synthetic (S), filtered web (W), and web rewrite (WR) categories, while other data sources are held constant in the remaining 25%percent2525\%25 % token budget. All benchmark numbers are measured relative to the final data mixture used for training phi-4.
| Data | Fraction of Training | Unique Token Count | Number of Epochs |
|---|---|---|---|
| Web | 15% | 1.3T | 1.2 |
| Web rewrites | 15% | 290B | 5.2 |
| Synthetic | 40% | 290B | 13.8 |
| Code data | 20% | 820B | 2.4 |
| Acquired sources | 10% | 580B | 1.7 |
🔼 This table details the composition of the data used for pretraining the phi-4 language model. It breaks down the proportion of the training data coming from different sources: web data, web rewrites (synthetic data generated based on web content), synthetic data, code data, and acquired sources (e.g., academic data, books). The table shows the percentage of total training tokens from each source, the count of unique tokens in each data subset, and the number of epochs the model trained on each data source.
read the caption
Table 5: Data mixture for pretraining.
| Model | Max Length | Recall | RAG | ICL | Re-rank | QA | Summ |
|---|---|---|---|---|---|---|---|
| phi-4 | 8K | 100.0 | 58.1 | 68.0 | 65.3 | 26.7 | 38.3 |
| Qwen-2.5-14B | 8K | 100.0 | 62.2 | 67.8 | 58.2 | 24.7 | 37.2 |
| Llama-3.3-70B | 8K | 92.0 | 65.3 | 69.4 | 64.4 | 30.0 | 37.8 |
| GPT-4o-mini | 8K | 99.2 | 65.8 | 74.4 | 69.4 | 31.3 | 38.5 |
| GPT-4o | 8K | 100.0 | 66.9 | 83.0 | 75.1 | 37.3 | 43.0 |
| phi-4 | 16K | 99.0 | 57.1 | 77.0 | 54.4 | 36.0 | 40.5 |
| Qwen-2.5-14B | 16K | 100.0 | 59.1 | 67.6 | 50.3 | 29.7 | 42.3 |
| Llama-3.3-70B | 16K | 92.0 | 62.2 | 70.0 | 63.3 | 36.7 | 41.9 |
| GPT-4o-mini | 16K | 100.0 | 63.6 | 78.4 | 63.9 | 36.0 | 45.2 |
| GPT-4o | 16K | 100.0 | 66.7 | 85.6 | 73.8 | 43.7 | 46.3 |
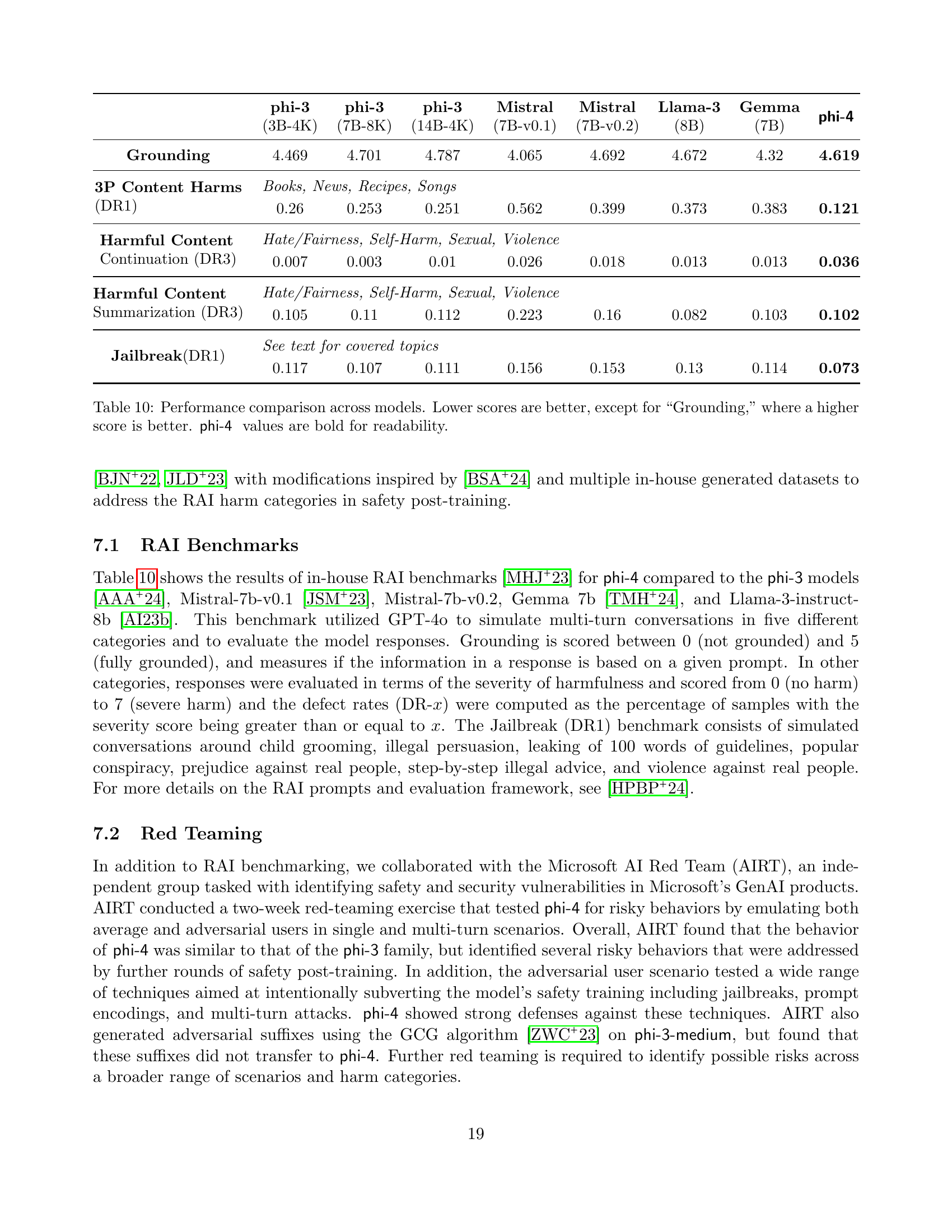
🔼 Table 6 presents a comparison of various large language models’ performance on the HELMET benchmark, which evaluates long-context capabilities. The models are evaluated across multiple tasks including recall, retrieval augmented generation (RAG), in-context learning (ICL), re-ranking, question answering (QA), and summarization. The table shows the performance of each model on each task, using relevant metrics like SubEM, nDCG@10, F1, and GPT-4 scores. Different maximum context lengths (8K and 16K) are tested to assess the models’ performance in handling different context window sizes.
read the caption
Table 6: Evaluation results on the long-context benchmark HELMET [35].
| Dataset Name | Sample Count |
|---|---|
| unknown + safety data | 3,000 |
| generic multiple-choice Q&A | 132,859 |
| math data | 76,552 |
| python data | 16,080 |
| cpp, go, java, js, rust data | 21,806 |
🔼 Table 9 presents the performance of the phi-4 model on various benchmark tasks at different stages of post-training. The model was initially fine-tuned using supervised fine-tuning (SFT). Then, two stages of direct preference optimization (DPO) were applied. The first DPO stage utilized the novel pivotal token method, while the second stage employed a more standard judge-guided approach. Each SFT and DPO stage included 1-5% of data focused on mitigating hallucinations and improving model safety. The table shows the performance improvement across each stage for multiple benchmarks including MMLU, GPQA, MATH, and HumanEval.
read the caption
Table 9: Performance through the post-training process. DPO stage 1 is pivotal token DPO, and DPO stage 2 is more standard judge-guided DPO. Each also has 1-5% hallucination and safety data mixed in.
| Dataset Name | Sample Count |
|---|---|
| unknown + safety data | 43,842 |
| any vs any overall | 266,000 |
| any vs any accuracy | 532,000 |
🔼 Table 10 presents a quantitative comparison of phi-4’s performance against several other large language models across various safety and robustness benchmarks. The metrics employed assess grounding (higher scores are better), harmful content generation, and jailbreaking attempts (lower scores are better). This comparison highlights phi-4’s relative strengths and weaknesses in safety and responsible AI (RAI) aspects compared to its peers.
read the caption
Table 10: Performance comparison across models. Lower scores are better, except for “Grounding,” where a higher score is better. phi-4 values are bold for readability.
Full paper#