↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) are increasingly used in real-world applications, yet their ability to accurately follow complex rules remains a significant challenge. Existing benchmarks often oversimplify the problem, using artificial or single-step logic tasks. This limits our understanding of how well LLMs perform in situations that require complex reasoning and understanding of multifaceted, nuanced rules, creating potentially significant risks in real-world deployment.
To address this issue, the researchers introduce RULEARENA, a novel benchmark designed to evaluate LLMs’ proficiency in following complex rules grounded in real-world scenarios. RULEARENA includes tasks from three diverse domains—airline baggage fees, NBA transactions, and tax regulations— each with a set of realistic rules. The benchmark assesses LLMs’ ability to understand complex natural language instructions, perform logical reasoning, and execute accurate mathematical computations. The findings reveal significant limitations in current LLMs, highlighting the challenges of advancing their rule-guided reasoning abilities.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for robust benchmarks evaluating LLMs’ real-world rule-following abilities. Current benchmarks often lack the complexity and realism of real-world scenarios, hindering the development of truly reliable and safe LLMs. This work directly contributes to bridging this gap, guiding future research and development efforts toward more trustworthy AI systems.
Visual Insights#
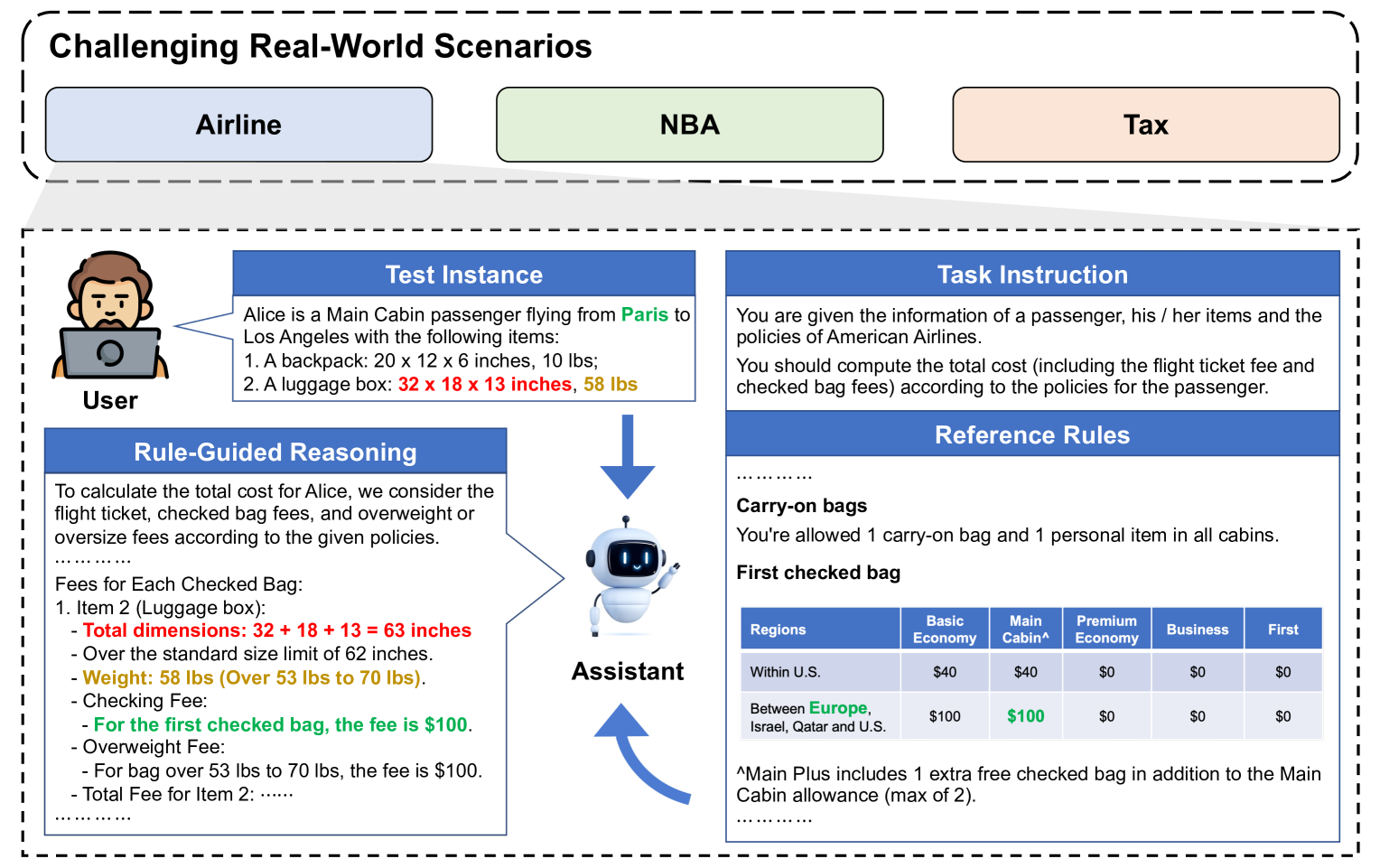
🔼 RULEARENA is a benchmark dataset for evaluating LLMs’ ability to perform rule-guided reasoning on real-world tasks. It contains 95 rules and 816 test problems across three domains: airline baggage fees, NBA transactions, and tax policies. Each problem presents an LLM with a user’s request, the relevant rules, and asks the LLM to conduct the reasoning and calculations necessary to provide a correct answer based on those rules.
read the caption
Figure 1: Overview of RuleArena. RuleArena contains 95 commonly used and moderately complex rules and 816 test problems from three representative real-world scenarios - airline luggage fees, NBA transactions, and taxation policies. LLMs are given a the task instruction, the reference rules in this scenario, and a user instance, and required to conduct reasoning and computation for the user input under the guidance of reference rules.
| Airline | NBA | Tax |
|---|---|---|
| # Rules | 10 | 54 |
| Average # Tokens | 376 | 398 |
🔼 This table presents a statistical summary of the rules used in each of the three domains included in the RULEARENA benchmark: Airline, NBA, and Tax. For each domain, it shows the number of rules, and the average number of tokens (words or sub-words) per rule. This information gives an indication of the complexity and length of the rules that the large language models (LLMs) need to process in the benchmark.
read the caption
Table 1: Statistics of rules in each domain.
In-depth insights#
LLM Rule Limits#
LLMs demonstrate significant limitations when tasked with complex, real-world rule-following. Rule recall is a major challenge; LLMs frequently fail to identify all necessary rules, especially those less central or applicable under specific conditions. This points to a lack of complete understanding of rule interdependencies. Even when rules are identified, accuracy in rule application is inconsistent. While LLMs often perform well on simpler mathematical or logical computations within a rule, errors can significantly impact the final outcome. The use of similar-but-distinct rules presents further problems, as LLMs struggle to differentiate and correctly apply the appropriate rule in context, leading to mistakes. Distracting information or extraneous rules significantly impair performance, demonstrating the models’ susceptibility to irrelevant information. Improving these aspects requires focusing on enhancing LLMs’ comprehensive understanding of rules, improving computational accuracy, and enhancing their ability to filter out irrelevant information.
Real-World Rules#
The concept of “Real-World Rules” in the context of a research paper likely refers to the challenges of applying formal logical rules to real-world scenarios. Real-world problems rarely map neatly onto the clean, unambiguous structures of formal logic; they’re messy, nuanced, and often involve conflicting or incomplete information. A key insight would be exploring how the paper addresses this gap, perhaps by proposing a methodology for adapting or interpreting formal rules for practical application, or by highlighting the limitations of current systems when faced with the inherent ambiguity of real-world contexts. The discussion might examine specific examples where the discrepancy between formal logic and real-world application is significant, potentially analyzing failure cases and suggesting potential solutions. Another vital element would involve identifying the types of rules that pose the greatest challenges, whether it’s those involving complex conditional statements, mathematical computations, or extensive contextual factors. Essentially, a strong section on “Real-World Rules” would provide a critical evaluation of the applicability and limitations of rule-based systems in a realistic setting.
Benchmark Design#
A robust benchmark design for evaluating LLMs’ rule-guided reasoning necessitates real-world applicability, moving beyond artificial or simplified scenarios. The selection of domains should reflect diverse rule complexities and natural language nuances, such as airline baggage fees, NBA regulations, or tax codes. Comprehensive rule sets are crucial, encompassing various rule types, interdependencies, and levels of specificity. The benchmark must incorporate a range of problem difficulty levels, systematically varying the complexity of the input data and required reasoning steps. Evaluation metrics should go beyond simple accuracy, capturing rule recall, precision in rule selection, and the correctness of rule application. The design should also consider factors that could confound LLM performance, such as the presence of distractor rules or the influence of in-context examples. Finally, a well-designed benchmark should offer transparent annotation and data collection methodologies allowing for reproducibility and further analysis of LLM limitations.
Eval Metrics#
A robust evaluation methodology is crucial for assessing the effectiveness of Large Language Models (LLMs) in rule-guided reasoning. Comprehensive evaluation metrics should move beyond simple accuracy measures and delve into the intricacies of the reasoning process. This requires a multi-faceted approach, examining not only the final answer but also the intermediate steps and rule application. Key metrics should include rule recall (were all relevant rules identified?), rule precision (were only relevant rules applied?), and rule application correctness (were the rules applied accurately?). Furthermore, the evaluation should consider different levels of problem complexity, allowing for a nuanced understanding of LLM capabilities across various difficulty levels. Careful consideration of the specific tasks and rule sets used in the evaluation is also paramount, ensuring that the metrics accurately reflect real-world scenarios and avoid biases. Finally, the chosen metrics should be easily interpretable and provide actionable insights for future model development.
Future Work#
The ‘Future Work’ section of this research paper on LLMs and rule-guided reasoning could significantly benefit from exploring hybrid reasoning systems that combine the strengths of LLMs with symbolic reasoning methods. This approach could address the limitations of LLMs in handling complex rules by incorporating the precision and reliability of symbolic methods. Furthermore, research should focus on improving the automation of evaluation. Currently, relying on LLMs to parse responses for analysis introduces potential biases and limitations. Developing fully automated evaluation methods would enhance the objectivity and scalability of the benchmark. Finally, the research should delve into training LLMs with rule-guided reasoning data, investigating whether pretraining or fine-tuning on such data enhances their performance on complex rule-following tasks. This approach could lead to more robust and reliable LLMs capable of handling real-world applications demanding accurate rule-guided reasoning.
More visual insights#
More on figures

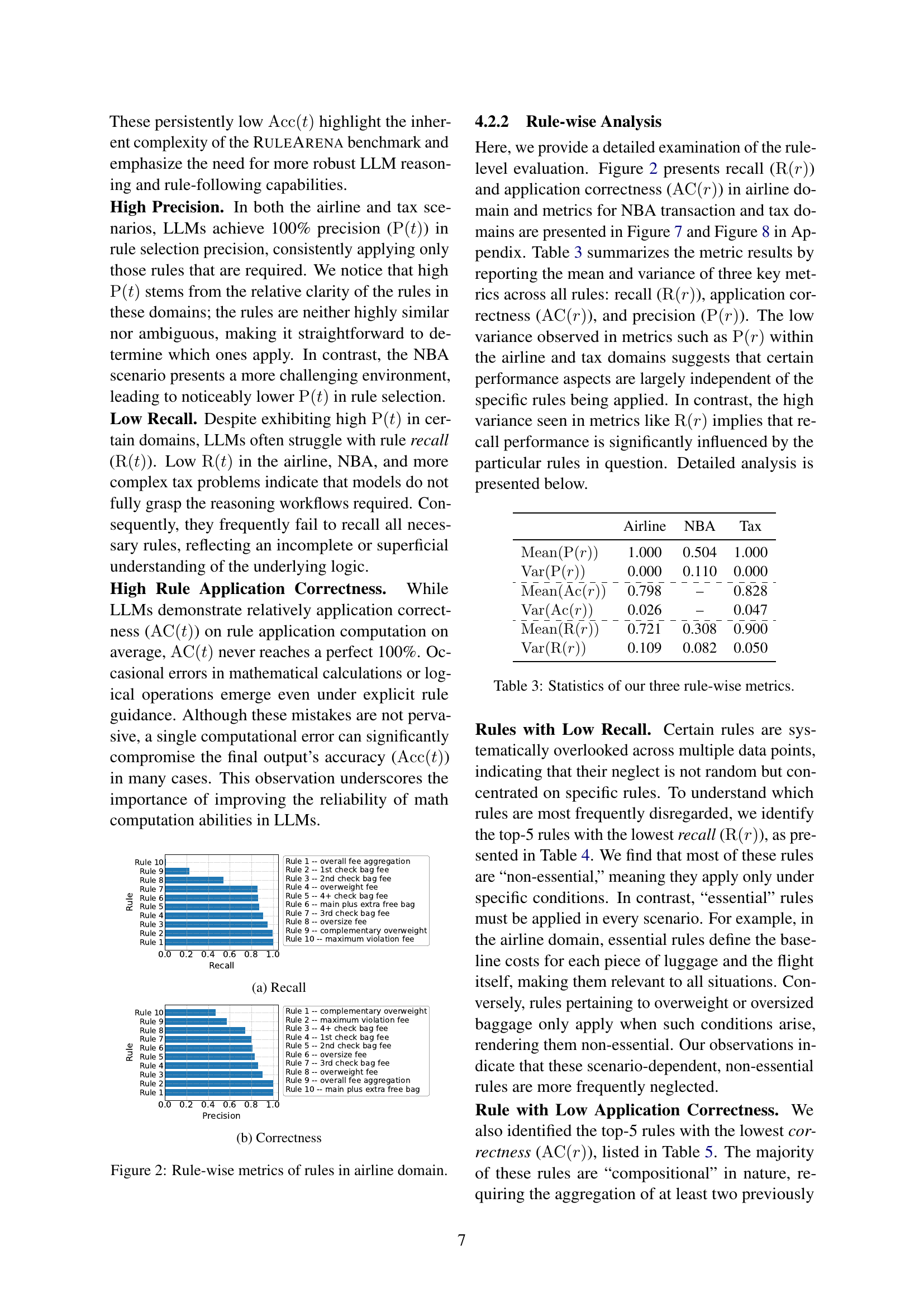
🔼 This bar chart visualizes the rule-wise recall metric for the airline domain. The x-axis represents individual rules, ordered from lowest to highest recall, while the y-axis indicates the recall score (proportion of problems the LLM correctly applied each rule to). Each bar’s height corresponds to a specific rule’s recall, demonstrating the relative effectiveness of different rules in this context. Rules with higher recall are more consistently applied by the LLM. Conversely, lower recall highlights rules where the model’s performance was less successful.
read the caption
(a) Recall

🔼 This figure shows the rule-wise application correctness of rules in the airline domain. The x-axis represents the rules, and the y-axis represents the correctness score. Each bar shows the correctness of applying a particular rule in the airline domain, indicating the proportion of times the LLM applied a given rule correctly.
read the caption
(b) Correctness

🔼 This figure shows the performance of large language models (LLMs) on a rule-by-rule basis for the airline domain. It presents two bar charts displaying the recall and precision for each of the rules used in the airline baggage fee calculation task. Higher bars indicate better performance for a given rule. The x-axis represents the individual rules, and the y-axis represents the recall and precision scores. This visualization allows for a granular analysis of the model’s understanding and application of specific rules in the complex airline baggage fee calculation process.
read the caption
Figure 2: Rule-wise metrics of rules in airline domain.

🔼 Figure 2(a) shows the recall of rules in the airline domain. The x-axis represents the rules, and the y-axis represents the recall. The height of each bar corresponds to the recall of the corresponding rule. It is observed that some rules have perfect recall, meaning the LLM always applies them correctly when needed, while others have lower recall, indicating the LLM sometimes fails to apply them correctly even when needed.
read the caption
(a) Airline

🔼 This figure shows the results of problem-wise analysis for the NBA transaction domain. It presents the precision (P(t)), rule application correctness (AC(t)), recall (R(t)), and accuracy (Acc(t)) for different LLMs (Llama-3.1 70B, Qwen-2.5 72B, Llama-3.1 405B, Claude-3.5 Sonnet, and GPT-40) under varying levels of difficulty (Level 1, Level 2, Level 3). Both 0-shot and 1-shot prompting strategies are compared. The data illustrate the LLMs’ performance in applying relevant rules correctly to solve NBA transaction problems according to the specified regulations.
read the caption
(b) NBA

🔼 This figure shows the correlation between problem-wise metrics (recall, correctness, and precision) and accuracy for the tax domain in the RULEARENA benchmark. It visually represents the relationship between the accuracy of LLM’s answers and how well they recalled, correctly applied, and precisely selected the relevant rules for each problem. The x-axis represents the range of recall/correctness/precision values, while the y-axis represents accuracy.
read the caption
(c) Tax
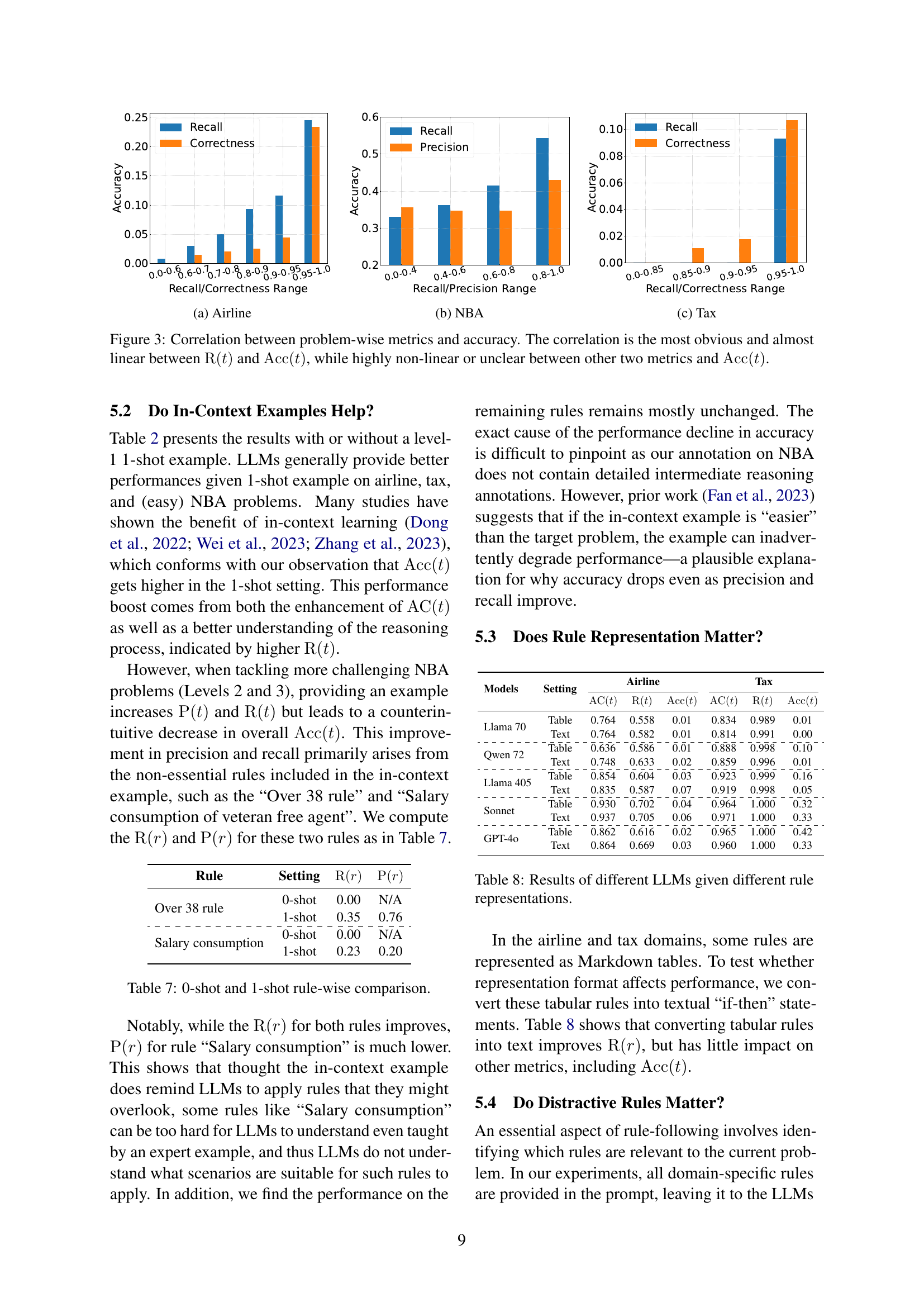
🔼 This figure displays the correlation analysis between accuracy and other problem-wise metrics (precision, recall, rule application correctness). The results show a strong, nearly linear positive correlation between accuracy and recall, indicating that higher recall strongly predicts higher accuracy. In contrast, the correlations between accuracy and precision, and accuracy and rule application correctness are considerably weaker and highly non-linear, suggesting that achieving high precision or rule application correctness alone is not sufficient to guarantee high overall accuracy. The figure helps visualize and understand how different factors contribute to successful rule-following performance in the three benchmark domains.
read the caption
Figure 3: Correlation between problem-wise metrics and accuracy. The correlation is the most obvious and almost linear between R(t)R𝑡{\rm R}(t)roman_R ( italic_t ) and Acc(t)Acc𝑡{\rm Acc}(t)roman_Acc ( italic_t ), while highly non-linear or unclear between other two metrics and Acc(t)Acc𝑡{\rm Acc}(t)roman_Acc ( italic_t ).

🔼 This figure shows the correlation between the problem-wise correctness metric and the accuracy metric across three different domains (Airline, NBA, and Tax). It demonstrates how well the large language models (LLMs) apply the rules correctly in relation to the overall accuracy of their problem solutions. The relationship is analyzed and visualized in three separate charts to better showcase the performance across all three domains.
read the caption
(a) Correctness
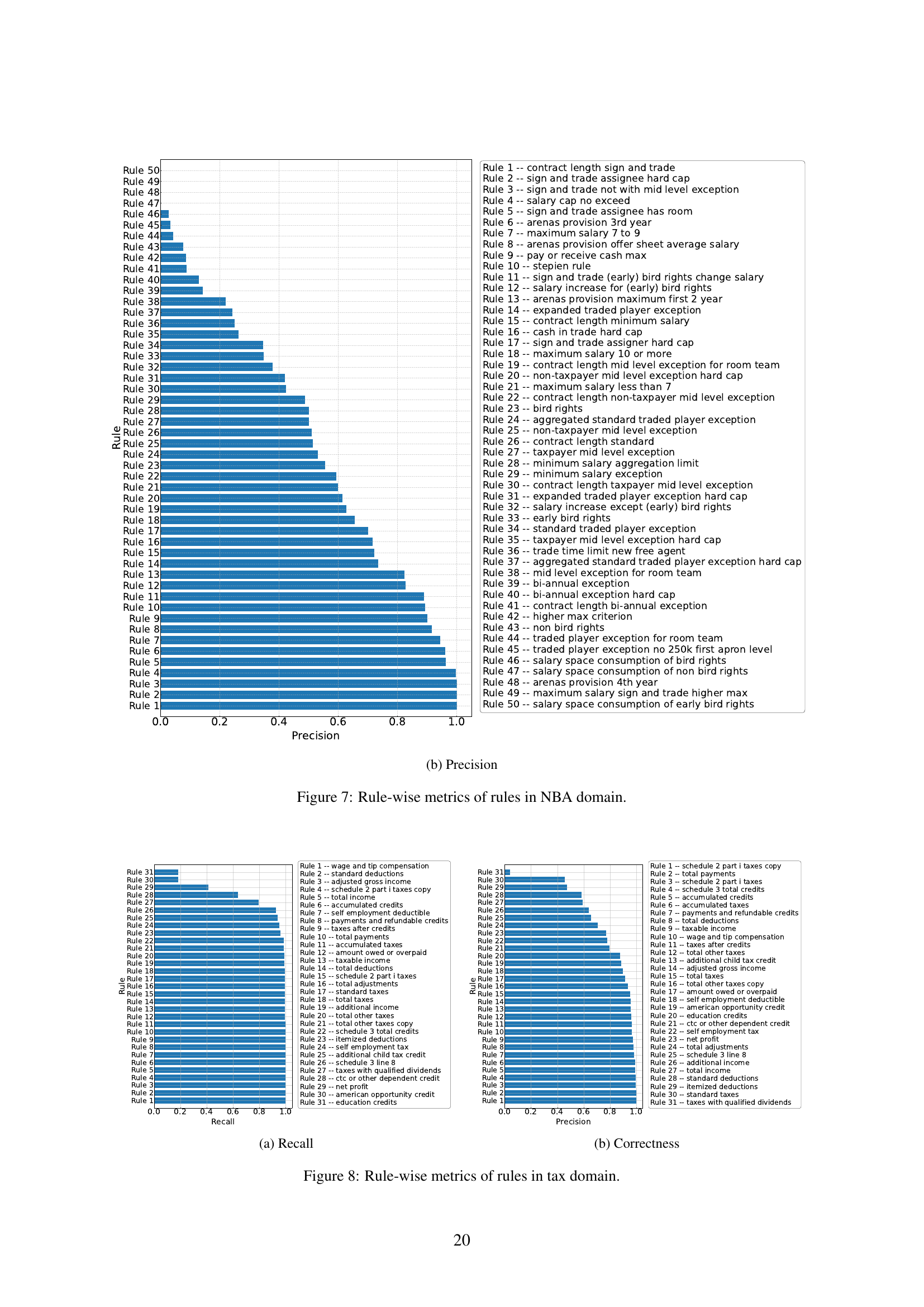
🔼 This bar chart visualizes the rule-wise recall of rules within the NBA domain. The x-axis represents individual rules, numbered 1 through 52. The y-axis denotes the recall rate, ranging from 0.0 to 1.0. Each bar’s height corresponds to a specific rule’s recall rate, indicating the proportion of times the rule was correctly applied across the dataset by LLMs. The chart offers a granular view of the rules’ recall performance, helping to identify rules that are consistently or inconsistently applied by LLMs.
read the caption
(b) Recall

🔼 This figure shows the correlation between the problem-wise accuracy (Acc(t)) and other metrics (Recall, Correctness, Precision) for the Tax domain in the RULEARENA benchmark. It visually represents how well the LLMs accurately answer the problems compared to the ground truth, considering the influence of rule recall, correct rule application, and the precision of rule selection. The x-axis displays the ranges of Recall/Precision/Correctness, and the y-axis represents the corresponding accuracy.
read the caption
(c) Accuracy

🔼 This figure demonstrates the impact of irrelevant information and increased context length on the performance of Large Language Models (LLMs) in tax calculations. Three experimental conditions are compared: a standard setting with only relevant information, a distractor setting where irrelevant (but seemingly valid) tax forms are added, and a placeholder setting where meaningless tokens are added to match the length of the distractor forms. The results show that while additional context length (placeholder setting) has a minimal impact on performance, the addition of irrelevant tax forms significantly reduces the accuracy of LLMs. This highlights LLMs’ vulnerability to distraction from irrelevant information, even if the added information is seemingly valid and not inherently contradictory.
read the caption
Figure 4: The effect of distractive rules and context length. The “Standard” mode refers to the default setting of Level 1 tax problems, the “Distractor” mode appends nullified forms after the “Standard” input, and the “Placeholder” mode adds meaningless tokens on space lines. Distractive rules lead to a significant drop on the performances of all LLMs, while meaningless tokens make little difference to the performance.

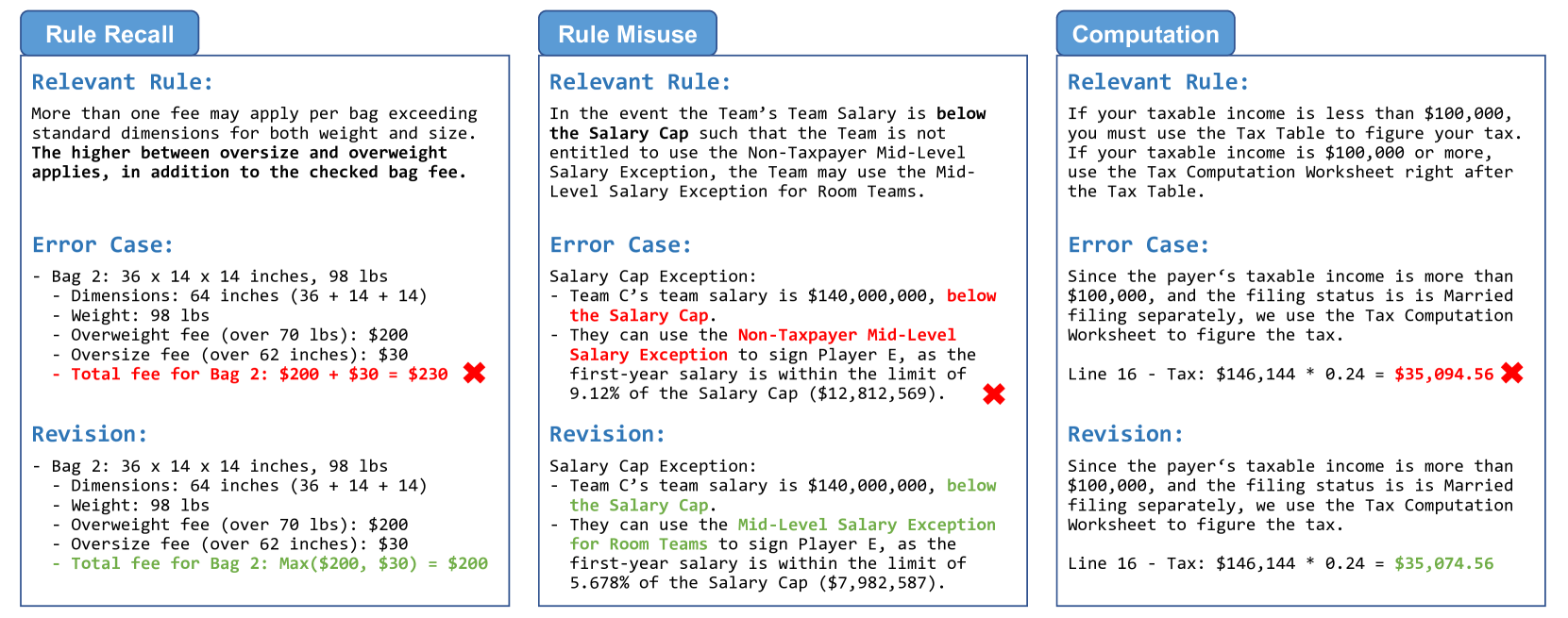
🔼 Figure 5 presents three examples showcasing common failure modes of Large Language Models (LLMs) when performing rule-guided reasoning tasks. The first example demonstrates inadequate rule recall, where the LLM overlooks a crucial rule leading to an incorrect calculation. The second example shows inappropriate usage of similar rules, where the LLM confuses similar but distinct regulations. The third example highlights computation errors, where the LLM makes a mathematical mistake, resulting in an incorrect final answer. These examples highlight the challenges LLMs face in accurately applying rules and performing complex computations, even when given comprehensive instructions.
read the caption
Figure 5: Failure Case Studies. Existing LLMs commonly fail due to inadequate rule recall, inappropriate usage of similar rules, and computation errors.

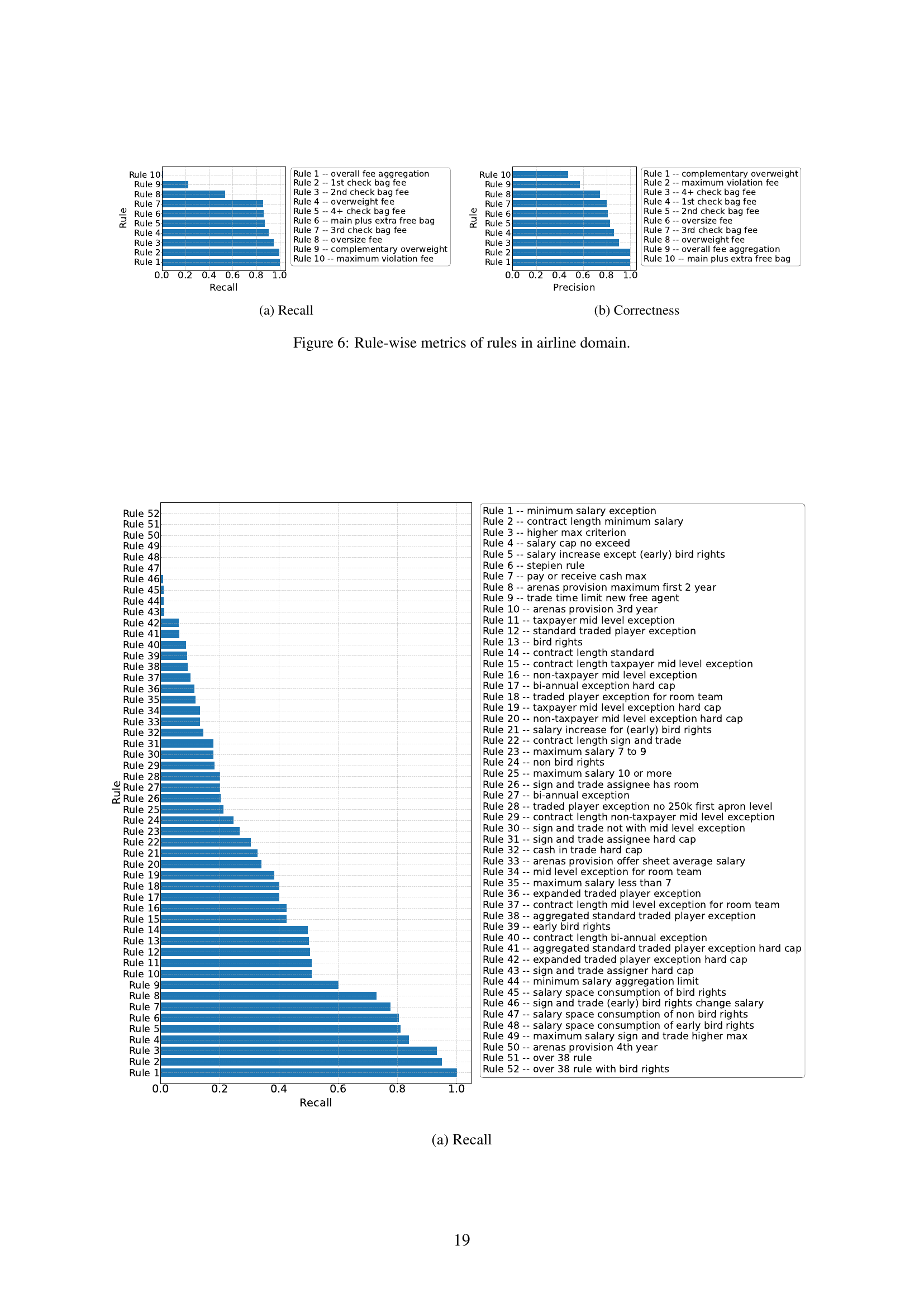
🔼 This figure shows the rule-wise recall of rules in the airline domain. The x-axis represents the rules, and the y-axis represents the recall rate. Each bar corresponds to a rule, and its height indicates the recall rate for that rule. The rules are ordered from highest recall to lowest recall.
read the caption
(a) Recall

🔼 This figure shows the rule-wise application correctness of rules in the airline domain. The x-axis represents the rules, ordered by correctness score. The y-axis represents the application correctness score for each rule, indicating the proportion of times the LLM correctly applied the rule. A higher bar indicates higher correctness.
read the caption
(b) Correctness

🔼 This figure shows the performance of large language models (LLMs) on a rule-by-rule basis for the airline domain of the RULEARENA benchmark. It presents two bar charts: one for recall (R(r)) and one for application correctness (AC(r)). Each bar represents a specific rule, and the height of the bar indicates the metric’s value for that rule. This visualization allows for a detailed analysis of which rules are easier or harder for LLMs to correctly identify and apply, highlighting potential weaknesses in the models’ rule-guided reasoning capabilities in real-world scenarios.
read the caption
Figure 6: Rule-wise metrics of rules in airline domain.
More on tables
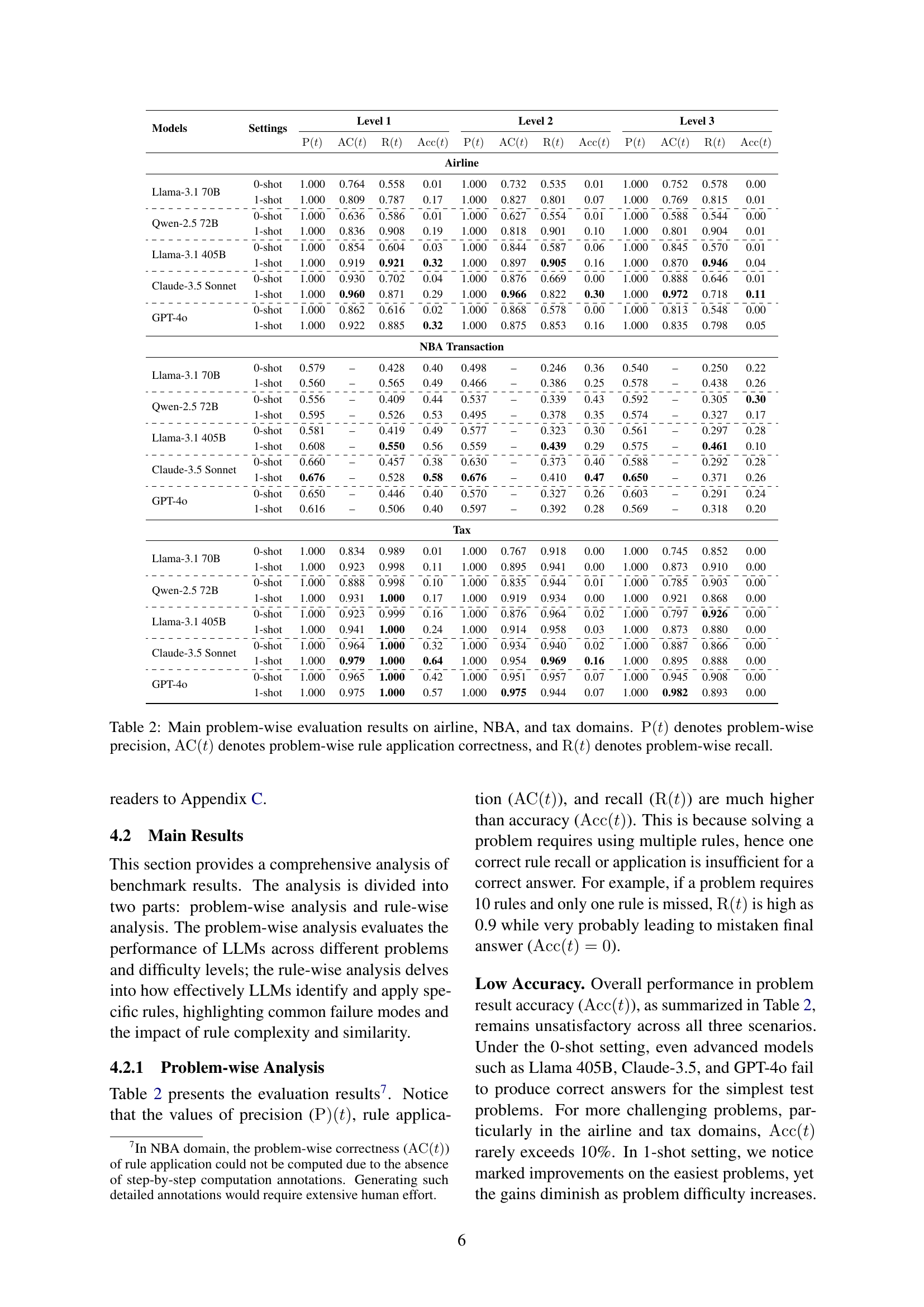
🔼 This table presents the performance of various large language models (LLMs) on three different real-world scenarios: airline baggage fees, NBA transactions, and tax calculations. The performance is evaluated across three difficulty levels for each scenario. The metrics used are problem-wise precision (P(t)), indicating the proportion of correctly identified relevant rules; problem-wise rule application correctness (AC(t)), showing the proportion of correctly applied rules; and problem-wise recall (R(t)), representing the proportion of relevant rules successfully applied.
read the caption
Table 2: Main problem-wise evaluation results on airline, NBA, and tax domains. P(t)P𝑡{\rm P}(t)roman_P ( italic_t ) denotes problem-wise precision, AC(t)AC𝑡{\rm AC}(t)roman_AC ( italic_t ) denotes problem-wise rule application correctness, and R(t)R𝑡{\rm R}(t)roman_R ( italic_t ) denotes problem-wise recall.
| Airline | NBA | Tax | |
|---|---|---|---|
| Mean(P(r)) | 1.000 | 0.504 | 1.000 |
| Var(P(r)) | 0.000 | 0.110 | 0.000 |
| Mean(Ac(r)) | 0.798 | – | 0.828 |
| Var(Ac(r)) | 0.026 | – | 0.047 |
| Mean(R(r)) | 0.721 | 0.308 | 0.900 |
| Var(R(r)) | 0.109 | 0.082 | 0.050 |
🔼 This table presents a statistical summary of three key rule-wise metrics (Recall, Application Correctness, and Precision) across all rules within the Airline, NBA, and Tax domains of the RULEARENA benchmark. It shows the mean and variance for each metric in each domain, offering insights into the consistency and variability of LLM performance at the rule level.
read the caption
Table 3: Statistics of our three rule-wise metrics.
| Airline | essential | NBA | essential | Tax | essential |
|---|---|---|---|---|---|
| maximum violation fee | salary space consumption of bird right | education credits | |||
| complementary overweight | salary space consumption of early bird right | american opportunity credit | |||
| oversize fee | sign and trade maximum salary | ✓ | net profit | ||
| 3rd base check fee | ✓ | Arenas provision | ctc or other dependent credit | ||
| main plus extra free bag | over 38 rule | taxes with qualified dividends | ✓ |
🔼 This table lists the top five rules from the Airline, NBA, and Tax domains that were least frequently applied correctly by LLMs. It highlights the non-essential rules that are often overlooked, illustrating challenges with recall in the model’s rule-guided reasoning.
read the caption
Table 4: Top-5555 rules of the lowest recall in ascent order of recall.
| Airline | Tax | ||
|---|---|---|---|
| Rule | Composition | Rule | Composition |
| main plus extra free bag | ✓ | taxes with qualified dividends | ✓ |
| overall fee aggregation | ✓ | standard taxes | |
| overweight fee matching | itemized deductions | ✓ | |
| 3rd base check fee | standard deductions | ✓ | |
| oversize fee matching | ✓ | total income | ✓ |
🔼 This table presents the five rules with the lowest correctness scores in the RULEARENA benchmark’s Airline domain, ordered by increasing correctness. The ‘correctness’ metric assesses whether the LLM correctly applied the rule in the problems where the rule was relevant.
read the caption
Table 5: Top-5555 rules of the lowest correctness in ascent order of correctness.
| Rule | Substitutable |
|---|---|
| higher max criterion | |
| non bird right | ✓ |
| taxpayer mid level exception hard cap | ✓ |
| standard traded player exception | ✓ |
| salary increase ratio except bird right | ✓ |
🔼 This table presents the top five rules with the lowest precision in the NBA domain, ordered by ascending precision values. It highlights rules where the model frequently misapplies them, often confusing them with similar rules due to subtle differences in application conditions. The table helps to illustrate the challenges posed by similar-looking rules in a complex, real-world scenario.
read the caption
Table 6: Top-5555 rules of the lowest precision in ascent order of precision.
| Rule | Setting | R(r) | P(r) |
|---|---|---|---|
| Over 38 rule | 0-shot | 0.00 | N/A |
| 1-shot | 0.35 | 0.76 | |
| Salary consumption | 0-shot | 0.00 | N/A |
| 1-shot | 0.23 | 0.20 |
🔼 This table compares the performance of LLMs in applying rules when using zero-shot and one-shot prompting strategies. It shows the recall (R(r)) and precision (P(r)) for two specific rules: ‘Over 38 rule’ and ‘Salary consumption’ in the NBA transaction domain. These metrics reveal how well LLMs identify and apply these rules accurately under different prompting conditions.
read the caption
Table 7: 0-shot and 1-shot rule-wise comparison.
| Models | Setting | Airline AC(t) | Airline R(t) | Airline Acc(t) | Tax AC(t) | Tax R(t) | Tax Acc(t) |
|---|---|---|---|---|---|---|---|
| Llama 70 | Table | 0.764 | 0.558 | 0.01 | 0.834 | 0.989 | 0.01 |
| Text | 0.764 | 0.582 | 0.01 | 0.814 | 0.991 | 0.00 | |
| Qwen 72 | Table | 0.636 | 0.586 | 0.01 | 0.888 | 0.998 | 0.10 |
| Text | 0.748 | 0.633 | 0.02 | 0.859 | 0.996 | 0.01 | |
| Llama 405 | Table | 0.854 | 0.604 | 0.03 | 0.923 | 0.999 | 0.16 |
| Text | 0.835 | 0.587 | 0.07 | 0.919 | 0.998 | 0.05 | |
| Sonnet | Table | 0.930 | 0.702 | 0.04 | 0.964 | 1.000 | 0.32 |
| Text | 0.937 | 0.705 | 0.06 | 0.971 | 1.000 | 0.33 | |
| GPT-4o | Table | 0.862 | 0.616 | 0.02 | 0.965 | 1.000 | 0.42 |
| Text | 0.864 | 0.669 | 0.03 | 0.960 | 1.000 | 0.33 |
🔼 This table compares the performance of different large language models (LLMs) on a rule-following task. Specifically, it shows how each LLM performs when given rules in two different formats: a table format and a text format. The comparison allows for an analysis of whether the representation of the rules (tabular vs. textual) influences the LLMs’ accuracy, recall, and correctness in applying the rules to solve a problem.
read the caption
Table 8: Results of different LLMs given different rule representations.
Full paper#