↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Controllable human image animation, aiming to generate videos from reference images using driving videos, faces challenges. Existing methods often rely on dense guidance (depth maps, etc.), which limits their ability to handle variations in body shape between the reference and driving video and hinder the overall quality. Sparse guidance (skeleton pose) is less restrictive but provides limited control. The inconsistent quality and appearance is also a major issue.
DisPose tackles these issues by disentangling sparse pose guidance into motion field estimation and keypoint correspondence. It generates a dense motion field from a sparse motion field and the reference image, providing region-level dense guidance while maintaining the generalizability of sparse pose control. It also extracts diffusion features from the reference image and transfers them to the target pose, preserving appearance consistency. Experimental results demonstrate DisPose’s improved quality and consistency over existing methods, showcasing its effectiveness and generalizability.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to controllable human image animation, addressing limitations of existing methods. It offers a plug-and-play module, improving the quality and consistency of generated videos, and opens avenues for advancements in AI-driven video generation and digital human technologies. The proposed method’s generalizability and efficiency make it highly relevant to researchers working on similar problems.
Visual Insights#

🔼 This figure showcases the results of the DISPOSE method on a set of input images, demonstrating its ability to generate a wide variety of animations while maintaining the visual consistency of the subject’s appearance. The animations are diverse in terms of pose and movement, highlighting the method’s effectiveness in controlling the animation process. The consistency shows that the generated animations maintain the original appearance, avoiding significant changes or distortions. Each animation maintains a consistent look and feel, even with varied movements.
read the caption
Figure 1: Our method demonstrates its ability to produce diverse animations and preserve consistency of appearance.
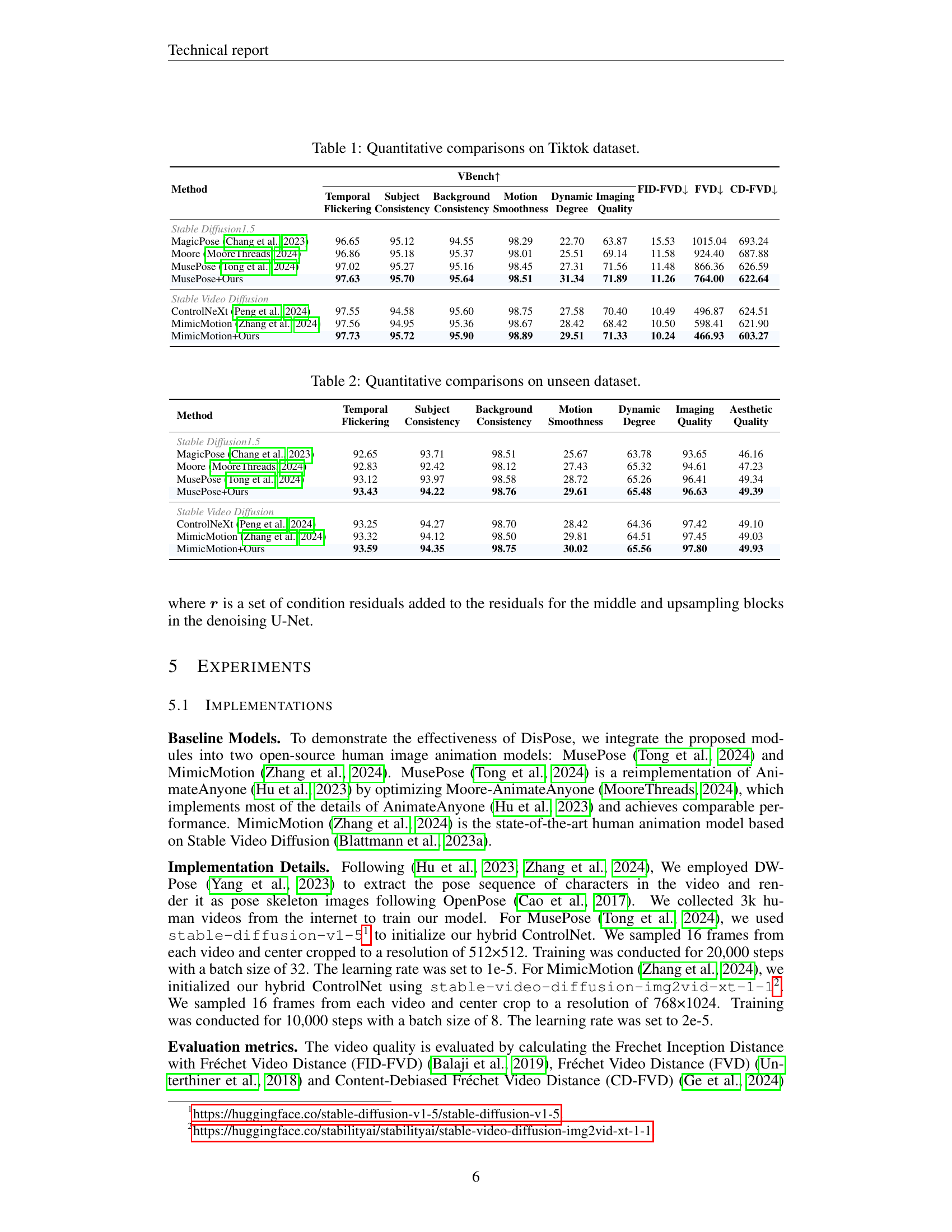
| Method | Temporal | Subject | Background | Motion | Dynamic | Imaging | FID-FVD ↓ | FVD ↓ | CD-FVD ↓ |
|---|---|---|---|---|---|---|---|---|---|
| Stable Diffusion1.5 | |||||||||
| MagicPose Chang et al., 2023 | 96.65 | 95.12 | 94.55 | 98.29 | 22.70 | 63.87 | 15.53 | 1015.04 | 693.24 |
| Moore MooreThreads, 2024 | 96.86 | 95.18 | 95.37 | 98.01 | 25.51 | 69.14 | 11.58 | 924.40 | 687.88 |
| MusePose Tong et al., 2024 | 97.02 | 95.27 | 95.16 | 98.45 | 27.31 | 71.56 | 11.48 | 866.36 | 626.59 |
| MusePose+Ours | 97.63 | 95.70 | 95.64 | 98.51 | 31.34 | 71.89 | 11.26 | 764.00 | 622.64 |
| Stable Video Diffusion | |||||||||
| ControlNeXt Peng et al., 2024 | 97.55 | 94.58 | 95.60 | 98.75 | 27.58 | 70.40 | 10.49 | 496.87 | 624.51 |
| MimicMotion Zhang et al., 2024 | 97.56 | 94.95 | 95.36 | 98.67 | 28.42 | 68.42 | 10.50 | 598.41 | 621.90 |
| MimicMotion+Ours | 97.73 | 95.72 | 95.90 | 98.89 | 29.51 | 71.33 | 10.24 | 466.93 | 603.27 |
🔼 This table presents a quantitative comparison of different human image animation methods on the TikTok dataset. The methods are evaluated across several key metrics, including temporal flickering, subject consistency, background consistency, motion smoothness, dynamic range, and image quality. Lower values for FID, FVD, and CD-FVD indicate better video quality, while higher values for VBench suggest better overall video quality according to human perception.
read the caption
Table 1: Quantitative comparisons on Tiktok dataset.
In-depth insights#
Pose Guidance Disentanglement#
The concept of “Pose Guidance Disentanglement” in human image animation addresses the challenge of effectively using sparse pose data (like skeletal keypoints) to control complex and realistic movements. Traditional methods often struggle because sparse pose information lacks the detail needed for accurate animation. Disentanglement aims to separate the motion control from the identity and appearance information within the pose data. This allows for independent control over different aspects of the animation. For instance, one can modify the motion field (the overall flow of movement) without altering the character’s appearance, and vice versa. This decoupling enhances the model’s generalizability, allowing it to adapt to different reference images and driving video styles more robustly. By disentangling the pose data, the model avoids imposing overly strict constraints based on the driving video, resulting in more natural and high-quality animations, even with variations in body shapes between source and target. This leads to improved motion alignment and a greater capacity for producing consistent and diverse animations. The core idea is to leverage dense motion fields generated from sparse guidance, combined with identity-preserving mechanisms that preserve the visual characteristics of the reference image. This approach achieves more versatile and controllable human image animation compared to approaches that rely solely on sparse or dense pose guidance.
Hybrid ControlNet#
The proposed “Hybrid ControlNet” is a crucial contribution, acting as a bridge between the disentangled pose guidance (motion field and keypoint correspondence) and the pre-trained video generation model. Its “plug-and-play” nature is a significant advantage, allowing seamless integration with existing models without extensive retraining. This modularity enhances both flexibility and efficiency. By incorporating both motion field and keypoint correspondence, the Hybrid ControlNet addresses two key challenges: consistent motion and accurate appearance transfer. The motion field provides region-level motion guidance, ensuring smooth animation, while the keypoint correspondence leverages diffusion features to maintain the identity of the reference image. This dual approach overcomes the limitations of relying solely on sparse skeleton pose or restrictive dense guidance. The successful integration of these control signals into the ControlNet architecture showcases a sophisticated approach to controllable human image animation, offering a promising method to produce high-quality and consistent results.
Dense Motion Field#
The concept of a ‘Dense Motion Field’ in the context of controllable human image animation is crucial for generating realistic and fluid movements. A sparse motion field, typically derived from keypoints like those provided by pose estimation models, offers limited information about the motion between keypoints. A dense motion field aims to fill this gap by providing a vector for every pixel in the image, indicating the direction and magnitude of motion. This dense representation allows for significantly more precise control and more nuanced animation, leading to higher-quality results. However, generating a dense motion field directly from sparse data can be challenging and computationally expensive. The paper likely addresses this by proposing a method that leverages the reference image to infer dense motion from the sparse motion field, thereby mitigating the computational burden and potentially enhancing generalization to various body shapes and poses not explicitly present in the driving video. This technique is likely to involve some form of interpolation or extrapolation, potentially using techniques like optical flow estimation or other image-based motion analysis methods to intelligently fill in the gaps between sparse motion vectors. The key is to find a balance between the level of detail (density) and robustness to variations in pose and appearance. Too dense a field might be overly sensitive to noise and variations in the driving video, while an insufficiently dense field might lack the fidelity to produce realistic movement. The successful implementation of this method would represent a significant advancement in controllable human image animation.
Cross-Identity Animation#
The concept of “Cross-Identity Animation” in the context of this research paper refers to the ability of the proposed model to transfer the animation style and movements from a driving video onto a reference image featuring a different person. This capability goes beyond simple pose transfer; it aims to seamlessly integrate the motion from one individual onto another while preserving the appearance and identity characteristics of the target individual. The success of cross-identity animation demonstrates the model’s robustness and generalization ability. It signifies that the learned representations of motion are not tightly coupled to the specific identity features of the source video, enabling more versatile and creative animation applications. The ability to perform cross-identity animation highlights the effectiveness of the model’s disentangled pose guidance and keypoint correspondence mechanisms in separating motion information from identity information. The results are significant because they allow for greater flexibility and creativity in animation, creating possibilities for applications such as virtual avatars, digital character manipulation, or personalized video generation.
Future Research#
Future research directions stemming from this paper on controllable human image animation could profitably explore several avenues. Improving the handling of complex backgrounds is crucial; current methods struggle with accurate motion field estimation in cluttered scenes. Addressing occlusions and self-occlusions more effectively is also key, as these currently cause artifacts in the generated videos. Exploring different pose representations beyond skeletons, such as dense pose or mesh-based representations, might offer more nuanced control. A promising area is improving the generalization capability across diverse body shapes and appearances. The current method shows improvement but could benefit from further advancements in robustness. Finally, investigating the integration with other video generation methods to produce longer, more complex animations and exploring applications beyond human image animation could lead to significant advancements. Specifically, expanding capabilities to multi-view video synthesis or 3D human animation represent exciting possibilities.
More visual insights#
More on figures

🔼 This figure provides a detailed overview of the DisPose architecture. It illustrates the input elements: a reference image and driving video. The process is broken down into stages: (a) user input (reference image and driving video), (b) existing animation model, (c) motion field estimation which involves both sparse and dense motion field calculation from the driving video and reference image, (d) point feature extraction from reference and target images, and (e) the final hybrid ControlNet which combines all information to generate the final video. The figure visually summarizes how DisPose processes inputs, generating a dense motion field and keypoint correspondence for controllable animation.
read the caption
Figure 2: The overview of proposed DisPose.

🔼 Figure 3 presents a qualitative comparison of video generation results from different methods on the TikTok dataset. The figure shows generated videos alongside a reference image and ground truth video. This allows for a visual assessment of each method’s ability to accurately animate the reference image based on the driving video, considering factors such as motion fidelity, temporal consistency, and overall visual quality. The comparison includes our proposed method (MusePose+Ours and MimicMotion+Ours) against state-of-the-art methods such as Stable Diffusion, MagicPose, Moore, MusePose, ControlNeXt, and MimicMotion. By visually inspecting these generated videos, one can qualitatively evaluate the effectiveness and visual appeal of various approaches to controllable human image animation.
read the caption
Figure 3: Qualitative comparisons between our method and the state-of-the-art models on the TikTok dataset.

🔼 Figure 4 presents a qualitative comparison of the proposed DisPose method against a dense control-based method (Champ). The figure showcases animation results from both methods using the same reference and driving videos. The visual comparison highlights the differences in generated video quality and consistency between the approaches, emphasizing how DisPose can maintain better appearance consistency and fidelity to the reference image even in scenarios where significant body shape differences exist between the reference and driving images. This illustrates DisPose’s effectiveness in generating high-quality human image animation without the need for dense guidance.
read the caption
Figure 4: Qualitative comparison of our approach with the dense control-based method.

🔼 Figure 5 presents a qualitative comparison between DisPose’s reference-based dense motion field and existing dense methods (like Champ) for human image animation. It visually demonstrates the generalization capability of DisPose by showing generated videos from various methods using the same reference and driving video. The goal is to highlight how DisPose handles differences in body shape between reference and driving video better than methods that rely on strict dense constraints.
read the caption
Figure 5: Comparison of our reference-based dense motion field and existing dense conditions.

🔼 This figure demonstrates the capability of the proposed DisPose method to perform cross-identity animation. It shows several examples where the motion from a driving video is applied to a reference image of a different person. The results highlight the model’s ability to maintain the appearance of the reference person while accurately replicating the motion from the driving video, showcasing its versatility and effectiveness in controlling both appearance and motion independently.
read the caption
Figure 6: The demonstration of cross ID animation from the proposed method.

🔼 This figure demonstrates the concept of semantic correspondence in the DisPose model. A red point is selected in a source image (far left). The DisPose model then uses the diffusion features extracted from that point to locate and highlight the corresponding point in another image (far right). This showcases the model’s ability to maintain consistent appearance across different images by mapping keypoints based on their semantic meaning rather than just their spatial location.
read the caption
Figure 7: Qualitative analysis of semantic correspondence. Given a red source point in an image (far left), we use its diffusion feature to retrieve the corresponding point in the image on the right.

🔼 This figure showcases the results of applying the proposed DisPose method to generate multi-view videos. It demonstrates the model’s ability to produce consistent and high-quality animations from a single reference image, even when generating multiple viewpoints of the same action. This highlights one of the key capabilities of DisPose: its generalization and effectiveness in various situations, moving beyond the limitations of traditional single-view human image animation.
read the caption
Figure 8: Qualitative results of our method for multi-view video generation.

🔼 Figure 9 presents additional qualitative results comparing the proposed DisPose method against other state-of-the-art human image animation methods. The figure showcases multiple examples of generated videos, highlighting the improved quality and consistency achieved by DisPose in terms of temporal coherence, motion smoothness, and overall visual fidelity. It visually demonstrates DisPose’s ability to generate diverse and realistic animations while maintaining consistency in appearance and accurately reflecting the pose and motion from the driving video.
read the caption
Figure 9: More Qualitative Comparisons.

🔼 Figure 10 presents additional qualitative results, showcasing the performance of the proposed DisPose method on various human image animation scenarios. It visually demonstrates the model’s ability to generate high-quality and consistent video animations across diverse body shapes, poses, and backgrounds. The figure complements the quantitative results presented earlier in the paper by providing concrete visual examples of the method’s capabilities.
read the caption
Figure 10: More Qualitative Comparisons.

🔼 This figure provides a qualitative comparison of the model’s performance with and without different components of the proposed method. Specifically, it shows the impact of motion field guidance and keypoint correspondence on the generated video quality. By comparing results with and without these components, the figure demonstrates their individual contributions to improving the overall quality and consistency of the generated animations.
read the caption
Figure 11: Qualitative results about motion field guidance and keypoints correspondence.

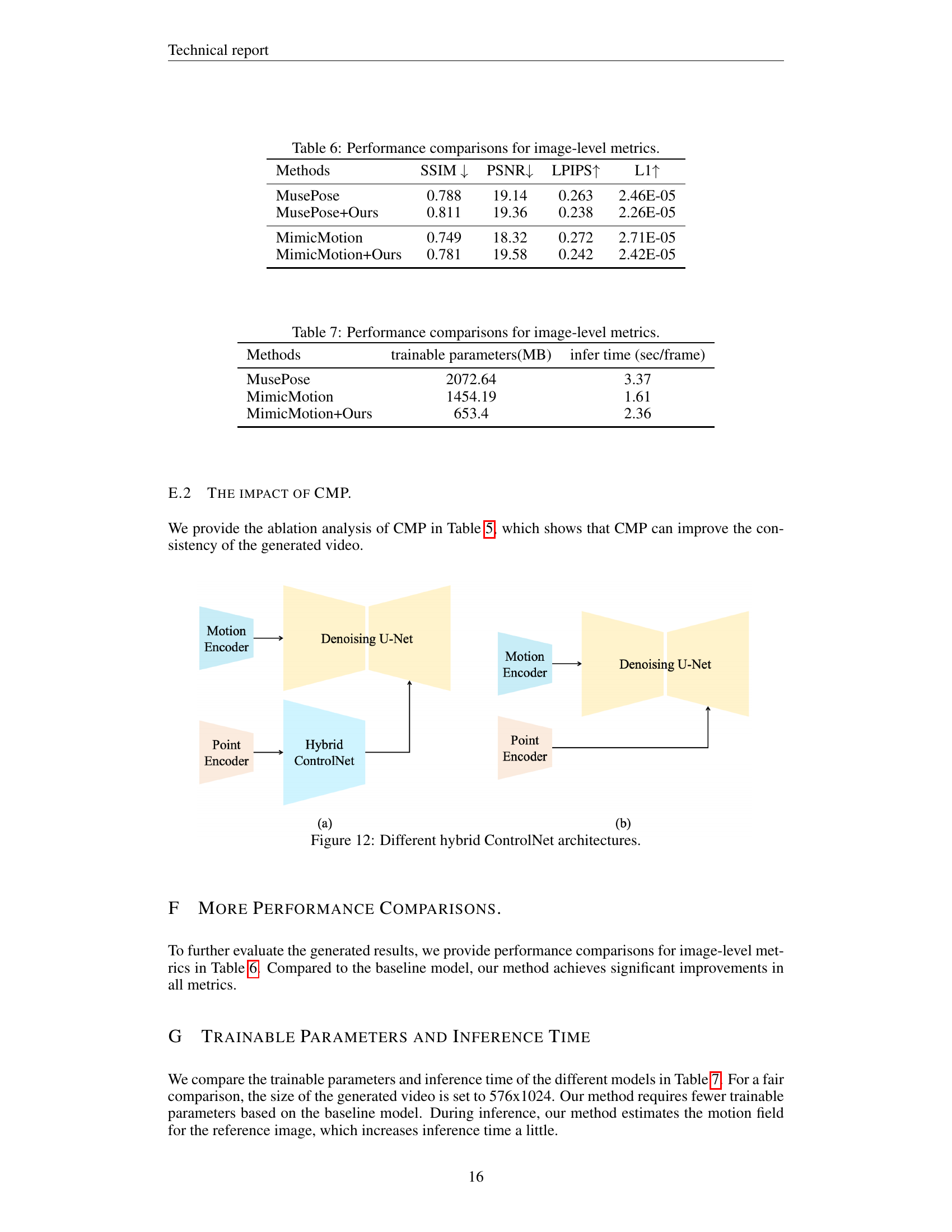
🔼 This table presents a quantitative analysis of the impact of using a hybrid ControlNet architecture on the performance of the DisPose model for human image animation. It compares results across various metrics, such as FID-FVD and FVD, which measure the quality of generated videos, likely including measures of temporal consistency and visual fidelity. By showing results with and without the hybrid ControlNet, the table highlights its contribution to improving the overall quality and consistency of the generated animations.
read the caption
Table 4: The impact of hybrid ControlNet.

🔼 Table 5 presents the results of an ablation study assessing the impact of Conditional Motion Propagation (CMP) on the overall performance of the proposed DisPose method. It shows how CMP affects the model’s ability to generate videos with improved consistency and quality.
read the caption
Table 5: The impact of CMP.

🔼 This figure illustrates two variations of the hybrid ControlNet architecture used in the DisPose model. The hybrid ControlNet integrates motion field guidance and keypoint correspondence to enhance the quality of human image animation. The left architecture (a) shows the motion field information fed directly into the denoising U-Net, while the right architecture (b) depicts the use of a separate hybrid ControlNet module to process this information before feeding it to the denoising U-Net. The difference highlights alternative approaches for integrating additional control signals into the diffusion process.
read the caption
Figure 12: Different hybrid ControlNet architectures.

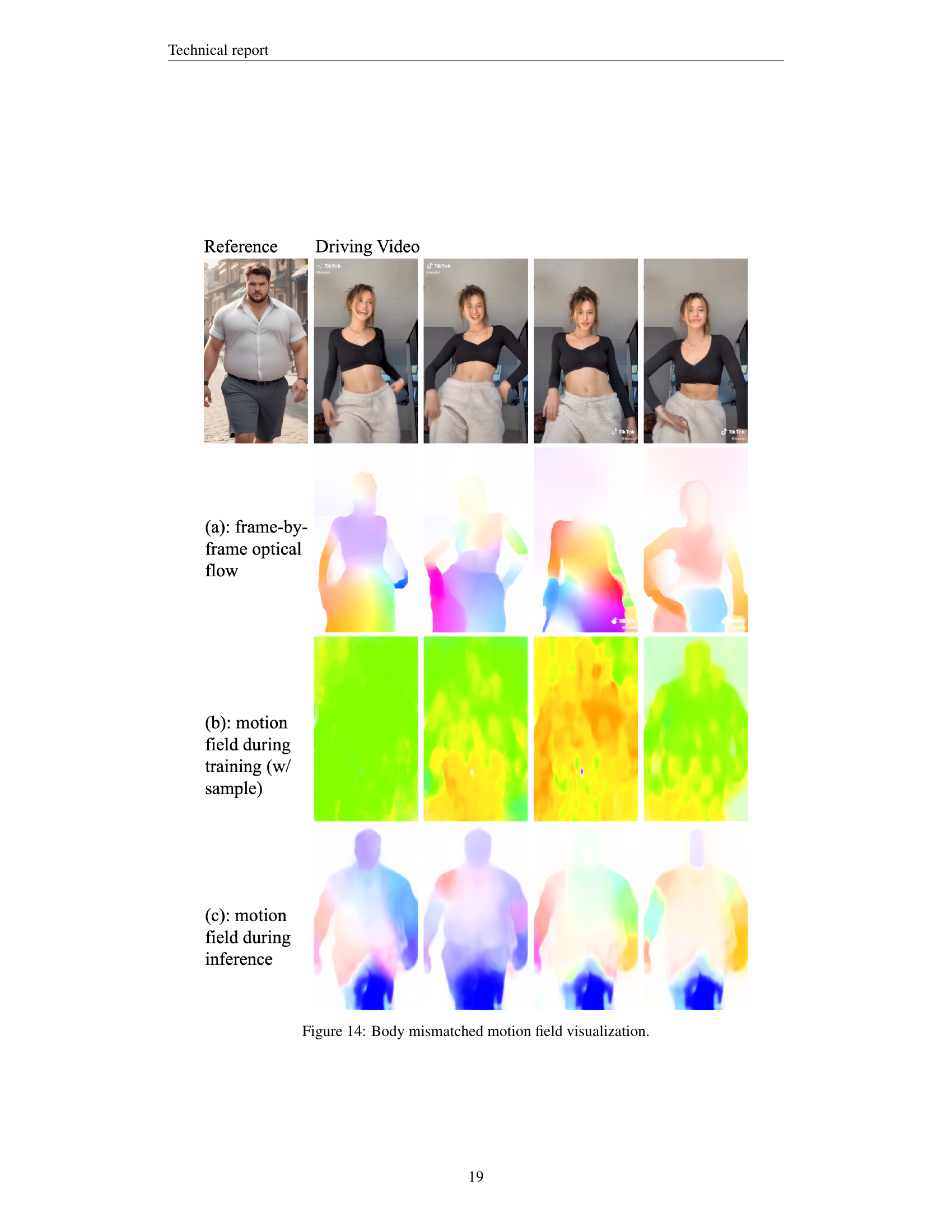
🔼 This figure visualizes the motion fields generated by the proposed method during different stages. (a) shows the frame-by-frame optical flow extracted from the driving video, highlighting the overall movement. (b) illustrates the motion field computed during training without sample refinement, revealing a less refined and possibly noisy representation. (c) presents the motion field generated with sample refinement during training, showing a smoother and more accurate motion representation. Finally, (d) shows the motion field used during inference, demonstrating the final refined motion guidance used to animate the target image.
read the caption
Figure 13: Body matched motion field visualization.
More on tables
| Method | Temporal | Subject | Background | Motion | Dynamic | Imaging | Aesthetic |
|---|---|---|---|---|---|---|---|
| Method | Flickering | Consistency | Consistency | Smoothness | Degree | Quality | Quality |
| Stable Diffusion1.5 | |||||||
| MagicPose (Chang et al., 2023) | 92.65 | 93.71 | 98.51 | 25.67 | 63.78 | 93.65 | 46.16 |
| Moore (MooreThreads, 2024) | 92.83 | 92.42 | 98.12 | 27.43 | 65.32 | 94.61 | 47.23 |
| MusePose (Tong et al., 2024) | 93.12 | 93.97 | 98.58 | 28.72 | 65.26 | 96.41 | 49.34 |
| MusePose+Ours | 93.43 | 94.22 | 98.76 | 29.61 | 65.48 | 96.63 | 49.39 |
| Stable Video Diffusion | |||||||
| ControlNeXt (Peng et al., 2024) | 93.25 | 94.27 | 98.70 | 28.42 | 64.36 | 97.42 | 49.10 |
| MimicMotion (Zhang et al., 2024) | 93.32 | 94.12 | 98.50 | 29.81 | 64.51 | 97.45 | 49.03 |
| MimicMotion+Ours | 93.59 | 94.35 | 98.75 | 30.02 | 65.56 | 97.80 | 49.93 |
🔼 This table presents a quantitative comparison of different human image animation methods on an unseen dataset. It evaluates the performance of each method across several key metrics, including temporal flickering, subject consistency, background consistency, motion smoothness, dynamic degree, imaging quality, and aesthetic quality. The unseen dataset helps assess the generalizability of the models beyond the training data.
read the caption
Table 2: Quantitative comparisons on unseen dataset.
| Method | Temporal | Subject | Background | Motion | Dynamic | Imaging | FID-FVD | FVD |
|---|---|---|---|---|---|---|---|---|
| w/o Motion | 97.66 | 95.04 | 95.31 | 98.75 | 29.42 | 69.53 | 10.31 | 478.91 |
| w/o Point | 97.47 | 95.57 | 95.43 | 98.42 | 29.14 | 70.14 | 10.28 | 498.74 |
| Full Model | 97.73 | 95.72 | 95.90 | 98.89 | 29.51 | 71.33 | 10.24 | 466.93 |
🔼 This ablation study analyzes the impact of different control signals on the performance of the DisPose model for human image animation. The table compares the full DisPose model against two variants: one without motion field guidance (‘w/o Motion’) and one without keypoint correspondence (‘w/o Point’). The results demonstrate the contribution of each component to overall performance metrics, including temporal flickering, subject and background consistency, motion smoothness, and image quality.
read the caption
Table 3: Ablation study on different control guidance. “w/o Motion” denotes the model configuration that disregards motion filed guidance. “w/o Point” indicates the variant model that removes the keypoint correspondence.
| Methods | FID-FVD↓ | FVD↓ |
|---|---|---|
| Exp1 | 10.43 | 514.83 |
| Exp2 | 10.94 | 551.32 |
| Full Model | 10.24 | 466.93 |
🔼 This table presents a quantitative comparison of different methods for human image animation, focusing on image-level metrics. It shows the performance of various models, including baselines and those incorporating the proposed DisPose method, across metrics such as SSIM, PSNR, LPIPS, and L1. Lower values for PSNR, LPIPS, and L1 indicate better performance, while higher SSIM values are desirable. This allows for assessment of the image quality generated by each method.
read the caption
Table 6: Performance comparisons for image-level metrics.
| Methods | subject consistency ↑ | background consistency ↑ |
|---|---|---|
| Full Model w/o CMP | 93.94 | 97.83 |
| Full Model | 94.35 | 98.75 |
🔼 This table presents a quantitative comparison of different methods for human image animation, focusing on image-level metrics. It shows a comparison of the trainable parameters (in MB) and inference time (seconds per frame) for several methods, including MusePose, MimicMotion, and versions of these methods that incorporate the proposed DisPose approach. This allows for a comparison of computational cost and efficiency among the different animation techniques.
read the caption
Table 7: Performance comparisons for image-level metrics.
Full paper#