↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Training large language models (LLMs) often involves using copyrighted data, raising significant legal and ethical concerns. This has led to numerous lawsuits globally and demands for better compensation mechanisms for content creators. The lack of empirical research on the impact of copyrighted material in LLM training necessitates studies like this.
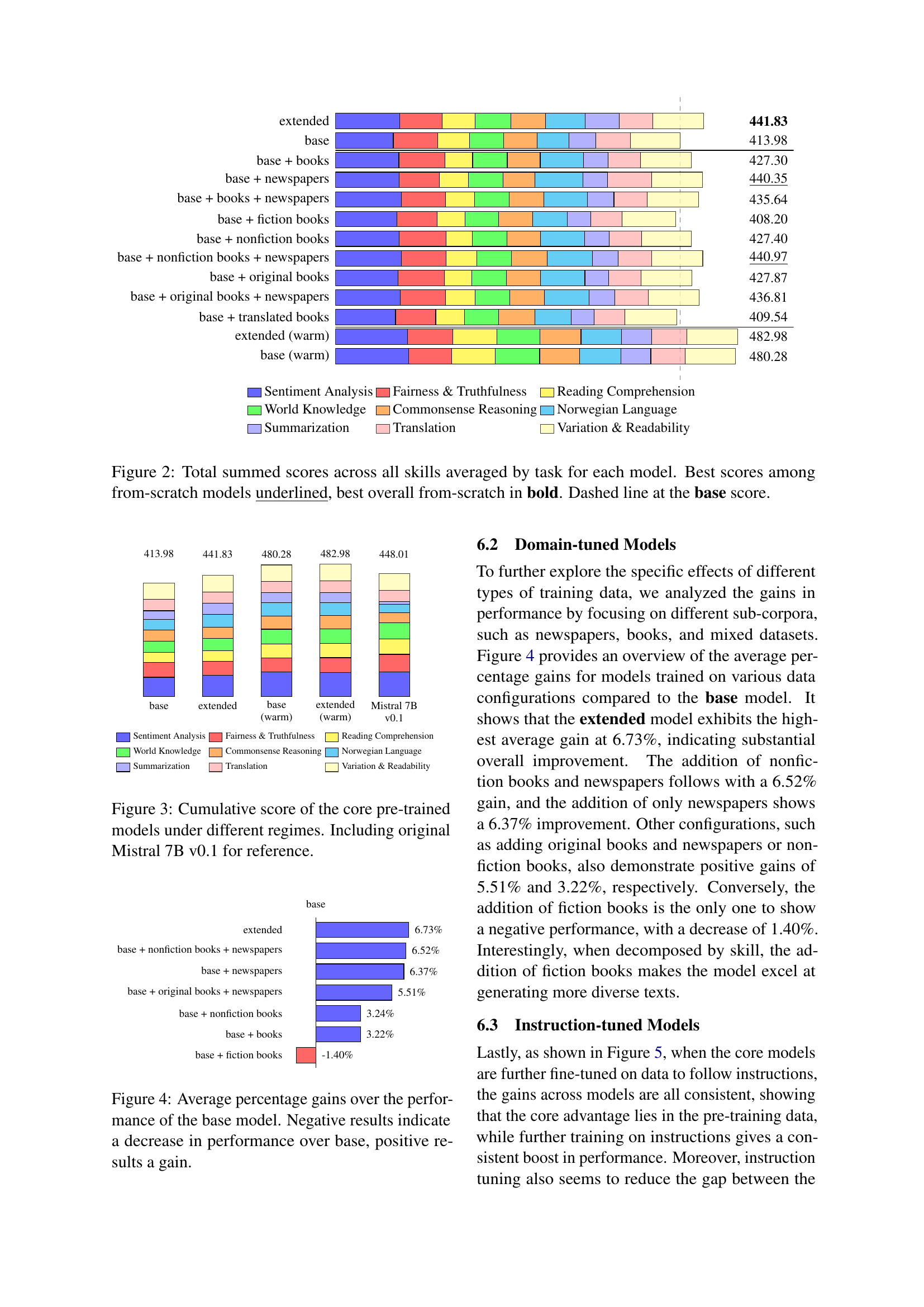
This paper empirically evaluates the impact of copyrighted data on Norwegian LLMs. Researchers created a benchmarking suite to assess the performance of LLMs trained on different datasets, including those with copyrighted materials. They found that while copyrighted books and news data positively impact the performance of LLMs, fiction data leads to performance decrease. The findings underscore the need for ethical guidelines and compensation schemes for authors whose works contribute to AI development, providing a crucial framework for future legal and ethical considerations in AI research.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs), intellectual property rights, and AI ethics. It provides empirical evidence on the impact of copyrighted data in LLM training, which is essential for informing copyright policy and promoting fair compensation for authors. The findings offer new avenues for research in multilingual LLM training and the development of better compensation schemes in the digital age. This research also contributes to the ongoing discussion regarding the ethical implications of AI development.
Visual Insights#

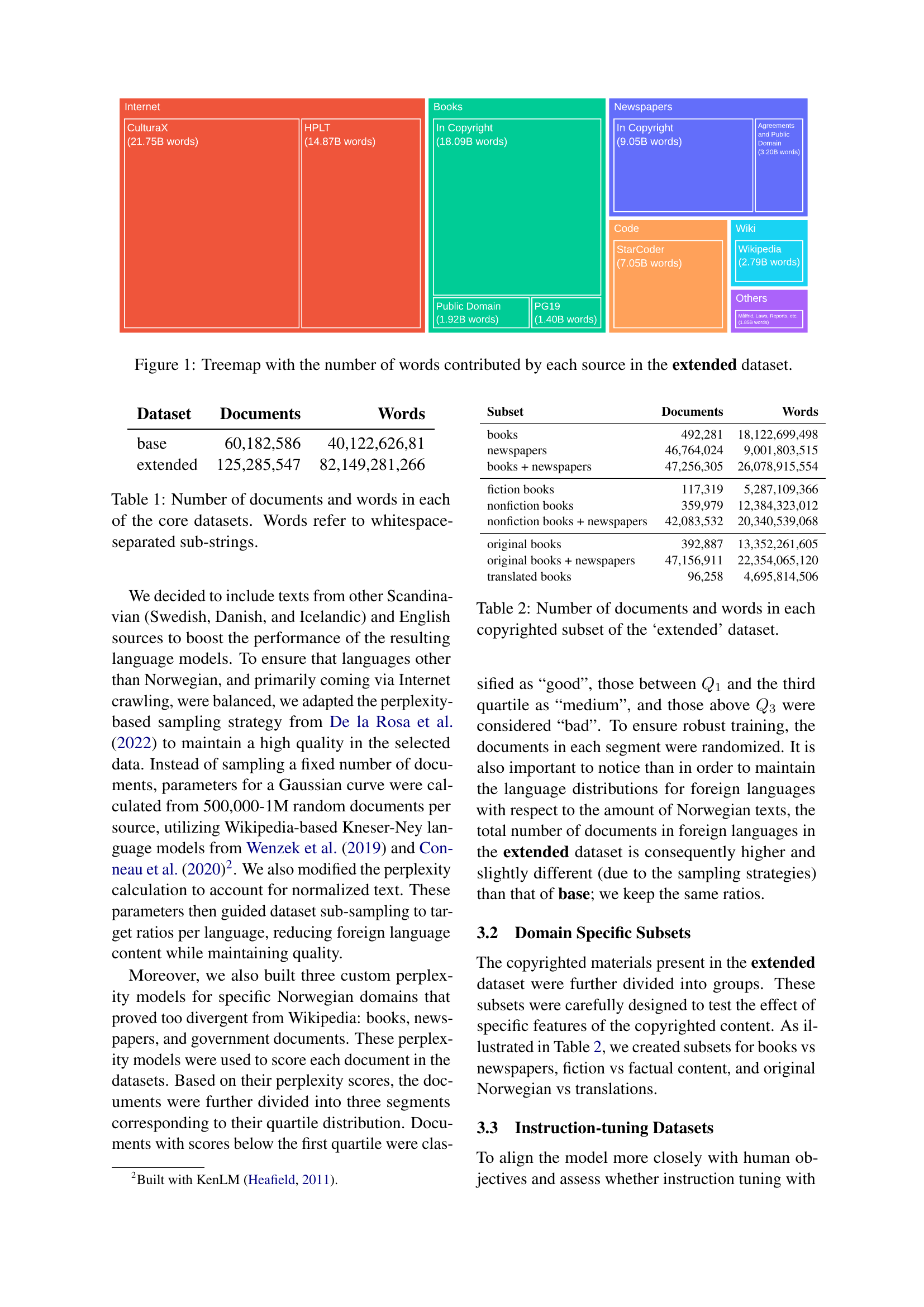
🔼 This treemap visualizes the composition of the extended dataset used to train the language models. Each colored tile represents a different source of text data, with the size of the tile corresponding to the number of words contributed by that source. The sources include copyrighted books and newspapers, public domain materials, and various online resources such as Wikipedia and code repositories. This breakdown provides a clear picture of the data’s diversity and the proportion of copyrighted versus non-copyrighted content.
read the caption
Figure 1: Treemap with the number of words contributed by each source in the extended dataset.
| Dataset | Documents | Words |
|---|---|---|
| base | 60,182,586 | 40,122,626,81 |
| extended | 125,285,547 | 82,149,281,266 |
🔼 This table presents the size of the two core datasets used in the study: ‘base’ and ’extended’. The ‘base’ dataset contains only publicly available or non-copyrighted material, while the ’extended’ dataset includes copyrighted material in addition to the content of the ‘base’ dataset. The table shows the number of documents and the number of words (counting whitespace-separated substrings as individual words) in each dataset. This provides context for understanding the scale of data used to train the different language models.
read the caption
Table 1: Number of documents and words in each of the core datasets. Words refer to whitespace-separated sub-strings.
In-depth insights#
LLM Copyright Impact#
The impact of copyrighted material on LLMs is a multifaceted issue with significant legal and ethical implications. The research highlights that using copyrighted data improves LLM performance, particularly for nuanced tasks like those involving Norwegian language processing. However, this benefit raises concerns about copyright infringement and the need for fair compensation to authors and publishers. Legal challenges surrounding the unauthorized use of copyrighted material in training datasets are widespread, underscoring the urgency for clear guidelines and policies to address this. The findings suggest a need for balanced approaches that recognize both the advancements LLMs offer and the fundamental rights of content creators. Further investigation into different types of copyrighted material, their impact, and the effectiveness of compensation models is crucial for shaping future policy and practice in this domain.
Norwegian LLM Data#
The research paper’s focus on “Norwegian LLM Data” highlights the unique challenges and opportunities in developing large language models for less-resourced languages. The scarcity of high-quality, publicly available Norwegian text data necessitates creative data acquisition strategies, such as collaborations with national libraries and publishers, to balance the need for a large training corpus with copyright considerations. The ethical and legal implications of using copyrighted material are explicitly addressed, emphasizing the importance of fair compensation schemes and the necessity for transparent and responsible data practices in the development of LLMs. The study’s approach of comparing models trained on datasets with varying proportions of copyrighted and non-copyrighted content provides valuable insights into the relative contribution of copyrighted material to model performance. This focus on the legal and ethical implications, coupled with rigorous empirical evaluation, sets a strong precedent for future research on LLMs in similar contexts.
LLM Benchmarking#
LLM Benchmarking for Norwegian is a crucial aspect of the research, focusing on evaluating the performance of large language models (LLMs) trained on various datasets with different proportions of copyrighted material. The methodology uses a newly created benchmarking suite comprising diverse NLP tasks, assessing models’ capabilities in areas such as sentiment analysis, fairness, translation, and reading comprehension. A key challenge is the creation of a comprehensive and representative benchmarking suite specifically tailored for the nuances of the Norwegian language. This requires careful consideration of linguistic features and potential biases in existing datasets. The results highlight the importance of high-quality, curated data, including copyrighted material, for optimal LLM performance, but also emphasize the necessity of addressing ethical and legal considerations around copyright in the creation and usage of such datasets. The study’s findings will inform future copyright policy for AI development in Norway, ensuring a balance between promoting innovation and protecting creators’ rights. The choice of metrics and tasks within the benchmark also significantly impacts the findings. Future work needs to carefully investigate the choice and weighting of those metrics. A robust benchmark should not only assess accuracy but also factors like fluency, coherence, and bias, to provide a holistic evaluation of LLM quality.
Instruction Tuning#
Instruction tuning, in the context of large language models (LLMs), is a crucial fine-tuning technique that significantly enhances the model’s ability to perform downstream tasks. It involves training the pre-trained model on a dataset of instruction-following examples, formatted as (instruction, input, output) triplets. This process teaches the model to understand and respond appropriately to a wide range of instructions, improving its versatility and making it suitable for numerous applications. The effectiveness of instruction tuning heavily depends on the quality and quantity of the instruction dataset, with larger, more diverse, and carefully curated datasets leading to better performance. The research highlights the importance of instruction tuning for addressing specific objectives, suggesting that even with high-quality pre-training data, instruction tuning bridges the performance gap and elevates the model’s capacity to execute diverse tasks. In essence, this fine-tuning method fine-tunes the pre-trained model toward human-centric instructions, shaping its behavior to be more aligned with user expectations and desired output formats.
Ethical & Legal Issues#
The use of copyrighted material in training large language models (LLMs) presents significant ethical and legal challenges. The paper highlights the tension between the benefits of using diverse datasets for model improvement and the rights of copyright holders whose work is used without explicit consent or compensation. Fair compensation schemes are crucial for balancing innovation with the need to protect intellectual property rights. The research emphasizes the need for clear guidelines and regulations to manage the use of copyrighted data, emphasizing the importance of transparency and accountability in LLM development and deployment. Failure to address these issues could stifle innovation while simultaneously harming content creators and fostering legal disputes. A collaborative approach involving AI developers, copyright holders, and policymakers is essential for establishing a sustainable ecosystem for the development and deployment of AI technologies.
More visual insights#
More on tables
| Subset | Documents | Words |
|---|---|---|
| books | 492,281 | 18,122,699,498 |
| newspapers | 46,764,024 | 9,001,803,515 |
| books + newspapers | 47,256,305 | 26,078,915,554 |
| fiction books | 117,319 | 5,287,109,366 |
| nonfiction books | 359,979 | 12,384,323,012 |
| nonfiction books + newspapers | 42,083,532 | 20,340,539,068 |
| original books | 392,887 | 13,352,261,605 |
| original books + newspapers | 47,156,911 | 22,354,065,120 |
| translated books | 96,258 | 4,695,814,506 |
🔼 This table presents a detailed breakdown of the copyrighted material within the ’extended’ dataset used in the study. It shows the number of documents and the total word count for various subsets of copyrighted data. These subsets are categorized based on different criteria, such as the type of publication (books vs. newspapers), content genre (fiction vs. nonfiction), and origin of the text (original Norwegian vs. translations). This granular breakdown allows for a precise analysis of the impact of different types of copyrighted material on the performance of the language models.
read the caption
Table 2: Number of documents and words in each copyrighted subset of the ‘extended’ dataset.
| Model | Initialization | GPU/hours | Accelerator |
|---|---|---|---|
| 1.5 Core Models | |||
| base | From scratch | 50K | AMD MI250X |
| extended | From scratch | 50K | AMD MI250X |
| base (warm) | Mistral 7B v0.1 | 13.8K | NVIDIA H100 |
| extended (warm) | Mistral 7B v0.1 | 55.6K | AMD MI250X |
| 1 Domain Tuned Models | |||
| base + fiction books | base | 7.5K | AMD MI250X |
| base + nonfiction books | base | 7.5K | AMD MI250X |
| base + nonfiction books + newspapers | base | 7.5K | AMD MI250X |
| base + newspapers | base | 4.8K | Google TPUv4 |
| base + books | base | 4.8K | Google TPUv4 |
| base + books + newspapers | base | 4.8K | Google TPUv4 |
| base + original books + newspapers | base | 9.1K | AMD MI250X |
| base + original books | base | 9.1K | AMD MI250X |
| base + translated books | base | 9.1K | AMD MI250X |
| 1 Instruction Fine Tuned Models | |||
| base instruct | base | 14.2 | NVIDIA H100 |
| extended instruct | extended | 14.2 | NVIDIA H100 |
| base (warm) instruct | base (warm) | 14.2 | NVIDIA H100 |
| extended (warm) instruct | extended (warm) | 14.2 | NVIDIA H100 |
🔼 Table 3 details the training configurations for 17 different large language models (LLMs). It shows the model name, the initial model used (if any, otherwise ‘from scratch’), the dataset used for training, the total GPU hours consumed during training, and the type of hardware accelerator utilized (e.g., AMD MI250X, NVIDIA H100, Google TPUv4). This table provides a comprehensive overview of the computational resources used to build the models described in the paper, enabling comparison and reproducibility.
read the caption
Table 3: Model training specifications, where Model represents the model identifier and the data used for training, Initialization represents the base model used for training, GPU/hours indicates the total GPU hours required for model training, and Accelerator represents the type of accelerator used.
| Model | SA | FT | RC | WK | RC | NL | S | T | VR |
|---|---|---|---|---|---|---|---|---|---|
| extended | 3 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 |
| base | 4 | 3 | 4 | 4 | 3 | 4 | 3 | 4 | 3 |
| extended (warm) | 2 | 3 | 1 | 2 | 1 | 1 | 2 | 1 | 1 |
| base (warm) | 1 | 1 | 2 | 1 | 1 | 3 | 2 | 2 | 4 |
🔼 This table presents a ranking of core language models across various tasks, categorized by skill. The ranking considers the best performance (lowest score) achieved using different numbers of examples (k-shot learning). Each skill encompasses several sub-tasks, and the final ranking is based on aggregating the individual scores for these sub-tasks. The skills evaluated are Sentiment Analysis (SA), Fairness & Truthfulness (FT), Reading Comprehension (RC), Norwegian Language proficiency (NL), World Knowledge (WK), Commonsense Reasoning (CR), Summarization (S), Translation (T), and Variation & Readability (VR). Lower scores indicate better performance.
read the caption
Table 4: Results for ranking the core models on all tasks by skill via (i) finding the best k-shot configuration for each task and (ii) aggregating metric-wise rankings. SA=Sentiment Analysis. FT=Fairness & Truthfulness. RC=Reading Comprehension. NL=Norwegian Language. WK=World Knowledge. CR=Commonsense Reasoning. S=Summarization. T=Translation. VR=Variation & Readability. Lower is better.
Full paper#