↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) often lack robust speech capabilities, limiting their versatility and efficiency. Existing omni-models insufficiently explore speech integration with other modalities. This creates a need for advanced models that seamlessly integrate speech for more efficient and versatile AI.
This paper introduces Lyra, an efficient MLLM designed to address this gap. Lyra utilizes three key strategies: leveraging existing open-source large models to reduce costs and data requirements, strengthening relationships between speech and other modalities via a novel latent multi-modality regularizer and extractor, and training on a high-quality, large-scale dataset including diverse long speech samples. Lyra demonstrates state-of-the-art performance across various benchmarks and surpasses previous models in efficiency and versatility.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Lyra, a novel and efficient framework for omni-cognition that significantly advances the capabilities of multimodal large language models. Its speech-centric approach addresses a critical gap in existing models by integrating speech with other modalities. The presented methods, including latent cross-modality regularizer and latent multi-modality extractor, contribute to improved efficiency and performance. This work is relevant to current research trends in MLLMs and opens new avenues for developing more versatile and efficient AI systems.
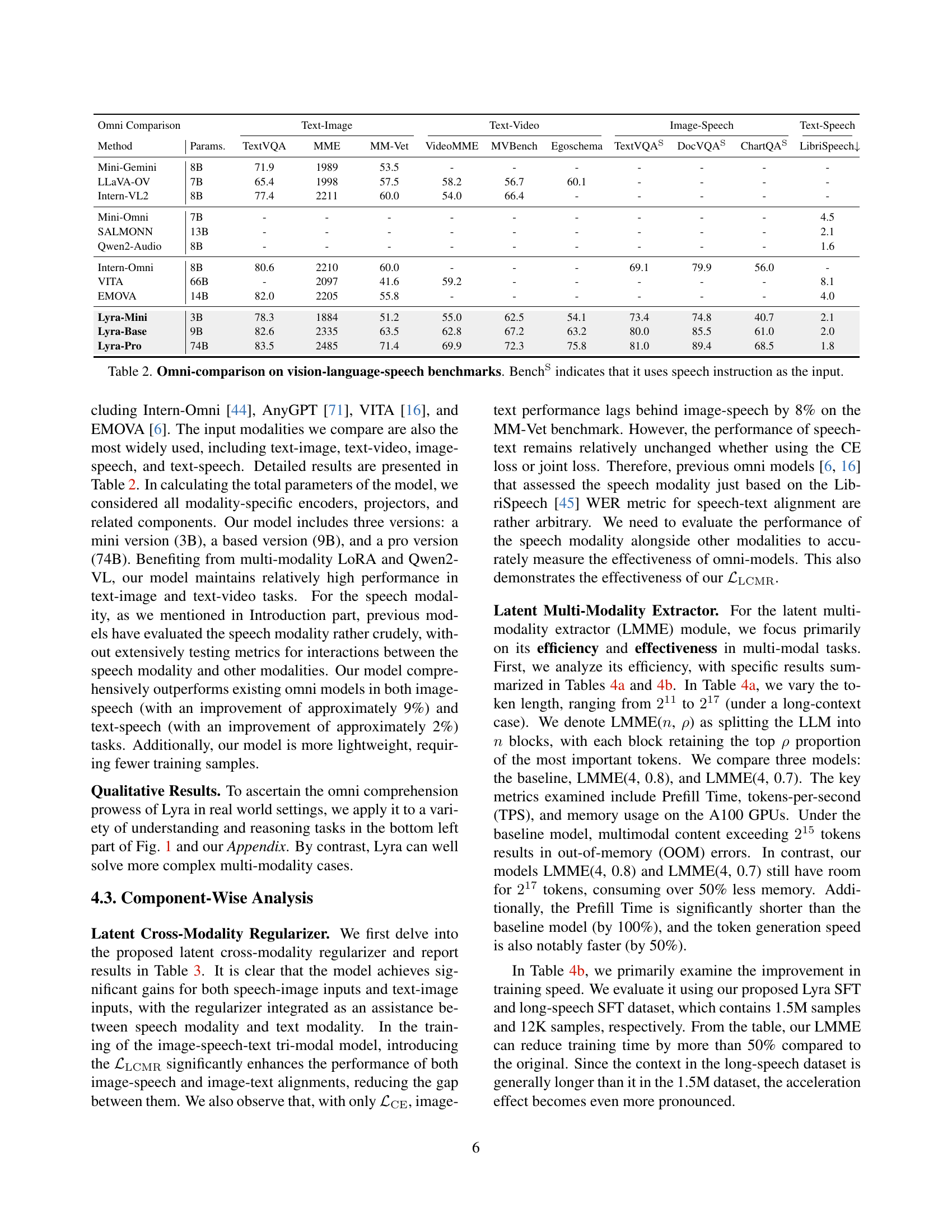
Visual Insights#
🔼 Figure 1 provides a high-level overview of the Lyra model, highlighting its key advantages over existing state-of-the-art models. It showcases Lyra’s superior performance across various multi-modal tasks (image, video, audio, text), emphasizing its ability to handle very long-duration audio and video inputs (hours of content) while maintaining efficiency through reduced data requirements and faster processing speed. The figure visually represents these aspects through charts and diagrams comparing Lyra’s performance and resource consumption to other leading models.
read the caption
Figure 1: Overview of Lyra. Lyra shows superiority compared with leading models in the following aspects: 1. Stronger performance. Lyra achieves state-of-the-art results across a variety of modalities understanding and reasoning tasks. 2. More versatile. Lyra can directly handle images, videos and audio tasks even lasting several hours. 3. More efficient. Lyra is trained with less data and increases the speed, reduces memory usage, making it suitable for latency-sensitive and long-context multi-modality applications.
| Function | Method | Vision | Audio | |||||
|---|---|---|---|---|---|---|---|---|
| Image | Video | SU | SG | LS | Sound | |||
| Vision | LLaVA-OV | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | |
| Intern-VL | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ||
| Mini-Gemini | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ||
| Audio | Qwen-Audio | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | |
| Mini-Omni | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ||
| LLaMA-Omni | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ||
| Intern-Omni | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ||
| VITA | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ||
| Any-GPT | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ||
| EMOVA | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ||
| Omni | Lyra | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares the capabilities of various related works in terms of their functionalities across different modalities. Specifically, it focuses on the ability of each model to perform speech understanding (SU), speech generation (SG), and support for long speech inputs (LS). The table provides a quick overview of the strengths and weaknesses of each model concerning speech-related tasks, allowing for easy comparison and identification of state-of-the-art capabilities. This helps the reader understand the unique contributions of the Lyra model in relation to existing methods and highlight its focus on efficient and speech-centric omni-cognition.
read the caption
Table 1: Function comparison of related work. SU, SG, and LS represents speech understanding, speech generation, and long speech support, respectively.
In-depth insights#
Speech-Centric MLLMs#
Speech-centric Multimodal Large Language Models (MLLMs) represent a significant paradigm shift in AI, prioritizing speech understanding and generation. Current MLLMs often treat speech as a secondary modality, focusing primarily on vision-language or text-speech interactions. A speech-centric approach, however, recognizes the richness of speech data, encompassing intonation, accent, and emotion, and leverages this information for enhanced performance. This requires careful consideration of various factors. High-quality, extensive datasets containing diverse speech samples with corresponding visual and textual data are essential for training robust models. Moreover, efficient model architectures and training strategies that can handle the inherent complexities of long-context speech inputs, including long audio recordings and dynamic interactions, are crucial. Evaluation methodologies need to move beyond simple speech-to-text metrics, encompassing cross-modal tasks and nuanced assessments of speech comprehension and generation. A speech-centric framework has the potential to unlock more natural and human-like interactions with AI systems, leading to impactful applications in areas such as virtual assistants, accessibility tools, and personalized healthcare.
Lyra Framework#
The Lyra framework presents a novel approach to efficient and speech-centric omni-cognition, addressing limitations in existing multimodal large language models (MLLMs). Its core strength lies in leveraging readily available open-source models, reducing training costs and data requirements. Three key strategies drive its efficiency: leveraging existing large models via a multi-modality LoRA, strengthening inter-modality relationships using latent regularizers and extractors, and employing a high-quality dataset rich in multimodal and long-speech data. This approach results in a system with enhanced performance across various benchmarks, demonstrating superior capabilities in handling long-context speech and achieving state-of-the-art results in vision-language, vision-speech, and speech-language tasks. Lyra’s emphasis on speech-centric evaluation is particularly noteworthy, highlighting the need for more comprehensive assessment of multimodal models beyond simple text-based metrics. Its modular architecture promises extensibility to other modalities, making it a significant step towards more robust and versatile omni-cognitive AI.
Multimodal LoRA#
The concept of “Multimodal LoRA” presents a powerful technique for efficiently enhancing the capabilities of large multimodal language models (MLLMs). By leveraging existing open-source LLMs and VLMs as a foundation, Multimodal LoRA avoids the computational cost and data requirements of training entirely new models from scratch. Instead, it introduces low-rank adaptations via LoRA to integrate additional modalities, particularly speech, with minimal training data. This approach is particularly valuable for integrating speech into MLLMs, a largely unexplored area that offers significant potential for advancements in omni-cognition. The efficiency gains are substantial, as demonstrated by the reduced training costs and faster inference speeds. Further enhancing efficiency, a latent multi-modality extractor identifies and retains only the most relevant tokens across modalities, improving speed and reducing memory usage. This approach represents a significant step forward in developing more efficient and versatile MLLMs capable of handling diverse input modalities, including complex and lengthy speech inputs, and achieving state-of-the-art performance with significantly fewer computational resources.
Long Speech SFT#
The section on ‘Long Speech SFT’ in this research paper is crucial because it addresses a significant limitation of existing multi-modal large language models (MLLMs): their inability to effectively process and understand long-form speech. The creation of a high-quality dataset comprising 12K long speech samples (Lyra-LongSpeech-12K) is a major contribution, pushing beyond the limitations of previous datasets that typically only included short audio clips. This new dataset, covering diverse topics and durations (8 minutes to 2 hours), allows for more robust training and evaluation of the model’s ability to handle extended speech inputs. Furthermore, the paper acknowledges the computational challenge posed by long audio, and describes using compression techniques to manage the increased number of tokens. This is an important consideration for practical applications. Overall, the focus on long speech significantly enhances the model’s versatility and real-world applicability, moving beyond the limitations of previous omni-modal models.
Omni-Cognition#
The concept of “Omni-Cognition” suggests a system capable of understanding and interacting with the world across multiple modalities. This is in contrast to traditional AI systems that often focus on a single input type (like text or images). A truly omni-cognitive system would seamlessly integrate various forms of input, such as vision, speech, sound, and even other sensory modalities, to achieve a holistic understanding. This necessitates advanced multi-modal fusion techniques, allowing the system to not just recognize distinct inputs but also to infer relationships and context between them. The challenge lies in building models that are both efficient and powerful enough to handle the complexity of diverse input types. Efficiency is crucial, particularly for real-time applications demanding quick responses. The integration of large language models and other powerful pre-trained models may provide a foundational framework for omni-cognition; however, these models need to be adapted to deal effectively with the demands of heterogeneous data, while addressing concerns about computational cost and data demands.
More visual insights#
More on figures

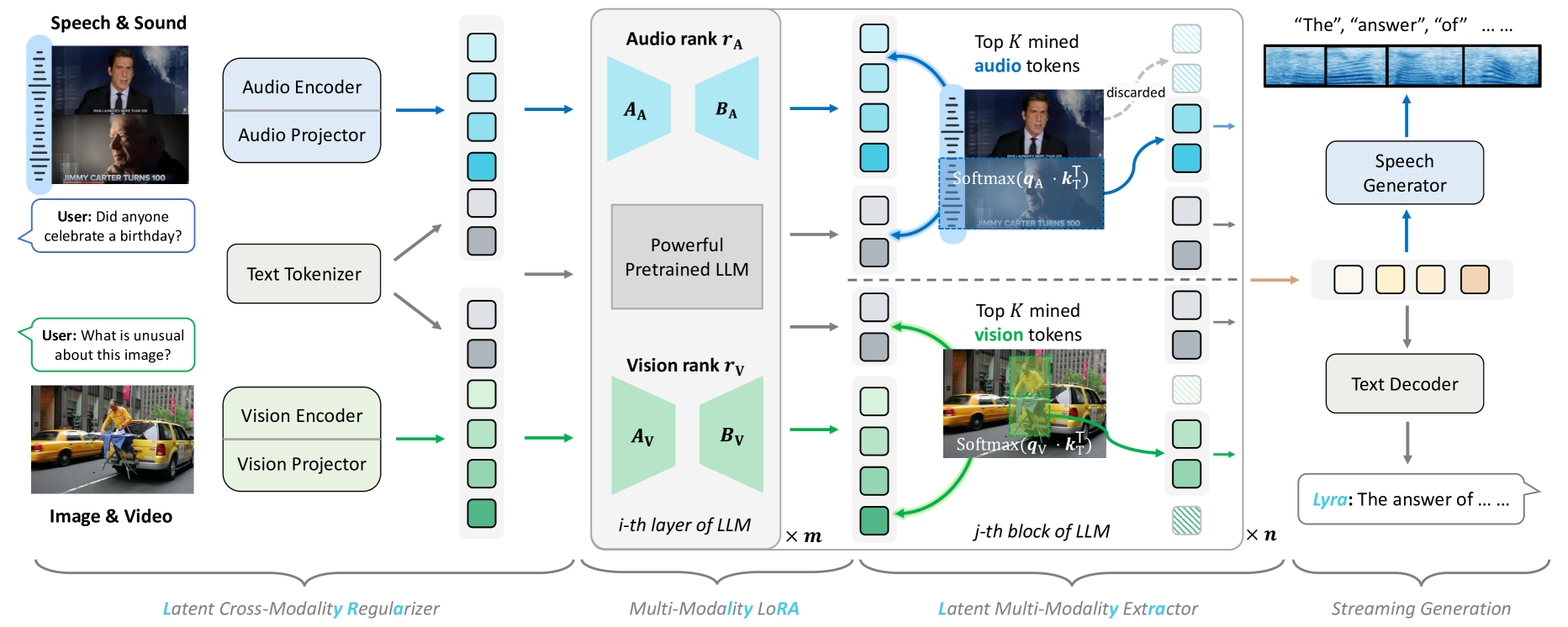
🔼 Lyra, a multi-modal large language model (MLLM), processes various input modalities (text, image, video, audio) through modality-specific encoders. A latent cross-modal regularizer helps align speech with other modalities. Encoded data then passes through projectors before being fed into a pre-trained large language model (LLM). Inside the LLM, a multi-modality Low-Rank Adaptation (LoRA) and a latent multi-modality extractor work together to efficiently learn relationships between different modalities and to select only relevant information for improved performance and reduced computational cost. The result is the simultaneous generation of text and speech outputs.
read the caption
Figure 2: The framework of Lyra. Lyra supports multi-modal inputs. When the data contains a speech modality, we use the latent cross-modality regularizer to assist. Data from each modality is processed through encoders and projectors before being sent into the LLM. Within the LLM, multi-modality LoRA and latent multi-modality extraction modules operate synergistically, facilitating the simultaneous generation of both speech and text outputs.

🔼 This figure illustrates the Dynamic Time Warping (DTW) algorithm used to align speech tokens with their corresponding text translations (produced by an automatic speech recognition system). The goal is to minimize the distance between the two token sequences, even though they may differ in length. This alignment helps to improve the integration of speech data with other modalities in the model, as it ensures that speech information is effectively incorporated into downstream tasks.
read the caption
Figure 3: Illustration of the DTW algorithm in our alignment. Our goal is to make the speech tokens as similar as possible to the corresponding translated tokens.
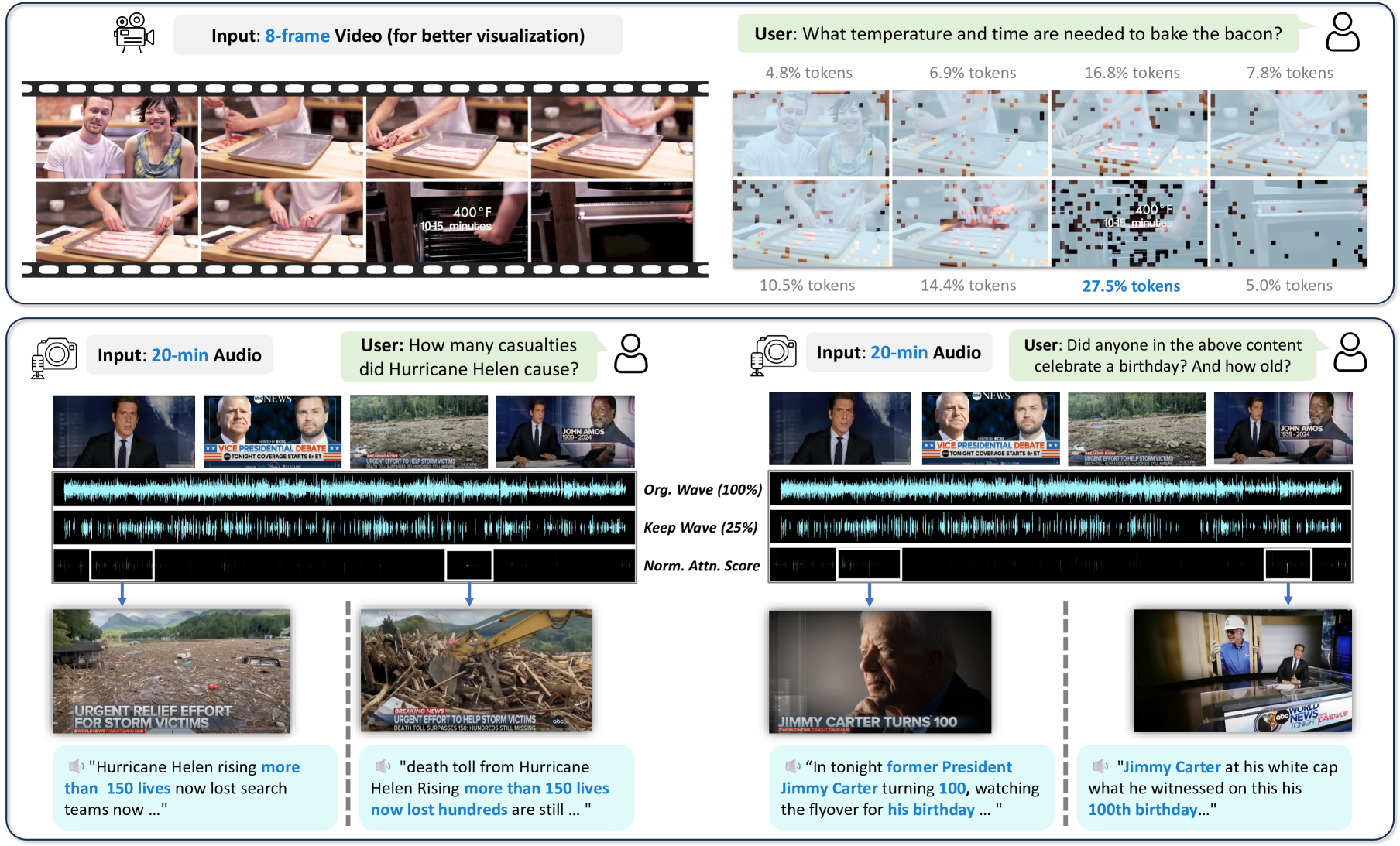
🔼 Figure 4 illustrates the process of integrating long speech capabilities into the Lyra model. The top panel shows the distribution of question types and speech categories within the custom long speech dataset used to train this aspect of the model. The middle panel details the pipeline used to create the instruction-following data for training, highlighting the steps involved in preparing the long speech segments. Finally, the bottom panel provides a visual representation of the long speech Supervised Fine-Tuning (SFT) pipeline, which includes clipping and flattening long audio segments to make them suitable for training.
read the caption
Figure 4: Long speech capability integration pipeline. (Middle) Our pipeline for generating instruction-following data for long speech. (Top) The proportion of question and speech categories in our long speech SFT dataset. (Bottom) Our long speech SFT pipeline. Long speech segments will be clipped and flattened.

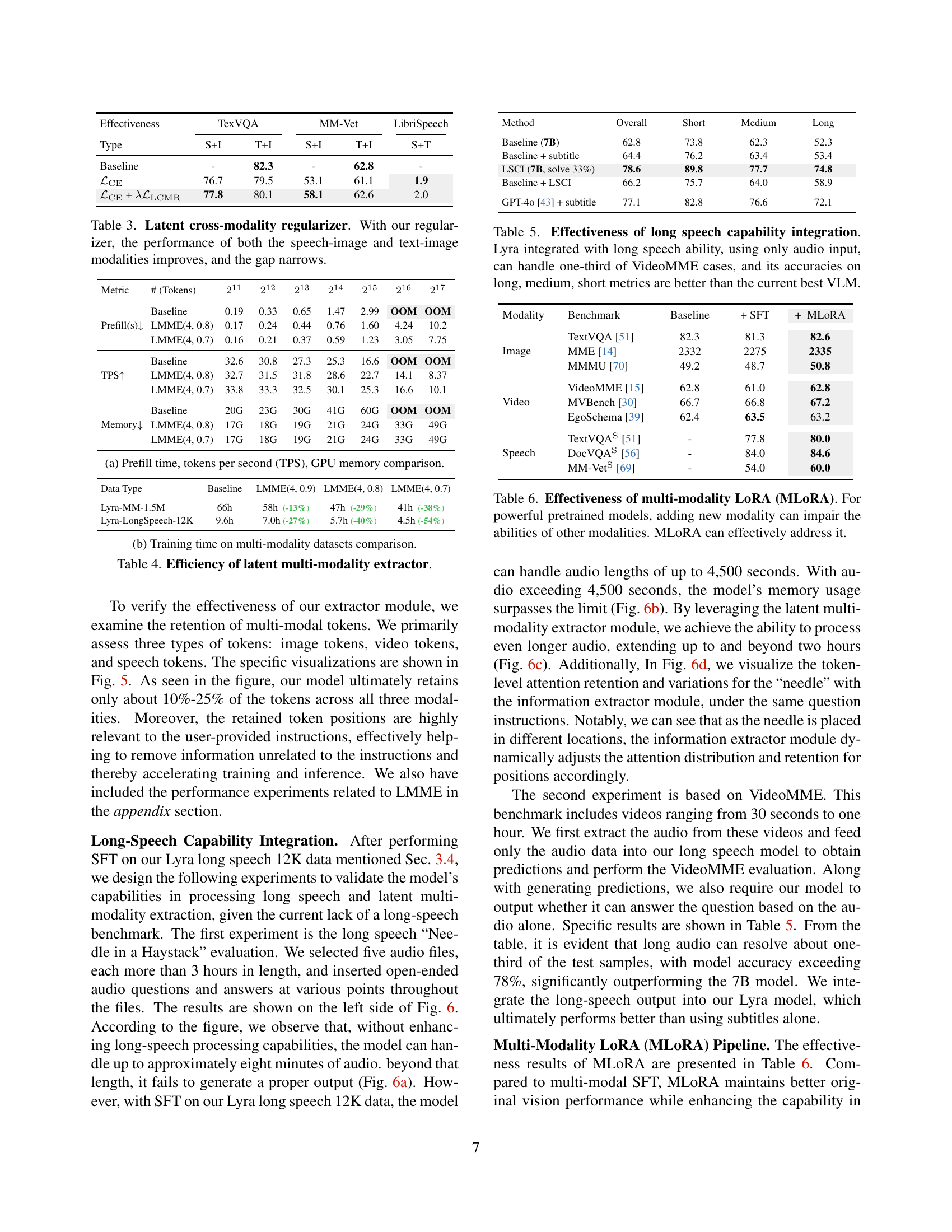
🔼 This figure presents a comparison of the prefill time, tokens per second (TPS), and GPU memory usage across three different models: a baseline model and two models incorporating the Latent Multi-Modality Extractor (LMME) with different hyperparameters. The comparison is shown for various input token lengths, demonstrating the impact of LMME on efficiency for handling long contexts. It shows how LMME reduces memory consumption and improves speed, particularly significant for longer inputs where the baseline model runs out of memory (OOM).
read the caption
(a) Prefill time, tokens per second (TPS), GPU memory comparison.

🔼 This figure compares the training time of different models on two multi-modality datasets: Lyra-MM-1.5M (containing 1.5 million text-image-speech samples) and Lyra-LongSpeech-12K (containing 12,000 long-speech samples). The baseline model is compared to three variants of the model that utilize the latent multi-modality extractor (LMME), with varying numbers of blocks (n) and top proportions of tokens retained (p). The results show significant reductions in training time for the LMME models on both datasets, demonstrating improved training efficiency by selectively retaining important tokens and reducing redundancy.
read the caption
(b) Training time on multi-modality datasets comparison.

🔼 This table presents a comparison of the efficiency of the Latent Multi-Modality Extractor (LMME) module against a baseline model. It shows the prefill time (in seconds), tokens per second (TPS), and GPU memory usage for different sequence lengths (211-217 tokens), under varying configurations of the LMME (splitting the model into 4 blocks and retaining the top 80% or 70% of tokens). The results demonstrate how LMME significantly improves efficiency in terms of memory usage and processing speed, particularly for longer sequences, while maintaining comparable performance.
read the caption
Table 4: Efficiency of latent multi-modality extractor.

🔼 Table 5 presents a detailed evaluation of Lyra’s performance on long-speech tasks, specifically focusing on the Video Multimodal Multitask Evaluation (VideoMME) benchmark. It shows that Lyra, leveraging its long-speech capabilities, successfully processes audio inputs that are significantly longer than what typical models handle. The results highlight Lyra’s ability to achieve comparable or even better accuracy compared to the state-of-the-art VLMs on VideoMME, demonstrating its improved performance on long, medium, and short-length audio inputs, despite using only audio data.
read the caption
Table 5: Effectiveness of long speech capability integration. Lyra integrated with long speech ability, using only audio input, can handle one-third of VideoMME cases, and its accuracies on long, medium, short metrics are better than the current best VLM.

🔼 The table demonstrates the effectiveness of Multi-modality Low-Rank Adaptation (MLoRA) in addressing the performance degradation of pre-trained models when a new modality is added. Powerful pre-trained models often suffer reduced capabilities in existing modalities after incorporating a new one. This table shows that MLoRA mitigates this issue, maintaining or improving performance across multiple modalities, even with limited training data.
read the caption
Table 6: Effectiveness of multi-modality LoRA (MLoRA). For powerful pretrained models, adding new modality can impair the abilities of other modalities. MLoRA can effectively address it.

🔼 This figure visualizes the latent multi-modality extractor’s functionality across video and audio data. The top half shows the video modality, while the bottom half displays the audio modality. The key idea is that the extractor identifies and retains only the semantically relevant tokens from each modality that directly relate to the given instruction. By filtering out irrelevant tokens, the computational cost of processing this multimodal information is significantly reduced. The appendix includes visualizations for the image modality and a breakdown of the process across different blocks within the model architecture.
read the caption
Figure 5: Visualization of latent multi-modality extractor in various modalities. The upper part is the video modality, and the lower part is the audio modality. Through latent multi-modality information extraction, semantic tokens related to the instruction are retained, reducing the computational cost of the MLLM. The visualization of the image modality and different blocks can be found in the appendix.

🔼 This figure shows the results of the needle in a haystack experiment for evaluating the model’s ability to handle long speech inputs. The x-axis represents the position of the needle (in seconds), and the y-axis represents the accuracy of the model in retrieving the correct information. Different lines represent different methods: the baseline model, a model trained with long speech data, and a model incorporating both long speech data and the latent multi-modality extractor. The figure visually demonstrates the significant improvement in accuracy and the ability to handle increasingly longer audio inputs by incorporating the improvements in Lyra, especially with the multi-modality extractor.
read the caption
(a)
More on tables
| TextVQA (S+I) | TextVQA (T+I) | MM-Vet (S+I) | MM-Vet (T+I) |
|---|---|---|---|
| 76.7 (-2.8) | 79.5 | 53.1 (-8.0) | 63.1 |
🔼 This table presents a comprehensive comparison of Lyra’s performance against state-of-the-art models across various vision-language-speech benchmarks. It shows the performance of each model on tasks involving different combinations of modalities (text, image, video, and speech), highlighting Lyra’s superior performance in various multi-modal understanding tasks. The ‘BenchS’ suffix indicates results where the model received instructions in speech format, offering additional insights into the model’s capacity to handle speech-based inputs.
read the caption
Table 2: Omni-comparison on vision-language-speech benchmarks. BenchS indicates that it uses speech instruction as the input.
| #(Token) | 100 | 150 | 300 | 500 | 1500 |
|---|---|---|---|---|---|
| TextVQAS | 75.9% | 76.8% | 77.8% | 78.0% | 76.8% |
| MM-VetS | 55.3% | 54.4% | 56.3% | 58.8% | 58.9% |
🔼 Table 3 presents a component-wise analysis of the Lyra model’s performance, focusing on the impact of the proposed latent cross-modality regularizer. The table shows how this regularizer enhances the alignment between different modalities (specifically speech and image, and text and image), leading to improved results on benchmark tasks. The improvement is measured by the increase in performance metrics across various tasks and a reduction in the discrepancy of performance between the speech-image and text-image modalities.
read the caption
Table 3: Latent cross-modality regularizer. With our regularizer, the performance of both the speech-image and text-image modalities improves, and the gap narrows.
| Omni Comparison | Text-Image | Text-Video | Image-Speech | Text-Speech |
|---|---|---|---|---|
| Method | Params. | TextVQA | MME | MM-Vet |
| — | — | — | — | — |
| Mini-Gemini | 8B | 71.9 | 1989 | 53.5 |
| LLaVA-OV | 7B | 65.4 | 1998 | 57.5 |
| Intern-VL2 | 8B | 77.4 | 2211 | 60.0 |
| Mini-Omni | 7B | - | - | - |
| SALMONN | 13B | - | - | - |
| Qwen2-Audio | 8B | - | - | - |
| Intern-Omni | 8B | 80.6 | 2210 | 60.0 |
| VITA | 66B | - | 2097 | 41.6 |
| EMOVA | 14B | 82.0 | 2205 | 55.8 |
| Lyra-Mini | 3B | 78.3 | 1884 | 51.2 |
| Lyra-Base | 9B | 82.6 | 2335 | 63.5 |
| Lyra-Pro | 74B | 83.5 | 2485 | 71.4 |
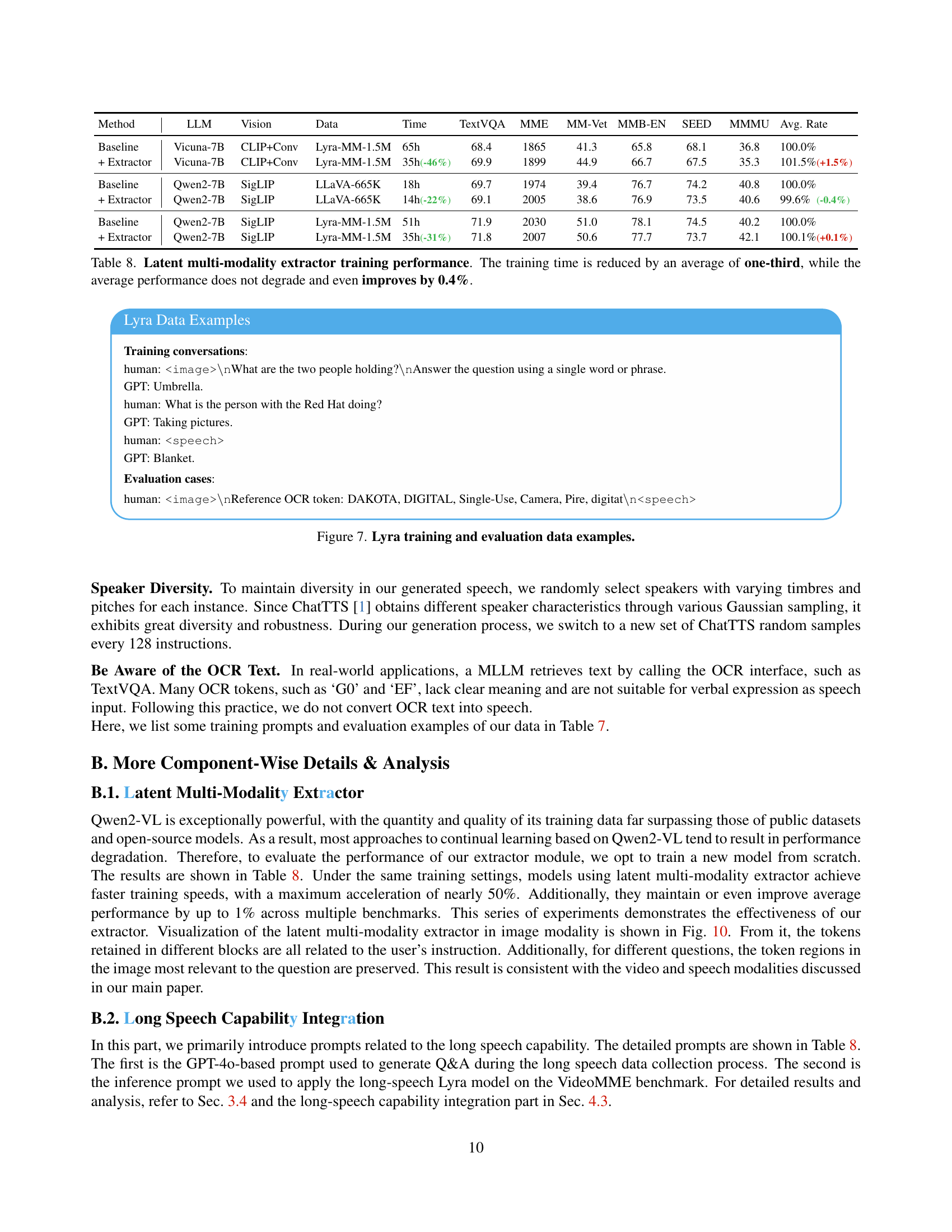
🔼 This table details the hyperparameters and data used for training the Lyra model across four distinct stages. Stage 1 focuses on speech projector pre-training using the LibriSpeech and Common Voice datasets. Stage 2 involves joint training of text, image, and speech modalities using the Lyra-MultiModal-1.5M dataset. Stage 3 extends training to incorporate long-speech capabilities using the Lyra-LongSpeech-12K dataset. Finally, Stage 4 trains the speech generator. The table provides specifics such as audio length, number of tokens, dataset size, batch size, learning rate, and number of epochs for each stage, offering a comprehensive view of the model’s training process.
read the caption
Table 7: Detailed training settings of Lyra.
| Effectiveness | TexVQA | MM-Vet | LibriSpeech | |||
|---|---|---|---|---|---|---|
| Type | S+I | T+I | S+I | T+I | S+T | |
| Baseline | - | 82.3 | - | 62.8 | - | |
| $ | ||||||
| \mathcal{L} | ||||||
| _{\rm CE}$ | 76.7 | 79.5 | 53.1 | 61.1 | 1.9 | |
| $ | ||||||
| \mathcal{L} | ||||||
| _{\rm CE}$ + $ | ||||||
| \lambda | ||||||
| \mathcal{L} | ||||||
| _{\rm LCMR}$ | 77.8 | 80.1 | 58.1 | 62.6 | 2.0 |
🔼 This table presents a comparison of training performance with and without the latent multi-modality extractor. It shows that incorporating the extractor significantly reduces training time (by an average of one-third) without sacrificing model performance; in fact, average performance is slightly improved (by 0.4%). The table compares various metrics such as TextVQA, MME, MM-Vet, MMB-EN, SEED, MMMU, and average performance rate across different model configurations (baseline and with the extractor).
read the caption
Table 8: Latent multi-modality extractor training performance. The training time is reduced by an average of one-third, while the average performance does not degrade and even improves by 0.4%.
Full paper#