↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current sparse-view 3D reconstruction methods heavily rely on precise camera pose information, which is difficult and often unreliable to obtain from sparse views. This limitation restricts the applicability and efficiency of these methods. Existing pose-free approaches either suffer from low resolution, inefficient rendering, or complex processes.
FreeSplatter addresses these issues by introducing a novel feed-forward framework. It uses a streamlined transformer architecture to predict pixel-wise 3D Gaussian primitives directly from multi-view images. These primitives are then used to reconstruct the 3D scene and estimate camera parameters simultaneously using off-the-shelf solvers. This approach significantly improves reconstruction quality and pose estimation accuracy while maintaining computational efficiency. The model’s flexibility caters to both object-centric and scene-level reconstructions.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances sparse-view 3D reconstruction, a crucial problem in computer vision with broad applications. By eliminating the need for accurate camera poses, it enhances the efficiency and generalizability of 3D modeling, opening new avenues for research in areas like text/image-to-3D content creation and robotics. The novel approach using Gaussian splatting and transformers offers a unique solution that is both efficient and highly effective, setting a new benchmark for pose-free reconstruction.
Visual Insights#

🔼 This figure demonstrates the FreeSplatter model’s ability to reconstruct 3D scenes from a small number of images without prior knowledge of camera positions or internal parameters. The top half shows an object-centric example where the model successfully reconstructs a 3D representation of a toy figure from several input views. The bottom half shows a scene-level example where a more complex scene is similarly reconstructed. The model produces pixel-wise 3D Gaussians, allowing for high-fidelity novel view rendering and extremely fast (seconds) camera pose estimation.
read the caption
Figure 1: Given uncalibrated sparse-view images, our FreeSplatter can reconstruct pixel-wise 3D Gaussians, enabling both high-fidelity novel view rendering and instant camera pose estimation in mere seconds. FreeSplatter can deal with both object-centric (up) and scene-level (down) scenarios.
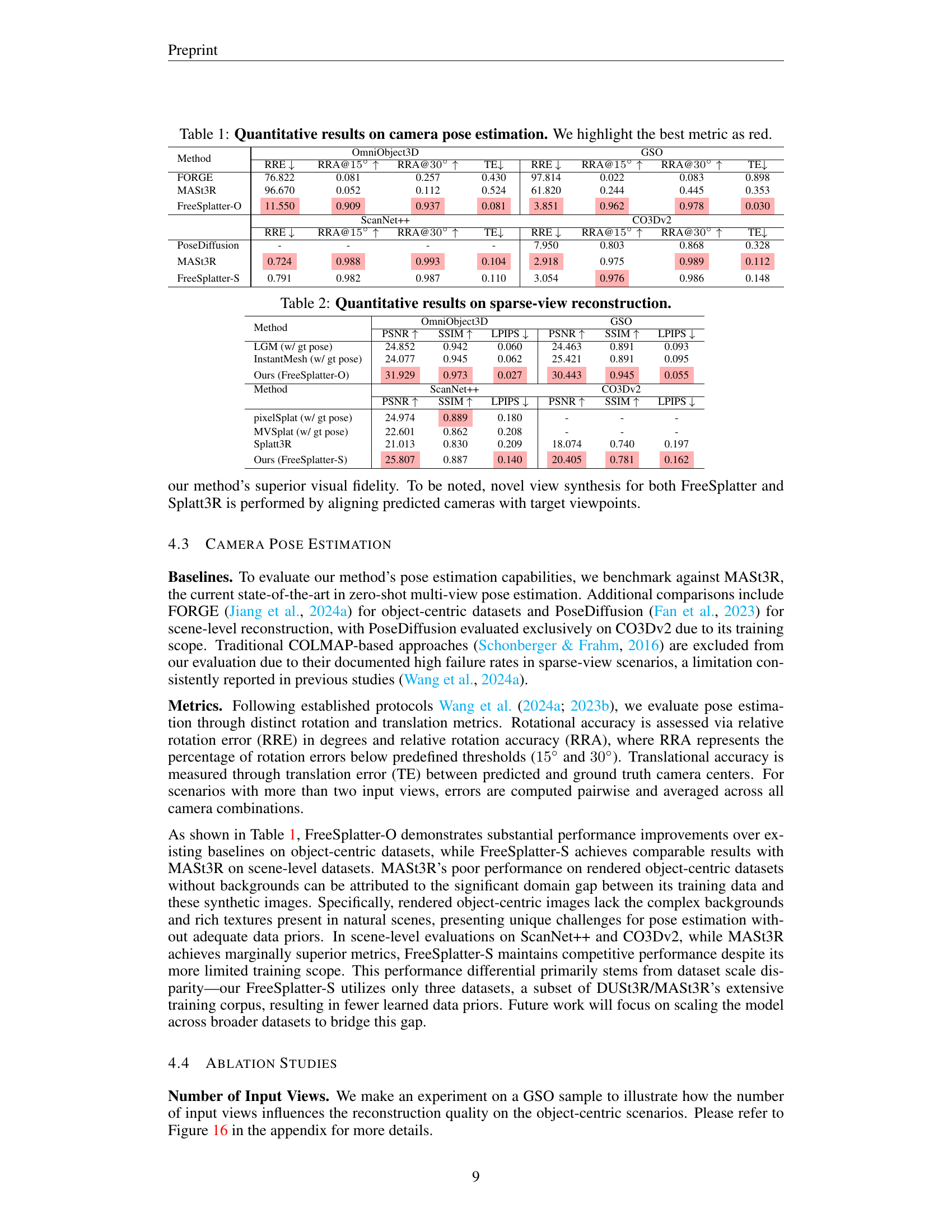
| Method | OmniObject3D | GSO | ||||||
|---|---|---|---|---|---|---|---|---|
| RRE ↓ | RRA@15° ↑ | RRA@30° ↑ | TE ↓ | RRE ↓ | RRA@15° ↑ | RRA@30° ↑ | TE ↓ | |
| — | — | — | — | — | — | — | — | — |
| FORGE | 76.822 | 0.081 | 0.257 | 0.430 | 97.814 | 0.022 | 0.083 | 0.898 |
| MASt3R | 96.670 | 0.052 | 0.112 | 0.524 | 61.820 | 0.244 | 0.445 | 0.353 |
| FreeSplatter-O | 11.550 | 0.909 | 0.937 | 0.081 | 3.851 | 0.962 | 0.978 | 0.030 |
| ScanNet++ | CO3Dv2 | |||||||
| — | — | — | — | — | — | — | — | — |
| RRE ↓ | RRA@15° ↑ | RRA@30° ↑ | TE ↓ | RRE ↓ | RRA@15° ↑ | RRA@30° ↑ | TE ↓ | |
| — | — | — | — | — | — | — | — | — |
| PoseDiffusion | - | - | - | - | 7.950 | 0.803 | 0.868 | 0.328 |
| MASt3R | 0.724 | 0.988 | 0.993 | 0.104 | 2.918 | 0.975 | 0.989 | 0.112 |
| FreeSplatter-S | 0.791 | 0.982 | 0.987 | 0.110 | 3.054 | 0.976 | 0.986 | 0.148 |
🔼 This table presents a quantitative comparison of different methods for camera pose estimation. The methods are evaluated on two datasets: OmniObject3D and Google Scanned Objects (GSO). For each method and dataset, the table shows the relative rotation error (RRE), relative rotation accuracy at 15° (RRA@15°), relative rotation accuracy at 30° (RRA@30°), and translation error (TE). Lower values for RRE and TE indicate better performance, while higher values for RRA indicate better accuracy. The best metric for each column is highlighted in red.
read the caption
Table 1: Quantitative results on camera pose estimation. We highlight the best metric as red.
In-depth insights#
Pose-Free 3D Recon#
Pose-free 3D reconstruction is a significant challenge in computer vision, aiming to reconstruct 3D scenes without relying on known camera poses. Traditional methods heavily depend on accurate pose estimation, often using Structure-from-Motion (SfM) techniques. However, SfM struggles with sparse views where image overlaps are insufficient. Pose-free approaches offer the advantage of handling uncalibrated data directly, circumventing the need for computationally expensive and sometimes unreliable pose estimation steps. The core challenge lies in learning robust representations that can capture scene geometry and appearance from limited and unconstrained views. Recent advances utilize deep learning architectures, often transformers and neural radiance fields, to learn intricate scene representations. These approaches typically predict 3D structures (points, meshes, or implicit functions) directly from images, often incorporating self-attention mechanisms to leverage information from multiple views. The key is designing effective loss functions that encourage geometric consistency and photorealism without the explicit supervision provided by known camera poses. Further research focuses on improving robustness to noise, handling complex scenes, and achieving real-time performance for practical applications. The potential impact of reliable pose-free 3D reconstruction is vast, enabling new applications in augmented and virtual reality, robotics, and 3D modeling.
Gaussian Splatting#
Gaussian splatting, a novel 3D scene representation technique, offers significant advantages over traditional methods. By representing scenes as a collection of 3D Gaussian primitives, it enables efficient view synthesis and high-fidelity rendering. Each Gaussian splat encodes not only spatial location but also attributes like color and opacity, allowing for more detailed and realistic reconstructions. Unlike methods reliant on dense sampling, Gaussian splatting’s implicit nature allows for effective rendering even with relatively few primitives, resulting in substantial computational savings. The differentiability of the Gaussian splatting representation is a key feature, making it particularly well-suited for integration within neural rendering pipelines and optimization processes. This differentiability is crucial for training efficient and accurate neural networks to learn complex scene representations from multi-view images. Furthermore, adaptability to various data types and sparsity levels significantly enhances its practical applicability. This makes Gaussian splatting a powerful tool for many applications, from novel view synthesis to high-fidelity 3D reconstruction.
Transformer Network#
Transformer networks, particularly the self-attention mechanism, are revolutionizing sequence modeling tasks. In the context of 3D reconstruction, transformers excel at processing multi-view image data by capturing long-range dependencies between image patches across different viewpoints. The sequential self-attention blocks facilitate information flow between image tokens, allowing the model to aggregate global context from all views before reconstructing the 3D scene. Unlike traditional methods relying on explicit feature matching or camera pose estimation, transformers learn implicit representations of the scene geometry and camera parameters, making the process more robust and efficient. The scalability of the transformer architecture is a key advantage, enabling processing of high-resolution images and complex scenes. However, challenges remain in fully understanding the learned representations, the computational cost associated with large-scale transformers, and the potential limitations of the feed-forward nature of these models in handling occlusions or ambiguities.
Camera Pose Estim#
Camera pose estimation is a crucial aspect of 3D reconstruction, particularly challenging in sparse-view scenarios where traditional methods struggle. Accurate camera poses are essential for aligning multiple views to create a consistent 3D model. The paper’s approach to camera pose estimation, likely leveraging the predicted Gaussian maps, is noteworthy. By using the predicted locations of Gaussian primitives, the method bypasses the need for explicit feature matching or correspondence identification, a common bottleneck in traditional SfM pipelines. Instead, it employs off-the-shelf solvers, possibly PnP (Perspective-n-Point) or RANSAC (Random Sample Consensus), to rapidly estimate camera poses. This feed-forward approach directly predicts camera parameters jointly with scene representation, leading to significant speed gains over iterative methods. The accuracy of pose estimation is tightly coupled to the quality of the scene reconstruction, highlighting the importance of a robust and accurate 3D model generation. The performance gains from this approach are substantial because of its direct prediction ability and its efficiency in not needing point cloud initialization.
Future Research#
Future research directions for pose-free Gaussian splatting should prioritize improving the model’s generalization capabilities across diverse scene types and object categories. Addressing the limitations of the current model’s reliance on depth data during pre-training is crucial for broader applicability to datasets lacking depth information. A unified model that seamlessly handles both object-centric and scene-level reconstruction would streamline application and reduce computational needs. Further exploration of occlusion handling is important; current methods rely on simple masking strategies that may not generalize well to complex scenes. Investigating more advanced techniques to predict complete scene geometry despite limited input views is also necessary. Finally, enhancing the efficiency of the pipeline, both in terms of training time and inference speed, is vital for wider adoption in real-time applications.
More visual insights#
More on figures

🔼 The FreeSplatter pipeline processes uncalibrated multi-view images to reconstruct a 3D scene. The input images are first divided into patches and converted into image tokens. These tokens are then processed through a series of self-attention transformer blocks, allowing information exchange between different views. The output from the transformer is then decoded into N Gaussian maps (one for each input image). These Gaussian maps represent the 3D scene as a collection of Gaussian primitives. From these Gaussian maps, novel views of the scene can be rendered, and the camera parameters (focal length and pose) for each input image can be estimated using iterative solvers.
read the caption
Figure 2: FreeSplatter pipeline. Given input views {𝑰n∣n=1,…,N}conditional-setsuperscript𝑰𝑛𝑛1…𝑁\left\{{\bm{I}}^{n}\mid n=1,\ldots,N\right\}{ bold_italic_I start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∣ italic_n = 1 , … , italic_N } without any known camera extrinsics or intrinsics, we first patchify them into image tokens, and then feed all tokens into a sequence of self-attention blocks to exchange information among multiple views. Finally, we decode the output image tokens into N𝑁Nitalic_N Gaussian maps {𝑮n∣n=1,…,N}conditional-setsuperscript𝑮𝑛𝑛1…𝑁\left\{{\bm{G}}^{n}\mid n=1,\ldots,N\right\}{ bold_italic_G start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∣ italic_n = 1 , … , italic_N }, from which we can render novel views, as well as recovering camera focal length f𝑓fitalic_f and poses {𝑷n∣n=1,…,N}conditional-setsuperscript𝑷𝑛𝑛1…𝑁\left\{{\bm{P}}^{n}\mid n=1,\ldots,N\right\}{ bold_italic_P start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∣ italic_n = 1 , … , italic_N } with simple iterative solvers.

🔼 Figure 3 showcases a comparison of object-centric sparse-view 3D reconstruction methods. Six examples from the Google Scanned Objects dataset are used. The top two rows display results from LGM and InstantMesh, respectively, which both leverage ground truth camera poses and intrinsic parameters for reconstruction. The bottom row shows FreeSplatter’s results, demonstrating high-fidelity reconstruction achieved without any prior knowledge of camera poses.
read the caption
Figure 3: Object-centric Sparse-view Reconstruction. We show 6 samples from the Google Scanned Objects dataset. To be noted, the results of LGM and InstantMesh (\nth2 and \nth3 rows) are generated with ground truth camera poses (and intrinsics), while our results (\nth4 row) are generated in a completely pose-free manner.

🔼 This figure compares the scene reconstruction capabilities of different methods on the ScanNet++ dataset. It shows the results of four methods: pixelSplat, MVSplat, Splat3R, and the proposed FreeSplatter. PixelSplat and MVSplat are presented as baselines that rely on accurate camera pose information (ground truth poses). In contrast, Splat3R and FreeSplatter are both pose-free methods; that is, they don’t require ground truth camera poses as input. The image displays a visual comparison of the scene reconstruction quality produced by each approach.
read the caption
Figure 4: Scene-level Reconstruction on ScanNet++. The results of pixelSplat and MVSplat are obtained with ground truth input poses, while the results of Splat3R and ours are pose-free.

🔼 This figure displays a comparison of scene-level 3D reconstruction results on the CO3Dv2 dataset. It showcases the input image, the results of the FreeSplatter model (rendering of input views with predicted poses), the results of Splatt3R (a comparable pose-free model), and additional novel views rendered by both FreeSplatter and Splatt3R. The goal is to visually demonstrate FreeSplatter’s ability to generate high-quality novel views compared to a leading pose-free competitor, highlighting its performance in a challenging real-world scene reconstruction scenario.
read the caption
Figure 5: Scene-level Reconstruction on CO3Dv2.

🔼 Figure 6 demonstrates the application of FreeSplatter in 3D content creation. The top two rows showcase image-to-3D results, utilizing Zero123++, a multi-view image generation model. For each example, the input image is shown, followed by a visualization of the generated 3D Gaussian representation, and finally two novel views rendered from this representation. The bottom row presents text-to-3D results generated with MVDream, where a text prompt is provided, along with visualizations of the generated Gaussian representation and two novel views.
read the caption
Figure 6: 3D content creation with FreeSplatter. \nth1 and \nth2 rows: Image-to-3D results using Zero123++ (input image, Gaussian visualization, two novel views). \nth3 row: Text-to-3D results using MVDream (prompt shown above; two Gaussian visualizations, two novel views).

🔼 This figure compares the performance of FreeSplatter-O and PF-LRM on two datasets: Google Scanned Objects (GSO) and OmniObject3D. The top three rows showcase results from the GSO dataset, while the bottom four rows display results from the OmniObject3D dataset. Each set of images shows the input image, followed by reconstructions generated by FreeSplatter-O and PF-LRM, and finally the ground truth image. The visual comparison demonstrates that FreeSplatter-O produces significantly finer details and more accurate reconstructions than PF-LRM.
read the caption
Figure 7: Comparison with PF-LRM on its evaluation datasets. The test samples in the first 3 rows are from the GSO evaluation set of PF-LRM, while the samples in the last 4 rows are from the OmniObject3D evaluation set of PF-LRM. Our FreeSplatter-O synthesizes significantly better visual details than PF-LRM.

🔼 This figure compares the image-to-3D generation results of different methods, including FreeSplatter (ours), LGM, and InstantMesh. All methods use Zero123++ v1.2 to generate multiple views from a single input image. The comparison highlights the differences in the quality of 3D models produced by each method, showcasing FreeSplatter’s ability to generate clearer and more detail-rich views.
read the caption
Figure 8: Comparison on image-to-3D generation with Zero123++ v1.2 (Shi et al., 2023).

🔼 Figure 9 presents a comparison of image-to-3D generation results using different methods. It shows the results of generating 3D models from a single input image using three approaches: Hunyuan3D Std (a state-of-the-art multi-view diffusion model used for generating multi-view images as input), a pose-dependent LRM (Large Reconstruction Model) which needs camera pose information for accurate results, and the proposed FreeSplatter method which is pose-free. The figure illustrates the visual quality of the 3D models generated by each method, comparing the generated novel views against the ground truth. This comparison highlights the performance of FreeSplatter in terms of generating visually accurate and detailed 3D models, especially when compared to pose-dependent methods.
read the caption
Figure 9: Comparison on image-to-3D generation with Hunyuan3D Std (Yang et al., 2024b).

🔼 This figure demonstrates how incorporating the input image alongside the generated views improves the image-to-3D generation results. The input image generally has higher quality and richer visual detail than views generated by a multi-view diffusion model like Zero123++ v1.1. However, pose-dependent Large Reconstruction Models (LRMs) cannot utilize the input image because its camera pose is unknown. FreeSplatter’s ability to use both the input image and the generated views is particularly beneficial when reconstructing challenging subjects, such as human faces, where multi-view diffusion models often struggle.
read the caption
Figure 10: Use input image to enhance the image-to-3D generation results with Zero123++ v1.1 (Shi et al., 2023). The input image is often more high-quality and contains richer visual details than the generated views, but its camera pose is unknown, making it impossible for pose-dependent LRMs to leverage it. The capability of using the input image alongside generated views of our FreeSplatter is particularly valuable for challenging content like human faces, where Zero123++ often struggles to generate.

🔼 This figure demonstrates FreeSplatter’s ability to accurately estimate camera poses from images generated by multi-view diffusion models. It compares the ground truth camera poses (shown as gray pyramids) with the poses estimated by FreeSplatter (colorful pyramids). The ground truth poses are defined by pre-defined azimuth (φ) and elevation (θ) angles, which are specified in the multi-view diffusion model. For models that use a fixed field of view (FOV), the FOV angles and corresponding focal lengths (in pixels) are also indicated.
read the caption
Figure 11: Our FreeSplatter can faithfully recover the pre-defined camera poses of existing multi-view diffusion models. We use gray pyramids to visualize the ground truth pre-defined camera poses of the diffusion models, and colorful pyramids to visualize the estimated poses. φ𝜑\varphiitalic_φ and θ𝜃\thetaitalic_θ denote the pre-defined azimuth and elevation angles, respectively. Since Zero123++ v1.2 and Hunyuan3D Std generate images at pre-defined fixed Field-of-View (fov), we mark their pre-defined fov angles and corresponding focal lengths (in pixel units) too.

🔼 This figure showcases the zero-shot, pose-free 3D reconstruction capabilities of the FreeSplatter-O model on the ABO and OmniObject3D datasets. Importantly, these datasets were not included in the model’s training data. The results demonstrate that FreeSplatter-O accurately estimates the input camera poses, even without prior knowledge, and generates high-fidelity novel views of the 3D scenes. This highlights the model’s robustness and generalization ability.
read the caption
Figure 12: Zero-shot pose-free reconstruction results on ABO and OmniObject3D. Both datasets are unseen for FreeSplatter-O. Our model can faithfully estimate the input camera poses and render high-fidelity novel views.

🔼 This figure demonstrates the zero-shot capabilities of FreeSplatter-S on the RealEstate10K dataset, a dataset it was not trained on. The results show that the model accurately reconstructs the input views using its estimated camera poses. More importantly, the novel views generated by the model closely match the ground truth views, highlighting the model’s ability to generalize well to unseen data.
read the caption
Figure 13: Zero-shot pose-free reconstruction and view synthesis results on RealEstate10K. Our FreeSplatter-S model was not trained on RealEstate10K, we directly utilize it for zero-shot view synthesis on this dataset. We can observe that our model can faithfully reconstruct the input views at the estimated input poses, and the rendered novel views align well with the ground truth.

🔼 This figure demonstrates the zero-shot generalization capabilities of the FreeSplatter-S model on diverse datasets. It showcases two examples each from four distinct datasets: DTU (a dataset of scanned objects), MVImgNet (multi-view images), Tanks & Temples (large-scale outdoor scenes), and Sora-generated videos. For each dataset, the figure displays the input images, the reconstructed images with predicted poses, and the rendered novel views. This visualization highlights the model’s ability to generalize across various scene types, scales, and capture conditions.
read the caption
Figure 14: Zero-shot generalization of FreeSplatter-S on various datasets. We show 2 examples for DTU, MVImgNet, Tanks & Temples and Sora-generated videos, respectively.

🔼 This figure demonstrates the impact of the pixel-alignment loss on the model’s performance. It visually compares the results of the model trained with and without the pixel-alignment loss. The comparison is shown on two examples from the Google Scanned Objects (GSO) dataset. The images reveal significantly better visual detail and clarity in the model trained with the pixel-alignment loss, highlighting its importance in improving the overall quality of the 3D reconstruction.
read the caption
Figure 15: Ablation on pixel-alignment loss. We show two samples from the GSO dataset.

🔼 This figure shows an ablation study on the number of input views used in FreeSplatter-O, the object-centric variant of the model. It demonstrates how the reconstruction quality and completeness improve as more views are added. The figure displays the input views, the resulting 3D Gaussian representation, and renderings from four fixed viewpoints for each number of input views (from 1 to 6). As the number of input views increases, the density of the Gaussian representation increases, filling in gaps and leading to more detailed and complete 3D reconstructions. However, beyond four input views, the improvements become marginal as the scene is already well-captured.
read the caption
Figure 16: Illustration on the influence of input view number. We show the visual comparison of FreeSplatter-O results with varying numbers of input views (n=1−6𝑛16n=1-6italic_n = 1 - 6). From left to right: input views, reconstructed Gaussians, and rendered target views at 4 fixed viewpoints. Additional input views increase Gaussian density and improve previously uncovered regions, with diminishing returns beyond n=4 when object coverage becomes sufficient.

🔼 This ablation study investigates the effect of adding view embeddings to image tokens within the FreeSplatter model. The experiment uses four input views (V1, V2, V3, V4). Different combinations of adding a reference view embedding (eref, red boxes) and a source view embedding (esrc, blue boxes) to the image tokens are tested. The resulting image rendered with an identity camera (reference pose) for each case is shown. This helps to understand how the model utilizes view embeddings to differentiate between the reference view and other views, ultimately affecting the reconstruction quality.
read the caption
Figure 17: Ablation study on view embedding addition. Red/blue boxes indicate views added with reference/source view embeddings respectively. For each case, we visualize the image rendered with identity camera (i.e., reference pose) on the right.
More on tables
| Method | OmniObject3D PSNR ↑ | OmniObject3D SSIM ↑ | OmniObject3D LPIPS ↓ | GSO PSNR ↑ | GSO SSIM ↑ | GSO LPIPS ↓ |
|---|---|---|---|---|---|---|
| LGM (w/ gt pose) | 24.852 | 0.942 | 0.060 | 24.463 | 0.891 | 0.093 |
| InstantMesh (w/ gt pose) | 24.077 | 0.945 | 0.062 | 25.421 | 0.891 | 0.095 |
| Ours (FreeSplatter-O) | 31.929 | 0.973 | 0.027 | 30.443 | 0.945 | 0.055 |
| Method | ScanNet++ PSNR ↑ | ScanNet++ SSIM ↑ | ScanNet++ LPIPS ↓ | CO3Dv2 PSNR ↑ | CO3Dv2 SSIM ↑ | CO3Dv2 LPIPS ↓ |
| — | — | — | — | — | — | — |
| pixelSplat (w/ gt pose) | 24.974 | 0.889 | 0.180 | - | - | - |
| MVSplat (w/ gt pose) | 22.601 | 0.862 | 0.208 | - | - | - |
| Splatt3R | 21.013 | 0.830 | 0.209 | 18.074 | 0.740 | 0.197 |
| Ours (FreeSplatter-S) | 25.807 | 0.887 | 0.140 | 20.405 | 0.781 | 0.162 |
🔼 This table presents a quantitative comparison of different methods for sparse-view 3D reconstruction. It shows the performance of various techniques, including both pose-dependent and pose-free methods, across two datasets: OmniObject3D and Google Scanned Objects (GSO). Metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Higher PSNR and SSIM values indicate better reconstruction quality, while a lower LPIPS value suggests improved perceptual similarity to ground truth.
read the caption
Table 2: Quantitative results on sparse-view reconstruction.
| Method | GSO PSNR ↑ | GSO SSIM ↑ | GSO LPIPS ↓ | ScanNet++ PSNR ↑ | ScanNet++ SSIM ↑ | ScanNet++ LPISP ↓ |
|---|---|---|---|---|---|---|
| FreeSplatter-O (w/o \mathcal{L}_{align}) | 26.684 | 0.898 | 0.092 | 21.330 | 0.832 | 0.201 |
| FreeSplatter-S (w/o \mathcal{L}_{align}) | 21.330 | 0.832 | 0.201 | 25.807 | 0.887 | 0.140 |
| FreeSplatter-O | 30.443 | 0.945 | 0.055 | 25.807 | 0.887 | 0.140 |
🔼 This table presents the ablation study on the impact of the pixel-alignment loss on the model’s performance. It compares the performance metrics (PSNR, SSIM, LPIPS) of the FreeSplatter model trained with and without the pixel-alignment loss on two datasets: Google Scanned Objects (GSO) and ScanNet++. The results demonstrate the significant contribution of the pixel-alignment loss to the model’s performance, particularly in improving the visual fidelity of the generated novel views.
read the caption
Table 3: Ablation on the pixel-alignment loss.
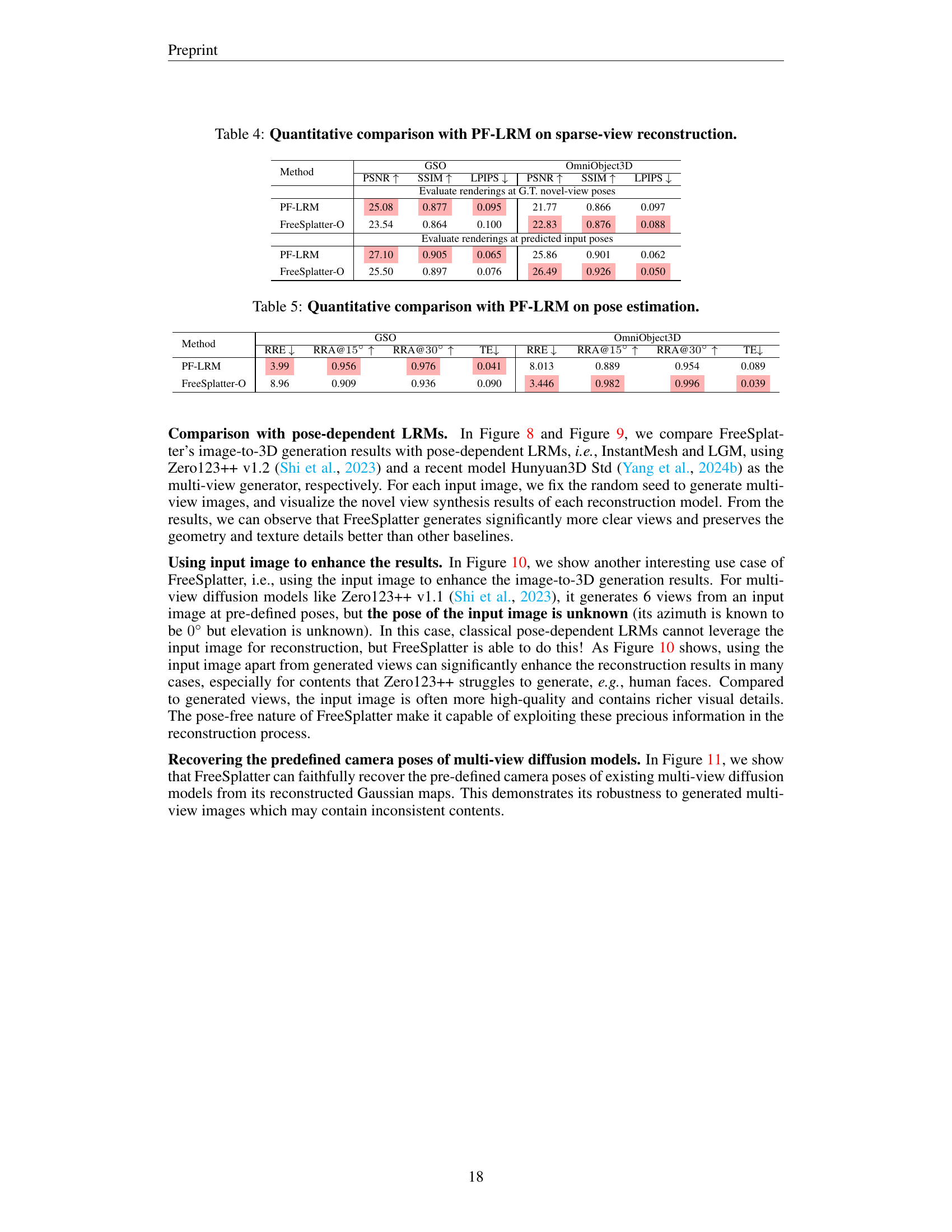
| Method | GSO PSNR ↑ | GSO SSIM ↑ | GSO LPIPS ↓ | OmniObject3D PSNR ↑ | OmniObject3D SSIM ↑ | OmniObject3D LPIPS ↓ |
|---|---|---|---|---|---|---|
| Evaluate renderings at G.T. novel-view poses | ||||||
| PF-LRM | 25.08 | 0.877 | 0.095 | 21.77 | 0.866 | 0.097 |
| FreeSplatter-O | 23.54 | 0.864 | 0.100 | 22.83 | 0.876 | 0.088 |
| Evaluate renderings at predicted input poses | ||||||
| PF-LRM | 27.10 | 0.905 | 0.065 | 25.86 | 0.901 | 0.062 |
| FreeSplatter-O | 25.50 | 0.897 | 0.076 | 26.49 | 0.926 | 0.050 |
🔼 This table presents a quantitative comparison of the proposed FreeSplatter model and the PF-LRM method on sparse-view 3D reconstruction tasks. It compares the performance of both models across two key metrics: PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). The LPIPS (Learned Perceptual Image Patch Similarity) metric, which assesses the perceptual difference between images, is also included. The comparison is made for two different scenarios: using the ground truth novel view poses for evaluation and using the predicted input poses for evaluation. This provides a comprehensive comparison of reconstruction quality under varying conditions.
read the caption
Table 4: Quantitative comparison with PF-LRM on sparse-view reconstruction.
| Method | GSO RRE ↓ | GSO RRA@15° ↑ | GSO RRA@30° ↑ | GSO TE ↓ | OmniObject3D RRE ↓ | OmniObject3D RRA@15° ↑ | OmniObject3D RRA@30° ↑ | OmniObject3D TE ↓ |
|---|---|---|---|---|---|---|---|---|
| PF-LRM | 3.99 | 0.956 | 0.976 | 0.041 | 8.013 | 0.889 | 0.954 | 0.089 |
| FreeSplatter-O | 8.96 | 0.909 | 0.936 | 0.090 | 3.446 | 0.982 | 0.996 | 0.039 |
🔼 This table presents a quantitative comparison of FreeSplatter-O and PF-LRM on camera pose estimation performance. It uses metrics such as Relative Rotation Error (RRE), Relative Rotation Accuracy at 15° and 30° (RRA@15°, RRA@30°), and Translation Error (TE) to compare the accuracy of pose estimation by both methods on the OmniObject3D and GSO datasets.
read the caption
Table 5: Quantitative comparison with PF-LRM on pose estimation.
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| pixelSplat (w/ GT poses) | 24.469 | 0.829 | 0.224 |
| MVSplat (w/ GT poses) | 20.033 | 0.789 | 0.280 |
| Splatt3R (no pose) | 16.634 | 0.604 | 0.422 |
| FreeSplatter-S (no pose) | 18.851 | 0.659 | 0.369 |
🔼 This table presents a quantitative comparison of different methods for sparse-view 3D reconstruction on the RealEstate10K dataset. It evaluates the performance of several approaches, including methods that use ground truth camera poses (pixelSplat and MVSplat) and pose-free methods (Splatt3R and FreeSplatter-S). The metrics used to assess the performance are PSNR, SSIM, and LPIPS, providing a comprehensive evaluation of the reconstruction quality.
read the caption
Table 6: Quantitative sparse-view reconstruction results on RealEstate10K.
| Method | RRE ↓ | RRA@15°↑ | RRA@30°↑ | TE ↓ |
|---|---|---|---|---|
| PoseDiffsion | 14.387 | 0.732 | 0.780 | 0.466 |
| RayDiffsion | 12.023 | 0.767 | 0.814 | 0.439 |
| RoMa | 5.663 | 0.918 | 0.947 | 0.402 |
| MASt3R | 2.341 | 0.972 | 0.994 | 0.374 |
| FreeSplatter-S | 3.513 | 0.982 | 0.995 | 0.293 |
🔼 This table presents a quantitative comparison of camera pose estimation methods on the RealEstate10K dataset. The metrics used to evaluate the accuracy of pose estimation include Relative Rotation Error (RRE), Relative Rotation Accuracy at 15° and 30° thresholds (RRA@15°, RRA@30°), and Translation Error (TE). The methods compared include several state-of-the-art techniques, both pose-dependent and pose-free, allowing for a comprehensive assessment of pose estimation accuracy in the context of sparse-view reconstruction.
read the caption
Table 7: Quantitative pose estimation results on RealEstate10K.
| Architecture | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| L=16, P=16 | 25.417 | 0.896 | 0.088 |
| L=16, P=8 | 28.945 | 0.934 | 0.064 |
| L=24, P=16 | 28.622 | 0.927 | 0.063 |
| L=24, P=8 | 30.443 | 0.945 | 0.055 |
🔼 This table presents the results of an ablation study conducted to analyze the impact of different model architectures on the performance of the FreeSplatter model. Specifically, it investigates the effects of varying the number of transformer layers (L) and the patch size (P) used in the model. The study was performed using the Google Scanned Objects (GSO) dataset, and the results shown represent the PSNR, SSIM, and LPIPS metrics achieved by each model configuration. This allows for a comprehensive evaluation of how architectural choices influence the reconstruction quality and provides insights into the optimal balance between model complexity, computational resources and performance.
read the caption
Table 8: Ablation study on model architectures. The results are evaluated on GSO dataset. L𝐿Litalic_L and P𝑃Pitalic_P denote number of transformer layers and patch size, respectively.
Full paper#