↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Estimating object geometry and material properties (like color, roughness, and reflectivity) from just one image is a very hard problem in computer vision. Current methods often struggle with accuracy and efficiency, especially when dealing with real-world images which have complex lighting conditions. This is because a single image doesn’t provide enough information to uniquely determine all these properties.
This paper introduces Neural LightRig, a new framework that tackles this challenge. It cleverly generates multiple images of the same object, but under different lighting conditions, using a technique called ‘multi-light diffusion’. These synthetic images are then used to train a powerful model that can accurately predict surface normals and material properties. The experiments show that Neural LightRig is substantially better than other methods, particularly in the accuracy of its estimations and ability to generate realistic re-lit images. It also provides publicly available code and data, making it easy for other researchers to build upon this work. The framework’s accuracy and the release of code and dataset are especially valuable contributions
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to a challenging problem in computer vision and graphics: recovering object geometry and material properties from a single image. The method is significant due to its accuracy, efficiency, and generalizability, surpassing existing state-of-the-art techniques. It offers a new direction for research by successfully leveraging multi-light diffusion models for image generation and G-buffer prediction. This opens up new avenues for research in areas like augmented reality, virtual reality, and realistic image rendering.
Visual Insights#

🔼 This figure demonstrates the Neural LightRig pipeline. An input image is fed into the system. The system then generates multiple images of the same object, each illuminated from a different direction (multi-light images). This process helps to overcome the inherent ambiguity in estimating surface normal and physically-based rendering (PBR) materials from a single image. These estimated materials are high-quality and can be used to create photorealistic renderings of the object under various lighting conditions, showcasing the system’s ability to improve both the accuracy and realism of material estimation compared to only using a single image.
read the caption
Figure 1: Neural LightRig takes an image as input and generates multi-light images to assist the estimation of high-quality normal and PBR materials, which can be used to render realistic relit images under various environment lighting.
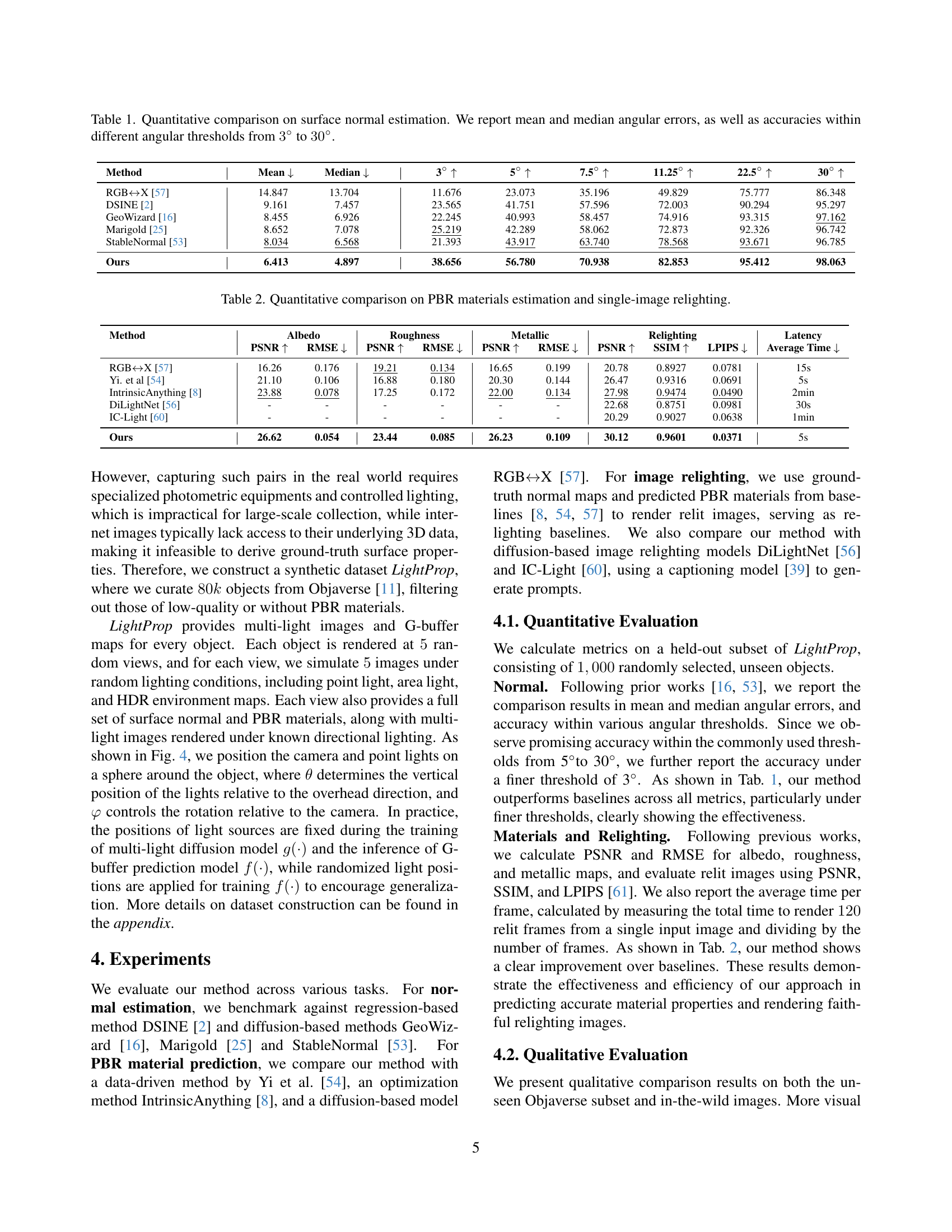
| Method | Mean ↓ | Median ↓ | 3° ↑ | 5° ↑ | 7.5° ↑ | 11.25° ↑ | 22.5° ↑ | 30° ↑ |
|---|---|---|---|---|---|---|---|---|
| RGB ↔ X [57] | 14.847 | 13.704 | 11.676 | 23.073 | 35.196 | 49.829 | 75.777 | 86.348 |
| DSINE [2] | 9.161 | 7.457 | 23.565 | 41.751 | 57.596 | 72.003 | 90.294 | 95.297 |
| GeoWizard [16] | 8.455 | 6.926 | 22.245 | 40.993 | 58.457 | 74.916 | 93.315 | 97.162 |
| Marigold [25] | 8.652 | 7.078 | 25.219 | 42.289 | 58.062 | 72.873 | 92.326 | 96.742 |
| StableNormal [53] | 8.034 | 6.568 | 21.393 | 43.917 | 63.740 | 78.568 | 93.671 | 96.785 |
| Ours | 6.413 | 4.897 | 38.656 | 56.780 | 70.938 | 82.853 | 95.412 | 98.063 |
🔼 This table presents a quantitative comparison of different methods for surface normal estimation. The metrics used are mean and median angular errors, which measure the average and middle values of the errors in angle between the estimated surface normal and the ground truth normal. In addition, the table shows the accuracy of the estimation for different angular thresholds (3°, 5°, 7.5°, 11.25°, 22.5°, and 30°). A higher accuracy percentage at a given threshold means the estimated normal is closer to the ground truth within that angular tolerance. This allows for a comprehensive evaluation of the performance across various levels of precision.
read the caption
Table 1: Quantitative comparison on surface normal estimation. We report mean and median angular errors, as well as accuracies within different angular thresholds from 3°3°3\degree3 ° to 30°30°30\degree30 °.
In-depth insights#
Multi-Light Diffusion#
The core idea behind “Multi-Light Diffusion” is to leverage the power of diffusion models to generate multiple consistent images of a single object under various lighting conditions. This is crucial because object geometry and material properties are often ambiguous from a single image. By synthesizing multiple views with diverse lighting, the inherent under-constrained nature of the inverse rendering problem is mitigated. The approach uses a pre-trained diffusion model, fine-tuned on a synthetic dataset with varied lighting, to generate these consistent images. This synthetic dataset is key; carefully designed to provide ground truth data, including surface normals and material properties (albedo, roughness, metallic), enabling supervised training of the diffusion model. The resulting multi-light images serve as enriched input to a subsequent G-buffer model, which accurately predicts the object’s surface normals and materials. This two-stage process significantly enhances accuracy and robustness compared to traditional single-image approaches. The success hinges on the consistent and realistic generation of multi-light images that faithfully represent real-world lighting variations. The use of a synthetic dataset, while requiring effort in construction, simplifies the process of obtaining high-quality training data and allows for detailed control over lighting parameters. It allows researchers to generate consistent training data, a major advantage over using real-world images for this challenging task.
G-Buffer Prediction#
The G-Buffer prediction module is a critical component of the Neural LightRig framework, tasked with estimating surface properties (normals, albedo, roughness, metallic) from a set of multi-light images generated by a diffusion model. Its effectiveness hinges on the quality of the input multi-light images and the architecture’s ability to disentangle lighting and material effects. The use of a U-Net architecture is particularly well-suited for this task, given its efficiency in processing high-resolution images and its ability to learn spatial relationships between pixels. The network’s input consists of the original image concatenated with the multi-light images, leveraging both low-level and high-level features. The predicted G-buffer is then used for realistic relighting and other downstream tasks. Careful loss function design is crucial, employing cosine similarity loss for normals to enforce precise orientation estimation and MSE loss for albedo, roughness, and metallic to quantify material properties. Data augmentation techniques, including random degradation, intensity adjustments, and orientation perturbations, play a significant role in bridging the domain gap between synthetically generated training data and real-world images, improving robustness and generalization. The success of G-buffer prediction relies on effective conditioning of the diffusion model providing consistent and informative multi-light images. Overall, the G-Buffer Prediction section demonstrates a well-considered approach, combining a suitable architecture with appropriate loss functions and data augmentation to address the challenges inherent in inverse rendering.
LightProp Dataset#
The creation of the LightProp dataset is a critical contribution of this research. It directly addresses the limitations of existing datasets for multi-light image generation and material estimation by providing synthetic data with controlled lighting conditions. This approach allows for precise ground truth generation of both surface normals and PBR materials, crucial for training a robust model. The use of Blender and its Cycles renderer allows for a high degree of control over lighting, object properties, and scene setup. The careful curation process to select high-quality 3D models from Objaverse also ensures the dataset’s quality and reduces noise. The 80,000 object subset carefully chosen from Objaverse is significantly large, enabling thorough training and avoiding overfitting. Further, the dataset’s design allows for generating consistent, high-quality images for various viewpoints and lighting conditions. The balance between synthetic data control and high-quality visual realism make LightProp a valuable resource for advancing research in the field.
Ablation Experiments#
Ablation studies are crucial for understanding the contribution of individual components within a complex model. In the context of a research paper focusing on a novel method for accurate object normal and material estimation, ablation experiments would systematically remove or modify parts of the proposed model to assess their impact on the overall performance. Key aspects to investigate include the multi-light diffusion model’s architecture and its impact on the generated images’ quality and consistency. Examining the role of different conditioning strategies in the multi-light diffusion model is important, comparing techniques like simple concatenation vs. more sophisticated methods incorporating attention mechanisms. The number of generated multi-light images is another critical factor, assessing if more images improve accuracy and at what point diminishing returns occur. Furthermore, evaluating the efficacy of different augmentation techniques applied during training is vital, determining if data augmentation strategies reduce overfitting and improve the model’s generalization ability to unseen data. Finally, examining the impact of various loss functions and training hyperparameters on the model’s performance will help to uncover optimal settings and contribute to the broader understanding of the method’s strengths and limitations.
Future Directions#
Future research could explore extending Neural LightRig to handle more complex scenes containing multiple objects and intricate lighting interactions, moving beyond the single-object focus of the current work. Improving the robustness to noisy or low-quality input images is crucial, potentially through advanced denoising techniques or incorporating uncertainty estimation. Investigating alternative multi-light generation methods beyond diffusion models could unlock efficiency gains or superior image quality. The framework could be enhanced by integrating it with 3D reconstruction techniques to create complete 3D models, rather than just surface properties. Finally, exploring applications in new domains beyond the presented benchmarks, such as augmented reality, virtual reality, and robotics, would showcase the broader impact of accurate normal and material estimation.
More visual insights#
More on figures
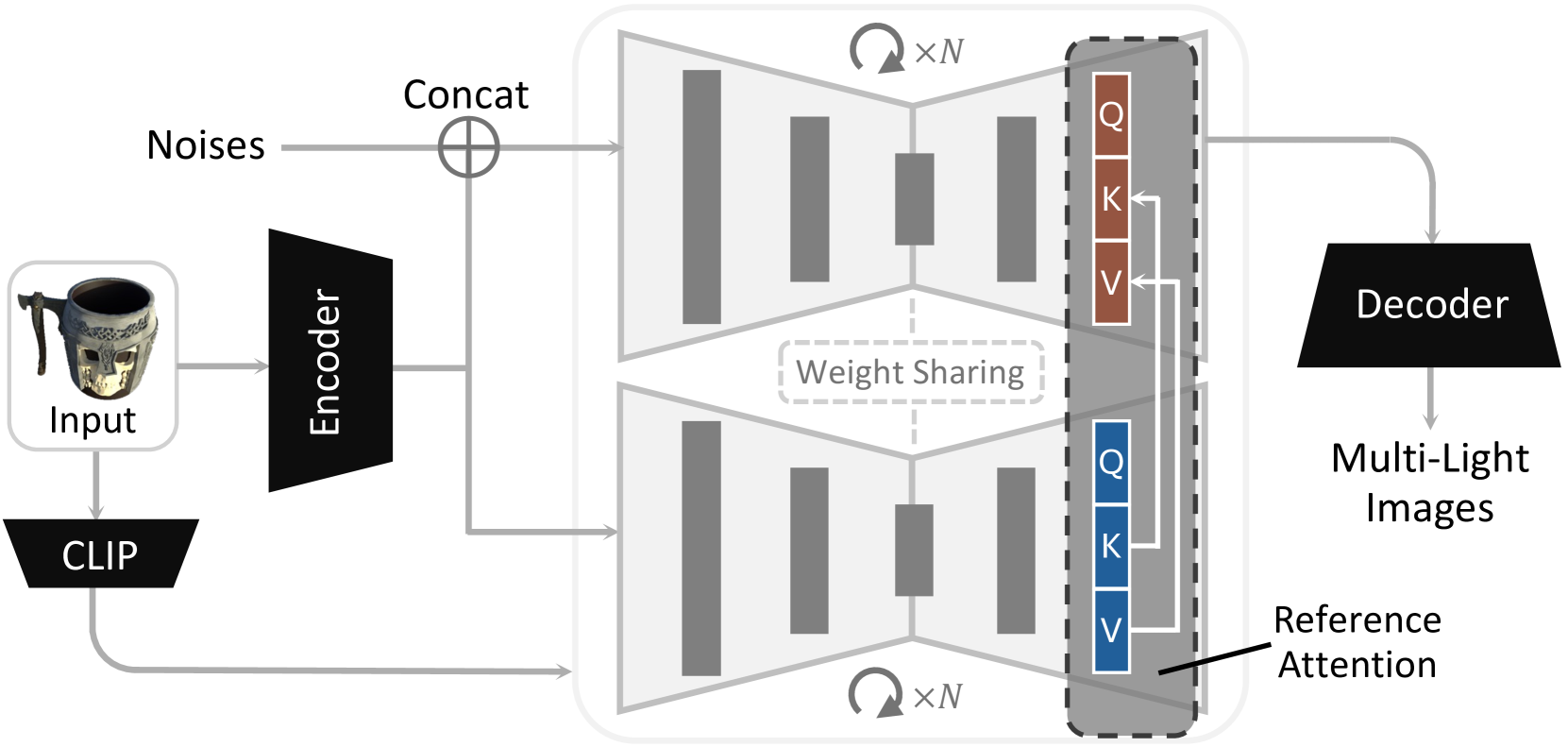
🔼 This figure illustrates the Neural LightRig framework. It begins with a single input image. This image is fed into a multi-light diffusion model, which generates multiple consistent images of the object, each illuminated from a different light source direction. These directions are explicitly tracked. This set of multi-light images, along with their corresponding lighting orientations, is then input to a large G-buffer model (a U-Net). This model simultaneously predicts the surface normal and physically-based rendering (PBR) material properties (albedo, roughness, and metallic) of the object from the varied lighting conditions. This allows for more accurate and robust estimation compared to methods using only a single image.
read the caption
Figure 2: Framework Overview. Multi-light diffusion generates multi-light images from an input image. These images with corresponding lighting orientations are then used to predict surface normals and PBR materials with a regression U-Net.

🔼 This figure illustrates the hybrid conditioning strategy used in the multi-light diffusion model. The input image isn’t simply added to the noise; it’s cleverly integrated using two methods: concatenation and reference attention. Concatenation merges the input image’s features directly with the noise latents, providing a straightforward way to incorporate image context. Simultaneously, reference attention enhances this integration. This mechanism allows the network to focus on relevant aspects of the input image while generating the multi-light versions. Specifically, the ‘queries’ within the noise-reduction process of the diffusion model attend to both the ‘keys’ and ‘values’ derived from both the noise and the input image, creating a refined, context-aware representation before generating the final image.
read the caption
Figure 3: Hybrid condition in multi-light diffusion. Input images are incorporated via concatenation with noise latents and enhanced through reference attention, where queries in the denoise stream attend to keys and values from both streams.

🔼 Figure 4 illustrates the LightProp dataset’s multi-light setup. A camera and multiple point light sources are arranged on a sphere surrounding a 3D object. The position of each light source is defined by its spherical coordinates (θ, φ), representing the polar and azimuthal angles respectively. These coordinates determine the direction of the light relative to the object, enabling the creation of diverse lighting conditions for each image in the dataset.
read the caption
Figure 4: Visualization of multi-light setup in LightProp. Camera and point lights are positioned on a sphere around the object. θ,φ𝜃𝜑\theta,\varphiitalic_θ , italic_φ are spherical coordinates to determine each light’s orientation relative to the object.

🔼 This figure showcases a qualitative comparison of surface normal estimation results from different methods, including DSINE, GeoWizard, Marigold, StableNormal, and the proposed method. The first two rows display results for images from real-world scenes (‘in-the-wild’), while the last two rows show results using images synthetically rendered from 3D models. The ground truth (G.T.) surface normals are provided for the 3D-rendered images, allowing for a direct comparison. This visualization helps to illustrate the relative strengths and weaknesses of each method in accurately estimating surface normals in both controlled and uncontrolled image settings.
read the caption
Figure 5: Qualitative comparison on surface normal estimation. Ground truth normals (G.T.) are provided for input images rendered from available 3D objects (the last two rows) and are omitted for in-the-wild images (the first two rows).

🔼 This figure displays a qualitative comparison of single-image relighting results produced by various methods, including the proposed Neural LightRig model. Each row shows results for different objects; the input image is presented alongside environment maps, demonstrating lighting conditions. Then, results from multiple existing methods and the proposed approach are shown, enabling visual comparison of the methods’ abilities to accurately predict the relighting given changes to the lighting condition. The ground truth relit image is also included for objective comparison.
read the caption
Figure 6: Qualitative comparison on single-image relighting.

🔼 This figure shows a qualitative comparison of PBR material estimation results from different methods. The left column showcases results from real-world images, while the right column uses images rendered from 3D models, allowing for ground truth comparison (G.T.). Each row displays the input image, followed by the results from various methods: RGB-X, Yi et al., IntrinsicAnything, and the proposed method. The results demonstrate the methods’ accuracy in estimating albedo, roughness, and metallic properties of the objects.
read the caption
Figure 7: Qualitative comparison on PBR material estimation. Ground truth materials (G.T.) are provided for input images rendered from available 3D objects (the right column) and are omitted for in-the-wild images (the left column).

🔼 This figure compares three different methods for incorporating the input image into the multi-light diffusion model: concatenation (Concat), reference attention (RA), and a combination of both. Each method generates nine multi-light images from a single input image, showing variations in lighting. The goal is to assess how effectively each approach leverages the input image to produce consistent and realistic multi-light images, ultimately improving the accuracy of downstream G-buffer estimation. Visual comparisons are shown for two examples: a vase and chess pieces, highlighting differences in color tones, texture, and overall fidelity.
read the caption
Figure 8: Visualization of different conditioning strategies in multi-light diffusion. Concat stands for concatenation. RA stands for reference attention.

🔼 This figure visualizes the impact of using varying numbers of multi-light images as input to the G-Buffer prediction model. The experiment compares four scenarios: using no additional multi-light images (0), three additional images (3), six additional images (6), and nine additional images (9). Each scenario’s output of albedo, roughness, metallic properties, and surface normals is shown, allowing for a direct comparison of the model’s performance and accuracy as the number of multi-light images increases.
read the caption
Figure 9: Visualization of using different numbers of multi-light images. We evaluate the G-Buffer prediction model with different numbers of novel-light images (00, 3333, 6666, and 9999) as conditions.

🔼 This figure shows the effects of the data augmentation strategy used in training the Neural LightRig model. It visually compares the results of using the augmentation strategy to the results without it. The results with augmentation show improved consistency and robustness in the generated images, indicating its efficacy in enhancing the model’s performance.
read the caption
Figure 10: Visualization of the augmentation strategy.

🔼 This figure showcases a failure case of the Neural LightRig model, highlighting its limitations. The model struggles to accurately estimate the albedo (surface color) when the input image contains extreme highlights or shadows, leading to inaccurate predictions. This emphasizes the challenges in robustly handling varied lighting conditions during inverse rendering tasks.
read the caption
Figure 11: Failure case.

🔼 This figure displays additional examples of the Neural LightRig method’s performance. For a variety of objects, it shows the input image, the generated multi-light images (multiple images of the object under varying lighting conditions), and the estimated surface normal, albedo, roughness, and metallic maps. These results demonstrate the model’s ability to accurately reconstruct the object’s geometry and material properties from a single image, even under challenging lighting conditions.
read the caption
Figure 12: More results of our method.

🔼 This figure displays additional results generated by the Neural LightRig model. It showcases the model’s ability to accurately estimate surface normals, albedo, roughness, and metallic properties from a single input image. For various objects, the figure presents the input image, the generated multi-light images, and the estimated surface properties. The results demonstrate the effectiveness of the proposed method in handling diverse objects and lighting conditions.
read the caption
Figure 13: More results of our method.

🔼 This figure displays additional examples of single-image relighting results achieved using the Neural LightRig method. It showcases the model’s ability to generate realistic relit images of various objects under different lighting conditions. Each row presents an input image followed by the relit images generated by the model, highlighting the diversity of lighting scenarios and the method’s capacity to maintain object details and visual fidelity across different lighting conditions. This figure supports the paper’s claim on the effectiveness of the method for single-image relighting.
read the caption
Figure 14: More single-image relighting results of our method.

🔼 This figure shows additional examples of single-image relighting results produced by the Neural LightRig method. It demonstrates the model’s ability to realistically relight various objects under diverse lighting conditions, showcasing the quality and consistency of the generated images.
read the caption
Figure 15: More single-image relighting results of our method.

🔼 This figure provides an extended qualitative comparison of surface normal estimation results. It showcases the performance of various methods (DSINE, GeoWizard, Marigold, StableNormal, and the proposed method) on diverse objects. Each row presents a different object, with the input image on the left followed by surface normal maps generated by each method and the ground truth normal map (G.T.) on the far right. Visual differences between the generated normal maps highlight the strengths and weaknesses of the different approaches in accurately capturing surface details and geometric features.
read the caption
Figure 16: More comparisons on surface normal estimation.

🔼 This figure provides additional qualitative comparisons of PBR material estimation results. It shows multiple example objects, each with the input image, outputs from several competing methods (Yi et al., IntrinsicAnything), and the output from the proposed Neural LightRig method, alongside the ground truth. The comparison allows for visual assessment of the accuracy of albedo, roughness, and metallic property estimation for different methods across various object types.
read the caption
Figure 17: More comparisons on PBR material estimation.

🔼 This figure provides additional qualitative comparisons of PBR material estimation results. It shows input images alongside the albedo, roughness, and metallic maps generated by different methods (Yi et al., IntrinsicAnything, and the proposed method, Neural LightRig). The ground truth (GT) is also included for comparison. The goal is to visually demonstrate the accuracy and effectiveness of the proposed method in recovering fine material details, particularly in challenging conditions, compared to other state-of-the-art techniques.
read the caption
Figure 18: More comparisons on PBR material estimation.
More on tables
| Method | Albedo PSNR ↑ | Albedo RMSE ↓ | Roughness PSNR ↑ | Roughness RMSE ↓ | Metallic PSNR ↑ | Metallic RMSE ↓ | Relighting PSNR ↑ | Relighting SSIM ↑ | Relighting LPIPS ↓ | Latency |
|---|---|---|---|---|---|---|---|---|---|---|
| RGB ↔ X [57] | 16.26 | 0.176 | 19.21 | 0.134 | 16.65 | 0.199 | 20.78 | 0.8927 | 0.0781 | 15s |
| Yi. et al [54] | 21.10 | 0.106 | 16.88 | 0.180 | 20.30 | 0.144 | 26.47 | 0.9316 | 0.0691 | 5s |
| IntrinsicAnything [8] | 23.88 | 0.078 | 17.25 | 0.172 | 22.00 | 0.134 | 27.98 | 0.9474 | 0.0490 | 2min |
| DiLightNet [56] | - | - | - | - | - | - | 22.68 | 0.8751 | 0.0981 | 30s |
| IC-Light [60] | - | - | - | - | - | - | 20.29 | 0.9027 | 0.0638 | 1min |
| Ours | 26.62 | 0.054 | 23.44 | 0.085 | 26.23 | 0.109 | 30.12 | 0.9601 | 0.0371 | 5s |
🔼 This table presents a quantitative comparison of different methods for estimating physically-based rendering (PBR) material properties (albedo, roughness, metallic) and performing single-image relighting. It compares the performance of several state-of-the-art techniques, including the proposed method, using metrics like Peak Signal-to-Noise Ratio (PSNR) and Root Mean Squared Error (RMSE) for material estimation, and PSNR, Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and average processing time for relighting. Lower RMSE values and higher PSNR, SSIM values indicate better performance.
read the caption
Table 2: Quantitative comparison on PBR materials estimation and single-image relighting.
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Concatenation | 19.32 | 0.8597 | 0.0909 |
| Reference Attention | 19.87 | 0.8691 | 0.0829 |
| Concatenation + Reference Attention | 20.01 | 0.8718 | 0.0815 |
🔼 This table presents a comparison of different conditioning strategies used in the multi-light diffusion model. It shows the impact of using concatenation, reference attention, and a combination of both on the performance of the model in terms of PSNR, SSIM, and LPIPS scores. This helps in understanding which strategy is most effective for generating high-quality multi-light images for subsequent G-buffer prediction.
read the caption
Table 3: Effects of condition strategies in multi-light diffusion.
| Number of Light Images | Albedo PSNR ↑ | Albedo RMSE ↓ | Roughness PSNR ↑ | Roughness RMSE ↓ | Metallic PSNR ↑ | Metallic RMSE ↓ | Normal MAE ↓ | Normal 5° ↑ | Normal 7.5° ↑ | Normal 11.25° ↑ | Normal 22.5° ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22.22 | 0.082 | 20.99 | 0.104 | 18.56 | 0.136 | 7.563 | 45.846 | 61.425 | 76.948 | 95.488 |
| 3 | 23.72 | 0.068 | 23.89 | 0.075 | 20.66 | 0.106 | 4.763 | 68.344 | 80.896 | 89.959 | 97.928 |
| 6 | 23.82 | 0.068 | 24.19 | 0.072 | 20.64 | 0.106 | 4.275 | 72.777 | 83.997 | 91.730 | 98.312 |
| 9 | 23.90 | 0.067 | 24.36 | 0.069 | 20.74 | 0.105 | 4.059 | 74.720 | 85.092 | 92.330 | 98.431 |
🔼 This table shows how the performance of the large G-buffer model (which predicts surface normals and material properties) changes depending on the number of multi-light images used as input. It presents quantitative results, such as Peak Signal-to-Noise Ratio (PSNR) and Root Mean Squared Error (RMSE) for albedo, roughness, metallic values, and Mean Angular Error (MAE) for surface normals, along with accuracy within specific angular thresholds (5°, 7.5°, 11.25°, 22.5°). The different numbers of input images allow for assessing the impact of additional lighting information on prediction accuracy.
read the caption
Table 4: Effect of the number of multi-light images on the performance of the large G-buffer model.
| Albedo PSNR ↑ | Albedo RMSE ↓ | Roughness PSNR ↑ | Roughness RMSE ↓ | Metallic PSNR ↑ | Metallic RMSE ↓ | Normal MAE ↓ | Normal 5° ↑ | Normal 7.5° ↑ | Normal 11.25° ↑ | Normal 22.5° ↑ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o augmentation | 21.69 | 0.087 | 20.46 | 0.110 | 16.61 | 0.179 | 7.080 | 52.235 | 67.032 | 80.115 | 94.802 |
| w/ augmentation | 22.36 | 0.081 | 21.39 | 0.099 | 18.81 | 0.135 | 6.342 | 55.893 | 70.326 | 82.848 | 96.230 |
🔼 This table presents a quantitative analysis of the impact of using data augmentation strategies during the training of the large G-buffer model. It compares the performance of the model trained with augmentations against a model trained without augmentations, evaluating the results across various metrics for Albedo, Roughness, Metallic, and Normal estimations. These metrics likely include things like Peak Signal-to-Noise Ratio (PSNR) and Root Mean Square Error (RMSE) to assess the quality and accuracy of the model’s predictions. The comparison helps determine the effectiveness of data augmentation in improving the overall robustness and accuracy of the model’s predictions.
read the caption
Table 5: Effect of augmentation strategy on the large G-buffer model.
Full paper#