↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing unified Multimodal Large Language Models (MLLMs) often struggle with complex architectures and training pipelines, limiting scalability. This is especially problematic when dealing with high-resolution images due to the long visual token sequences generated by current visual tokenizers. Moreover, integrating visual capabilities into large language models often disrupt the models’ pre-trained knowledge, affecting general perception and generalization capabilities.
This paper introduces SynerGen-VL, a new unified MLLM for both image understanding and generation using a simple next-token prediction framework. SynerGen-VL incorporates token folding to handle high-resolution images efficiently and vision experts to integrate visual capabilities into pre-trained LLMs. A progressive alignment pre-training strategy is used to preserve the LLM’s knowledge while incorporating visual features. Experimental results show that SynerGen-VL achieves strong performance on various benchmarks with a smaller model size compared to existing MLLMs.
Key Takeaways#
Why does it matter?#
Unified MLLMs for image understanding and generation are trending, but face challenges like training complexity and limited scalability. This paper’s novel architecture and training strategy offers a simpler, more efficient approach, potentially influencing future MLLM development and opening new research avenues in multimodal learning and high-resolution image processing within LLMs.
Visual Insights#

🔼 This figure provides a comparison of different unified Multimodal Large Language Models (MLLMs) architectures designed for both image understanding and generation tasks. The architectures are categorized into two groups: (a) through (d), which employ complex designs involving external diffusion models, distinct training objectives, or specialized encoders, and (e), which represents encoder-free unified MLLMs. The encoder-free approach (e) is highlighted for its simplicity, utilizing a shared next-token prediction framework for both understanding and generation, and offering advantages in scalability and data distribution.
read the caption
Figure 1: Comparison among exemplary unified MLLMs for synergizing image understanding and generation tasks. Compared with methods (a)∼similar-to\sim∼(d) that incorporate complicated designs of model architectures, training methods, and the use of external pretrained diffusion models, (e) encoder-free unified MLLMs adopt a simple design that uses the simple next token prediction framework for both images understanding and generation tasks, allowing for broader data distribution and better scalability.
| Task | #Sam. | Datasets | |
|---|---|---|---|
| Gen. | 667M | LAION-Aesthetics [67], Megalith [52], SAM [33], Objects365 [69], ImageNet-1k [18], | |
| S.1 | Und. | 667M | Laion-En [67], COYO [6], SAM [33] |
| Gen. | 170M | LAION-Aesthetics [67], Megalith [52], Objects365 [69], Unsplash [85], Dalle-3-HQ [3], JourneyDB [74], Internal Dataset | |
| 170M | Captioning: Laion-En [67], Laion-Zh [67], COYO [6], GRIT [60], COCO [40], TextCaps [71] | ||
| Detection: Objects365 [69], GRIT [60], All-Seeing [90] | |||
| OCR (large): Wukong-OCR [26], LaionCOCO-OCR [68], Common Crawl PDF | |||
| OCR (small): MMC-Inst [41], LSVT [79], ST-VQA [5], RCTW-17 [70], ReCTs [106], ArT [13], SynthDoG [32], ChartQA [53], CTW [104], DocVQA [15], TextOCR [73], | |||
| S.2 | Und. | 170M | COCO-Text [87], PlotQA [55], InfoVQA [54] |
🔼 This table summarizes the datasets used for visual alignment pre-training of SynerGen-VL, a multimodal large language model. The table is organized into stages (S.1 and S.2), tasks (image generation and understanding), and datasets. For each task and stage, the number of samples used is specified. Notably, all image understanding data from S.2 is also used in InternVL-1.5.
read the caption
Table 1: Summary of datasets used in Visual Alignment Pretraining. “S.1” and “S.2” denote the first and second stage. “Gen.” and “Und.” denote the image generation and understanding task. “#Sam.” denotes the number of total samples seen during training of each task at each stage. Note that all data used for image understanding in the second stage is also used in InternVL-1.5 [11].
In-depth insights#
Unifying MLLMs#
Unifying Multimodal Large Language Models (MLLMs) represents a significant advancement in AI, aiming to create a single model capable of both image understanding (e.g., captioning, VQA) and image generation (e.g., text-to-image synthesis). This contrasts with previous approaches that often relied on separate, specialized models for each task. A key advantage of unified MLLMs is their potential for synergy between understanding and generation, where improvements in one task can benefit the other. This is because a shared representation of visual and textual information is learned. However, challenges exist in training these unified models effectively. They require massive datasets and careful optimization to prevent interference with pre-existing language model knowledge. Moreover, supporting high-resolution images is computationally expensive due to the long sequences of visual tokens generated by current tokenizers. Innovative techniques like token folding are being explored to address these computational limitations. Despite these challenges, the progress in unifying MLLMs is promising, pointing towards more versatile and efficient multimodal AI systems in the future.
Vision Experts#
SynerGen-VL introduces vision experts, specialized modules within its architecture, to enhance image understanding and generation. These experts are designed as image-specific Feed-Forward Networks (FFNs) within the Multimodal Mixture-of-Experts (MMoE) structure. Instead of extensively modifying the pre-trained Large Language Model (LLM), vision experts are aligned through a two-stage pretraining process. This approach minimizes disruption to the LLM’s existing knowledge base, preserving its general perception and generalization capabilities while integrating visual expertise. By dedicating separate parameters for image representation, SynerGen-VL efficiently processes high-resolution images and supports synergistic image understanding and generation tasks. The progressive alignment pretraining ensures the model effectively learns visual concepts without compromising the LLM’s core strengths.
Token Folding#
Token Folding introduces a novel approach to handling high-resolution images within the memory constraints of LLMs. By downsampling visual token sequences through a hierarchical structure, SynerGen-VL efficiently processes detailed images without exceeding capacity. This mechanism compresses the image representation, making it suitable for LLM processing. Crucially, the subsequent unfolding process ensures that fine-grained image details are preserved for tasks like generation. This innovative folding-unfolding strategy enhances both understanding and generation capabilities, demonstrating a potent solution for high-resolution image processing in MLLMs.
Two-Stage Align#
The two-stage alignment strategy in SynerGen-VL is crucial for effectively integrating visual capabilities into the pre-trained LLM while minimizing disruption to its existing knowledge. The first stage, using noisy web data, focuses on establishing a basic semantic understanding and aligning visual representations with the LLM’s representation space. This initial alignment provides a foundation for visual comprehension and generation. The second stage refines this alignment by using high-quality curated data, focusing on more complex image understanding and high-fidelity image generation. This progressive approach enables SynerGen-VL to learn intricate visual concepts and relationships while preserving the LLM’s general knowledge and reasoning abilities. The two-stage process allows for both efficient learning from diverse data sources and specialized refinement, resulting in a robust and versatile model capable of handling both understanding and generation tasks effectively.
Encoder-Free VL#
Encoder-free visual-language (VL) models represent a significant shift in multimodal learning, moving away from traditional architectures that rely on separate encoders for image and text. This approach simplifies the model design and facilitates a more unified understanding of visual and textual information. By directly processing image pixels or discrete visual tokens, encoder-free VL models bypass the need for pre-computed image features. This promotes better scalability and allows for end-to-end training, which can potentially lead to improved performance. Moreover, it opens up possibilities for more flexible and efficient cross-modal interaction. Despite these advantages, challenges remain in effectively handling high-resolution images and integrating visual capabilities into large language models while preserving their pre-trained knowledge. The development of techniques like token folding and progressive alignment pretraining shows promise in addressing these challenges and paving the way for more powerful and versatile encoder-free MLLMs.
More visual insights#
More on figures
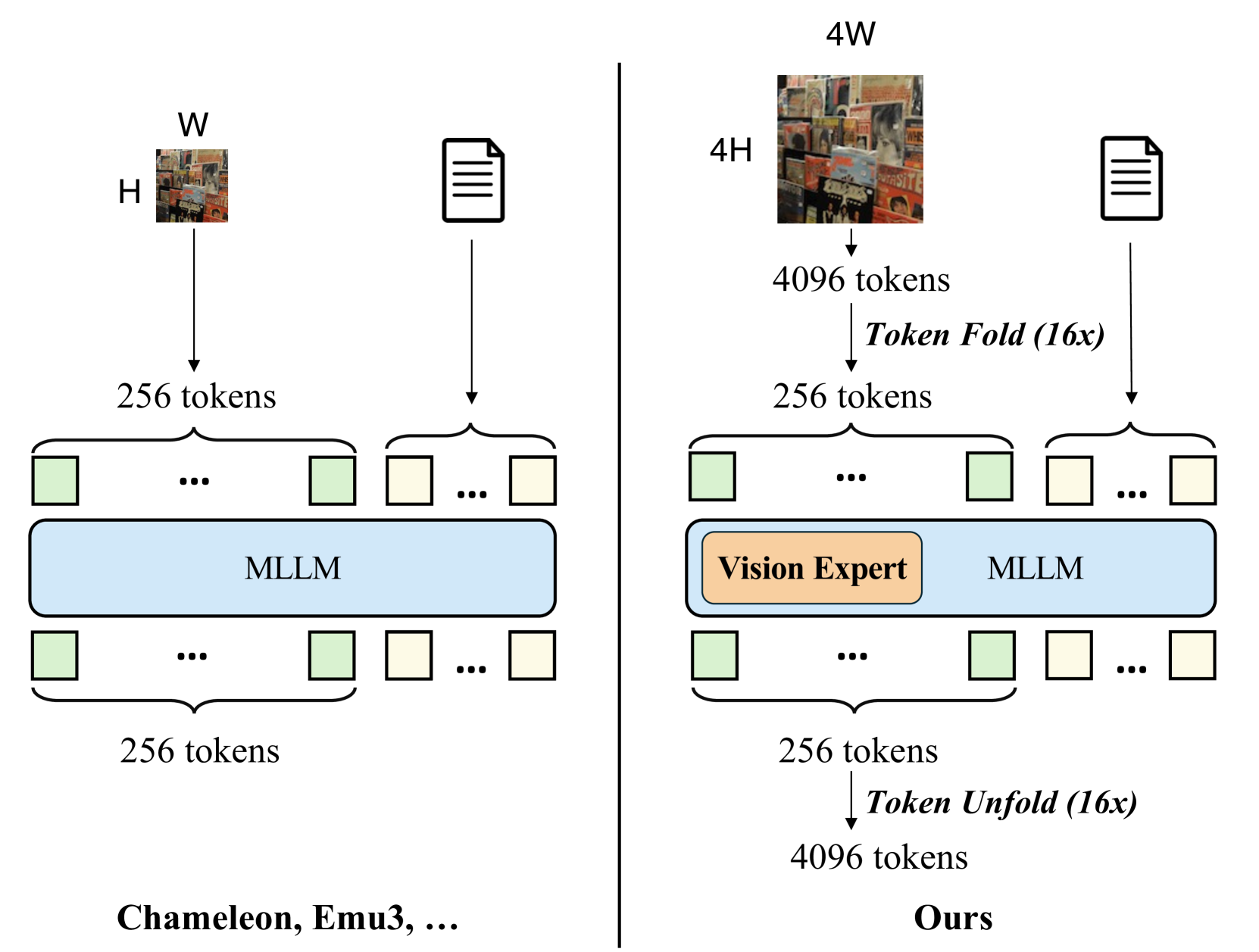
🔼 SynerGen-VL uses a token folding and unfolding mechanism and vision experts, which allows it to support higher resolution images compared to other encoder-free unified MLLMs with the same image context length. Other methods such as Chameleon and Emu3 lack these features. The diagram compares SynerGen-VL with other encoder-free unified MLLMs by illustrating the token processing stages in each architecture. It shows that SynerGen-VL can handle images with 4 times the resolution (4H x 4W, resulting in 4096 tokens after tokenization) while maintaining the same input context length for the MLLM (256 tokens) as other models that work with lower resolution images (H x W, 256 tokens after tokenization). SynerGen-VL incorporates a token folding mechanism to compress the visual token sequence (from 4096 to 256 tokens), effectively reducing its length, and it employs a shallow autoregressive transformer head to reconstruct detailed image sequences during generation using a token unfolding mechanism (from 256 to 4096 tokens). Additionally, SynerGen-VL introduces Vision Expert MLLMs to enhance visual capabilities within the framework.
read the caption
Figure 2: Comparision between SynerGen-VL and previous encoder-free unified MLLMs. SynerGen-VL adopts a token folding and unfolding mechanism and vision experts to build a strong and simple unified MLLM. With the same image context length, SynerGen-VL can support images of much higher resolutions, ensuring the performance of both high-resolution image understanding and generation.

🔼 SynerGen-VL is a unified MLLM capable of image understanding and generation through next-token prediction. It represents images and text as discrete tokens, processed by an LLM enhanced with text and vision expert FFNs. To handle high-resolution images, it uses a token folding mechanism, reducing the input sequence length, and a shallow autoregressive Transformer head unfolds the tokens for image generation.
read the caption
Figure 3: Overview of the proposed SynerGen-VL. The image and text are represented as discrete tokens, and modeled with a single LLM and unified next-token prediction paradigm. Text and vision expert FFNs are introduced to incorporate visual capabilities into the pretrained LLM. To support processing high-resolution images, the input image token sequence is folded to reduce its length, and unfolded by a shallow autoregressive Transformer head to generate images.

🔼 This figure, located in Section 5.3 (Analysis of Relationship Between Image Generation and Understanding), visualizes the cosine similarity between visual features of image generation and understanding tasks across different layers of SynerGen-VL. The x-axis represents the layer depth, while the y-axis represents the cosine similarity. The plot shows high similarity in shallow layers, indicating shared representations. However, the similarity decreases significantly in deeper layers, suggesting a disentanglement of representations as the model processes information specific to each task.
read the caption
Figure 4: Cosine similarity of visual features between generation and understanding tasks across different layers. The representations of the image understanding and generation tasks are similar in shallow layers but disentagle in deeper layers.

🔼 This figure visualizes the attention maps of an encoder-free multimodal large language model (MLLM) for both image understanding and generation tasks. The model uses a token folding mechanism, where each token represents a 2x4 rectangular area in the original image. The first two rows show attention maps for the understanding task, while the last two rows show attention maps for the generation task. Each visualization includes attention maps for four different layers of the MLLM (layers 4, 12, 20, and 24). Within each layer visualization, the red dot indicates the query token, and the blue dots indicate the tokens attended to by the query token. The darker the blue color, the higher the attention weight. Locality is observed at early layers, where tokens attend mostly to nearby tokens. Global interactions emerge at later layers. The attention visualization suggests that locality is more prominent in the generation task, while global context is more crucial for the understanding task.
read the caption
Figure 5: Attention map visualization of understanding and generation tasks. In the second and fourth rows, we visualize a query token (red) and its attended tokens (blue) in the input image. Each token corresponds to a horizontal rectangular area in the original image due to the 2×4242\times 42 × 4 token folding. Darker blue indicates larger attention weights.

🔼 Qualitative examples of 512x512 images generated by SynerGen-VL, showcasing its ability to generate images from various text prompts such as landscapes, character portraits, and object close-ups. The examples include detailed descriptions of the generated images within the figure.
read the caption
Figure 6: Qualitative results of image generation. The images are of size 512×512512512512\times 512512 × 512.
More on tables
| Model | #A-Param | POPE | MMB | MMVet | MMMU | MME | MME-P | MathVista | SEED-I | OCRBench |
|---|---|---|---|---|---|---|---|---|---|---|
| Understanding Only | ||||||||||
| Encoder-based | ||||||||||
| LLaVA-1.5 [43] | 7B | 85.9 | 64.3 | 31.1 | 35.4 | - | 1512 | - | 58.6 | - |
| Mini-Gemini-2B [38] | 3.5B | - | 59.8 | 31.1 | 31.7 | 1653 | - | 29.4 | - | - |
| DeepSeek-VL-1.3B [48] | 2B | 87.6 | 64.6 | 34.8 | 32.2 | 1532 | - | 31.1 | 66.7 | 409 |
| PaliGemma-3B [4] | 2.9B | 87.0 | 71.0 | 33.1 | 34.9 | 1686 | - | 28.7 | 69.6 | 614 |
| MiniCPM-V2 [100] | 2.8B | - | 69.1 | 41.0 | 38.2 | 1809 | - | 38.7 | 67.1 | 605 |
| InternVL-1.5 [11] | 2B | - | 70.9 | 39.3 | 34.6 | 1902 | - | 41.1 | 69.8 | 654 |
| Qwen2-VL [88] | 2B | - | 74.9 | 49.5 | 41.1 | 1872 | - | 43.0 | - | 809 |
| Encoder-free | ||||||||||
| Fuyu-8B (HD) [2] | 8B | - | 10.7 | 21.4 | - | - | - | - | - | - |
| EVE-7B [19] | 7B | 83.6 | 49.5 | 25.6 | 32.3 | 1483 | - | 25.2 | 61.3 | 327 |
| Mono-InternVL [51] | 1.8B | - | 65.5 | 40.1 | 33.7 | 1875 | - | 45.7 | 67.4 | 767 |
| Understanding & Generation | ||||||||||
| Encoder-based | ||||||||||
| Emu [78] | 14B | - | - | 36.3 | - | - | - | - | - | - |
| Emu2 [76] | 37B | - | 63.6 | 48.5 | 34.1 | - | 1345 | - | 62.8 | - |
| SEED-X [24] | 17B | 84.2 | 75.4 | - | 35.6 | - | 1436 | - | - | - |
| LWM [45] | 7B | 75.2 | - | 9.6 | - | - | - | - | - | - |
| DreamLLM [20] | 7B | - | 58.2 | 36.6 | - | - | - | - | - | - |
| Janus [92] | 1.3B | 87.0 | 69.4 | 34.3 | 30.5 | - | 1338 | - | 63.7 | - |
| Encoder-free | ||||||||||
| Chameleon [8] | 7B | - | - | 8.3 | 22.4 | - | - | - | - | - |
| Show-o [96] | 1.3B | 84.5 | - | - | 27.4 | - | 1233 | - | - | - |
| VILA-U [94] | 7B | 85.8 | - | 33.5 | - | - | 1402 | - | 59.0 | - |
| Emu3-Chat [91] | 8B | 85.2 | 58.5 | 37.2 | 31.6 | - | - | - | 68.2 | 687 |
| SynerGen-VL (Ours) | 2.4B | 85.3 | 53.7 | 34.5 | 34.2 | 1837 | 1381 | 42.7 | 62.0 | 721 |
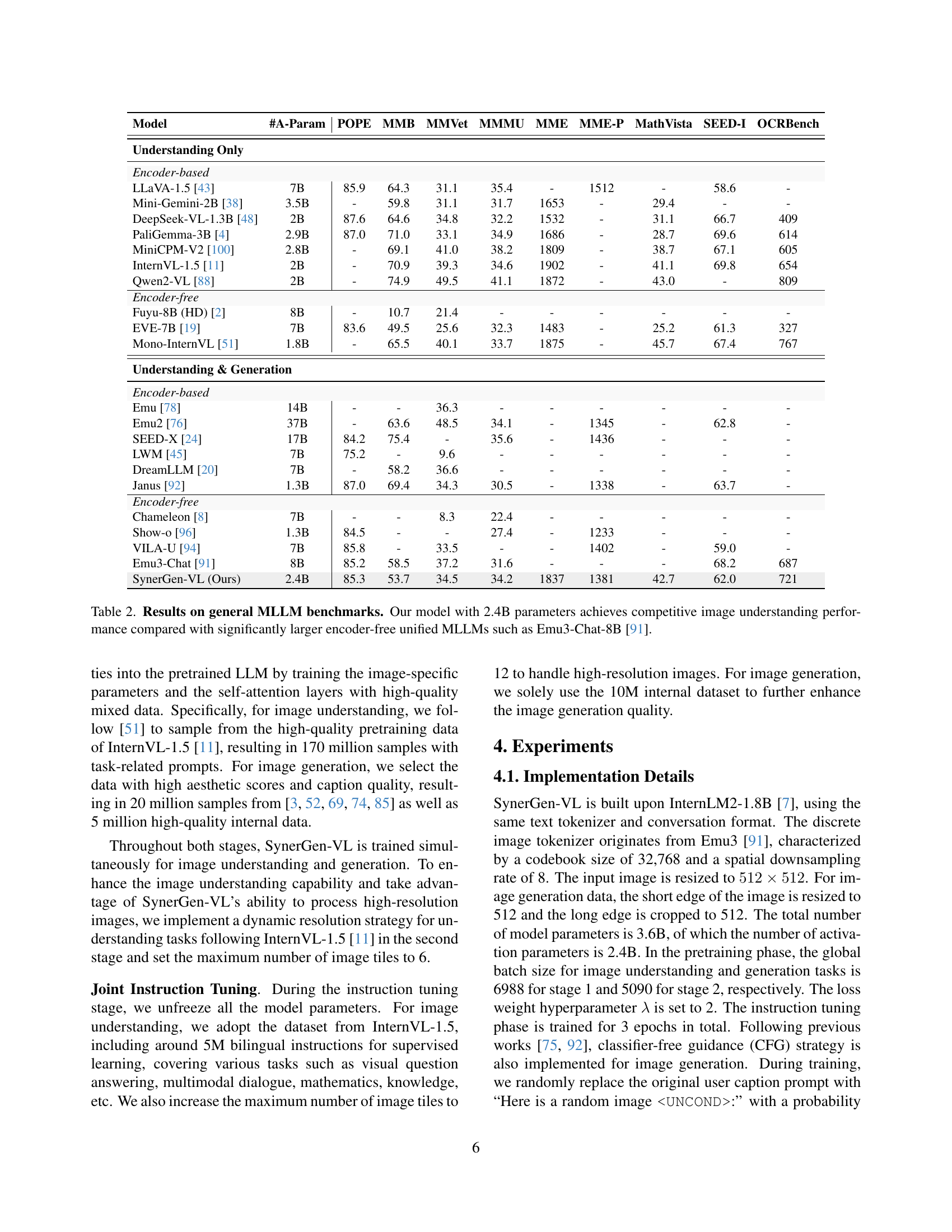
🔼 This table presents the results of various Multimodal Large Language Models (MLLMs) on a set of general benchmarks, evaluating their performance in image understanding tasks. SynerGen-VL, a novel encoder-free model with 2.4B parameters, is compared against other state-of-the-art MLLMs, both encoder-based and encoder-free, across various metrics such as POPE, MMB, MMVet, MMMU, MME, MME-P, MathVista, SEED-I, and OCRBench. The results demonstrate that SynerGen-VL achieves competitive performance compared to larger encoder-free models and even approaches the performance of some encoder-based methods, highlighting its efficiency and strong visual understanding capabilities.
read the caption
Table 2: Results on general MLLM benchmarks. Our model with 2.4B parameters achieves competitive image understanding performance compared with significantly larger encoder-free unified MLLMs such as Emu3-Chat-8B [91].
| Method | #A-Param | TextVQA | SQA-I | GQA | DocVQA | AI2D | ChartQA | InfoVQA |
|---|---|---|---|---|---|---|---|---|
| Understanding Only | ||||||||
| Encoder-based | ||||||||
| MobileVLM-V2 [14] | 1.7B | 52.1 | 66.7 | 59.3 | - | - | - | - |
| Mini-Gemini-2B [39] | 3.5B | 56.2 | - | - | 34.2 | - | - | - |
| PaliGemma-3B [4] | 2.9B | 68.1 | - | - | - | 68.3 | - | |
| MiniCPM-V2 [100] | 2.8B | 74.1 | - | - | 71.9 | - | - | - |
| InternVL-1.5 [11] | 2B | 70.5 | 84.9 | 61.6 | 85.0 | 69.8 | 74.8 | 55.4 |
| Encoder-free | ||||||||
| EVE-7B [19] | 7B | 51.9 | 63.0 | 60.8 | - | - | - | - |
| Mono-InternVL [51] | 1.8B | 72.6 | 93.6 | 59.5 | 80.0 | 68.6 | 73.7 | 43.0 |
| Understanding & Generation | ||||||||
| Encoder-based | ||||||||
| Emu2 [76] | 37B | 66.6 | - | 65.1 | - | - | - | - |
| LWM [45] | 7B | 18.8 | 47.7 | 44.8 | - | - | - | - |
| DreamLLM [20] | 7B | 41.8 | - | - | - | - | - | - |
| MM-Interleaved [82] | 13B | 61.0 | - | 60.5 | - | - | - | - |
| Janus [92] | 1.3B | - | - | 59.1 | - | - | - | - |
| Encoder-free | ||||||||
| Chameleon⋄ [8] | 7B | 4.8 | 47.2 | - | 1.5 | 46.0 | 2.9 | 5.0 |
| Show-o [96] | 1.3B | - | - | 61.0 | - | - | - | - |
| VILA-U [94] | 7B | 60.8 | - | 60.8 | - | - | - | - |
| Emu3-Chat [91] | 8B | 64.7 | 89.2 | 60.3 | 76.3 | 70.0 | 68.6 | 43.8 |
| SynerGen-VL (Ours) | 2.4B | 67.5 | 92.6 | 59.7 | 76.6 | 60.8 | 73.4 | 37.5 |
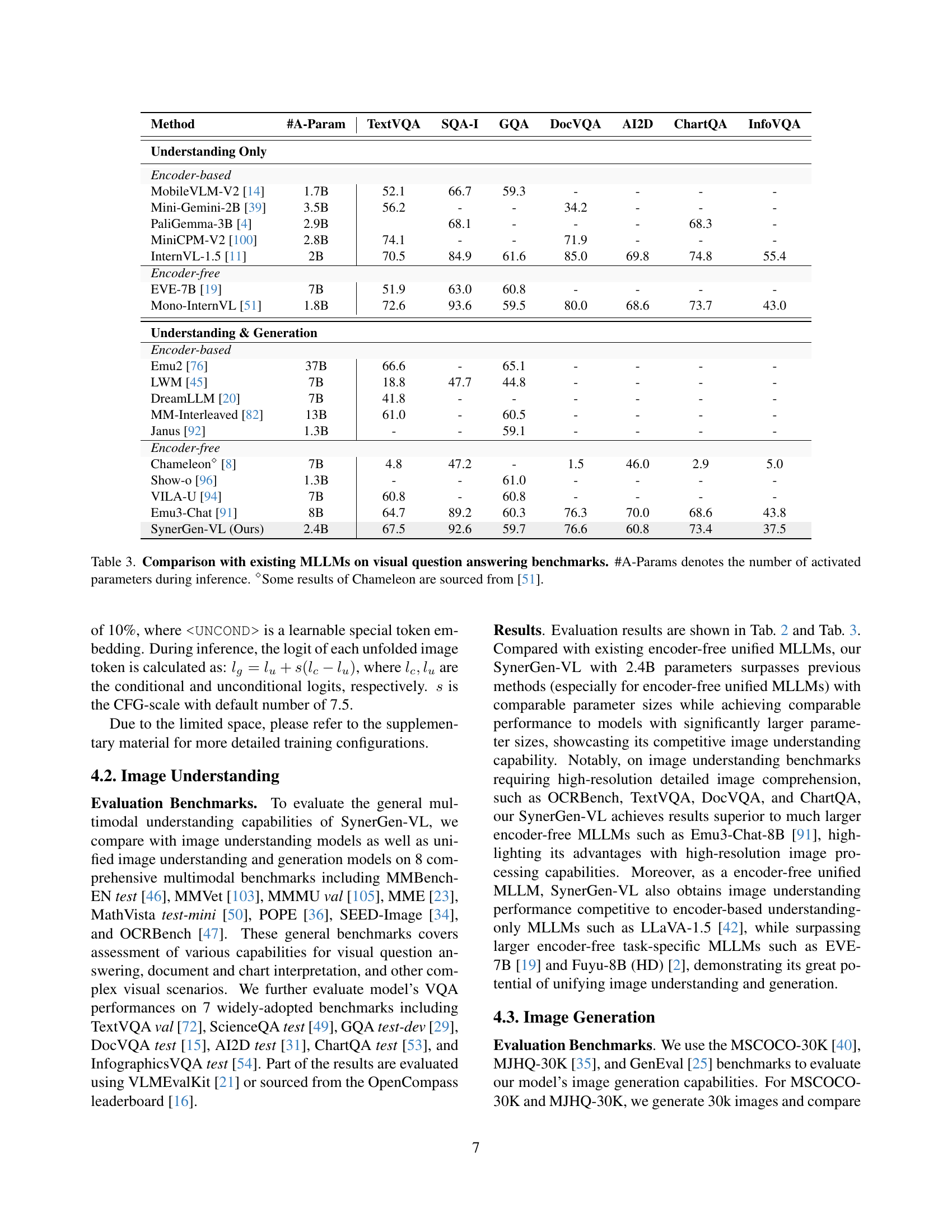
🔼 This table presents a comparison of SynerGen-VL with other Multimodal Large Language Models (MLLMs) on various visual question answering (VQA) benchmarks. The models are compared based on their performance on TextVQA, SQA-I, GQA, DocVQA, AI2D, ChartQA, and InfoVQA datasets. The table also lists the number of activated parameters during inference (#A-Params) to showcase the efficiency of SynerGen-VL in achieving strong performance with fewer activated parameters. Some of the results for the ‘Chameleon’ model were obtained from the Mono-Intern VL paper [51].
read the caption
Table 3: Comparison with existing MLLMs on visual question answering benchmarks. #A-Params denotes the number of activated parameters during inference. ⋄Some results of Chameleon are sourced from [51].
| Method | # A-Param | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall↑ |
|---|---|---|---|---|---|---|---|---|
| Generation Only | ||||||||
| LlamaGen [75] | 0.8B | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 | 0.32 |
| LDM [65] | 1.4B | 0.92 | 0.29 | 0.23 | 0.70 | 0.02 | 0.05 | 0.37 |
| SDv1.5 [65] | 0.9B | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | 0.43 |
| SDXL [61] | 2.6B | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 |
| PixArt-α [9] | 0.6B | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 |
| DALL-E 2 [64] | 6.5B | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 |
| Understanding & Generation | ||||||||
| SEED-X† [24] | 17B | 0.97 | 0.58 | 0.26 | 0.80 | 0.19 | 0.14 | 0.49 |
| Show-o [96] | 1.3B | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 |
| LWM [45] | 7B | 0.93 | 0.41 | 0.46 | 0.79 | 0.09 | 0.15 | 0.47 |
| Chameleon [8] | 34B | - | - | - | - | - | - | 0.39 |
| Emu3-Gen [91] | 8B | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 |
| Janus [92] | 1.3B | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 | 0.61 |
| SynerGen-VL (Ours) | 2.4B | 0.99 | 0.71 | 0.34 | 0.87 | 0.37 | 0.37 | 0.61 |
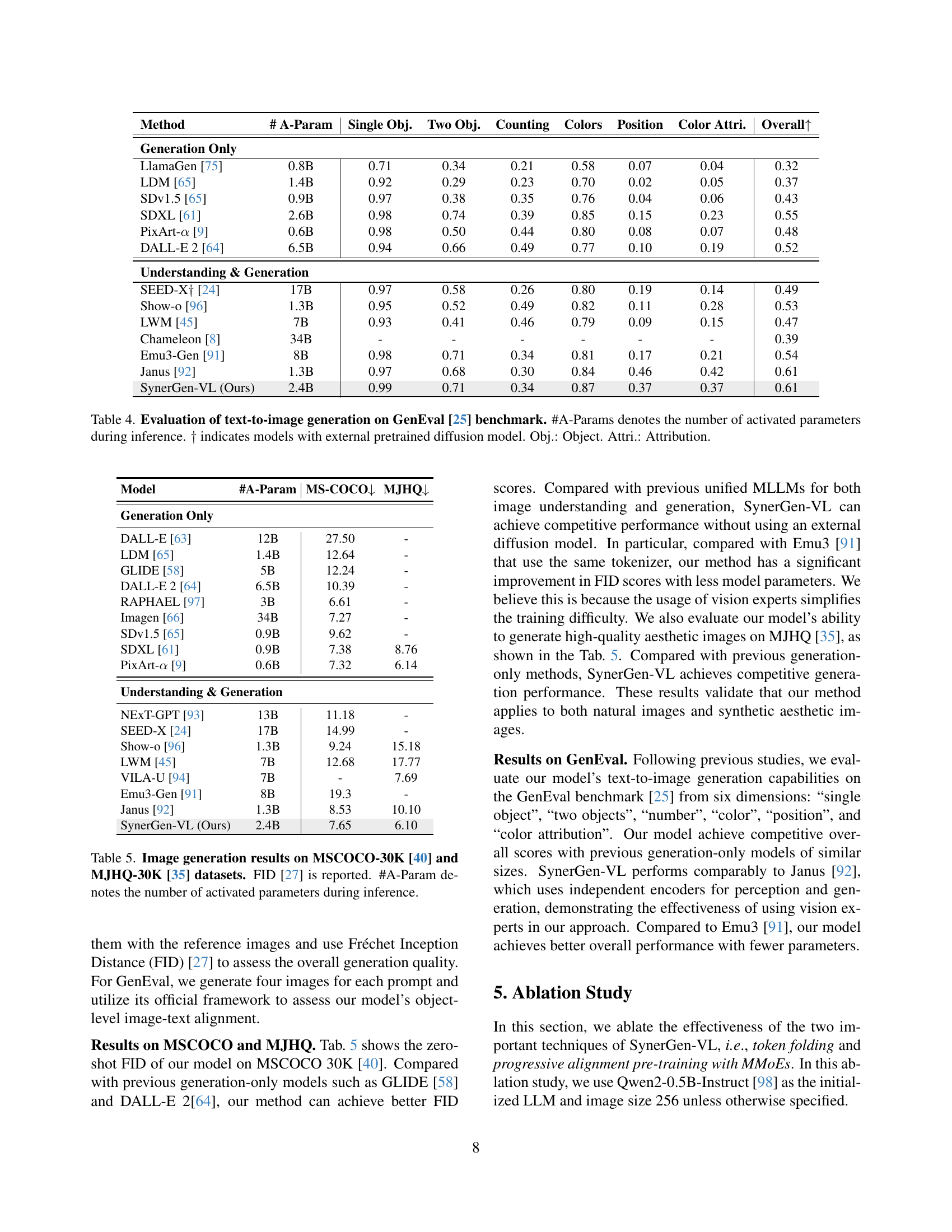
🔼 This table presents the evaluation results of various text-to-image generation models on the GenEval benchmark. It includes both single modality generation models and multi-modal models with image understanding and generation capabilities. The metrics used for evaluation cover aspects like single object, two objects, counting, color accuracy, positional accuracy, color attribute accuracy, and the overall score. The number of activated parameters during inference (#A-Params) is also provided for each model. Some models (marked with †) utilize external pre-trained diffusion models.
read the caption
Table 4: Evaluation of text-to-image generation on GenEval [25] benchmark. #A-Params denotes the number of activated parameters during inference. ††{\dagger}† indicates models with external pretrained diffusion model. Obj.: Object. Attri.: Attribution.
| Model | #A-Param | MS-COCO↓ | MJHQ↓ |
|---|---|---|---|
| Generation Only | |||
| DALL-E [63] | 12B | 27.50 | - |
| LDM [65] | 1.4B | 12.64 | - |
| GLIDE [58] | 5B | 12.24 | - |
| DALL-E 2 [64] | 6.5B | 10.39 | - |
| RAPHAEL [97] | 3B | 6.61 | - |
| Imagen [66] | 34B | 7.27 | - |
| SDv1.5 [65] | 0.9B | 9.62 | - |
| SDXL [61] | 0.9B | 7.38 | 8.76 |
| PixArt-α [9] | 0.6B | 7.32 | 6.14 |
| Understanding & Generation | |||
| NExT-GPT [93] | 13B | 11.18 | - |
| SEED-X [24] | 17B | 14.99 | - |
| Show-o [96] | 1.3B | 9.24 | 15.18 |
| LWM [45] | 7B | 12.68 | 17.77 |
| VILA-U [94] | 7B | - | 7.69 |
| Emu3-Gen [91] | 8B | 19.3 | - |
| Janus [92] | 1.3B | 8.53 | 10.10 |
| SynerGen-VL (Ours) | 2.4B | 7.65 | 6.10 |
🔼 This table presents a comparison of different models on image generation tasks, using the MSCOCO-30K and MJHQ-30K datasets. The Fréchet Inception Distance (FID) score is used to evaluate the quality of generated images, with lower FID scores indicating better quality. The table includes both models designed solely for image generation and unified models capable of both image understanding and generation. The number of activated parameters during inference (#A-Param) is also provided for each model, giving insight into the computational resources required.
read the caption
Table 5: Image generation results on MSCOCO-30K [40] and MJHQ-30K [35] datasets. FID [27] is reported. #A-Param denotes the number of activated parameters during inference.
| Model | TextVQA | GQA | DocVQA | AI2D | ChartQA | InfoVQA |
|---|---|---|---|---|---|---|
| w/o token folding | 18.7 | 45.3 | 14.7 | 42.0 | 20.9 | 18.7 |
| w/ token folding | 35.0 | 45.1 | 36.7 | 42.1 | 49.7 | 21.1 |
🔼 This table compares the performance of two models on six Visual Question Answering (VQA) benchmarks: TextVQA, GQA, DocVQA, AI2D, ChartQA, and InfoVQA. One model uses token folding, while the other does not. The purpose of this comparison is to demonstrate the effectiveness of token folding, specifically in scenarios that require understanding of high-resolution images or detailed image comprehension, such as in OCR-related tasks. Both models were trained using a subset of stage 2 understanding data, as outlined in Section 3.2 of the paper. The results show that the model with token folding achieves significantly better performance across all six VQA benchmarks, supporting the hypothesis that this technique improves the model’s ability to understand high-resolution image details. The metric used for evaluation is presumably accuracy, although the specific metric is not explicitly stated in the caption or surrounding text. The table also includes the scores of a baseline model ‘Qwen2-0.5B’ for comparison.
read the caption
Table 6: Comparison between models with and without token-folding on VQA benchmarks. The model with token folding demonstrates significant performance improvements with the same image token sequence length.
| Stage | Strategy | TextVQA | GQA | DocVQA | AI2D | ChartQA | InfoVQA | MMLU | CMMLU | AGIEVAL | MATH | MSCOCO |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline (Qwen2-0.5B) | - | - | - | - | - | - | 42.3 | 51.4 | 29.3 | 12.1 | - | |
| S.1 + S.2 | Full | 14.3 | 42.9 | 11.3 | 24.7 | 12.4 | 12.6 | 23.1 | 23.0 | 8.1 | 0.9 | 30.7 |
| S.1 only | Progressive | 0.1 | 13.0 | 0.2 | 0.3 | 0.0 | 0.0 | 42.3 | 51.4 | 29.3 | 12.1 | 28.3 |
| S.2 only | Progressive | 8.7 | 36.9 | 8.6 | 40.9 | 11.7 | 16.2 | 37.6 | 45.3 | 28.9 | 7.2 | 34.9 |
| S.1 + S.2 | Progressive | 13.2 | 41.2 | 11.4 | 41.9 | 12.8 | 17.0 | 39.3 | 48.2 | 26.2 | 8.9 | 20.2 |
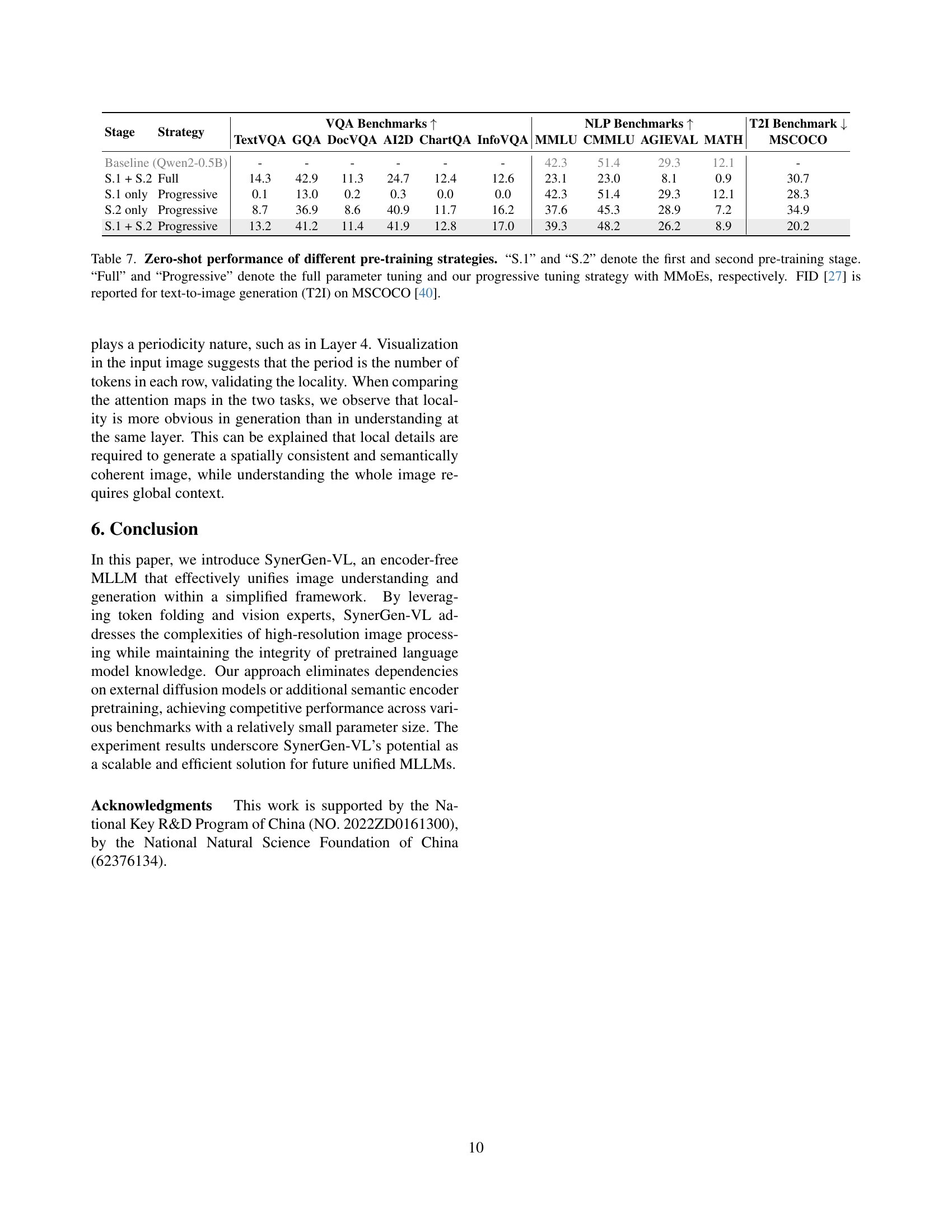
🔼 This table (Table 7) presents the zero-shot performance results of SynerGen-VL under different pre-training strategies, compared to a baseline model (Qwen2-0.5B-Instruct). The pre-training strategies involve different combinations of two stages (S.1 and S.2) and two tuning approaches (‘Full’ and ‘Progressive’). ‘Full’ refers to training all model parameters, while ‘Progressive’ denotes training with Multimodal Mixture-of-Experts (MMoEs), where only specific visual components are trained initially, followed by training the entire model. The evaluation metrics include various VQA benchmarks, NLP benchmarks (MMLU, CMMLU, AGIEVAL, MATH), and FID score for text-to-image generation on MSCOCO. The table aims to demonstrate the effectiveness of the proposed progressive alignment pre-training with MMoEs in preserving the pre-trained LLM’s knowledge while improving performance on visual tasks.
read the caption
Table 7: Zero-shot performance of different pre-training strategies. “S.1” and “S.2” denote the first and second pre-training stage. “Full” and “Progressive” denote the full parameter tuning and our progressive tuning strategy with MMoEs, respectively. FID [27] is reported for text-to-image generation (T2I) on MSCOCO [40].
| Configuration | Alignment Pre-training | Instruction |
|---|---|---|
| S.1 | S.2 | |
| Maximum number of image tiles | 1 | 6 |
| LLM sequence length | 4,096 | 8,192 |
| Use thumbnail | ✗ | ✓ |
| Global batch size (per-task) | 6,988 | 5,090 |
| Peak learning rate | 1e^{-4} | 5e^{-5} |
| Learning rate schedule | constant with warm-up | cosine decay |
| Weight decay | 0.05 | 0.05 |
| Training steps | 95k | 35k |
| Warm-up steps | 200 | 200 |
| Optimizer | AdamW | AdamW |
| Optimizer hyperparameters | \beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8} | \beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8} |
| Gradient accumulation | 1 | 1 |
| Numerical precision | bfloat16 | bfloat16 |
🔼 This table provides a detailed breakdown of the hyper-parameters employed during the two stages of alignment pre-training and the subsequent instruction tuning stage. The alignment pre-training aims to integrate visual capabilities into the pre-trained language model while minimizing disruption to its existing knowledge. Stage 1 focuses on establishing basic visual concept understanding and generating images that align with the language model’s representation space. Stage 2 refines this alignment using higher-quality data to enhance image-text alignment and improve image aesthetics. Instruction tuning then adapts the model to a wide range of downstream tasks by fine-tuning all parameters on a diverse set of instructions. The table details settings like maximum image tiles, sequence length, batch size, learning rate, and optimization strategies for each stage.
read the caption
Table 8: Hyper-parameters used in the alignment pre-training and instruction tuning stages.
Full paper#