↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
High-quality image generation is key in AI, but precisely editing these images remains a challenge. Existing methods struggle to isolate specific features, leading to unwanted changes in other image areas. This makes it hard to do things like changing a person’s smile without affecting their other facial features, or changing an image’s style without altering the content. Rectified flow transformers, like Flux, produce high-quality images, but existing editing techniques often don’t work well with them. This makes precise editing difficult within this powerful class of generative models. Existing works can also require long training hours for edit-per-domain, making it not suitable for editing without retraining. Moreover, many of the state-of-the-art editing methods require manual mask inputs from users to identify editable parts of an image, which may not always be convenient and accurate. This work aims to propose a method that enables image editing without manual mask inputs. Existing methods also mainly focus on the editing capabilities within diffusion-based image generation models, where the rectified flow-based image generation is relatively unexplored. This work aims to bridge this gap and enables a method for editing images with high-fidelity generated with rectified flow models.
This paper introduces FluxSpace, a new method for editing images generated by flow transformers. It leverages the attention layers within these models to offer disentangled control over image features. Unlike previous methods, FluxSpace doesn’t require additional training and applies edits directly at inference time. It also allows both fine-grained adjustments (e.g., adding eyeglasses) and coarse edits (e.g. stylization) without requiring mask inputs, opening new possibilities for creative image editing and better disentanglement within rectified flow models. Quantitative and qualitative experiments demonstrate that FluxSpace preserves image identity better than state-of-the-art methods while achieving precise edits. The results also show that FluxSpace is both able to edit real and generated images, increasing its versatility in different tasks. The method allows a more flexible image editing method by introducing linear edit scale control within flow-based generative models, opening new directions for future research.
Key Takeaways#
Why does it matter?#
Disentangled image editing is crucial for responsible image manipulation. This work offers a scalable method within the powerful flow transformer architecture, allowing precise edits without retraining. It advances research in interpretable generative models, impacting areas like content creation & digital media authenticity, while raising important ethical considerations.
Visual Insights#

🔼 FluxSpace edits images based on text prompts without needing extra training or masks. It works across various subjects (people, animals, cars) and complex scenes (like streets). It allows disentangled edits, meaning edits are applied to only the intended areas without affecting other parts of the image. For example, changing a car to a truck is done by using the keyword ’truck'.
read the caption
Figure 1: FluxSpace. We propose a text-guided image editing approach on rectified flow transformers [14], such as Flux. Our method can generalize to semantic edits on different domains such as humans, animals, cars, and extends to even more complex scenes such as an image of a street (third row, first example). FluxSpace can apply edits described as keywords (e.g. “truck” for transforming a car into a truck) and offers disentangled editing capabilities that do not require manually provided masks to target a specific aspect in the original image. In addition, our method does not require any training and can apply the desired edit during inference time.
 |
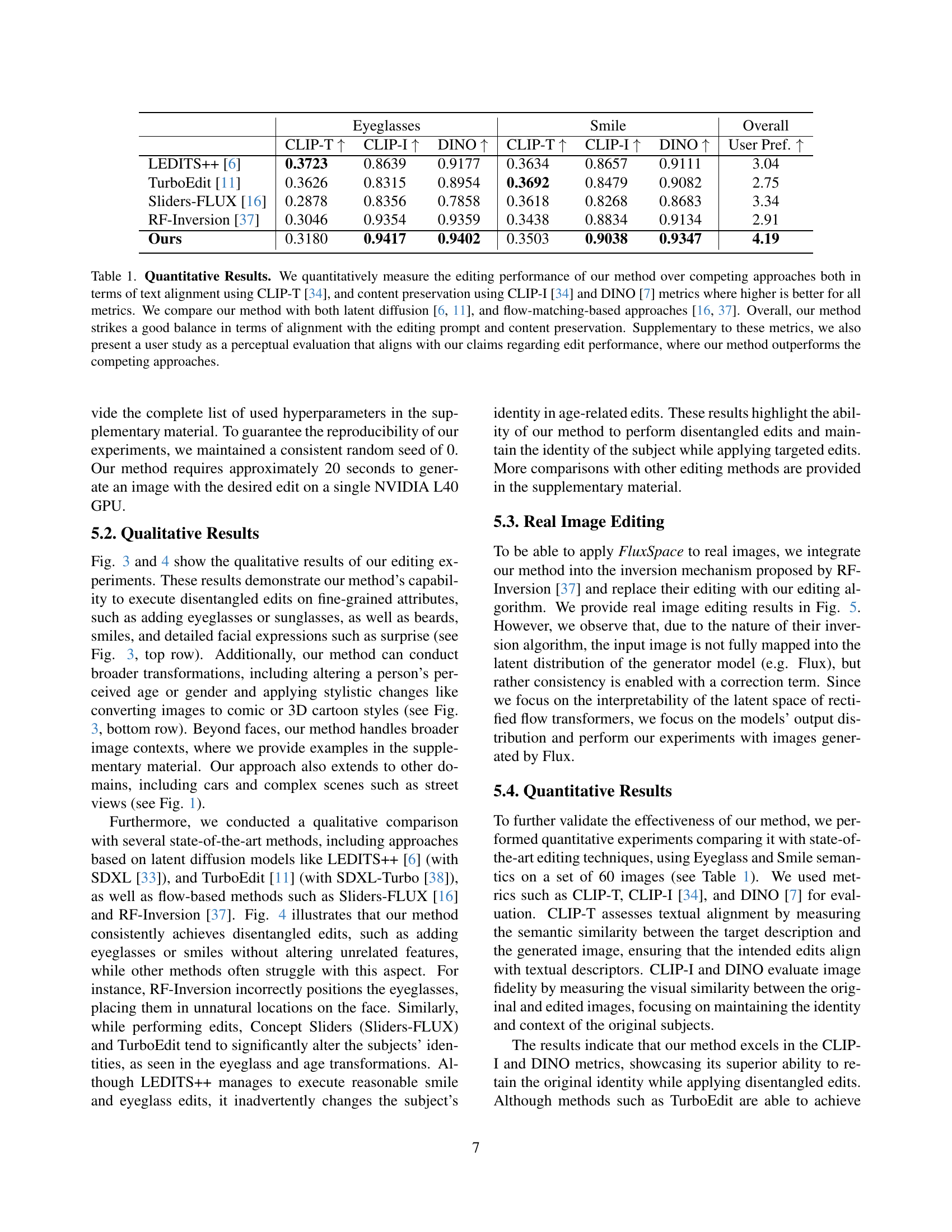
🔼 This table presents a quantitative comparison of FluxSpace with other state-of-the-art image editing methods, using CLIP-T, CLIP-I, and DINO metrics, and a user study to evaluate performance on tasks such as adding eyeglasses and smiles. It demonstrates FluxSpace’s superior ability to balance textual alignment with content preservation and maintain subject identity, compared to both latent diffusion and flow-matching based approaches.
read the caption
Table 1: Quantitative Results. We quantitatively measure the editing performance of our method over competing approaches both in terms of text alignment using CLIP-T [34], and content preservation using CLIP-I [34] and DINO [7] metrics where higher is better for all metrics. We compare our method with both latent diffusion [6, 11], and flow-matching-based approaches [16, 37]. Overall, our method strikes a good balance in terms of alignment with the editing prompt and content preservation. Supplementary to these metrics, we also present a user study as a perceptual evaluation that aligns with our claims regarding edit performance, where our method outperforms the competing approaches.
In-depth insights#
Rectified Flows#
Rectified flows introduce a novel approach to generative modeling by defining straight-line paths between noise and data distributions. This contrasts with diffusion models’ more complex trajectories. By predicting flow velocity, rectified flow models, such as Flux, efficiently learn the mapping between these distributions. This approach simplifies training and facilitates high-fidelity image generation. The flow-matching objective ensures optimal trajectory estimation, crucial for accurate image synthesis. Furthermore, rectified flows’ architecture, particularly the use of transformers, allows for effective integration of textual and visual information, enabling semantically rich image editing. This architecture also contributes to the disentanglement of semantic features, opening doors for precise control over generated image content.
FluxSpace Editing#
FluxSpace editing introduces a novel approach to image manipulation within flow-matching transformers. By leveraging the representational power of attention layers, FluxSpace enables disentangled semantic editing, allowing for precise control over specific attributes without affecting unrelated image aspects. This capability facilitates both fine-grained edits like adding a smile and coarse-level modifications such as style changes. FluxSpace operates directly on the latent space of the model, avoiding the need for external masks or training procedures, thus offering a scalable and efficient editing framework.
Disentanglement#
Disentanglement in image editing refers to the ability to manipulate specific attributes (like eyeglasses, age, or smile) independently, without affecting other aspects of the image. This is crucial for precise and controlled image manipulation. Many generative models struggle with this, producing entangled edits where changing one attribute unintentionally alters others. Achieving true disentanglement requires a model to understand the underlying semantic structure of images, allowing it to isolate and modify chosen features. This often involves complex latent space manipulation, posing significant challenges for multi-step diffusion models which lack a structured latent space like GANs. Effective disentanglement enhances editing precision and creative control, opening doors for advanced image manipulation and synthesis.
Dual-Level Edits#
Dual-level editing empowers precise image manipulation. It combines both global transformations and fine-grained adjustments. This approach offers flexible control over image attributes and overall style. Global edits affect the entire image, ideal for stylization or large-scale changes. Fine-grained edits target specific features, enabling precise modifications like adding a smile or eyeglasses. This combination allows for a wider range of creative possibilities, bridging the gap between broad stylistic changes and detailed refinements. This dual approach makes it a versatile tool suitable for diverse image editing needs.
Ethical Concerns#
Disentangled image editing presents significant ethical challenges. While enabling creative expression, tools like FluxSpace raise concerns about misinformation and manipulation. The ability to create realistic yet fabricated content necessitates careful consideration of potential misuse. Deepfakes, manipulated evidence, and malicious editing could erode public trust and cause harm. Responsible development requires addressing these challenges. This involves transparency about capabilities, promoting media literacy to identify manipulated content, and potentially developing detection technologies. Open discussion and collaboration are crucial to navigate these complex issues and ensure these powerful tools are used ethically.
More visual insights#
More on figures

🔼 FluxSpace enables image editing in two ways: coarse and fine-grained. Coarse editing adjusts overall image appearance (like stylization) through pooled representations. Fine-grained editing allows for precise attribute changes using attention outputs.
read the caption
Figure 2: FluxSpace Framework. The FluxSpace framework introduces a dual-level editing scheme within the joint transformer blocks of Flux, enabling coarse and fine-grained visual editing. Coarse editing operates on pooled representations of base (cpoolsubscript𝑐𝑝𝑜𝑜𝑙c_{pool}italic_c start_POSTSUBSCRIPT italic_p italic_o italic_o italic_l end_POSTSUBSCRIPT) and edit (ce,poolsubscript𝑐𝑒𝑝𝑜𝑜𝑙c_{e,pool}italic_c start_POSTSUBSCRIPT italic_e , italic_p italic_o italic_o italic_l end_POSTSUBSCRIPT) conditions, allowing global changes like stylization, controlled by the scale λcoarsesubscript𝜆𝑐𝑜𝑎𝑟𝑠𝑒\lambda_{coarse}italic_λ start_POSTSUBSCRIPT italic_c italic_o italic_a italic_r italic_s italic_e end_POSTSUBSCRIPT (a). For fine-grained editing, we define a linear editing scheme using base, prior, and edit attention outputs, guided by scale λfinesubscript𝜆𝑓𝑖𝑛𝑒\lambda_{fine}italic_λ start_POSTSUBSCRIPT italic_f italic_i italic_n italic_e end_POSTSUBSCRIPT (b). With this flexible design, our framework is both able to perform coarse-level and fine-grained editing, with a linearly adjustable scale.

🔼 This figure showcases FluxSpace’s capabilities in performing a variety of edits on facial images. Examples of fine-grained edits include adding eyeglasses, sunglasses, and beards. It also demonstrates broader transformations like age and gender alteration, and stylistic changes such as applying comic or 3D cartoon effects. Importantly, the edits are disentangled, meaning they affect the desired attribute without altering other unrelated features, thereby preserving the original identity and characteristics of the face.
read the caption
Figure 3: Qualitative Results on Face Editing. Our method can perform a variety of edits from fine-grained face editing (e.g. adding eyeglasses) to changes over the overall structure of the image (e.g. comics style). As our method utilizes disentangled representations to perform image editing, we can precisely edit a variety of attributes while preserving the properties of the original image.

🔼 Qualitative comparison of image editing results with different methods. The figure shows a portrait of a man and compares how different editing techniques apply modifications like adding a smile, eyeglasses, or changing age. The methods compared are divided into latent diffusion-based (LEDITS++, TurboEdit) and flow-based (Sliders-FLUX, RF-Inversion). The comparison focuses on how well each method can disentangle the desired edit (e.g., adding glasses) from other facial features, while preserving the original identity of the person. The comparison suggests that the proposed method offers better results in preserving identity and applying the edits cleanly.
read the caption
Figure 4: Qualitative Comparisons. We compare our method both with latent diffusion-based approaches (LEDITS++ [6] and TurboEdit [11]) and flow-based methods (Sliders-FLUX [16] and RF-Inversion [37]) in terms of their disentangled editing capabilities. We present qualitative results for smile, eyeglasses, and age edits where our method succeeds over competing methods in both reflecting the semantic and preserving the input identity.

🔼 This figure showcases FluxSpace’s ability to edit real images by integrating it with the inversion mechanism of RF-Inversion. The top row displays the original input images, while the subsequent rows present edits for age and gender. The results highlight FluxSpace’s improved disentanglement compared to the baseline RF-Inversion, as it effectively applies the desired edits while better preserving the original identity and overall image structure, using identical inversion hyperparameters.
read the caption
Figure 5: Real Image Editing. By integrating FluxSpace on the inversion approach proposed by RF-Inversion [37], we extend our method for real image editing task. As we show qualitatively, our method achieves improved disentanglement over the performed edits compared to the baseline approach, where we use identical hyperparameters for the inversion task on both approaches.

🔼 This figure presents a series of ablation studies showcasing the impact of different hyperparameters within the FluxSpace framework on image editing results. Specifically, it examines how varying the coarse editing scale (λcoarse), fine-grained editing scale (λfine), masking coefficient (τm), and the timestep (t) at which editing begins influences the final edited image. Each row in the figure corresponds to a different hyperparameter being ablated, with each column showing the visual result of a different parameter value. This allows for a direct visual comparison of how each parameter contributes to the overall editing process and its effect on disentanglement and semantic accuracy.
read the caption
Figure 6: Ablation Study. We present ablations over the hyperparameters introduced within the FluxSpace framework. Specifically, we perform ablations on coarse editing scale λcoarsesubscript𝜆𝑐𝑜𝑎𝑟𝑠𝑒\lambda_{coarse}italic_λ start_POSTSUBSCRIPT italic_c italic_o italic_a italic_r italic_s italic_e end_POSTSUBSCRIPT, fine-grained editing scale λfinesubscript𝜆𝑓𝑖𝑛𝑒\lambda_{fine}italic_λ start_POSTSUBSCRIPT italic_f italic_i italic_n italic_e end_POSTSUBSCRIPT, masking coefficient τmsubscript𝜏𝑚\tau_{m}italic_τ start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT and timestep t𝑡titalic_t when the editing is initiated. For all ablations, we report qualitative results for changing values of the specified hyperparameters.

🔼 This figure shows an example of a user study setup for evaluating the quality of image edits. Participants are shown the original image alongside the edited version. They’re asked to rate the edit on a Likert scale from 1 to 5, where 1 represents ‘strongly disagree’ (unsatisfactory editing) and 5 represents ‘strongly agree’ (satisfactory editing). The provided example focuses on evaluating a ‘Smiling’ edit, assessing how well the edited image reflects the smiling expression while retaining the person’s original facial characteristics (hair, beard, clothing). This methodology helps evaluate both the effectiveness of the edit and the preservation of the subject’s identity.
read the caption
Figure 7: User Study Setup. We conduct our user study on unedited-edited image pairs. For each editing method, we provide the original image where the edit is not applied, with the edited image, and ask the users to rate the edit from a scale of 1-to-5. On the Likert scale that the users are asked to provide their preference on, 1 corresponds to unsatisfactory editing and 5 corresponds to a satisfactory edit.

🔼 This figure provides additional qualitative comparisons of FluxSpace with other editing methods, specifically Prompt2Prompt (with Null-Text Inversion) and PnP-Diffusion, which are based on Stable Diffusion. The comparisons highlight FluxSpace’s superior performance in achieving disentangled and semantically correct edits, while competing methods exhibit artifacts in edited results (e.g., ‘Eyeglasses’ edit) and significantly alter the subject’s identity (e.g., ‘Age’ edit). FluxSpace maintains better fidelity to the original image while effectively applying the desired edits.
read the caption
Figure 8: Additional Qualitative Comparisons. In addition to comparisons provided in the main paper, we provide additional comparisons with Prompt2Prompt [18] (with Null-Text Inversion [27]) and PnP-Diffusion [39], as Stable Diffusion based editing methods. As we demonstrate qualitatively, FluxSpace both achieves disentangled and semantically correct edits where competing methods contain artifacts in edited results (see the edit “Eyeglasses” for both methods), and significantly alter the subject identity (see “Age” edit).

🔼 This figure showcases additional results for gender editing, demonstrating FluxSpace’s success in both male-to-female and female-to-male transformations. Results are presented for both portrait images (preserving facial details) and complex scenes (editing only the human subject), highlighting the method’s ability to maintain subject identity and background details while disentangling the editing task.
read the caption
Figure 9: Gender Editing Results. We provide additional editing results for editing the gender semantics. As shown in the examples, our method succeeds in both male-to-female and female-to-male translations. We provide editing results on both portrait images, where our edits preserve the facial details, and edits on complex scenes where we succeed in only editing the human subject. Both in terms of preserving the identity of the subject and the background details, FluxSpace succeeds in the disentanglement editing task.

🔼 This figure presents additional qualitative results demonstrating FluxSpace’s ability to add sunglasses to images of people in both portrait and complex scenes. It highlights the method’s accurate targeting of the edit without needing an input mask. The first two rows show edits on portrait photos where the person is the primary subject, and the last two rows display edits on scenes with more complex backgrounds, further demonstrating that the method preserves background details while still applying the sunglasses to the human subjects.
read the caption
Figure 10: Sunglasses Editing Results. We provide additional qualitative results for the edit “adding sunglasses”. As we demonstrate on human subjects in both portrait images and more complex scenes, our editing method can accurately target where the edit should be applied without any input mask. We show the editing capabilities of FluxSpace both in images where the human subject is the main focus of the image (first two rows) and with human subjects as a part of a scene (last two rows). In both cases, our method succeeds in performing the desired edit and preserving the edit-irrelevant details.

🔼 This figure showcases FluxSpace’s ability to perform conceptual edits by altering the overall appearance of an image using abstract prompts like ‘fall’, ‘snow’, ‘sunny’, ‘cherry blossom’, ‘comics style’, ‘happy’, ‘anime style’, and ‘cinematic lighting’. The top row demonstrates content changes by correctly interpreting unedited image structures, as exemplified by the ‘cherry blossom’ edit, which accurately adds cherry blossoms to the existing trees. The bottom row shows the method’s capacity to alter image style and overall appearance through different artistic or lighting effects.
read the caption
Figure 11: Conceptual Editing Results. We provide editing results with abstract concepts, that affect the overall appearance of the image. Our method succeeds in performing edits that alter the content of the image (top row) by being able to interpret the structures in the unedited image (e.g. the trees on the back for the edit “cherry blossom”) and can change the style and overall appearance of the image (bottom row).
Full paper#