↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for customizing image generation models struggle with combining multiple personalized models, often leading to attribute entanglement or requiring extensive retraining. This necessitates separate training for each concept, hindering efficiency and scalability. The challenge lies in merging these models while maintaining the quality and distinctness of each individual concept.
LoRACLR addresses this by introducing a novel approach that merges multiple pre-trained LoRA models using a contrastive objective. This method aligns the weight spaces of individual LoRA models, ensuring compatibility while minimizing interference between concepts. LoRACLR achieves scalable model composition, producing high-quality images with multiple distinct concepts without additional fine-tuning or retraining. The results demonstrate significant improvements in visual quality and compositional coherence, showcasing the effectiveness of this method for high-quality multi-concept image synthesis.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to combining multiple pre-trained customization models for image generation, overcoming the limitations of existing methods. This significantly advances personalized image generation, enabling high-quality, multi-concept synthesis with minimal computational overhead. The proposed method is broadly applicable and opens up new avenues for research in efficient model composition and customization techniques.
Visual Insights#

🔼 This figure showcases the high-fidelity multi-concept image generation capabilities of the LoRACLR model. It presents several example images, each combining multiple distinct characters (e.g., celebrities like Messi, Taylor Swift, Brad Pitt) and artistic styles across diverse settings (e.g., a high-tech laboratory, a futuristic spaceship, a seashore). The key takeaway is LoRACLR’s ability to seamlessly merge these varied concepts without losing the individual character identities or visual quality. Each generated image demonstrates the successful integration of different concepts specified in the accompanying text prompt, highlighting the model’s strength in managing multiple attributes simultaneously.
read the caption
Figure 1: High-Fidelity Multi-Concept Image Generation. Examples illustrating LoRACLR’s ability to generate unified scenes with multiple distinct characters and styles across diverse settings. Each scene demonstrates LoRACLR’s capability to combine varied concepts seamlessly, preserving the original identities of each character, as seen in concepts.
 |
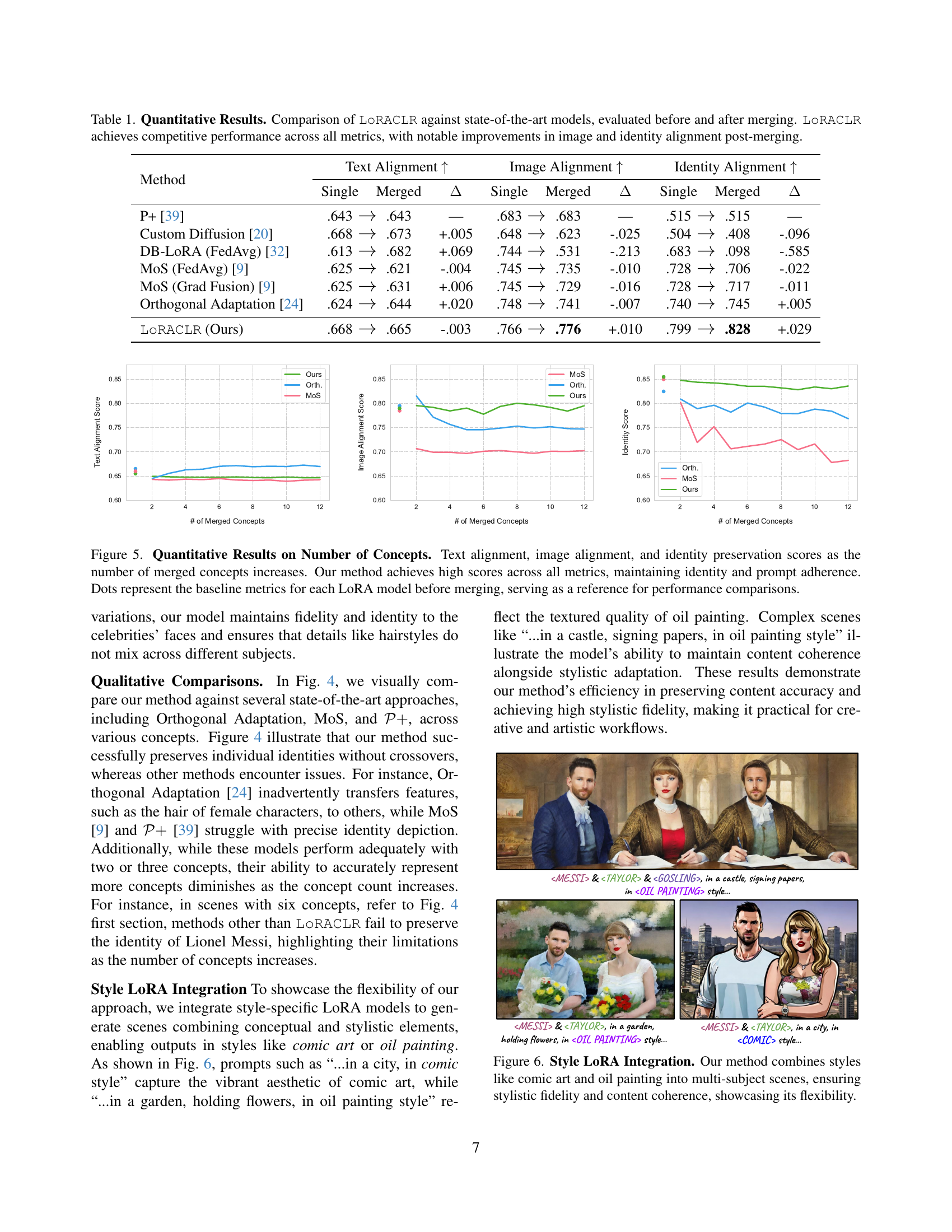
🔼 This table presents a quantitative comparison of the LoRACLR model against several state-of-the-art methods for multi-concept image generation. The models are evaluated on three metrics: Text Alignment, Image Alignment, and Identity Alignment, both before and after merging multiple concepts. LoRACLR demonstrates competitive performance across all metrics, showing particular improvement in Image and Identity Alignment after the merging process, indicating its ability to successfully integrate multiple concepts while preserving visual fidelity and identity.
read the caption
Table 1: Quantitative Results. Comparison of LoRACLR against state-of-the-art models, evaluated before and after merging. LoRACLR achieves competitive performance across all metrics, with notable improvements in image and identity alignment post-merging.
In-depth insights#
Multi-Concept Synthesis#
Multi-concept synthesis in image generation aims to combine multiple distinct concepts within a single image, such as different characters, objects, and styles. Current methods often struggle with attribute entanglement, where the features of one concept interfere with another, leading to unrealistic or incoherent results. LoRACLR addresses this challenge by employing a novel contrastive learning objective. This approach aligns the weight spaces of individual LoRA models (each representing a concept) while actively preventing interference between them. The key to success lies in the contrastive loss function, which encourages similar concepts to attract and dissimilar concepts to repel in the merged weight space. This strategy allows for the generation of high-fidelity images that preserve the unique qualities of each individual concept while maintaining overall coherence. The method’s efficiency and scalability are highlighted by its ability to process multiple concepts without additional training or substantial computational overhead. This makes LoRACLR an efficient and promising solution for multi-concept image generation.
Contrastive LoRA Merge#
The concept of “Contrastive LoRA Merge” presents a novel approach to combining multiple Low-Rank Adaptation (LoRA) models within a diffusion model. Instead of simply adding the weights, a contrastive loss function is introduced to learn a delta weight matrix that merges the models while preserving the distinctiveness of each individual concept. This contrasts with additive merging techniques, which can lead to interference and blurring of concepts. The contrastive loss encourages alignment of weights for the same concept while simultaneously pushing apart weights representing different concepts. This approach elegantly addresses the challenge of multi-concept generation in diffusion models, enhancing both quality and coherence by preventing feature entanglement. The contrastive loss, along with a regularization term, ensures both alignment and separation and enables efficient and scalable model composition. It’s a significant advance in personalized and context-rich image generation as it allows effective merging of pre-trained LoRA models without requiring further training, making it highly practical for various applications.
Scalable Model Compos.#
The concept of “Scalable Model Compos.” in the context of text-to-image generation using diffusion models speaks to the ability to efficiently combine multiple pre-trained models to generate images containing diverse concepts and styles. This is crucial because current approaches often struggle with combining multiple personalized models, leading to issues like attribute entanglement or the need for extensive retraining. A scalable solution would allow the seamless merging of many models without significant computational overhead or loss of individual model fidelity. Such a system would dramatically increase the creative potential and application range of personalized image synthesis. Key to scalability is the development of novel objective functions or training strategies that ensure the compatibility and distinctiveness of each constituent model. The ideal approach would allow for the combination of readily available pre-trained models, obviating the need for extensive retraining or access to original training data. This would accelerate progress in the field and contribute to democratizing access to cutting-edge image generation technologies.
Ablation Study & Limits#
An ablation study for a text-to-image model would systematically remove or alter components to understand their individual contributions. For example, removing the contrastive loss, changing the margin in the contrastive loss, or altering regularization strength would isolate the impact of each component on the model’s performance. Limits would focus on the model’s boundaries, such as the number of concepts it can effectively combine, the types of concepts it handles well (e.g., faces vs. objects), and any computational constraints on scalability. Analyzing scenarios with increasingly complex compositions would help define the practical limits. The study should consider both qualitative aspects (visual quality of generated images) and quantitative measures (e.g., metrics evaluating identity preservation and compositional coherence). By systematically varying parameters and observing the effects, researchers could determine the optimal configuration and pinpoint critical factors limiting performance. The results would provide a clear understanding of the model’s strengths and weaknesses, guiding future improvements and applications.
Future Work: LoRA++#
The proposed “LoRA++” could significantly advance multi-concept image generation. Building upon LoRACLR’s success, LoRA++ might explore more sophisticated contrastive loss functions to better disentangle and harmonize diverse concepts, potentially using techniques like triplet loss or other metric learning approaches. Furthermore, incorporating attention mechanisms within the contrastive framework could enable the model to selectively focus on relevant features from each LoRA, further reducing interference. Improving scalability to handle an even greater number of concepts is crucial, perhaps through hierarchical merging strategies or efficient dimensionality reduction techniques. Investigating the use of LoRA++ in different generative model architectures (beyond Stable Diffusion) would broaden its applicability and reveal its generalizability. Finally, thorough exploration of potential biases and ethical considerations arising from generating increasingly complex and personalized images should be a primary focus.
More visual insights#
More on figures

🔼 The figure illustrates the two-stage framework of LORACLR. Stage (a) shows individual pre-trained LoRA models generating concept-specific input-output pairs. Positive pairs represent aligned concepts from the same model, while negative pairs represent unrelated concepts from different models. Stage (b) details how these representations are merged into a single unified model (ΔW) using a contrastive objective function. This objective attracts positive pairs, preserving individual concept identities, and repels negative pairs, preventing interference between concepts. The result is a model capable of high-fidelity multi-concept image generation.
read the caption
Figure 2: Framework Overview. The framework comprises two main stages: (a) generating concept-specific representations with individual pre-trained LoRA models and (b) merging these representations into a unified model using a novel contrastive objective. In (a), each LoRA model produces input-output pairs (Xi,Yi)subscript𝑋𝑖subscript𝑌𝑖(X_{i},Y_{i})( italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_Y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) for distinct concepts (V1,V2,…,Vn)subscript𝑉1subscript𝑉2…subscript𝑉𝑛(V_{1},V_{2},\dots,V_{n})( italic_V start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_V start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_V start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ), establishing positive pairs (aligned concepts) and negative pairs (unrelated concepts). In (b), these representations are combined into a single model, ΔWΔ𝑊\Delta Wroman_Δ italic_W, to enable multi-concept synthesis. LoRACLR aligns attracting positive pairs to ensure identity retention and repelling negative pairs to prevent cross-concept interference.

🔼 This figure showcases the results of the LoRACLR model in generating images with multiple concepts. The top rows demonstrate LoRACLR’s ability to successfully combine several concepts (people, settings, styles) into a single, coherent scene while maintaining the individual identity and characteristics of each concept. Notice how different characters (e.g., Margot Robbie, Taylor Swift, LeBron James) maintain their unique features even when combined in various scenarios. The bottom row shows single-concept generation results from the merged model, demonstrating that it can also generate high-fidelity images for individual concepts without interference. The real images of the individual concepts used as input to the model are shown on the left for comparison.
read the caption
Figure 3: Qualitative Results. LoRACLR effectively combines different numbers of unique concepts across a wide range of scenes, producing high-fidelity compositions that capture the complexity and nuance of multi-concept prompts in diverse environments. LoRACLR preserves the identity of each concept, ensuring accurate representation in composite scenes while also maintaining fidelity in single-concept generation, as demonstrated in the last row. Real images from the original concepts are shown on the left for reference.

🔼 Figure 4 presents a comparison of multi-concept image generation results from LoRACLR and three other methods: Orthogonal Adaptation, Mix-of-Show, and Prompt+. Each row shows a different scene generated from a specific text prompt involving multiple concepts (e.g., multiple celebrities in various settings). The figure highlights LoRACLR’s ability to consistently preserve the individual identities of each subject within the composed image, unlike the other methods, which struggle with identity preservation and experience concept interference (where features of one concept bleed into another).
read the caption
Figure 4: Multi-Concept Comparison. Composite images generated by our method (LoRACLR) and competing methods (Orthogonal Adaptation [24], Mix-of-Show [9], Prompt+ [39]) for multi-concept prompts. Each row depicts a different scene defined by the text prompts. Our method consistently preserves individual identities, while others struggle with identity preservation and concept interference.

🔼 This figure displays graphs showing the performance of the LORACLR model and other baseline models on three metrics: text alignment, image alignment, and identity preservation. The x-axis represents the number of concepts merged, and the y-axis represents the score for each metric. The graphs show that LORACLR maintains high scores across all metrics as the number of merged concepts increases. The dots on the graphs represent the baseline performance of each individual LoRA model before merging, providing a benchmark for comparison.
read the caption
Figure 5: Quantitative Results on Number of Concepts. Text alignment, image alignment, and identity preservation scores as the number of merged concepts increases. Our method achieves high scores across all metrics, maintaining identity and prompt adherence. Dots represent the baseline metrics for each LoRA model before merging, serving as a reference for performance comparisons.

🔼 Figure 6 showcases the flexibility of the LORACLR method by demonstrating its ability to integrate style-specific LoRA models into multi-subject scenes. It shows how LORACLR successfully merges concepts and styles, resulting in images that maintain both stylistic fidelity (e.g., accurately representing the characteristics of comic art or oil painting) and content coherence (e.g., correctly portraying the subjects and their interactions within the scene). This demonstrates LORACLR’s capacity to handle complex compositions with diverse stylistic elements while retaining high visual quality.
read the caption
Figure 6: Style LoRA Integration. Our method combines styles like comic art and oil painting into multi-subject scenes, ensuring stylistic fidelity and content coherence, showcasing its flexibility.

🔼 Figure 7 showcases the model’s ability to generate images with non-human subjects. It demonstrates the seamless integration of diverse concepts, including animals (cats and dogs), everyday objects (tables, chairs, vases), and monuments (pyramids and rocks), into visually coherent and aesthetically pleasing scenes. This highlights the model’s versatility and capacity for complex composition, even beyond human subjects.
read the caption
Figure 7: Non-human subject generation. Our method effectively combines diverse concepts such as animals, objects (e.g., tables, chairs, vases), and monuments (e.g., pyramids, rocks) into cohesive and visually appealing scenes.

🔼 This ablation study investigates the effect of three hyperparameters (margin, λdelta, and the number of concepts) on the performance of the proposed model. The study uses four different numbers of concepts (2, 5, 8, and 12) to evaluate the model’s ability to maintain identity and visual coherence across varying complexity levels. Different values for margin and λdelta were tested to determine their optimal ranges for robust performance. The results reveal the optimal settings for achieving high-quality multi-concept image generation.
read the caption
Figure 8: Ablation Study on Margin, λdeltasubscript𝜆delta\lambda_{\text{delta}}italic_λ start_POSTSUBSCRIPT delta end_POSTSUBSCRIPT, and Concept Count. Effect of varying margin, λdeltasubscript𝜆delta\lambda_{\text{delta}}italic_λ start_POSTSUBSCRIPT delta end_POSTSUBSCRIPT, and number of concepts (2, 5, 8, 12) on identity preservation and visual coherence.

🔼 This figure shows the user interface of a study conducted to evaluate the performance of the proposed method in preserving identity and realism in generated images. Participants were shown pairs of images: a reference image of a celebrity and a corresponding generated image from the model. They were asked to rate the similarity of the generated image to the reference image on a scale of 1 to 5, where 1 represents ‘does not look similar’ and 5 represents ’looks very similar’. The study aimed to measure the accuracy and realism of the generated images compared to their reference counterparts.
read the caption
Figure 9: User Study Interface. Participants rated identity similarity between reference images and generated scenes, focusing on accuracy and realism.

🔼 Figure 10 presents a comparison of multi-concept image generation results between the proposed LORACLR method and the OMG method. Two example scenarios are shown: one with Chris Evans and Taylor Swift on a street, and another with Lawrence and Taylor Swift in a restaurant. The comparison highlights the limitations of OMG, which relies on a two-stage process involving an intermediate layout generation step before placing the subjects within the scene. This leads to errors in composition and subject placement. The figure shows that OMG has particular difficulty when subjects share similar characteristics, such as the two female subjects in the restaurant scene. In contrast, LORACLR directly generates the scene without the intermediate step, resulting in more seamless and accurate results.
read the caption
Figure 10: Comparison between our method and OMG for generating multi-concept scenes. OMG struggles with intermediate layout dependence and compositional errors, particularly with same-gender concepts, while our method achieves seamless and accurate results.

🔼 Figure 11 presents a qualitative comparison of image generation results across different methods for multi-concept scenes. The images demonstrate the ability of the proposed method, LORACLR, to generate images with multiple concepts (e.g., multiple people in various settings) while effectively capturing dynamic interactions between the concepts and maintaining complex stylistic elements. Examples include a bustling kitchen scene and a futuristic spaceship scene. These examples highlight LORACLR’s superior performance in terms of coherence and realism compared to alternative methods such as Orthogonal Adaptation, Mix-of-Show, and P+.
read the caption
Figure 11: Qualitative comparison of multi-concept scenes. Our method effectively captures dynamic interactions and complex stylistic elements, as seen in examples such as bustling kitchens and futuristic spaceships. It surpasses Orthogonal Adaptation, Mix-of-Show and 𝒫+limit-from𝒫\mathcal{P}+caligraphic_P + in coherence and realism.

🔼 Figure 12 presents more examples of images generated using the LORACLR method. It showcases the model’s ability to successfully combine multiple distinct concepts within a single image, even in complex and contrasting settings. The examples demonstrate the model’s ability to maintain the unique characteristics and styles of each individual concept while seamlessly integrating them into a coherent whole. The figure highlights the model’s ability to handle diverse scenarios such as operating rooms (medical setting), and crime scenes (noir detective setting), effectively blending the distinct visual styles appropriate for each context.
read the caption
Figure 12: Additional multi-concept image generation examples. Our method demonstrates superior integration of concepts and themes in diverse scenarios, such as operating rooms and detective noir settings, while maintaining stylistic fidelity.
Full paper#