↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Creating AI that can understand and navigate 3D spaces like humans do is a challenge. Current AI struggles to build a full understanding of their surroundings and plan complex actions. Most AI rely heavily on real-time sensory input, which limits their ability to anticipate and plan effectively. Bridging the gap between simply perceiving the world and truly understanding and interacting with it remains a key problem. Creating robust video generation to understand the scene is also a challenge.
GenEx tackles this by generating a complete, explorable 3D world from a single image. Imagine giving an AI a picture and it creates an entire virtual environment that it can then explore! It uses video generation, guided by user instructions or a language model (GPT), to let AI agents move through and interact with this world. This is important because it lets AI learn and practice complex navigation and decision-making in a safe, controlled setting. The system also utilizes sphere-consistent learning to refine video quality during transitions and rotations. It offers an approach to study how AI can learn like humans by building and refining mental maps of their surroundings, using its imagination to learn and plan.
Key Takeaways#
Why does it matter?#
This research bridges the gap between imaginative and real-world AI, allowing exploration of AI-generated environments. This offers a novel platform for embodied AI research, allowing the study of complex planning and decision-making in safe, controlled environments. It opens new research avenues for multi-agent interaction, 3D world generation from single images, and robust video generation, with potential implications for robotics, gaming, and virtual reality applications. It provides researchers with tools and methods to study human-like cognitive processes in simulated 360 environments, enabling exploration of how AI can learn and adapt in realistic yet synthetic worlds.
Visual Insights#

🔼 This figure showcases examples of the virtual environments used to train GenEx. The left example uses highly realistic city assets from Unreal Engine 5, while the right example demonstrates more stylized, animated assets from Unity. Leveraging these diverse environments and their physics engines allows for the creation of a robust and varied dataset for training the generative model. The use of game engines also enables precise control over the virtual camera, facilitating the collection of panoramic images and videos for training.
read the caption
Figure 1: Our data curation leverages physical engines, utilizing realistic city assets from UE5 and animated world assets from Unity.
| Model | Representation | FVD ↓ | MSE ↓ | LPIPS ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|---|---|---|
| Baseline | 6-view cubemaps | 196.7 | 0.10 | 0.09 | 26.1 | 0.88 |
| GenEx w/o SCL | panorama | 81.9 | 0.05 | 0.05 | 29.4 | 0.91 |
| GenEx | panorama | 69.5 | 0.04 | 0.03 | 30.2 | 0.94 |
🔼 This table compares the video generation quality of GenEx, a system for generating explorable worlds from single images, with a baseline model. The metrics used are Fréchet Video Distance (FVD), Mean Squared Error (MSE), Learned Perceptual Image Patch Similarity (LPIPS), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM). Lower values are better for FVD, MSE, and LPIPS, while higher values are better for PSNR and SSIM. The table shows that GenEx achieves higher quality video generation across all metrics, both with and without spherical-consistent learning (SCL). The models are evaluated using 6-view cubemap and panorama representations.
read the caption
Table 1: GenEx with high generation quality.
In-depth insights#
Generative Worlds#
Generative worlds represent a paradigm shift in AI, moving from static environments to dynamic, explorable spaces. This allows for unprecedented experimentation and learning, mirroring human cognitive processes of imagining and exploring possibilities. Key is the ability to generate 3D-consistent environments from minimal input, like a single image, opening doors to numerous applications. This advancement raises important questions about the interplay between imagination and embodiment, how agents can leverage generated observations for more informed decision-making, and the potential to enhance human cognitive abilities through immersive exploration. However, challenges remain, including bridging the gap between simulated and real worlds, ensuring ethical development, and tackling the complexities of dynamic conditions.
3D Exploration#
3D exploration represents a paradigm shift in scene understanding, moving beyond 2D image analysis to encompass spatial reasoning and interaction. GenEx enables this by generating navigable 3D environments from single images, empowering embodied AI agents to explore, learn, and interact within these spaces. This functionality could revolutionize fields like robotics, where agents can virtually navigate and manipulate objects before real-world deployment. Further, 3D exploration within GenEx facilitates active 3D mapping, allowing for the reconstruction of detailed scene geometry from limited viewpoints. This holds potential for applications like autonomous driving and virtual reality. The dynamic environment generation also opens exciting research avenues in reinforcement learning, where agents can learn optimal navigation policies in complex, evolving 3D spaces. GenEx’s approach could also contribute to more realistic and interactive gaming experiences.
Embodied AI#
GenEx empowers embodied AI by creating explorable, generative 3D worlds from single images. This bridges the gap between imagination and physical reality, enabling agents to learn through simulated interaction. Unlike prior work limited to static scenes or lacking physical grounding, GenEx supports dynamic exploration, informed decision-making, and even multi-agent scenarios. This offers potential for more robust and adaptable AI across diverse real-world applications like robotics and navigation, pushing beyond limitations of purely observational learning.
Loop Consistency#
Loop consistency is crucial for evaluating the robustness of generative video models, particularly in simulating long-range exploration. It assesses the model’s ability to maintain coherence and fidelity after traversing a closed-loop path. A key metric is the latent MSE between the initial and final frames, which quantifies drift. Minimizing drift is essential. GenEx utilizes spherical-consistency learning to enhance loop consistency. This technique mitigates discontinuities at panorama edges, ensuring seamless transitions and preserving visual fidelity during rotations. This robustness is crucial in applications like 3D mapping and navigation, where accumulating errors can significantly impact performance. Consistent loops demonstrate the model’s capacity for long-term planning and realistic world generation. The ability to return accurately to a starting point after complex movements underscores the effectiveness of GenEx in creating believable virtual environments.
World Transition#
World transition in GenEx centers on dynamic updates to the agent’s 360° view as it navigates. This process is driven by actions, including rotations and forward movement, generating new panoramic video frames. Key is the use of a spherical representation and spherical-consistent learning, ensuring visual coherence during transitions and preventing distortions. This approach enables exploration beyond the initial view, creating a continuous and dynamic experience within the generated world.
More visual insights#
More on figures

🔼 The figure shows three different representations of a 360° panoramic image: cubemap, equirectangular panorama, and sphere panorama. These are mathematically equivalent and can be converted from one to another. A cubemap represents the scene projected onto the six faces of a cube. An equirectangular panorama maps the scene onto a 2D plane, creating a distorted, wide-angle view. A sphere panorama represents the scene on the surface of a sphere. The choice of representation depends on the specific application. Cubemaps are commonly used in gaming and graphics, while equirectangular panoramas are often used for viewing and storing panoramic images. Sphere panoramas can be useful for certain types of image processing or visualization tasks.
read the caption
Figure 2: Three panorama representations that can be transformed into one another.

🔼 This figure illustrates the process of generating a 360° panoramic view from a single input image. A single view image is first warped, then inpainted using a diffusion model conditioned on the single image and a text description, resulting in the full 360 panorama.
read the caption
Figure 3: From single view to 360∘ panorama.

🔼 The figure visually illustrates the world transition process within the GenEx system. It begins with the last fully explored 360° panoramic view. An action is then taken which rotates the agent’s viewing direction (represented as a sphere). Based on this rotation and the previous panorama, a sequence of new panoramic views is generated, simulating forward movement and exploration in the imagined environment.
read the caption
Figure 4: We model the world transition as a panoramic video generation process. Given the last explored 360∘ panorama and an action that rotates the viewing sphere, the model produces a sequence of newly generated panoramic views

🔼 Figure 5 illustrates three distinct modes of exploration within the GenEx framework: Interactive Exploration, where users manually control the agent’s movement; GPT-assisted Free Exploration, where a GPT guides exploration to ensure high-quality, coherent video generation while preventing model collapse; and Goal-driven Navigation, where the agent follows GPT-generated instructions to navigate towards a specified goal within the generated environment. Each mode offers a unique way to interact with and explore the virtual world, catering to different levels of user control and exploration objectives.
read the caption
Figure 5: Three exploration modes — interactive, GPT-assisted, and goal-driven — each defined by distinct exploration instructions.

🔼 Figure 6 illustrates three distinct modes of exploration within the GenEx framework: Interactive Exploration, where a human user directly controls the agent’s movements and exploration; GPT-assisted Free Exploration, where a GPT model guides the agent’s exploration to maximize world fidelity and prevent model collapse; and Goal-driven Navigation, where the agent receives specific navigation instructions from a GPT based on an initial image and overall goal. Each mode offers a unique approach to navigating and understanding the generated environment, showcasing the flexibility and potential of GenEx for diverse exploration tasks. The generated images in this figure are panoramic, and small sections have been extracted from the panorama and arranged as cube faces for better visualization.
read the caption
Figure 6: GenEx-driven imaginative exploration can gather observations that are just as informed as those obtained through physical exploration.

🔼 Figure 7 illustrates how GenEx empowers single and multi-agents to enhance their decision-making through imagination in both single-agent and multi-agent scenarios. In (a) single-agent reasoning with imagination, a single agent leverages GenEx to generate imaginative views of previously unseen parts of the environment, gaining a more comprehensive understanding before deciding whether to stop or continue at an intersection or how to react to other moving agents. In (b) multi-agent reasoning and planning with imagination, agents in a multi-agent setting utilize GenEx to imagine the perspectives of other agents, enabling them to infer the other agents’ intentions and make better informed decisions in collaborative scenarios such as avoiding collisions at intersections. All input and generated images are panoramic, and cubes are extracted solely for the purpose of clearer visualization of the spatial relations and agent perspectives.
read the caption
Figure 7: Single agent reasoning with imagination and multi-agent reasoning and planning with imagination. (a) The single agent can imagine previously unobserved views to better understand the environment. (b) In the multi-agent scenario, the agent infers the perspective of others to make decisions based on a more complete understanding of the situation. Input and generated images are panoramic; cubes are extracted for visualization.

🔼 This figure, located in the Exploration Loop Consistency section, visualizes the Imaginative Exploration Loop Consistency (IELC) metric across varying distances and rotation amounts during exploration in a generated world. The heatmap uses Mean Squared Error (MSE) between the initial image and final generated image after completing a loop path, averaged over 1000 such paths. Lower MSE values (cooler colors) indicate better loop closure and higher consistency, meaning the generated world remains coherent even after extensive exploration. The x-axis represents the total rotation, and the y-axis represents the total distance traveled within the loop.
read the caption
Figure 8: Imaginative Exploration Loop Consistency (IELC) varying distance and rotations.

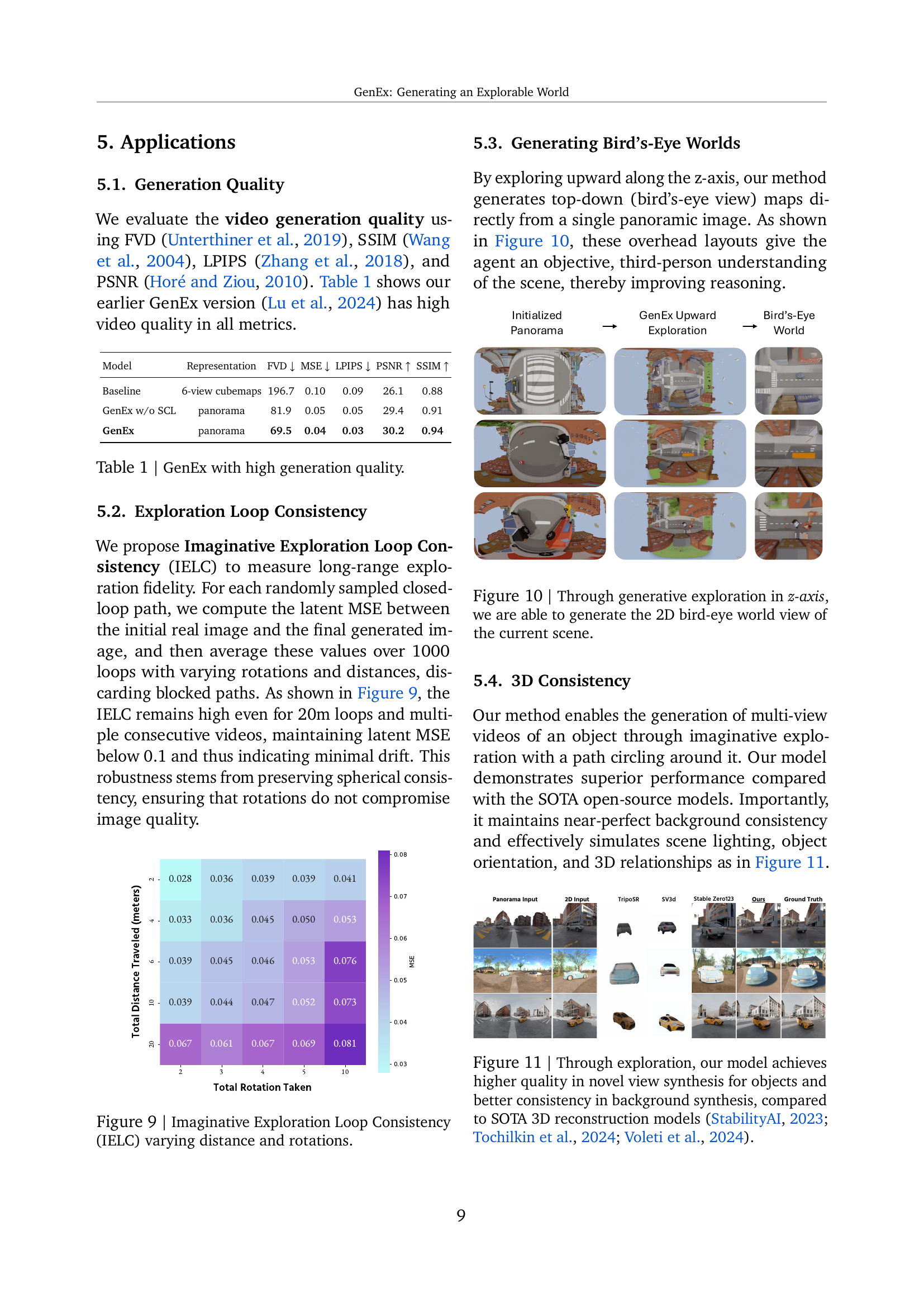
🔼 This figure showcases the generation of a 2D bird’s-eye view map derived directly from a single panoramic image by moving upwards along the z-axis within the generated environment. The resulting overhead view provides the agent with a broader, more objective understanding of the scene’s layout, which is beneficial for spatial reasoning and navigation.
read the caption
Figure 9: Through generative exploration in z-axis, we are able to generate the 2D bird-eye world view of the current scene.

🔼 This figure visually compares the quality of novel view synthesis and background consistency generated by the described model against other state-of-the-art (SOTA) 3D reconstruction models. It showcases the model’s enhanced capabilities in generating realistic and coherent scenes from novel viewpoints, surpassing existing techniques in terms of visual fidelity and background consistency. The figure likely presents a series of images or a video demonstrating the model’s output compared side-by-side with the outputs of other SOTA methods like SV3D, TripoSR, and Stable Zero123, highlighting improvements in object details and seamless integration with the background. The comparison emphasizes the model’s ability to generate more realistic and consistent 3D environments from single images, suitable for tasks like exploration and navigation.
read the caption
Figure 10: Through exploration, our model achieves higher quality in novel view synthesis for objects and better consistency in background synthesis, compared to SOTA 3D reconstruction models (Voleti et al., 2024; Tochilkin et al., 2024; StabilityAI, 2023).

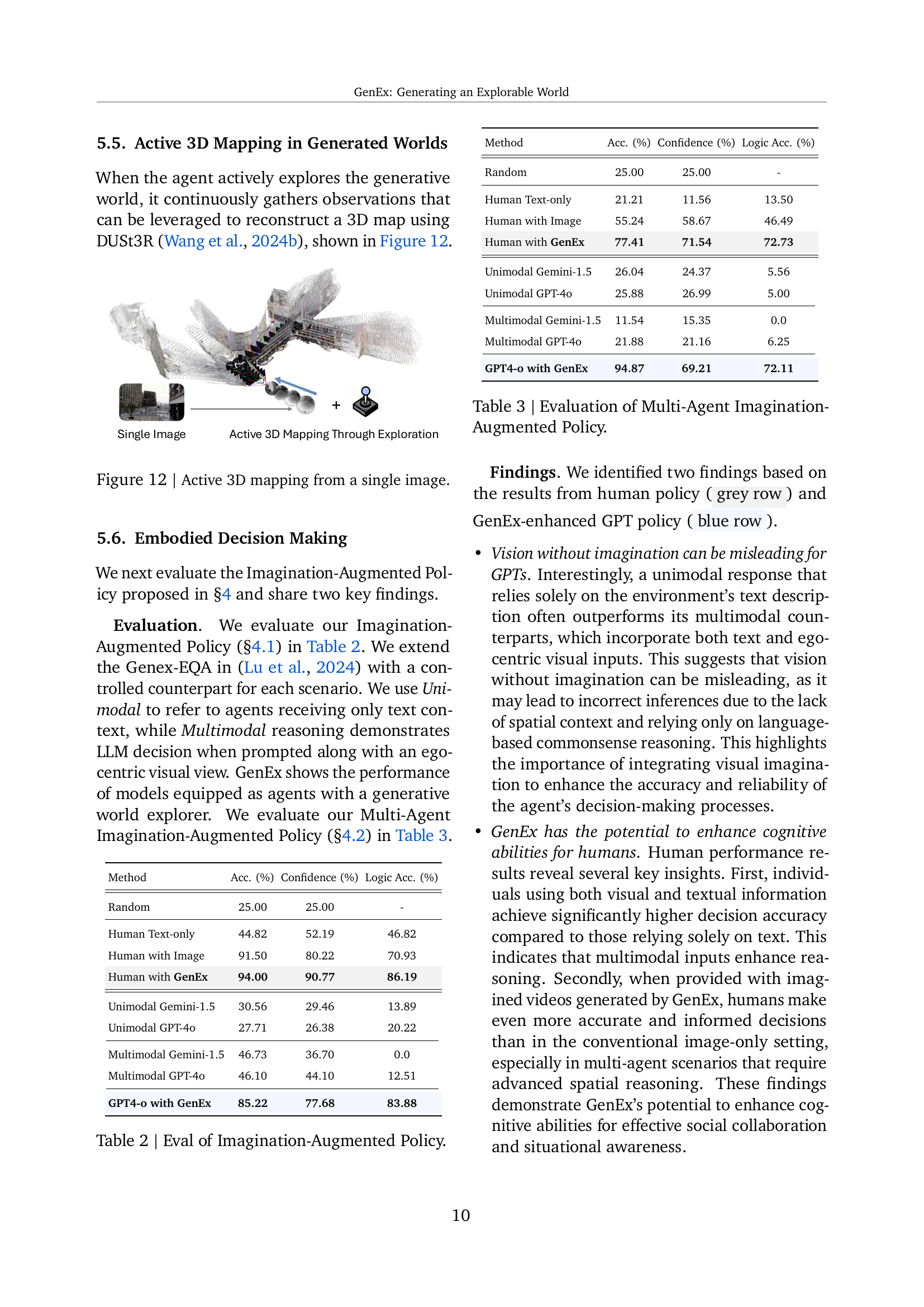
🔼 This figure showcases the capability of GenEx to perform active 3D mapping within its generated world. Starting from a single image, an agent explores the environment. As the agent navigates (as illustrated by the camera trajectory), it gathers observations from different viewpoints within the generated 3D environment. This collected data enables the agent to progressively construct a full 3D map of the scene, as shown in the final 3D model.
read the caption
Figure 11: Active 3D mapping from a single image.
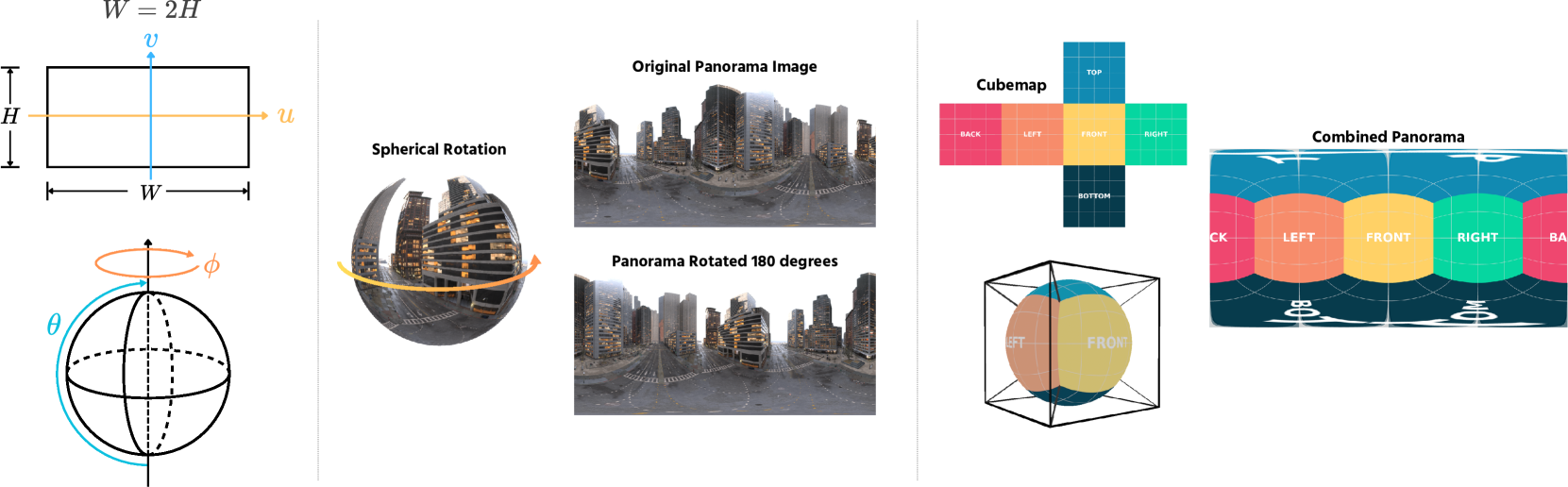
🔼 Figure 13 illustrates the relationship between different coordinate systems and panorama images. The left part of the figure visualizes the Pixel Grid coordinate system (u, v) used for representing pixels in a 2D image and the Spherical Polar coordinate system (φ, θ, r) which defines a point in 3D space using longitude, latitude, and radial distance. The middle portion demonstrates that rotating a panorama image corresponds to a rotation within the spherical coordinate system. The right part shows how a panorama, which is a 2D representation of a 360° view, can be converted into a cubemap, a 3D representation consisting of six square faces, and vice-versa.
read the caption
Figure 12: Left: Pixel Grid coordinate and Spherical Polar coordinate systems; Middle: rotation in Spherical coordinates corresponds to rotation in 2D image; Right: expansion from panorama to cubemap or composition in reverse.
More on tables
| Method | Acc. (%) | Confidence (%) | Logic Acc. (%) |
|---|---|---|---|
| Random | 25.00 | 25.00 | - |
| Human Text-only | 44.82 | 52.19 | 46.82 |
| Human with Image | 91.50 | 80.22 | 70.93 |
| Human with GenEx | 94.00 | 90.77 | 86.19 |
| Unimodal Gemini-1.5 | 30.56 | 29.46 | 13.89 |
| Unimodal GPT-4o | 27.71 | 26.38 | 20.22 |
| Multimodal Gemini-1.5 | 46.73 | 36.70 | 0.0 |
| Multimodal GPT-4o | 46.10 | 44.10 | 12.51 |
| GPT4-o with GenEx | 85.22 | 77.68 | 83.88 |
🔼 This table evaluates the performance of the Imagination-Augmented Policy, a novel approach for enhancing decision-making in embodied AI. The policy allows agents to explore unseen environments through imagined observations generated by GenEx, leading to more informed actions. The table compares the performance of various models, including unimodal (text-only) and multimodal (text and image) LLMs, with and without the GenEx augmentation. It also includes human performance as a baseline. The metrics used for evaluation are accuracy, confidence, and logical accuracy, showcasing the impact of imagined observations on decision-making quality.
read the caption
Table 2: Eval of Imagination-Augmented Policy.
| Method | Acc. (%) | Confidence (%) | Logic Acc. (%) |
|---|---|---|---|
| Random | 25.00 | 25.00 | - |
| Human Text-only | 21.21 | 11.56 | 13.50 |
| Human with Image | 55.24 | 58.67 | 46.49 |
| Human with GenEx | 77.41 | 71.54 | 72.73 |
| Unimodal Gemini-1.5 | 26.04 | 24.37 | 5.56 |
| Unimodal GPT-4o | 25.88 | 26.99 | 5.00 |
| Multimodal Gemini-1.5 | 11.54 | 15.35 | 0.0 |
| Multimodal GPT-4o | 21.88 | 21.16 | 6.25 |
| GPT4-o with GenEx | 94.87 | 69.21 | 72.11 |
🔼 This table presents the evaluation results of the Multi-Agent Imagination-Augmented Policy in a scenario involving multiple agents. It assesses the policy’s effectiveness by measuring the decision-making accuracy (Acc.), confidence level (Confidence), and logical reasoning accuracy (Logic Acc.) of the agents. Different methods, including random selection, human input with and without access to GenEx, and unimodal/multimodal responses from Gemini 1.5 and GPT-40 are compared. The results highlight the impact of imagination on decision-making in multi-agent settings.
read the caption
Table 3: Evaluation of Multi-Agent Imagination-Augmented Policy.
Full paper#