↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
Evaluating visual generative models is crucial, but existing methods are slow and rigid. This paper offers a faster, more flexible approach using a human-like “Evaluation Agent.” This framework is highly relevant to current research on generative AI and evaluation metrics, opening new avenues for creating more efficient and customizable evaluation methods, and potentially automated model recommendation systems.
Visual Insights#

🔼 Figure 1 contrasts traditional evaluation methods with the proposed Evaluation Agent framework. Traditional methods rely on extensive sampling from fixed benchmarks and provide numerical scores without detailed explanations. The Evaluation Agent, however, uses a human-like strategy, requiring only a few samples tailored to a user’s specific request. It offers a multi-round, dynamic evaluation process with detailed explanations, enhancing efficiency and user understanding. The figure visually illustrates this through an example user query about a generative model’s ability to generate objects and their attributes. The traditional approach would require extensive sampling and provide only a numerical score (e.g., 0.89). The Evaluation Agent, in contrast, uses a thought process based on a few samples in multiple rounds. It first evaluates simple prompts, then progresses to more complex evaluations like color attributes and spatial relationships. Finally, it provides a summary explanation of the model’s strengths and weaknesses regarding object and attribute generation, rather than just a score.
read the caption
Figure 1: An Example of Evaluation Agent. Existing evaluation methods typically assess visual generative models by extensively sampling from a fixed benchmark. In contrast, our Evaluation Agent framework requires only a small number of sampled images or videos, tailored to the user’s specific evaluation request. Additionally, it goes beyond providing a simple numerical score by offering detailed explanations to the evaluation conclusions.
| Queries | |||||||
|---|---|---|---|---|---|---|---|
| Supported | |||||||
| # Required | |||||||
| Open Evaluation | |||||||
| Dynamic | |||||||
| Open | |||||||
| Tool-Use | |||||||
| FID / FVD [Unterthiner et al. (2018); Heusel et al. (2017)] | ✗ | ✗ | T2I / T2V | 2,048 | ✗ (Fixed-Form) | ✗ | ✗ |
| T2I-CompBench [Huang et al. (2023)] | ✗ | ✗ | T2I | 18,000 | ✗ (Pre-Defined) | ✗ | ✗ |
| VBench [Huang et al. (2024a)] | ✗ | ✗ | T2V | 4,730 | ✗ (Pre-Defined) | ✗ | ✗ |
| Evaluation Agent (Ours) | ✓ | ✓ | T2I & T2V | 400 | ✓ (Open-Ended) | ✓ | ✓ |
🔼 Compares Evaluation Agent with traditional benchmarks (FID/FVD, T2I-CompBench, VBench) across several criteria: customized queries, supported models, required samples, open request support, dynamic evaluation, open tool use. Evaluation Agent efficiently supports customized queries, both T2I and T2V models with dynamic evaluation using multiple tools, unlike others.
read the caption
Table 1: Comparison of the Evaluation Agent Framework with Traditional T2I and T2V Benchmarks. The Evaluation Agent framework supports customized user queries in natural language and works with both T2I and T2V models. Unlike traditional benchmarks, it dynamically updates the evaluation process using multiple tools, providing comprehensive and explainable results with detailed textual analysis.
In-depth insights#
Eval Agent Framework#
The Eval Agent Framework dynamically evaluates visual generative models, mimicking human evaluation strategies. It addresses limitations of traditional benchmarks by using fewer samples and offering flexible, open-ended queries. The framework’s two-stage process starts with the Proposal Stage, where a Plan Agent determines evaluation aspects and a PromptGen Agent designs prompts. This is followed by the Execution Stage, where models generate content based on these prompts, and an Evaluation Toolkit assesses the outputs. This iterative process allows the agent to refine its evaluation, uncovering subtle model behaviors and limitations efficiently. This innovative approach allows for more targeted insights and reduces overfitting to specific prompts observed in fixed benchmarks. The framework’s scalability and interpretable results benefit both experts and non-experts in understanding model capabilities.
Dynamic Multi-Round Eval#
Dynamic multi-round evaluation signifies a pivotal shift from static benchmarks. It mirrors human assessment by iteratively refining evaluation through multiple rounds. This adaptive approach allows for deeper exploration of model capabilities beyond fixed prompts, uncovering subtle strengths and weaknesses. Beginning with a preliminary focus, subsequent rounds adjust based on prior results, targeting specific aspects like complex scenarios or nuanced prompts. This iterative refinement enhances efficiency, avoids redundant tests, and ultimately provides a more comprehensive, nuanced understanding of a model’s true potential.
Open-Ended Queries#
Open-ended queries are crucial for evaluating visual generative models’ adaptability to diverse user needs. Traditional benchmarks use fixed prompts, limiting insights and potentially leading to overfitting. Open-ended queries allow for flexible exploration of a model’s capabilities, uncovering strengths and limitations in handling nuanced instructions and abstract concepts. This approach is more aligned with real-world usage, where users have unique requests and expectations. By analyzing responses to open-ended queries, we gain a deeper understanding of a model’s reasoning and its ability to generalize beyond pre-defined scenarios. This offers valuable insights for future development, guiding improvements in areas where models struggle to interpret or execute complex or unconventional instructions. This approach is more aligned with real-world usage, where users have unique requests and expectations. Therefore, incorporating open-ended queries into evaluation frameworks is essential for robust and meaningful assessment of visual generative models’ true potential.
LLM & Toolkit Limits#
LLM limitations hinder Evaluation Agent performance. Inconsistent outputs and numerical struggles necessitate refined outputs and external tools. Toolkits, while SOTA, don’t fully align with human perception, impacting accuracy. They also lack fine-grained detail sensitivity, hindering nuanced evaluations. A versatile VQA-based toolkit using VLMs offers promise for fine-grained assessments. Though VLM effectiveness depends on its capabilities, current VLMs show impressive results, with future advancements enhancing performance.
Future of Eval Agents#
Eval Agents represent a nascent but potent shift in evaluating complex systems like generative models. Their dynamic, user-centric approach offers advantages over traditional static benchmarks, allowing for tailored evaluations based on specific user needs and open-ended queries. Future development hinges on improving the Evaluation Toolkit, augmenting it with more diverse and nuanced evaluation tools. This includes moving beyond current general metrics and incorporating tools sensitive to fine-grained aspects. Furthermore, the future Eval Agent will harness more sophisticated LLM agents capable of enhanced reasoning and planning, including better numerical reasoning and reduced inconsistencies. Finally, the growth of evaluation data through continuous assessment and user feedback will enable the development of model recommendation systems, guiding users toward the most suitable model based on their specific requirements.
More visual insights#
More on figures

🔼 The Evaluation Agent framework uses LLM-powered agents for efficient and flexible visual model assessments. It consists of two stages: 1. Proposal Stage: User queries are decomposed into sub-aspects, and prompts are generated. 2. Execution Stage: Visual content is generated and evaluated using an Evaluation Toolkit. These two stages interact iteratively, creating a dynamic assessment process based on user queries, intermediate results, and feedback.
read the caption
Figure 2: Overview of Evaluation Agent Framework. This framework leverages LLM-powered agents for efficient and flexible visual model assessments. As shown, it consists of two stages: (a) the Proposal Stage, where user queries are decomposed into sub-aspects, and prompts are generated, and (b) the Execution Stage, where visual content is generated and evaluated using an Evaluation Toolkit. The two stages interact iteratively to dynamically assess models based on user queries.

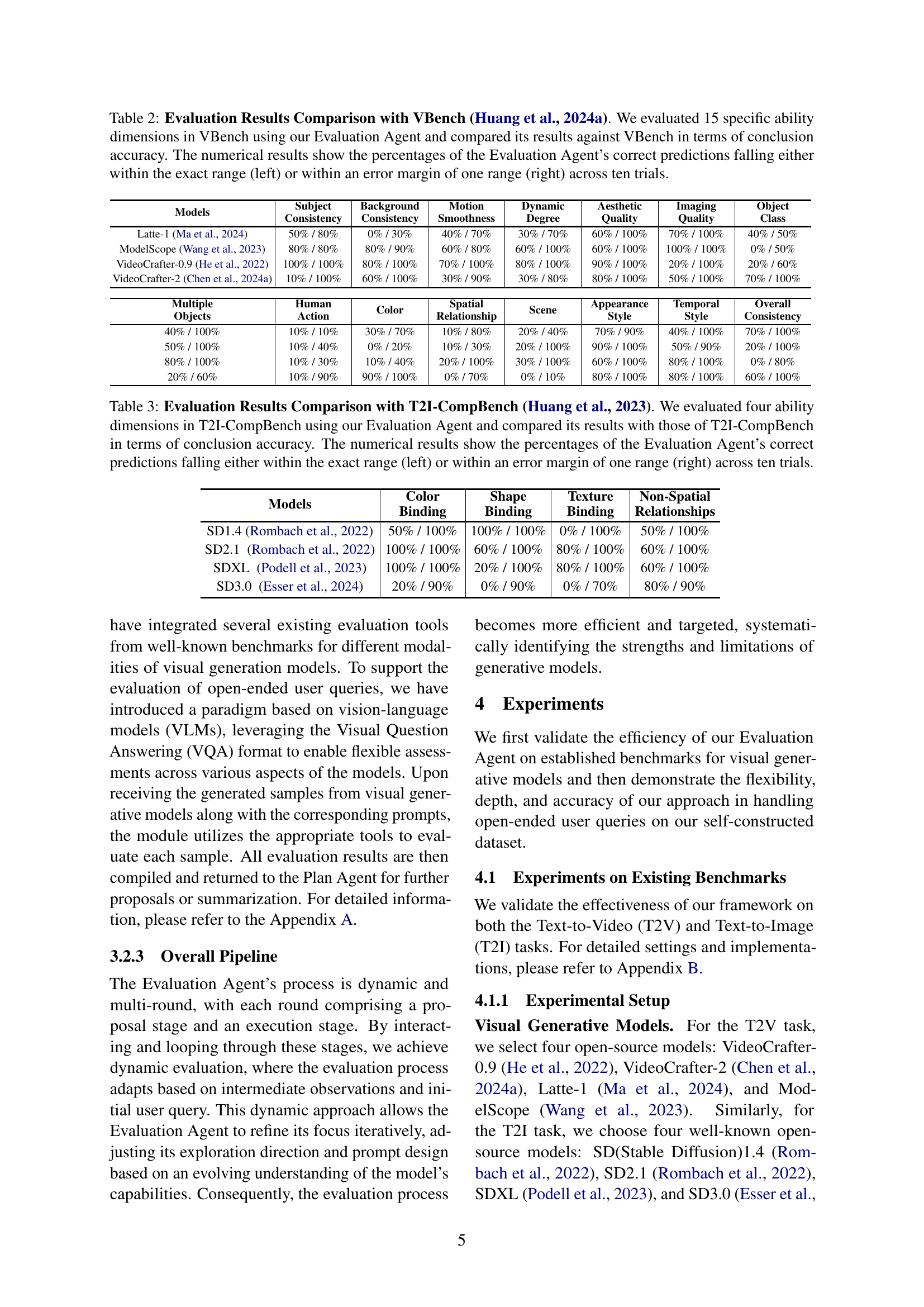
🔼 This figure compares the Evaluation Agent’s performance against VBench on four dimensions: Human Action, Scene, Color, and Object Class, using two models: Latte-1 and ModelScope. Two bar styles are used for each model-dimension pair: lighter bars represent performance using the original, smaller set of prompts; darker bars represent performance with an increased number of prompts (30). Within each bar, the hatched section indicates the percentage of predictions where the agent’s rating precisely matched VBench, and the solid section represents predictions within one rating level of VBench. This visualization demonstrates how the Evaluation Agent’s performance improves with increased samples, especially for metrics relying on binary sample-level evaluations, and aims to show its effectiveness can be comparable to full benchmark pipelines with more samples. The exact percentages for each setting are detailed in Table 6.
read the caption
Figure 3: Validation on VBench Percentage Dimensions. We conducted additional validation experiments on VBench by increasing the number of prompts in each evaluation. For each model and dimension, lighter bars represent results with the original settings, darker bars with increased sample size. Hatched portions indicate predictions within the exact range, and solid portions within an error margin of one range. Specific numerical results are provided in Table 6

🔼 This figure shows an example of how the Evaluation Agent assesses a visual generative model based on an open-ended user query. The user asks if the model can generate variations of existing artwork while maintaining the original style. The agent explores this by testing the model’s ability to replicate basic art styles (like Impressionism), maintain style consistency in detail-oriented artworks (like replicating a Van Gogh with a skyline), and blend styles by merging elements from different artistic traditions (like adding elements of Indigenous Australian dot painting to Monet’s Water Lilies). The results are then summarized to provide the user with a comprehensive analysis of the model’s ability to handle variations within and across different artistic styles.
read the caption
Figure 4: A Case of Open-Ended User Query Evaluation. For open-ended user queries, the Evaluation Agent systematically explores the model’s capabilities in specific areas, starting from basic aspects and gradually delving deeper, culminating in a detailed analysis and summary. Please refer to the Appendix E.2 for the complete results.

🔼 This figure analyzes the distribution of the open-ended user query dataset across three dimensions: General/Specific, Ability, and Specific Domain. The General/Specific dimension categorizes queries as either addressing general model capabilities or focusing on specific functionalities. The Ability dimension labels the type of model capability being evaluated, such as prompt following, visual quality, creativity, knowledge, or other. The Specific Domain dimension identifies the area of application for the query, including law, film and entertainment, fashion, game design, architecture and interior design, medical, science and education, history and culture, and others. The distribution reveals a relatively balanced representation across these dimensions, indicating the dataset’s diversity and suitability for evaluating a wide range of model capabilities.
read the caption
Figure 5: Data Distribution of Open-Ended User Query Dataset. We analyze the constructed open-ended user query dataset from three aspects: General/Specific, Ability, and Specific Domain. The results indicate that our dataset exhibits a relatively balanced distribution across these dimensions.

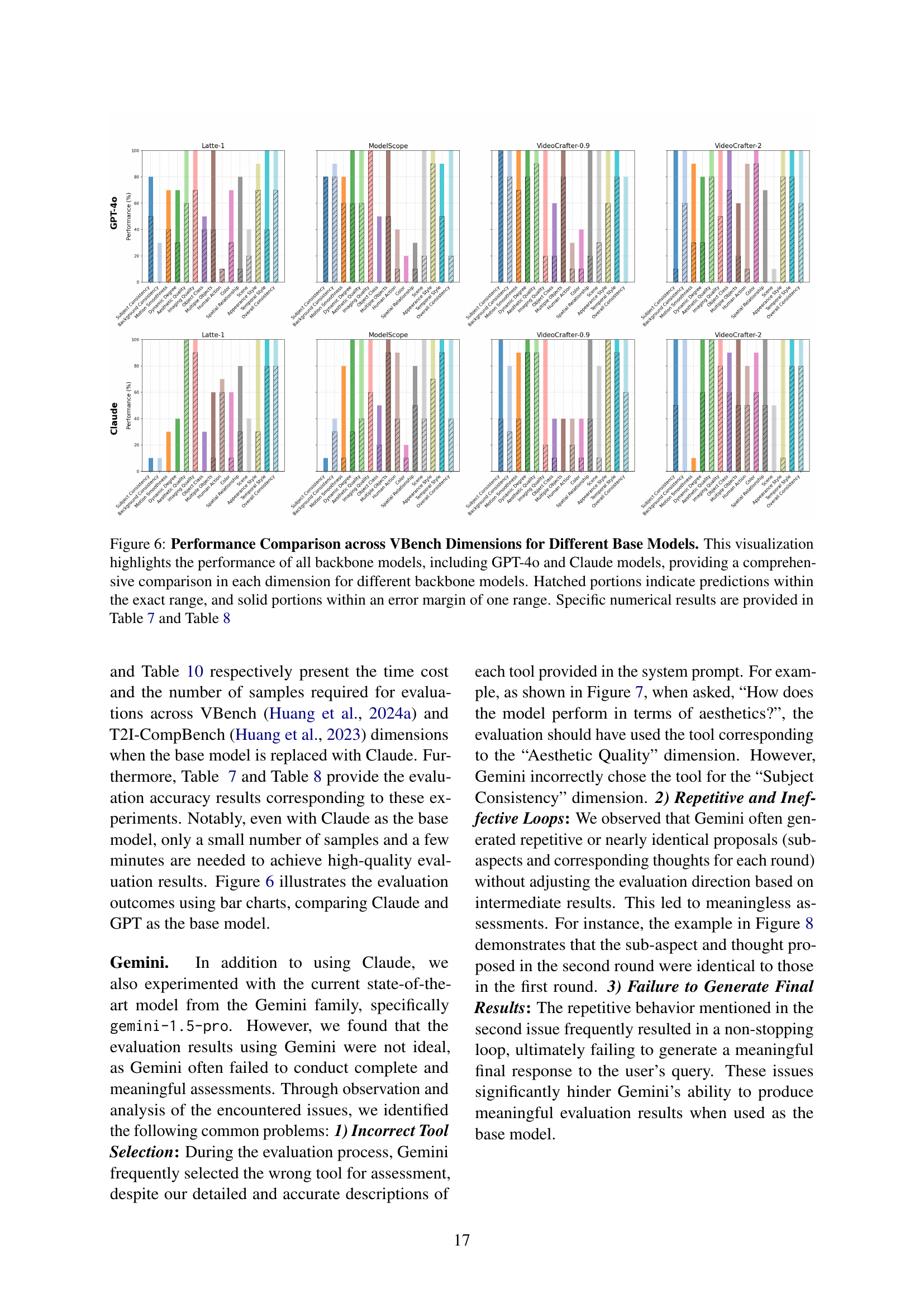
🔼 This figure visually compares the performance of different base models (GPT-40 and Claude) across various dimensions of the VBench benchmark for text-to-video generation. Each dimension’s bar chart shows the accuracy of the model’s predictions, with hatched sections representing predictions within the exact target range and solid sections showing predictions within one range of the target. The comparison demonstrates how different LLMs perform as the backbone of the evaluation agent, affecting its ability to assess video generation models.
read the caption
Figure 6: Performance Comparison across VBench Dimensions for Different Base Models. This visualization highlights the performance of all backbone models, including GPT-4o and Claude models, providing a comprehensive comparison in each dimension for different backbone models. Hatched portions indicate predictions within the exact range, and solid portions within an error margin of one range. Specific numerical results are provided in Table C.2 and Table 8

🔼 This figure shows an example where Gemini selected an incorrect tool for evaluation. Asked to assess aesthetics, it chose the ‘Subject Consistency’ tool instead of ‘Aesthetic Quality,’ leading to inaccurate assessments. This illustrates Gemini’s challenges in tool selection during visual model evaluation.
read the caption
Figure 7: A Common Failure Pattern in Tool Selection. As shown in the figure, Gemini frequently selected an incorrect tool for evaluation. In this case, the model should have selected the “Aesthetic Quality” tool, but it incorrectly chose “Subject Consistency,” leading to inaccuracies in subsequent assessments.

🔼 Gemini, when used as the backbone of the Evaluation Agent, exhibits two main failure modes. First, it fails to propose new sub-aspects, engaging in repetitive loops without adapting to feedback. Second, these loops often prevent it from generating a final response to the user’s query.
read the caption
Figure 8: Common Failures in Generating Sub-Aspects and Finalizing Responses. The figure highlights two critical failures: first, Gemini fails to propose new sub-aspects based on observations from previous rounds, instead engaging in repetitive and meaningless loops without strictly adhering to the provided instructions. Second, this repetitive behavior leads to a non-stopping loop, ultimately failing to generate a meaningful final response to the user’s query.

🔼 The Evaluation Agent assesses a model’s ability to generate variations of existing artwork while maintaining the original style. It begins by replicating basic art styles (Impressionism), then tests style consistency in detail-oriented artworks (Van Gogh’s Starry Night with a city skyline), and finally explores blending styles (integrating indigenous Australian dot painting into Monet’s Water Lilies) and complex style integration (combining Japanese ukiyo-e with African tribal patterns). The results reveal proficiency in single-style variations but limitations in blending diverse styles.
read the caption
Figure 9: A Case of Open-Ended User Query Evaluation. This figure illustrates the Evaluation Agent’s response to the user query, “Can the model generate variations of existing artwork while maintaining the original style?”

🔼 This figure showcases an example of the Evaluation Agent’s response to an open-ended user query concerning the precision of object relationships. The agent conducts multiple rounds of evaluations, starting with simple relationships and progressing to complex and abstract ones. Each round involves generating images, posing questions about the generated image to a VLM (Visual Language Model), and analyzing the VLM’s answers to refine subsequent prompts. The agent’s thought process and the generated images provide insight into its evaluation strategy and its capabilities and limitations in understanding and generating spatial arrangements.
read the caption
Figure 10: A Case of Open-Ended User Query Evaluation. This figure illustrates the Evaluation Agent’s response to the user query, “How precisely can the user specify object relationships?”

🔼 This figure details the step-by-step evaluation process performed by the Evaluation Agent when responding to the open-ended user query, ‘How well can the model generate a specific number of objects?’ The figure presents a series of sub-aspects explored by the agent, each with corresponding prompts, generated images, questions posed to the VLM about the images, the VLM’s answers, and finally, a summary of the findings. The exploration begins with simple scenarios involving small numbers of identical objects and progresses to more complex situations with varied object types and environments. The goal is to assess the model’s capability to accurately generate the requested number of objects under diverse conditions.
read the caption
Figure 11: A Case of Open-Ended User Query Evaluation. This figure illustrates the Evaluation Agent’s response to the user query, “How well the model can generate a specific number of objects?”
More on tables
| Models | Subject | Background | Motion | Dynamic | Aesthetic | Imaging | Object | Class |
|---|---|---|---|---|---|---|---|---|
| Consistency | Subject | |||||||
| Consistency | Background | |||||||
| Consistency | Motion | |||||||
| Smoothness | Dynamic | |||||||
| Degree | Aesthetic | |||||||
| Quality | Imaging | |||||||
| Quality | Object | |||||||
| Class | ||||||||
| Latte-1 Ma et al. (2024) | 50% / 80% | 0% / 30% | 40% / 70% | 30% / 70% | 60% / 100% | 70% / 100% | 40% / 50% | |
| ModelScope Wang et al. (2023) | 80% / 80% | 80% / 90% | 60% / 80% | 60% / 100% | 60% / 100% | 100% / 100% | 0% / 50% | |
| VideoCrafter-0.9 He et al. (2022) | 100% / 100% | 80% / 100% | 70% / 100% | 80% / 100% | 90% / 100% | 20% / 100% | 20% / 60% | |
| VideoCrafter-2 Chen et al. (2024a) | 10% / 100% | 60% / 100% | 30% / 90% | 30% / 80% | 80% / 100% | 50% / 100% | 70% / 100% |
🔼 Compares the Evaluation Agent’s performance against VBench across 15 ability dimensions, measuring the percentage of correct predictions within the exact specified range and within a one-range error margin. The Evaluation Agent uses fewer samples and less time than traditional benchmarks, while still achieving comparable accuracy.
read the caption
Table 2: Evaluation Results Comparison with VBench Huang et al. (2024a). We evaluated 15 specific ability dimensions in VBench using our Evaluation Agent and compared its results against VBench in terms of conclusion accuracy. The numerical results show the percentages of the Evaluation Agent’s correct predictions falling either within the exact range (left) or within an error margin of one range (right) across ten trials.
| Multiple Objects | Human | Spatial | Scene | Temporal | Overall | ||
|---|---|---|---|---|---|---|---|
| Objects | Human | ||||||
| Action | Color | Spatial | |||||
| Relationship | Scene | Appearance | |||||
| Style | Temporal | ||||||
| Style | Overall | ||||||
| Consistency | |||||||
| — | — | — | — | — | — | — | — |
| 40% / 100% | 10% / 10% | 30% / 70% | 10% / 80% | 20% / 40% | 70% / 90% | 40% / 100% | 70% / 100% |
| 50% / 100% | 10% / 40% | 0% / 20% | 10% / 30% | 20% / 100% | 90% / 100% | 50% / 90% | 20% / 100% |
| 80% / 100% | 10% / 30% | 10% / 40% | 20% / 100% | 30% / 100% | 60% / 100% | 80% / 100% | 0% / 80% |
| 20% / 60% | 10% / 90% | 90% / 100% | 0% / 70% | 0% / 10% | 80% / 100% | 80% / 100% | 60% / 100% |
🔼 This table compares the Evaluation Agent’s performance against the T2I-CompBench benchmark across four ability dimensions: Color Binding, Shape Binding, Texture Binding, and Non-Spatial Relationships. It presents the percentage of times the Evaluation Agent’s assessment agreed exactly with T2I-CompBench’s conclusion (left number) and the percentage of times it was within one level of agreement (right number). These percentages are averaged over ten trials for each model and dimension, showcasing the Evaluation Agent’s ability to replicate established benchmark results with high fidelity.
read the caption
Table 3: Evaluation Results Comparison with T2I-CompBench Huang et al. (2023). We evaluated four ability dimensions in T2I-CompBench using our Evaluation Agent and compared its results with those of T2I-CompBench in terms of conclusion accuracy. The numerical results show the percentages of the Evaluation Agent’s correct predictions falling either within the exact range (left) or within an error margin of one range (right) across ten trials.
| Models | Color | Shape | Texture | Non-Spatial |
|---|---|---|---|---|
| SD1.4 Rombach et al. (2022) | 50% / 100% | 100% / 100% | 0% / 100% | 50% / 100% |
| SD2.1 Rombach et al. (2022) | 100% / 100% | 60% / 100% | 80% / 100% | 60% / 100% |
| SDXL Podell et al. (2023) | 100% / 100% | 20% / 100% | 80% / 100% | 60% / 100% |
| SD3.0 Esser et al. (2024) | 20% / 90% | 0% / 90% | 0% / 70% | 80% / 90% |
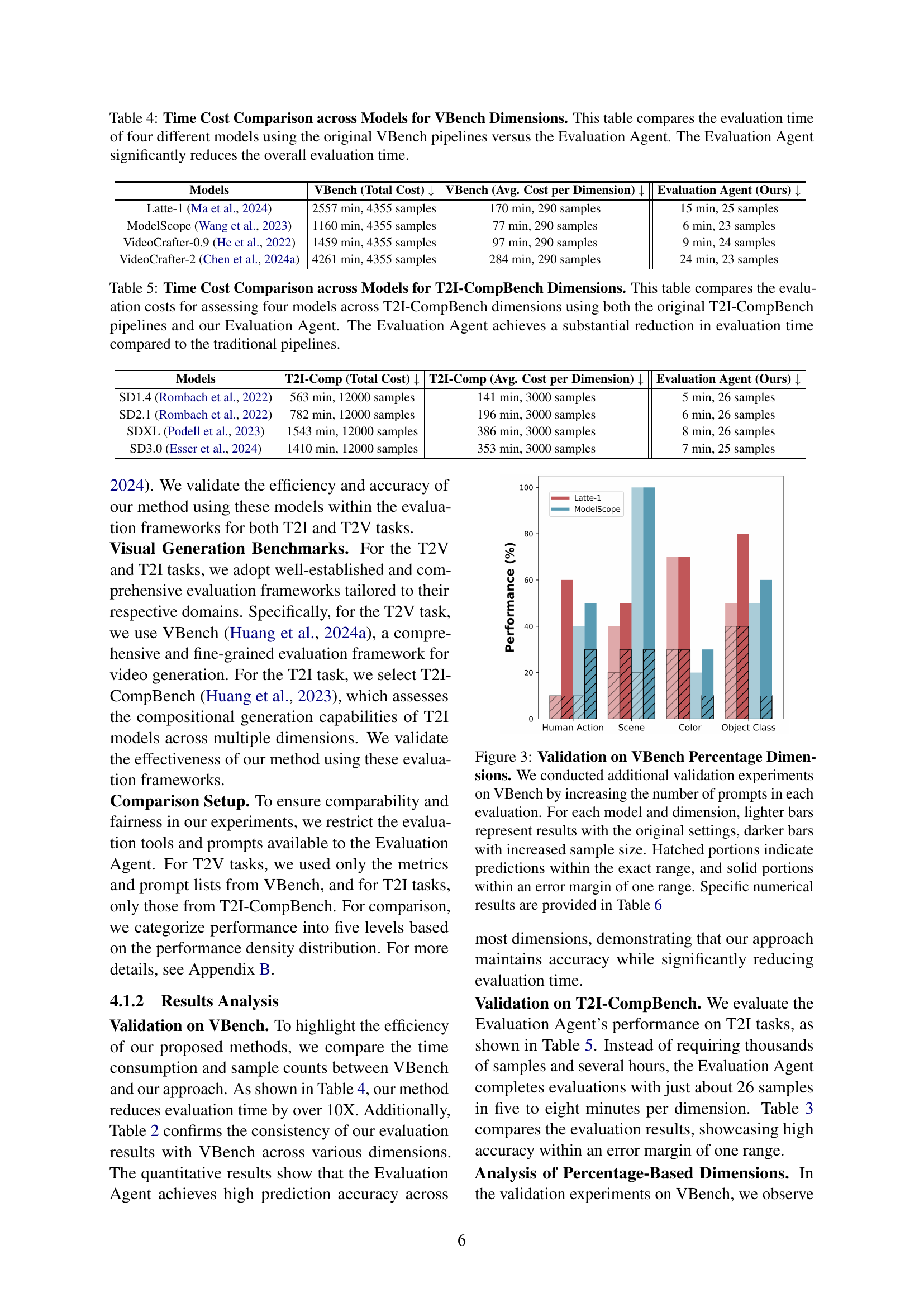
🔼 This table compares the time and the number of samples required for evaluating four different video generation models (Latte-1, ModelScope, VideoCrafter-0.9, VideoCrafter-2) across fifteen dimensions defined in VBench. It presents results for both the original VBench evaluation pipeline and the proposed Evaluation Agent framework. The results demonstrate a significant reduction in evaluation time (over 90%) when using the Evaluation Agent while maintaining comparable performance.
read the caption
Table 4: Time Cost Comparison across Models for VBench Dimensions. This table compares the evaluation time of four different models using the original VBench pipelines versus the Evaluation Agent. The Evaluation Agent significantly reduces the overall evaluation time.
| Models | VBench (Total Cost) ↓ | VBench (Avg. Cost per Dimension) ↓ | Evaluation Agent (Ours) ↓ |
|---|---|---|---|
| Latte-1 Ma et al. (2024) | 2557 min, 4355 samples | 170 min, 290 samples | 15 min, 25 samples |
| ModelScope Wang et al. (2023) | 1160 min, 4355 samples | 77 min, 290 samples | 6 min, 23 samples |
| VideoCrafter-0.9 He et al. (2022) | 1459 min, 4355 samples | 97 min, 290 samples | 9 min, 24 samples |
| VideoCrafter-2 Chen et al. (2024a) | 4261 min, 4355 samples | 284 min, 290 samples | 24 min, 23 samples |
🔼 This table compares the time and number of samples required to evaluate four different Stable Diffusion models on four compositional generation dimensions using the traditional T2I-CompBench evaluation method and the proposed Evaluation Agent. The results demonstrate that the Evaluation Agent significantly reduces the evaluation time while using substantially fewer samples.
read the caption
Table 5: Time Cost Comparison across Models for T2I-CompBench Dimensions. This table compares the evaluation costs for assessing four models across T2I-CompBench dimensions using both the original T2I-CompBench pipelines and our Evaluation Agent. The Evaluation Agent achieves a substantial reduction in evaluation time compared to the traditional pipelines.
| Models | T2I-Comp (Total Cost) ↓ | T2I-Comp (Avg. Cost per Dimension) ↓ | Evaluation Agent (Ours) ↓ |
|---|---|---|---|
| SD1.4 Rombach et al. (2022) | 563 min, 12000 samples | 141 min, 3000 samples | 5 min, 26 samples |
| SD2.1 Rombach et al. (2022) | 782 min, 12000 samples | 196 min, 3000 samples | 6 min, 26 samples |
| SDXL Podell et al. (2023) | 1543 min, 12000 samples | 386 min, 3000 samples | 8 min, 26 samples |
| SD3.0 Esser et al. (2024) | 1410 min, 12000 samples | 353 min, 3000 samples | 7 min, 25 samples |
🔼 This table presents a comparison of the Evaluation Agent’s performance against VBench across various percentage-based dimensions, including Human Action, Scene, Color, and Object Class. The results are presented as percentages, reflecting the accuracy of the Evaluation Agent’s predictions over ten trials. For each dimension, two percentage values are provided: the percentage of predictions falling within the exact range defined by VBench, and the percentage of predictions falling within one range above or below the exact range. This allows for an assessment of both the precision and general accuracy of the Evaluation Agent.
read the caption
Table 6: Validation on VBench Percentage Dimensions. The numerical results show the percentages of the Evaluation Agent’s correct predictions falling either within the exact range (left) or within an error margin of one range (right) across ten trials.
| Models | Human | Scene | Color | Object Class |
|---|---|---|---|---|
| — | — | — | — | — |
| Latte-1 (default) Ma et al. (2024) | 10% / 10% | 20% / 40% | 30% / 70% | 40% / 50% |
| Latte-1 (30 prompts) Ma et al. (2024) | 10% / 60% | 30% / 50% | 30% / 70% | 40% / 80% |
| ModelScope (default) Wang et al. (2023) | 10% / 40% | 20% / 100% | 0% / 20% | 0% / 50% |
| ModelScope (30 prompts) Wang et al. (2023) | 30% / 50% | 30% / 100% | 10% / 30% | 10% / 60% |
🔼 This table compares the evaluation results of four different text-to-video generation models on 15 dimensions of the VBench benchmark, using the Claude language model as the backbone for the evaluation agent. The original experimental settings and parameters were maintained, but the GPT backbone used in the main experiments was replaced with Claude. The results are presented as percentages, reflecting the proportion of evaluations where the agent’s prediction fell within the exact specified range or within one range of the correct value across ten trials. This provides insight into the accuracy and consistency of the Claude-based evaluation agent compared to the original GPT-based agent when assessing video generation models using VBench.
read the caption
Table 7: Evaluation Results Comparison with VBench Huang et al. (2024a) using Claude as Base Model. We adhere to the same experimental settings and parameters as in the main experiments, but we replace the planning and reasoning agents’ backbones with claude-3-5-sonnet-20241022 as the base model.
| Models | Subject | Background | Motion | Dynamic | Aesthetic | Imaging | Object | Class |
|---|---|---|---|---|---|---|---|---|
| Consistency | ||||||||
| Consistency | Background | |||||||
| Consistency | Motion | |||||||
| Smoothness | Dynamic | |||||||
| Degree | Aesthetic | |||||||
| Quality | Imaging | |||||||
| Quality | Object | |||||||
| Class | ||||||||
| Latte-1 Ma et al. (2024) | 0% / 10% | 0% / 10% | 0% / 30% | 0% / 40% | 100% / 100% | 90% / 100% | 0% / 30% | |
| ModelScope Wang et al. (2023) | 0% / 10% | 30% / 40% | 10% / 80% | 30% / 100% | 40% / 100% | 60% / 100% | 20% / 50% | |
| VideoCrafter-0.9 He et al. (2022) | 40% / 100% | 30% / 80% | 40% / 90% | 90% / 100% | 90% / 100% | 20% / 100% | 10% / 40% | |
| VideoCrafter-2 Chen et al. (2024a) | 50% / 100% | 0% / 100% | 0% / 10% | 60% / 100% | 100% / 100% | 80% / 100% | 60% / 90% |
🔼 This table presents a comparison of evaluation results between the Evaluation Agent framework and the T2I-CompBench, a comprehensive benchmark for text-to-image generation models. The Evaluation Agent leverages large language models (LLMs) to guide its evaluation process. In this specific experiment, the LLM backbone for the Evaluation Agent was replaced with Claude-3-5-sonnet-20241022. The table focuses on four key dimensions of image generation: Color Binding, Shape Binding, Texture Binding, and Non-Spatial Relationships. For each model and dimension, the table reports the accuracy of the Evaluation Agent’s assessment compared to the ground truth provided by T2I-CompBench. The accuracy is represented as two percentages. The first percentage signifies how often the Evaluation Agent’s prediction falls within the exact range defined by the benchmark. The second percentage indicates how often the prediction falls within a margin of one range of the benchmark’s classification. This two-tiered accuracy reporting provides a more nuanced understanding of the Evaluation Agent’s performance. Results are averaged over ten trials.
read the caption
Table 8: Evaluation Results Comparison with T2I-CompBench Huang et al. (2023) using Claude as Base Model. We follow the same experimental setting and the parameters in the main experiments but changing the planning and reasoning agent’s backbones with claude-3-5-sonnet-20241022 as the base model.
| Multiple Objects | Human | Spatial | Scene | Temporal | Overall | Consistency | |
|---|---|---|---|---|---|---|---|
| Objects | Human | ||||||
| Action | Color | Spatial | |||||
| Relationship | Scene | Appearance | |||||
| Style | Temporal | ||||||
| Style | Overall | ||||||
| Consistency | |||||||
| 10% / 60% | 60% / 70% | 10% / 60% | 30% / 80% | 0% / 40% | 30% / 100% | 80% / 100% | 80% / 100% |
| 90% / 100% | 40% / 90% | 10% / 20% | 50% / 80% | 40% / 100% | 70% / 100% | 90% / 100% | 40% / 100% |
| 0% / 40% | 20% / 40% | 10% / 40% | 40% / 100% | 10% / 80% | 100% / 100% | 90% / 100% | 60% / 100% |
| 50% / 100% | 50% / 80% | 60% / 90% | 50% / 100% | 0% / 50% | 10% / 100% | 80% / 100% | 80% / 100% |
🔼 This table compares the time it takes to evaluate four text-to-video generation models using both the original VBench evaluation suite and the new Evaluation Agent framework. The results show that the Evaluation Agent significantly reduces the evaluation time.
read the caption
Table 9: Time Cost Comparison across Models for VBench Huang et al. (2024a) Dimensions using Claude as Base Model. This table compares the evaluation time of four different models using the original VBench pipelines versus the Evaluation Agent. The Evaluation Agent significantly reduces the overall evaluation time.
| Models | Color | Shape | Texture | Non-Spatial |
|---|---|---|---|---|
| SD1.4 Rombach et al. (2022) | 80% / 100% | 70% / 100% | 80% / 100% | 70% / 100% |
| SD2.1 Rombach et al. (2022) | 80% / 100% | 30% / 100% | 60% / 100% | 70% / 100% |
| SDXL Podell et al. (2023) | 90% / 100% | 60% / 100% | 70% / 100% | 30% / 100% |
| SD3.0 Esser et al. (2024) | 10% / 100% | 20% / 100% | 30% / 100% | 20% / 100% |
🔼 This table presents a comparison of evaluation time and required number of samples between the original T2I-CompBench evaluation process and the proposed Evaluation Agent, using Claude as the base model, when applied to four different Stable Diffusion models (SD1.4, SD2.1, SDXL, SD3.0). The table demonstrates that the Evaluation Agent significantly reduces evaluation time while requiring substantially fewer samples across all assessed models and T2I-CompBench dimensions (Color Binding, Shape Binding, Texture Binding, and Non-Spatial Relationships).
read the caption
Table 10: Time Cost Comparison across Models for T2I-CompBench Huang et al. (2023) Dimensions using Claude as Base Model. This table compares the evaluation costs for assessing four models across T2I-CompBench dimensions using both the original T2I-CompBench pipelines and our Evaluation Agent. The Evaluation Agent achieves a substantial reduction in evaluation time compared to the traditional pipelines.
Full paper#