↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
DNNs in medical imaging are vulnerable to attacks. This work is crucial as it demonstrates a novel attack method, P2P, exploiting text embeddings. This reveals vulnerabilities in medical image diagnosis DNNs, highlighting the need for robust defense mechanisms. P2P’s text-guided nature offers new research directions in adversarial attacks and defenses within medical imaging, pushing towards safer and more reliable AI-driven diagnosis.
Visual Insights#

🔼 Figure 1 visually compares the original breast ultrasound image with two adversarial attacks: one generated by Diff-PGD and another by the proposed P2P method. It highlights that P2P produces a visually similar image to the original, preserving image semantics, unlike Diff-PGD which introduces noticeable changes.
read the caption
Figure 1: Illustration of P2P in an adversarial attack against Diff-PGD; note there is no exhibited change of image semantics in our method.
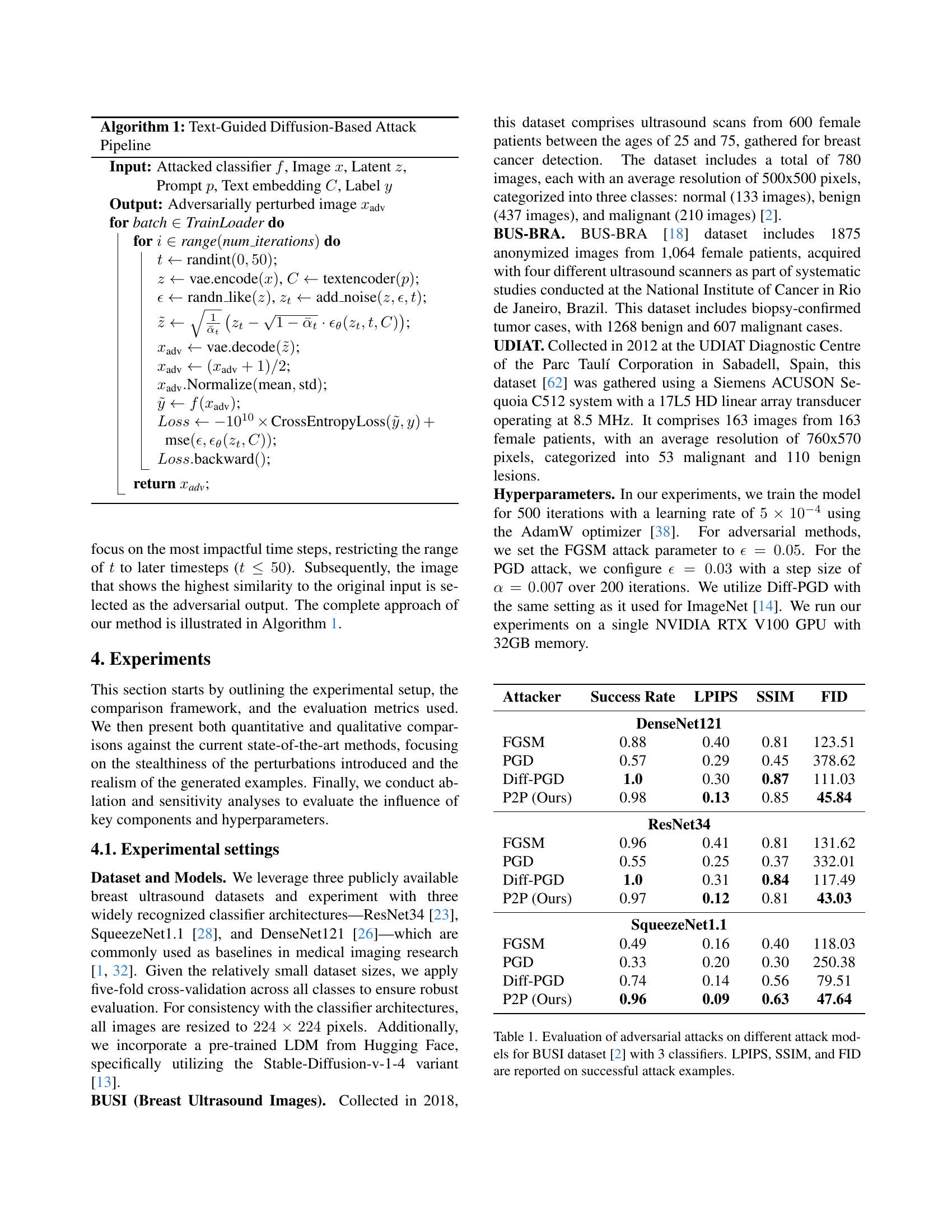
| Attacker | Success Rate | LPIPS | SSIM | FID |
|---|---|---|---|---|
| DenseNet121 | ||||
| FGSM | 0.88 | 0.40 | 0.81 | 123.51 |
| PGD | 0.57 | 0.29 | 0.45 | 378.62 |
| Diff-PGD | 1.0 | 0.30 | 0.87 | 111.03 |
| P2P (Ours) | 0.98 | 0.13 | 0.85 | 45.84 |
| ResNet34 | ||||
| FGSM | 0.96 | 0.41 | 0.81 | 131.62 |
| PGD | 0.55 | 0.25 | 0.37 | 332.01 |
| Diff-PGD | 1.0 | 0.31 | 0.84 | 117.49 |
| P2P (Ours) | 0.97 | 0.12 | 0.81 | 43.03 |
| SqueezeNet1.1 | ||||
| FGSM | 0.49 | 0.16 | 0.40 | 118.03 |
| PGD | 0.33 | 0.20 | 0.30 | 250.38 |
| Diff-PGD | 0.74 | 0.14 | 0.56 | 79.51 |
| P2P (Ours) | 0.96 | 0.09 | 0.63 | 47.64 |
🔼 This table evaluates the performance of different adversarial attacks (FGSM, PGD, Diff-PGD, and the proposed P2P) against three classifiers (DenseNet121, ResNet34, and SqueezeNet1.1) on the BUSI dataset. The metrics used to evaluate the attack performance are Success Rate, LPIPS, SSIM, and FID. The table shows these metrics specifically for the successfully attacked examples, not on the whole dataset.
read the caption
Table 1: Evaluation of adversarial attacks on different attack models for BUSI dataset [2] with 3 classifiers. LPIPS, SSIM, and FID are reported on successful attack examples.
In-depth insights#
DNN Vulnerability#
DNNs in medical imaging, particularly those trained via transfer learning from natural images, exhibit heightened vulnerability to adversarial attacks. This susceptibility arises from the discrepancy between natural and medical image data distributions. Attacks like FGSM, PGD, and even diffusion-based methods can manipulate DNN predictions by introducing subtle, often imperceptible perturbations. These attacks raise significant concerns about DNN reliability and security in critical diagnostic settings. While traditional attacks using fixed-norm perturbations might not align with real-world scenarios, diffusion-based attacks present challenges due to data requirements and model availability. Prompt-based attacks, leveraging text embeddings, are an emerging area. Addressing this vulnerability demands robust defense mechanisms and attack-aware training strategies to ensure trustworthy AI-driven medical diagnoses.
P2P Attack#
The Prompt2Perturb (P2P) attack introduces a novel approach to adversarial attacks, leveraging text-guided perturbations within Stable Diffusion. Unlike traditional methods adding pixel-level noise or manipulating latent codes, P2P optimizes text embeddings to subtly guide image generation towards misclassification. This method enhances the imperceptibility of the attack while maintaining image realism. P2P also avoids retraining diffusion models, crucial for data-scarce medical applications by directly updating text embeddings. Additionally, it focuses on optimizing early reverse diffusion steps for improved efficiency without sacrificing image quality. P2P effectively targets classifier vulnerabilities by crafting semantically aligned adversarial examples through subtle text modifications, making them challenging to distinguish from original images.
Text-Guided Attacks#
Text-guided attacks represent a new frontier in adversarial machine learning, leveraging the power of natural language to manipulate model predictions. This approach contrasts sharply with traditional methods that rely on perturbing image pixels directly. By exploiting the semantic understanding of text encoders within diffusion models, these attacks can generate adversarial examples that are both highly effective and perceptually subtle. This subtlety makes them particularly challenging to detect, raising significant concerns about model robustness in real-world applications. Furthermore, the ability to guide attacks with specific text prompts offers a new level of control and interpretability. This feature allows adversaries to target specific vulnerabilities or induce desired misclassifications, adding a layer of complexity to defense strategies. The emergence of text-guided attacks underscores the growing importance of multimodal security in machine learning and highlights the need for novel defense mechanisms that can effectively counter these sophisticated threats.
Diffusion Models#
Diffusion models have revolutionized image generation by iteratively denoising images from random noise. Their ability to generate high-quality, diverse samples makes them powerful tools. Conditioning these models on text prompts or other inputs allows for controlled generation, opening avenues for applications like targeted image editing and style transfer. Diffusion models achieve impressive realism by learning the underlying data distribution, contrasting with other generative methods. However, the iterative denoising process can be computationally expensive. Research continues to improve their efficiency and explore new applications. Furthermore, understanding the theoretical underpinnings of these models is crucial for further advancements.
Medical Imaging#
Medical imaging’s vulnerability to adversarial attacks raises serious concerns about DNN reliability in diagnostics. Subtle image alterations can mislead classifiers, jeopardizing patient safety. Traditional attack methods often lack realism, hindering their clinical relevance. Diffusion-based attacks offer enhanced realism but require extensive data, impractical in medical settings with limited datasets and diverse modalities. Addressing this challenge demands innovative attack strategies that enhance realism without extensive data needs, focusing on clinically relevant perturbations for robust evaluation and improvement of DNNs in medical imaging.
More visual insights#
More on figures

🔼 The figure presents the overall framework of the proposed Prompt2Perturb (P2P) method. It illustrates the integration of a text encoder, Stable Diffusion (a latent diffusion model), and a classifier within the attack pipeline. The workflow begins with a textual prompt input to the text encoder, which generates corresponding text embeddings. These embeddings then condition the Stable Diffusion model, guiding the generation of a perturbed image. This perturbed image subsequently undergoes classification, and the resultant loss guides the update of text embeddings in the pursuit of creating an adversarial example. The text encoder component has trainable parameters while the diffusion model component is frozen in this framework.
read the caption
Figure 2: Overall framework of the proposed method. Image adapted from [36]

🔼 Figure 3 visually compares different attack methods (FGSM, PGD, Diff-PGD, and the proposed P2P) on a benign image from the BUSI dataset, using DenseNet121 as the classifier. The top row showcases the attacked images generated by each method. The bottom row displays the perturbations for each attack, visualized as the difference between the original image and its corresponding attacked version. Notably, P2P’s perturbations appear more subtle and less patterned compared to other methods, suggesting that it introduces less noticeable artifacts while maintaining a natural appearance.
read the caption
Figure 3: Visual comparison of different attack methods on a benign image from the BUSI dataset, using DenseNet121 as the classifier. The second row displays the perturbations, calculated as the difference between the original image and the attacked example.

🔼 The figure shows a comparison of original breast ultrasound images from the BUS-BRA dataset and their corresponding adversarial examples generated by the Prompt2Perturb (P2P) attack method. The images are classified using a DenseNet121 model. The top row displays the original images with green boxes indicating their true diagnostic labels (malignant or benign). The bottom row shows the same images after the P2P attack, with the predicted labels indicated by red boxes. The P2P method successfully alters the predicted labels while maintaining a high degree of visual similarity between the original and attacked images. The examples effectively demonstrate how the P2P attack can mislead a classifier without introducing noticeable artifacts or unrealistic alterations to the image content, making the attack subtle and difficult to detect.
read the caption
Figure 4: Comparison of original and P2P-attacked ultrasound images from BUS-BRA Dataset, using DenseNet121 as the classifier. The top row shows the original images with their diagnostic labels, while the bottom row displays the same images after applying the P2P attack. Green boxes indicate the true labels, while red boxes show the labels predicted by the classifier after the attack.
More on tables
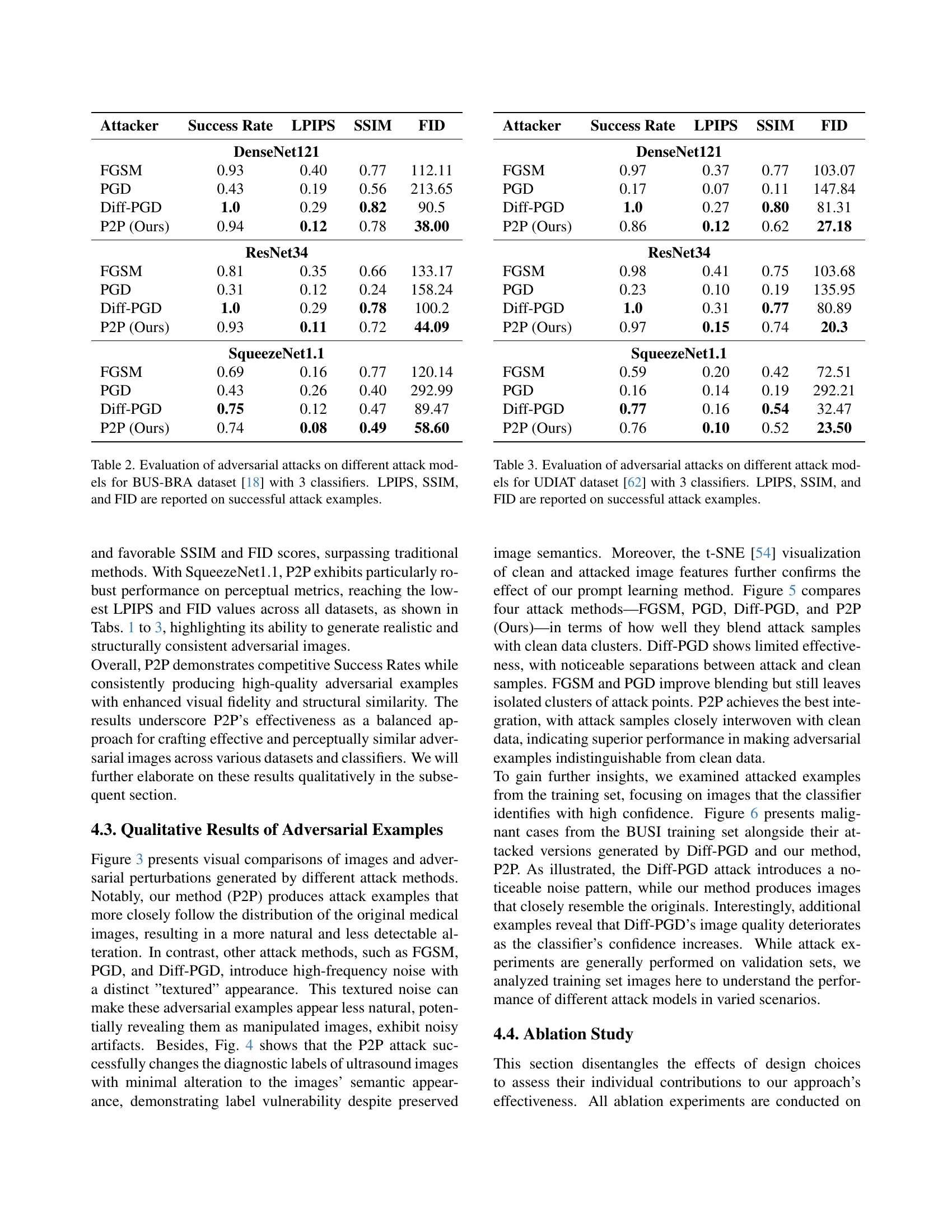
| Attacker | Success Rate | LPIPS | SSIM | FID |
|---|---|---|---|---|
| DenseNet121 | ||||
| FGSM | 0.93 | 0.40 | 0.77 | 112.11 |
| PGD | 0.43 | 0.19 | 0.56 | 213.65 |
| Diff-PGD | 1.0 | 0.29 | 0.82 | 90.5 |
| P2P (Ours) | 0.94 | 0.12 | 0.78 | 38.00 |
| ResNet34 | ||||
| FGSM | 0.81 | 0.35 | 0.66 | 133.17 |
| PGD | 0.31 | 0.12 | 0.24 | 158.24 |
| Diff-PGD | 1.0 | 0.29 | 0.78 | 100.2 |
| P2P (Ours) | 0.93 | 0.11 | 0.72 | 44.09 |
| SqueezeNet1.1 | ||||
| FGSM | 0.69 | 0.16 | 0.77 | 120.14 |
| PGD | 0.43 | 0.26 | 0.40 | 292.99 |
| Diff-PGD | 0.75 | 0.12 | 0.47 | 89.47 |
| P2P (Ours) | 0.74 | 0.08 | 0.49 | 58.60 |
🔼 This table presents a comparative evaluation of four different adversarial attack methods (FGSM, PGD, Diff-PGD, and the proposed P2P) on three distinct classifier models (DenseNet121, ResNet34, and SqueezeNet1.1). These attacks were applied to breast ultrasound images from the BUS-BRA dataset to assess their effectiveness in misclassifying images while maintaining perceptual similarity. The table reports the success rate of each attack, along with quality metrics including LPIPS (Learned Perceptual Image Patch Similarity), SSIM (Structural Similarity Index Measure), and FID (Fréchet Inception Distance), which measure the perceptual difference, structural similarity, and distribution similarity, respectively, between the attacked and original images. The metrics are calculated only on successfully attacked examples. Lower LPIPS and FID, along with higher SSIM, generally indicate better perceptual quality of the adversarial example, meaning it appears more like a real medical ultrasound image.
read the caption
Table 2: Evaluation of adversarial attacks on different attack models for BUS-BRA dataset [18] with 3 classifiers. LPIPS, SSIM, and FID are reported on successful attack examples.
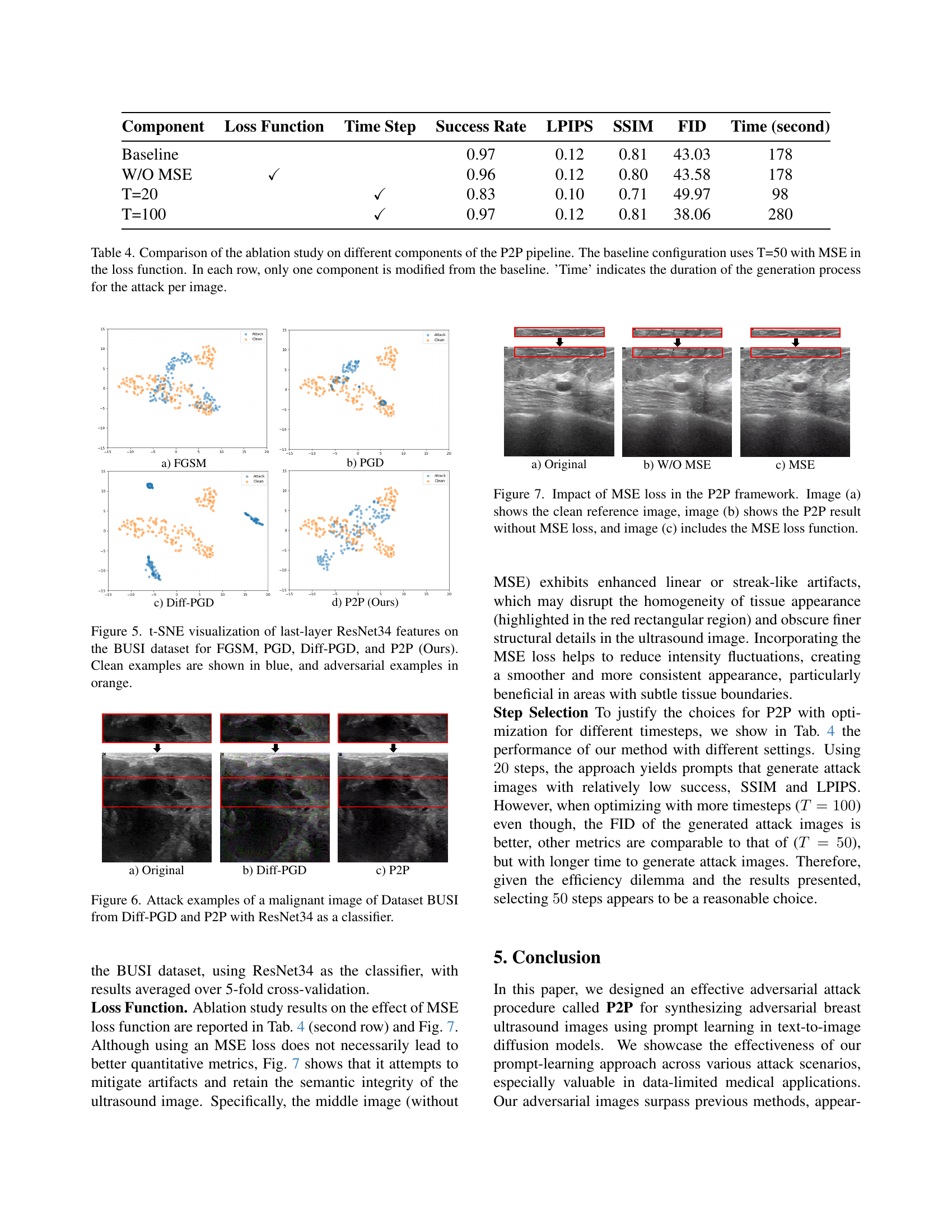
| Attacker | Success Rate | LPIPS | SSIM | FID |
|---|---|---|---|---|
| DenseNet121 | ||||
| FGSM | 0.97 | 0.37 | 0.77 | 103.07 |
| PGD | 0.17 | 0.07 | 0.11 | 147.84 |
| Diff-PGD | 1.0 | 0.27 | 0.80 | 81.31 |
| P2P (Ours) | 0.86 | 0.12 | 0.62 | 27.18 |
| ResNet34 | ||||
| FGSM | 0.98 | 0.41 | 0.75 | 103.68 |
| PGD | 0.23 | 0.10 | 0.19 | 135.95 |
| Diff-PGD | 1.0 | 0.31 | 0.77 | 80.89 |
| P2P (Ours) | 0.97 | 0.15 | 0.74 | 20.3 |
| SqueezeNet1.1 | ||||
| FGSM | 0.59 | 0.20 | 0.42 | 72.51 |
| PGD | 0.16 | 0.14 | 0.19 | 292.21 |
| Diff-PGD | 0.77 | 0.16 | 0.54 | 32.47 |
| P2P (Ours) | 0.76 | 0.10 | 0.52 | 23.50 |
🔼 Table 3 shows the success rate and image quality metrics (LPIPS, SSIM, and FID) of four different adversarial attack methods (FGSM, PGD, Diff-PGD, and P2P) on a breast ultrasound dataset named UDIAT. The table includes results for three different classifiers: DenseNet121, ResNet34, and SqueezeNet. Lower LPIPS and FID scores and higher SSIM scores mean better image quality and less noticeable alterations caused by the attack.
read the caption
Table 3: Evaluation of adversarial attacks on different attack models for UDIAT dataset [62] with 3 classifiers. LPIPS, SSIM, and FID are reported on successful attack examples.
| a) FGSM | b) PGD |
|---|---|
 |  |
| c) Diff-PGD | d) P2P (Ours) |
 |  |
🔼 This table presents the ablation study results for the Prompt2Perturb (P2P) method, comparing different configurations against a baseline. The baseline configuration uses 50 timesteps (T=50) and includes Mean Squared Error (MSE) as part of the loss function. Each row in the table modifies one component of the baseline, either changing the loss function by removing the MSE term or adjusting the number of diffusion steps (T). The ‘Time’ column denotes the computational time required to generate an adversarial attack for a single image.
read the caption
Table 4: Comparison of the ablation study on different components of the P2P pipeline. The baseline configuration uses T=50 with MSE in the loss function. In each row, only one component is modified from the baseline. ’Time’ indicates the duration of the generation process for the attack per image.
Full paper#