↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image editing methods using diffusion models struggle with large modifications, complex instructions, and interactive control. Inversion-based methods are computationally expensive and limited in editability, while instruction-based methods lack interactivity and often rely on noisy datasets. Existing inpainting methods have limitations in preserving unmasked regions and generalizing to different mask types. These challenges hinder the development of versatile and user-friendly image editing tools.
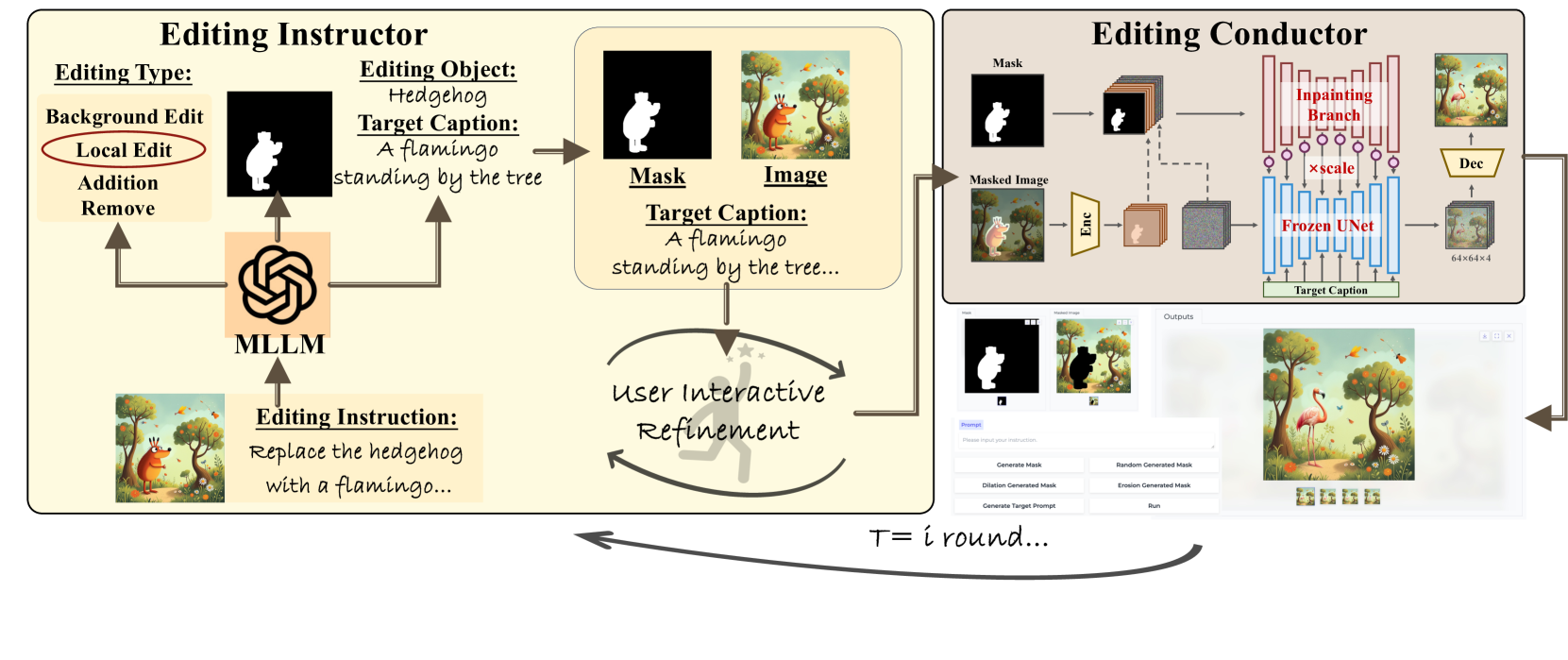
BrushEdit introduces an innovative framework that combines multimodal large language models (MLLMs) with a novel dual-branch inpainting model to address these limitations. It allows users to edit images by simply providing text instructions and interacting with free-form masks. The MLLM interprets instructions, identifies target objects, and generates captions for the edited image. The dual-branch inpainting model, trained on a unified dataset, then seamlessly fills the masked regions while preserving the background. This agent-based cooperative approach enables multi-turn interactive editing with flexible control over mask shapes and editing intensity, significantly enhancing image editing quality and user experience.
Key Takeaways#
Why does it matter?#
BrushEdit offers a novel approach to image editing, by combining language models with inpainting techniques. Its interactive nature and compatibility with pre-trained models open up new avenues for researchers exploring user-friendly image manipulation, free-form instruction-based editing, and agent-based creative tools.
Visual Insights#

🔼 BrushEdit allows users to input their own masks, which often combine the detailed structure of segmentation masks with the noise of random masks. Unlike previous methods that require separate models for different mask types (e.g., BrushNet-Ran for random masks and BrushNet-Seg for segmentation masks), BrushEdit uses a single, unified model, resulting in more natural and coherent edits. This figure shows four examples of user-provided masks and how BrushEdit uses them to generate realistic and artifact-free inpainting results.
read the caption
Figure 1: BrushEdit can achieve all-in-one inpainting for arbitrary mask shapes without requiring separate model training for each mask type. This flexibility in handling arbitrary shapes also enhances user-driven editing, as user-provided masks often combine segmentation-based structural details with random mask noise. By supporting arbitrary mask shapes, BrushEdit avoids the artifacts introduced by the random-mask version of BrushNet-Ran and the edge inconsistencies caused by the segmentation-mask version BrushNet-Seg’s strong reliance on boundary shapes.
| Editing Model | Plug-and-Play | Flexible-Scale | Multi-turn Interactive | Instruction Editing |
|---|---|---|---|---|
| Prompt2Prompt [8] | ✓ | ✓ | ||
| MasaCtrl [9] | ✓ | ✓ | ||
| MagicQuill [17] | ✓ | ✓ | ✓ | |
| InstructPix2Pix [13] | ✓ | |||
| GenArtist [25] | ✓ | ✓ | ||
| BrushEdit | ✓ | ✓ | ✓ | ✓ |
| Inpainting Model | Plug-and-Play | Flexible-Scale | Content-Aware | Shape-Aware |
| Blended Diffusion [26, 27] | ✓ | |||
| SmartBrush [28] | ✓ | |||
| SD Inpainting [5] | ✓ | ✓ | ||
| PowerPaint [29] | ✓ | ✓ | ||
| HD-Painter [30] | ✓ | ✓ | ||
| ReplaceAnything [31] | ✓ | ✓ | ||
| Imagen [32] | ✓ | ✓ | ||
| ControlNet-Inpainting [33] | ✓ | ✓ | ✓ | |
| BrushEdit | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares BrushEdit with other image editing and inpaining methods, focusing on key features like flexible content scaling, multi-turn interactivity, instruction-based editing, and handling of various mask shapes. The comparison highlights BrushEdit’s unique ability to handle all these aspects in a single, unified framework.
read the caption
TABLE I: Comparison of BrushEdit with Previous Image Editing/Inpainting Methods. Note that we only list commonly used text-guided diffusion methods in this table.
In-depth insights#
Inpainting & Edit#
BrushEdit, an innovative framework, tackles limitations of current image editing by unifying inpainting and instruction-guided editing. It leverages the power of MLLMs for instruction comprehension and a dual-branch inpainting model (BrushNet) for seamless edits. This approach allows versatile modifications like object addition/removal and structural changes using free-form masks, overcoming the restrictions of inversion-based methods and the rigidity of instruction-based approaches. BrushEdit excels in preserving background fidelity and aligning with editing instructions, offering a user-friendly, interactive editing experience.
BrushEdit Paradigm#
BrushEdit introduces a novel paradigm for interactive image editing, integrating inpainting and language models. It allows users to provide free-form text instructions and masks, streamlining complex edits. Unlike inversion-based methods, BrushEdit maintains high background fidelity while enabling significant structural changes. This is achieved by a dual-branch inpainting model, where one branch focuses on background preservation and the other generates the edited region based on instructions. The integration with MLLMs allows for semantic understanding of user intent, further improving edit quality. This paradigm also offers flexible control, enabling seamless integration with diverse pre-trained diffusion models and adjustment of background preservation levels, making it versatile and user-friendly.
MLLM Integration#
Integrating Multimodal Large Language Models (MLLMs) is transformative for image editing. BrushEdit leverages MLLMs to interpret complex natural language instructions, enabling a seamless user experience. This goes beyond keyword matching; the MLLM understands the nuances of language to identify editing types (addition, removal, style change), locate target objects, and generate detailed captions for the desired output. This deep understanding allows for free-form, interactive editing, where users provide instructions like “Replace the cat with a bear” and the MLLM guides the editing process. This intelligent interpretation is crucial for bridging the gap between user intent and image manipulation, enabling complex edits that go beyond the capabilities of traditional methods.
Versatile Control#
Versatile control in image editing empowers users with fine-grained manipulation over image elements and attributes. This control can manifest in various forms, from precisely adjusting colors and textures to modifying object shapes and positions. Advanced techniques even allow for content-aware modifications, where edits seamlessly integrate into the existing image context. This level of control is crucial for achieving realistic and high-quality editing results, enabling users to realize their creative visions effectively. Beyond the technical capabilities, versatile control also enhances the user experience, fostering intuitive and interactive editing workflows. This, in turn, promotes accessibility and empowers users of all skill levels to engage with image editing tools effectively. The continuous development of more sophisticated and intuitive control mechanisms remains a key area of focus in the field of image editing, aiming to further bridge the gap between user intent and editing outcome.
Ethical Concerns#
Ethical considerations are paramount in image editing research. Potential misuse includes creating deepfakes, manipulating images for disinformation, and amplifying harmful biases. While innovation drives progress, responsible development and usage are crucial. Open discussions about ethical implications, transparency in model limitations, and the establishment of usage guidelines are essential to mitigate potential harm. Furthermore, dataset bias must be addressed to ensure fair representation and prevent perpetuation of stereotypes. Copyright infringement is another concern, especially with models trained on copyrighted material. Balancing creative freedom with ethical responsibility is an ongoing challenge. User education plays a vital role in promoting ethical awareness and preventing malicious applications of these powerful tools. Finally, accountability mechanisms for misuse must be considered. Ongoing dialogue and collaboration among researchers, developers, and policymakers are crucial to navigate these complex issues.
More visual insights#
More on figures
🔼 BrushEdit’s model architecture takes a mask and a masked image as input and outputs an inpainted image. It involves downsampling the mask, encoding the masked image with VAE, concatenating noisy latent, masked image latent, and downsampled mask as BrushEdit input, adding extracted BrushEdit features to pre-trained UNet layers (using a zero convolution block), denoising, and blending the generated and masked images with a blurred mask.
read the caption
Figure 2: Model overview. Our model outputs an inpainted image given the mask and masked image input. Firstly, we downsample the mask to accommodate the size of the latent, and input the masked image to the VAE encoder to align the distribution of latent space. Then, noisy latent, masked image latent, and downsampled mask are concatenated as the input of BrushEdit. The feature extracted from BrushEdit is added to pretrained UNet layer by layer after a zero convolution block[33]. After denoising, the generated image and masked image are blended with a blurred mask.

🔼 Figure 3 provides a visual overview of the benchmarks used for evaluating the BrushEdit model. The top two rows (I and II) showcase examples from BrushBench, featuring both natural and artificially generated images alongside their corresponding masks and captions. These examples cover various scenarios, including humans, animals, indoor, and outdoor settings. Each image in these rows is accompanied by two masks: one for ‘inside’ inpainting, where the inner part of the image is masked, and one for ‘outside’ inpainting, where the outer area is masked. The bottom row (III) displays samples from EditBench, another benchmark used for testing inpainting performance. It includes both generated images and natural images with their respective masks and captions. All images shown are randomly selected from their respective benchmarks.
read the caption
Figure 3: Benchmark overview. I and II separately show natural and artificial images, masks, and caption of BrushBench. (a) to (d) show images of humans, animals, indoor scenarios, and outdoor scenarios. Each group of images shows the original image, inside-inpainting mask, and outside-inpainting mask, with an image caption on the top. III show image, mask, and caption from EditBench [32], with (e) for generated images and (f) for natural images. The images are randomly selected from both benchmarks.

🔼 This figure visually compares existing image editing methods (Prompt-to-Prompt, MasaCtrl, pix2pix-zero, and Plug-and-Play with DDIM and PnP inversion) with BrushEdit. It demonstrates various editing operations like removing, adding, modifying, and swapping objects on both natural and synthetic images. Specifically, row I shows removing a flower from a dog’s mouth and a laptop from a table. Row II presents adding a collar to a dog and flowers to a woman’s hair. Row III depicts changing a jacket to a blouse and a wreath to a crown. Lastly, row IV showcases replacing dumplings with sushi and a car with a motorcycle. BrushEdit exhibits better coherence between edited and unedited regions, closer adherence to editing instructions, smoother transitions at mask boundaries, and higher overall consistency.
read the caption
Figure 4: Comparison of previous editing methods and BrushEdit on natural and synthetic images, covering image editing operations such as removing objects (I), adding objects (II), modifying attributes (III), and swapping objects (IV).

🔼 Figure 5 compares the output of BrushEdit and other image inpainting models on various inpainting tasks and masks, including random and segmentation masks. Each example includes the original masked image and outputs from multiple methods: BLD, SDI, HDP, PP, CNI, BrushNet, and BrushEdit. The figure showcases BrushEdit’s ability to produce more coherent and contextually appropriate inpainted regions compared to other state-of-the-art inpainting models across various scenes, objects, and masking conditions.
read the caption
Figure 5: Performance comparisons of BrushEdit and previous image inpainting methods across various inpainting tasks: (I) Random Mask Inpainting (II) Segmentation Mask Inpainting. Each group of results contains 7777 inpainting methods: (b) Blended Latent Diffusion (BLD) [27], (c) Stable Diffusion Inpainting (SDI) [5], (d) HD-Painter (HDP) [30], (e) PowerPaint (PP) [29], (f) ControlNet-Inpainting (CNI) [33], (g) Our Previous BrushNet and (h) Ours.

🔼 Figure 6 demonstrates the integration of BrushEdit with five popular community-fine-tuned Stable Diffusion 1.5 models: DreamShaper, epiCRealism, Henmix_Real, MeinaMix (specifically designed for anime), and Realistic Vision. The figure showcases how BrushEdit, through its flexible design, allows these diverse models to perform image editing tasks while preserving background details and adhering to the textual instructions.
read the caption
Figure 6: Integrating BrushEdit to community fine-tuned diffusion models. We use five popular community diffusion models fine-tuned from stable diffusion v1.5: DreamShaper (DS) [99], epiCRealism (ER) [100], Henmix_Real (HR) [101], MeinaMix (MM) [102], and Realistic Vision (RV) [103]. MM is specifically designed for anime images.

🔼 Figure 7 demonstrates how BrushEdit’s control scale parameter, w, allows adjustment of the balance between preserving the original content of the unmasked regions and applying the edits specified in the text prompt. Subfigures (b) through (h) show the output images as w decreases from 1.0 to 0.2. A larger w value prioritizes preserving the original image, leading to more subtle edits. Conversely, a smaller w value emphasizes the edits, potentially at the cost of altering more of the original content. This demonstrates that w acts as a slider for how strongly the edits are applied, giving users fine-grained control over the editing process.
read the caption
Figure 7: Flexible control scale of BrushEdit. (a) shows the given masked image, (b)-(h) show adding control scale w𝑤witalic_w from 1.01.01.01.0 to 0.20.20.20.2. Results show a gradually diminishing controllable ability from precise to rough control.
More on tables
| Inverse | Editing | PSNR (↑) | LPIPS×10³ (↓) | MSE×10⁴ (↓) | SSIM×10² (↑) | CLIP Similariy (↑) |
|---|---|---|---|---|---|---|
| DDIM | P2P | 17.87 | 208.80 | 219.88 | 71.14 | 22.44 |
| PnP | P2P | 27.22 | 54.55 | 32.86 | 84.76 | 22.10 |
| DDIM | MasaCtrl | 22.17 | 106.62 | 86.97 | 79.67 | 21.16 |
| PnP | MasaCtrl | 22.64 | 87.94 | 81.09 | 81.33 | 21.35 |
| DDIM | P2P-Zero | 20.44 | 172.22 | 144.12 | 74.67 | 20.54 |
| PnP | P2P-Zero | 21.53 | 138.98 | 127.32 | 77.05 | 21.05 |
| DDIM | PnP | 22.28 | 113.46 | 83.64 | 79.05 | 22.55 |
| PnP | PnP | 22.46 | 106.06 | 80.45 | 79.68 | 22.62 |
| BrushEdit | 32.16 | 17.22 | 8.43 | 97.08 | 22.44 |
🔼 This table presents a quantitative comparison of BrushEdit with various other image editing methods using the PnPBench dataset. The comparison includes inversion-based methods like Prompt-to-Prompt, MasaCtrl, Pix2Pix-Zero, and Plug-and-Play, each evaluated with two inversion techniques (DDIM and PnP). The metrics used for evaluation are PSNR, LPIPS, MSE, SSIM, and CLIP Similarity. The best results are highlighted in red, and the second-best results are highlighted in blue, demonstrating BrushEdit’s superior performance in preserving unedited regions and ensuring accurate text alignment in edited areas.
read the caption
TABLE II: Comparison of BrushEdit with various editing methods in PnpBench. For editing methods Prompt-to-Prompt (P2P)[8], MasaCtrl[9], Pix2Pix-Zero (P2P-Zero)[9], and Plug-and-Play (PnP)[66], we evaluate two inversion techniques, DDIM Inversion (DDIM)[2] and PnP Inversion (PnP)[11], to establish stronger baselines. Red stands for the best result, Blue stands for the second best result.
| Methods | BrushEdit | NP | EF | AIDI | EDICT | NT | Style Diffusion |
|---|---|---|---|---|---|---|---|
| Inference Time (s) | 3.57 | 18.22 | 19.10 | 35.41 | 35.48 | 148.48 | 382.98 |
🔼 This table compares the inference time of BrushEdit with other inversion-based editing methods on image editing tasks. It demonstrates that BrushEdit achieves comparable or better results while using significantly less inference time. Specifically, BrushEdit takes 3.57 seconds per image edit, while other methods range from 18.22 to 382.98 seconds.
read the caption
TABLE III: Comparison of inference time between our inpainting-based BrushEdit and other inversion-based methods, including Negative-Prompt Inversion (NP), Edit Friendly Inversion (EF), AIDI[98], EDICT, Null-Text Inversion (NT), and Style Diffusion added with Prompt-to-Prompt. BrushEdit achieves better editing results with far less inference time than all inversion-based methods.
| Inside-inpainting | Outside-inpainting | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | Models | PSNR↑ | MSE×10³↓ | LPIPS×10³↓ | SSIM↑ | CLIP Sim↑ | Metrics | Models | PSNR↑ | MSE×10³↓ | LPIPS×10³↓ | SSIM↑ | CLIP Sim↑ |
| BLD (1) | 21.33 | 9.76 | 49.26 | 74.58 | 26.15 | BLD (1) | 15.85 | 35.86 | 21.40 | 77.40 | 26.73 | ||
| SDI (2) | 21.52 | 13.87 | 48.39 | 89.07 | 26.17 | SDI (2) | 18.04 | 19.87 | 15.13 | 91.42 | 27.21 | ||
| HDP (3) | 22.61 | 9.95 | 43.50 | 89.03 | 26.37 | HDP (3) | 18.03 | 22.99 | 15.22 | 90.48 | 26.96 | ||
| PP (4) | 21.43 | 32.73 | 48.43 | 86.39 | 26.48 | PP (4) | 18.04 | 31.78 | 15.13 | 90.11 | 26.72 | ||
| CNI (5) | 12.39 | 78.78 | 243.62 | 65.25 | 26.47 | CNI (5) | 11.91 | 83.03 | 58.16 | 66.80 | 27.29 | ||
| CNI (5)* | 22.73 | 24.58 | 43.49 | 91.53 | 26.22 | CNI (5)* | 17.50 | 37.72 | 19.95 | 94.87 | 26.92 | ||
| BrushNet-Seg* | 31.94 | 0.80 | 18.67 | 96.55 | 26.39 | BrushNet-Seg* | 27.82 | 2.25 | 4.63 | 98.95 | 27.22 | ||
| BrushEdit** | 31.98 | 0.79 | 18.92 | 96.68 | 26.24 | BrushEdit** | 27.65 | 2.30 | 4.90 | 98.97 | 27.29 |
🔼 Comparison of BrushEdit and other diffusion-based inpainting models on BrushBench for inside- and outside-inpainting tasks, evaluating background fidelity and text alignment using Stable Diffusion v1.5. Metrics include PSNR, MSE, LPIPS, SSIM, and CLIP Similarity. Higher values indicate better performance for PSNR, SSIM, CLIP Similarity. Lower values indicate better performance for MSE, LPIPS.
read the caption
TABLE IV: Quantitative comparisons between BrushEdit and other diffusion-based inpainting models in BrushBench: Blended Latent Diffusion (BLD)[27], Stable Diffusion Inpainting (SDI)[5], HD-Painter (HDP)[30], PowerPaint (PP)[29], ControlNet-Inpainting (CNI)[33], and our previous Segmentation-based BrushNet-Seg[22]. The table shows metrics on background fidelity and text alignment (Text Align) for both inside- and outside-inpainting. All models use Stable Diffusion V1.5 as the base model. Red indicates the best result, while Blue indicates the second-best result.
| Metrics | Masked Background Fidelity | Text Align | CLIP Sim | |
|---|---|---|---|---|
| Models | PSNR | MSE x 10^3 | LPIPS x 10^3 | SSIM x 10^3 |
| — | — | — | — | — |
| BLD[27] | 20.89 | 10.93 | 31.90 | 85.09 |
| SDI[5] | 23.25 | 6.94 | 24.30 | 90.13 |
| HDP[30] | 23.07 | 6.70 | 24.32 | 92.56 |
| PP[29] | 23.34 | 20.12 | 24.12 | 91.49 |
| CNI[33] | 12.71 | 69.42 | 159.71 | 79.16 |
| CNI*[33] | 22.61 | 35.93 | 26.14 | 94.05 |
| BrushNet-Ran* | 33.66 | 0.63 | 10.12 | 98.13 |
| BrushEdit | 32.97 | 0.70 | 7.24 | 98.60 |
🔼 This table presents a quantitative comparison of various image inpainting models using the EditBench dataset with random masks. The comparison includes Blended Latent Diffusion (BLD), Stable Diffusion Inpainting (SDI), HD-Painter (HDP), PowerPaint (PP), ControlNet-Inpainting (CNI), BrushNet-Ran, and the proposed method BrushEdit. The table evaluates the models based on background fidelity metrics (PSNR, MSE, LPIPS, SSIM) and text alignment using CLIP Similarity. The results demonstrate that BrushEdit significantly improves the preservation of masked regions, outperforming other methods, thanks to its novel dual-branch framework and combined mask training strategy.
read the caption
TABLE V: Quantitative comparisons among BrushEdit and other diffusion-based inpainting models, Random-mask-based BrushNet-Ran in EditBench. A detailed explanation of compared methods and metrics can be found in the caption of Tab. IV. Red stands for the best result, Blue stands for the second best result.
| Metrics | Image Quality | Masked Region Preservation | Text Align | CLIP Sim | ||||
|---|---|---|---|---|---|---|---|---|
| Model | IR×10↑ | HPS×10²↑ | AS↑ | PSNR↑ | MSE×10²↓ | LPIPS×10³↓ | ||
| — | — | — | — | — | — | — | — | — |
| SDI | 11.00 | 27.53 | 6.53 | 19.78 | 16.87 | 31.76 | 26.69 | |
| w/o fine-tune | 11.59 | 27.71 | 6.59 | 19.86 | 16.09 | 31.68 | 26.91 | |
| w/ fine-tune | 11.63 | 27.73 | 6.60 | 20.13 | 15.84 | 31.57 | 26.93 |
🔼 This table presents an ablation study on BrushEdit’s dual-branch vs. single-branch design for image inpainting. Stable Diffusion Inpainting (SDI) uses a single-branch design where the entire UNet is fine-tuned. Two dual-branch models were evaluated: one with the base UNet fine-tuned and one with the base UNet frozen. Results show superior performance with the dual-branch design, with freezing the base UNet providing the best balance of performance and model flexibility.
read the caption
TABLE VI: Ablation on dual-branch design. Stable Diffusion Inpainting (SDI) use single-branch design, where the entire UNet is fine-tuned. We conducted an ablation analysis by training a dual-branch model with two variations: one with the base UNet fine-tuned, and another with the base UNet forzened. Results demonstrate the superior performance achieved by adopting the dual-branch design. Red is the best result.
| Metrics | Image Quality | Masked Region Preservation | Text Align | ||
|---|---|---|---|---|---|
| Enc | Mask | Attn | UNet | Blend | IR ×10↑ |
| — | — | — | — | — | — |
| Conv | w/ | w/o | full | w/o | 11.05 |
| VAE | w/o | w/o | full | w/o | 11.55 |
| VAE | w/ | w/ | full | w/o | 11.25 |
| Conv | w/ | w/ | CN | w/o | 9.58 |
| VAE | w/ | w/ | CN | w/o | 10.53 |
| VAE | w/ | w/o | CN | w/o | 11.42 |
| VAE | w/ | w/o | half | w/o | 11.47 |
| VAE | w/ | w/o | full | w/o | 11.59 |
| VAE | w/ | w/o | full | paste | 11.72 |
| VAE | w/ | w/o | full | blur | 11.76 |
🔼 This table presents the ablation study results for different model architectures on image inpainting tasks. It investigates the impact of varying components such as the image encoder (using a randomly initialized convolutional layer or a VAE), mask inclusion, the presence of cross-attention layers, the method of UNet feature addition (full, half, or like ControlNet), and blending operation (none, direct pasting, or blurred blending).
read the caption
TABLE VII: Ablation on model architecture. We ablate on the following components: the image encoder (Enc), selected from a random initialized convolution (Conv) and a VAE; the inclusion of mask in input (Mask), chosen from adding (w/) and not adding (w/o); the presence of cross-attention layers (Attn), chosen from adding (w/) and not adding (w/o); the type of UNet feature addition (UNet), selected from adding the full UNet feature (full), adding half of the UNet feature (half), and adding the feature like ControlNet (CN); and finally, the blending operation (Blend), chosen from not adding (w/o), direct pasting (paste), and blurred blending (blur). Red is the best result.
Full paper#