↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Long-context language models (LLMs) struggle with memory efficiency, especially when dealing with multiple requests and reusable contexts. Current benchmarks evaluate models on single requests, overlooking the important aspect of Key-Value (KV) cache reuse, common in real-world applications like chatbots. This leads to unrealistic evaluations, as models often reuse previous context to save computation. Efficient long-context solutions are needed, but their evaluation under realistic reusable context scenarios remains a challenge. Current methods focus on single-turn benchmarks which cannot fully reflect real world scenarios with shared context and multiple rounds of conversations or interactions. This leads to inaccurate model evaluations. Specifically, sub-O(n) methods struggle in handling shared context scenarios where O(n) memory is necessary to preserve all essential information for different queries.
This paper introduces SCBench, a new benchmark designed to tackle these limitations. SCBench evaluates models on shared-context scenarios and multi-turn interactions, using two common context reuse patterns. It features 12 tasks assessing four key capabilities: string retrieval, semantic retrieval, global information processing, and multi-tasking. SCBench’s design offers a more realistic evaluation of long-context models, reflecting real-world application scenarios. Testing eight LLMs and 13 long-context methods, including a novel method called Tri-shape, it reveals that O(n) memory with sub-O(n^2) pre-filling calculation is critical for robust multi-turn performance, while dynamic sparse attention methods show higher efficiency and effectiveness than static sparse methods.
Key Takeaways#
Why does it matter?#
SCBench provides a standardized platform for evaluating long-context LLMs, crucial for efficient memory management in increasingly complex language processing tasks. It spotlights suboptimal performance of some current methods in handling multi-turn requests and shared contexts, exposing areas for improvement and inspiring new research directions. The benchmark’s focus on KV cache optimization paves the way for creating more efficient and resource-aware LLMs, enabling wider applications in scenarios like multi-turn dialogue systems.
Visual Insights#

🔼 This figure illustrates the lifecycle of a key-value (KV) cache in long-context large language models (LLMs). Traditional benchmarks focus on single requests, ignoring the reuse of KV caches across requests common in real-world applications. The proposed benchmark, SCBench, addresses this gap by considering the full KV cache lifecycle, categorizing long-context methods into generation, compression, retrieval, and loading stages. The diagram contrasts single-request and multi-request LLM interactions with their corresponding KV cache processes.
read the caption
Figure 1: KV Cache lifecycle. Prior benchmarks focus on single-request, while real-world applications reuse KV cache across requests. We propose SCBench and categorize long-context methods into KV Cache Generation, Compression, Retrieval, and Loading from a KV-cache-centric perspective.
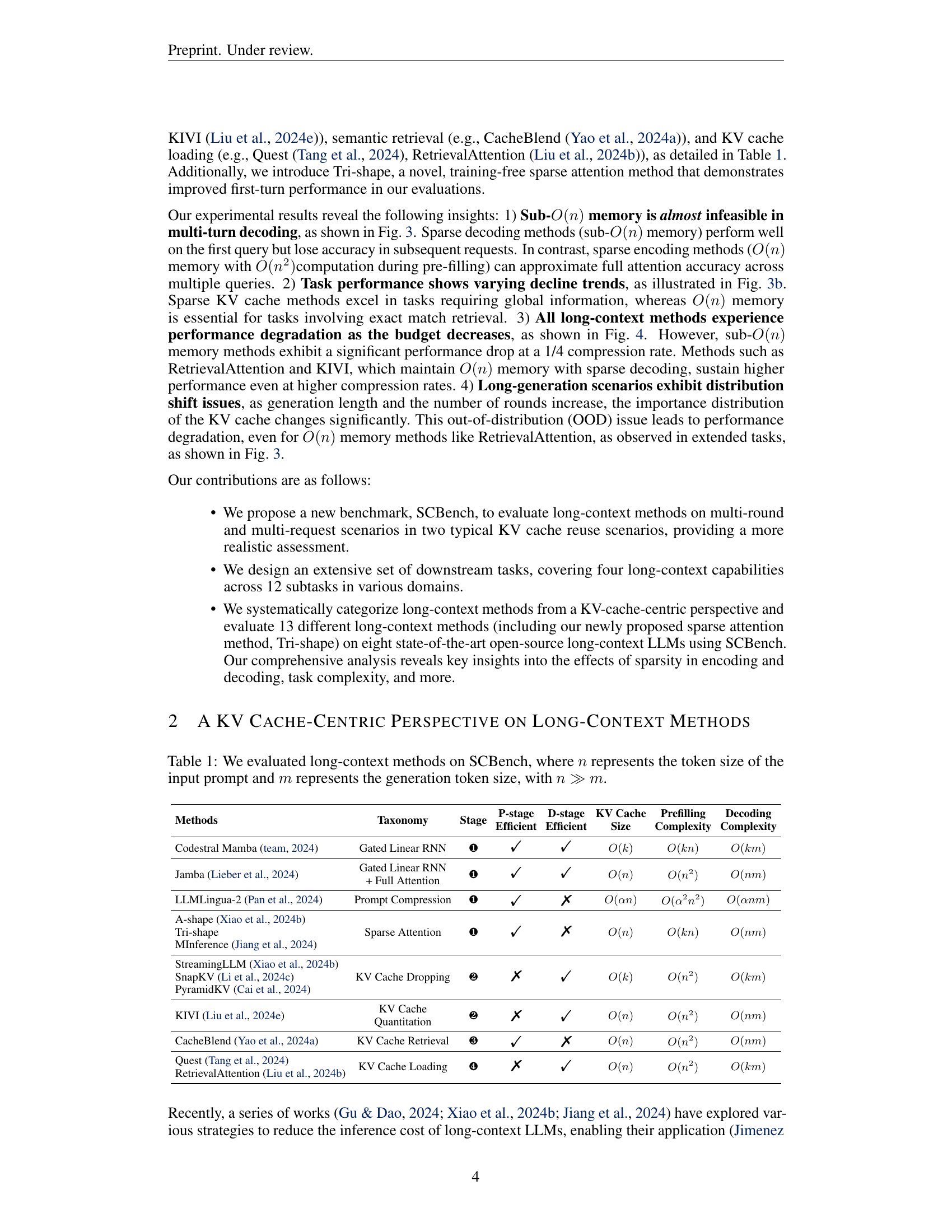
| Methods | Taxonomy | Stage | P-stage Efficient | D-stage Efficient | KV Cache Size | Prefilling Complexity | Decoding Complexity |
|---|---|---|---|---|---|---|---|
| Codestral Mamba (team, 2024) | Gated Linear RNN | ❶ | ✓ | ✓ | O(k) | O(kn) | O(km) |
| Jamba (Lieber et al., 2024) | Gated Linear RNN + Full Attention | ❶ | ✓ | ✓ | O(n) | O(n²) | O(nm) |
| LLMLingua-2 (Pan et al., 2024) | Prompt Compression | ❶ | ✓ | ✗ | O(αn) | O(α²n²) | O(αnm) |
| A-shape (Xiao et al., 2024b) | Sparse Attention | ❶ | ✓ | ✗ | O(n) | O(kn) | O(nm) |
| Tri-shape | Sparse Attention | ❶ | ✓ | ✗ | O(n) | O(kn) | O(nm) |
| MInference (Jiang et al., 2024) | Sparse Attention | ❶ | ✓ | ✗ | O(n) | O(kn) | O(nm) |
| StreamingLLM (Xiao et al., 2024b) | KV Cache Dropping | ❷ | ✗ | ✓ | O(k) | O(n²) | O(km) |
| SnapKV (Li et al., 2024c) | KV Cache Dropping | ❷ | ✗ | ✓ | O(k) | O(n²) | O(km) |
| PyramidKV (Cai et al., 2024) | KV Cache Dropping | ❷ | ✗ | ✓ | O(k) | O(n²) | O(km) |
| KIVI (Liu et al., 2024e) | KV Cache Quantitation | ❷ | ✗ | ✓ | O(n) | O(n²) | O(nm) |
| CacheBlend (Yao et al., 2024a) | KV Cache Retrieval | ❸ | ✓ | ✗ | O(n) | O(n²) | O(nm) |
| Quest (Tang et al., 2024) | KV Cache Loading | ❹ | ✗ | ✓ | O(n) | O(n²) | O(km) |
| RetrievalAttention (Liu et al., 2024b) | KV Cache Loading | ❹ | ✗ | ✓ | O(n) | O(n²) | O(km) |
🔼 This table provides a taxonomy of long-context methods evaluated on SCBench, categorizing them by the stage of optimization (KV Cache Generation, Compression, Retrieval, Loading), the efficiency of their operations (pre-filling and decoding stages), the resulting KV cache size (O(n), O(k)), and the computational complexity of pre-filling and decoding. The table uses ’n’ to represent the input prompt token size and ’m’ for the generation token size, with ’n’ significantly larger than ’m’. A checkmark indicates the method employs an efficient operation at the corresponding stage (P-stage: pre-filling, D-stage: decoding).
read the caption
Table 1: We evaluated long-context methods on SCBench, where n𝑛nitalic_n represents the token size of the input prompt and m𝑚mitalic_m represents the generation token size, with n≫mmuch-greater-than𝑛𝑚n\gg mitalic_n ≫ italic_m.
In-depth insights#
KV Cache Focus#
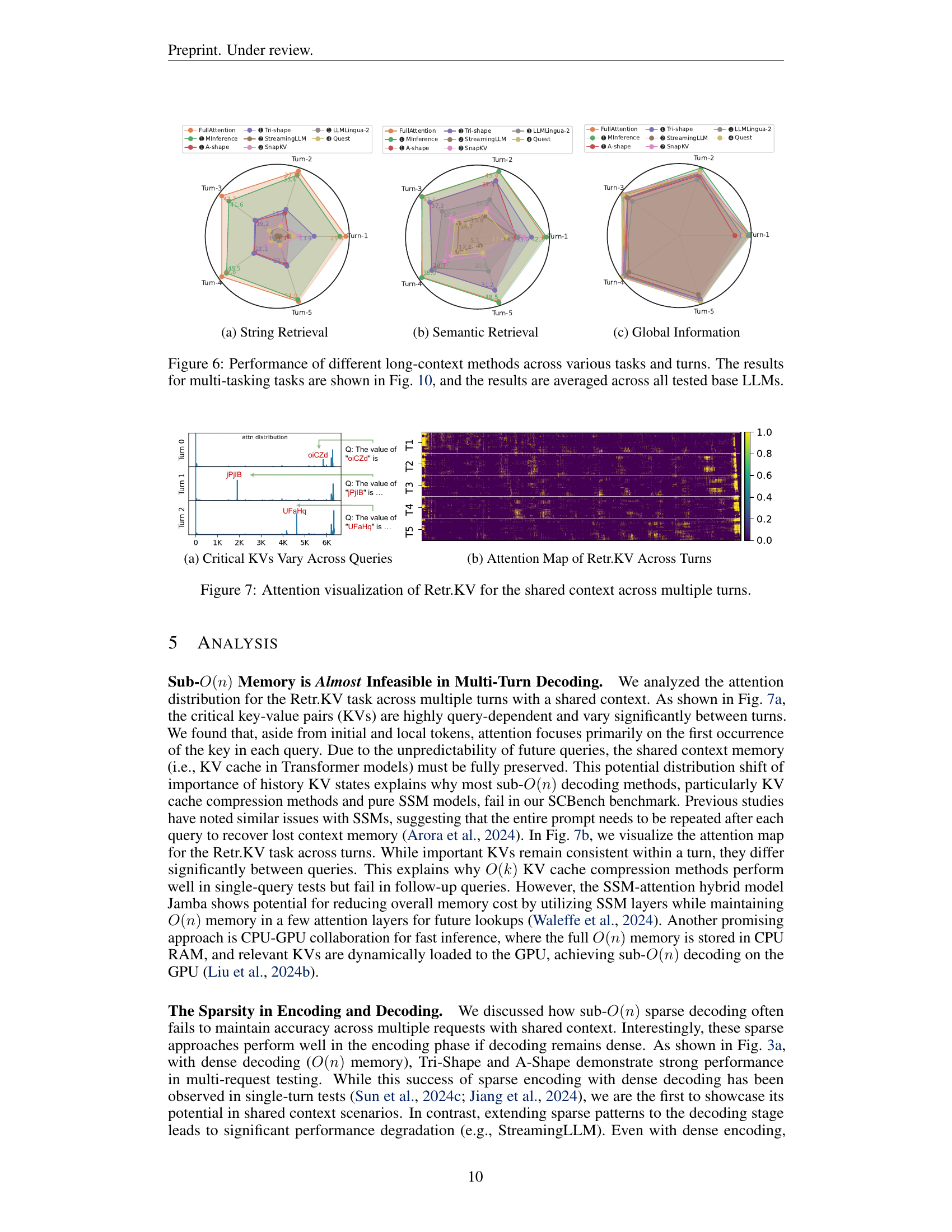
The paper lacks a dedicated “KV Cache Focus” heading, but KV cache optimization is central. It introduces SCBench, a benchmark evaluating long-context LLM performance through a KV cache-centric lens. SCBench assesses KV cache generation, compression, retrieval, and loading, vital for efficient long-context inference. This focus highlights the often-overlooked challenge of KV cache reuse in multi-turn/request scenarios, unlike prior single-request benchmarks. SCBench exposes weaknesses in existing methods, particularly sub-O(n) memory approaches, which struggle in multi-turn settings. It underscores the need for efficient encoding and robust retrieval strategies to maintain performance with extended contexts. By focusing on KV cache, SCBench provides a valuable framework for understanding and improving long-context LLM performance in real-world applications.
SCBench Intro#
SCBench introduces a novel evaluation framework for long-context LLMs, shifting from single-request benchmarks to multi-round/request scenarios mimicking real-world usage, where KV cache reuse is crucial. This addresses the limitations of prior benchmarks which neglect real-world cache behavior, impacting accurate long-context method evaluation. SCBench’s KV cache-centric approach analyzes four key stages: generation, compression, retrieval, and loading, providing a holistic evaluation across diverse tasks like retrieval, QA, and summarization. This comprehensive analysis unveils critical insights into memory efficiency, impact of query awareness in shared context, and the dynamic interplay of sparse attention in encoding vs. decoding phases, ultimately guiding more robust and efficient long-context LLM development.
LongCtx Analysis#
SCBENCH introduces shared-context, multi-round benchmarks evaluating the full KV cache lifecycle (generation, compression, retrieval, loading). Findings reveal sub-O(n) memory methods struggle in multi-turn scenarios due to the importance distribution shift of KV states with varying queries. Sparse encoding with O(n) memory performs robustly, especially with dynamic sparsity. Hybrid architectures show potential with layer-level sparsity. Different tasks exhibit varying compressibility. Prompt compression aids ICL but hinders retrieval. Overall, SCBENCH provides crucial insights into KV cache behavior for realistic long-context LLM evaluation and development.
Perf. Insights#
SCBench, focusing on KV cache reuse, reveals sub-O(n) methods struggle in multi-turn scenarios, especially in complex retrieval tasks. Sparse encoding with O(n) memory performs robustly but requires further sophistication in sparse patterns. Dynamic sparsity methods, like MInference, show promise by adapting better to shifting context importance across turns. Hybrid SSM-attention models offer potential but underperform in SCBench’s shared context modes, suggesting improvement is needed for complex, multi-turn settings. KV Cache compression techniques show limited benefits in shared scenarios. Prompt compression methods are effective for some global tasks, but weak in others. Attention distribution shift in long-generation scenarios adds complexity, emphasizing the need to handle OOD data. Overall, SCBench highlights that balancing efficiency and multi-turn performance remains a key challenge for long-context LLM architectures.
SharedCtx Future#
Shared context scenarios represent a pivotal shift in LLM interaction paradigms, transitioning from isolated queries to continuous, context-rich exchanges. This shift necessitates reevaluating existing long-context methods and benchmarks. Benchmarks should prioritize multi-turn and multi-request settings to reflect real-world usage patterns where context reuse dominates. Optimizing for dynamic context adaptation is crucial, as attention distributions shift across queries. This necessitates exploring advanced sparse attention mechanisms that can dynamically capture critical context elements. Beyond computational efficiency, maintaining instruction-following capabilities in shared context remains paramount. Future research should also explore heterogeneous context integration, where diverse data modalities are dynamically loaded and processed. This holistic approach will shape the next generation of robust and adaptable long-context LLMs.
More visual insights#
More on figures

🔼 The figure shows two shared context modes used for evaluating long-context language models: Multi-turn Mode and Hinted KV Cache Multi-request Mode. In Multi-turn Mode (1), the KV cache generated from previous turns within the same session is reused for subsequent turns. Each turn involves a query (Q) and answer (A) pair, and the LLM stores information from previous turns (Q1, A1, Q2, A2…) in the KV cache. This mode simulates a conversational setting. The Hinted KV Cache Multi-request Mode (2) allows for KV cache reuse across multiple requests, potentially even across different users or sessions. A ‘hinted’ KV cache from a previous request is provided as input, alongside the new request. This mode emulates scenarios like code repository access where multiple users interact with a shared context. Both modes assess an LLM’s ability to leverage and access information stored in the KV cache to efficiently respond to subsequent queries or requests within and across contexts.
read the caption
(a) Two Shared Context Modes

🔼 SCBench assesses four key long-context abilities (string retrieval, semantic retrieval, global information, and multi-tasks) across 12 tasks with two shared context modes (multi-turns, multi-requests). Each test example includes a shared context and multiple follow-up queries.
read the caption
(b) Overview of SCBench

🔼 Figure 2 visualizes the concept of shared contexts in long-context tasks, which is central to the SCBench evaluation. Subfigure (a) illustrates two common shared-context patterns: 1) A multi-turn dialogue where context is carried within a single session. 2) A multi-request scenario where context is shared across multiple sessions, even potentially with different users (like a shared code repository). Subfigure (b) offers an overview of SCBench, categorized by long-context capabilities (String Retrieval, Semantic Retrieval, Global Information, and Multi-tasking) and shared context modes (Multi-turn and Multi-request). This overview shows how the benchmark covers a broad range of long-context scenarios and abilities, all focused on evaluating the effectiveness of KV cache mechanisms.
read the caption
Figure 2: Long-context tasks often involve contexts sharing, e.g., multi-turn dialogues, multi-step reasoning, and repository-level tasks. (a) Illustration of two common shared-context patterns. (b) Overview of tasks and scenarios covered by our benchmark, encompassing four categories of long-context abilities and two shared-context modes.

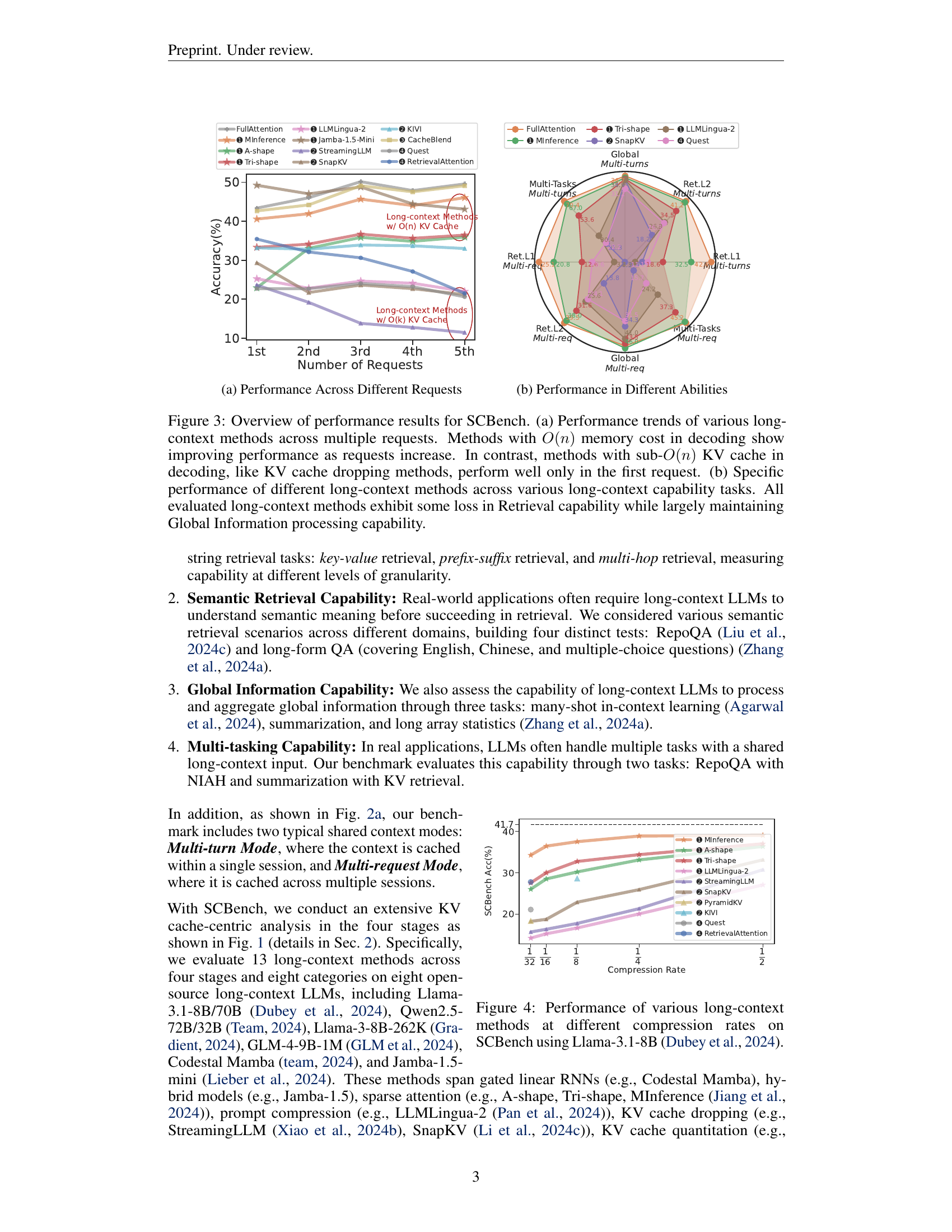
🔼 This figure, located in the ‘Experiments & Results’ section, illustrates how various long-context methods perform when handling multiple requests involving a shared context. Specifically, it shows the accuracy of these methods on a set of tasks designed to test their ability to retrieve and utilize information from a lengthy input. The x-axis represents the number of requests made, while the y-axis represents the accuracy achieved. Different lines represent different long-context methods, categorized by their memory usage during decoding (either O(n) or sub-O(n)). The key takeaway is that methods with O(n) memory usage show improving performance as the number of requests increases, whereas methods with sub-O(n) memory only perform well on the initial request but struggle with subsequent ones. This highlights the importance of memory capacity in handling multiple requests that rely on a shared context.
read the caption
(a) Performance Across Different Requests

🔼 This radar chart displays the performance of different long-context methods across various task categories, including Retrieval L1, Retrieval L2, Global Information, and Multi-tasks, in both multi-turns and multi-requests settings. Each vertex of the radar chart represents a task category, and the distance from the center indicates the average performance of a given method on that task. The shaded area enclosed by the connected points represents the overall performance profile of a long-context method. Different colors are used to distinguish between different methods, allowing for easy comparison of their strengths and weaknesses across different task categories. Figure 3b shows that long context models show a performance drop on Retrieval L1 task, where methods with O(n) memory cost outperform other methods by a large margin. While methods with sub-O(n) memory cost achieve close performance on other task categories, and even slightly outperform O(n) method on Multi-task.
read the caption
(b) Performance in Different Abilities

🔼 This figure provides a general overview of how different long-context methods performed in SCBench across different tasks and scenarios. Figure 3(a) showcases the performance trends of various long-context methods as the number of requests increases in SCBench. The x-axis represents the number of requests, while the y-axis represents the accuracy. The methods are categorized based on their KV cache memory costs during decoding: O(n) (linear) and sub-O(n) (sublinear). The plot shows that methods with linear memory costs generally improve or maintain their performance as requests increase, while methods with sublinear memory costs often perform well only in the first request but degrade as requests increase. Figure 3(b) displays the specific performance of each long-context method on different long-context capability tasks. The x-axis represents the four capabilities: Retrieval L1, Retrieval L2, Global Information, and Multi-tasks. The y-axis represents the accuracy. Each capability is further divided into multi-turn and multi-request scenarios. The radar chart shows that almost all long-context methods exhibit some loss in retrieval capability while largely maintaining global information processing capability.
read the caption
Figure 3: Overview of performance results for SCBench. (a) Performance trends of various long-context methods across multiple requests. Methods with O(n)𝑂𝑛O(n)italic_O ( italic_n ) memory cost in decoding show improving performance as requests increase. In contrast, methods with sub-O(n)𝑂𝑛O(n)italic_O ( italic_n ) KV cache in decoding, like KV cache dropping methods, perform well only in the first request. (b) Specific performance of different long-context methods across various long-context capability tasks. All evaluated long-context methods exhibit some loss in Retrieval capability while largely maintaining Global Information processing capability.

🔼 This figure evaluates the performance of various long-context methods on SCBench with varying compression rates using the Llama-3.1-8B model as a base. Compression rate refers to the ratio between the size of the compressed KV cache and the original one. The x-axis of the plot is the compression rate, and the y-axis is the average accuracy across all SCBench tasks under the multi-request setting. Each line in the graph corresponds to one specific long-context method with varying compression rates, illustrating how performance changes with memory reduction. Lower compression rates signify higher memory savings but potentially larger performance drops, highlighting the trade-off between efficiency and effectiveness. The observation is that most methods can maintain reasonable performance when the compression rates are above 1/4, as the context can still be captured even with a certain level of compression or sparsity. However, as the compression rate grows larger, the model will lack important information or connectivity for proper generation, which explains the substantial performance degradation for all the approaches at a 1/8 compression rate or lower.
read the caption
Figure 4: Performance of various long-context methods at different compression rates on SCBench using Llama-3.1-8B (Dubey et al., 2024).

🔼 This figure visually compares two sparse attention patterns: A-shape and Tri-shape. The triangular shape within the attention matrix represents the areas where attention is focused. The sink, local, and last window query regions are highlighted. Tri-shape includes an additional last window query region compared to A-shape.
read the caption
Figure 5: The sparse attention methods framework.

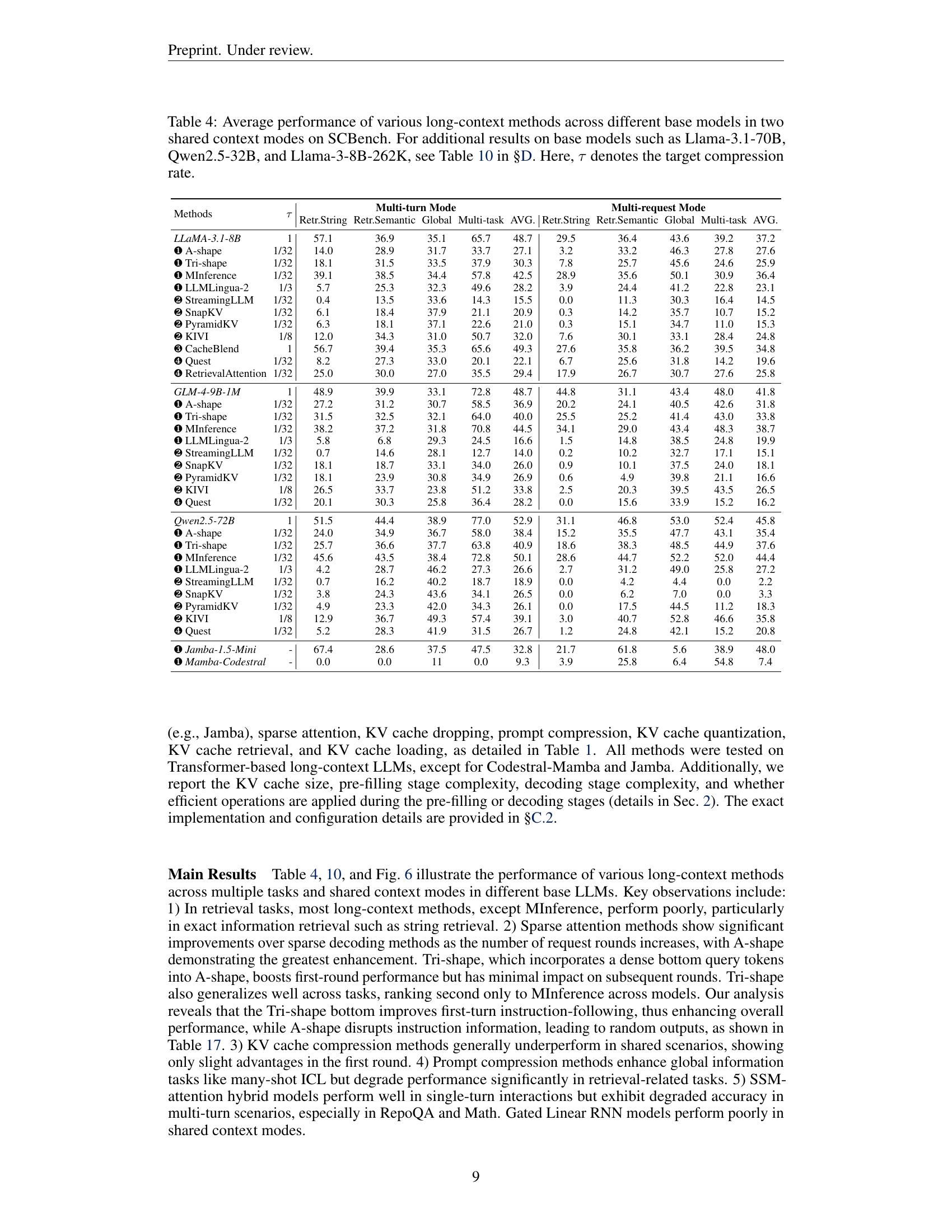
🔼 This figure, located in Section 4 (Experiments & Results), illustrates the performance of various long-context methods, specifically for string retrieval tasks, over multiple turns. It shows how the accuracy of different methods changes as the conversation progresses (from Turn 1 to Turn 5). The comparison includes methods like Full Attention, A-Shape, Tri-Shape, MInference, StreamingLLM, SnapKV, LLMLingua-2, and Quest, all evaluated against a baseline LLM. The x-axis represents the turn number, while the y-axis indicates the task accuracy. This visualization helps to understand how well different approaches maintain performance in string retrieval as more context is added to the conversation.
read the caption
(a) String Retrieval

🔼 Figure 3 (b) presents the performance of various long-context methods on semantic retrieval tasks within SCBench. The figure shows how each method performs across four key sub-categories of semantic retrieval, providing a visual comparison of their effectiveness in this specific capability area. It allows for the evaluation of how well different optimizations for handling long sequences perform when tasked with understanding meaning and context, rather than just matching strings.
read the caption
(b) Semantic Retrieval

🔼 This figure, belonging to the ‘Experiments & Results’ section, presents the performance of various long-context methods on Global Information tasks and turns within SCBench. These tasks assess the models’ capacity to process and aggregate information from the entire context, encompassing areas like summarization, statistical tasks, and in-context learning. The downward trend across turns for several methods indicates potential challenges in maintaining performance with increased context length or repeated queries within the same context. This visualization allows for comparisons between sparse and dense methods, prompt compression techniques, and hybrid models in managing global information effectively.
read the caption
(c) Global Information

🔼 This figure, located in Section 4 of the paper, presents a performance comparison of various long-context methods (Full Attention, A-shape, Tri-shape, MInference, StreamingLLM, SnapKV, LLMLingua-2, Quest) across different tasks and conversation turns in the SCBench. The tasks are categorized into three main groups: String Retrieval, Semantic Retrieval, and Global Information. The figure shows the accuracy trends of each method across five conversation turns (Turn 1 to Turn 5). The results for multi-tasking tests are presented in Figure 10. The results are averaged across all the base LLMs tested in the benchmark.
read the caption
Figure 6: Performance of different long-context methods across various tasks and turns. The results for multi-tasking tasks are shown in Fig. 10, and the results are averaged across all tested base LLMs.
More on tables
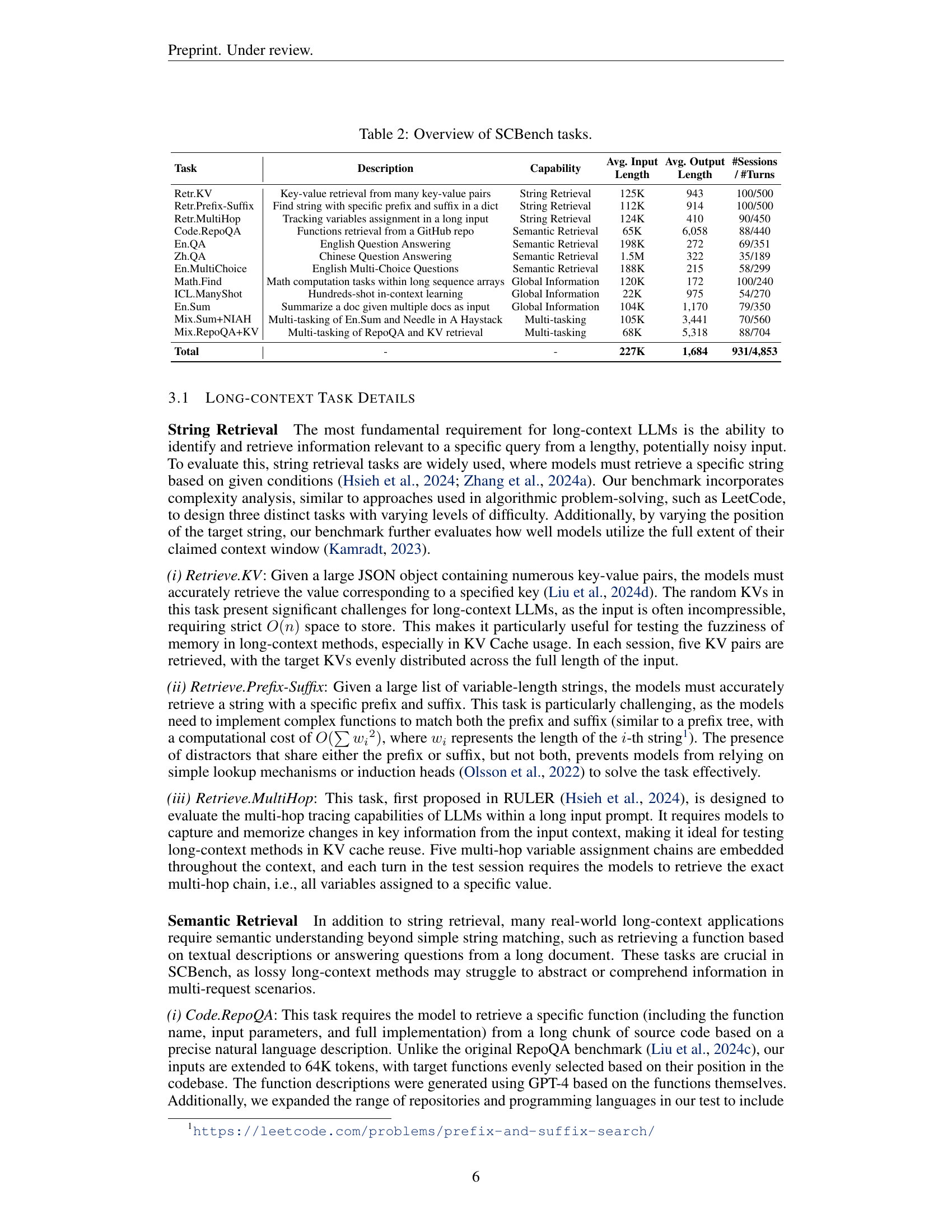
| Task | Description | Capability | Avg. Input Length | Avg. Output Length | #Sessions / #Turns |
|---|---|---|---|---|---|
| Retr.KV | Key-value retrieval from many key-value pairs | String Retrieval | 125K | 943 | 100/500 |
| Retr.Prefix-Suffix | Find string with specific prefix and suffix in a dict | String Retrieval | 112K | 914 | 100/500 |
| Retr.MultiHop | Tracking variables assignment in a long input | String Retrieval | 124K | 410 | 90/450 |
| Code.RepoQA | Functions retrieval from a GitHub repo | Semantic Retrieval | 65K | 6,058 | 88/440 |
| En.QA | English Question Answering | Semantic Retrieval | 198K | 272 | 69/351 |
| Zh.QA | Chinese Question Answering | Semantic Retrieval | 1.5M | 322 | 35/189 |
| En.MultiChoice | English Multi-Choice Questions | Semantic Retrieval | 188K | 215 | 58/299 |
| Math.Find | Math computation tasks within long sequence arrays | Global Information | 120K | 172 | 100/240 |
| ICL.ManyShot | Hundreds-shot in-context learning | Global Information | 22K | 975 | 54/270 |
| En.Sum | Summarize a doc given multiple docs as input | Global Information | 104K | 1,170 | 79/350 |
| Mix.Sum+NIAH | Multi-tasking of En.Sum and Needle in A Haystack | Multi-tasking | 105K | 3,441 | 70/560 |
| Mix.RepoQA+KV | Multi-tasking of RepoQA and KV retrieval | Multi-tasking | 68K | 5,318 | 88/704 |
| Total | - | - | 227K | 1,684 | 931/4,853 |
🔼 SCBench tasks are categorized by capability (String Retrieval, Semantic Retrieval, Global Information, Multi-tasking) and include metrics, average input/output lengths, and the number of sessions/turns.
read the caption
Table 2: Overview of SCBench tasks.
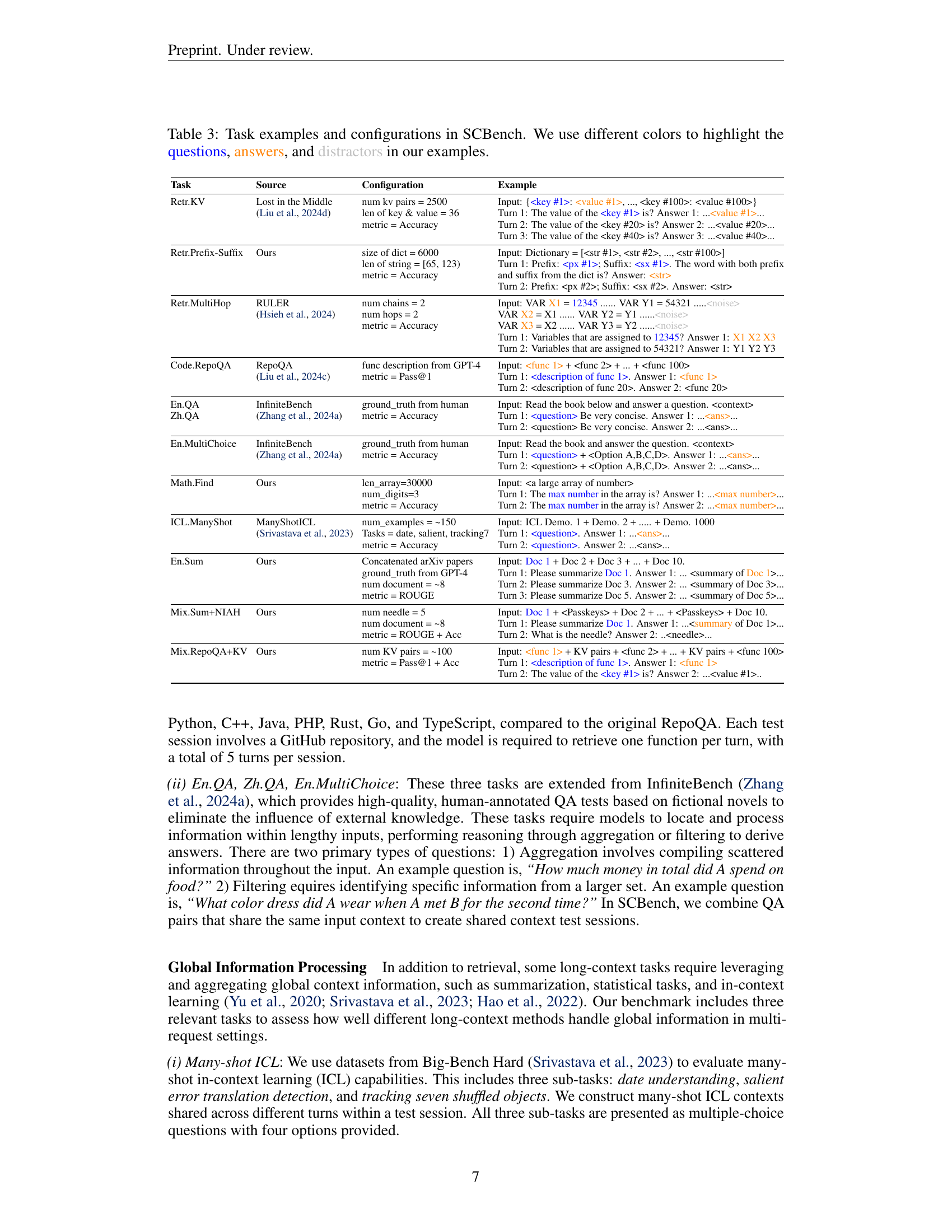
| Task | Source | Configuration | Example |
|---|---|---|---|
| Retr.KV | Lost in the Middle (Liu et al., 2024d) | num kv pairs = 2500 len of key & value = 36 metric = Accuracy | Input: {<key #1>: <value #1>, …, <key #100>: <value #100>}Turn 1: The value of the <key #1> is? Answer 1: …<value #1>…Turn 2: The value of the <key #20> is? Answer 2: …<value #20>…Turn 3: The value of the <key #40> is? Answer 3: …<value #40>… |
| Retr.Prefix-Suffix | Ours | size of dict = 6000 len of string = [65, 123) metric = Accuracy | Input: Dictionary = [<str #1>, <str #2>, …, <str #100>]Turn 1: Prefix: <px #1>; Suffix: <sx #1>. The word with both prefix and suffix from the dict is? Answer: <str>Turn 2: Prefix: <px #2>; Suffix: <sx #2>. Answer: <str> |
| Retr.MultiHop | RULER (Hsieh et al., 2024) | num chains = 2 num hops = 2 metric = Accuracy | Input: VAR <X1> = 12345 …… VAR <Y1> = 54321 …..<noise>VAR <X2> = X1 …… VAR Y2 = Y1 ……<noise>VAR <X3> = X2 …… VAR Y3 = Y2 ……<noise>Turn 1: Variables that are assigned to 12345? Answer 1: <X1 X2 X3>Turn 2: Variables that are assigned to 54321? Answer 1: Y1 Y2 Y3 |
| Code.RepoQA | RepoQA (Liu et al., 2024c) | func description from GPT-4 metric = Pass@1 | Input: <func 1> + <func 2> + … + <func 100>Turn 1: <description of func 1>. Answer 1: <func 1>Turn 2: <description of func 20>. Answer 2: <func 20> |
| En.QA Zh.QA | InfiniteBench (Zhang et al., 2024a) | ground_truth from human metric = Accuracy | Input: Read the book below and answer a question. <context>Turn 1: <question> Be very concise. Answer 1: …<ans>…Turn 2: <question> Be very concise. Answer 2: …<ans>… |
| En.MultiChoice | InfiniteBench (Zhang et al., 2024a) | ground_truth from human metric = Accuracy | Input: Read the book and answer the question. <context>Turn 1: <question> + <Option A,B,C,D>. Answer 1: …<ans>…Turn 2: <question> + <Option A,B,C,D>. Answer 2: …<ans>… |
| Math.Find | Ours | len_array=30000 num_digits=3 metric = Accuracy | Input: <a large array of number>Turn 1: The <max number> in the array is? Answer 1: …<max number>…Turn 2: The <max number> in the array is? Answer 2: …<max number>… |
| ICL.ManyShot | ManyShotICL (Srivastava et al., 2023) | num_examples = ~150 Tasks = date, salient, tracking7 metric = Accuracy | Input: ICL Demo. 1 + Demo. 2 + ….. + Demo. 1000 Turn 1: <question>. Answer 1: …<ans>…Turn 2: <question>. Answer 2: …<ans>… |
| En.Sum | Ours | Concatenated arXiv papers ground_truth from GPT-4 num document = ~8 metric = ROUGE | Input: <Doc 1> + Doc 2 + Doc 3 + … + Doc 10.Turn 1: Please summarize <Doc 1>. Answer 1: … <summary of Doc 1>…Turn 2: Please summarize Doc 3. Answer 2: … <summary of Doc 3>…Turn 3: Please summarize Doc 5. Answer 2: … <summary of Doc 5>… |
| Mix.Sum+NIAH | Ours | num needle = 5 num document = ~8 metric = ROUGE + Acc | Input: <Doc 1> + <Passkeys> + Doc 2 + … + <Passkeys> + Doc 10.Turn 1: Please summarize <Doc 1>. Answer 1: …<summary> of Doc 1…Turn 2: What is the needle? Answer 2: .. <needle>… |
| Mix.RepoQA+KV | Ours | num KV pairs = ~100 metric = Pass@1 + Acc | Input: <func 1> + KV pairs + <func 2> + … + KV pairs + <func 100>Turn 1: <description of func 1>. Answer 1: <func 1>Turn 2: The value of the <key #1> is? Answer 2: …<value #1>.. |
🔼 This table provides examples and configurations for the tasks included in SCBench. It showcases the diversity of tasks, including string retrieval, semantic retrieval, global information processing, and multi-tasking, across various domains like code, retrieval, question answering, summarization, in-context learning, multi-hop tracing, and multi-tasking. The table illustrates the input format, expected output, evaluation metrics, and specific configurations (e.g., number of key-value pairs, dictionary size, number of chains/hops, etc.) for each task. Color-coding is used to distinguish between questions, correct answers, and distractor information within the examples.
read the caption
Table 3: Task examples and configurations in SCBench. We use different colors to highlight the questions, answers, and distractors in our examples.
🔼 This table presents the average performance of various long-context methods, evaluated across different base large language models (LLMs). The evaluation uses SCBench, a new benchmark designed to assess performance in scenarios involving shared context and multiple rounds or requests. These scenarios are common in real-world applications, where the same context (e.g., a conversation history) is reused across multiple interactions. The table is divided based on two ‘shared context modes’: Multi-turn Mode, where the context is cached within a single session (like a continuous conversation), and Multi-request Mode, where the context is cached across multiple sessions (like different users interacting with the same information source). The metrics reported are average performance scores across various tasks within SCBench, covering string retrieval, semantic retrieval, global information processing, and multi-tasking capabilities of LLMs. The table also includes a compression rate (τ), indicating the level of context compression applied by certain methods.
read the caption
Table 4: Average performance of various long-context methods across different base models in two shared context modes on SCBench. For additional results on base models such as Llama-3.1-70B, Qwen2.5-32B, and Llama-3-8B-262K, see Table 10 in §D. Here, τ𝜏\tauitalic_τ denotes the target compression rate.
| Lost in the Middle |
|---|
| (Liu et al., 2024d) |
🔼 This table presents a comparison of the performance of three query-aware long-context methods on a subset of SCBench tasks. The methods include SnapKV (KV cache dropping), Tri-shape (sparse attention), and MInference (dynamic sparse attention). Results are shown for Llama-3.1-8B with and without the query provided during inference, to assess the impact of query awareness on performance in KV cache reuse scenarios. The metrics used are Retr.String (string retrieval), Retr.Semantic (semantic retrieval), Global (Global Information), and Multi-task, representing different capabilities of long-context models. The underlined values represent the scores of methods when the query is NOT provided during the later rounds of testing.
read the caption
Table 5: Results of query-awareness long-context methods. w/ (first) and w/o (later) query.
| num kv pairs = 2500 | |
|---|---|
| len of key & value = 36 | |
| metric = Accuracy |
🔼 This table compares existing long-context benchmarks, including LongBench, InfiniteBench, RULER, LongCTXBench, HELMET, Michelangelo, and SCBench (the benchmark introduced in this paper). The comparison focuses on several key aspects: the types of long-context capabilities assessed by each benchmark (precise retrieval, semantic retrieval, global information processing, and multi-tasking), the types of requests considered (single question, multi-turn, and multi-request), and whether the benchmark’s implementation involves reusing the key-value cache, a crucial aspect for efficient handling of long contexts.
read the caption
Table 6: Comparison of Long-Context Benchmarks.
| Retr.Prefix-Suffix |
|---|
🔼 This table presents a comparison of the summarization capabilities of various efficient long-context methods, using both prior benchmarks (InfiniteBench and LongBench) and the newly introduced SCBench. Results are presented for various turns in multi-request scenarios in SCBench, as well as overall performance on InfiniteBench and LongBench. This comparison aims to highlight the unique insights offered by SCBench, especially in evaluating performance under multi-request settings which are not typically covered by existing benchmarks. The table demonstrates how SCBench can reveal the strengths and weaknesses of different long-context methods in handling summarization tasks, particularly their ability to maintain performance across multiple requests within a shared context.
read the caption
Table 7: Comparing the summarization capability of efficient long-context methods on prior benchmarks and our SCBench.
🔼 This table compares the retrieval performance of various efficient long-context methods on existing benchmarks (InfiniteBench and LongBench) and the newly proposed SCBench. It focuses on string retrieval tasks and includes results for different request modes (multi-request, turn 1-5). The goal is to highlight how these methods perform in retrieving information from long sequences, particularly when the context is reused across multiple queries.
read the caption
Table 8: Comparing the retrieval capability of efficient long-context methods on prior benchmarks and our SCBench.
| size of dict = 6000 | |
|---|---|
| len of string = [65, 123) | |
| metric = Accuracy |
🔼 This table provides a comprehensive overview of the configurations used for various long-context methods evaluated in SCBench. It details specific settings for each method, including parameters for State Space Models (SSMs), Mamba-Attention hybrid architectures, sparse attention mechanisms (A-shape, Tri-shape, MInference), KV cache compression techniques (StreamingLLM, PyramidKV, SnapKV), KV cache quantization (KIVI), KV cache retrieval (CacheBlend), prompt compression (LLMLingua-2), and KV cache loading (Quest, RetrievalAttention). These configurations provide insights into the architectural choices and hyperparameter settings that enable efficient long-context modeling within the benchmark.
read the caption
Table 9: Configurations of long-context methods in SCBench.
| Retr.MultiHop |
|---|
🔼 This table presents the average results of various long-context methods evaluated on three large language models (LLMs): Llama-3.1-70B, Qwen2.5-32B, and Llama-3-8B-262K. The evaluation is conducted using SCBench, a new benchmark designed to assess long-context LLM performance. Results are shown for two shared context modes: multi-turn and multi-request. The table breaks down the performance for four key long-context capabilities: string retrieval, semantic retrieval, processing global information, and multi-tasking. An average score across all tasks is also provided. This comparison allows for analysis of how different long-context methods and varying model sizes affect performance in different context scenarios.
read the caption
Table 10: The average results of various long-context methods on Llama-3.1-70B, Qwen2.5-32B, and Llama-3-8B-262K with two shared context modes on SCBench.
| RULER |
|---|
| Hsieh et al., 2024 |
🔼 This table presents a detailed breakdown of the performance results of various long-context methods on each individual sub-task within SCBench, specifically focusing on the multi-turn mode. This mode evaluates how well these methods maintain performance when the context is carried over across multiple conversational turns. The table provides insights into the strengths and weaknesses of different methods on a granular level, offering a more nuanced understanding of their capabilities in handling various tasks like retrieval, question answering, summarization, and multi-tasking within an ongoing dialogue or multi-turn scenario.
read the caption
Table 11: The results breakdown of SCBench for all sub-tasks in multi-turn mode.
| num chains = 2 |
|---|
| num hops = 2 |
| metric = Accuracy |
🔼 This table presents a detailed breakdown of the performance of various long-context language models on the SCBench benchmark, specifically focusing on the multi-request mode. It covers numerous sub-tasks within four key categories: String Retrieval (Retr.KV, Retr.PS, Retr.MH), Semantic Retrieval (RepoQA, En.QA, Zh.QA, En.MC), Global Information (ICL, En.Sum, Math.Find), and Multi-tasking (Mix.Sum+NIAH, Mix.RepoQA+KV). The results are presented as scores for each model on each sub-task, allowing for a granular comparison of performance and an analysis of strengths and weaknesses across different task types and models within a multi-request context where a single context is shared among multiple requests.
read the caption
Table 12: The results breakdown of SCBench for all sub-tasks in multi-requests mode.
| Code.RepoQA |
|---|
🔼 This table compares the performance of a long-context language model (Llama-3.1-8B) and several efficient long-context methods (A-shape, Tri-shape, StreamingLLM, MInference) across multiple turns of a conversation when model-generated answers from previous turns are used as context for subsequent turns, unlike the main experiments where ground-truth answers were used. The table highlights the performance difference (positive or negative) compared to using ground-truth answers, offering insights into the impact of error propagation and how different models handle context generated by themselves.
read the caption
Table 13: Results when disabling golden answer as context. The later number indicate the gap compared to golden-answer-as-context.
| RepoQA |
|---|
| Liu et al., 2024c |
🔼 This table presents a case study of the En.Sum (English Summarization) task, comparing the performance of various large language models (LLMs) and long-context approaches. It includes a ground truth summary and the responses generated by different models and methods, such as Jamba-1.5-Mini, Llama variants, Qwen2.5 variants, as well as Llama models with added A-Shape, Tri-Shape, MInference, and StreamingLLM methods. The table uses blue color to highlight missing information and orange to indicate potential hallucinations or inaccuracies in the generated summaries.
read the caption
Table 14: Case Study of En.Sum. We use blue to indicate mising informaiton, and orange to mark potential hallucination.
| func description from GPT-4 |
|---|
| metric = Pass@1 |
🔼 This table presents a case study of the Retr.Prefix-Suffix task, which evaluates the ability of long-context LLMs and efficient long-context methods to retrieve strings with specific prefixes and suffixes within a large dictionary. It highlights the difference in model responses compared to the ground truth, using orange color to mark these discrepancies. By analyzing these differences, the study aims to showcase the impact of model architecture and efficiency techniques on string retrieval accuracy, especially in scenarios where exact matching of both prefix and suffix is required.
read the caption
Table 15: Case Study of Retr.Prefix-Suffix. Orange is used to mark the difference of model response compared to the ground truth.
| En.QA |
|---|
| Zh.QA |
🔼 This table presents a case study comparing the responses of Llama-3.1-70B and Llama-3.1-70B with MInference on the Mix.RepoQA + KV multi-tasking benchmark. The task involves retrieving a key-value pair and reproducing a Python function. The table highlights differences in function reproduction and minor hallucinations (marked in orange) in the model outputs compared to the ground truth.
read the caption
Table 16: Case Study of Mix.RepoQA + KV. Orange indicate the potential model hallucination.
| InfiniteBench |
|---|
| Zhang et al., 2024a |
🔼 This table presents a case study comparing the performance of A-shape and Tri-shape sparse attention methods on the Retr.KV (key-value retrieval) task. It showcases example responses from Llama-3.1-70B with and without these sparse attention methods, highlighting Tri-shape’s ability to maintain instruction-following capabilities, unlike A-shape, which disrupts task structure and generates incomplete outputs.
read the caption
Table 17: Case Study of Retr.KV to compare A-shape and Tri-shape.
Full paper#