↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Multimodal Models (LMMs) are revolutionizing how we understand and interact with video data. However, designing and training effective video-LMMs is computationally demanding, leading to suboptimal design decisions. Existing video understanding benchmarks lack rigorous analysis, and evaluating on them is computationally expensive and time-consuming. Limited open research restricts progress in video-LMMs due to their complexity and high computational cost. This necessitates a comprehensive study into effective model design and training strategies.
This research explores numerous video-specific design choices for video-LMMs, like video sampling, architectures, data composition, and training schedules. A key finding is Scaling Consistency, where design decisions on smaller models and datasets transfer to larger ones, reducing computational costs. The authors introduce Apollo, a family of LMMs demonstrating state-of-the-art performance on multiple video understanding benchmarks across different model sizes. They also curate ApolloBench, an efficient benchmark suite that reduces evaluation time while improving quality. The research uncovers critical factors driving performance, such as the superiority of fps video sampling and specific vision encoder combinations, providing actionable insights for the research community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large multimodal models (LMMs) applied to video. It provides valuable insights into effective design and training strategies, significantly impacting efficiency and performance in video understanding tasks. The introduction of Scaling Consistency simplifies experimentation, while Apollo and ApolloBench establish new benchmarks and facilitate further progress. This research opens new avenues by highlighting data composition and video sampling. It empowers researchers to develop better video-LMMs.
Visual Insights#

🔼 This figure provides a schematic overview of the comprehensive exploration conducted in the Apollo project, focusing on video-specific design choices within Large Multimodal Models (LMMs). The exploration covers various aspects, from video sampling methods and model architecture to training schedules and data composition strategies. Key findings include the identification of SigLIP as the most effective single encoder for video-LMMs, the potential benefits of combining encoders for improved temporal perception, and the importance of maintaining a specific percentage of text data during fine-tuning for optimal video understanding performance.
read the caption
Figure 1: Apollo exploration. Schematic illustrating our comprehensive exploration of video-specific design choices; critically evaluating the existing conceptions in the field, from video sampling and model architecture to training schedules and data compositions. For example, we found that the SigLIP encoder is the best single encoder for video-LMMs but can be combined with additional encoders to improve temporal perception, and that keeping a ∼10%similar-toabsentpercent10\sim 10\%∼ 10 % text data during fine-tuning is critical for video understanding performance. More insights can be found in Sec. 4 & LABEL:sec:training.
In-depth insights#
Scaling Consistency#
Scaling Consistency observes that design choices in moderately sized multimodal models (2-4B parameters) strongly correlate with outcomes in much larger models. This offers a crucial advantage by reducing computational costs in LMM development, allowing researchers to prototype with smaller models and confidently extrapolate findings to larger ones. This is particularly relevant because traditional scaling laws, computationally expensive for LLMs, are impractical for multimodal models due to the integration of multiple pretrained components. This approach significantly accelerates the exploration of the design space, fostering rapid innovation. Notably, this transferability extends across different model families, highlighting a robustness beyond specific architectures. By leveraging Scaling Consistency, researchers gain efficient access to the behavior of large models without incurring the prohibitive costs of training them, accelerating model development and research progress.
Video-LMM Design#
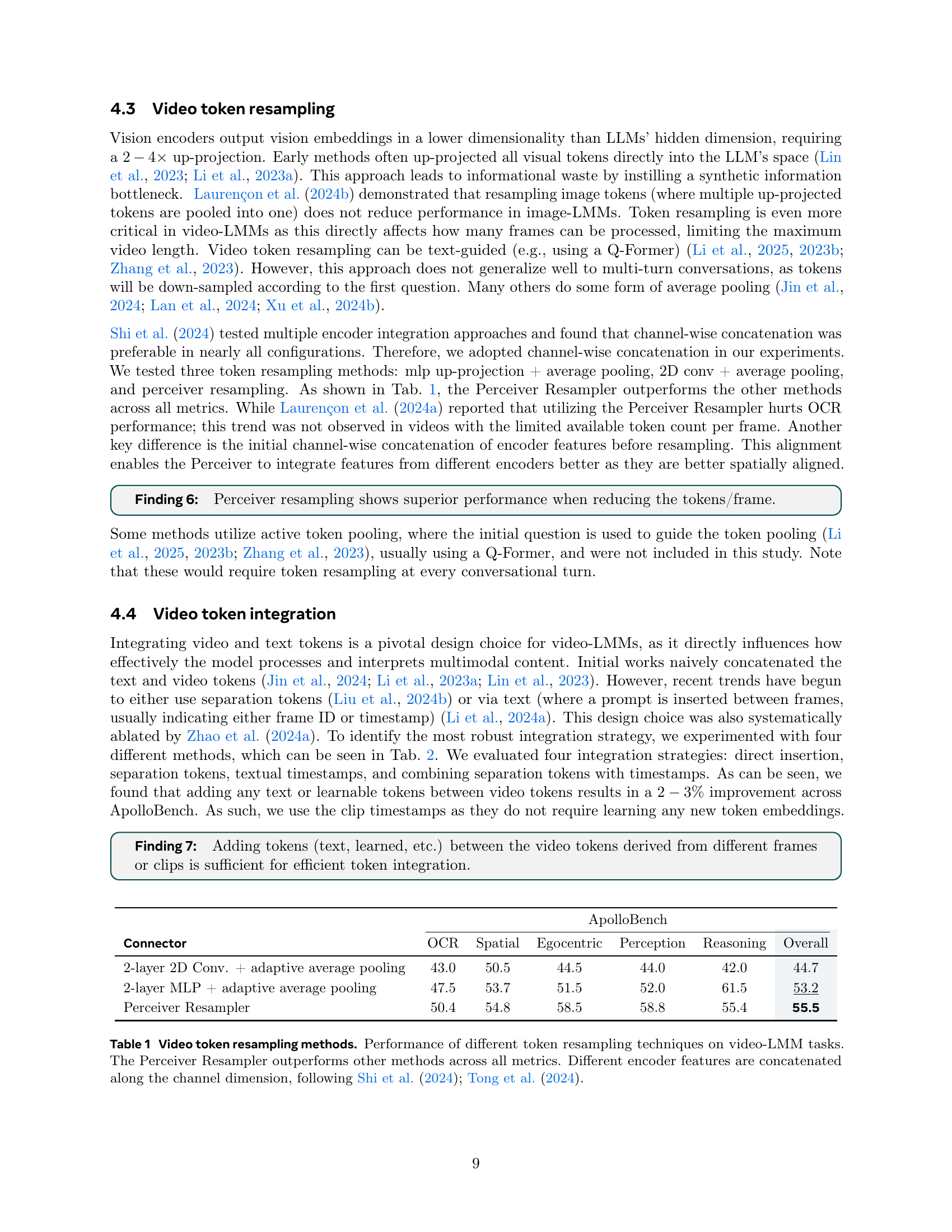
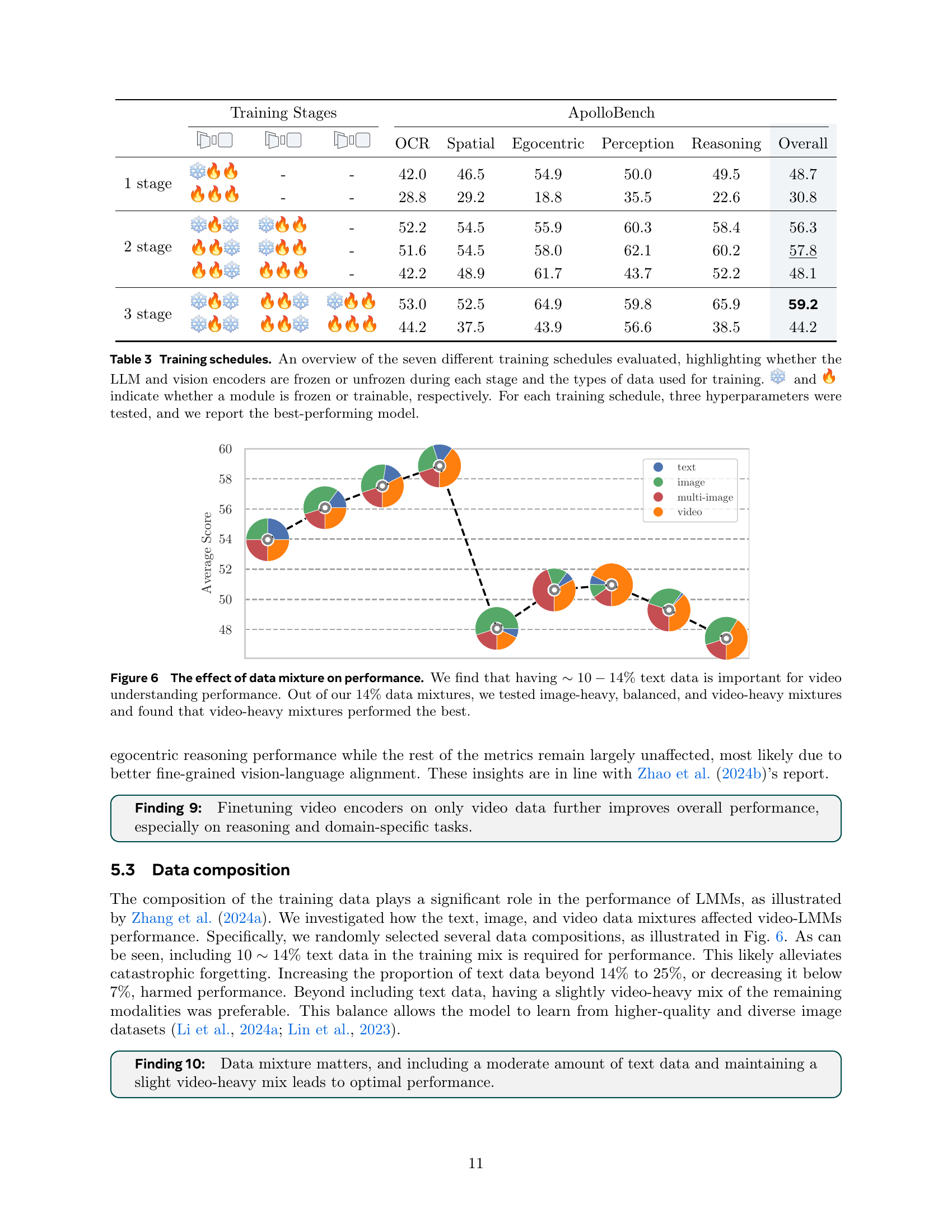
Video-LMM design presents complex challenges. Efficient video sampling is crucial, with fps sampling outperforming uniform sampling for capturing temporal dynamics. Vision encoders significantly impact performance, where language-supervised models generally outperform self-supervised ones, and combining video and image encoders can enhance both spatial and temporal understanding. Efficient token resampling, preferably using a Perceiver Resampler, is vital for handling longer videos, while thoughtful token integration strategies, such as inserting timestamps, improve multi-modal processing. Training procedures also play a key role; multi-stage training with progressive unfreezing of components often yields performance gains. Finally, data composition is crucial, balancing text, image, and video data effectively.
ApolloBench#
ApolloBench, a curated video-LMM benchmark, addresses evaluation inefficiencies and biases in existing benchmarks. Many current video benchmarks are redundant and rely heavily on text comprehension rather than video understanding, as models often perform well with only text or single-frame inputs. ApolloBench prioritizes video perception by filtering out questions solvable without video and focusing on temporal reasoning categories like OCR and egocentric understanding. This makes ApolloBench 41x faster than existing benchmarks while remaining highly correlated with them, offering a more efficient and accurate evaluation of video-LMM performance.
The Apollo Models#
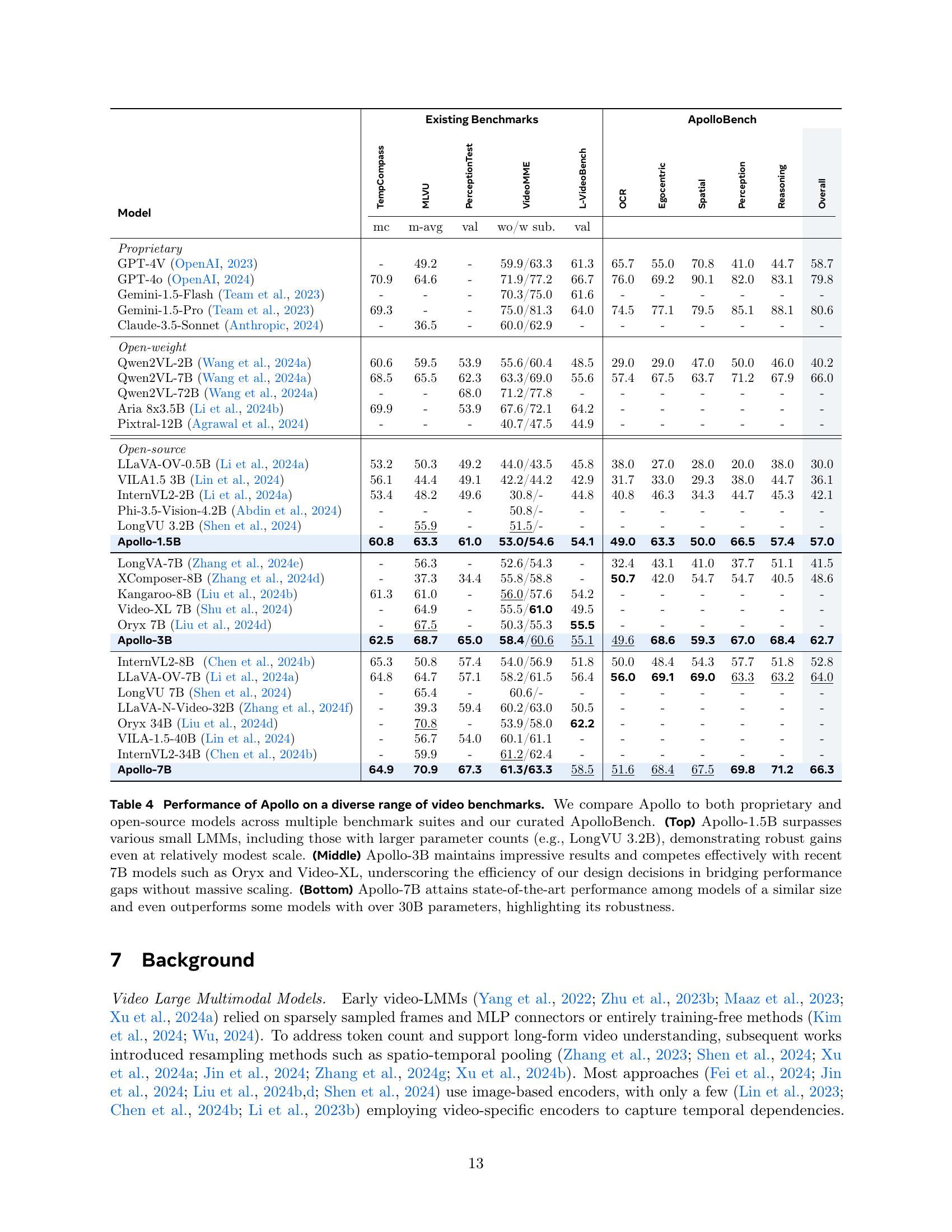
The Apollo models represent a significant advancement in video-LMMs, demonstrating state-of-the-art performance across various benchmarks and model sizes. A key strength lies in their efficiency, often outperforming much larger models. This is achieved through several key design choices validated by extensive experimentation. FPS sampling, critical for capturing temporal dynamics in videos, is prioritized. SigLIP and InternVideo2 encoders, a powerful combination for visual representation, excel at capturing both spatial and temporal information. The use of a Perceiver Resampler optimizes token handling, maximizing efficiency and performance. Multi-stage training, another defining feature, progressively refines the model’s understanding of video content. The data composition during training further enhances this understanding. Notably, Apollo-3B excels, surpassing many 7B models, while Apollo-7B sets a new standard for 7B models, rivaling even larger 30B models. This efficiency and performance make the Apollo models a promising direction for future video-LMM development.
Future of Video-LMMs#
The future of Video-LMMs hinges on addressing key challenges. Unified architectures, while efficient, may limit specialized modality handling. Exploring separate processing streams for images and videos might unlock performance gains. Training video and image encoders during fine-tuning could reveal their contributions, improving training strategies. Memory-based methods like memory banks and retrieval, coupled with text-conditioned pooling, warrant investigation for multi-turn conversations. Dedicated conversational benchmarks are crucial for assessing and enhancing dialogue capabilities. Lastly, expanding training data beyond multiple-choice questions could foster more robust and interactive Video-LMM agents.
More visual insights#
More on figures

🔼 This figure analyzes existing video question-answering benchmarks. The left plot compares open-source LMM performance across different input modalities (full video, single frame, text-only) on various benchmarks. Green bars represent full video performance, red bars single frame performance and blue bars, text-only performance. The light blue shaded area highlights the performance difference between video and text inputs. Yellow shaded area highlights the performance difference between video and single frame image. The right plot is a correlation matrix showing the relationship between model performance across different video benchmarks. The brighter the cell the higher the correlation, indicated a high redundancy amongst those benchmarks.
read the caption
Figure 2: Benchmark Analysis. (Left) Accuracy of the open-source LMMs on various video question-answering benchmarks when provided with different input modalities: full video (green bars), a single frame from the video (red bars), and text-only input without any visual content (blue bars). The light blue shaded areas represent the difference in accuracy between video and text inputs, highlighting the extent to which video perception enhances performance over text comprehension alone. The yellow shaded areas indicate the difference between video and image inputs, quantifying the additional benefit of temporal information from videos compared to static images. (Right) The correlation matrix shows the redundancy among benchmarks by illustrating the correlation coefficients between model performances on different benchmarks. Each cell in the matrix represents how closely the two benchmarks are related in terms of model performance. Our proposed benchmark, ApolloBench, is highly correlated with all tested benchmarks, suggesting that it offers an equally effective evaluation while being more computationally efficient.
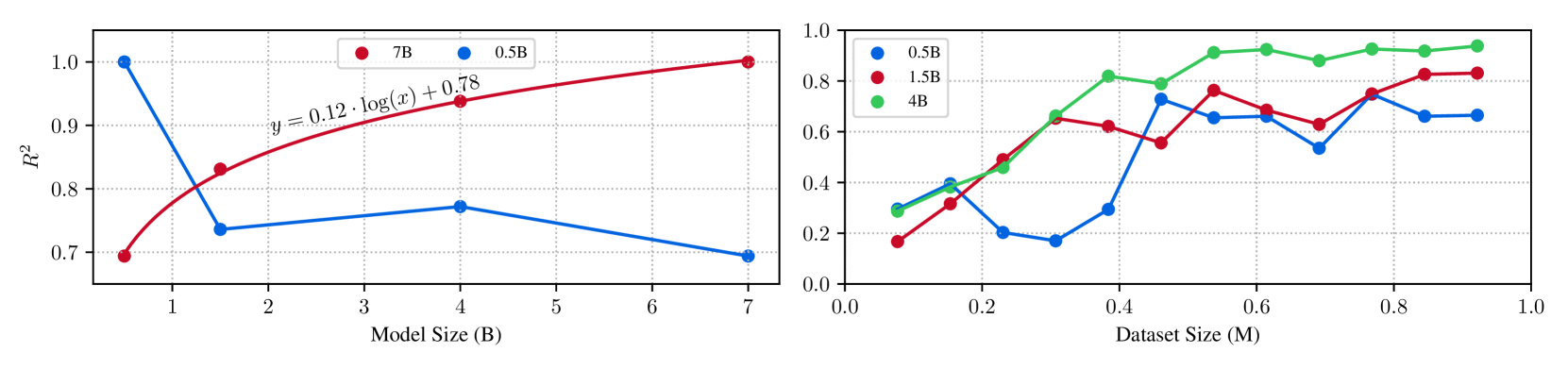
🔼 This figure explores the concept of Scaling Consistency, which means design decisions made using smaller models on smaller datasets effectively transfer to larger models and datasets. The left plot shows the R-squared values of 7B and 0.5B models compared to other LLM sizes. It demonstrates an increasing correlation with larger LLM sizes for the 7B model, while the same trend isn’t observed in the 0.5B model. Interestingly, even when the Qwen1.5-4B model performs similarly to the smaller Qwen2-1.5B model, its correlation to larger models is still higher. The right plot investigates the R-squared correlation of 0.5B/1.5B/4B models to the 7B model concerning dataset size. The correlation tends to plateau around 500k samples, indicating a point of diminishing returns for using larger datasets.
read the caption
Figure 3: Scaling Consistency. We discover Scaling Consistency, where design decisions made with smaller models on smaller datasets carry over to larger models on larger datasets. (Left) R2superscript𝑅2R^{2}italic_R start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT values of 7B and 0.5B versus other LLM sizes show an increasing correlation with larger LLM sizes for the 7B model. The same trend is not seen in the 0.50.50.50.5B model. Interestingly, while the Qwen1.51.51.51.5-4444B model variants have lower/similar performance to their smaller Qwen2−1.521.52-1.52 - 1.5B counterparts, the correlation to larger models is still higher (See App. Fig. LABEL:sup:fig:scaling_consistency). (Right) R2superscript𝑅2R^{2}italic_R start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT of 0.5/1.5/40.51.540.5/1.5/40.5 / 1.5 / 4B models to 7777B vs dataset size. R2superscript𝑅2R^{2}italic_R start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT to larger datasets starts to plateau at around 500500500500K samples.

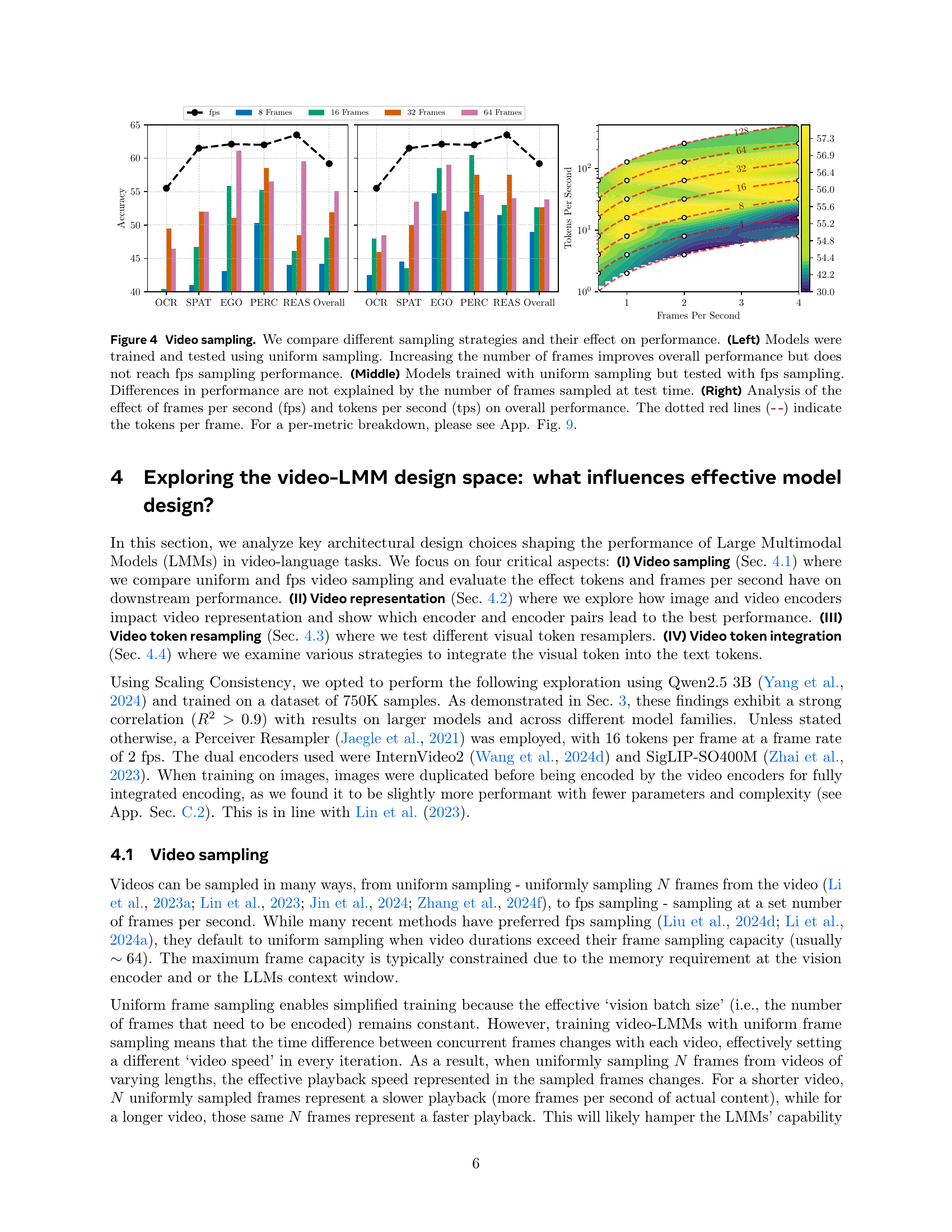
🔼 This figure explores the impact of different video sampling strategies on Large Multimodal Model (LMM) performance. The left plot compares uniform sampling during both training and testing, showing that increasing the number of frames helps but doesn’t match fps sampling. The middle plot demonstrates that the performance difference isn’t solely due to testing differences. The right plot analyzes the effects of frames per second (fps) and tokens per second (tps) on performance, with dotted red lines indicating tokens per frame. Overall, the figure highlights that training with fps sampling is crucial for optimal video understanding in LMMs.
read the caption
Figure 4: Video sampling. We compare different sampling strategies and their effect on performance. (Left) Models were trained and tested using uniform sampling. Increasing the number of frames improves overall performance but does not reach fps sampling performance. (Middle) Models trained with uniform sampling but tested with fps sampling. Differences in performance are not explained by the number of frames sampled at test time. (Right) Analysis of the effect of frames per second (fps) and tokens per second (tps) on overall performance. The dotted red lines (- -) indicate the tokens per frame. For a per-metric breakdown, please see App. Fig. LABEL:sup:fig:full_sampling.

🔼 This figure explores the impact of different vision encoders on video-LMM performance, both individually and in combination. It shows that SigLIP-SO400M is the strongest single encoder, and that combining InternVideo2 with SigLIP-SO400M yields the best overall performance. Additionally, it demonstrates that language-supervised encoders outperform self-supervised models, and video encoders are superior to image encoders for temporal perception tasks.
read the caption
Figure 5: Vision encoders. In our study, we tested InternVideo2 (internvideo2), LanguageBind-Image/Video (languagebind),V-JEPA (vjepa), Video-MAE (videomae), SigLIP-SO400400400400M (siglip), and DINOv2 (dinov2), and their combinations. (Left) SigLIP-SO-400400400400M emerges as the best overall among single encoders. We also find that image encoders underperform in temporal perception compared to video encoders. (Right) Performance of dual-encoder configurations. Language-supervised encoders outperformed their self-supervised counterparts. Combining InternVideo2 and SigLIP-SO-400400400400M leads to the best overall performance.
Full paper#