↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current audio generative models rely heavily on discrete audio tokens, which struggle with long audio sequences due to increased context length. This results in high computational costs, making it challenging to train these models. Traditional continuous representations like spectrograms lack the ability to predict future tokens easily, which makes them not suitable to be used as a stand-alone representation. This limits their ability to generate diverse and high-quality audio. Current methods to circumvent some of these issues either require enormous computing resources or do not provide an efficient path to high-quality audio generation.
This paper proposes Whisper-GPT, a hybrid model that leverages the strengths of both continuous and discrete representations. By combining mel-spectrograms with discrete acoustic tokens, Whisper-GPT efficiently processes long audio contexts. This innovative architecture significantly improves the perplexity and negative log-likelihood scores, demonstrating its effectiveness in predicting future audio tokens and reducing the computational needs compared to purely token-based models, by using fewer parameters and making pre-training these models more accessible. This is done by predicting coarsest acoustic tokens based on this hybrid representation.
Key Takeaways#
Why does it matter?#
Whisper-GPT introduces a novel approach to audio LLMs, merging continuous and discrete representations. This is crucial for researchers exploring efficient long-context audio modeling. The hybrid approach reduces computational burden, enabling broader academic access to advanced audio LLM research and allowing to train audio LLMs on machines which are normally computationally infeasible. The improved perplexity and likelihood scores suggest potential for higher-quality audio generation. The architecture’s flexibility opens up exciting new research directions in hybrid modeling for other modalities.
Visual Insights#

🔼 The figure illustrates two architectures: Whisper (left) and the proposed Generative Whisper-GPT (right). Whisper, an ASR model, uses a Transformer Encoder on mel-spectrogram slices, followed by a Transformer Decoder for next-token prediction. The Generative Whisper-GPT model combines continuous (mel-spectrogram) and discrete (ENCODEC coarse tokens) representations. Spectrogram slices are passed through lightweight decoder blocks, and the learned representation is concatenated with corresponding discrete tokens. This combined input feeds a decoder Transformer stack for next-token prediction, similar to LLM pre-training.
read the caption
Fig. 1: (Left) Whisper Architecture proposed by OpenAI [26] which treats ASR as a sequence to sequence which takes in mel-spectrogram slices and decodes it token by token. It has a Transformer Encoder stack on the spectrogram followed by a Transformer decoder, trained for the shift-by-one token prediction, and the cross-attention module on learned spectrogram representation. (Right) Our generative model combines both continuous and discrete representations. We align the spectrogram and ENCODEC coarse tokens. Instead of a Transformer encoder, we pass spectrogram slices through lightweight decoder blocks. The learned representation per-token slice is concatenated with discrete tokens corresponding to the spectrogram slice to have a decoder Transformer stack, trained on shift by one next token prediction, similar to a typical LLM pre-training.
| Model | # of Param | NLL | Accuracy | PPL |
|---|---|---|---|---|
| Baseline GPT-S | 3.7 million | 2.02 | 34.18% | 7.54 |
| GPT-L | 40 million | 1.94 | 34.82% | 6.96 |
| Hyrbid LLM | 4 million | 1.93 | 35.05% | 6.96 |
🔼 This table compares the performance of three different models on the LibriSpeech dataset using negative log-likelihood (NLL), accuracy, and perplexity (PPL) as metrics. The models compared are a baseline small GPT, a larger GPT (10x the size of small GPT), and the proposed hybrid model. The hybrid model combines continuous audio representation with discrete tokens and is shown to outperform the larger GPT model despite having fewer parameters.
read the caption
Table 1: Negative-log likelihood (NLL) and Perplexity (PPL) scores for our proposed hybrid architecture, baseline GPT-Small and a GPT-Large 10 times larger than GPT-Small for LibriSpeech.
In-depth insights#
Hybrid LLM for Audio#
Hybrid LLMs for audio offer a compelling approach to generating realistic and nuanced sound. By combining continuous representations like spectrograms with discrete tokens, these models capture both the fine-grained details and broader structural patterns within audio. This approach leverages the strengths of both representations, improving next-token prediction accuracy and mitigating limitations of solely token-based or continuous models. The hybrid approach facilitates longer context modeling, crucial for audio where sequential dependencies span extended periods. It also enables more efficient training, mitigating the computational burden associated with processing long sequences of tokens alone. Moreover, it addresses the limitations of current discrete-based approaches by providing richer temporal detail and overcoming the sampling and diversity challenges in purely continuous models. This advancement holds promise for enhanced audio synthesis, editing, and understanding tasks, paving the way for more sophisticated and creative audio applications.
Continuous & Discrete Fusion#
Fusing continuous and discrete data representations offers a powerful approach to enhance model performance in various domains. Continuous data, like audio waveforms or images, provides rich, nuanced information, while discrete representations, such as tokens, allow for efficient processing and symbolic manipulation. By combining these modalities, models can leverage both fine-grained details and high-level abstractions. This fusion can be achieved through various mechanisms, such as early fusion where representations are combined at the input level, or late fusion where separate model branches process each modality before merging their outputs. Hybrid architectures, like Whisper-GPT, exemplify this approach, demonstrating significant improvements in tasks like audio language modeling. The challenge lies in effectively integrating these diverse data types, aligning their temporal or spatial relationships, and managing the increased computational complexity. Further exploration of fusion techniques, particularly for tasks involving sequential data, is crucial for realizing the full potential of hybrid models.
Whisper-Inspired Arch.#
The Whisper-inspired architecture adapts the Whisper ASR model for audio generation. Whisper, originally a seq-to-seq encoder-decoder for speech recognition, is modified into a seq-to-seq model for generative purposes. Key changes involve replacing the Whisper encoder with a decoder and performing early fusion of learned representations with a decoder-only architecture operating on acoustic tokens. This hybrid approach combines continuous mel-spectrogram representations with discrete acoustic tokens, offering a richer input space. This architecture aims to improve next-token prediction by leveraging both the fine-grained temporal information of the spectrogram and the symbolic representation of tokens. It tackles the context length limitations of purely token-based models, especially in high-fidelity audio generation. The model predicts coarsest acoustic tokens, forming a foundation for subsequent generation of finer-grained details.
Perplexity Gains in TTS#
Perplexity, a metric quantifying uncertainty in next-token prediction, is crucial for evaluating TTS models. Lower perplexity indicates better prediction and potentially higher quality generation. Improvements in perplexity suggest the model’s enhanced ability to capture sequential dependencies in language and acoustic features. This could stem from several factors such as improved model architecture, larger training data, or better optimization techniques. Consequently, reduced perplexity promises more natural and coherent synthesized speech, minimizing unnatural pauses or robotic intonation. Further investigation might involve correlating perplexity gains with subjective listening tests to confirm perceived quality improvements. Analyzing perplexity trends across different datasets can also reveal model strengths and weaknesses.
Context Length Limits#
Context length limits pose a significant challenge in audio LLMs, especially for high-fidelity generation. Longer contexts, representing more audio, require extensive computational resources due to the quadratic complexity of attention mechanisms. This limitation restricts the model’s ability to capture long-range dependencies in audio, affecting the coherence and quality of generated output. Furthermore, maintaining causality within these extended contexts becomes increasingly difficult, potentially leading to information leakage from future timesteps, which is undesirable in generative tasks. Overcoming this challenge demands exploring alternative architectures or training methodologies. For instance, methods like sparse attention or hierarchical models have been proposed to address this issue, promising more efficient and longer context processing capabilities for audio LLMs. Such methods are important for achieving high-quality and coherent audio generation, as they allow the model to consider broader temporal contexts and interdependencies, capturing nuances and overall structure of the target audio.
More visual insights#
More on figures

🔼 This figure compares the performance of three different models on a music dataset, measured by validation loss over the number of training epochs. The models are: 1. GPT on coarse acoustic tokens (Baseline GPT-S): A standard GPT model trained on discrete audio tokens representing coarse acoustic features. This model serves as the baseline. 2. LARGE-GPT on acoustic tokens (GPT-L): A larger GPT model, also trained on the coarse acoustic tokens. This model tests whether simply increasing the size of the GPT model improves performance. 3. Whisper-GPT on hybrid representation: This is the proposed model, which uses both continuous audio representations (mel-spectrogram) and discrete acoustic tokens. The hypothesis is that this hybrid approach will leverage the strengths of both representations. The plot shows that increasing the size of the GPT model from baseline to large GPT offers marginal improvements. Whisper GPT model significantly outperforms both baseline and large GPT model showing the effectiveness of leveraging the continuous audio representation along with discrete tokens for next token prediction in a generative setup.
read the caption
Fig. 2: Comparison of GPT on coarse acoustic tokens with i) GPT-L ii) Our hybrid continuous-discrete representation.

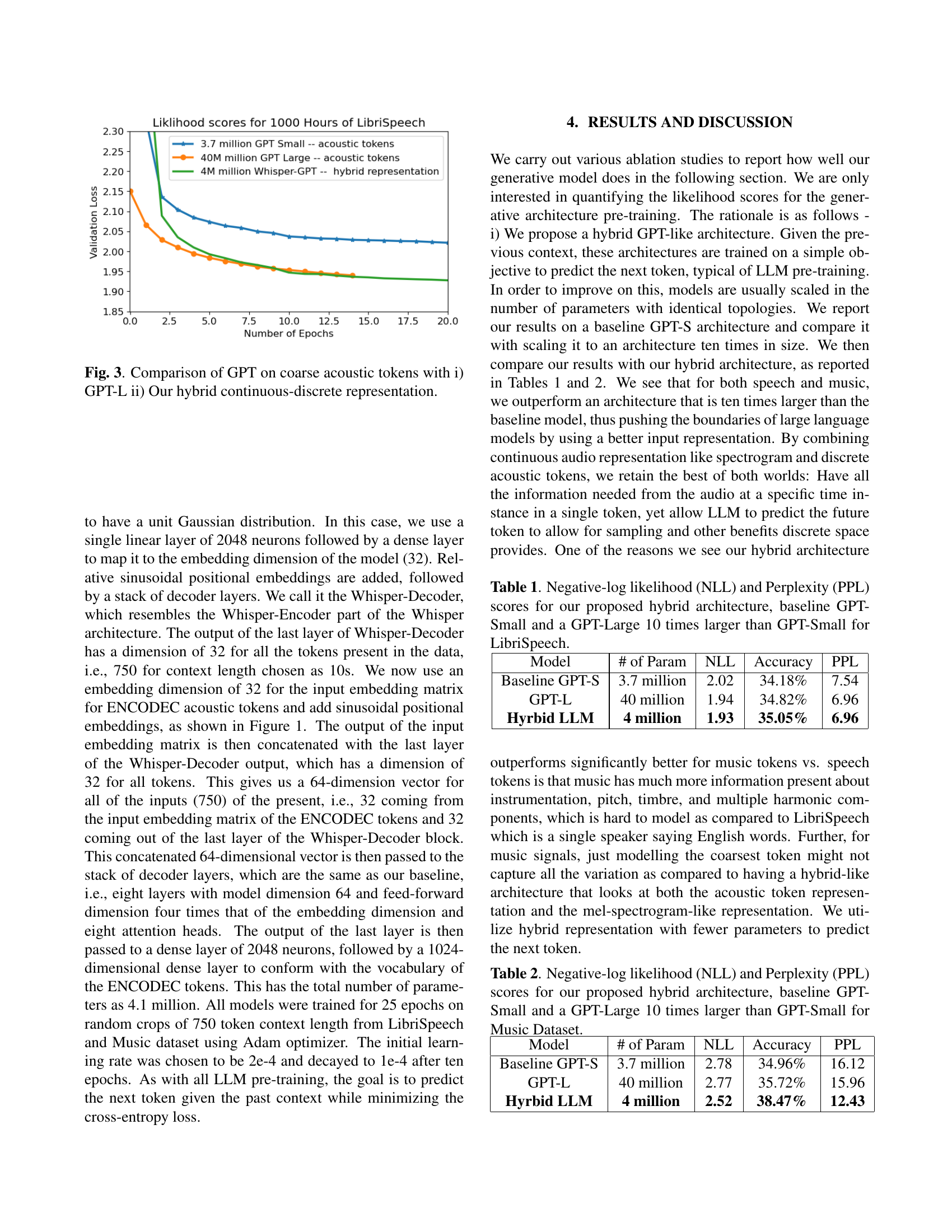
🔼 This figure presents a comparison of performance on the LibriSpeech dataset using different model architectures for predicting coarse acoustic tokens. The plot shows the validation loss over the number of training epochs. Three models are compared: 1. GPT-S (Small): A baseline GPT model with 3.7 million parameters. 2. GPT-L (Large): A scaled-up GPT model with 40 million parameters. 3. Whisper-GPT: The proposed hybrid model combining continuous (mel-spectrogram) and discrete (acoustic token) representations, having 4 million parameters. The graph demonstrates that the smaller hybrid model (Whisper-GPT) achieves comparable or better performance than the much larger GPT-L model, and significantly outperforms the smaller GPT-S model.
read the caption
Fig. 3: Comparison of GPT on coarse acoustic tokens with i) GPT-L ii) Our hybrid continuous-discrete representation.
Full paper#