↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Precise instruction-following in LLMs is important, and preference learning methods play a key role in achieving it. However, current methods often create preference pairs by sampling multiple independent responses, introducing irrelevant variations. For example, if the instruction is to write a story with a specific ending, the models might generate completely different stories, making it difficult to learn the nuances of the instructions. This issue hinders the effectiveness of preference learning and limits its potential for improving instruction-following abilities.
This paper introduces SPAR, a self-play framework with tree-search refinement to improve instruction following in LLMs. It addresses the limitations of existing preference learning methods by generating comparable preference pairs through a novel self-play mechanism. An LLM acts as both actor and refiner, generating responses and refining them based on instructions. A tree search algorithm systematically refines responses, minimizing irrelevant variations and highlighting key differences. Experiments show that SPAR significantly improves instruction following across various LLMs, even outperforming GPT-4 on the IFEval benchmark. The results demonstrate the importance of refinement and the potential for continuous LLM self-improvement.
Key Takeaways#
Why does it matter?#
Improving instruction following in LLMs is crucial for their effective deployment. This paper offers a novel self-play framework, SPAR, which significantly enhances instruction following capabilities by refining preference pairs and minimizing irrelevant variations. This approach has the potential to improve the alignment and overall performance of LLMs, contributing to safer and more reliable AI systems. It opens up new avenues for research in autonomous LLM improvement and preference learning, furthering our understanding of how to make LLMs more effective and adaptable to diverse instructions.
Visual Insights#

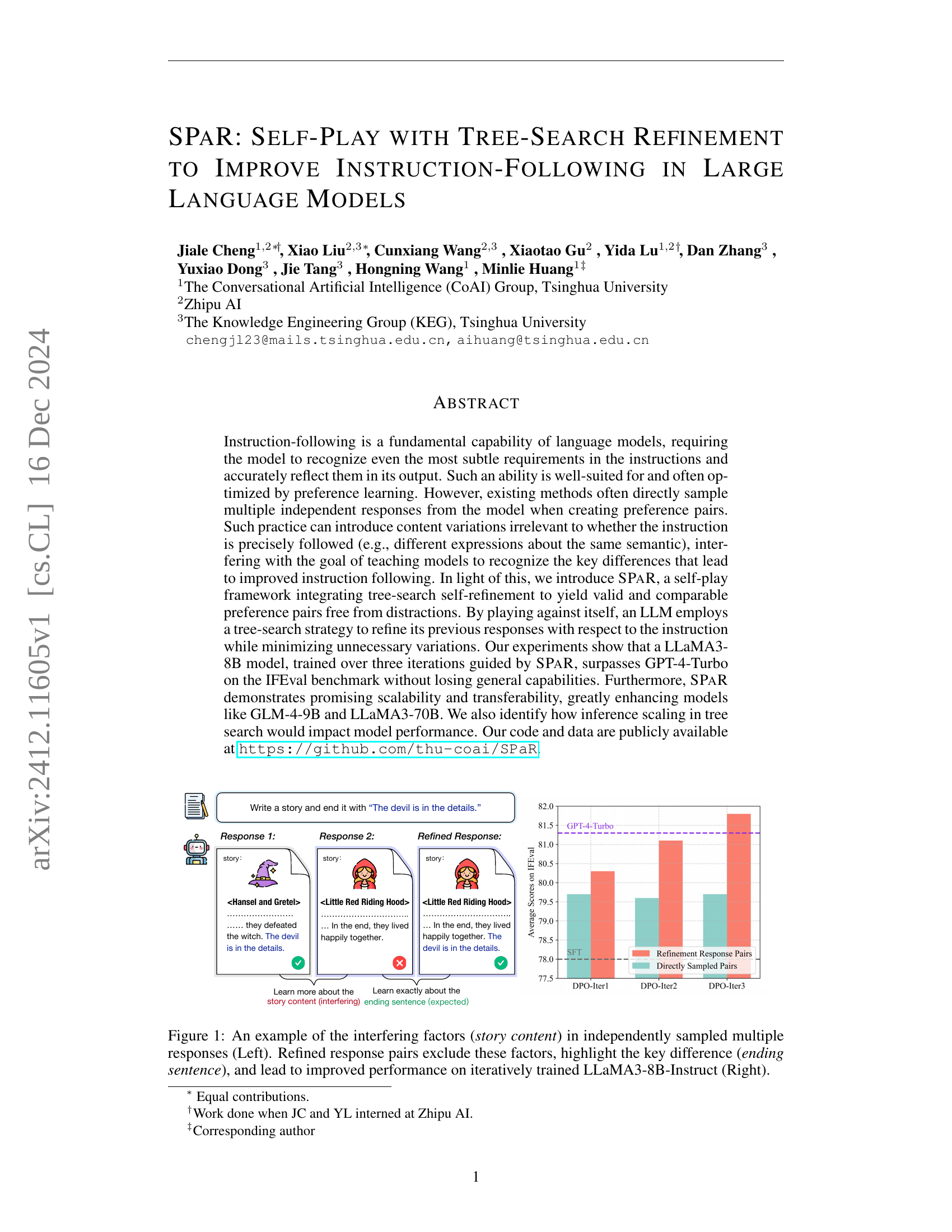
🔼 The figure shows an example of multiple responses generated from an LLM for the prompt ‘Write a story and end it with ‘The devil is in the details.’’ It highlights how independently sampled responses can vary in content, such as different story titles (e.g., Hansel and Gretel vs. Little Red Riding Hood) which interferes with preference learning. It then shows how refined responses maintain consistent story content and focus on the key requirement of the prompt, which is the ending sentence. A bar graph on the right illustrates the improved performance achieved by using refined response pairs during the iterative training of a LLaMA3-8B-Instruct model.
read the caption
Figure 1: An example of the interfering factors (story content) in independently sampled multiple responses (Left). Refined response pairs exclude these factors, highlight the key difference (ending sentence), and lead to improved performance on iteratively trained LLaMA3-8B-Instruct (Right).
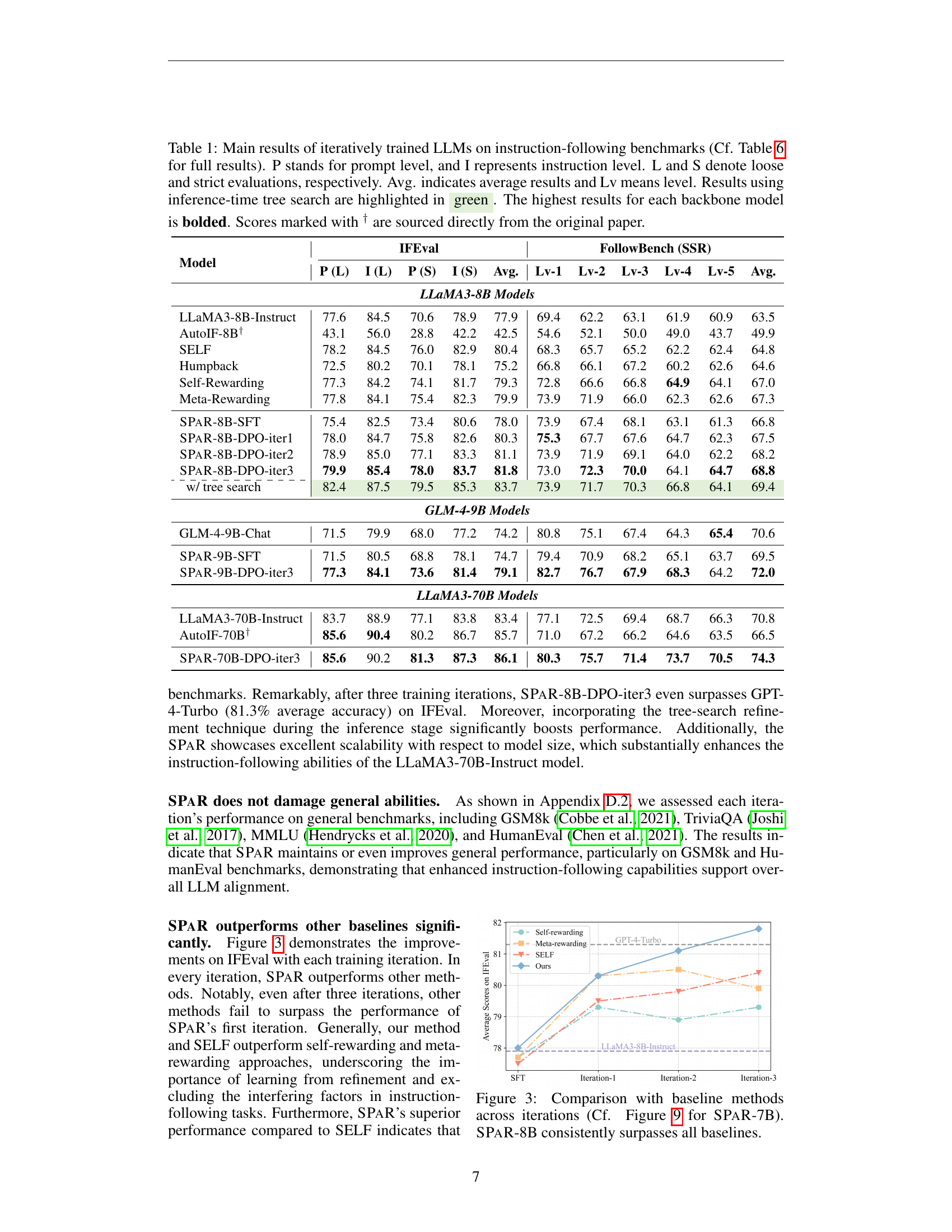
| Model | IFEval | FollowBench (SSR) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P (L) | I (L) | P (S) | I (S) | Avg. | Lv-1 | Lv-2 | Lv-3 | Lv-4 | Lv-5 | Avg. | |
| — | — | — | — | — | — | — | — | — | — | — | — |
| LLaMA3-8B Models | |||||||||||
| LLaMA3-8B-Instruct | 77.6 | 84.5 | 70.6 | 78.9 | 77.9 | 69.4 | 62.2 | 63.1 | 61.9 | 60.9 | 63.5 |
| AutoIF-8B† | 43.1 | 56.0 | 28.8 | 42.2 | 42.5 | 54.6 | 52.1 | 50.0 | 49.0 | 43.7 | 49.9 |
| SELF | 78.2 | 84.5 | 76.0 | 82.9 | 80.4 | 68.3 | 65.7 | 65.2 | 62.2 | 62.4 | 64.8 |
| Humpback | 72.5 | 80.2 | 70.1 | 78.1 | 75.2 | 66.8 | 66.1 | 67.2 | 60.2 | 62.6 | 64.6 |
| Self-Rewarding | 77.3 | 84.2 | 74.1 | 81.7 | 79.3 | 72.8 | 66.6 | 66.8 | 64.9 | 64.1 | 67.0 |
| Meta-Rewarding | 77.8 | 84.1 | 75.4 | 82.3 | 79.9 | 73.9 | 71.9 | 66.0 | 62.3 | 62.6 | 67.3 |
| SPaR-8B-SFT | 75.4 | 82.5 | 73.4 | 80.6 | 78.0 | 73.9 | 67.4 | 68.1 | 63.1 | 61.3 | 66.8 |
| SPaR-8B-DPO-iter1 | 78.0 | 84.7 | 75.8 | 82.6 | 80.3 | 75.3 | 67.7 | 67.6 | 64.7 | 62.3 | 67.5 |
| SPaR-8B-DPO-iter2 | 78.9 | 85.0 | 77.1 | 83.3 | 81.1 | 73.9 | 71.9 | 69.1 | 64.0 | 62.2 | 68.2 |
| SPaR-8B-DPO-iter3 | 79.9 | 85.4 | 78.0 | 83.7 | 81.8 | 73.0 | 72.3 | 70.0 | 64.1 | 64.7 | 68.8 |
| \cdashline{1-12} w/ tree search | 82.4 | 87.5 | 79.5 | 85.3 | 83.7 | 73.9 | 71.7 | 70.3 | 66.8 | 64.1 | 69.4 |
| GLM-4-9B Models | |||||||||||
| GLM-4-9B-Chat | 71.5 | 79.9 | 68.0 | 77.2 | 74.2 | 80.8 | 75.1 | 67.4 | 64.3 | 65.4 | 70.6 |
| SPaR-9B-SFT | 71.5 | 80.5 | 68.8 | 78.1 | 74.7 | 79.4 | 70.9 | 68.2 | 65.1 | 63.7 | 69.5 |
| SPaR-9B-DPO-iter3 | 77.3 | 84.1 | 73.6 | 81.4 | 79.1 | 82.7 | 76.7 | 67.9 | 68.3 | 64.2 | 72.0 |
| LLaMA3-70B Models | |||||||||||
| LLaMA3-70B-Instruct | 83.7 | 88.9 | 77.1 | 83.8 | 83.4 | 77.1 | 72.5 | 69.4 | 68.7 | 66.3 | 70.8 |
| AutoIF-70B† | 85.6 | 90.4 | 80.2 | 86.7 | 85.7 | 71.0 | 67.2 | 66.2 | 64.6 | 63.5 | 66.5 |
| SPaR-70B-DPO-iter3 | 85.6 | 90.2 | 81.3 | 87.3 | 86.1 | 80.3 | 75.7 | 71.4 | 73.7 | 70.5 | 74.3 |
🔼 This table presents the main results of Large Language Models (LLMs) trained iteratively on instruction-following benchmarks, including IFEval and FollowBench. The table compares performance across prompt level (P) and instruction level (I), with both loose (L) and strict (S) evaluations. Average (Avg) scores and level-specific (Lv) results are also provided. Results highlighted in green indicate the use of inference-time tree search, a technique to enhance performance at test time by increasing compute resources. Bolded values represent the best score for each base LLM.
read the caption
Table 1: Main results of iteratively trained LLMs on instruction-following benchmarks (Cf. Table 6 for full results). P stands for prompt level, and I represents instruction level. L and S denote loose and strict evaluations, respectively. Avg. indicates average results and Lv means level. Results using inference-time tree search are highlighted in green. The highest results for each backbone model is bolded. Scores marked with † are sourced directly from the original paper.
In-depth insights#
Self-Play Refinement#
Self-play refinement, a novel training paradigm, enhances LLMs by iterative self-improvement. A model acts as both “actor” generating text and “refiner” critiquing and improving it. This feedback loop fosters continuous learning, focusing on subtle nuances crucial for complex instruction following. By playing against itself, the model identifies and corrects its weaknesses, minimizing discrepancies between generated text and instructions. Tree search within self-play systematically explores refinement paths, ensuring significant improvement. Unlike methods using independent responses, refinement pairs created via self-play reduce irrelevant content variations, highlighting key differences for effective preference learning. This approach allows models to learn from their mistakes, boosting performance without relying solely on external data or human feedback. The refiner’s role as both judge and improver allows for scalable self-correction, potentially exceeding the initial bootstrapping data quality.
Nuance-Driven I-F#
Nuance-Driven Instruction Following (I-F) emphasizes the profound impact of subtle variations in instructions on an LLM’s output. Ignoring these nuances can lead to misinterpretations and inaccurate responses, even when the core instruction is understood. This highlights the need for models to be sensitive to not just the explicit directives, but also the implicit connotations and contextual cues embedded within the instructions. Effectively capturing these subtle variations is crucial for achieving truly robust and reliable I-F capabilities, enabling LLMs to respond accurately and appropriately to the full spectrum of user intent.
Tree-Search Refinement#
Tree-search refinement enhances instruction following by iteratively improving responses. A refiner model critiques actor model outputs. Unlike directly sampling varied responses, tree search refines a single response, minimizing interfering variations. This targeted approach helps isolate crucial differences affecting instruction adherence, leading to more effective learning for the actor model via DPO. The refiner uses breadth-first or depth-first search to explore potential refinements, judged for correctness. Experiments demonstrate that this approach significantly boosts performance, even surpassing strong baselines. This suggests that highlighting key differences is crucial for preference learning in instruction following.
Iterative LLM Training#
Iterative LLM training is crucial for progressive self-improvement in complex instruction following. By refining model responses through methods like tree search and using these refined pairs for preference learning, LLMs can focus on key differences, minimizing irrelevant variations. This iterative process allows both actor and refiner models to enhance performance reciprocally, surpassing capabilities achieved through standard training. The results demonstrate potential for continuous self-improvement without reliance on extensive external data, offering a promising direction for autonomous LLM alignment and instruction following tasks.
Bias in Self-Eval#
Bias in self-evaluation of language models is a critical concern. LLMs judging their own refinements can create a feedback loop, amplifying existing biases and hindering true improvement. This self-reinforcement of errors can lead to overestimation of capabilities and a skewed learning process. Mitigating this bias requires external evaluation methods, diverse training data, and techniques to decouple self-assessment from refinement training. Exploring strategies like adversarial training or incorporating human feedback can offer more objective performance measures, crucial for building robust and reliable LLMs.
More visual insights#
More on figures

🔼 The figure illustrates the iterative training process of SPaR. At each iteration t, there’s an actor model (M_t) and a refiner model (R_t), both initialized from the same base model. The actor generates responses to instructions, and the refiner critiques these responses, identifying negative (incorrect) examples. The refiner then uses a tree-search algorithm to refine these negative responses into correct ones, creating refined response pairs. These pairs, along with the refiner’s judgments, are used to train the next iteration’s actor (M_{t+1}) and refiner (R_{t+1}) via DPO and RFT respectively. This iterative process fosters continuous self-improvement in both models, leading to enhanced instruction following capabilities.
read the caption
Figure 2: SPaR iterative training framework. At iteration t𝑡titalic_t, the refiner Rtsubscript𝑅𝑡R_{t}italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT first judges the generated responses from the actor Mtsubscript𝑀𝑡M_{t}italic_M start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT to collect negative data. Next, a tree-search algorithm is employed to refine these imperfect responses. Finally, using the data from the above steps, we can optimize the actor and refiner for the next iteration, aiming for continuous self-improvement.

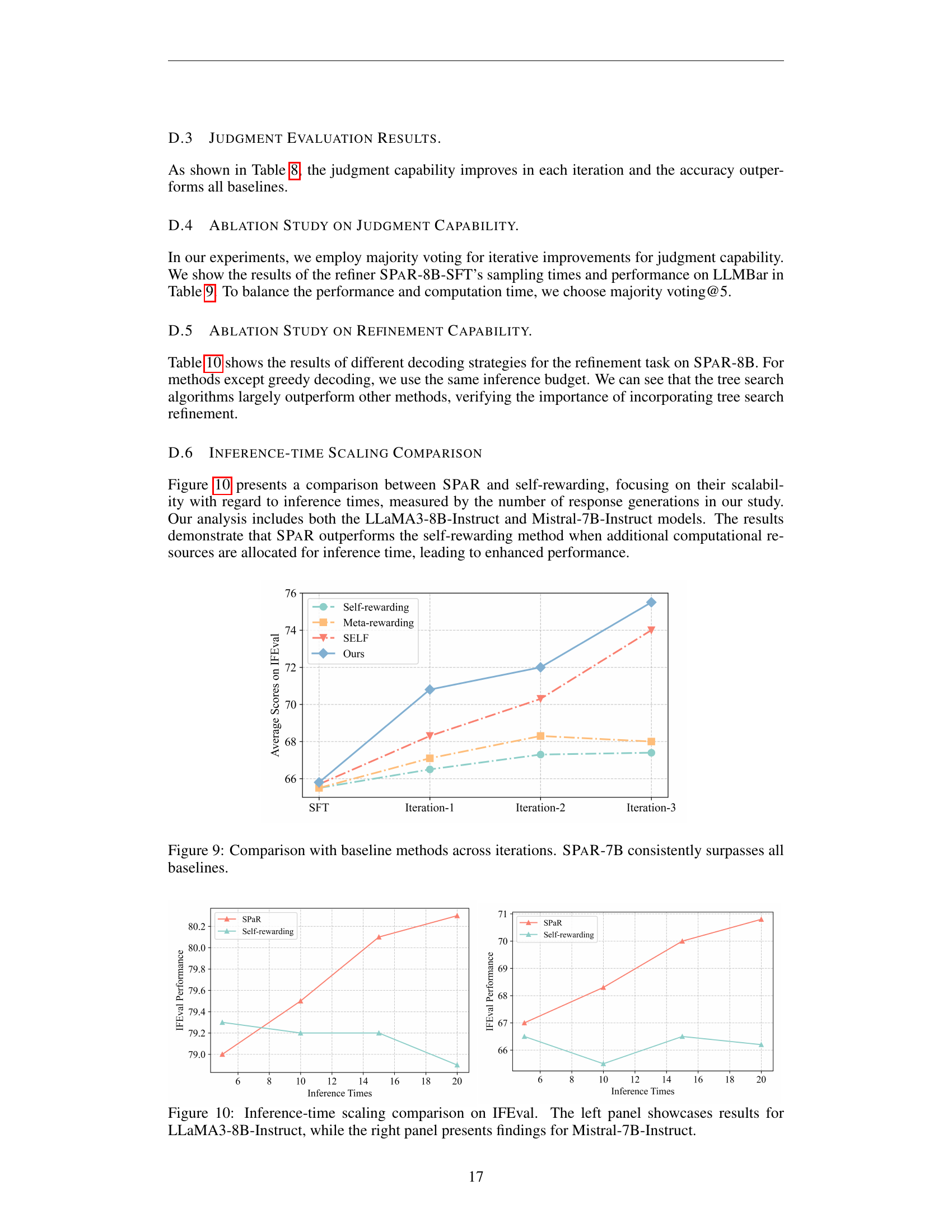
🔼 This figure compares the performance of SPAR-8B with other baseline methods (AutoIF, SELF, Self-Rewarding, and Meta-Rewarding) on the IFEval benchmark across three iterations of training. The x-axis represents the training iteration, while the y-axis represents the average score on IFEval. The results demonstrate that SPAR-8B consistently outperforms all baseline methods in each iteration and improves with each training iteration. The performance of GPT-4-Turbo is also included as a reference point.
read the caption
Figure 3: Comparison with baseline methods across iterations (Cf. Figure 9 for SPaR-7B). SPaR-8B consistently surpasses all baselines.

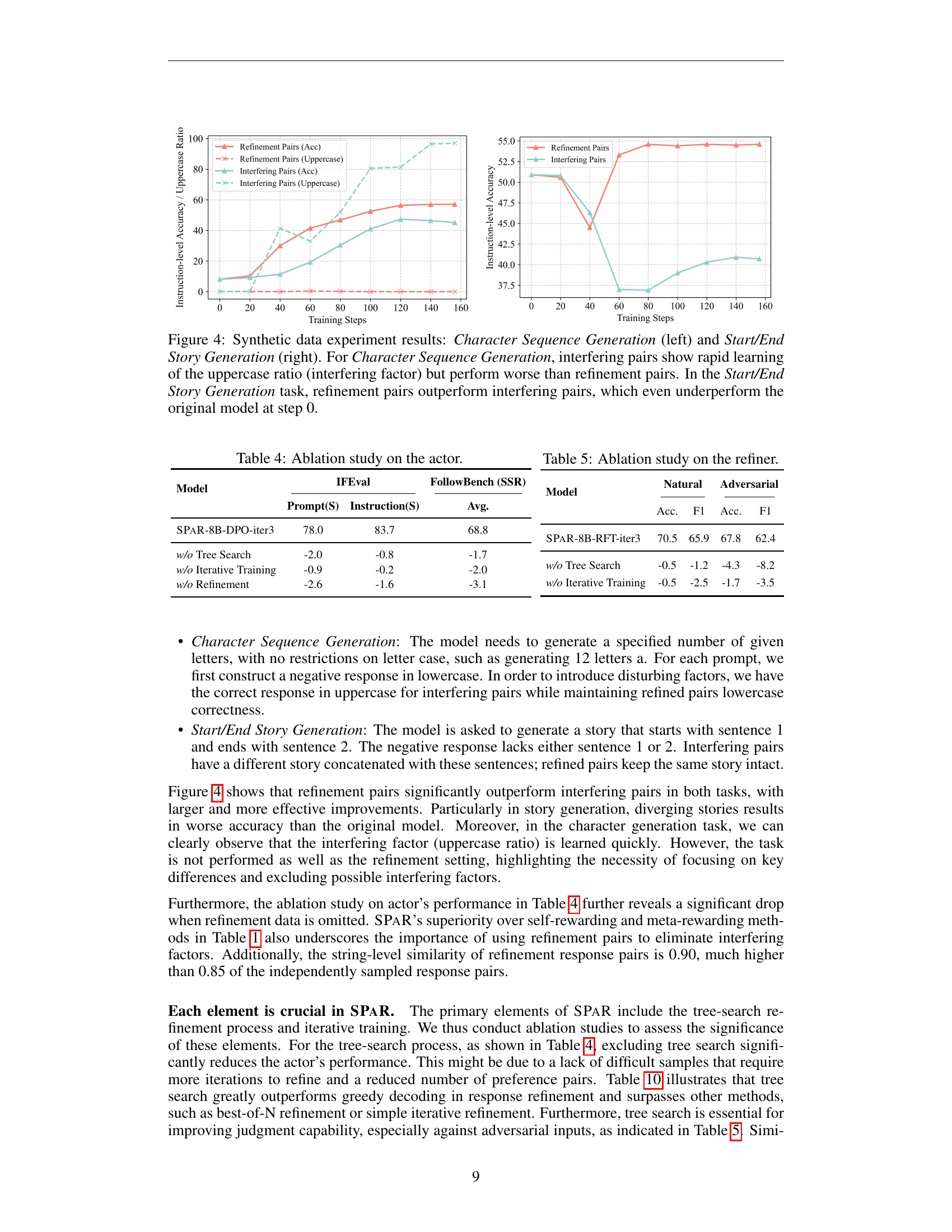
🔼 This figure presents the results of a synthetic data experiment designed to isolate the impact of interfering factors in preference learning. Two tasks are used: Character Sequence Generation and Start/End Story Generation. In the Character Sequence Generation task, the model is prompted to generate a sequence of characters with length constraints. Interfering pairs are created by introducing variation in character case. Results show that the model quickly learns the uppercase ratio in interfering pairs but performs worse on the primary instruction following objective, as compared to training with refined pairs. The Start/End Story Generation task prompts the model to generate a story with a specified beginning and ending sentence. Here, interfering pairs contain variations in the story’s middle section, which is irrelevant to the given instruction. Results show that refinement pairs outperform interfering pairs significantly. Notably, training with interfering pairs leads to worse performance than the initial model.
read the caption
Figure 4: Synthetic data experiment results: Character Sequence Generation (left) and Start/End Story Generation (right). For Character Sequence Generation, interfering pairs show rapid learning of the uppercase ratio (interfering factor) but perform worse than refinement pairs. In the Start/End Story Generation task, refinement pairs outperform interfering pairs, which even underperform the original model at step 0.

🔼 This table presents an ablation study conducted on the actor model within the SPAR framework. The study examines the impact of removing key components of SPAR, specifically Tree Search and Refinement data, on the actor’s performance on the IFEval and FollowBench (SSR) benchmarks. The purpose is to demonstrate the importance of these components for enhancing instruction-following capabilities. The evaluation metrics include prompt-level strict accuracy and instruction-level strict accuracy on IFEval, and the average score on FollowBench (SSR). The results show a performance drop when these components are removed, highlighting their contribution to the effectiveness of the SPAR framework.
read the caption
Table 4: Ablation study on the actor.

🔼 This table presents an ablation study conducted on the refiner model, exploring the impact of different training components on its performance. It assesses how removing certain aspects like tree-search, refinement data, or iterative training affects the refiner’s ability to evaluate instruction-following responses accurately, as measured by accuracy (Acc.) and F1-score on both Natural and Adversarial subsets of the LLMBar benchmark. The ‘Average’ columns represents the average scores across both subsets.
read the caption
Table 5: Ablation study on the refiner.

🔼 This figure compares different decoding strategies during inference for SPAR-8B-DPO-iter3 on IFEval benchmark, including greedy decoding, best-of-N, Breadth-First Search (BFS), and Depth-First Search (DFS). X-axis represents inference times, measured by the number of response generations. Y-axis is the average score on IFEval. The results demonstrate increased inference times enhance model performance. While tree search refinement (BFS and DFS)’s performance growth is slower, it ultimately gets superior results than best-of-N. Refinement could be more suitable for scaling test-time compute for the instruction-following task.
read the caption
Figure 5: Comparison of decoding strategies. Model performance improves with increased inference times.
More on tables
| Model | Natural | Adversarial | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | GPTInst | GPTOut | Manual | Neighbor | Average | Acc. | ||||||
| — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| GPT-4o-Mini | 74.5 | 70.5 | 69.2 | 61.6 | 60.9 | 51.4 | 59.8 | 51.9 | 72.8 | 66.4 | 65.7 | 57.8 | 67.4 |
| LLaMA3-8B Models | |||||||||||||
| LLaMA3-8B-Instruct | 60.0 | 51.8 | 55.4 | 46.1 | 47.9 | 39.5 | 51.1 | 36.6 | 54.5 | 45.0 | 52.2 | 41.8 | 53.8 |
| SELF | 69.5 | 61.6 | 62.0 | 50.7 | 64.9 | 54.8 | 57.6 | 41.8 | 64.6 | 51.3 | 62.2 | 49.6 | 63.7 |
| Self-Rewarding | 71.0 | 66.3 | 70.1 | 66.7 | 63.8 | 59.5 | 62.0 | 55.7 | 67.5 | 61.7 | 65.9 | 60.9 | 66.9 |
| Meta-Rewarding | 70.5 | 66.3 | 68.5 | 64.6 | 64.9 | 60.2 | 64.1 | 58.3 | 69.0 | 63.1 | 66.6 | 61.6 | 67.4 |
| SPaR-8B-SFT | 68.5 | 60.9 | 67.9 | 62.4 | 59.6 | 50.0 | 63.0 | 54.1 | 68.3 | 59.3 | 64.7 | 56.5 | 65.5 |
| SPaR-8B-RFT-iter1 | 68.5 | 63.2 | 66.8 | 60.6 | 63.8 | 55.3 | 62.0 | 53.3 | 66.8 | 59.0 | 64.9 | 57.1 | 65.6 |
| SPaR-8B-RFT-iter2 | 70.5 | 64.2 | 66.8 | 61.6 | 66.0 | 60.0 | 65.2 | 57.9 | 69.0 | 62.4 | 66.8 | 60.5 | 67.5 |
| SPaR-8B-RFT-iter3 | 70.5 | 65.9 | 70.7 | 66.7 | 63.8 | 57.5 | 68.5 | 63.3 | 68.3 | 62.2 | 67.8 | 62.4 | 68.3 |
| GLM-4-9B Models | |||||||||||||
| GLM-4-9B-Chat | 74.5 | 76.5 | 74.5 | 75.9 | 57.4 | 62.3 | 53.3 | 56.6 | 69.8 | 72.0 | 63.7 | 66.7 | 65.9 |
| SPaR-9B-SFT | 70.5 | 65.5 | 72.8 | 70.2 | 69.6 | 55.8 | 64.1 | 53.5 | 71.3 | 67.2 | 66.9 | 61.7 | 67.7 |
| SPaR-9B-RFT-iter3 | 71.0 | 68.8 | 75.5 | 74.6 | 58.5 | 55.2 | 68.5 | 64.2 | 71.7 | 65.9 | 67.8 | 64.9 | 68.4 |
| LLaMA3-70B Models | |||||||||||||
| LLaMA3-70B-Instruct | 75.0 | 71.9 | 73.4 | 69.6 | 75.1 | 70.7 | 66.3 | 65.8 | 69.0 | 63.4 | 69.5 | 65.1 | 70.6 |
| SPaR-70B-RFT-iter3 | 78.0 | 74.7 | 78.8 | 76.9 | 64.9 | 61.2 | 73.4 | 59.5 | 76.4 | 72.1 | 75.9 | 70.4 | 76.3 |
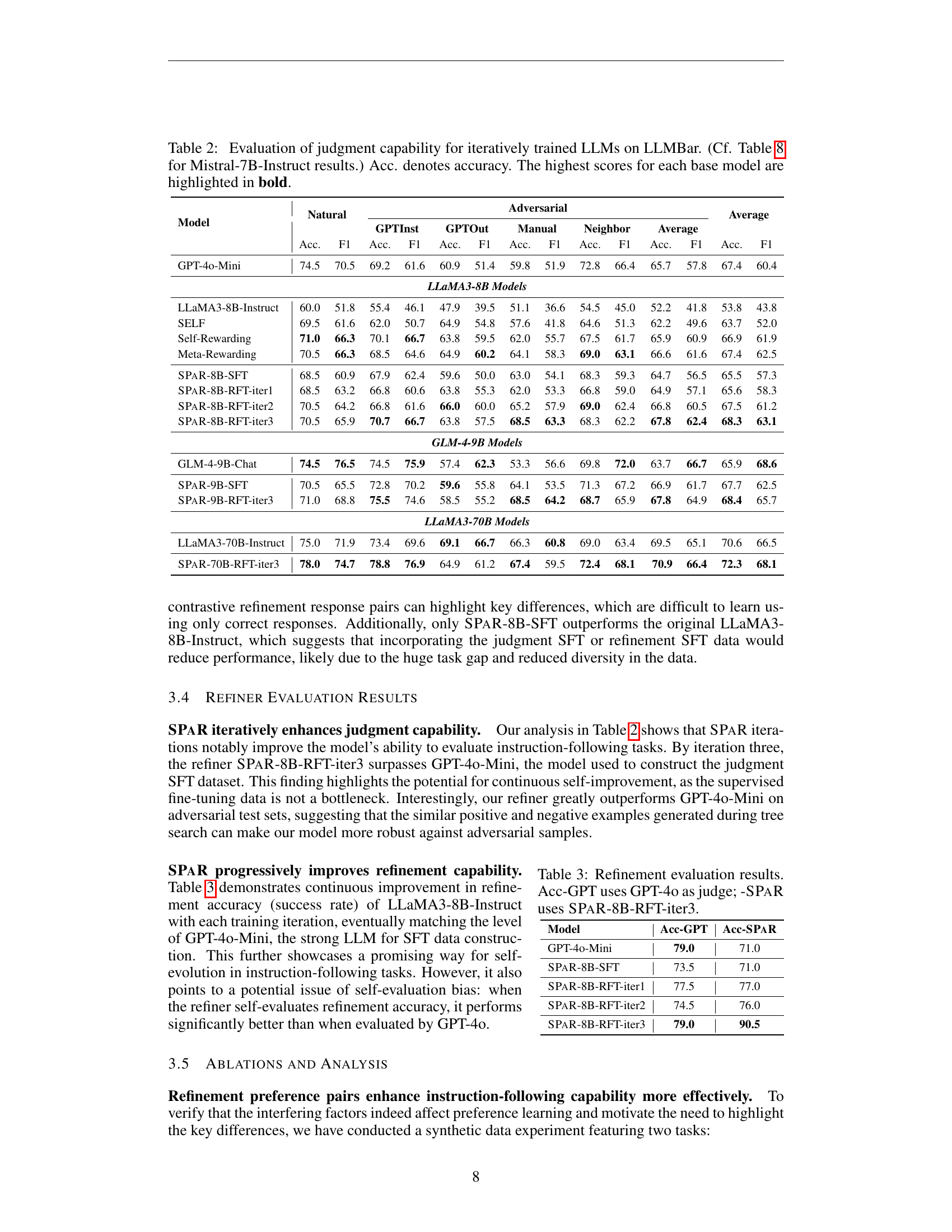
🔼 This table presents the judgment capabilities of various large language models (LLMs), including different sizes of LLaMA and GLM, evaluated on the LLMBar dataset. The table shows how these models’ ability to distinguish between correct and incorrect instruction-following responses improves over multiple training iterations. It also includes comparisons with other self-improvement techniques like SELF, Self-Rewarding, and Meta-Rewarding. The results are presented in terms of accuracy and F1 scores, with the best scores for each base model highlighted. Additionally, the caption mentions Table 8, which contains the results for Mistral-7B-Instruct, indicating that this particular model is treated separately.
read the caption
Table 2: Evaluation of judgment capability for iteratively trained LLMs on LLMBar. (Cf. Table 8 for Mistral-7B-Instruct results.) Acc. denotes accuracy. The highest scores for each base model are highlighted in bold.
| Model | Acc-GPT | Acc-SPaR |
|---|---|---|
| GPT-4o-Mini | 79.0 | 71.0 |
| SPaR-8B-SFT | 73.5 | 71.0 |
| SPaR-8B-RFT-iter1 | 77.5 | 77.0 |
| SPaR-8B-RFT-iter2 | 74.5 | 76.0 |
| SPaR-8B-RFT-iter3 | 79.0 | 90.5 |
🔼 This table presents the results of evaluating the refinement capabilities of different models. It compares the accuracy of two judges, GPT-40 and SPAR-8B-RFT-iter3 (the refiner after three iterations), in assessing the correctness of refined responses generated by various models during different stages of training.
read the caption
Table 3: Refinement evaluation results. Acc-GPT uses GPT-4o as judge; -SPaR uses SPaR-8B-RFT-iter3.
| Model | IFEval | FollowBench (SSR) | |
|---|---|---|---|
| Prompt(S) | Instruction(S) | Avg. | |
| SPaR-8B-DPO-iter3 | 78.0 | 83.7 | 68.8 |
| w/o Tree Search | -2.0 | -0.8 | -1.7 |
| w/o Iterative Training | -0.9 | -0.2 | -2.0 |
| w/o Refinement | -2.6 | -1.6 | -3.1 |
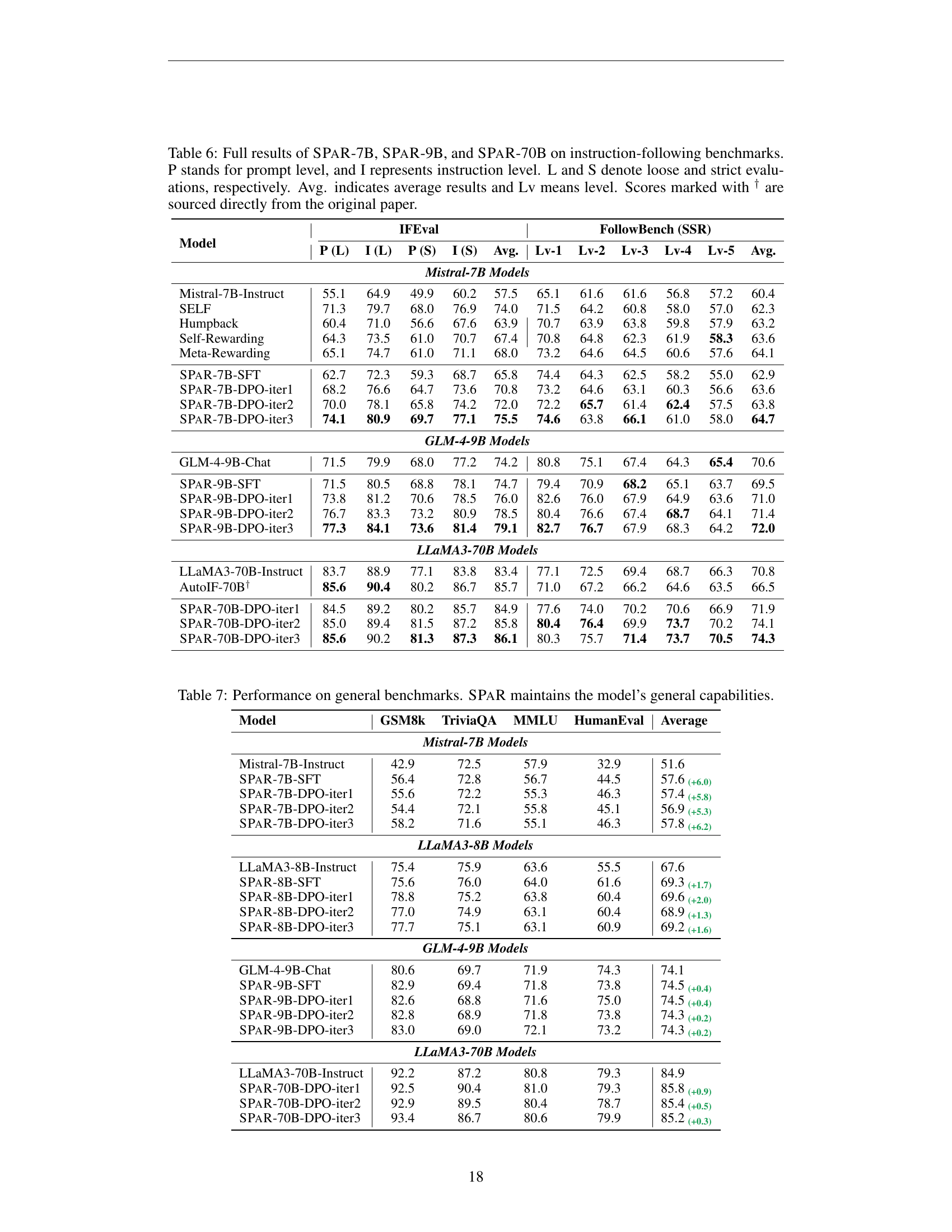
🔼 This table presents the comprehensive results of instruction-following benchmarks for different sizes of Large Language Models (LLMs) fine-tuned using the SPaR framework. The models evaluated are SPaR-7B (based on Mistral-7B-Instruct), SPaR-9B (based on GLM-4-9B-Chat), and SPaR-70B (based on LLaMA3-70B-Instruct). The benchmarks used are IFEval and FollowBench (using SSR metric). IFEval scores are presented at both prompt (P) and instruction (I) levels, with loose (L) and strict (S) evaluations. FollowBench scores are provided for each level (Lv1-Lv5) and an average score. The average performance across all levels for both IFEval and FollowBench is also reported. Some scores are taken directly from the original papers and marked accordingly.
read the caption
Table 6: Full results of SPaR-7B, SPaR-9B, and SPaR-70B on instruction-following benchmarks. P stands for prompt level, and I represents instruction level. L and S denote loose and strict evaluations, respectively. Avg. indicates average results and Lv means level. Scores marked with † are sourced directly from the original paper.
| Model | Natural | Adversarial | ||
|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | |
| SPaR-8B-RFT-iter3 | 70.5 | 65.9 | 67.8 | 62.4 |
| w/o Tree Search | -0.5 | -1.2 | -4.3 | -8.2 |
| w/o Iterative Training | -0.5 | -2.5 | -1.7 | -3.5 |
🔼 This table presents an evaluation of various large language models (LLMs) on several general benchmarks. These benchmarks are designed to assess the overall capabilities of the models, including mathematical reasoning (GSM8k), question answering (TriviaQA), multi-task language understanding (MMLU), and code generation (HumanEval). The table compares the performance of different LLMs, including Mistral-7B-Instruct, LLaMA3-8B-Instruct, GLM-4-9B-Chat, and LLaMA3-70B-Instruct, both before and after training with the SPaR framework. The results are presented as average scores across different iterations of training. The purpose of this table is to demonstrate that while SPaR improves the instruction-following capabilities of the LLMs (as shown in other tables), it does not negatively impact their general performance on these broader benchmarks.
read the caption
Table 7: Performance on general benchmarks. SPaR maintains the model’s general capabilities.
| Model | IFEval | FollowBench (SSR) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P (L) | I (L) | P (S) | I (S) | Avg. | Lv-1 | Lv-2 | Lv-3 | Lv-4 | Lv-5 | Avg. | |
| — | — | — | — | — | — | — | — | — | — | — | — |
| Mistral-7B Models | |||||||||||
| Mistral-7B-Instruct | 55.1 | 64.9 | 49.9 | 60.2 | 57.5 | 65.1 | 61.6 | 61.6 | 56.8 | 57.2 | 60.4 |
| SELF | 71.3 | 79.7 | 68.0 | 76.9 | 74.0 | 71.5 | 64.2 | 60.8 | 58.0 | 57.0 | 62.3 |
| Humpback | 60.4 | 71.0 | 56.6 | 67.6 | 63.9 | 70.7 | 63.9 | 63.8 | 59.8 | 57.9 | 63.2 |
| Self-Rewarding | 64.3 | 73.5 | 61.0 | 70.7 | 67.4 | 70.8 | 64.8 | 62.3 | 61.9 | 58.3 | 63.6 |
| Meta-Rewarding | 65.1 | 74.7 | 61.0 | 71.1 | 68.0 | 73.2 | 64.6 | 64.5 | 60.6 | 57.6 | 64.1 |
| SPaR-7B-SFT | 62.7 | 72.3 | 59.3 | 68.7 | 65.8 | 74.4 | 64.3 | 62.5 | 58.2 | 55.0 | 62.9 |
| SPaR-7B-DPO-iter1 | 68.2 | 76.6 | 64.7 | 73.6 | 70.8 | 73.2 | 64.6 | 63.1 | 60.3 | 56.6 | 63.6 |
| SPaR-7B-DPO-iter2 | 70.0 | 78.1 | 65.8 | 74.2 | 72.0 | 72.2 | 65.7 | 61.4 | 62.4 | 57.5 | 63.8 |
| SPaR-7B-DPO-iter3 | 74.1 | 80.9 | 69.7 | 77.1 | 75.5 | 74.6 | 63.8 | 66.1 | 61.0 | 58.0 | 64.7 |
| GLM-4-9B Models | |||||||||||
| GLM-4-9B-Chat | 71.5 | 79.9 | 68.0 | 77.2 | 74.2 | 80.8 | 75.1 | 67.4 | 64.3 | 65.4 | 70.6 |
| SPaR-9B-SFT | 71.5 | 80.5 | 68.8 | 78.1 | 74.7 | 79.4 | 70.9 | 68.2 | 65.1 | 63.7 | 69.5 |
| SPaR-9B-DPO-iter1 | 73.8 | 81.2 | 70.6 | 78.5 | 76.0 | 82.6 | 76.0 | 67.9 | 64.9 | 63.6 | 71.0 |
| SPaR-9B-DPO-iter2 | 76.7 | 83.3 | 73.2 | 80.9 | 78.5 | 80.4 | 76.6 | 67.4 | 68.7 | 64.1 | 71.4 |
| SPaR-9B-DPO-iter3 | 77.3 | 84.1 | 73.6 | 81.4 | 79.1 | 82.7 | 76.7 | 67.9 | 68.3 | 64.2 | 72.0 |
| LLaMA3-70B Models | |||||||||||
| LLaMA3-70B-Instruct | 83.7 | 88.9 | 77.1 | 83.8 | 83.4 | 77.1 | 72.5 | 69.4 | 68.7 | 66.3 | 70.8 |
| AutoIF-70B† | 85.6 | 90.4 | 80.2 | 86.7 | 85.7 | 71.0 | 67.2 | 66.2 | 64.6 | 63.5 | 66.5 |
| SPaR-70B-DPO-iter1 | 84.5 | 89.2 | 80.2 | 85.7 | 84.9 | 77.6 | 74.0 | 70.2 | 70.6 | 66.9 | 71.9 |
| SPaR-70B-DPO-iter2 | 85.0 | 89.4 | 81.5 | 87.2 | 85.8 | 80.4 | 76.4 | 69.9 | 73.7 | 70.2 | 74.1 |
| SPaR-70B-DPO-iter3 | 85.6 | 90.2 | 81.3 | 87.3 | 86.1 | 80.3 | 75.7 | 71.4 | 73.7 | 70.5 | 74.3 |
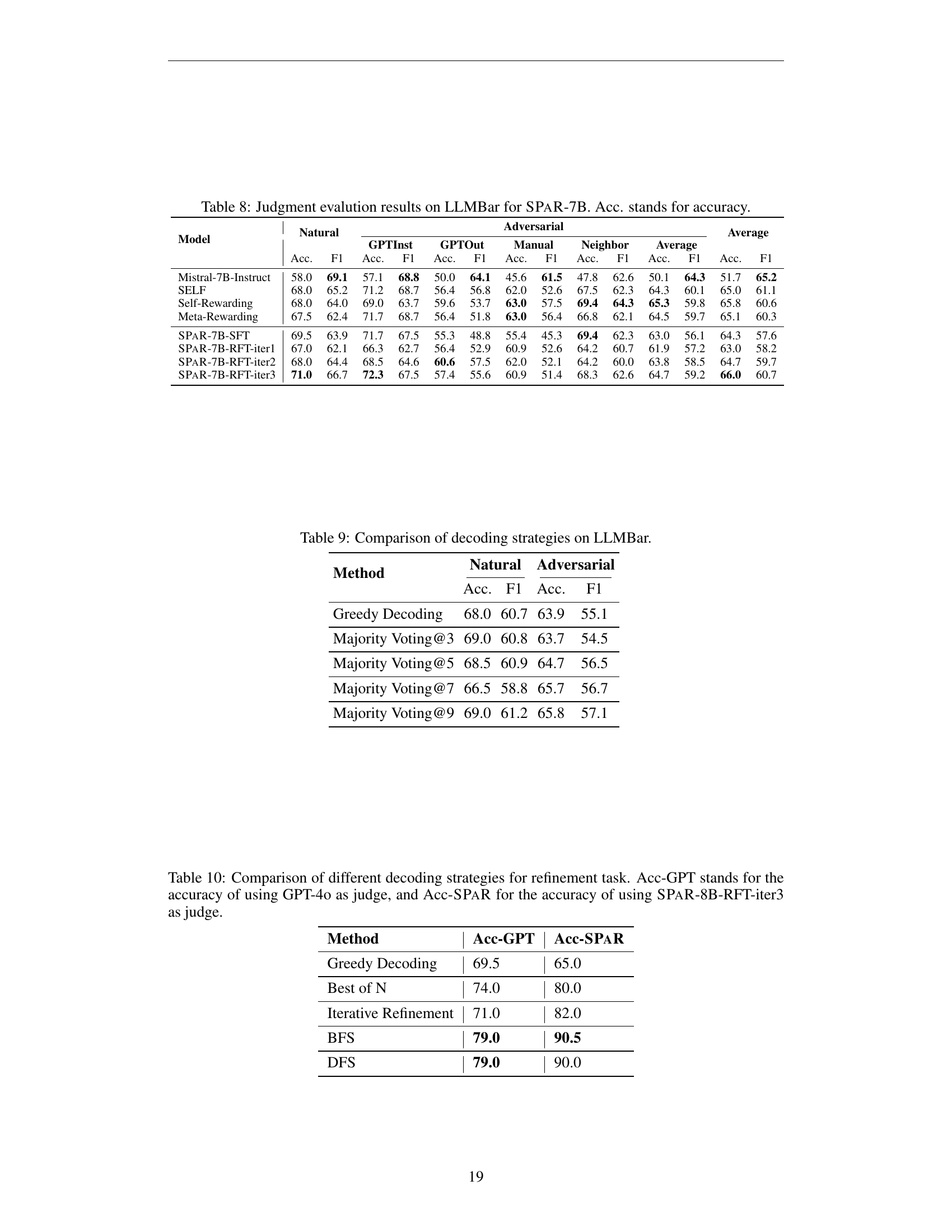
🔼 This table presents the judgment evaluation results on the LLMBar dataset for the SPAR-7B model. It assesses the refiner’s ability to judge instruction-following responses by evaluating its performance across different iterations of training. Specifically, the table presents the accuracy and F1 score for both natural and adversarial examples, including different types of evaluations (GPTInst, GPTOut, Manual, Neighbor) that comprise the LLMBar dataset. This provides a comprehensive evaluation of the refiner’s judgment capability and its ability to handle various challenges in instruction following.
read the caption
Table 8: Judgment evalution results on LLMBar for SPaR-7B. Acc. stands for accuracy.
| Model | GSM8k | TriviaQA | MMLU | HumanEval | Average |
|---|---|---|---|---|---|
| Mistral-7B Models | |||||
| Mistral-7B-Instruct | 42.9 | 72.5 | 57.9 | 32.9 | 51.6 |
| SPaR-7B-SFT | 56.4 | 72.8 | 56.7 | 44.5 | 57.6 (+6.0) |
| SPaR-7B-DPO-iter1 | 55.6 | 72.2 | 55.3 | 46.3 | 57.4 (+5.8) |
| SPaR-7B-DPO-iter2 | 54.4 | 72.1 | 55.8 | 45.1 | 56.9 (+5.3) |
| SPaR-7B-DPO-iter3 | 58.2 | 71.6 | 55.1 | 46.3 | 57.8 (+6.2) |
| LLaMA3-8B Models | |||||
| LLaMA3-8B-Instruct | 75.4 | 75.9 | 63.6 | 55.5 | 67.6 |
| SPaR-8B-SFT | 75.6 | 76.0 | 64.0 | 61.6 | 69.3 (+1.7) |
| SPaR-8B-DPO-iter1 | 78.8 | 75.2 | 63.8 | 60.4 | 69.6 (+2.0) |
| SPaR-8B-DPO-iter2 | 77.0 | 74.9 | 63.1 | 60.4 | 68.9 (+1.3) |
| SPaR-8B-DPO-iter3 | 77.7 | 75.1 | 63.1 | 60.9 | 69.2 (+1.6) |
| GLM-4-9B Models | |||||
| GLM-4-9B-Chat | 80.6 | 69.7 | 71.9 | 74.3 | 74.1 |
| SPaR-9B-SFT | 82.9 | 69.4 | 71.8 | 73.8 | 74.5 (+0.4) |
| SPaR-9B-DPO-iter1 | 82.6 | 68.8 | 71.6 | 75.0 | 74.5 (+0.4) |
| SPaR-9B-DPO-iter2 | 82.8 | 68.9 | 71.8 | 73.8 | 74.3 (+0.2) |
| SPaR-9B-DPO-iter3 | 83.0 | 69.0 | 72.1 | 73.2 | 74.3 (+0.2) |
| LLaMA3-70B Models | |||||
| LLaMA3-70B-Instruct | 92.2 | 87.2 | 80.8 | 79.3 | 84.9 |
| SPaR-70B-DPO-iter1 | 92.5 | 90.4 | 81.0 | 79.3 | 85.8 (+0.9) |
| SPaR-70B-DPO-iter2 | 92.9 | 89.5 | 80.4 | 78.7 | 85.4 (+0.5) |
| SPaR-70B-DPO-iter3 | 93.4 | 86.7 | 80.6 | 79.9 | 85.2 (+0.3) |
🔼 This table presents an ablation study comparing the performance of different decoding strategies during the tree search refinement process within the SPAR framework. The evaluation focuses on the refiner’s judgment capabilities, assessed on the LLMBar benchmark, across both natural and adversarial datasets. Metrics include accuracy (Acc) and F1-score (F1) for different sampling times during majority voting.
read the caption
Table 9: Comparison of decoding strategies on LLMBar.
| Model | Natural | Adversarial | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | GPTInst | GPTOut | Manual | Neighbor | Average | Acc. | ||||||
| — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| Mistral-7B-Instruct | 58.0 | 69.1 | 57.1 | 68.8 | 50.0 | 64.1 | 45.6 | 61.5 | 47.8 | 62.6 | 50.1 | 64.3 | 51.7 |
| SELF | 68.0 | 65.2 | 71.2 | 68.7 | 56.4 | 56.8 | 62.0 | 52.6 | 67.5 | 62.3 | 64.3 | 60.1 | 65.0 |
| Self-Rewarding | 68.0 | 64.0 | 69.0 | 63.7 | 59.6 | 53.7 | 63.0 | 57.5 | 69.4 | 64.3 | 65.3 | 59.8 | 65.8 |
| Meta-Rewarding | 67.5 | 62.4 | 71.7 | 68.7 | 56.4 | 51.8 | 63.0 | 56.4 | 66.8 | 62.1 | 64.5 | 59.7 | 65.1 |
| SPaR-7B-SFT | 69.5 | 63.9 | 71.7 | 67.5 | 55.3 | 48.8 | 55.4 | 45.3 | 69.4 | 62.3 | 63.0 | 56.1 | 64.3 |
| SPaR-7B-RFT-iter1 | 67.0 | 62.1 | 66.3 | 62.7 | 56.4 | 52.9 | 60.9 | 52.6 | 64.2 | 60.7 | 61.9 | 57.2 | 63.0 |
| SPaR-7B-RFT-iter2 | 68.0 | 64.4 | 68.5 | 64.6 | 60.6 | 57.5 | 62.0 | 52.1 | 64.2 | 60.0 | 63.8 | 58.5 | 64.7 |
| SPaR-7B-RFT-iter3 | 71.0 | 66.7 | 72.3 | 67.5 | 57.4 | 55.6 | 60.9 | 51.4 | 68.3 | 62.6 | 64.7 | 59.2 | 66.0 |
🔼 This table compares the effectiveness of different decoding strategies for the refinement task, which is refining model responses to better adhere to instructions. It presents the accuracy achieved using each strategy. Specifically, it compares Greedy Decoding, Best-of-N, Iterative Refinement, Breadth-First Search (BFS), and Depth-First Search (DFS). The table also shows two different accuracy scores: one evaluated by GPT-4 (Acc-GPT) and the other by a specific version of the model being tested, the SPAR-8B-RFT-iter3 refiner (Acc-SPAR). This comparison helps assess the alignment of self-evaluation with external judgment.
read the caption
Table 10: Comparison of different decoding strategies for refinement task. Acc-GPT stands for the accuracy of using GPT-4o as judge, and Acc-SPaR for the accuracy of using SPaR-8B-RFT-iter3 as judge.
Full paper#