↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Recovering intrinsic properties of objects from images is vital but challenging due to ambiguities between lighting and material. Traditional methods are computationally expensive and struggle with these ambiguities, while learning-based methods suffer from multi-view inconsistency. Existing datasets are limited in scale and lighting diversity, hindering effective training. Accurate intrinsic image decomposition enables applications such as realistic image editing, relighting, and 3D content creation.
This work introduces IDArb, a diffusion-based model that tackles intrinsic decomposition from an arbitrary number of views under unconstrained lighting. IDArb leverages a cross-view, cross-domain attention module for multi-view consistent decomposition. To enable robust training, the researchers introduce ARB-Objaverse, a novel dataset containing a diverse collection of objects rendered under various lighting. This combined approach achieves state-of-the-art results in intrinsic decomposition on both synthetic and real-world images and could serve as strong priors for downstream applications like relighting, photometric stereo, and 3D reconstruction.
Key Takeaways#
Why does it matter?#
Intrinsic image decomposition is crucial for various applications. This paper introduces a novel diffusion model, pushing the boundaries of the field. It allows for more robust and accurate estimations compared to traditional optimization-based methods, and opens new avenues for research in realistic 3D content creation.
Visual Insights#

🔼 IDArb performs intrinsic image decomposition from images with varying numbers of views and illumination conditions. It disentangles intrinsic properties (albedo, normal, etc.) from lighting effects, leading to multi-view consistency. Compared to learning-based methods, IDArb maintains consistency across multiple views. Compared to optimization-based methods, IDArb is less susceptible to artifacts from lighting. This figure showcases these advantages and suggests applications in relighting, material editing, stereo, and 3D reconstruction.
read the caption
Figure 1: IDArb tackles intrinsic decomposition for an arbitrary number of views under unconstrained illumination. Our approach (a) achieves multi-view consistency compared to learning-based methods and (b) better disentangles intrinsic components from lighting effects via learnt priors compared to optimization-based methods. Our method could enhance a wide range of applications such as image relighting and material editing, photometric stereo, and 3D reconstruction.
| Albedo | Normal | Metallic | Roughness | ||
|---|---|---|---|---|---|
| SSIM↑ | PSNR↑ | Cosine Similarity ↑ | MSE ↓ | MSE ↓ | |
| IID | 0.901 | 27.35 | - | 0.192 | 0.131 |
| RGB↔X | 0.902 | 28.09 | 0.834 | 0.162 | 0.347 |
| IntrinsicAnything | 0.901 | 28.17 | - | - | - |
| GeoWizard | - | - | 0.871 | - | - |
| Ours(single) | 0.935 | 32.79 | 0.928 | 0.037 | 0.058 |
| Ours(multi) | 0.937 | 33.62 | 0.941 | 0.016 | 0.033 |
🔼 This table presents a quantitative comparison of IDArb against other baseline methods for intrinsic image decomposition using various metrics. IDArb consistently outperforms the baselines in albedo, normal, roughness, and metallic estimations, demonstrating its effectiveness.
read the caption
Table 1: Quantitative evaluation of IDArb against baselines. IDArb consistently achieves the best results among all albedo, normal, metallic and roughness metrics.
In-depth insights#
Intrinsic Decomp#
Intrinsic decomposition separates an image into its underlying components: albedo, normal, metallic, and roughness. This disentanglement is crucial for various computer vision tasks, such as relighting, material editing, and 3D reconstruction. Traditional methods face challenges with computational cost and ambiguities between lighting and material properties. Learning-based approaches, while faster, struggle with multi-view consistency. Novel approaches leverage diffusion models and cross-domain attention mechanisms to fuse information from multiple views, enabling robust decomposition under diverse lighting. These advancements enhance the realism and editability of 3D content creation.
Diffusion Model#
Diffusion models offer a powerful approach to intrinsic image decomposition, tackling the challenge of separating an image into its underlying components like albedo, normals, and material properties. These models excel at capturing high-frequency details and complex relationships between intrinsic components, leading to more realistic and nuanced estimations. By iteratively denoising input images, diffusion models effectively learn the underlying distribution of intrinsic properties, enabling the generation of high-quality, consistent outputs. However, applying diffusion models to intrinsic decomposition presents unique challenges. The high dimensionality of intrinsic data, coupled with ambiguities in separating lighting effects from material properties, requires careful model design and training strategies. The use of cross-view and cross-component attention mechanisms, along with specialized training datasets, significantly enhances the model’s ability to resolve these ambiguities and generate consistent multi-view decompositions.
Multi-view Decomp#
Multi-view decomposition methods extract intrinsic object properties (albedo, normals, material) from multiple images. These methods address the inherent ambiguity of inverse rendering by leveraging complementary information across views, promoting consistency. However, computational cost can be a significant challenge, especially with dense multi-view inputs and complex lighting. Furthermore, the arbitrary number of input views and diverse lighting introduce difficulties. Deep learning-based methods can mitigate the computational burden by leveraging learned priors and enabling efficient inference. Addressing challenges like view consistency and robustness under varying illuminations often involves novel attention mechanisms and training strategies. Multi-view decomposition offers valuable input for applications like relighting, material editing, and 3D reconstruction, advancing realistic content creation.
Dataset Creation#
Dataset creation is crucial for training robust machine learning models. A high-quality dataset should be diverse, representative, and accurately labeled. Key considerations include data sourcing, preprocessing, augmentation, and validation. Careful design choices in these stages significantly impact model performance. Data augmentation techniques, such as random cropping, rotations, and color jittering, can increase the dataset’s size and variability, improving the model’s ability to generalize to unseen data. Furthermore, using appropriate validation techniques, like k-fold cross-validation, can help prevent overfitting and ensure that the model can perform well on new, unseen data. Finally, open-sourcing the dataset promotes reproducibility and allows for community-driven improvements and broader research applications.
Real-World Limits#
Real-world limitations significantly hinder the practicality of purely synthetic training. While pre-trained models offer advantages, domain gaps between synthetic and real-world data necessitate further refinement. In real-world scenarios, material complexity surpasses the often-simplified representations in training datasets. Phenomena like spatially varying metallic properties due to corrosion or intricate text patterns challenge the model’s ability to capture fine-grained material variations. Additionally, outdoor scenes and complex lighting conditions pose further difficulties. Current models, predominantly trained on object-centric synthetic data, lack the robustness required for accurate decomposition in these complex real-world environments. This limitation underscores the importance of unsupervised techniques or other methods of incorporating real-world data to bridge the gap between synthetic training and real-world performance.
More visual insights#
More on figures

🔼 IDArb takes N images as input, which are sampled from N_v viewpoints and N_i illumination conditions. The input images are encoded into a latent space via VAE. The latent code is then concatenated with Gaussian noise for denoising. The intrinsic components are divided into 3 groups: albedo, normal, and metallic&roughness. Cross-component and cross-view attention modules are introduced in the UNet to exchange information across different components and views, enforcing global consistency.
read the caption
Figure 2: Top: Overview of IDArb. Bottom: Illustration of the attention block within the UNet. Our training batch consists of N𝑁Nitalic_N input images, sampled from Nvsubscript𝑁𝑣N_{v}italic_N start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT viewpoints and Nisubscript𝑁𝑖N_{i}italic_N start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT illuminations. The latent vector for each image is concatenated with Gaussian noise for denoising. Intrinsic components are divided into three triplets (D𝐷Ditalic_D=3): Albedo, Normal and Metallic&Roughness. Specific text prompts are used to guide the model toward different intrinsic components. For attention block inside UNet, we introduce cross-component and cross-view attention module into it, where attention is applied across components and views, facilitating global information exchange.

🔼 This figure gives an overview of the Arb-Objaverse dataset construction process. It shows examples of objects from ABO, G-Objaverse, and A12-Objaverse datasets, comparing their features regarding lighting conditions and object diversity. It then shows how Arb-Objaverse combines the strengths of other datasets with diverse objects from Objaverse, rendered under multiple illumination conditions using both HDR environment maps and point lights. Finally, the figure shows examples of generated intrinsic components (albedo, normal, metallic, and roughness) for an object from the Arb-Objaverse dataset.
read the caption
Figure 3: Overview of the Arb-Objaverse dataset. Our custom dataset features a diverse collection of objects rendered under various lighting conditions, accompanied by their intrinsic components.

🔼 This figure presents a qualitative comparison of albedo estimation results on synthetic data, showcasing the effectiveness of the proposed method (IDArb) in removing highlights and shadows from the estimated albedo. It compares IDArb with IID, RGB→X, IntrinsicAnything and ground truth.
read the caption
(a) Albedo estimation. Our method effectively removes highlights and shadows.

🔼 IDArb produces normals maps that accurately represent the shape geometry, including flat surfaces. It avoids artifacts and inconsistencies commonly produced by other methods, such as embedding texture details into the normal map. This is evident in the example shown, where IDArb correctly predicts smooth normals for the flat portions of the object.
read the caption
(b) Normal estimation. Our method gives shape geometry while correctly predicting flat surface.

🔼 Comparison of metallic estimation results among IID, RGB→X, the proposed method (IDArb), and ground truth. IDArb produces plausible metallic maps without interference from texture patterns and lighting, outperforming IID and RGB→X.
read the caption
(c) Metallic estimation. Our method outperforms IID and RGB↔↔\leftrightarrow↔X with plausible results free of interference from texture patterns and lighting.

🔼 This figure presents a qualitative comparison of roughness map estimation by different methods. The input image is shown alongside results from IID, RGB→X, and the proposed method (IDArb), along with the ground truth. The comparison highlights IDArb’s superior performance in producing plausible roughness maps that are free from the influence of texture patterns and lighting artifacts, unlike the other methods.
read the caption
(d) Roughness estimation. Our method outperforms IID and RGB↔↔\leftrightarrow↔X with plausible results free of interference from texture patterns and lighting.

🔼 Qualitative comparison of intrinsic decomposition results from different methods (IID, RGB→X, IntrinsicAnything, GeoWizard, IDArb) against ground truth on synthetic data. It shows example results for albedo, normal, metallic, and roughness estimation. IDArb produces more accurate and visually plausible intrinsic estimations compared to other methods, especially in removing highlights, shadows and texture interference caused by lighting.
read the caption
Figure 4: Qualitative comparison on synthetic data. IDArb demonstrates superior intrinsic estimation compared to all other methods.

🔼 This figure showcases qualitative results of IDArb on real-world images, comparing its performance against IntrinsicAnything for albedo estimation. The input images are shown in the first column, the albedo predicted by IntrinsicAnything in the second, and the albedo, normal, metallic, and roughness predicted by IDArb are in the third, fourth, fifth, and sixth columns respectively. IDArb generates accurate and detailed decompositions, preserving high-frequency details and correctly predicting albedo, particularly for metallic objects. In contrast, IntrinsicAnything tends to predict darker albedo for metallic materials and exhibits blurred details. Despite being trained solely on synthetic data, IDArb demonstrates robust generalization capabilities when applied to real-world images.
read the caption
Figure 5: Qualitative comparison on real-world data. IDArb generalizes well to real data, with accurate, convincing decompositions and high-frequency details.

🔼 This figure showcases how IDArb ensures multi-view consistency, unlike other learning-based methods which often produce inconsistent intrinsic properties across different views. Specifically, it visually compares the albedo and normal maps generated by IDArb and a competing learning-based approach when applied to multiple views of the same object. The close-up views emphasize the inconsistencies in the competitor’s outputs and highlight the consistent decompositions achieved by IDArb.
read the caption
(a)

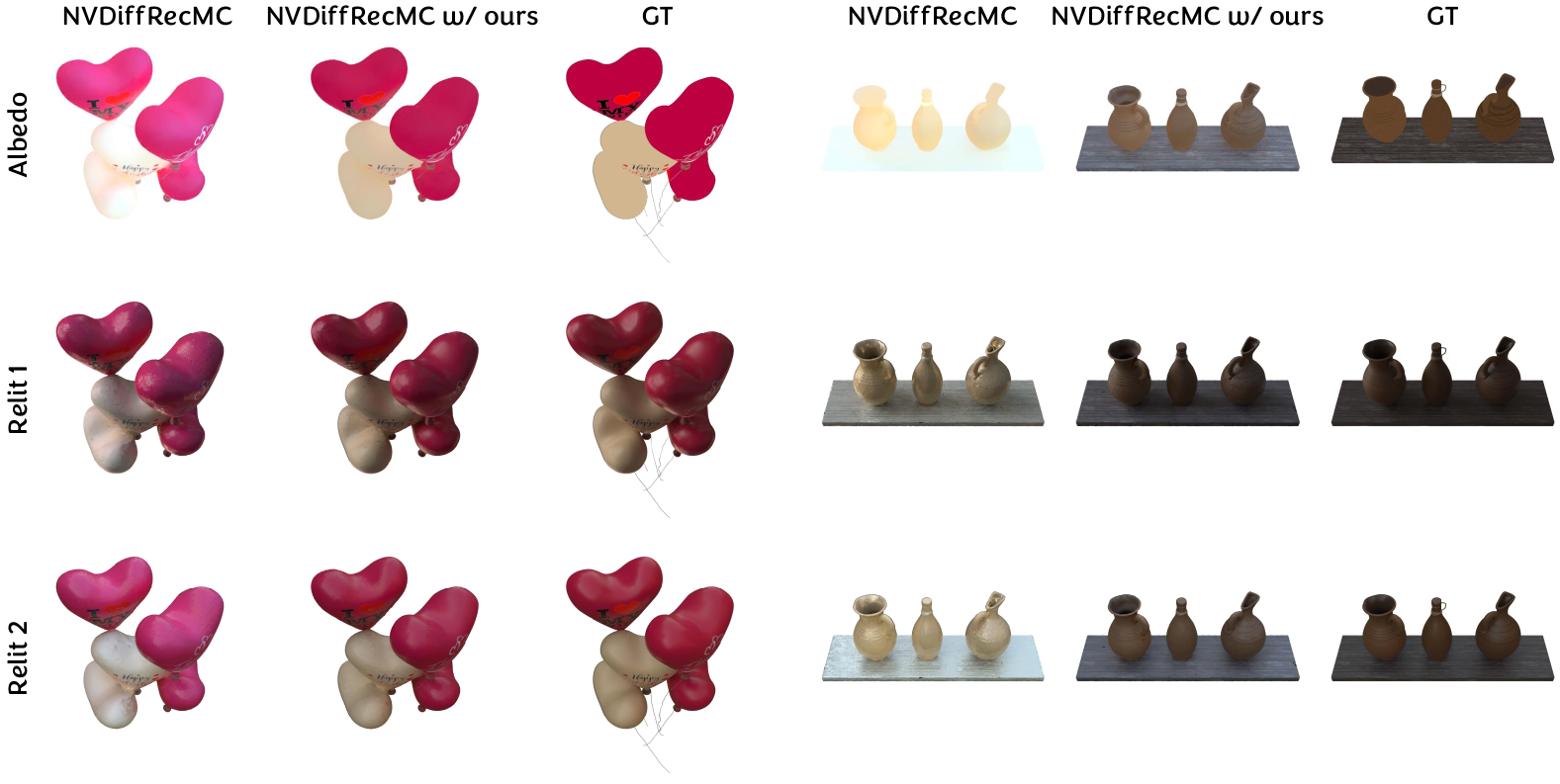
🔼 IDArb separates intrinsic images from lighting effects compared to traditional optimization-based methods. The optimization-based method NVDiffRecMC embeds some lighting effects in the intrinsic components, particularly in the material properties, as shown on the third column of the figure. The fourth column, representing the results of IDArb, successfully separates materials and lighting effects. This is attributed to the strong priors learned by IDArb from its training data on diverse objects under various lighting conditions.
read the caption
(b)

🔼 This figure presents two ablative studies conducted to assess the impact of key components of the IDArb model. (a) Cross-component Attention: This study investigates the effectiveness of fusing information across different intrinsic components (albedo, normal, metallic, and roughness). The results demonstrate that incorporating cross-component attention improves the accuracy of intrinsic decomposition, particularly by reducing material ambiguities for metallic and roughness properties. (b) Training Strategy: This study evaluates the impact of different training strategies on model performance. Specifically, it compares the results of training the model exclusively on multi-view inputs versus using a combined multi-view and single-view training approach. The results show that the combined approach leads to better generalization and improved performance on single-image inputs, highlighting the importance of incorporating both general object material priors and cross-view information during training.
read the caption
Figure 6: Ablative studies on (a) cross-component attention and (b) training strategy.
🔼 This figure analyzes the impact of varying the number of input viewpoints and lighting conditions on the performance of IDArb. The results generally indicate that increasing either the number of viewpoints or the diversity of lighting leads to improved intrinsic decomposition accuracy, especially in predicting metallic and roughness properties. However, the benefits of adding viewpoints appear to plateau beyond eight viewpoints.
read the caption
Figure 7: Effects of number of viewpoints and lighting conditions. We find increasing the number of viewpoints and the lighting conditions generally improves decomposition performance.

🔼 Figure 8 showcases the results of applying the IDArb model to perform relighting and material editing on real-world images. The figure is divided into three subfigures: (a) shows the original captured images, (b) displays the results of relighting the objects under novel illumination conditions, and (c) presents examples of material editing, demonstrating how IDArb can be used to modify material properties such as color, roughness, and metallic properties of the objects. The relighting results in (b) show that IDArb is robust to different lighting conditions. And material editing results in (c) show that IDArb can accurately decompose the intrinsic properties of the objects, thereby enabling their editing and creating realistic effects.
read the caption
Figure 8: Relighting and material editing results. From in-the-wild captures (a), our model allows for relighting under novel illumination (b) and material property modifications (c).

🔼 This figure showcases the results of using the proposed method in conjunction with an optimization-based inverse rendering approach, specifically NVDiffRecMC. It demonstrates that by incorporating the predictions of the proposed method as a prior, NVDiffRecMC can generate more plausible material properties, especially for albedo, which is prone to color shifting issues. In the figure, the first column displays the relighted results from two different novel environment maps using albedo produced by original NVDiffRecMC. The second column shows the relighted results utilizing albedo estimated by the proposed method together with NVDiffRecMC. The third column provides the ground truth. In these experiments, the proposed method’s output is used as pseudo-labels to guide the optimization of NVDiffRecMC.
read the caption
Figure 9: Optimization-based inverse rendering results. Our method guides NVDiffecMC generate more plausible material results.

🔼 This figure shows qualitative results of photometric stereo, which aims to estimate surface normal and albedo maps from images with varying lighting conditions using a fixed viewpoint, under the One-Light-At-a-Time (OLAT) setup, where each image is illuminated by a single point light source without ambient light. The first row demonstrates OLAT images and the estimated albedo and normal from OpenIllumination dataset (real data). The other rows present the decomposition on NeRFactor dataset (synthetic data).
read the caption
Figure 10: Photometric stereo results using 4 OLAT images in OpenIllumination and NeRFactor.

🔼 This figure showcases additional qualitative results of IDArb on real-world images, complementing the results presented earlier in the paper. Each row features a different object, and within each row, from left to right: the original input image, the estimated albedo, the estimated normal map, the estimated metallic map, and the estimated roughness map. These diverse examples illustrate IDArb’s capacity to decompose real-world images into their intrinsic components. The model, while trained on synthetic data, generalizes reasonably well to real-world photos of objects with varied material properties. The objects presented include a metal skull, a sofa, a bouquet of flowers, toy figure, a plate of fruit, a wooden easel, a metallic teapot, and a ceramic figurine of rabbits. These results provide a visual demonstration of the model’s ability to handle a range of object shapes, materials, and lighting conditions encountered in real-world photography.
read the caption
Figure 11: More results on real-world data.

🔼 This figure shows additional qualitative results of IDArb on real-world images. The first column displays the original input images. The following columns present the predicted albedo, normal, metallic, and roughness maps. The ‘Recon’ column shows the reconstructed images using the predicted intrinsic components, while the ‘Relit’ columns display the results after relighting with different environment maps, showcasing the applicability of IDArb to downstream tasks like single-image relighting and material editing. Specifically, it shows examples of a motorcycle, a car, trumpets, and a breakfast setting.
read the caption
Figure 12: More results on real-world data. We also provide the reconstructed and relighting images.

🔼 This figure showcases additional results of the IDArb model on multi-view data, further demonstrating its ability to decompose intrinsic properties (albedo, normal, metallic, and roughness) from multiple input images. Each row presents a different object, with the columns displaying the input images and the corresponding predicted intrinsic components. The consistent appearance of the intrinsic components across different viewpoints highlights the model’s multi-view consistency.
read the caption
Figure 13: More results on multi-view data.

🔼 This figure showcases the results of IDArb on multiview images with extreme lighting variations from the NeRD dataset. Each scene includes four input views demonstrating varying illumination conditions, alongside the predicted albedo, normal, metallic, and roughness maps.
read the caption
Figure 14: Multiview images with extreme lighting variation. For each scene in NeRD dataset (Boss et al., 2021a), we input 4 views.

🔼 This figure presents a few failure cases of the IDArb model. The first row shows an outdoor scene, where the model struggles with generalization since it is primarily trained on object-centric synthetic data. The second row shows a product box with text. The model has difficulty recovering complex text structures. The third row shows a telephone, where the model overly simplifies the material details, due to the limited material variations presented in the synthetic training data.
read the caption
Figure 15: Failure cases.

🔼 This figure presents the results of intrinsic image decomposition on outdoor scenes from the Mip-NeRF 360 dataset. For each scene, four input views are provided, and the model predicts albedo, normal, metallic, and roughness maps. The figure demonstrates the model’s ability to generalize to complex outdoor environments and maintain consistency across different viewpoints under various lighting conditions. Although trained primarily on object-centric data, the model exhibits reasonable performance on these scene-level images. However, it can be observed that some material predictions are oversimplified, particularly for metallic and roughness, where the model tends to assign global values rather than capturing finer details within the scene.
read the caption
Figure 16: Results on Mip-NeRF 360 (Barron et al., 2022) (Part 1, outdoor). We input 4 views for each scene.
More on tables
| # OLAT Images | 2 | 4 | 8 | |||
|---|---|---|---|---|---|---|
| Methods | Albedo | Normal | Albedo | Normal | Albedo | Normal |
| IID | 22.23 | - | 22.40 | - | 22.86 | - |
| RGB X | 21.29 | 0.71 | 22.08 | 0.77 | 23.29 | 0.81 |
| SDM-UniPS | 22.95 | 0.74 | 23.20 | 0.76 | 23.37 | 0.81 |
| Ours | 23.50 | 0.83 | 23.64 | 0.84 | 25.15 | 0.85 |
🔼 This table presents a quantitative comparison of different intrinsic decomposition methods’ performance on the NeRFactor dataset for photometric stereo under the challenging One-Light-At-a-Time (OLAT) condition, using varying numbers of input images (2, 4, and 8). Performance metrics such as albedo (SSIM, PSNR) and normal (cosine similarity) are compared across methods like IID, RGB↔X, SDM-UniPS, and the proposed IDArb. The results demonstrate IDArb achieves the best performance across all metrics and input image counts.
read the caption
Table 2: Quantitative results for photometric stereo on NeRFactor. We evaluate performance using 2, 4, and 8 OLAT images, and achieve the best performance among all compared methods.
| Nerfactor | Synthetic4Relight | |||||
|---|---|---|---|---|---|---|
| Albedo (raw) | Albedo (scaled) | Relighting | Albedo (raw) | Albedo (scaled) | Relighting | |
| NVDiffRecMC | 17.89 | 25.88 | 22.65 | 17.03 | 29.64 | 24.05 |
| NVDiffRecMC w/ Ours | 20.90 | 26.61 | 27.20 | 26.42 | 30.73 | 31.01 |
🔼 This table presents an ablation study on using IDArb’s intrinsic component predictions as pseudo-labels to guide optimization-based inverse rendering methods, specifically NVDiffRecMC. The experiments are conducted on NeRFactor and Synthetic4Relight datasets. It compares NVDiffRecMC’s raw and scaled albedo predictions, relighting quality, and estimated roughness, both with and without the IDArb-derived pseudo-labels. The table demonstrates that using IDArb’s predictions as a prior improves the optimization process in NVDiffRecMC, leading to enhanced relighting results and more physically plausible material estimation, particularly in mitigating color shifts in the reconstructed albedo.
read the caption
Table 3: Ablation on IDArb pseudo labels for optimization-based inverse rendering on NeRFactor and Synthetic4Relight datasets.
| # L | # V | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|---|
| 1 | 29.16 | 28.72 | 30.12 | 30.49 | 30.77 | |
| 2 | 29.96 | 30.26 | 30.96 | 31.13 | 31.26 | |
| 3 | 30.25 | 30.73 | 31.16 | 31.33 | 31.40 |
🔼 This table presents the Albedo performance measured by PSNR with varying number of input views and lighting conditions during training. ↑ indicates higher is better. The table shows that both increasing the number of input views and lighting conditions could generally improve the albedo prediction performance.
read the caption
Table 4: Albedo Performance ↑↑\uparrow↑ across different numbers of viewpoints (# V) and lightings (# L).
| # L | # V | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|---|
| 1 | 0.909 | 0.910 | 0.925 | 0.930 | 0.932 | |
| 2 | 0.922 | 0.927 | 0.930 | 0.933 | 0.934 | |
| 3 | 0.926 | 0.931 | 0.931 | 0.934 | 0.935 |
🔼 This table presents the performance of normal estimation across different numbers of input viewpoints and lighting conditions. The values in the table represent Cosine Similarity, where higher values indicate better performance.
read the caption
Table 5: Normal Performance ↑↑\uparrow↑ across different numbers of viewpoints (# V) and lightings (# L).
| # L | # V | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|---|
| 1 | 0.105 | 0.116 | 0.068 | 0.059 | 0.050 | |
| 2 | 0.061 | 0.068 | 0.047 | 0.044 | 0.042 | |
| 3 | 0.061 | 0.056 | 0.048 | 0.045 | 0.040 |
🔼 Shows the metallic estimation performance measured by Mean Squared Error (MSE) with varying numbers of input views and lighting conditions. Lower MSE indicates better performance.
read the caption
Table 6: Metallic Performance ↓↓\downarrow↓ across different numbers of viewpoints (# V) and lightings (# L).
| # L | # V | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|---|
| 1 | 0.049 | 0.050 | 0.024 | 0.019 | 0.021 | |
| 2 | 0.043 | 0.026 | 0.019 | 0.016 | 0.015 | |
| 3 | 0.031 | 0.022 | 0.016 | 0.014 | 0.013 |
🔼 Shows the performance of roughness prediction with varying numbers of input views and lighting conditions using Mean Squared Error (MSE). Lower values indicate better performance.
read the caption
Table 7: Roughness Performance ↓↓\downarrow↓ across different numbers of viewpoints (# V) and lightings (# L).
| SSIM↑ | PSNR↑ | LPIPS↓ | |
|---|---|---|---|
| Ours | 0.876 | 27.98 | 0.117 |
| IntrinsicAnything | 0.896 | 25.66 | 0.150 |
🔼 This table presents a quantitative comparison of the proposed IDArb method and a baseline method, IntrinsicAnything, on the MIT-Intrinsic dataset. The metrics used for evaluation are SSIM, PSNR, and LPIPS.
read the caption
Table 8: Quantitative comparisons on MIT-Intrinsic.
| Normal Cosine Distance↓ | Albedo SSIM↑ | Albedo PSNR↑ | Albedo LPIPS↓ | Re-rendering PSNR-H↑ | Re-rendering PSNR-L↑ | Re-rendering SSIM↑ | Re-rendering LPIPS↓ | |
|---|---|---|---|---|---|---|---|---|
| Ours(single) | 0.041 | 0.978 | 41.30 | 0.039 | 24.11 | 31.28 | 0.969 | 0.024 |
| Ours(multi) | 0.029 | 0.978 | 41.46 | 0.038 | 24.36 | 31.43 | 0.970 | 0.024 |
| StableNormal | 0.038 | |||||||
| IntrinsicNeRF | 0.981 | 39.31 | 0.048 |
🔼 This table presents a quantitative comparison of IDArb against StableNormal and IntrinsicNeRF on the Stanford-ORB dataset. The metrics used for evaluation include Cosine Distance for normals, SSIM, PSNR, and LPIPS for albedo, and PSNR-H, PSNR-L, SSIM, and LPIPS for re-rendering. IDArb is evaluated in both single-view and multi-view settings.
read the caption
Table 9: Quantitative comparisons on Stanford-ORB.
Full paper#



















