↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Creating realistic 3D scenes from single images is tough due to limited info & massive compute. Existing methods either need multiple views, have lengthy optimization, or struggle with detail & consistency. This limits broader use in AR/VR or gaming.
This paper proposes Wonderland, a system that generates detailed 3D scenes from single images efficiently. It leverages the power of video diffusion models to learn 3D relationships from videos, and uses their compressed video latents. A new dual-branch conditioning mechanism controls camera paths, and a large reconstruction model directly builds 3D from these latents. It yields high-quality, consistent 3D scenes faster than prior art.
Key Takeaways#
Why does it matter?#
This work significantly pushes single-view 3D scene generation forward by addressing limitations like multi-view data needs and extensive compute. The latent-based approach opens new research directions in leveraging video diffusion models for efficient, high-quality 3D content creation, impacting fields like VR/AR and gaming.
Visual Insights#

🔼 Figure 1 presents a set of visual outputs produced by the Wonderland model. Using just a single input image, Wonderland is able to generate novel views of a 3D scene. The 3D reconstruction process is feed-forward, leveraging the latent space of a video diffusion model to efficiently create 3D Gaussian Splatting (3DGS) representations. This figure demonstrates the model’s capacity to generate diverse and detailed 3D scenes from a single image. Two examples are shown, each with their input image and corresponding novel views generated from the reconstructed 3D scene.
read the caption
Figure 1: Visual results generated by Wonderland. Given a single image, Wonderland reconstructs 3D scenes from the latent space of a camera-guided video diffusion model in a feed-forward manner.
| Method | Dataset | FID ↓ | FVD ↓ | Rerr ↓ | Terr ↓ | LPIPS ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|---|---|---|---|---|
| MotionCtrl [47] | RealEstate10K | 22.58 | 229.34 | 0.231 | 0.794 | 0.296 | 14.68 | 0.402 |
| VD3D [1] | RealEstate10K | 21.40 | 187.55 | 0.053 | 0.126 | 0.227 | 17.26 | 0.514 |
| ViewCrafter [55] | RealEstate10K | 20.89 | 203.71 | 0.054 | 0.152 | 0.212 | 18.91 | 0.501 |
| Ours | RealEstate10K | 16.16 | 153.48 | 0.046 | 0.093 | 0.206 | 19.71 | 0.557 |
| MotionCtrl [47] | DL3DV | 25.58 | 248.77 | 0.467 | 1.114 | 0.309 | 14.35 | 0.385 |
| VD3D [1] | DL3DV | 22.70 | 232.97 | 0.094 | 0.237 | 0.259 | 16.28 | 0.487 |
| ViewCrafter [55] | DL3DV | 20.55 | 210.62 | 0.092 | 0.243 | 0.237 | 17.10 | 0.519 |
| Ours | DL3DV | 17.74 | 169.34 | 0.061 | 0.130 | 0.218 | 17.56 | 0.543 |
| MotionCtrl [47] | Tanks and Temples | 30.17 | 289.62 | 0.834 | 1.501 | 0.312 | 14.58 | 0.386 |
| VD3D [1] | Tanks and Temples | 24.33 | 244.18 | 0.117 | 0.292 | 0.284 | 15.35 | 0.467 |
| ViewCrafter [55] | Tanks and Temples | 22.41 | 230.56 | 0.125 | 0.306 | 0.245 | 16.20 | 0.506 |
| Ours | Tanks and Temples | 19.46 | 189.32 | 0.094 | 0.172 | 0.221 | 16.87 | 0.529 |
| Lora-branch | Ablations on RE10K | 19.02 | 212.74 | 0.102 | 0.157 | - | - | - |
| Ctrl-branch | Ablations on RE10K | 18.75 | 205.45 | 0.058 | 0.104 | - | - | - |
| Dual-branch | Ablations on RE10K | 17.22 | 183.54 | 0.052 | 0.095 | - | - | - |
🔼 This table presents a quantitative comparison of various camera-guided video generation models, including MotionCtrl, VD3D, ViewCrafter, and the proposed method. The evaluation is conducted on three benchmark datasets: RealEstate10K, DL3DV, and Tanks and Temples. The metrics used for comparison encompass visual quality (FID and FVD), camera guidance precision (Rotation Error and Translation Error), and visual similarity (LPIPS, PSNR, and SSIM). A lower value is better for FID, FVD, LPIPS, rotation error, and translation error. A higher value is better for PSNR and SSIM.
read the caption
Table 1: Quantitative comparison to the prior arts in camera-guided video generation on RealEstate10K, DL3DV, and Tanks and Temples dataset. We report the performance for visual quality (FID and FVD), camera-guidance precision (Rerrsubscript𝑅errR_{\text{err}}italic_R start_POSTSUBSCRIPT err end_POSTSUBSCRIPT and Terrsubscript𝑇errT_{\text{err}}italic_T start_POSTSUBSCRIPT err end_POSTSUBSCRIPT), and visual similarity (LPIPS, PSNR, and SSIM).
In-depth insights#
3D from Video#
Wonderland leverages video diffusion models to generate 3D scenes from single images. It bypasses the limitations of image-based methods by operating in a compressed, 3D-aware latent space, achieving higher efficiency and broader scene coverage. The novel dual-branch conditioning mechanism ensures precise camera control, vital for novel view synthesis. The latent-based 3D reconstruction model (LaLRM) directly generates 3D Gaussian Splats from these latents, sidestepping costly per-scene optimization and enabling fast, high-fidelity 3D generation. Though current work focuses on static scenes, future development could incorporate temporal dynamics for 4D content creation.
Latent 3D#
Latent 3D representations offer a powerful approach to 3D scene understanding and generation. By operating in a compressed latent space, rather than directly on pixels or point clouds, models can achieve greater efficiency and scalability. This is particularly crucial for handling complex scenes and facilitating feed-forward inference. Moreover, learning in latent space allows models to capture higher-level semantic information, leading to improved generalization and robustness, especially for out-of-domain data. Latent 3D also opens up exciting possibilities for controllable generation, allowing manipulation of scene attributes within the latent space. Despite these advantages, challenges remain in bridging the gap between latent representations and explicit 3D geometry, as well as ensuring consistency between latent manipulations and the rendered output. Continued research in this area promises further advancements in 3D vision tasks.
Dual-Branch Control#
Dual-branch control enhances camera guidance in video diffusion models. One branch uses ControlNet for precise pose control by directly influencing feature maps with camera data. The other branch employs LoRA for efficient fine-tuning, enhancing the model’s adaptation to static scenes and camera motions without altering base weights. This combined approach balances fine-grained control and computational efficiency, enabling high-quality video generation with accurate camera trajectories.
Progressive Training#
Progressive training tackles the domain gap between video latents and 3D Gaussian Splats. Initial training uses lower resolution videos with known camera poses from benchmarks. This establishes a foundation for 3D consistency. Subsequently, training scales to higher resolutions, incorporating synthetic data and out-of-domain videos. This enhances generalization and robustness to unseen scenarios, critical for high-fidelity, wide-scope 3D scene reconstruction.
Zero-Shot Synthesis#
Zero-shot synthesis signifies generating novel content without prior training on specific examples. This capability is crucial in 3D scene generation, allowing creation from single images or sparse data. Wonderland leverages this power by utilizing camera-guided video diffusion models. These models, trained on extensive video data, implicitly encode 3D scene understanding, enabling novel view synthesis and unseen region reconstruction. Key aspects of zero-shot synthesis in Wonderland include: 1) Leveraging video diffusion models: Camera trajectories embedded in video data instill 3D awareness. 2) Dual-branch camera guidance: Ensures precise control over camera poses for multi-view consistency. 3) Latent Large Reconstruction Model (LaLRM): Efficiently reconstructs 3D scenes from compressed video latents. These components allow Wonderland to generate high-quality, wide-scope 3D scenes directly from single images.
More visual insights#
More on figures

🔼 Given a single image, Wonderland reconstructs 3D scenes using a camera-guided video diffusion model and a latent-based large reconstruction model (LaLRM). The video diffusion model, conditioned on the input image and camera trajectory, generates a 3D-aware video latent. This latent is then used by the LaLRM to construct the 3D scene in a feed-forward manner. The dual-branch camera conditioning in the video diffusion model ensures precise pose control, while the LaLRM’s operation in latent space allows for efficient reconstruction of wide-scope, high-fidelity 3D scenes.
read the caption
Figure 2: Overview of Wonderland. Given a single image, a camera-guided video diffusion model follows the camera trajectory and generates a 3D-aware video latent, which is leveraged by the latent-based large reconstruction model to construct the 3D scene in a feed-forward manner. The video diffusion model involves dual-branch camera conditioning to fulfill precise pose control. The LaLRM operates in latent space and efficiently reconstructs a wide-scope and high-fidelity 3D scene.

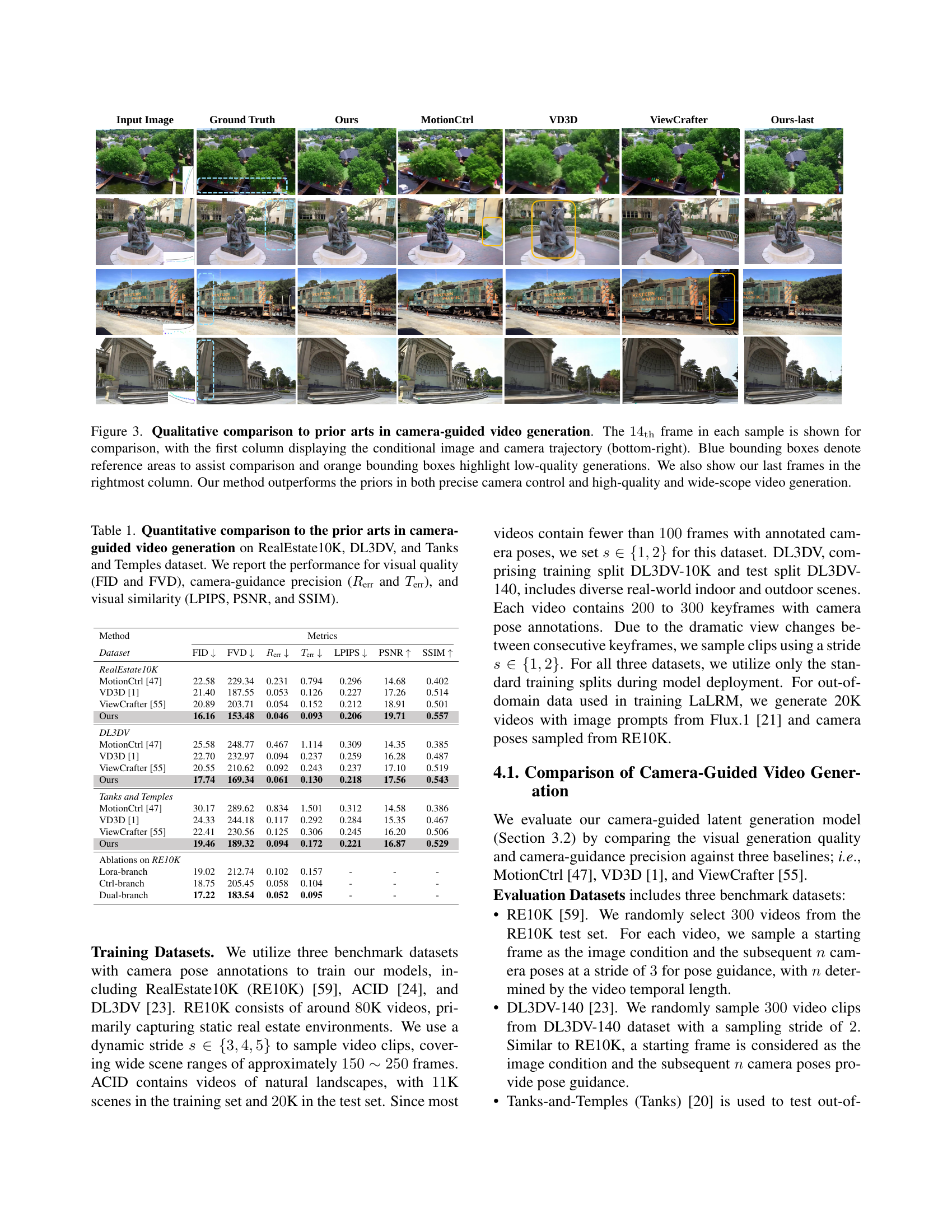
🔼 This figure provides a qualitative comparison of several camera-guided video generation models, including MotionCtrl, VD3D, ViewCrafter, and the proposed method, Wonderland. Each model is tasked with generating a video sequence conditioned on a single input image and a specified camera trajectory. The 14th frame of each generated sequence is displayed for comparison, along with the ground truth frame and the conditional input image. The comparison highlights Wonderland’s superior performance in terms of precise camera control, high visual quality, and wide-scope scene generation, particularly when compared to other methods that might exhibit misalignment with the specified camera trajectory, limited visual quality, or a narrow scope of generation.
read the caption
Figure 3: Qualitative comparison to prior arts in camera-guided video generation. The 14thsubscript14th14_{\mathrm{th}}14 start_POSTSUBSCRIPT roman_th end_POSTSUBSCRIPT frame in each sample is shown for comparison, with the first column displaying the conditional image and camera trajectory (bottom-right). Blue bounding boxes denote reference areas to assist comparison and orange bounding boxes highlight low-quality generations. We also show our last frames in the rightmost column. Our method outperforms the priors in both precise camera control and high-quality and wide-scope video generation.

🔼 This figure presents a qualitative comparison of novel view synthesis from a single image among Wonderland, ViewCrafter, and ZeroNVS. Each row showcases a different scene, with ground truth on the far left, then the novel view generated by each method. The first two scenes are indoors and the last is outdoors. Blue boxes indicate regions visible in the original image. Yellow boxes highlight areas where comparison methods struggle with quality or consistency. Wonderland shows significant improvement in rendering high-quality and detailed novel views, particularly in unseen or partially occluded regions.
read the caption
Figure 4: Qualitative comparison for 3D scene generation. Blue bounding boxes show visible regions from conditional images and yellow bounding boxes show low-quality regions. Our approach generates much higher quality novel views from one conditional image.

🔼 This figure presents a qualitative comparison of our proposed method, Wonderland, with two existing state-of-the-art approaches, ViewCrafter and WonderJourney, for generating 3D scenes from single in-the-wild images. Each row showcases a different scene. The leftmost column displays the original input image, while the remaining columns display novel views generated by each method. Wonderland excels at producing consistent and realistic renderings, even across wide viewpoints and previously unseen regions of the scene. ViewCrafter’s performance is limited to a narrow field of view around the input image, exhibiting quality degradation as the view range expands. WonderJourney, designed for zoom-out effects, generates novel views with a wider field of view but suffers from blurry outputs and noticeable artifacts.
read the caption
Figure 5: Comparison with ViewCrafter (left) and WonderJourney (right) for in-the-wild 3D scene generation from single input images.

🔼 This figure presents a qualitative comparison of 3D scene generation between Wonderland, ZeroNVS, and Cat3D on scenes from the Mip-NeRF dataset. Each scene’s source image is displayed in the leftmost column. For each method, renderings from two viewpoints are shown: the initial viewpoint (corresponding to the input image) in the top row and a novel view at a 120-degree rotation from the initial viewpoint in the bottom row. This comparison aims to demonstrate the quality and consistency of novel view synthesis generated by each method, particularly in handling out-of-view regions and geometric details.
read the caption
Figure 6: Comparison to ZeroNVS and Cat3D with Mip-Nerf dataset on 3D scene generation from single input images. For each scene, the conditional image is shown in the left-most column. We show renderings from two viewpoints, one at the conditional image (starting) view (upper) and another at around 120°-rotation from the starting view(lower).

🔼 This figure shows a comparison of video generations between two models: a source I2V model and a fine-tuned model. The top row displays output from the original source I2V model. The bottom row displays output from the I2V model fine-tuned on static scene datasets using LoRA. The comparison shows that the fine-tuned model produces significantly more static scenes. Specifically, the fine-tuned model generates videos with fewer motion changes compared to the original source model for scenes containing subjects like people and animals.
read the caption
Figure A1: Comparison of video generations between the source model (upper row) and the model fine-tuned on static-scene datasets with LoRA modules (lower row). The results demonstrate that fine-tuning the model on static-scene datasets equipped with LoRA produces significantly more static scenes.

🔼 This figure compares the 3D rendering performance of two latent reconstruction models: one fine-tuned without in-the-wild data and the other with it. Each model is used to render a pair of novel views of four different scenes. The upper row shows results from the model trained only on benchmark datasets, while the lower row shows results from the model further fine-tuned with an in-the-wild dataset. The inclusion of in-the-wild data during fine-tuning leads to a noticeable improvement in the generalization capability of the model, resulting in higher quality 3D renderings with finer details.
read the caption
Figure A2: Comparison of 3D rendering performance between latent reconstruction models fine-tuned without in-the-wild dataset (upper row) and with in-the-wild dataset (lower row). Involving in-the-wild datasets during fine-tuning improves the generalization capability.

🔼 This architecture diagram outlines the Dual-branch Camera-guided Video Diffusion Model. It illustrates the integration of camera guidance using both a LoRA-branch and a ControlNet-branch during the training process. Random noise is introduced to video latents, while the conditional image is incorporated through feature concatenation. For clarity, text tokens, diffusion time embeddings, positional embeddings, and some reshaping operations are omitted. In the underlying diffusion transformer, text tokens are concatenated with visual tokens along the number-of-token dimension. To maintain consistent length, zero-padding is applied to the camera tokens before concatenation or element-wise summation. The SiLU activation function is used by default.
read the caption
Figure A3: Structure of Dual-branch Camera-guided Video Diffusion Model. We show the skeletons of the training pipeline, where random noise is added to the video latents. The conditional image is merged to the noisy latents via feature concatenation. The camera guidance is integrated with LoRA-branch (left) and ControlNet-branch (right). We ignore the text tokens, the diffusion time embeddings, the positional embeddings, and some reshaping operations for simplicity in the figure. In the foundation diffusion transformer, the text tokens are concatenated along number-of-token dimension with visual tokens. Thus we apply zero-padding to camera tokens to guarantee the same length before concatenation or element-wise sum. By default, we use SiLu as our activation function.
More on tables
| Method | RealEstate10K | DL3DV | Tanks-and-Temples | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | ||
| — | — | — | — | — | — | — | — | — | — | — | |
| ZeroNVS [38] | 0.448 | 13.01 | 0.378 | 0.465 | 13.35 | 0.339 | 0.470 | 12.94 | 0.325 | ||
| ViewCrafter [55] | 0.341 | 16.84 | 0.514 | 0.352 | 15.53 | 0.525 | 0.384 | 14.93 | 0.483 | ||
| Ours | 0.292 | 17.15 | 0.550 | 0.325 | 16.64 | 0.574 | 0.344 | 15.90 | 0.510 | ||
| Ablation-LaLRM | |||||||||||
| RGB-14 | 0.137 | 21.39 | 0.751 | 0.205 | 18.76 | 0.696 | 0.221 | 19.70 | 0.605 | ||
| RGB-49 | 0.126 | 25.06 | 0.830 | 0.196 | 20.94 | 0.733 | 0.192 | 20.54 | 0.687 | ||
| Latent-based | 0.122 | 27.10 | 0.864 | 0.159 | 23.25 | 0.786 | 0.170 | 22.66 | 0.743 |
🔼 This table presents a quantitative comparison of different methods for 3D scene novel view synthesis from a single image on various benchmark datasets, including RealEstate10K, DL3DV, and Tanks-and-Temples. The metrics used for evaluation include LPIPS, PSNR, and SSIM, which measure the quality and similarity of the rendered views compared to ground truth views. The table shows the performance of ZeroNVS, ViewCrafter, the proposed method, and an ablation study of the proposed method.
read the caption
Table 2: Quantitative comparison on various benchmark datasets for 3D scene novel view synthesis with single view condition.
| Expression | Specification | Explanation |
|---|---|---|
| Expression | Specification | Explanation |
| — | — | — |
| commonly used | ||
| $x$ | $x \in R^{T\times H\times W\times 3}$ | source video clip |
| $s$ | - | stride to sample clip $x$ from source video |
| $z$ | $z \in R^{t\times h\times w\times c}$ | video latent embedded from $x$ |
| $\mathcal{E}$ | - | encoder from 3D-VAE |
| $r_s$ | $r_s = \frac{H}{h} = \frac{W}{w}$ | spatial compression rate |
| $r_t$ | $r_t = \frac{T}{t}$ | temporal compression rate |
| $p$ | $p \in R^{T\times H\times W\times 6}$ | Plücker embedding of cameras of video clip $x$ |
| diffusion used | ||
| $\tau$ | - | diffusion time step |
| $\alpha_{\tau}, \sigma_{\tau}$ | - | diffusion noise scheduler parameters |
| $z_{\tau}$ | - | noisy video latent |
| $D_{\theta}$ | - | diffusion model parameterized by $\theta$ |
| $o_v$ | $o_v \in R^{N_v\times d_v}$ | visual tokens as a sequence in diffusion model |
| $o_{\mathrm{ctrl}}$, $o_{\mathrm{lora}}$ | $o_{\mathrm{ctrl}}$, $o_{\mathrm{lora}} \in R^{N_v\times d_v}$ | camera tokens as a sequence in diffusion model |
| $N$ | - | number of transformer blocks in ControlNet branch |
| reconstruction used | ||
| $p_l$ | - | spatial patch size applied to $z$ in LaLRM |
| $o_l$ | $o_l \in R^{N_l\times d_l}$ | visual latent tokens as a sequence in LaLRM |
| $N_l$ | $N_l = t\cdot\frac{h}{p_l}\cdot\frac{w}{p_l}$ | number of visual latent tokens in LaLRM |
| $o_{\mathrm{p}}$ | $o_{\mathrm{p}} \in R^{N_l\times d_l}$ | camera tokens as a sequence in LaLRM |
| $V$ | - | number of supervision views in LaLRM |
| $G$ | $G \in R^{(T\cdot H\cdot W)\times 12}$ | Gaussian feature map in LaLRM |
🔼 This table provides a comprehensive list of notations used throughout the paper, along with their corresponding specifications and explanations. It serves as a quick reference for readers to understand the meaning of symbols and variables used in equations and figures.
read the caption
Table A1: Overview of the notations used in the paper.
| Architecture | FID ↓ | FVD ↓ | Rerr ↓ | Terr ↓ |
|---|---|---|---|---|
| Lora-branch | 19.02 | 212.74 | 0.102 | 0.157 |
| Ctrl-branch | 18.75 | 205.45 | 0.058 | 0.104 |
| Dual-branch | 17.22 | 183.54 | 0.052 | 0.095 |
| Dual w/o LoraModule | 17.84 | 195.07 | 0.062 | 0.101 |
| Ctrl-branch only | ||||
| w/o weight copy | 18.92 | 206.75 | 0.065 | 0.108 |
| block-1 | 19.90 | 214.66 | 0.114 | 0.162 |
| blocks-10 | 19.15 | 210.74 | 0.075 | 0.126 |
| blocks-30 | 20.15 | 221.61 | 0.056 | 0.105 |
🔼 This table evaluates different architecture designs for a camera-guided video generation model, focusing on visual quality (FID and FVD) and camera control precision (rotation and translation errors). The models are trained on the RealEstate10K dataset. The top section of this table replicates data from Table 1 in the main paper, providing a baseline comparison to other state-of-the-art methods.
read the caption
Table A2: Analysis on architecture designs in camera-guided video generation model. We report the performance for visual quality (FID and FVD) and pose control precision (Rerrsubscript𝑅errR_{\text{err}}italic_R start_POSTSUBSCRIPT err end_POSTSUBSCRIPT and Terrsubscript𝑇errT_{\text{err}}italic_T start_POSTSUBSCRIPT err end_POSTSUBSCRIPT) from models trained on RealEstate10K dataset. The first section of the table is adopted from Tab.1 in the main paper.
| Method | RealEstate10K | DL3DV | Tanks-and-Temples | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | |
| LaLRM– | 0.295 | 17.06 | 0.538 | 0.343 | 16.62 | 0.570 | 0.359 | 15.85 | 0.502 | |
| LaLRM | 0.292 | 17.15 | 0.550 | 0.325 | 16.64 | 0.574 | 0.344 | 15.90 | 0.510 |
🔼 This table evaluates the effect of fine-tuning the Latent Large Reconstruction Model (LaLRM) with an in-the-wild dataset on its ability to perform 3D scene novel view synthesis from single-view images. The evaluation uses three benchmark datasets: RealEstate10K, DL3DV, and Tanks-and-Temples. The metrics used are LPIPS, PSNR, and SSIM, which measure the quality and similarity of rendered images compared to ground truth views. Two versions of the model are evaluated: LaLRM- (trained without the in-the-wild dataset), and LaLRM (trained with the in-the-wild dataset), demonstrating the effectiveness of including in-the-wild data during fine-tuning.
read the caption
Table A3: Analysis on involving in-the-wild dataset to fine-tune LaLRM. We report the performance on various benchmark datasets for novel view synthesis of 3D scenes, which are built from single view condition.
Full paper#