↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
Data contamination significantly impacts LLM evaluation. This work introduces a novel benchmark, which automatically updates with real-world knowledge, ensuring contamination-free evaluation. This automation enables easier adaptation to new LLMs and facilitates more reliable research progress by addressing a critical challenge in the field.
Visual Insights#

🔼 AntiLeak-Bench constructs contamination-free benchmark samples by identifying knowledge updated after a given LLM’s knowledge cutoff time. It then uses this updated knowledge to create questions and gathers relevant supporting documents from sources like Wikipedia, ensuring the benchmark evaluates an LLM’s ability to handle truly novel information not present in its training data.
read the caption
Figure 1: Illustration of AntiLeak-Bench. It constructs contamination-free samples with the knowledge updated after LLMs’ cutoff time, which thus are not in LLMs’ training sets.
| Benchmark | Strictly Contamination-Free | Automated | Multilingual | Data Source |
|---|---|---|---|---|
| Realtime QA | ✗ | ✗ | ✗ | Real world |
| LiveBench | ✗ | ✗ | ✗ | Real world |
| ADU | ✗ | ✓ | ✗ | LLM generation |
| AntiLeak-Bench | ✓ | ✓ | ✓ | Real world |
🔼 This table compares AntiLeak-Bench with other benchmarks like RealtimeQA, LiveBench, and ADU, based on four criteria: strictly contamination-free, automated, multilingual, and data source. It highlights that AntiLeak-Bench is the only benchmark that satisfies all four criteria.
read the caption
Table 1: Comparisons between AntiLeak-Bench and other benchmarking frameworks.
In-depth insights#
Data Contamination#
Data contamination significantly impacts LLM evaluation. Benchmarks, used to assess LLMs, become unreliable when their test data leaks into training sets of newer models, artificially inflating performance metrics. This contamination undermines the validity of comparisons and progress tracking. Publicly available, static benchmarks are particularly susceptible. As LLMs evolve rapidly, ensuring contamination-free evaluation becomes crucial for reliable insights into true capabilities and advancements.
AntiLeak-Bench#
AntiLeak-Bench combats data contamination in Large Language Model (LLM) evaluation by creating benchmarks with up-to-date, real-world knowledge. It addresses the limitations of static benchmarks, whose reuse in training data inflates performance metrics and makes accurate assessment difficult. Unlike existing dynamic benchmarks, which simply use newly collected data, AntiLeak-Bench verifies that the knowledge is genuinely new and absent from LLMs’ training sets. This ensures contamination-free evaluation by constructing samples querying this updated knowledge. Furthermore, its fully automated workflow eliminates human labor, allowing easy maintenance and adaptation to new LLMs, unlike resource-intensive manual updates. This framework offers more reliable and practical benchmarking for consistent and contamination-free LLM evaluation.
Automated Workflow#
AntiLeak-Bench’s automated workflow revolutionizes benchmark maintenance. It eliminates manual updates by automatically constructing samples with newly updated real-world knowledge from Wikidata and Wikipedia. This automation reduces labor, ensures frequent updates, and enables the benchmark to adapt to emerging LLMs. The workflow retrieves updated claims, identifies corresponding Wikipedia articles and revisions after the LLM’s cutoff time, and constructs contamination-free samples querying the updated knowledge with the supporting documents as context. This ensures evaluation remains relevant and reliable, addressing the challenge of data contamination and enhancing benchmark scalability.
Contamination-Free Eval#
Data contamination significantly affects LLM evaluation by incorporating test data into training sets, leading to inflated performance metrics. Existing methods attempt to mitigate this by updating benchmarks with new data, but they often lack a guarantee of true contamination-free evaluation as the new data may contain pre-existing knowledge or require substantial manual effort to curate and verify. Furthermore, the rapid emergence of new LLMs makes frequent benchmark updates essential but challenging. A robust approach must prioritize strictly contamination-free samples by verifying the novelty of the added data. Additionally, automating the benchmark update process is vital to reducing human labor and ensuring that evaluations remain current and reliable with LLM advancements. This involves automatically identifying, acquiring, and validating new knowledge, constructing corresponding test samples, and integrating them into the benchmark.
Multi-Lingual Benchmarks#
The AntiLeak-Bench framework supports multi-lingual evaluation, leveraging the diverse language capabilities of Wikidata and Wikipedia. This allows for the creation of benchmark datasets in various languages, expanding the scope of LLM assessment beyond English. This multi-lingual capacity is crucial for evaluating the cross-lingual generalization abilities of LLMs and for identifying language-specific biases that may arise from training data predominantly in English. By incorporating diverse languages, AntiLeak-Bench facilitates a more comprehensive and inclusive evaluation of LLM performance, contributing to a broader understanding of their strengths and weaknesses across different linguistic contexts.
More visual insights#
More on figures

🔼 The figure illustrates the automated process of building the AntiLeak-Bench. It starts with preparing data from Wikidata. The workflow then identifies knowledge updated after an LLM’s knowledge cutoff time by comparing claim histories. Next, supporting documents are retrieved from Wikipedia based on the updated knowledge. Finally, contamination-free question-answering samples are generated using the updated knowledge and supporting documents.
read the caption
Figure 2: Illustration of the automated benchmark building workflow without human labor. After data preparation, it includes three main steps: (1) Identify updated knowledge after the cutoff time; (2) Build supporting documents; (3) Construct contamination-free samples (Figure 3 exemplifies how to construct multi-hop samples).

🔼 The figure illustrates the process of constructing multi-hop question-answering samples. It starts with an initial fact, such as Lionel Messi being a member of Inter Miami. Subsequent ‘hops’ are made by connecting the object of the previous fact to the subject of a new fact, forming a chain. For example, the second hop connects Inter Miami to its location (or head coach), and a third hop might link the head coach to their country of citizenship. This chain of relations forms the basis of a multi-hop question, where the answer requires traversing multiple linked facts. The supporting context for the question would include text related to each entity involved in these ‘hops’.
read the caption
Figure 3: Illustration of constructing multi-hop samples. Find the consequent relation of previous objects.

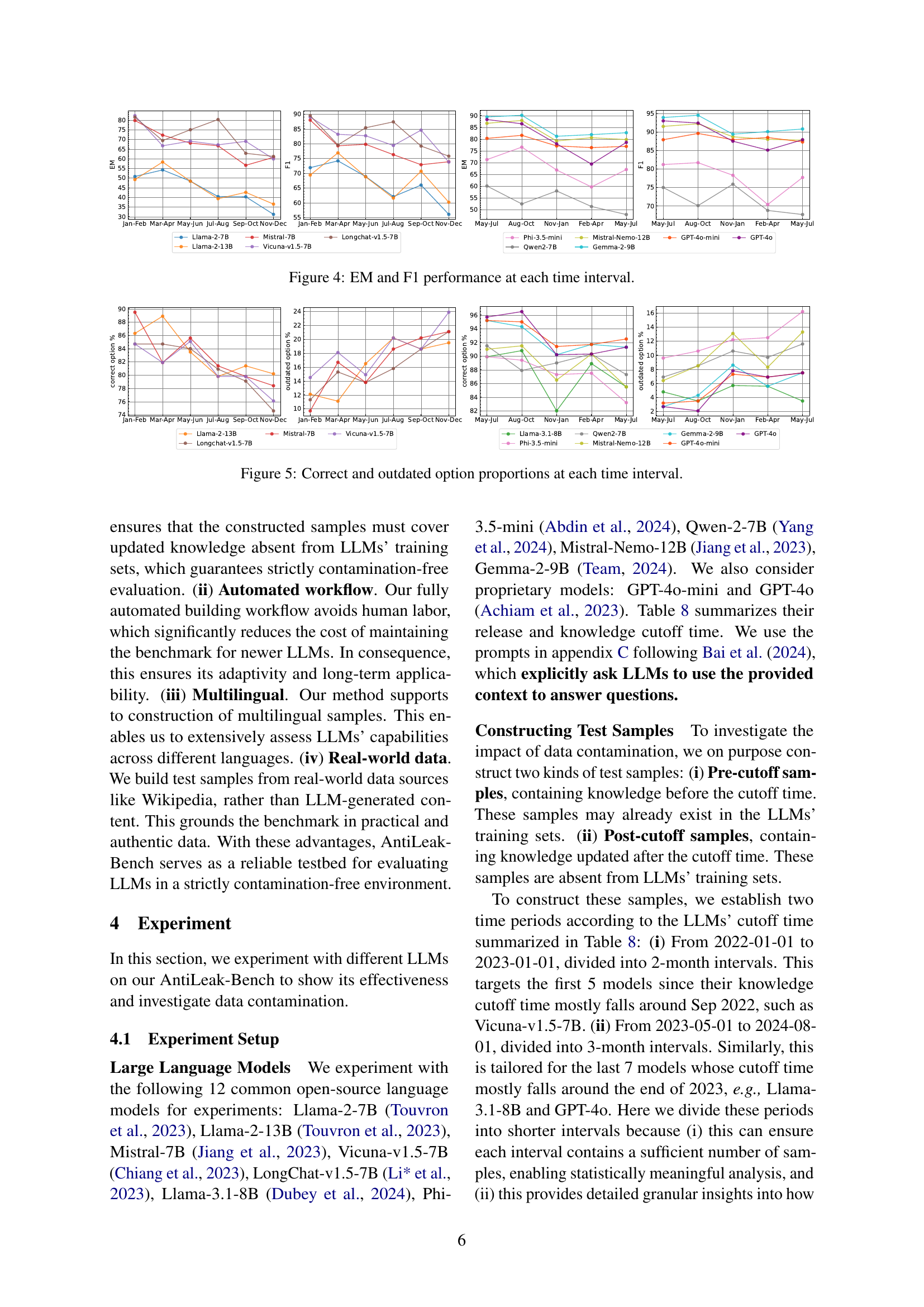
🔼 This figure presents the Exact Match (EM) and F1 scores of different large language models (LLMs) over multiple 2-month or 3-month intervals between 2022 and 2024. The models evaluated include Llama-2-7B, Llama-2-13B, Mistral-7B, Vicuna-v1.5-7B, LongChat-v1.5-7B, Phi-3.5-mini, Qwen-2-7B, Mistral-Nemo-12B, and Gemma-2-9B. The x-axis represents the time intervals, while the y-axis represents the EM and F1 scores. Different colors and line styles distinguish the performance of each model. The vertical dotted lines likely represent the knowledge cut-off times of the LLMs, indicating the point in time after which information used in evaluating the models was not included in their training data. The figure demonstrates the performance trends of different LLMs over time, highlighting potential data contamination issues and illustrating the effectiveness of the AntiLeak-Bench in evaluating LLMs in a contamination-free environment. This figure is important for understanding the reliability and validity of using benchmarks to assess LLMs’ capabilities.
read the caption
Figure 4: EM and F1 performance at each time interval.

🔼 This figure showcases the proportion of times Large Language Models (LLMs) select correct and outdated options in multi-choice question answering tasks related to data contamination in evaluations. The figure is separated into two parts based on different models and time intervals reflecting knowledge cut-off dates and updates. The analysis reveals that outdated options were selected more frequently by LLMs over time, and LLMs struggled to answer the questions correctly, with some LLMs performing poorly even before their knowledge cut-off date. The x-axis represents different time intervals, while the y-axis shows the percentage. Each line in the chart represents the selection frequency of an option over each time interval.
read the caption
Figure 5: Correct and outdated option proportions at each time interval.
More on tables
| Attributes | Examples |
|---|---|
| question (generation) | What sports team is Lionel Andrés Messi a member of? |
| answer (generation) | Inter Miami CF |
| Inter Miami | |
| Club Internacional de Fútbol Miami | |
| question (multi-choice) | What sports team is Lionel Andrés Messi a member of? |
| A. Inter Miami CF | |
| B. Paris Saint-Germain F.C. | |
| C. Prime Minister of Romania | |
| D. Unknown. | |
| answer (multi-choice) | A |
| subject | Lionel Messi |
| Lionel Andres Messi | |
| Lionel Andrés Messi | |
| pid | P54 (member of sports team) |
| object | Inter Miami CF |
| Inter Miami | |
| Club Internacional de Fútbol Miami | |
| object_old | Paris Saint-Germain F.C. |
| Paris Saint-Germain Football Club | |
| Paris Saint-Germain FC | |
| context | Lionel Andrés Messi (; born 24 June 1987), also known as Leo Messi, is an Argentine professional footballer who plays as a forward for Major League Soccer club Inter Miami… |
🔼 This table presents an example from the AntiLeak-Bench, demonstrating how questions, answers, and contexts are structured within the benchmark. It includes examples for both Generation and Multi-Choice question formats. The attributes provided are ‘question’ (in both formats), ‘answer’ (in both formats), ‘subject’, ‘pid’ (property ID), ‘object’, ‘object_old’, and ‘context’. The table showcases the different components used to create a contamination-free example.
read the caption
Table 2: An example from AntiLeak-Bench.
| Quality Metrics | Single-Hop Gold | Multi-Hop Gold |
|---|---|---|
| Context Accuracy | 97.3 | 98.7 |
| Answer Accuracy | 96.7 | 97.3 |
🔼 This table presents the human evaluation results of the generated samples’ context and answer accuracy for single-hop and multi-hop question answering. The results demonstrate high accuracy for both contexts and answers in the generated samples, indicating that the samples are of good quality.
read the caption
Table 3: Data quality by human verification.
| Language Models | Single-Hop | Single-Hop | Single-Hop | Single-Hop | Multi-Hop | Multi-Hop | Multi-Hop | Multi-Hop | Avg | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Gold | F1 | $N_d$=3 | F1 | $N_d$=5 | F1 | $N_d$=7 | Gold | F1 | $N_d$=3 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Llama-2-7B | 40.6 | 63.5 | 16.8 | 41.2 | 11.6 | 30.9 | 9.4 | 24.5 | 33.6 | 50.2 |
| Llama-2-13B | 42.7 | 65.3 | 14.0 | 40.6 | 9.4 | 30.6 | 7.0 | 24.0 | 13.3 | 34.6 |
| Mistral-7B | 65.4 | 77.2 | 27.8 | 41.3 | 16.7 | 27.3 | 7.3 | 15.3 | 21.4 | 27.9 |
| Vicuna-v1.5-7B | 66.8 | 79.9 | 39.1 | 60.4 | 25.8 | 48.3 | 15.3 | 39.1 | 26.0 | 43.5 |
| Longchat-v1.5-7B | 75.5 | 84.5 | 58.2 | 72.8 | 47.6 | 65.5 | 37.0 | 56.3 | 38.8 | 51.4 |
| Llama-3.1-8B | 19.2 | 66.2 | 21.4 | 59.4 | 18.1 | 53.5 | 14.2 | 45.7 | 24.4 | 50.2 |
| Phi-3.5-mini | 69.0 | 78.7 | 34.0 | 40.5 | 26.5 | 33.7 | 15.2 | 22.2 | 45.4 | 59.7 |
| Qwen-2-7B | 54.8 | 72.4 | 15.5 | 38.5 | 9.8 | 26.6 | 7.2 | 21.2 | 35.9 | 48.3 |
| Mistral-Nemo-12B | 82.7 | 89.7 | 75.6 | 83.8 | 66.3 | 75.1 | 51.8 | 62.2 | 57.7 | 67.3 |
| Gemma-2-9B | 85.0 | 91.6 | 80.2 | 86.2 | 68.8 | 75.2 | 55.4 | 61.2 | 82.7 | 86.4 |
| GPT-4o-mini | 78.5 | 88.1 | 80.3 | 89.2 | 79.1 | 88.1 | 79.2 | 88.5 | 68.8 | 83.1 |
| GPT-4o | 81.2 | 89.5 | 84.1 | 90.8 | 83.5 | 90.3 | 84.8 | 91.4 | 71.5 | 85.9 |
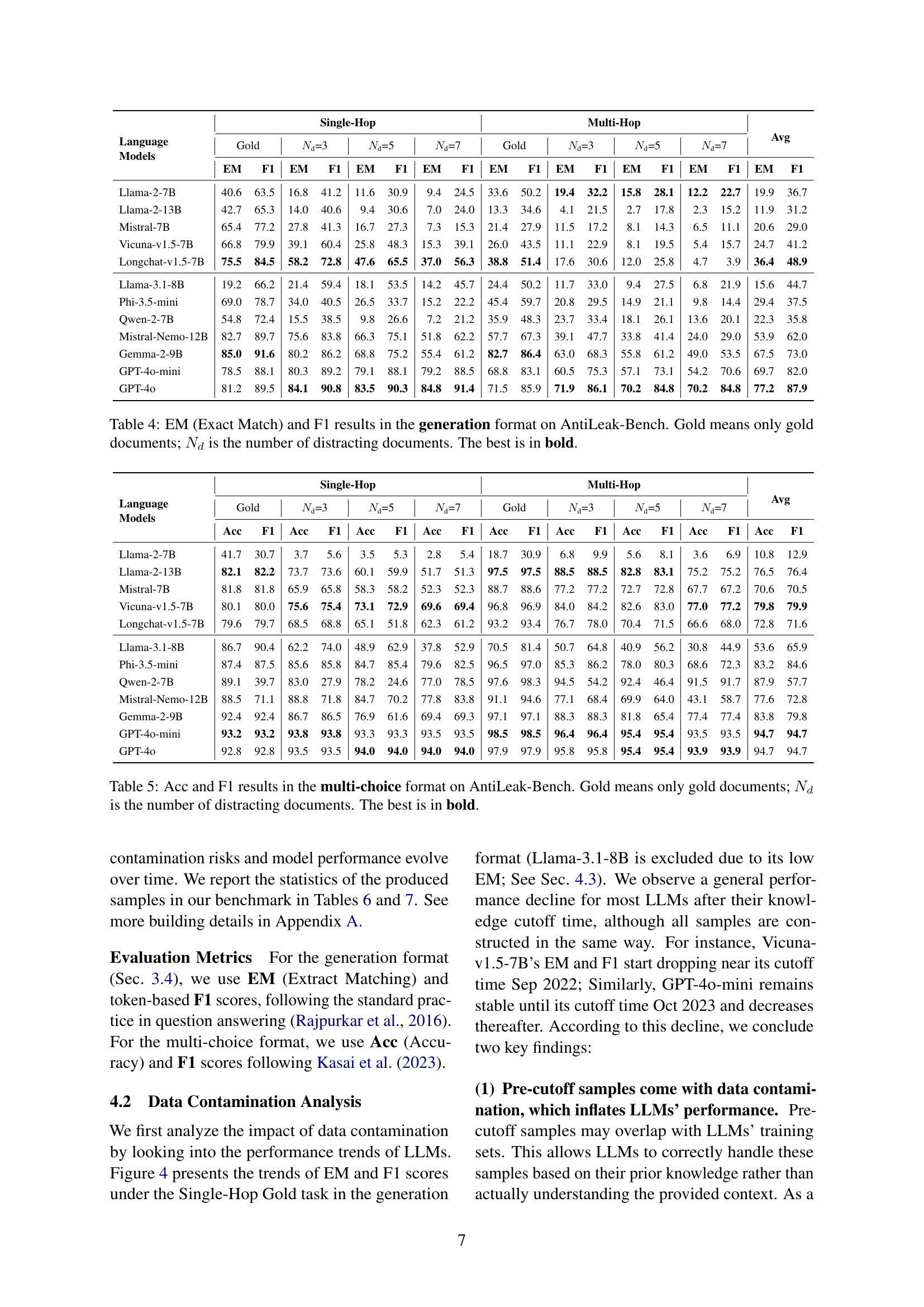
🔼 This table presents the Exact Match (EM) and F1 scores for several Large Language Models (LLMs) evaluated on the AntiLeak-Bench using the generation format. The benchmark evaluates LLMs’ ability to answer questions about updated real-world knowledge, while mitigating data contamination. Results are reported for different conditions: ‘Gold’ signifies evaluations with only relevant supporting documents provided, while ‘Ndsubscript𝑁𝑑N_{d}italic_N start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT’ denotes evaluations with an increasing number (3, 5, or 7) of distracting documents included in the context. Higher EM and F1 scores signify better performance and the highest scores are highlighted in bold. This allows for an analysis of LLM performance under varying difficulty levels within the AntiLeak-Bench.
read the caption
Table 4: EM (Exact Match) and F1 results in the generation format on AntiLeak-Bench. Gold means only gold documents; Ndsubscript𝑁𝑑N_{d}italic_N start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT is the number of distracting documents. The best is in bold.
| Language Models | Single-Hop | Single-Hop | Single-Hop | Single-Hop | Multi-Hop | Multi-Hop | Multi-Hop | Multi-Hop | Avg | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Gold | F1 | $N_d$=3 | F1 | $N_d$=5 | F1 | $N_d$=7 | F1 | Gold | F1 | |
| — | — | — | — | — | — | — | — | — | — | — |
| Llama-2-7B | 41.7 | 30.7 | 3.7 | 5.6 | 3.5 | 5.3 | 2.8 | 5.4 | 18.7 | 30.9 |
| Llama-2-13B | 82.1 | 82.2 | 73.7 | 73.6 | 60.1 | 59.9 | 51.7 | 51.3 | 97.5 | 97.5 |
| Mistral-7B | 81.8 | 81.8 | 65.9 | 65.8 | 58.3 | 58.2 | 52.3 | 52.3 | 88.7 | 88.6 |
| Vicuna-v1.5-7B | 80.1 | 80.0 | 75.6 | 75.4 | 73.1 | 72.9 | 69.6 | 69.4 | 96.8 | 96.9 |
| Longchat-v1.5-7B | 79.6 | 79.7 | 68.5 | 68.8 | 65.1 | 51.8 | 62.3 | 61.2 | 93.2 | 93.4 |
| Llama-3.1-8B | 86.7 | 90.4 | 62.2 | 74.0 | 48.9 | 62.9 | 37.8 | 52.9 | 70.5 | 81.4 |
| Phi-3.5-mini | 87.4 | 87.5 | 85.6 | 85.8 | 84.7 | 85.4 | 79.6 | 82.5 | 96.5 | 97.0 |
| Qwen-2-7B | 89.1 | 39.7 | 83.0 | 27.9 | 78.2 | 24.6 | 77.0 | 78.5 | 97.6 | 98.3 |
| Mistral-Nemo-12B | 88.5 | 71.1 | 88.8 | 71.8 | 84.7 | 70.2 | 77.8 | 83.8 | 91.1 | 94.6 |
| Gemma-2-9B | 92.4 | 92.4 | 86.7 | 86.5 | 76.9 | 61.6 | 69.4 | 69.3 | 97.1 | 97.1 |
| GPT-4o-mini | 93.2 | 93.2 | 93.8 | 93.8 | 93.3 | 93.3 | 93.5 | 93.5 | 98.5 | 98.5 |
| GPT-4o | 92.8 | 92.8 | 93.5 | 93.5 | 94.0 | 94.0 | 94.0 | 94.0 | 97.9 | 97.9 |
🔼 This table presents the accuracy (Acc) and F1 scores of several large language models (LLMs) on the AntiLeak-Bench using the multi-choice question format. The benchmark evaluates LLMs’ ability to answer questions correctly given a context, where ‘Gold’ refers to providing only the gold standard supporting document as context. ‘N_d’ represents the number of additional distracting documents added to the context, increasing the task’s difficulty by requiring the models to filter out irrelevant information. The table compares LLM performance across different levels of distraction (N_d = 3, 5, 7) and identifies the best-performing model for each setting with bold formatting.
read the caption
Table 5: Acc and F1 results in the multi-choice format on AntiLeak-Bench. Gold means only gold documents; Ndsubscript𝑁𝑑N_{d}italic_N start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT is the number of distracting documents. The best is in bold.
| Time period | Single-Hop | Multi-Hop | ||||||
|---|---|---|---|---|---|---|---|---|
| Gold | Nd=3 | Nd=5 | Nd=7 | Gold | Nd=3 | Nd=5 | Nd=7 | |
| 2022-01-01 to 2023-01-01 | 1090 | 1089 | 1088 | 1088 | 443 | 443 | 443 | 443 |
| 2023-05-01 to 2024-08-01 | 819 | 818 | 818 | 818 | 941 | 939 | 939 | 939 |
🔼 This table presents the number of samples within each time period, task, and number of distracting documents in AntiLeak-Bench. The table is split into two rows based on time period (2022-01-01 to 2023-01-01 and 2023-05-01 to 2024-08-01). The columns represent different tasks: single-hop and multi-hop question answering, with varying numbers of distracting documents (0, 3, 5, and 7).
read the caption
Table 6: Sample sizes in the constructed AntiLeak-Bench in the experiments.
| Time period | Single-Hop | Multi-Hop | ||||
|---|---|---|---|---|---|---|
| Gold | $N_d$=3 | $N_d$=5 | $N_d$=7 | Gold | $N_d$=3 | |
| 2022-01-01 to 2023-01-01 | 5998 | 23163 | 33867 | 46033 | 24646 | 40611 |
| 2023-05-01 to 2024-08-01 | 7210 | 27501 | 40800 | 54451 | 25505 | 43926 |
🔼 This table presents the average word counts of samples in the constructed AntiLeak-Bench across different time periods (2022-01-01 to 2023-01-01 and 2023-05-01 to 2024-08-01), tasks (single-hop and multi-hop), and the number of distracting documents (0, 3, 5, and 7). The data is organized by time period, task type, and the number of distracting documents, allowing for an analysis of question complexity and context length across various experimental settings.
read the caption
Table 7: Average word counts of samples in the constructed AntiLeak-Bench in the experiments.
| Model | Release time | Knowledge cutoff time |
|---|---|---|
| Llama-2-7B | 2023-07 | 2022-09 |
| Llama-2-13B | 2023-07 | 2022-09 |
| Mistral-7B | 2023-09 | 2022* |
| Vicuna-v1.5-7B | 2023-07 | 2022-09 |
| Longchat-v1.5-7B | 2023-07 | 2022-09 |
| Llama-3.1-8B | 2024-07 | 2023-12 |
| Phi-3.5-mini | 2024-08 | 2023-10 |
| Qwen-2-7B | 2024-06 | 2023* |
| Mistral-Nemo-12B | 2024-07 | 2024-04 |
| Gemma-2-9B | 2024-08 | 2024-06* |
| GPT-4o-mini | 2024-07 | 2023-10 |
| GPT-4o | 2024-07 | 2023-12 |
🔼 This table lists the release date and knowledge cutoff date for each of the large language models (LLMs) used in the study. The knowledge cutoff date refers to the point in time after which any newly generated knowledge is not included in the training dataset. An estimated cutoff date is marked with an asterisk.
read the caption
Table 8: Release dates and knowledge cutoff dates of LLMs. * means estimated time.
Full paper#