↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) struggle with visual tasks because they lack information from different visual levels. This makes it hard to align the visual information with the various levels of meaning needed to generate text. Standard visual transformers (ViTs) in MLLMs capture features at a single scale, inadequate for tasks requiring both fine-grained details and high-level semantics. Existing approaches to integrate multi-scale visual features, like feature pyramids, face challenges such as representation inheritance and compression effectiveness.
This paper introduces LLaVA-UHD v2, an improved MLLM that integrates a high-resolution feature pyramid using a hierarchical window transformer (Hiwin). The Hiwin transformer uses two key modules: an inverse feature pyramid constructed by a ViT-derived feature up-sampling process, and hierarchical window attention, which compresses multi-level feature maps using a set of learnable queries attending to key features within hierarchical windows. This architecture allows the model to capture both fine-grained details and high-level semantics, leading to better visual encoding for language generation.
Key Takeaways#
Why does it matter?#
Improving multimodal large language models (MLLMs) is crucial for advanced AI applications. This paper introduces an innovative approach to enhance the visual processing capabilities of MLLMs. The proposed hierarchical window transformer and inverse feature pyramid offer a novel way to integrate high-resolution visual information, which opens up new possibilities for future research in MLLM architectures and applications. The improved performance on various benchmarks demonstrates its potential impact on document analysis, visual grounding, and high-resolution image perception.
Visual Insights#

🔼 This figure compares three different architectures for multimodal large language models (MLLMs): (a) illustrates recent MLLMs that align vision transformer (ViT) features to language space using multilayer perceptrons (MLPs) or perceiver re-samplers, often lacking visual granularity. (b) shows a method combining multiple visual encoders which is non-universal and computationally intensive. (c) presents the proposed LLaVA-UHD v2, which employs a Hiwin transformer to construct an inverse feature pyramid, subsequently compressing it into visual tokens to provide various levels of semantic granularity for enhanced language generation.
read the caption
Figure 1: Comparison of LLaVA-UHD v2 with other MLLMs. (a) MLLMs typically align ViT features to language space using MLPs [63] or perceiver re-samplers [6, 52], lacking visual granularity. (b) Combining multiple visual encoders is non-universal and computationally intensive. (c) LLaVA-UHD v2 employs the Hiwin transformer to build an inverse feature pyramid and compress it into visual tokens, providing various semantic granularity for language generation.
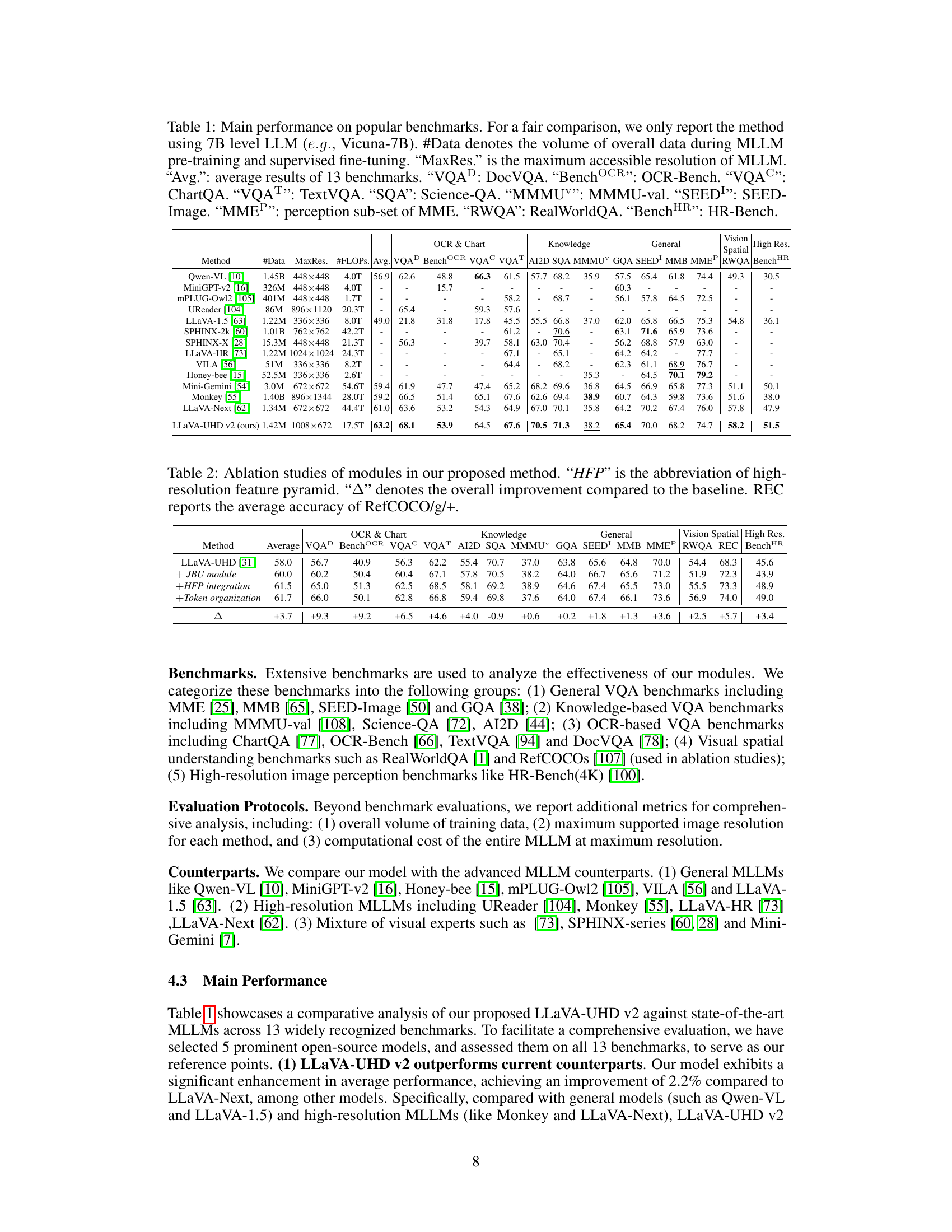
| Method | #Data | MaxRes. | #FLOPs. | Avg. | OCR & Chart | Knowledge | General | Vision Spatial | High Res | |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-VL [10] | 1.45B | 448×448 | 4.0T | 56.9 | 62.6 | 48.8 | 66.3 | 61.5 | 57.7 | 68.2 |
| MiniGPT-v2 [16] | 326M | 448×448 | 4.0T | - | - | 15.7 | - | - | - | - |
| mPLUG-Owl2 [105] | 401M | 448×448 | 1.7T | - | - | - | - | 58.2 | - | 68.7 |
| UReader [104] | 86M | 896×1120 | 20.3T | - | 65.4 | - | 59.3 | 57.6 | - | - |
| LLaVA-1.5 [63] | 1.22M | 336×336 | 8.0T | 49.0 | 21.8 | 31.8 | 17.8 | 45.5 | 55.5 | 66.8 |
| SPHINX-2k [60] | 1.01B | 762×762 | 42.2T | - | - | - | - | 61.2 | - | 70.6 |
| SPHINX-X [28] | 15.3M | 448×448 | 21.3T | - | 56.3 | - | 39.7 | 58.1 | 63.0 | 70.4 |
| LLaVA-HR [73] | 1.22M | 1024×1024 | 24.3T | - | - | - | - | 67.1 | - | 65.1 |
| VILA [56] | 51M | 336×336 | 8.2T | - | - | - | - | 64.4 | - | 68.2 |
| Honey-bee [15] | 52.5M | 336×336 | 2.6T | - | - | - | - | - | - | - |
| Mini-Gemini [54] | 3.0M | 672×672 | 54.6T | 59.4 | 61.9 | 47.7 | 47.4 | 65.2 | 68.2 | 69.6 |
| Monkey [55] | 1.40B | 896×1344 | 28.0T | 59.2 | 66.5 | 51.4 | 65.1 | 67.6 | 62.6 | 69.4 |
| LLaVA-Next [62] | 1.34M | 672×672 | 44.4T | 61.0 | 63.6 | 53.2 | 54.3 | 64.9 | 67.0 | 70.1 |
| LLaVA-UHD v2 (ours) | 1.42M | 1008×672 | 17.5T | 63.2 | 68.1 | 53.9 | 64.5 | 67.6 | 70.5 | 71.3 |
🔼 This table presents a performance comparison of various Multimodal Large Language Models (MLLMs) on a set of 14 benchmark datasets, encompassing tasks like Visual Question Answering (VQA), Optical Character Recognition (OCR), and high-resolution image understanding. The comparison focuses on models using a 7B parameter Large Language Model (LLM), such as Vicuna-7B. The table includes metrics like the total training data size, maximum supported image resolution, computational cost (#FLOPs), and average performance across 13 benchmarks, along with individual scores on datasets like DocVQA, OCR-Bench, ChartQA, TextVQA, ScienceQA, MMMU, SEED-Image, a subset of MME focused on perception, RealWorldQA, and HR-Bench.
read the caption
Table 1: Main performance on popular benchmarks. For a fair comparison, we only report the method using 7B level LLM (e.g.formulae-sequence𝑒𝑔e.g.italic_e . italic_g ., Vicuna-7B). #Data denotes the volume of overall data during MLLM pre-training and supervised fine-tuning. “MaxRes.” is the maximum accessible resolution of MLLM. “Avg.”: average results of 13 benchmarks. “VQAD: DocVQA. “BenchOCR”: OCR-Bench. “VQAC”: ChartQA. “VQAT”: TextVQA. “SQA”: Science-QA. “MMMUv”: MMMU-val. “SEEDI”: SEED-Image. “MMEP”: perception sub-set of MME. “RWQA”: RealWorldQA. “BenchHR”: HR-Bench.
In-depth insights#
HiWin Transformer#
The HiWin Transformer proposed in LLaVA-UHD v2 introduces a novel approach to visual encoding for Multimodal Large Language Models (MLLMs). It addresses the limitations of standard Vision Transformers (ViTs) by capturing diverse visual granularities. The HiWin Transformer achieves this through two key mechanisms: an inverse feature pyramid and hierarchical window attention. The inverse feature pyramid, constructed using a learned upsampling process, integrates high-frequency details, enriching the feature representation. Hierarchical window attention then compresses these multi-level feature maps into a condensed set of tokens. This approach preserves both fine-grained details and high-level semantics, leading to improved performance on various visual tasks. Notably, it maintains spatial consistency, facilitating a better understanding of image content.
Visual Granularity#
Visual granularity, or the level of detail captured, is crucial for MLLMs handling complex visual tasks. Single-scale features from standard ViTs often lack the diverse information needed for tasks demanding different levels of detail. A high-resolution feature pyramid offers a solution by integrating both fine-grained details and high-level semantics. This approach allows MLLMs to effectively handle tasks such as visual grounding, OCR, and image captioning, which require different levels of visual granularity. However, integrating these pyramids into MLLMs presents challenges such as preserving the benefits of pre-trained models and effective feature compression.
Feature Pyramid#
Feature pyramids are crucial for multi-scale visual analysis. They allow networks to integrate fine-grained details from high-resolution features with high-level semantic information captured in low-resolution features. Traditionally, CNN architectures naturally create feature pyramids, with earlier layers capturing fine details and deeper layers learning abstract semantics. However, incorporating feature pyramids into ViT architectures for MLLMs is challenging due to two key issues: representation inheritance from pre-trained ViTs like CLIP, and the need for effective compression of the pyramid to manage computational costs in LLMs. Existing methods, like using multiple visual experts, can be computationally intensive. Effective integration of feature pyramids in ViTs remains an important area of research for enhancing MLLM performance.
MLLM Enhancement#
Enhancing Multimodal Large Language Models (MLLMs) involves crucial improvements to their visual understanding capabilities. A core challenge lies in bridging the gap between the visual and linguistic modalities. This can be addressed by incorporating mechanisms that capture fine-grained visual details alongside high-level semantic understanding. By effectively integrating high-resolution visual features and efficient cross-modal attention, MLLMs can achieve significant performance gains in complex visual tasks like visual question answering, document analysis, and visual grounding. Hierarchical feature processing plays a key role in capturing diverse levels of visual information, facilitating more nuanced interactions between vision and language. The development of robust, efficient, and generalizable MLLM architectures remains a crucial area of focus.
JBU Module#
The JBU module, or Joint Bilateral Upsampling, functions as a guided upsampling technique, designed to enhance visual fidelity within multi-modal large language models (MLLMs). By leveraging image priors, the JBU module refines the upsampling process, introducing high-frequency details often lost during conventional upsampling methods like bilinear interpolation. This addresses the crucial need for fine-grained visual information in tasks such as visual grounding and optical character recognition, where precise details significantly influence accuracy. The JBU module’s effectiveness stems from its ability to capture local texture patterns from corresponding images in the pyramid, enabling the model to discern intricate visual cues. This process involves training convolutional layers within the module to learn high-frequency patterns, guiding the feature upsampling process and ensuring the integration of rich visual details. The overall objective is to reconstruct high-resolution features with enhanced visual fidelity, essential for complex visual understanding tasks in MLLMs.
More visual insights#
More on figures

🔼 LLaVA-UHD v2 processes image slices and an overview image with a CLIP-ViT. The resulting visual features are passed to a hierarchical window transformer (Hiwin Transformer) that builds an inverse feature pyramid and compresses it into visual tokens. These tokens are then fed to an LLM, facilitating vision-language alignment.
read the caption
Figure 2: The overall architecture of proposed LLaVA-UHD v2, consisting of a ViT, our hierarchical window transformer (Hiwin transformer), and an LLM. Hiwin transformers process sliced patches and the overview image by capturing inner multi-level representations and compressing them into spatially consistent tokens for a better vision-language alignment.

🔼 The Joint Bilateral Upsampling (JBU) module guides feature upsampling by leveraging the image pyramid, effectively integrating high-frequency details into upsampled feature maps. This addresses the issue of standard upsampling methods failing to introduce fine-grained details, which are crucial for tasks demanding high-resolution visual information. The JBU module learns convolutional layers on progressively downsampled image versions. These learned kernels capture local high-frequency textures that guide the upsampling of the initial feature map. Each pixel’s value in the upsampled map is a weighted average of values from the original feature map. These weights are determined by both the spatial distance between pixels and their similarity in terms of local textural patterns captured by the image pyramid. This process results in upsampled feature maps enriched with detailed texture information, making them more suitable for high-resolution tasks.
read the caption
Figure 3: Flowchart of the Joint Bilateral Upsampling (JBU) module, which leverages the image pyramid to guide feature up-sampling, integrating high-frequency information into the up-sampled feature maps.

🔼 The figure illustrates the hierarchical window attention mechanism. It begins by constructing an inverse feature pyramid from the input image using a vision transformer (ViT) and a learned upsampling module. The feature maps from different levels of this pyramid are then divided into a uniform grid of windows. These windows, which align across different pyramid levels and serve as regions of interest, undergo RoI alignment to generate spatially consistent sampling features. These sampling features from each level are concatenated together lengthwise and used as the key in the cross-attention block. For each grid location, there is a corresponding learnable query vector. Finally, the output of this cross-attention operation is aggregated and projected into a feature map, which serves as the visual representation for the input image.
read the caption
Figure 4: The flowchart of hierarchical window attention. Feature maps from different levels of the feature pyramid are adaptively RoI-aligned into sampling features and then concatenated along the length axis to serve as the key for the learnable queries.

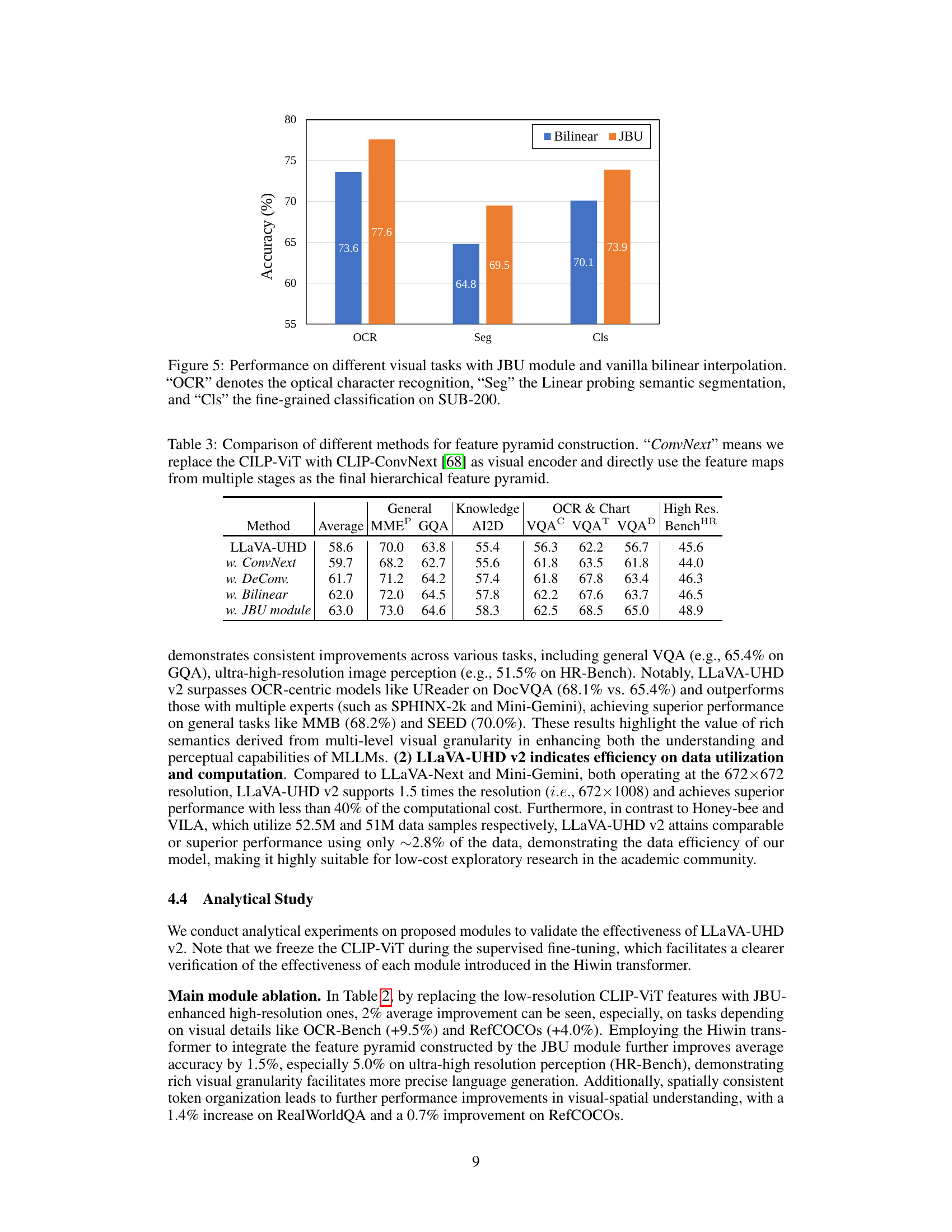
🔼 This figure compares the performance of a vision-language model on three visual tasks – optical character recognition (OCR), linear probing semantic segmentation (Seg), and fine-grained image classification (Cls) – when using two different up-sampling methods: bilinear interpolation and the proposed Joint Bilateral Upsampling (JBU) module. The JBU module consistently outperforms bilinear interpolation across all tasks, suggesting its ability to preserve more detailed visual information during upsampling. Specifically, JBU leads to a 4% improvement in OCR, 4.7% in segmentation, and 3.8% in classification over bilinear interpolation.
read the caption
Figure 5: Performance on different visual tasks with JBU module and vanilla bilinear interpolation. “OCR” denotes the optical character recognition, “Seg” the Linear probing semantic segmentation, and “Cls” the fine-grained classification on SUB-200.

🔼 This figure presents a qualitative comparison showcasing the enhanced capabilities of LLaVA-UHD v2 in handling high-resolution images involving complex perceptual tasks. It highlights two specific examples (A and B) where LLaVA-UHD v2 demonstrates accurate understanding of image content and question answering compared to other MLLMs like LLaVA-Next, Mini-Gemini, and GPT-4V. These tasks necessitate the model to effectively integrate both fine-grained details (e.g., text in images, small objects) with high-level semantic context.
read the caption
Figure 6: Qualitative comparison of proposed LLaVA-UHD v2 and advanced MLLMs, including LLaVA-Next, Mini-Gemini, and GPT-4V on high-resolution complex perception tasks, which require the integration of both fine-grained visual information and high-level semantic contexts.

🔼 This figure visualizes how different textual tokens activate differently across various levels of the visual feature pyramid. Red circles emphasize noticeable differences in activation patterns between these levels. Essentially, it demonstrates how certain visual features are captured more strongly at different scales (levels of the pyramid). For instance, finer details, such as text, might activate more strongly at higher resolution levels, while broader semantic concepts may have stronger activations at lower resolution levels. This multi-level analysis helps in understanding how the model connects language to visual information at varying granularities.
read the caption
Figure 7: Activation response of specific textual tokens to different visual feature levels. Red circles highlight the obvious difference between levels. (Best viewed in color and zoomed-in)

🔼 Qualitative comparison of LLaVA-UHD v2 with LLaVA-Next, Mini-Gemini, and GPT-4V on high-resolution, complex perceptual tasks requiring both fine-grained visual detail and higher-level semantic understanding, demonstrating superior performance in accurately extracting information from dense text and differentiating targets from similar objects (e.g., identifying the TV program start time, the show date, workout duration, and sale price).
read the caption
Figure 8: Qualitative comparison on high-resolution dense perception task which requires the capabilities of fine-grained details perception.

🔼 LLaVA-UHD v2 and GPT-4V are able to accurately perceive fine-grained details like the beginning time of the television program or small numbers on jerseys and buses, outperforming other models which fail to locate targets or discern them from similar objects.
read the caption
Figure 9: Qualitative comparison on high-resolution fine-grained perception task which requires robust fine-grained visual texture perception capabilities.

🔼 LLaVA-UHD v2 and GPT4V are compared with LLaVA-Next and Mini-Gemini on their spatial perception abilities. The figure presents four examples where models need to extract objects and their spatial relationship in high-resolution images. LLaVA-UHD v2 and GPT4V demonstrate better spatial understanding compared to the other two models.
read the caption
Figure 10: Qualitative comparison on high-resolution spatial perception which necessitates the capabilities of high-level spatial contexts.

🔼 This figure shows a PCA visualization of upsampled features produced by the Joint Bilateral Upsampling (JBU) module applied to a natural scene. Three different upsampling methods are compared: bilinear interpolation, JBU without hierarchical supervision, and JBU with hierarchical supervision. The goal is to demonstrate the effect of these methods on high-resolution (8x the original resolution) feature representation. The figure visually illustrates how hierarchical supervision, when used with the JBU module, helps maintain clearer object boundaries and sharper text details compared to the other two methods. Without hierarchical supervision, the JBU-upsampled features appear somewhat blurry. Bilinear interpolation results in the least clear output.
read the caption
Figure 11: PCA visualization of the up-sampled features by JBU module on nature scene. With hierarchical supervision, the high-resolution features (8×8\times8 ×) could clearly depict object boundary and text appearance. (Best viewed in color and zoomed in)
More on tables
| Method | Average | OCR & Chart | Knowledge | General | Vision Spatial | High Res. |
|---|---|---|---|---|---|---|
| LLaVA-UHD [31] | 58.0 | 56.7 | 55.4 | 63.8 | 54.4 | 45.6 |
| 40.9 | 70.7 | 65.6 | 68.3 | |||
| 56.3 | 37.0 | 64.8 | ||||
| 62.2 | 70.0 | |||||
| + JBU module | 60.0 | 60.2 | 57.8 | 64.0 | 51.9 | 43.9 |
| 50.4 | 70.5 | 66.7 | 72.3 | |||
| 60.4 | 38.2 | 65.6 | ||||
| 67.1 | 71.2 | |||||
| + HFP integration | 61.5 | 65.0 | 58.1 | 64.6 | 55.5 | 48.9 |
| 51.3 | 69.2 | 67.4 | 73.3 | |||
| 62.5 | 38.9 | 65.5 | ||||
| 68.5 | 73.0 | |||||
| + Token organization | 61.7 | 66.0 | 59.4 | 64.0 | 56.9 | 49.0 |
| 50.1 | 69.8 | 67.4 | 74.0 | |||
| 62.8 | 37.6 | 66.1 | ||||
| 66.8 | 73.6 | |||||
| Δ | +3.7 | +9.3 | +4.0 | +0.2 | +2.5 | +3.4 |
| +9.2 | -0.9 | +1.8 | +5.7 | |||
| +6.5 | +0.6 | +1.3 | ||||
| +4.6 | +3.6 |
🔼 This table presents the ablation study results for evaluating the effectiveness of different modules within the LLaVA-UHD v2 model, in particular, the JBU module, High-Resolution Feature Pyramid (HFP) integration, and spatially-consistent token organization. It compares their performance against the baseline LLaVA-UHD model on a variety of visual tasks, including OCR-related tasks, knowledge-based VQA, general vision benchmarks, spatial understanding and high-resolution image perception. The metrics include average accuracy, scores on specific datasets like DocVQA, BenchOCR, and average accuracy on RefCOCO benchmarks. “Δ” represents the overall performance improvement relative to the LLaVA-UHD baseline.
read the caption
Table 2: Ablation studies of modules in our proposed method. “HFP” is the abbreviation of high-resolution feature pyramid. “ΔΔ\Deltaroman_Δ” denotes the overall improvement compared to the baseline. REC reports the average accuracy of RefCOCO/g/+.
| Method | Average | MMEP | GQA | AI2D | VQAC | VQAT | VQAD | BenchHR |
|---|---|---|---|---|---|---|---|---|
| LLaVA-UHD | 58.6 | 70.0 | 63.8 | 55.4 | 56.3 | 62.2 | 56.7 | 45.6 |
| w. ConvNext | 59.7 | 68.2 | 62.7 | 55.6 | 61.8 | 63.5 | 61.8 | 44.0 |
| w. DeConv. | 61.7 | 71.2 | 64.2 | 57.4 | 61.8 | 67.8 | 63.4 | 46.3 |
| w. Bilinear | 62.0 | 72.0 | 64.5 | 57.8 | 62.2 | 67.6 | 63.7 | 46.5 |
| w. JBU module | 63.0 | 73.0 | 64.6 | 58.3 | 62.5 | 68.5 | 65.0 | 48.9 |
🔼 This table compares different methods for constructing a feature pyramid for visual encoding in multimodal large language models (MLLMs). It explores replacing the standard CLIP-ViT with CLIP-ConvNext and directly using its multi-stage feature maps as the hierarchical feature pyramid. It also investigates using deconvolution and bilinear interpolation for feature upsampling, alongside the proposed JBU module, and evaluates their impact on performance across various tasks including general knowledge VQA, OCR-based VQA, and high-resolution image perception.
read the caption
Table 3: Comparison of different methods for feature pyramid construction. “ConvNext” means we replace the CILP-ViT with CLIP-ConvNext [68] as visual encoder and directly use the feature maps from multiple stages as the final hierarchical feature pyramid.
| Method | Period(h) | Latency(s) | Memory(G) | Average | MMEP | GQA | AI2D | VQAC | VQAT | VQAD |
|---|---|---|---|---|---|---|---|---|---|---|
| Pyramid | 62.4 | 1.26 | 60.3 | 62.4 | 69.0 | 60.8 | 57.3 | 60.7 | 67.5 | 58.9 |
| Fix [33] | 26.9 | 0.62 | 41.7 | 64.6 | 73.8 | 63.9 | 58.8 | 60.9 | 66.2 | 63.8 |
| Selective | 27.7 | 0.54 | 39.4 | 65.3 | 73.0 | 64.6 | 58.3 | 62.5 | 68.5 | 65.0 |
🔼 This table (Table 4) compares different grid sizes for the RoI-Align operation within the hierarchical window attention mechanism, evaluating their impact on performance and efficiency. The ‘Pyramid’ method uses a multi-level grid where the size increases with the feature level (e.g., 2x3 for level 0, 4x6 for level 1), creating a region-level feature pyramid. The ‘Fix’ method uses a fixed 3x3 grid for all feature levels. The table reports training time (Period on 8xA100 GPUs), inference latency (Latency on a single A100 for a 1008x672 image), and GPU memory usage (Memory on 8xA100 GPUs with one image per GPU) during the supervised fine-tuning stage of the MLLM, as well as performance metrics (Average score across tasks, MMEP, GQA, AI2D, VQAC, VQAT, and VQAD) to show the effectiveness of different grid options.
read the caption
Table 4: Comparison of different choice of grid sizes on performance and efficiency. “Pyramid” means the feature grids from different levels form a region-level feature pyramid, e.g.formulae-sequence𝑒𝑔e.g.italic_e . italic_g ., [2×\times×3] for level-0, [4×\times×6] for level-1, [8×\times×12] for leval-2. “Fix” represents all feature maps are pooled into a 3×\times×3 feature grid. We measure the training period on 8×\times×A100s, the latency on an A100 with a 1008×\times×672 image, and the GPU memory on 8×\times×A100s with 1 image per GPU in supervised fine-tune phase.
| Data | Size | Response formatting prompts |
|---|---|---|
| LLaVA [63] | 158K | – |
| ShareGPT [90] | 40K | – |
| VQAv2 [29] | 83K | Answer the question using a single word or phrase. |
| GQA [38] | 72K | |
| OKVQA [75] | 9K | |
| OCRVQA [82] | 80K | |
| DocVQA [95] | 15K | |
| ChartQA [76] | 20K | |
| A-OKVQA [88] | 66K | Answer directly with the option’s letter from the given choices. |
| DVQA [41] | 20K | – |
| TextCaps [92] | 22K | Provide a one-sentence caption for the provided image. |
| ShareGPT4V [18] | 55K | – |
| AI2D [43] | 3K | – |
| LAION-GPT4V [3] | 11K | – |
| SythDog-EN [46] | 40K | – |
| LRV-Instruct [61] | 30K | – |
| RefCOCO | 48K | |
| [42, 74] | Provide a short description for this region. (for Region Caption) | |
| VG [48] | 86K | Provide the bounding box coordinate of the region this sentence describes. (for Referring Expression Comprehension) |
| Total | 858K |
🔼 This table details the composition of the 858k dataset used for supervised fine-tuning of the Multimodal Large Language Model (MLLM). It lists various data sources, their sizes, and the prompt templates used for response formatting during training.
read the caption
Table 5: Detailed composition of our 858k-mixed dataset.
| Level | Period(h) | Memory(G) | Average | GQA | SQA | REC | VQAC | VQAT | ESTVQA | MMEP |
|---|---|---|---|---|---|---|---|---|---|---|
| 0,2 | 27.7 | 41.9 | 63.4 | 63.9 | 69.5 | 71.5 | 60.5 | 66.5 | 40.6 | 71.0 |
| 0,1,2 | 28.0 | 41.9 | 63.7 | 63.8 | 70.2 | 71.8 | 60.5 | 66.9 | 40.8 | 72.1 |
| 0,1,2,3 | 45.6 | 53.0 | 63.8 | 64.4 | 69.3 | 72.6 | 60.7 | 66.4 | 41.6 | 71.4 |
| 0,1,2,3 (w/o HS.) | 45.6 | 52.6 | 62.4 | 63.6 | 69.8 | 67.1 | 57.8 | 66.5 | 39.9 | 72.0 |
🔼 This table presents the impact of different feature level choices on model performance and efficiency. It explores configurations using level 0, 2; levels 0, 1, 2; and levels 0, 1, 2, and 3 of the feature pyramid. A configuration without hierarchical supervision is included for levels 0, 1, 2, and 3. The metrics include efficiency measurements like training period and memory usage, as well as performance scores on various VQA benchmarks such as Average, GQA, SQA, REC, VQAC, VQAT, ESTVQA, and MMEP. The table demonstrates how different feature levels and hierarchical supervision affect model performance and resource consumption.
read the caption
Table 6: Comparison of different choices of feature level on performance and efficiency. “HS.”: hierarchical supervision. ESTVQA [101] is a VQA benchmark focusing on scene text recognition.
Full paper#