↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The rapid development of AI agents has led to optimistic predictions about workplace automation, while skeptics question the reasoning abilities and generalization capabilities of current language models. This gap stems from a lack of objective benchmarks assessing AI agents’ effectiveness on real-world professional tasks, as previous evaluations often focus on simpler tasks or lack the interactivity found in workplace settings. Assessing the potential and limitations of AI agents in real-world tasks is important given both their positive and negative implications, such as increased quality of life vs. job displacement.
To address this, the paper introduces TheAgentCompany, an extensible benchmark simulating a software development company. The benchmark evaluates AI agents on various tasks, including software engineering, project management, and financial analysis, requiring interactions with simulated colleagues and using real-world tools like web browsers, code editors, and terminals. The environment also includes a mock company intranet with websites for code, documents, project management, and communication. The evaluation includes checkpoints for partial credit and provides a nuanced perspective on task automation with LM agents, offering insights into their current capabilities and areas needing further development.
Key Takeaways#
Why does it matter?#
TheAgentCompany benchmark provides a crucial platform for evaluating the real-world capabilities of AI agents, offering insights into their potential impact on the workplace. This is important because it moves beyond simplified settings and introduces complexities like social interactions and intricate UIs, mirroring real-world professional environments. The benchmark enables realistic assessments of agent performance and facilitates focused development, contributing to the broader goal of understanding AI’s transformative role in the future of work. This research opens new avenues for investigation into improving AI agents’ abilities to handle complex real-world tasks, especially within specific occupational categories.
Visual Insights#

🔼 The figure provides a high-level overview of TheAgentCompany, a benchmark designed for evaluating AI agents in realistic work environments. It highlights key features such as: - Reproducible and Self-hosted Environment: Ensuring consistent and comparable evaluation across different methods and over time. - Simulated Colleagues: Testing agent communication capabilities. - Checkpoint and Execution-based Evaluation: Assessing agent progress and overall task completion. - Diverse and Realistic Tasks: Focusing on a set of 175 professional tasks commonly encountered in a software engineering company, making the benchmark relevant to real-world work scenarios.
read the caption
Figure 1: An overview of TheAgentCompany benchmark. It features a reproducible and self-hosted environment, simulated colleagues to test agent communication capabilities, checkpoint and execution-based evaluation, and a set of 175 diverse, realistic and professional tasks in a software engineering company setting.
| Website | https://the-agent-company.com | |
 | Code | https://github.com/TheAgentCompany/TheAgentCompany |
| Evaluations | https://github.com/TheAgentCompany/experiments |
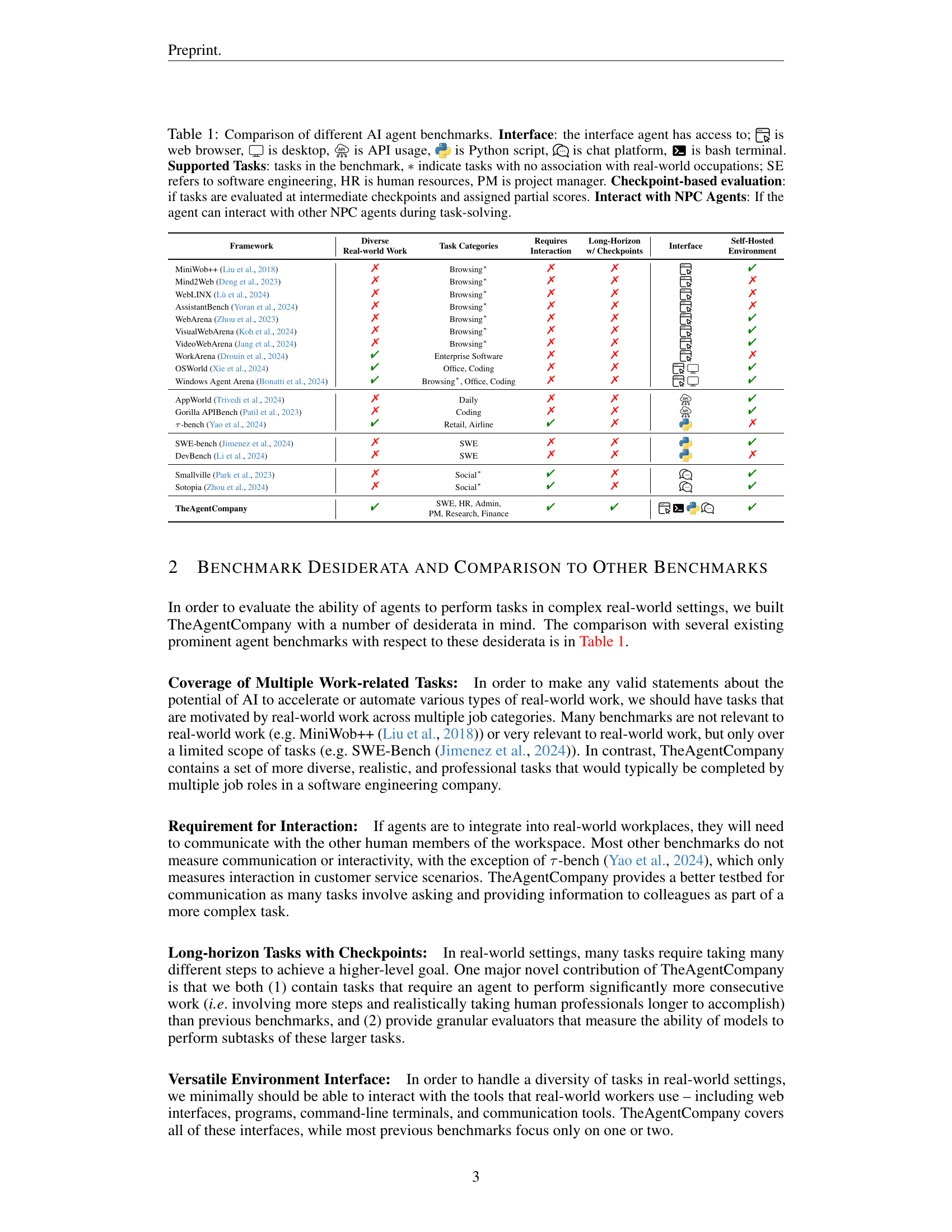
🔼 This table compares existing AI agent benchmarks across various criteria, including the interfaces they use (web, desktop, API, etc.), the types of tasks they support (real-world work-related vs. not), whether they use checkpoint-based evaluation with partial scores, and whether agents can interact with simulated colleagues (NPC agents). The table aims to highlight TheAgentCompany’s unique features in comparison to these other benchmarks by checking of each benchmarks meet those features.
read the caption
Table 1: Comparison of different AI agent benchmarks. Interface: the interface agent has access to; is web browser, is desktop, is API usage, is Python script, is chat platform, is bash terminal. Supported Tasks: tasks in the benchmark, ∗*∗ indicate tasks with no association with real-world occupations; SE refers to software engineering, HR is human resources, PM is project manager. Checkpoint-based evaluation: if tasks are evaluated at intermediate checkpoints and assigned partial scores. Interact with NPC Agents: If the agent can interact with other NPC agents during task-solving.
In-depth insights#
LLM Agent Limits#
LLM agents, despite rapid advancements, face key limitations. They struggle with tasks requiring common sense or social skills, often misinterpreting nuances of human communication. Web browsing remains a major challenge due to complex UI and distractions. Agents excel at well-defined coding tasks but falter when faced with ambiguity or implicit assumptions, lacking the domain expertise of human professionals. Furthermore, current LLM architectures are computationally expensive and require substantial resources. While progress is being made with smaller, more efficient models, they still lag behind larger counterparts. These limitations highlight crucial areas for future research, including imbuing agents with stronger reasoning abilities, improving web navigation, and making them more robust and cost-effective.
Real-World LLM Tasks#
Real-world LLM tasks represent a crucial area of focus as LLMs transition from theoretical constructs to practical tools. These tasks go beyond academic benchmarks and delve into the complex, nuanced challenges faced in professional environments. Effectively tackling real-world tasks demands LLMs not only possess advanced language understanding and generation capabilities but also demonstrate adaptability, commonsense reasoning, and problem-solving skills. Moreover, these tasks frequently involve intricate interactions with external systems and software tools, necessitating robust integration capabilities and the ability to navigate complex user interfaces. Further, successful execution of real-world tasks often hinges on effective collaboration with humans, requiring LLMs to grasp social cues, communicate clearly, and respond appropriately to feedback. Evaluating LLM performance on such tasks requires moving beyond simple metrics and incorporating measures of efficiency, robustness, and ethical considerations. TheAgentCompany benchmark offers a glimpse into this landscape by evaluating LLM agents in a simulated workplace setting, highlighting both the potential and the current limitations of LLMs in tackling real-world challenges. By confronting these complex, multifaceted tasks, LLM development can move towards creating truly impactful tools with far-reaching applications in various domains.
TheAgentCompany Env#
TheAgentCompany environment simulates a realistic software company setting for evaluating AI agents. It features a self-hosted, reproducible setup encompassing local workspaces, an intranet with collaborative platforms (GitLab, OwnCloud, Plane, RocketChat), and simulated colleagues. This versatile environment allows agents to interact via web browsers, terminals, and code editors, mimicking real-world workflows. The inclusion of long-horizon tasks with checkpoints and a focus on diverse, consequential tasks sets it apart. This design promotes a nuanced evaluation of agent capabilities regarding task automation in professional settings, pushing beyond simple instructions to encompass communication, coding, and web interactions.
Agent Evaluation#
Evaluating agents in realistic environments is crucial. TheAgentCompany benchmark employs a checkpoint-based system, offering partial credit for incomplete tasks, thus providing a nuanced performance assessment. This approach acknowledges the complexity of real-world tasks, and allows for better tracking of progress as agents improve. Beyond simple success/failure metrics, partial completion scoring reveals incremental learning and capability, distinguishing between outright failure and meaningful, albeit incomplete progress. This granular analysis is essential for identifying specific agent strengths and weaknesses, and guiding future development in agent design. The AgentCompany’s focus on partial credit promotes more robust, practical agent evaluation by reflecting real-world scenarios where perfect solutions aren’t always achievable, but partial solutions still hold value.
Future of Work & LLMs#
Large Language Models (LLMs) are poised to reshape the future of work significantly. While concerns around job displacement exist, the transformative potential of LLMs offers exciting possibilities. They can automate repetitive tasks, freeing human workers for more creative and strategic endeavors. Furthermore, LLMs can augment human capabilities, providing valuable insights and assistance in complex decision-making. This synergy between humans and LLMs is likely to define the next era of work, where collaboration becomes paramount. Adaptability and upskilling will be crucial for workers to thrive in this evolving landscape, as new roles emerge that require human-LLM interaction. Ethical considerations surrounding bias, transparency, and responsible AI development must be addressed proactively to ensure equitable outcomes and maximize societal benefit.
More visual insights#
More on figures

🔼 This figure illustrates a workflow of an agent completing a project management task within TheAgentCompany environment. The agent uses various tools and interacts with simulated colleagues to manage a sprint for the RisingWave project. Key steps shown in the workflow include: - Accessing and updating sprint issues in Plane. - Notifying issue assignees via Rocket.Chat. - Cloning the project repository from GitLab. - Running a code coverage script. - Uploading a summarized report to OwnCloud. - Incorporating feedback from a simulated project manager. Each step has associated checkpoints and scores, demonstrating the agent’s progress and performance on the task.
read the caption
Figure 2: Example TheAgentCompany workflow illustrating an agent managing a sprint for the RisingWave project. The task involves identifying and moving unfinished issues to next sprint cycle, notifying assignees of those issues, running a code coverage script, uploading summarized report to OwnCloud, and incorporating feedback on report from a simulated project manager.

🔼 This figure provides a schematic overview of the agent architecture employed in the study. The agent interacts with a simulated environment through three key interfaces: a browser, a bash shell, and an IPython server. The core of the agent’s operation involves receiving observations from the environment and using these, along with a history of past actions and observations, to determine the next action to take. This action is then relayed back to the environment, and the cycle continues. The diagram illustrates this flow, showing an example of an LLM prompt and the subsequent actions generated by the agent.
read the caption
Figure 3: Overview of OpenHands’ default CodeAct + Browsing agent architecture, the baseline agent used throughout the experiments.

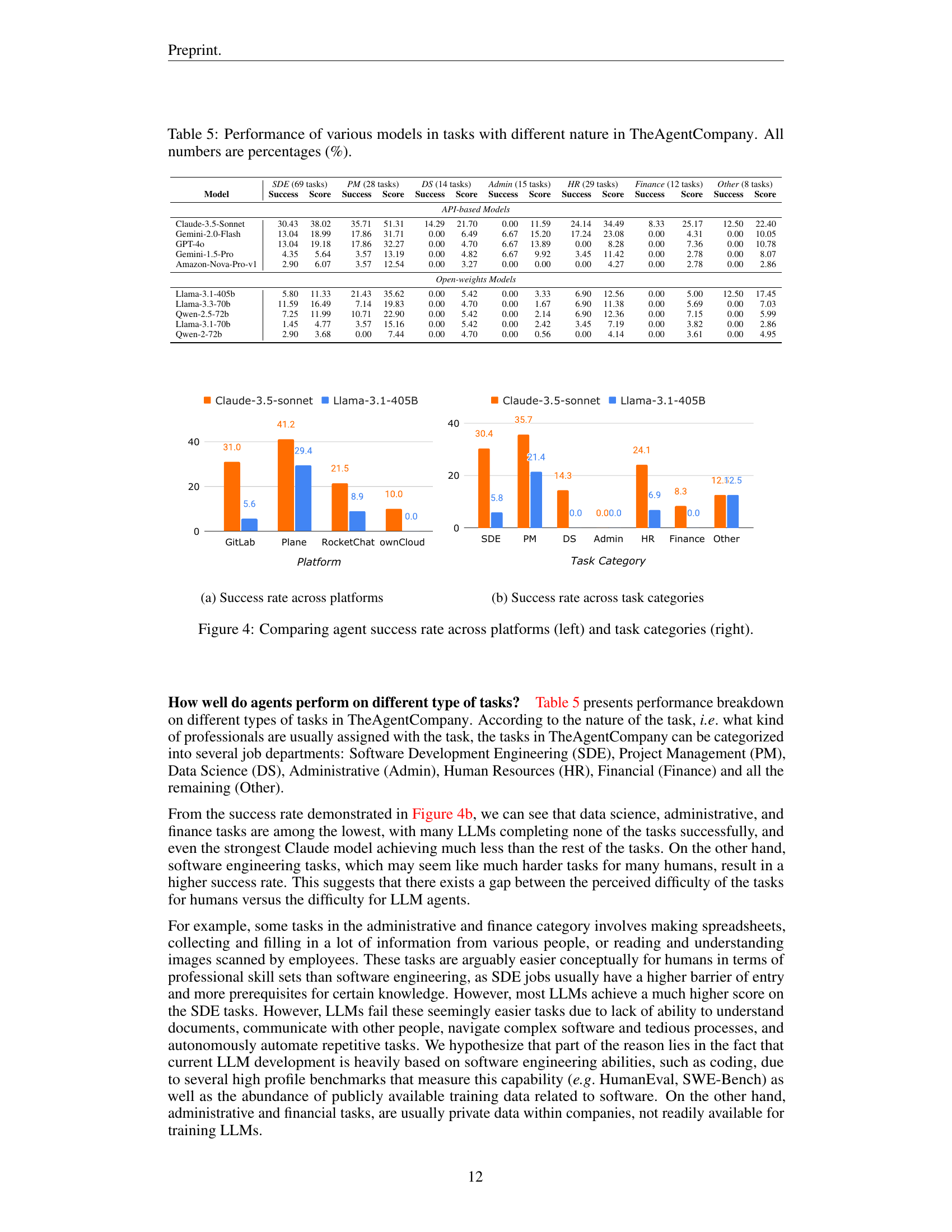
🔼 This bar chart compares the success rates of two large language models, Claude-3.5-sonnet and Llama-3.1-405B, across four different platforms: GitLab, Plane, RocketChat, and ownCloud. Success rate is defined as the percentage of tasks completed successfully on each platform. Claude-3.5-sonnet consistently outperforms Llama-3.1-405B on all platforms. Both models exhibit the highest success rates on GitLab and Plane, and struggle the most on ownCloud and RocketChat. This suggests that tasks involving coding and project management are easier for LLMs compared to those involving file management and communication.
read the caption
(a) Success rate across platforms

🔼 This bar chart compares the success rates of two large language models, Claude-3.5-Sonnet and Llama-3.1-405B, across seven different task categories: Software Development Engineering (SDE), Project Management (PM), Data Science (DS), Administration (Admin), Human Resources (HR), Finance, and Other. The x-axis represents the task category, and the y-axis represents the success rate, expressed as a percentage. Each bar represents the success rate of a specific LLM on a specific task category.
read the caption
(b) Success rate across task categories

🔼 This figure presents two bar charts comparing the success rates of different large language models (LLMs) on tasks within TheAgentCompany benchmark. The left chart (a) breaks down success rates by platform, indicating how well the models perform on tasks involving GitLab, Plane, RocketChat, and ownCloud. It highlights performance disparities across these platforms, suggesting areas where LLMs excel or struggle. The right chart (b) compares success rates across different task categories related to job roles within a software company, including Software Development Engineer (SDE), Project Management (PM), Data Science (DS), Administrative (Admin), Human Resources (HR), Finance, and Other. This analysis reveals how well LLMs perform on tasks typically associated with different professions within a simulated work environment. The specific models compared in both graphs are Claude-3.5-Sonnet and Llama-3.1-405B.
read the caption
Figure 4: Comparing agent success rate across platforms (left) and task categories (right).

🔼 The agent communicates with a simulated colleague (Zhang Wei) through RocketChat to request equipment (three HP Workstations and three wireless mice). Zhang Wei informs the agent that the request exceeds the department’s budget. The agent then revises the request to two mice and two desktops, demonstrating its ability to negotiate and adhere to budget constraints.
read the caption
Figure 5: Simulated Colleague Communication Example 1 – The agent is tasked with collecting required equipment while adhering to the department’s budget. After calculating that the requested items exceed the budget, the agent negotiates with the simulated colleague to reduce the request, showcasing its ability of effective communication.

🔼 The agent interacts with a simulated project manager (Li Ming) through a chat interface to gather requirements for a new graduate software engineering job description. The agent asks for the job description template, minimum and preferred qualifications, and the ideal salary range. Li Ming provides the requested information. This tests the agent’s ability to systematically collect information and clarify requirements via professional communication.
read the caption
Figure 6: Simulated Colleague Communication Example 2 – The agent is tasked with writing a job description for a new graduate software engineering position. To fulfill the task, the agent communicates with simulated Project Manager to gather requirements. The agent requests the job description template, minimum and preferred qualifications, and the ideal salary range. This interaction evaluates the agent’s ability to gather information systematically and clarify task-related requirements through effective communication.
More on tables
| Model | Success | Score | Steps | Costs |
|---|---|---|---|---|
| API-based Models | ||||
| Claude-3.5-Sonnet | 24.0% | 34.4% | 29.17 | $6.34 |
| Gemini-2.0-Flash | 11.4% | 19.0% | 39.85 | $0.79 |
| GPT-4o | 8.6% | 16.7% | 14.55 | $1.29 |
| Gemini-1.5-Pro | 3.4% | 8.0% | 22.10 | $6.78 |
| Amazon-Nova-Pro-v1 | 1.7% | 5.7% | 19.59 | $1.55 |
| Open-weights Models | ||||
| Llama-3.1-405b | 7.4% | 14.1% | 22.95 | $3.21 |
| Llama-3.3-70b | 6.9% | 12.8% | 20.93 | $0.93 |
| Qwen-2.5-72b | 5.7% | 11.8% | 23.99 | $1.53 |
| Llama-3.1-70b | 1.7% | 6.5% | 19.18 | $0.83 |
| Qwen-2-72b | 1.1% | 4.2% | 23.70 | $0.28 |
🔼 This table provides example task intents and checkpoints for three domains in TheAgentCompany, namely, SWE, Finance, and PM. Each domain includes a task intent, which is a brief description of the task, and several checkpoints that evaluate the agent’s progress in completing the task. Checkpoints reflect intermediate steps and measure completion based on actions performed, accuracy, and collaboration elements. This table showcases the diversity and structure of the tasks designed in TheAgentCompany.
read the caption
Table 2: Example task intents and checkpoints for three domains.
| Model | GitLab (71 tasks) | Plane (17 tasks) | RocketChat (79 tasks) | ownCloud (70 tasks) |
|---|---|---|---|---|
| — | Success (%) | Score (%) | Success (%) | Score (%) |
| API-based Models | ||||
| Claude-3.5-Sonnet | 30.99 | 40.25 | 41.18 | 50.37 |
| Gemini-2.0-Flash | 11.27 | 18.21 | 17.65 | 29.84 |
| GPT-4o | 11.27 | 19.46 | 23.53 | 33.68 |
| Gemini-1.5-Pro | 2.82 | 3.88 | 5.88 | 14.05 |
| Amazon-Nova-Pro-v1 | 2.82 | 7.22 | 5.88 | 16.67 |
| Open-weights Models | ||||
| Llama-3.1-405b | 5.63 | 11.84 | 29.41 | 39.12 |
| Llama-3.3-70b | 8.45 | 14.26 | 11.76 | 21.65 |
| Qwen-2.5-72b | 5.63 | 11.33 | 11.76 | 23.56 |
| Llama-3.1-70b | 1.41 | 6.09 | 5.88 | 15.35 |
| Qwen-2-72b | 1.41 | 1.94 | 5.88 | 12.45 |
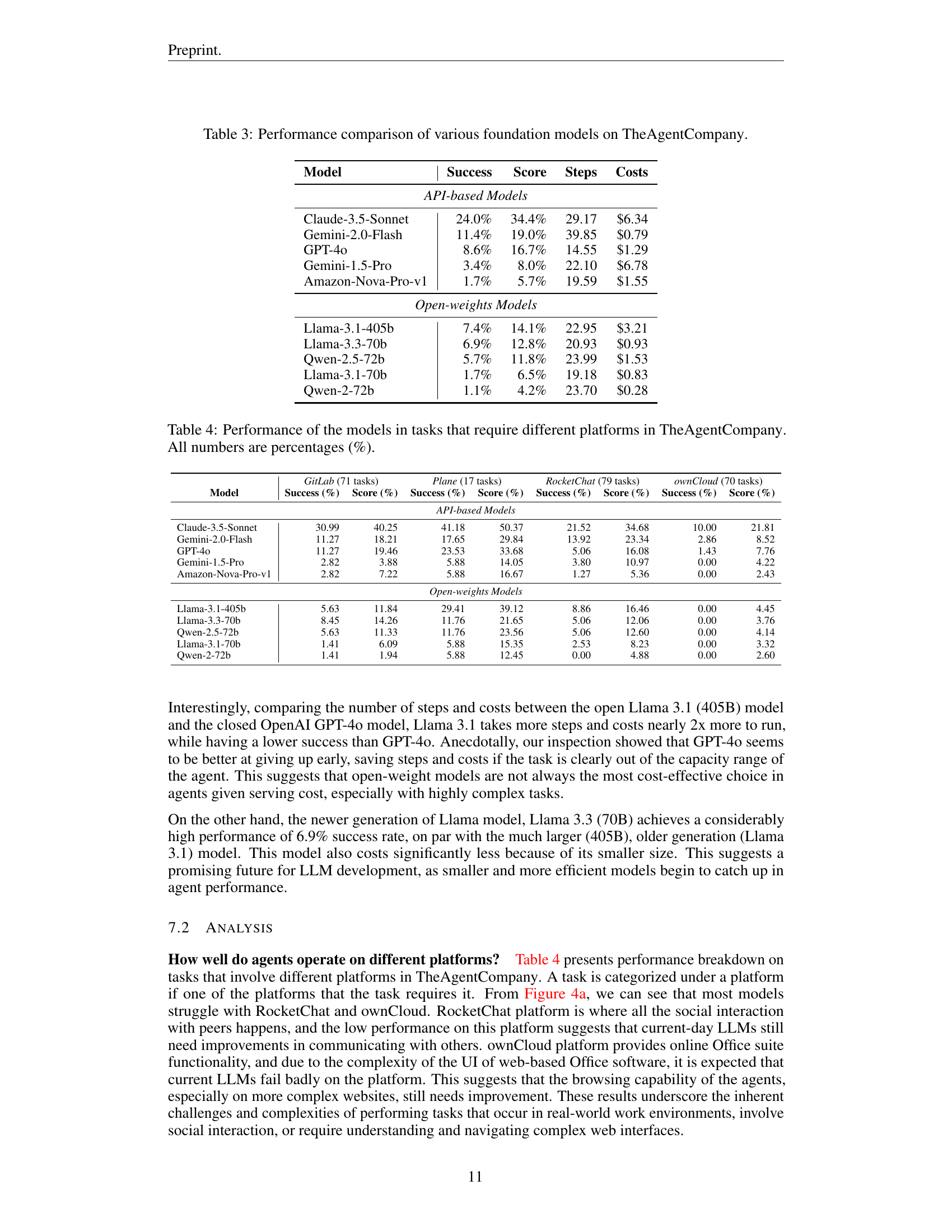
🔼 This table compares the performance of different large language models (LLMs) on a set of real-world tasks as defined in TheAgentCompany benchmark. It includes both API-based models (like Claude, Gemini, GPT-40, etc.) and open-weight models (like Llama, Qwen, etc.). The metrics used for comparison include success rate, overall score (taking into account partial completions), number of steps taken per task, and cost per task.
read the caption
Table 3: Performance comparison of various foundation models on TheAgentCompany.
| Model | SDE (69 tasks) | PM (28 tasks) | DS (14 tasks) | Admin (15 tasks) | HR (29 tasks) | Finance (12 tasks) | Other (8 tasks) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Success | Score | Success | Score | Success | Score | Success | Score | Success | Score | Success | Score | Success | |
| — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| API-based Models | |||||||||||||
| Claude-3.5-Sonnet | 30.43 | 38.02 | 35.71 | 51.31 | 14.29 | 21.70 | 0.00 | 11.59 | 24.14 | 34.49 | 8.33 | 25.17 | 12.50 |
| Gemini-2.0-Flash | 13.04 | 18.99 | 17.86 | 31.71 | 0.00 | 6.49 | 6.67 | 15.20 | 17.24 | 23.08 | 0.00 | 4.31 | 0.00 |
| GPT-4o | 13.04 | 19.18 | 17.86 | 32.27 | 0.00 | 4.70 | 6.67 | 13.89 | 0.00 | 8.28 | 0.00 | 7.36 | 0.00 |
| Gemini-1.5-Pro | 4.35 | 5.64 | 3.57 | 13.19 | 0.00 | 4.82 | 6.67 | 9.92 | 3.45 | 11.42 | 0.00 | 2.78 | 0.00 |
| Amazon-Nova-Pro-v1 | 2.90 | 6.07 | 3.57 | 12.54 | 0.00 | 3.27 | 0.00 | 0.00 | 0.00 | 4.27 | 0.00 | 2.78 | 0.00 |
| Open-weights Models | |||||||||||||
| Llama-3.1-405b | 5.80 | 11.33 | 21.43 | 35.62 | 0.00 | 5.42 | 0.00 | 3.33 | 6.90 | 12.56 | 0.00 | 5.00 | 12.50 |
| Llama-3.3-70b | 11.59 | 16.49 | 7.14 | 19.83 | 0.00 | 4.70 | 0.00 | 1.67 | 6.90 | 11.38 | 0.00 | 5.69 | 0.00 |
| Qwen-2.5-72b | 7.25 | 11.99 | 10.71 | 22.90 | 0.00 | 5.42 | 0.00 | 2.14 | 6.90 | 12.36 | 0.00 | 7.15 | 0.00 |
| Llama-3.1-70b | 1.45 | 4.77 | 3.57 | 15.16 | 0.00 | 5.42 | 0.00 | 2.42 | 3.45 | 7.19 | 0.00 | 3.82 | 0.00 |
| Qwen-2-72b | 2.90 | 3.68 | 0.00 | 7.44 | 0.00 | 4.70 | 0.00 | 0.56 | 0.00 | 4.14 | 0.00 | 3.61 | 0.00 |
🔼 This table presents a breakdown of the performance of different large language models on tasks that involve interactions with specific platforms within TheAgentCompany, such as GitLab, Plane, RocketChat, and ownCloud. The performance is measured in terms of success rate and overall score, both presented as percentages.
read the caption
Table 4: Performance of the models in tasks that require different platforms in TheAgentCompany. All numbers are percentages (%).
Full paper#