↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal retrieval struggles with the scarcity of high-quality training data. Existing methods either rely on small, manually annotated datasets or generate data of questionable quality. This limitation severely restricts progress.
MegaPairs tackles this problem by introducing a novel data synthesis technique that leverages vision-language models (VLMs) and open-domain images to create a large-scale, high-quality dataset of 26 million training examples. The method also includes a heterogeneous KNN triplet sampling strategy for diverse image pair selection and uses MLLMs to generate diverse and high-quality instructions, enhancing the dataset. The resulting models, trained on this data, significantly outperform the baselines, demonstrating the effectiveness of the approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical bottleneck of limited training data in multimodal retrieval. By introducing a novel data synthesis method and a massive synthetic dataset, it significantly advances the field and opens new avenues for research. The readily available dataset and models will accelerate progress and democratize research in this area. The innovative data synthesis technique is also highly relevant to the broader field of AI instruction tuning.
Visual Insights#

🔼 Figure 1 illustrates the process of creating multimodal triplets for training a universal multimodal retriever. Panel (a) shows how image pairs are mined from a large-scale image corpus using multiple similarity models (CLIP vision-encoder, DINO vision-encoder, and CLIP text-encoder) to ensure diverse correlations between images. These models identify various relationships between image pairs, including semantic similarity, visual pattern similarity, and caption similarity. Panel (b) demonstrates how open-ended instructions are generated for each image pair using a Multimodal Large Language Model (MLLM) and a Large Language Model (LLM). The MLLM generates a detailed description of the relationship between the images, and the LLM then refines this description into multiple open-ended instructions. These instructions provide diverse ways to describe the relationship between the image pairs and improve the model’s ability to generalize.
read the caption
Figure 1: Construction pipeline of multimodal triplets: (a) mining of image pairs, (b) generation of open-ended instructions. Multiple similarity models are used to introduce diversified correlations for the image pairs.
| Task | Zero-shot | Zero-shot | Zero-shot | Zero-shot | Zero-shot | Zero-shot | Zero-shot | Zero-shot | Fine-Tune | Fine-Tune |
|---|---|---|---|---|---|---|---|---|---|---|
| CLIP | OpenCLIP | SigLIP | BLIP2 | MagicLens | E5-V | UniIR | MMRet | VLM2Vec | MMRet | |
| Classification (10 tasks) | 55.8 | 63.5 | 45.4 | 10.3 | 48.0 | 9.6 | 53.7 | 49.1 | 65.6 | 58.8 |
| ImageNet-1K | 55.8 | 63.5 | 45.4 | 10.3 | 48.0 | 9.6 | 53.7 | 49.1 | 65.6 | 58.8 |
| N24News | 34.7 | 38.6 | 13.9 | 36.0 | 33.7 | 23.4 | 33.9 | 45.8 | 79.5 | 71.3 |
| HatefulMemes | 51.1 | 51.7 | 47.2 | 49.6 | 49.0 | 49.7 | 51.0 | 51.0 | 67.1 | 53.7 |
| VOC2007 | 50.7 | 52.4 | 64.3 | 52.1 | 51.6 | 49.9 | 62.7 | 74.6 | 88.6 | 85.0 |
| SUN397 | 43.4 | 68.8 | 39.6 | 34.5 | 57.0 | 33.1 | 61.7 | 60.1 | 72.7 | 70.0 |
| Place365 | 28.5 | 37.8 | 20.0 | 21.5 | 31.5 | 8.6 | 38.0 | 35.3 | 42.6 | 43.0 |
| ImageNet-A | 25.5 | 14.2 | 42.6 | 3.2 | 8.0 | 2.0 | 12.9 | 31.6 | 19.3 | 36.1 |
| ImageNet-R | 75.6 | 83.0 | 75.0 | 39.7 | 70.9 | 30.8 | 61.6 | 66.2 | 70.2 | 71.6 |
| ObjectNet | 43.4 | 51.4 | 40.3 | 20.6 | 31.6 | 7.5 | 37.1 | 49.2 | 29.5 | 55.8 |
| Country-211 | 19.2 | 16.8 | 14.2 | 2.5 | 6.2 | 3.1 | 8.8 | 9.3 | 13.0 | 14.7 |
| All Classification | 42.8 | 47.8 | 40.3 | 27.0 | 38.8 | 21.8 | 42.1 | 47.2 | 54.8 | 56.0 |
| VQA (10 tasks) | 7.5 | 11.5 | 2.4 | 8.7 | 12.7 | 8.9 | 24.5 | 28.0 | 63.2 | 73.3 |
| OK-VQA | 7.5 | 11.5 | 2.4 | 8.7 | 12.7 | 8.9 | 24.5 | 28.0 | 63.2 | 73.3 |
| A-OKVQA | 3.8 | 3.3 | 1.5 | 3.2 | 2.9 | 5.9 | 10.6 | 11.6 | 50.2 | 56.7 |
| DocVQA | 4.0 | 5.3 | 4.2 | 2.6 | 3.0 | 1.7 | 5.6 | 12.6 | 78.4 | 78.5 |
| InfographicsVQA | 4.6 | 4.6 | 2.7 | 2.0 | 5.9 | 2.3 | 5.0 | 10.6 | 40.8 | 39.3 |
| ChartQA | 1.4 | 1.5 | 3.0 | 0.5 | 0.9 | 2.4 | 1.8 | 2.4 | 59.0 | 41.7 |
| Visual7W | 4.0 | 2.6 | 1.2 | 1.3 | 2.5 | 5.8 | 12.3 | 9.0 | 47.7 | 49.5 |
| ScienceQA | 9.4 | 10.2 | 7.9 | 6.8 | 5.2 | 3.6 | 11.6 | 23.3 | 43.4 | 45.2 |
| VizWiz | 8.2 | 6.6 | 2.3 | 4.0 | 1.7 | 2.6 | 19.2 | 25.9 | 39.2 | 51.7 |
| GQA | 41.3 | 52.5 | 57.5 | 9.7 | 43.5 | 7.8 | 49.3 | 41.3 | 60.7 | 59.0 |
| TextVQA | 7.0 | 10.9 | 1.0 | 3.3 | 4.6 | 3.2 | 10.6 | 18.9 | 66.1 | 79.0 |
| All VQA | 9.1 | 10.9 | 8.4 | 4.2 | 8.3 | 4.9 | 15.0 | 18.4 | 54.9 | 57.4 |
| Retrieval (12 tasks) | 30.7 | 25.4 | 21.5 | 18.0 | 24.8 | 9.2 | 37.6 | 62.6 | 73.3 | 83.0 |
| VisDial | 30.7 | 25.4 | 21.5 | 18.0 | 24.8 | 9.2 | 37.6 | 62.6 | 73.3 | 83.0 |
| CIRR | 12.6 | 15.4 | 15.1 | 9.8 | 39.1 | 6.1 | 53.2 | 65.7 | 47.8 | 61.4 |
| VisualNews_t2i | 78.9 | 74.0 | 51.0 | 48.1 | 50.7 | 13.5 | 63.6 | 45.7 | 67.2 | 74.2 |
| VisualNews_i2t | 79.6 | 78.0 | 52.4 | 13.5 | 21.1 | 8.1 | 68.8 | 53.4 | 70.7 | 78.1 |
| MSCOCO_t2i | 59.5 | 63.6 | 58.3 | 53.7 | 54.1 | 20.7 | 72.0 | 68.7 | 70.6 | 78.6 |
| MSCOCO_i2t | 57.7 | 62.1 | 55.0 | 20.3 | 40.0 | 14.0 | 74.1 | 56.7 | 66.5 | 72.4 |
| NIGHTS | 60.4 | 66.1 | 62.9 | 56.5 | 58.1 | 4.2 | 69.7 | 59.4 | 66.1 | 68.3 |
| WebQA | 67.5 | 62.1 | 58.1 | 55.4 | 43.0 | 17.7 | 86.3 | 76.3 | 88.1 | 90.2 |
| FashionIQ | 11.4 | 13.8 | 20.1 | 9.3 | 11.2 | 2.8 | 39.3 | 31.5 | 12.9 | 54.9 |
| Wiki-SS-NQ | 55.0 | 44.6 | 55.1 | 28.7 | 18.7 | 8.6 | 11.3 | 25.4 | 56.6 | 24.9 |
| OVEN | 41.1 | 45.0 | 56.0 | 39.5 | 1.6 | 5.9 | 66.6 | 73.0 | 47.3 | 87.5 |
| EDIS | 81.0 | 77.5 | 23.6 | 54.4 | 62.6 | 26.8 | 78.2 | 59.9 | 79.9 | 65.6 |
| All Retrieval | 53.0 | 52.3 | 31.6 | 33.9 | 35.4 | 11.5 | 60.1 | 56.5 | 62.3 | 69.9 |
| Visual Grounding (4 tasks) | 33.8 | 34.5 | 46.4 | 28.9 | 22.1 | 10.8 | 46.6 | 42.7 | 67.3 | 76.8 |
| MSCOCO | 33.8 | 34.5 | 46.4 | 28.9 | 22.1 | 10.8 | 46.6 | 42.7 | 67.3 | 76.8 |
| RefCOCO | 56.9 | 54.2 | 70.8 | 47.4 | 22.8 | 11.9 | 67.8 | 69.3 | 84.7 | 89.8 |
| RefCOCO-matching | 61.3 | 68.3 | 50.8 | 59.5 | 35.6 | 38.9 | 62.9 | 63.2 | 79.2 | 90.6 |
| Visual7W-pointing | 55.1 | 56.3 | 70.1 | 52.0 | 23.4 | 14.3 | 71.3 | 73.5 | 86.8 | 77.0 |
| All Visual Grounding | 51.8 | 53.3 | 59.5 | 47.0 | 26.0 | 19.0 | 62.2 | 62.2 | 79.5 | 83.6 |
| Final Score (36 tasks) | 37.8 | 39.7 | 34.8 | 25.2 | 27.8 | 13.3 | 42.8 | 44.0 | 60.1 | 64.1 |
| All | 37.8 | 39.7 | 34.8 | 25.2 | 27.8 | 13.3 | 42.8 | 44.0 | 60.1 | 64.1 |
| All IND | 37.1 | 39.3 | 32.3 | 25.3 | 31.0 | 14.9 | 44.7 | 43.5 | 66.5 | 59.1 |
| All OOD | 38.7 | 40.2 | 38.0 | 25.1 | 23.7 | 11.5 | 40.4 | 44.3 | 52.0 | 68.0 |
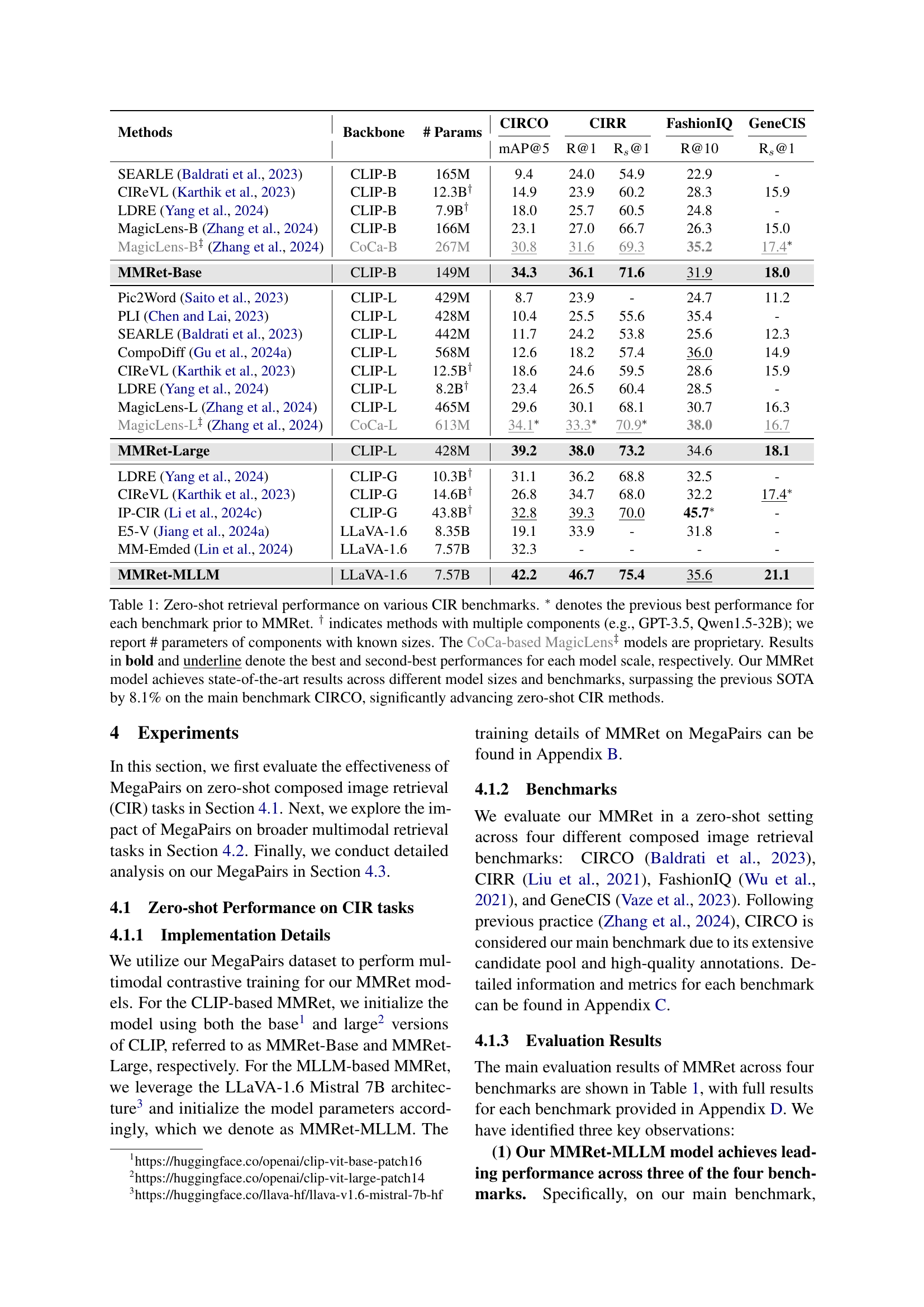
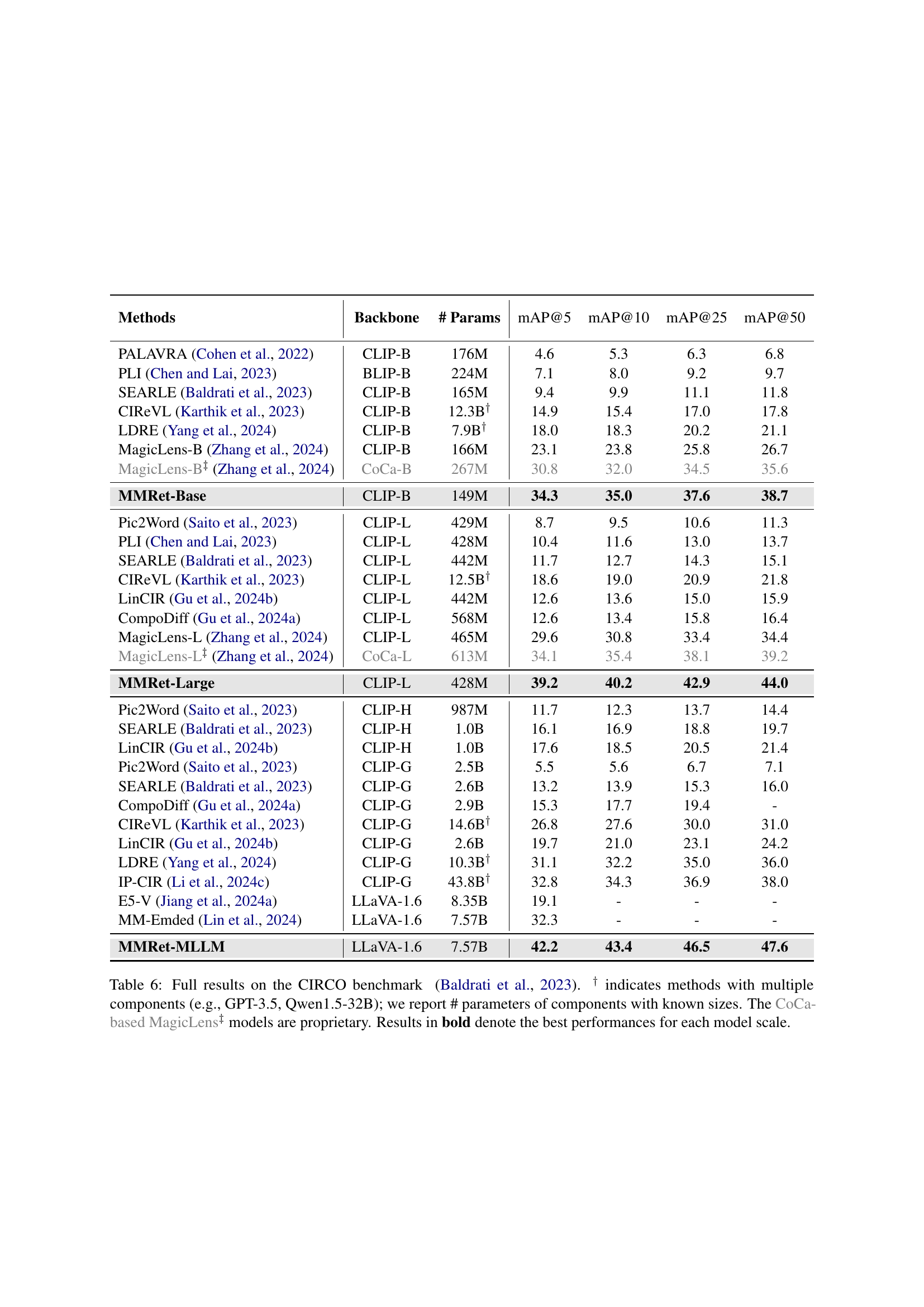
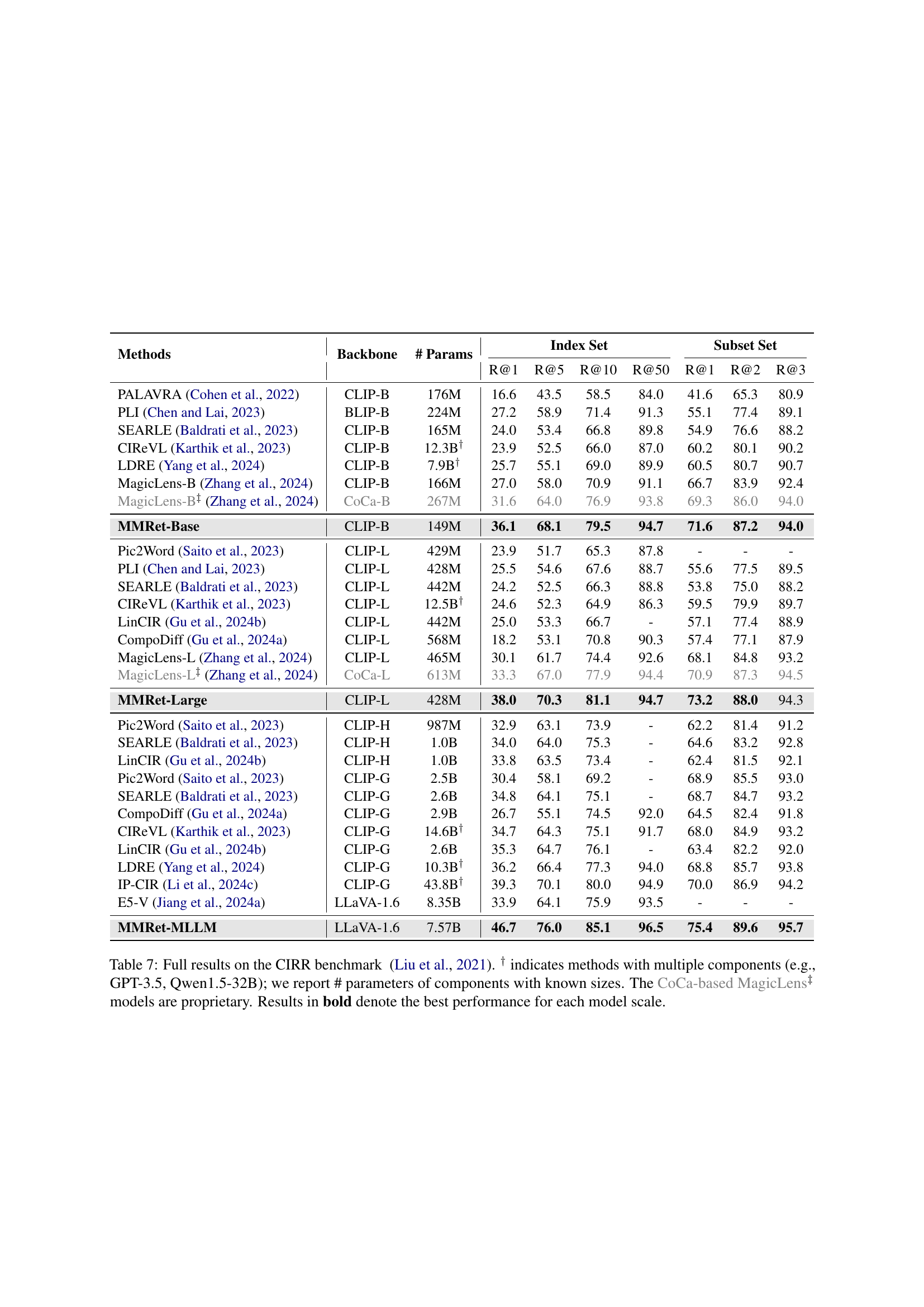
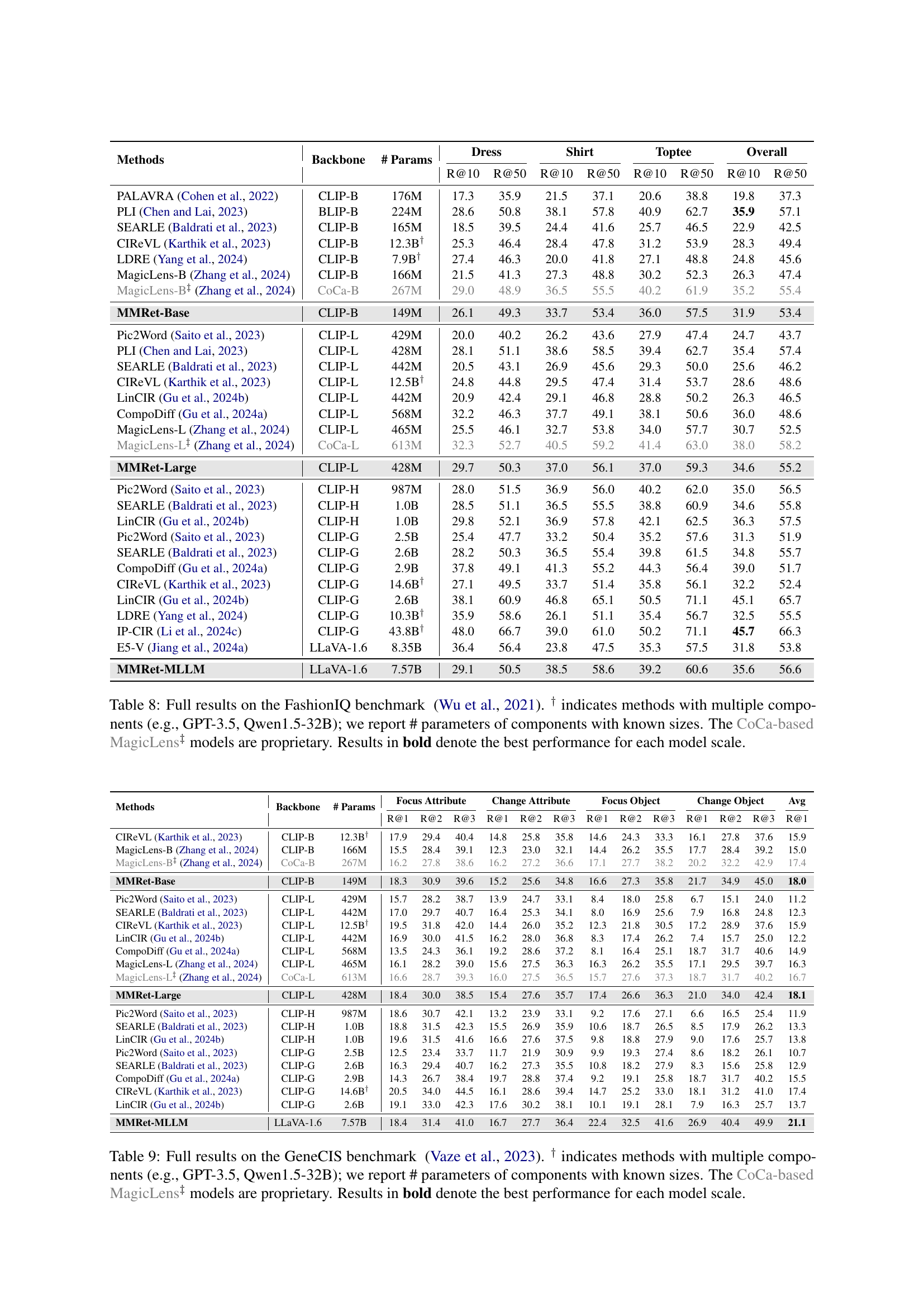
🔼 This table presents a comparison of zero-shot performance across four popular Composed Image Retrieval (CIR) benchmarks: CIRCO, CIRR, FashionIQ, and GeneCIS. The results show the mean Average Precision at 5 (mAP@5) and Recall at 1, 10, and 1 (R@1, R@10, R@1) for several different methods, including models based on CLIP, CoCa, and LLaVA architectures. The number of parameters in each model is also provided. Models denoted with a † symbol use multiple components; for these, only the parameters of the known components are given. Methods marked with ‡ used proprietary components (CoCa-based MagicLens). The table highlights the MMRet models’ state-of-the-art zero-shot performance across different model sizes, outperforming previous top performers significantly, notably by 8.1% on the CIRCO benchmark.
read the caption
Table 1: Zero-shot retrieval performance on various CIR benchmarks. ∗ denotes the previous best performance for each benchmark prior to MMRet. † indicates methods with multiple components (e.g., GPT-3.5, Qwen1.5-32B); we report # parameters of components with known sizes. The CoCa-based MagicLens‡ models are proprietary. Results in bold and underline denote the best and second-best performances for each model scale, respectively. Our MMRet model achieves state-of-the-art results across different model sizes and benchmarks, surpassing the previous SOTA by 8.1% on the main benchmark CIRCO, significantly advancing zero-shot CIR methods.
In-depth insights#
MegaPairs: Data Synthesis#
The MegaPairs data synthesis method tackles the critical problem of limited training data in multimodal retrieval. It cleverly leverages pre-trained vision-language models (VLMs) and large language models (LLMs) to generate a massive synthetic dataset. Instead of relying on manually annotated data, MegaPairs mines correlations between open-domain images using multiple similarity models, capturing diverse relationships. This approach, paired with the LLMs, generates high-quality, open-ended instructions, thus avoiding the limitations of existing methods in terms of scalability and quality. The resulting dataset, with 26 million training instances, enables significant performance gains, outperforming models trained on far larger datasets. This is a significant advancement, demonstrating the power of synthetic data generation in addressing the scarcity of labeled data and potentially accelerating progress in the field of multimodal retrieval.
MMRet Model Architectures#
The MMRet model’s architecture is a crucial aspect of its performance. The paper likely explores multiple architectures, perhaps comparing CLIP-based and MLLM-based approaches. A CLIP-based architecture, leveraging the dual-encoder design of CLIP, would independently encode image and text features. This approach offers efficiency but may lack the contextual understanding of MLLMs. In contrast, an MLLM-based architecture would integrate a visual encoder directly into a large language model. This allows for more sophisticated multimodal processing and potentially richer semantic understanding. The choice between these architectures likely depends on factors like computational resources, desired performance characteristics, and dataset size. A comparison would provide insights into the strengths and weaknesses of each method for universal multimodal retrieval. The paper might further investigate variations within each architecture, exploring different model sizes and parameter configurations to find optimal balance between accuracy and efficiency. The architecture descriptions should include detailed specifications of encoders, attention mechanisms, fusion techniques, and output representations, providing a blueprint for researchers to replicate the models or adapt them for similar tasks.
Zero-Shot CIR Results#
The heading “Zero-Shot CIR Results” strongly suggests a focus on evaluating the performance of a multimodal retrieval model, specifically on composed image retrieval (CIR) tasks, without any prior fine-tuning or task-specific training. This is crucial because it reveals the model’s inherent capabilities and generalizability. High performance in this setting would indicate a robust model architecture capable of effective cross-modal understanding. The results would likely present metrics like mean Average Precision (mAP) and Recall@K (R@K), comparing the model’s zero-shot performance against established baselines. State-of-the-art (SOTA) performance in zero-shot CIR would be a significant achievement, demonstrating the model’s ability to effectively leverage pre-trained knowledge for unseen tasks. A detailed analysis might further breakdown performance across different CIR benchmarks, highlighting strengths and weaknesses depending on dataset characteristics such as image diversity and complexity of instructions. The analysis should also discuss potential limitations of zero-shot evaluation and the need for fine-tuning in real-world scenarios, where optimal performance often requires task-specific adaptation.
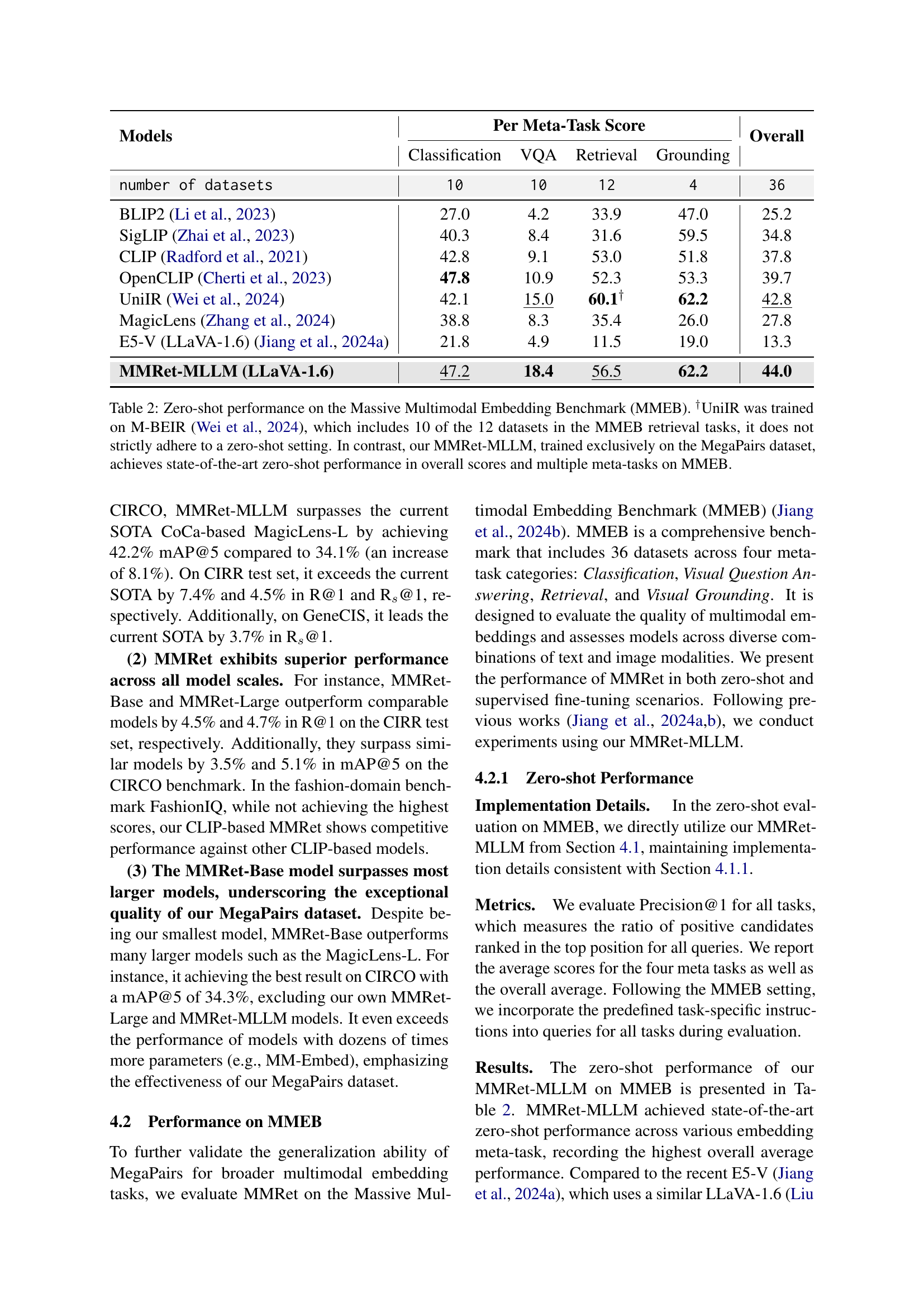
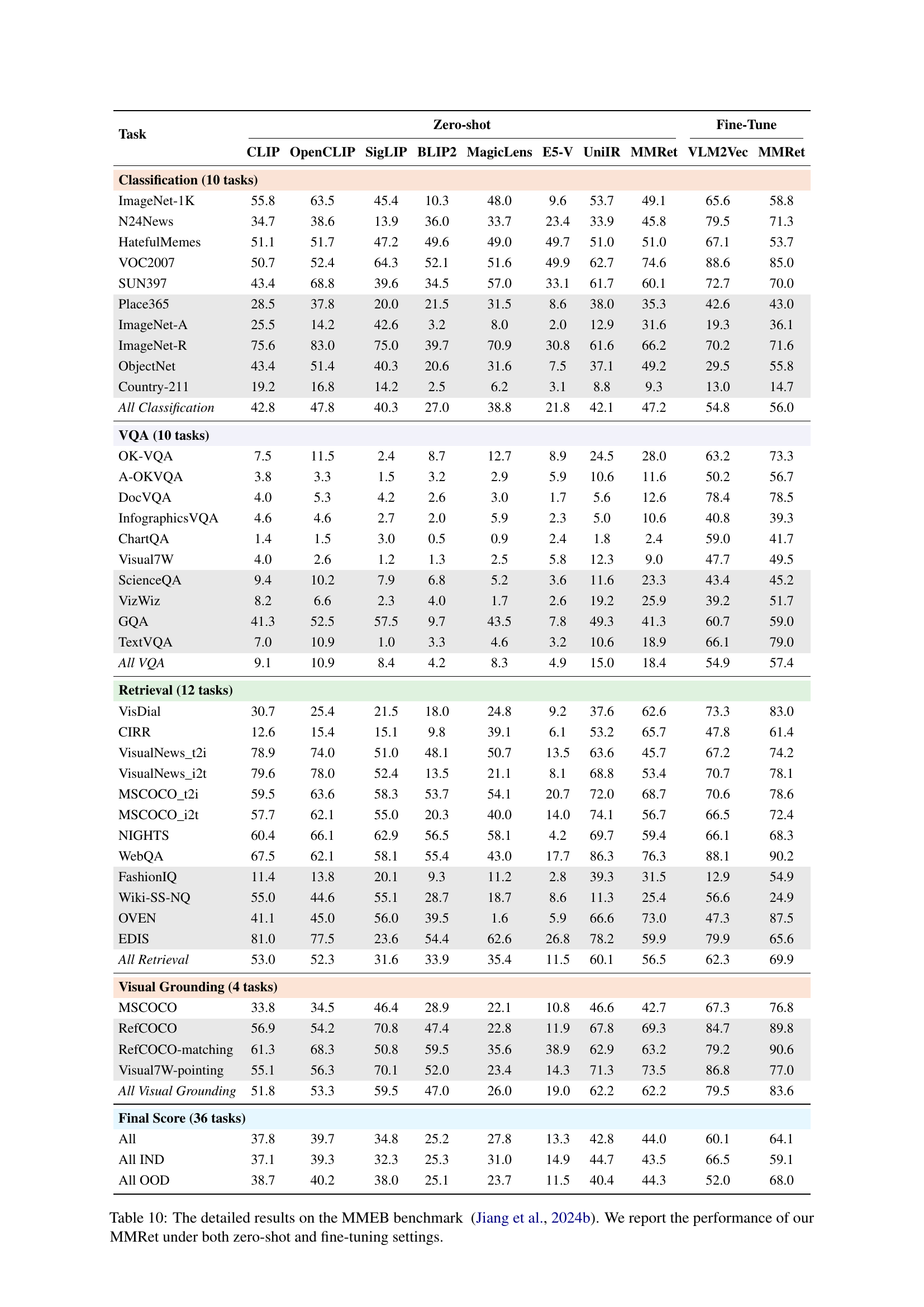
MMEB Benchmarking#
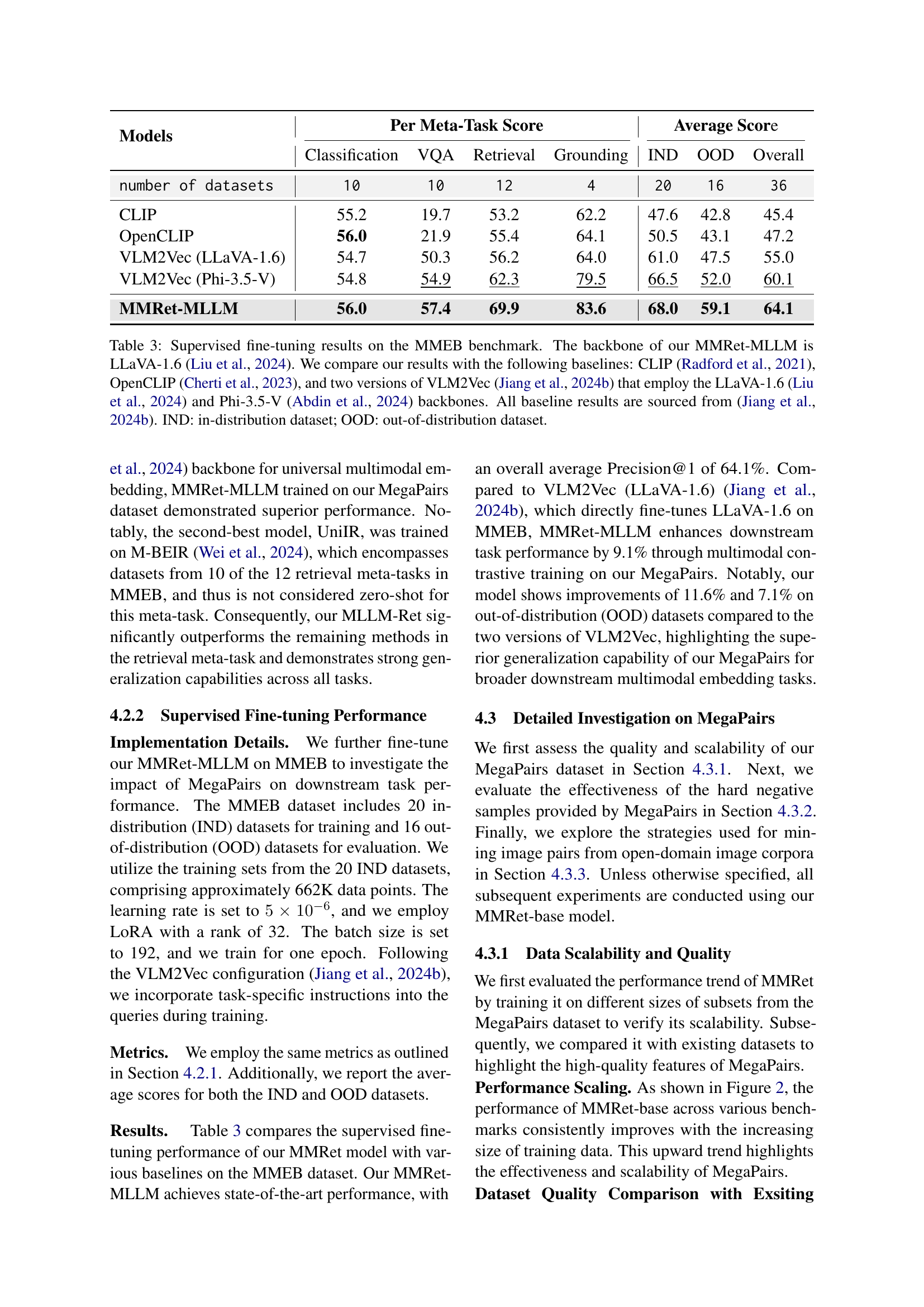
The MMEB (Massive Multimodal Embedding Benchmark) evaluation is crucial for assessing the generalization capabilities of multimodal models. A strong performance on MMEB suggests a model’s ability to handle diverse tasks and data distributions across various modalities. The benchmark’s design, encompassing four meta-tasks (classification, VQA, retrieval, grounding) and a wide array of datasets, ensures comprehensive evaluation. Analyzing results across these diverse tasks reveals a model’s strengths and weaknesses. Zero-shot performance is especially insightful, demonstrating a model’s ability to adapt without task-specific fine-tuning, showing inherent knowledge. Comparing zero-shot to fine-tuned results highlights the impact of training data and the model’s capacity for learning. State-of-the-art (SOTA) comparisons are essential to understand a model’s position within the research field. The MMEB results provide a holistic view, enabling a deep understanding of a model’s performance beyond individual metrics, crucial for the advancement of the multimodal retrieval field. Focusing on areas where the model lags provides important directions for future improvements.
Future Work and Limits#
Future research directions stemming from the MegaPairs paper could explore more sophisticated methods for generating diverse and high-quality image pairs. Leveraging more advanced vision-language models and incorporating diverse image retrieval techniques would significantly enhance the quality and realism of the synthetic data, potentially mitigating the current limitations in data diversity and the risk of monotonous relationships between synthesized images. Moreover, exploring alternative methods for generating instruction-tuning data, beyond the current two-step process, might yield better results. Investigating the effectiveness of different prompting strategies and incorporating more nuanced descriptions of the image relationships could enhance the quality and informativeness of the synthetic instructions. Finally, a critical limitation is the reliance on open-source VLMs and LLMs; this restricts access to proprietary models and the potential for superior performance if such models were available. Future work should assess the impact of using more powerful models and investigate techniques to leverage the strengths of both open-source and proprietary models to improve performance while remaining cost-effective.
More visual insights#
More on figures

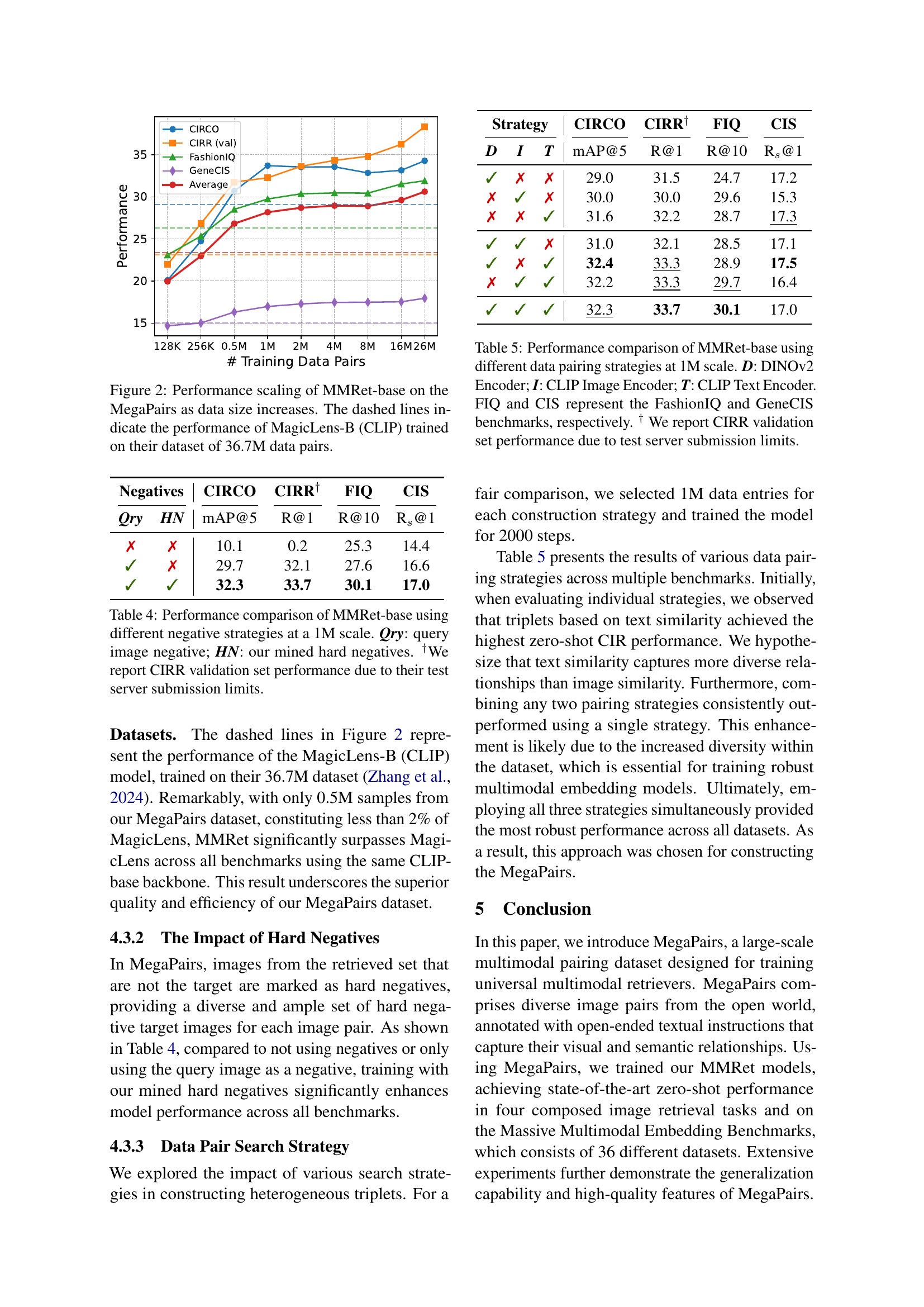
🔼 This figure demonstrates the performance scaling of the MMRet-base model as the size of the MegaPairs training dataset increases. The x-axis represents the number of training data pairs used, while the y-axis shows the model’s performance across four different benchmarks (CIRCO, CIRR, FashionIQ, and GeneCIS). The solid lines depict the performance of MMRet-base trained on various subsets of MegaPairs, showcasing improved performance with more data. For comparison, dashed lines show the performance of the MagicLens-B (CLIP) model, trained on a much larger dataset (36.7M pairs). This comparison highlights the effectiveness of MegaPairs, as MMRet-base trained on a small subset of MegaPairs outperforms MagicLens-B, which was trained on a significantly larger dataset. The figure visually illustrates that MegaPairs, despite being a much smaller dataset, leads to superior zero-shot performance.
read the caption
Figure 2: Performance scaling of MMRet-base on the MegaPairs as data size increases. The dashed lines indicate the performance of MagicLens-B (CLIP) trained on their dataset of 36.7M data pairs.

🔼 This figure details the prompts used for the Multimodal Large Language Model (MLLM) during the data synthesis process. The MLLM receives a pair of images and is tasked with generating a detailed description highlighting commonalities and differences between them. The prompt structure is designed to encourage diverse and nuanced descriptions by allowing for flexibility in word count (WORD_NUM ranging from 60 to 100 words). This variability helps create a richer and more varied instruction dataset.
read the caption
Figure 3: The specific prompts for MLLM. The value of WORD_NUM ranges from 60 to 100 in our practical data generation to enhance the diversity of the generated description.

🔼 Figure 4 details the prompts used for the large language model (LLM) in the MegaPairs data synthesis pipeline. The caption highlights that while only two examples are shown, in practice, five demonstrations were randomly selected from a pool of 50 and used to prompt the LLM. This ensured diversity and quality in the generated instructions, which described the relationships between pairs of images. The instructions are crucial for creating the final dataset used to train the multimodal retrieval models.
read the caption
Figure 4: The specific prompts for LLM. The figure showcases two demonstrations, while in our practical data generation process, five demonstrations are randomly selected from a pool of 50 and fed into the LLM.

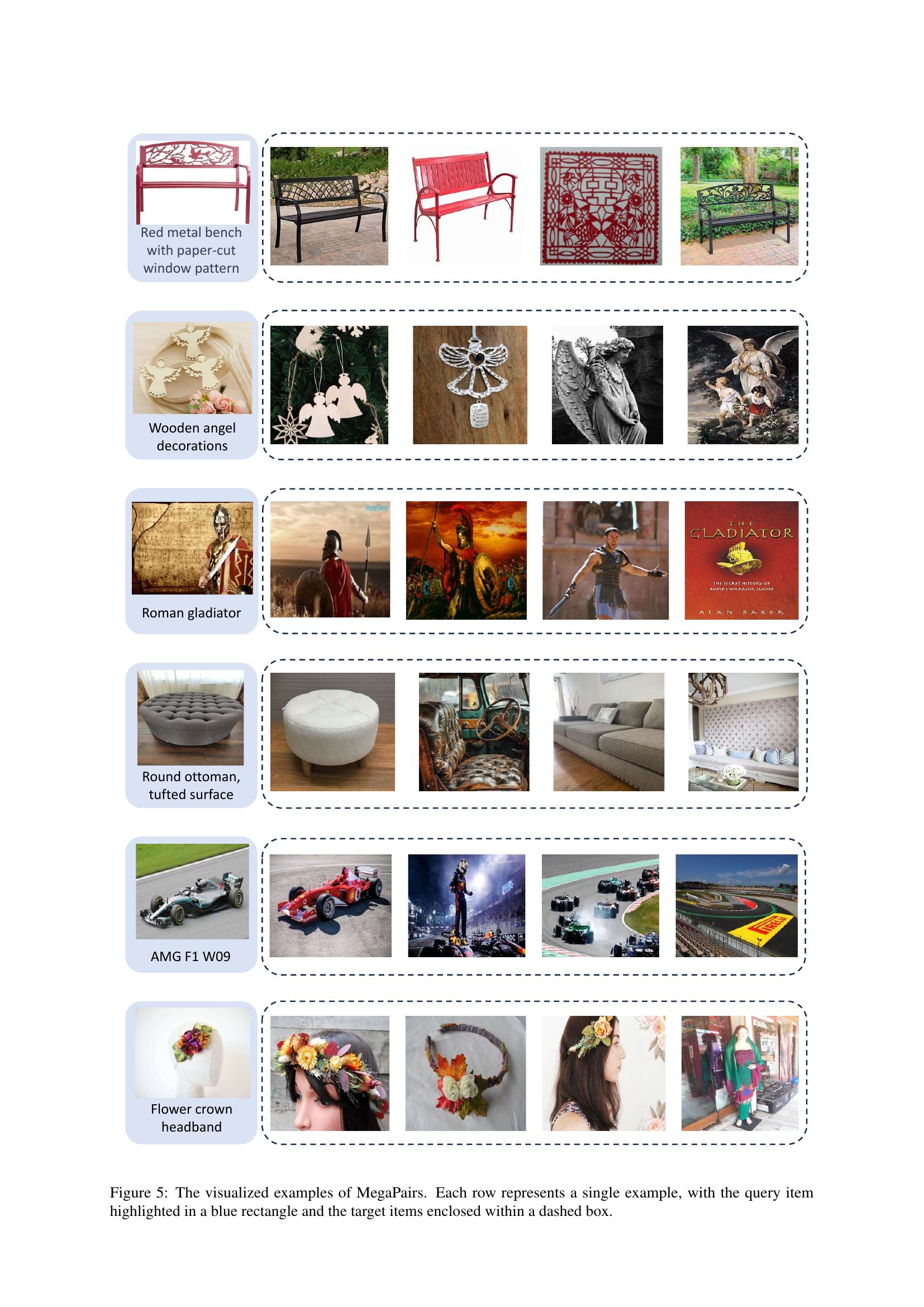
🔼 Figure 5 presents several examples from the MegaPairs dataset. Each row showcases a single example: a query (an image paired with its alt-text description, highlighted by a blue rectangle) and its associated target images (enclosed in dashed boxes). The target images demonstrate diversity, including those visually similar to the query and those semantically related but visually distinct. This visual representation illustrates the varied relationships captured within the MegaPairs dataset, highlighting its capacity to encompass both visual and semantic similarity.
read the caption
Figure 5: The visualized examples of MegaPairs. Each row represents a single example, with the query item highlighted in a blue rectangle and the target items enclosed within a dashed box.

🔼 Figure 6 presents a comparative analysis of the top 5 image retrieval results for both MMRet and MagicLens models. Both models used the CLIP-L backbone for a zero-shot cross-modal image retrieval (CIR) task. Each row showcases a different query, with the query text displayed on a blue background. The retrieved images are presented, with the most relevant images (considered correct by human evaluation) highlighted by green outlines. This visual comparison allows for a direct assessment of the retrieval accuracy and the relative strengths of the two models in handling various query scenarios.
read the caption
Figure 6: Top-5 retrieved images of MMRet and MagicLens on zero-shot CIR tasks, both using the CLIP-L backbone. Queries are shown with a blue background, and the most correct retrieved images are marked with green outlines.
Full paper#