↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) are powerful, but their performance suffers when trained on noisy data, a common problem in real-world applications. Current methods for handling noise in LLM fine-tuning are inadequate, especially for open-ended text generation tasks. This leads to unreliable model outputs and limits the practical use of LLMs.
The paper introduces ROBUSTFT, a new framework that effectively addresses this issue. ROBUSTFT uses a multi-expert system for noise detection and a context-enhanced strategy for relabeling noisy data. It also incorporates an entropy-based data selection mechanism to keep only high-quality samples. Experiments show that ROBUSTFT significantly improves LLM performance on various downstream tasks, even with high levels of noise in the training data, making it a valuable tool for building more robust and reliable LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because noisy data is a pervasive problem in real-world LLM applications and this work directly addresses it. The proposed method, ROBUSTFT, offers a novel approach to enhance the robustness of LLM fine-tuning. This has significant implications for improving the reliability and performance of LLMs across diverse downstream tasks, making the research highly relevant to the current focus on reliable and safe AI.
Visual Insights#

🔼 The figure illustrates how increasing noise in training data significantly reduces the performance of Large Language Models (LLMs) after supervised fine-tuning (SFT). The x-axis represents the percentage of noise in the training data, while the y-axis shows the resulting performance on the MMLU benchmark. As noise increases from 30% to 70%, the LLM’s performance on MMLU drops substantially, emphasizing the need for developing noise-robust fine-tuning techniques.
read the caption
Figure 1: Impact of noisy data on LLM performance during SFT. Increasing noise levels deteriorates model performance, highlighting the critical need for noise-robust fine-tuning approaches.
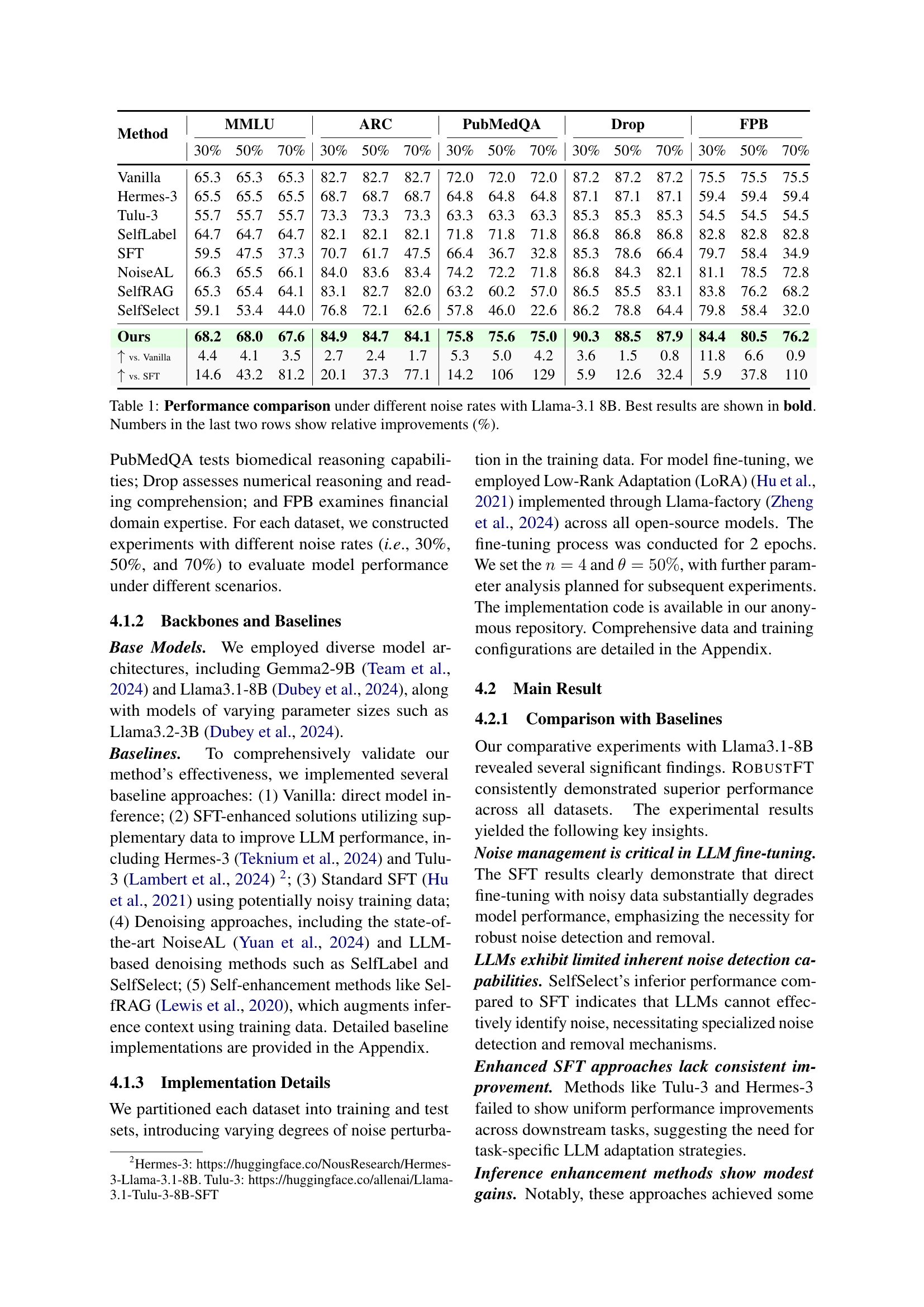
| Method | MMLU (30%) | MMLU (50%) | MMLU (70%) | ARC (30%) | ARC (50%) | ARC (70%) | PubMedQA (30%) | PubMedQA (50%) | PubMedQA (70%) | Drop (30%) | Drop (50%) | Drop (70%) | FPB (30%) | FPB (50%) | FPB (70%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vanilla | 65.3 | 65.3 | 65.3 | 82.7 | 82.7 | 82.7 | 72.0 | 72.0 | 72.0 | 87.2 | 87.2 | 87.2 | 75.5 | 75.5 | 75.5 |
| Hermes-3 | 65.5 | 65.5 | 65.5 | 68.7 | 68.7 | 68.7 | 64.8 | 64.8 | 64.8 | 87.1 | 87.1 | 87.1 | 59.4 | 59.4 | 59.4 |
| Tulu-3 | 55.7 | 55.7 | 55.7 | 73.3 | 73.3 | 73.3 | 63.3 | 63.3 | 63.3 | 85.3 | 85.3 | 85.3 | 54.5 | 54.5 | 54.5 |
| SelfLabel | 64.7 | 64.7 | 64.7 | 82.1 | 82.1 | 82.1 | 71.8 | 71.8 | 71.8 | 86.8 | 86.8 | 86.8 | 82.8 | 82.8 | 82.8 |
| SFT | 59.5 | 47.5 | 37.3 | 70.7 | 61.7 | 47.5 | 66.4 | 36.7 | 32.8 | 85.3 | 78.6 | 66.4 | 79.7 | 58.4 | 34.9 |
| NoiseAL | 66.3 | 65.5 | 66.1 | 84.0 | 83.6 | 83.4 | 74.2 | 72.2 | 71.8 | 86.8 | 84.3 | 82.1 | 81.1 | 78.5 | 72.8 |
| SelfRAG | 65.3 | 65.4 | 64.1 | 83.1 | 82.7 | 82.0 | 63.2 | 60.2 | 57.0 | 86.5 | 85.5 | 83.1 | 83.8 | 76.2 | 68.2 |
| SelfSelect | 59.1 | 53.4 | 44.0 | 76.8 | 72.1 | 62.6 | 57.8 | 46.0 | 22.6 | 86.2 | 78.8 | 64.4 | 79.8 | 58.4 | 32.0 |
| Ours | 68.2 | 68.0 | 67.6 | 84.9 | 84.7 | 84.1 | 75.8 | 75.6 | 75.0 | 90.3 | 88.5 | 87.9 | 84.4 | 80.5 | 76.2 |
| ↑ vs. Vanilla | 4.4 | 4.1 | 3.5 | 2.7 | 2.4 | 1.7 | 5.3 | 5.0 | 4.2 | 3.6 | 1.5 | 0.8 | 11.8 | 6.6 | 0.9 |
| ↑ vs. SFT | 14.6 | 43.2 | 81.2 | 20.1 | 37.3 | 77.1 | 14.2 | 106 | 129 | 5.9 | 12.6 | 32.4 | 5.9 | 37.8 | 110 |
🔼 This table presents a performance comparison of different methods for fine-tuning a Llama-3.1 8B language model under varying levels of noise in the training data. The methods compared include a vanilla approach (no fine-tuning), standard supervised fine-tuning (SFT), several noise-robust SFT approaches (NoiseAL, SelfRAG, SelfSelect), and the proposed ROBUSTFT method. Performance is evaluated across five downstream tasks (MMLU, ARC, PubMedQA, Drop, and FPB) using three noise levels (30%, 50%, and 70% noisy data). The best performance for each condition is highlighted in bold, and the last two rows quantify the relative improvement of each method compared to the Vanilla and SFT baselines.
read the caption
Table 1: Performance comparison under different noise rates with Llama-3.1 8B. Best results are shown in bold. Numbers in the last two rows show relative improvements (%).
In-depth insights#
Noisy SFT Challenges#
The heading “Noisy SFT Challenges” highlights the critical issues arising from the presence of noise in data used for supervised fine-tuning (SFT) of large language models (LLMs). Noise, inherent in real-world data, stems from various sources such as human annotation errors, model hallucinations, and data inconsistencies. This noise significantly impacts the performance of LLMs on downstream tasks, leading to accuracy degradation and unreliable outputs. Addressing these challenges requires robust methods capable of detecting and mitigating the effects of noise. Strategies to improve noise robustness include multi-expert collaborative systems for noise detection, context-enhanced reasoning to improve data quality, and data selection techniques to retain high-confidence samples for fine-tuning. This is crucial because traditional relabeling strategies often prove insufficient in the context of open-ended text generation tasks, a common application of LLMs. Overcoming these challenges is essential for ensuring that LLMs achieve reliable performance in real-world applications, given the inherent presence of noise in practical data collection and annotation processes. Therefore, research into noise-robust SFT is vital for enabling the successful and safe deployment of LLMs in various domains.
Multi-Expert Denoising#
A hypothetical ‘Multi-Expert Denoising’ section in a research paper on improving Large Language Model (LLM) training with noisy data would likely detail a system using multiple LLMs to collaboratively identify and correct noisy data points. This approach leverages the strengths of diverse models, reducing reliance on a single model’s potentially flawed judgment. The core idea involves consensus-based decision-making: if multiple LLMs independently flag a data point as noisy, it’s treated as such. This process improves the accuracy of noise detection compared to relying on a single LLM’s subjective assessment. The section would also describe the denoising process itself, which may involve techniques like context-enhanced relabeling using the most confident, reliable LLM predictions as references for cleaning the noisy samples, and data selection strategies, perhaps using response entropy or similar metrics to only retain high-quality examples for retraining. The effectiveness of this multi-expert system would be evaluated experimentally, comparing its denoising accuracy and downstream LLM performance improvements against single-expert or traditional methods. The results would demonstrate the benefits of collaboration for robust noise handling in LLM training.
Entropy-Based Selection#
Entropy-based selection, in the context of noisy data handling for fine-tuning large language models (LLMs), is a crucial technique for enhancing data quality. It leverages the inherent uncertainty, quantified by entropy, associated with model predictions. Higher entropy indicates lower confidence in the model’s prediction, suggesting the presence of noise or ambiguity. By filtering out samples with high entropy, the method retains only the most confident predictions, ensuring that the fine-tuning process is focused on high-quality, reliable data points. This selective approach not only mitigates the negative impact of noise but also improves the efficiency of the fine-tuning, preventing the model from learning spurious patterns from unreliable data, leading to enhanced downstream performance. The threshold for determining high or low entropy is a crucial parameter that often needs careful tuning to find an optimal balance between maintaining a sufficient amount of data for training and rejecting noisy instances. The effectiveness of entropy-based selection heavily relies on the reliability of the model’s probability estimates. If the model itself is significantly prone to errors, the entropy measure might not accurately reflect the true uncertainty in the data.
Cross-LLM Robustness#
Cross-LLM robustness examines how effectively a model trained on one large language model (LLM) generalizes to others. A robust model should perform well regardless of the underlying LLM architecture, showcasing its inherent capabilities rather than relying on specific LLM characteristics. This is critical because LLMs are constantly evolving, and a system dependent on a single LLM risks obsolescence. Research in this area focuses on identifying factors that contribute to cross-LLM inconsistencies, such as differences in training data, architectural variations, and inherent biases. Strategies for improving cross-LLM robustness often involve techniques that enhance the model’s generalization ability, reducing its reliance on idiosyncrasies of a specific LLM. Methods might include careful data augmentation, regularization methods, or the use of more generalizable feature representations. This is an important area of investigation to increase the reliability and longevity of LLM-based systems.
Future Noise Research#
Future research in noise robustness for LLMs should prioritize several key areas. Developing more sophisticated noise detection mechanisms is crucial, moving beyond simple consistency checks to incorporate contextual understanding and nuanced analysis of model confidence. This includes exploring techniques from other fields like anomaly detection. Advanced denoising strategies are needed, going beyond simple relabeling to explore generative models for noise-aware data augmentation or novel data synthesis techniques that actively mitigate noise characteristics in training data. Investigating the interplay between different noise types (e.g., human annotation errors vs. model hallucinations) and their impact on downstream tasks is also important. Finally, benchmarking noise robustness needs standardization. This requires creating robust and diverse benchmark datasets with carefully controlled noise levels, allowing for rigorous comparisons of different noise-handling techniques across various LLMs and fine-tuning methods.
More visual insights#
More on figures

🔼 Figure 2 illustrates the RobustFT framework’s two-stage process for handling noisy data in downstream fine-tuning tasks. The first stage is noise detection, which uses a collaborative learning approach involving multiple expert LLMs to identify potentially noisy samples. The second stage is denoising, employing context-enhanced reasoning with cleaner samples to relabel identified noisy samples, ensuring high-quality data for subsequent fine-tuning. The process improves overall model robustness and performance on downstream tasks.
read the caption
Figure 2: Overview of RobustFT. Our RobustFT enhances model performance through a two-stage noise detection-and-denoising framework, leveraging collaborative learning among expert LLMs for noise detection and context-enhanced reasoning for data denoising, ultimately enabling robust downstream fine-tuning.

🔼 This figure presents a sensitivity analysis of the ROBUSTFT model’s performance on the MMLU benchmark under different noise levels. It investigates the impact of two hyperparameters: β (beta), which controls the selection ratio of confident samples after the denoising process, and k, representing the number of context samples used in the context-enhanced reasoning for data relabeling. The analysis examines how the accuracy changes across various combinations of these hyperparameters and noise levels (30%, 50%, and 70%), providing insights into their optimal settings for robust performance.
read the caption
Figure 3: Sensitivity analysis on MMLU under different β𝛽\betaitalic_β and k𝑘kitalic_k with varying noise levels.

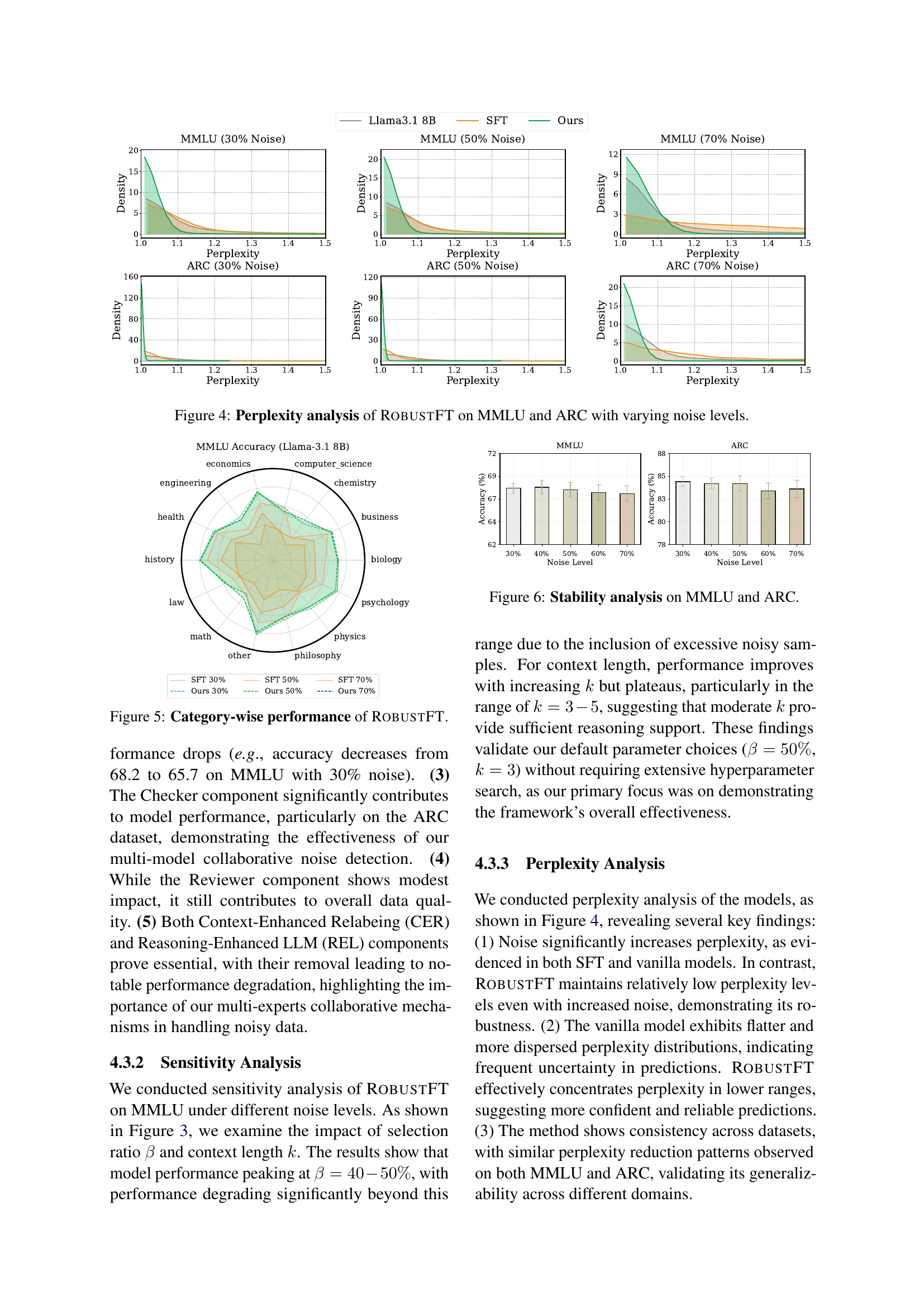
🔼 This figure displays the perplexity scores generated by the RobustFT model and the standard supervised fine-tuning (SFT) model on the MMLU and ARC datasets at various noise levels (30%, 50%, and 70%). Perplexity is a measure of how well a probability model predicts a sample. Lower perplexity indicates better prediction and therefore less uncertainty by the model. The figure illustrates how the RobustFT model maintains lower perplexity scores compared to the SFT model, especially as noise levels increase. This demonstrates RobustFT’s ability to handle noisy data effectively and generate more confident predictions.
read the caption
Figure 4: Perplexity analysis of RobustFT on MMLU and ARC with varying noise levels.

🔼 This figure shows a radar chart comparing the performance of RobustFT and standard SFT across various categories within the MMLU benchmark dataset under different noise levels (30%, 50%, and 70%). Each axis represents a category (e.g., economics, computer science, health, etc.), and the length of each line from the center indicates the model’s accuracy in that specific category. The chart visually demonstrates RobustFT’s superior and more consistent performance compared to the standard SFT approach across all categories, especially when dealing with noisy data. It highlights RobustFT’s ability to maintain accuracy in multiple domains compared to SFT, which shows significant drops in performance.
read the caption
Figure 5: Category-wise performance of RobustFT.

🔼 This figure displays the results of a stability analysis performed on the MMLU and ARC datasets. The analysis assesses the robustness of the ROBUSTFT model to variations in input instructions by rephrasing them five times using GPT-4. The figure shows the mean accuracy and standard deviation for both datasets across various noise levels (30%, 50%, 70%), demonstrating the model’s consistent performance even with instruction variations.
read the caption
Figure 6: Stability analysis on MMLU and ARC.
More on tables
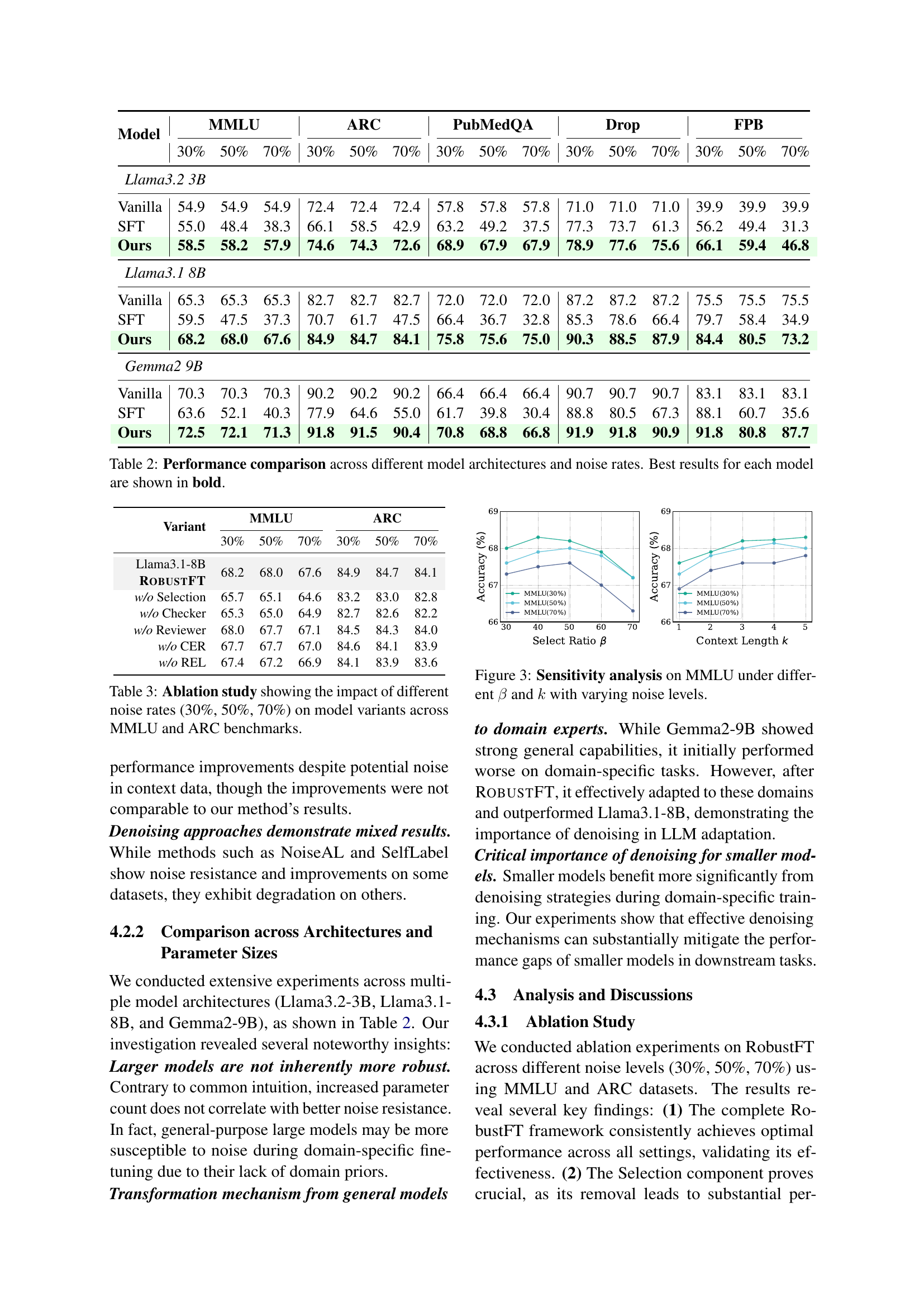
| Model | MMLU 30% | MMLU 50% | MMLU 70% | ARC 30% | ARC 50% | ARC 70% | PubMedQA 30% | PubMedQA 50% | PubMedQA 70% | Drop 30% | Drop 50% | Drop 70% | FPB 30% | FPB 50% | FPB 70% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama3.2 3B | ||||||||||||||||
| Vanilla | 54.9 | 54.9 | 54.9 | 72.4 | 72.4 | 72.4 | 57.8 | 57.8 | 57.8 | 71.0 | 71.0 | 71.0 | 39.9 | 39.9 | 39.9 | |
| SFT | 55.0 | 48.4 | 38.3 | 66.1 | 58.5 | 42.9 | 63.2 | 49.2 | 37.5 | 77.3 | 73.7 | 61.3 | 56.2 | 49.4 | 31.3 | |
| Ours | 58.5 | 58.2 | 57.9 | 74.6 | 74.3 | 72.6 | 68.9 | 67.9 | 67.9 | 78.9 | 77.6 | 75.6 | 66.1 | 59.4 | 46.8 | |
| Llama3.1 8B | ||||||||||||||||
| Vanilla | 65.3 | 65.3 | 65.3 | 82.7 | 82.7 | 82.7 | 72.0 | 72.0 | 72.0 | 87.2 | 87.2 | 87.2 | 75.5 | 75.5 | 75.5 | |
| SFT | 59.5 | 47.5 | 37.3 | 70.7 | 61.7 | 47.5 | 66.4 | 36.7 | 32.8 | 85.3 | 78.6 | 66.4 | 79.7 | 58.4 | 34.9 | |
| Ours | 68.2 | 68.0 | 67.6 | 84.9 | 84.7 | 84.1 | 75.8 | 75.6 | 75.0 | 90.3 | 88.5 | 87.9 | 84.4 | 80.5 | 73.2 | |
| Gemma2 9B | ||||||||||||||||
| Vanilla | 70.3 | 70.3 | 70.3 | 90.2 | 90.2 | 90.2 | 66.4 | 66.4 | 66.4 | 90.7 | 90.7 | 90.7 | 83.1 | 83.1 | 83.1 | |
| SFT | 63.6 | 52.1 | 40.3 | 77.9 | 64.6 | 55.0 | 61.7 | 39.8 | 30.4 | 88.8 | 80.5 | 67.3 | 88.1 | 60.7 | 35.6 | |
| Ours | 72.5 | 72.1 | 71.3 | 91.8 | 91.5 | 90.4 | 70.8 | 68.8 | 66.8 | 91.9 | 91.8 | 90.9 | 91.8 | 80.8 | 87.7 |
🔼 This table presents a comparison of the performance of three different large language models (LLMs) - Llama 3.2 3B, Llama 3.1 8B, and Gemma2 9B - across various downstream tasks. The performance is evaluated under three different noise levels (30%, 50%, and 70%) in the training data. For each LLM and noise level, the table shows the accuracy achieved by a vanilla (untuned) model, a model fine-tuned using supervised fine-tuning (SFT), and a model fine-tuned using the proposed ROBUSTFT method. The best result for each model configuration is highlighted in bold, allowing for a direct comparison of the effectiveness of each approach under different conditions.
read the caption
Table 2: Performance comparison across different model architectures and noise rates. Best results for each model are shown in bold.
| Variant | MMLU 30% | MMLU 50% | MMLU 70% | ARC 30% | ARC 50% | ARC 70% |
|---|---|---|---|---|---|---|
| Llama3.1-8B | ||||||
| RobustFT | 68.2 | 68.0 | 67.6 | 84.9 | 84.7 | 84.1 |
| w/o Selection | 65.7 | 65.1 | 64.6 | 83.2 | 83.0 | 82.8 |
| w/o Checker | 65.3 | 65.0 | 64.9 | 82.7 | 82.6 | 82.2 |
| w/o Reviewer | 68.0 | 67.7 | 67.1 | 84.5 | 84.3 | 84.0 |
| w/o CER | 67.7 | 67.7 | 67.0 | 84.6 | 84.1 | 83.9 |
| w/o REL | 67.4 | 67.2 | 66.9 | 84.1 | 83.9 | 83.6 |
🔼 This ablation study analyzes the performance of different ROBUSTFT model variants on the MMLU and ARC benchmarks under varying levels of noise (30%, 50%, and 70%). It shows the impact of removing or modifying key components of the ROBUSTFT framework (such as the data selection mechanism, the noise detection component, the denoising mechanism, and the review agent), providing insights into the contributions of each part to the overall robustness and performance of the model in handling noisy data.
read the caption
Table 3: Ablation study showing the impact of different noise rates (30%, 50%, 70%) on model variants across MMLU and ARC benchmarks.
Full paper#