↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current large language models (LLMs) struggle with complex coding tasks due to issues like unreliability and inconsistent performance. Existing process supervision methods, while showing promise, often require extensive human-annotated data and suffer from unreliable evaluation, limiting their effectiveness. Furthermore, these models often fail to self-correct or self-validate, highlighting a need for improved techniques.
This paper introduces Outcome-Refining Process Supervision (ORPS), a novel paradigm that leverages concrete execution signals to supervise reasoning steps. ORPS uses a tree-structured exploration space to maintain multiple solution trajectories and incorporates execution feedback for verification. Experimental results demonstrate that ORPS enables even smaller LLMs to achieve high accuracy and performance on competitive programming tasks. It surpasses the performance of existing methods across various models and datasets, highlighting the effectiveness of integrating execution feedback into process supervision for code generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Outcome-Refining Process Supervision (ORPS), a novel framework for code generation that significantly improves the accuracy and efficiency of code generation, especially for complex tasks. It addresses the limitations of existing methods by leveraging execution feedback and structured reasoning, offering a more reliable and scalable approach. This work opens new avenues for research in process supervision, prompting, and code generation, potentially leading to more robust and efficient AI systems.
Visual Insights#

🔼 This figure compares three different approaches to code generation: Outcome Supervision, Process Supervision, and Outcome-Refining Process Supervision (the authors’ proposed method). Outcome supervision uses only the final output to guide the model. Process supervision utilizes intermediate reasoning steps evaluated by a Process Reward Model (PRM). The authors’ method combines both, using concrete execution signals from code execution to directly ground the supervision of reasoning steps, thus avoiding the need for training PRMs and improving reliability. The figure illustrates the differences in model training, feedback mechanisms, and evaluation.
read the caption
Figure 1: Comparison of code generation paradigms.
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
|---|---|---|---|---|
| Llama-3.1-8B-Instruct (2024) CoT | 30.9 | 44.3 | 63.0 | 176.8 |
| Llama-3.1-8B-Instruct (2024) Reflexion | 34.0 | 49.3 | 67.3 | 148.5 |
| Llama-3.1-8B-Instruct (2024) LDB (w/ T) | 25.9 | 39.8 | 58.0 | 252.2 |
| Llama-3.1-8B-Instruct (2024) BoN | 46.9 | 64.7 | 84.6 | 107.6 |
| Llama-3.1-8B-Instruct (2024) ORPS | 45.9 | 66.9 | 88.5 | 99.1 |
| Llama-3.1-8B-Instruct (2024) ORPS (w/ T) | 67.1 | 81.4 | 93.7 | 89.4 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) CoT | 32.7 | 45.9 | 67.3 | 160.1 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) Reflexion | 25.9 | 41.9 | 63.0 | 153.0 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) LDB (w/ T) | 31.5 | 45.7 | 61.7 | 206.2 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) BoN | 49.4 | 63.9 | 80.2 | 123.4 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) ORPS | 56.3 | 71.1 | 88.0 | 89.4 |
| DeepSeek-Coder-7B-Instruct-v1.5 (2024) ORPS (w/ T) | 63.7 | 80.8 | 96.9 | 74.4 |
| Qwen-2.5-Coder-7B-Instruct (2024) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
| Qwen-2.5-Coder-7B-Instruct (2024) CoT | 40.1 | 55.3 | 72.2 | 118.6 |
| Qwen-2.5-Coder-7B-Instruct (2024) Reflexion | 37.7 | 57.1 | 78.4 | 111.2 |
| Qwen-2.5-Coder-7B-Instruct (2024) LDB (w/ T) | 35.8 | 49.9 | 65.4 | 187.8 |
| Qwen-2.5-Coder-7B-Instruct (2024) BoN | 53.1 | 68.8 | 85.8 | 117.9 |
| Qwen-2.5-Coder-7B-Instruct (2024) ORPS | 59.9 | 75.7 | 92.0 | 84.1 |
| Qwen-2.5-Coder-7B-Instruct (2024) ORPS (w/ T) | 77.8 | 87.9 | 96.9 | 82.4 |
| Qwen-2.5-Coder-14B-Instruct (2024) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
| Qwen-2.5-Coder-14B-Instruct (2024) CoT | 53.7 | 63.9 | 77.2 | 119.2 |
| Qwen-2.5-Coder-14B-Instruct (2024) Reflexion | 60.5 | 70.5 | 82.1 | 113.3 |
| Qwen-2.5-Coder-14B-Instruct (2024) LDB (w/ T) | 51.9 | 62.9 | 75.3 | 225.2 |
| Qwen-2.5-Coder-14B-Instruct (2024) BoN | 61.7 | 74.9 | 90.7 | 115.6 |
| Qwen-2.5-Coder-14B-Instruct (2024) ORPS | 61.7 | 77.4 | 90.7 | 84.8 |
| Qwen-2.5-Coder-14B-Instruct (2024) ORPS (w/ T) | 85.8 | 90.7 | 95.7 | 64.2 |
| GPT-4o-Mini (2024) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
| GPT-4o-Mini (2024) CoT | 50.0 | 65.9 | 80.2 | 124.5 |
| GPT-4o-Mini (2024) Reflexion | 62.3 | 73.9 | 87.7 | 93.2 |
| GPT-4o-Mini (2024) LDB (w/ T) | 54.9 | 67.8 | 82.7 | 220.1 |
| GPT-4o-Mini (2024) BoN | 64.2 | 78.6 | 93.8 | 88.9 |
| GPT-4o-Mini (2024) ORPS | 67.9 | 81.2 | 94.4 | 81.5 |
| GPT-4o-Mini (2024) ORPS (w/ T) | 88.9 | 94.3 | 98.1 | 61.6 |
| HumanEval (2021b) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
| MBPP (2021) | ||||
| Model/Method | Pass@1 ↑ | Tests ↑ | Valid ↑ | Time ↓ |
| — | — | — | — | — |
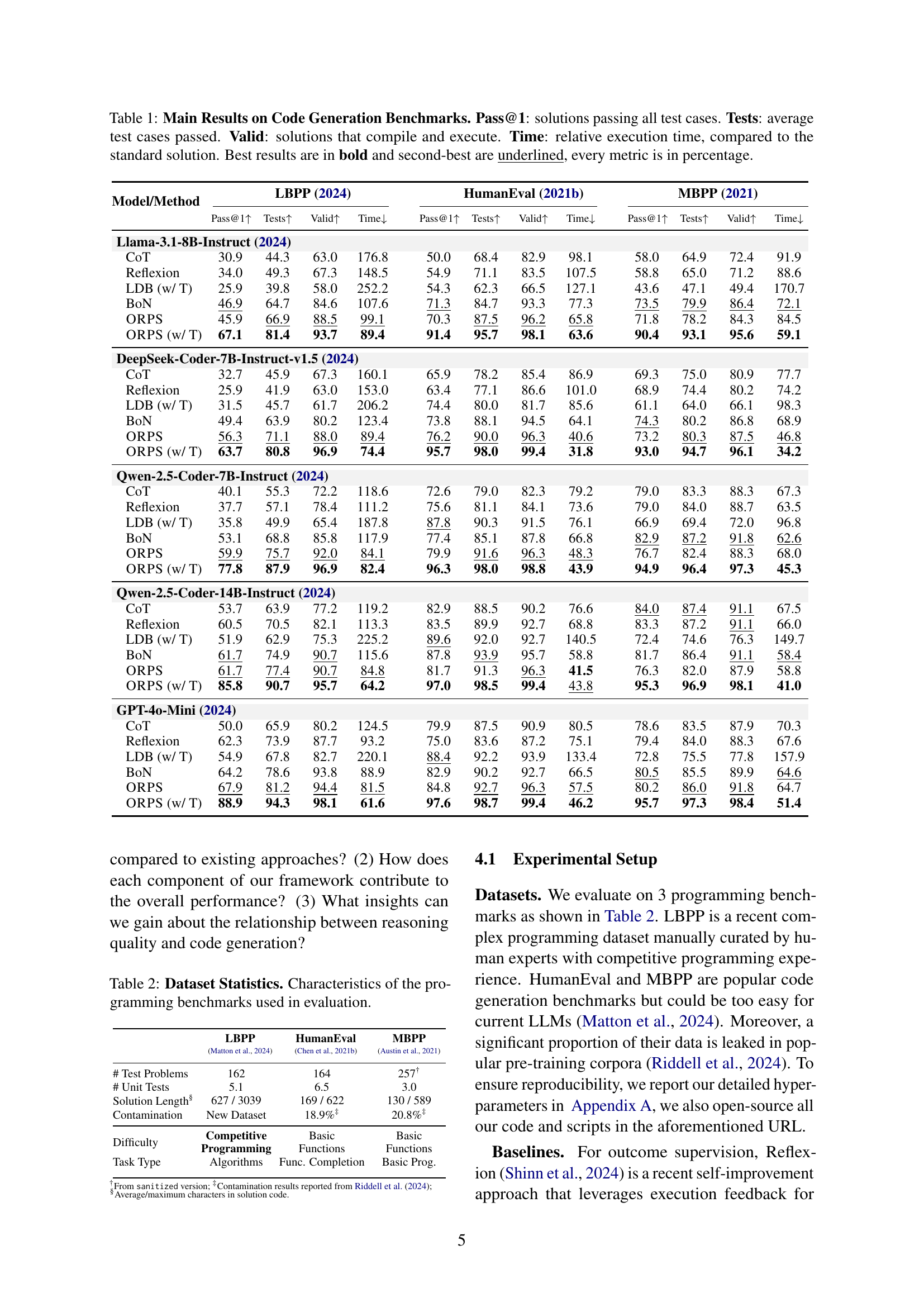
🔼 This table presents the performance of different code generation models and methods across three benchmarks: LBPP, HumanEval, and MBPP. For each model and method (including several baselines and the proposed ORPS method), the table shows the percentage of successful solutions (Pass@1), the average percentage of test cases passed, the percentage of solutions that compiled and ran successfully (Valid), and the relative execution time compared to a standard solution. The best results for each metric are bolded, and the second-best are underlined. This allows for a comparison of the effectiveness and efficiency of various code generation approaches on different types and complexities of coding tasks.
read the caption
Table 1: Main Results on Code Generation Benchmarks. Pass@1: solutions passing all test cases. Tests: average test cases passed. Valid: solutions that compile and execute. Time: relative execution time, compared to the standard solution. Best results are in bold and second-best are underlined, every metric is in percentage.
In-depth insights#
Outcome-Refining Supervision#
Outcome-refining supervision presents a novel approach to enhance code generation by integrating execution feedback directly into the process of refining outcomes. Unlike traditional methods that solely rely on final output or intermediate reasoning steps, this paradigm leverages concrete execution signals to ground the supervision of reasoning. By treating outcome refinement as the supervised process, it eliminates the need for expensive process reward models (PRMs) commonly used in process supervision. The method’s core strength lies in its ability to maintain multiple solution trajectories simultaneously through a tree-structured exploration, enabling models to discover and refine diverse solution strategies. This allows for exploration of different algorithmic approaches and avoids getting stuck in local improvements. The use of verifiable signals from code execution, in turn, creates a natural synergy with the model’s inherent reasoning capabilities. Concrete execution signals provide objective evaluation anchors, ensuring reliable verification and enhancing the model’s ability to self-correct. The outcome-refining approach represents a significant step towards creating more robust and efficient code generation models, particularly for complex programming tasks.
Execution-Driven Feedback#
Execution-driven feedback, in the context of code generation, represents a paradigm shift from traditional outcome-based evaluations. Instead of solely judging the final output’s correctness, this approach leverages the actual execution of the generated code to provide feedback. This feedback isn’t limited to a simple ‘pass’ or ‘fail’; it can encompass various metrics, including runtime, memory usage, and even the intermediate states during program execution. The key benefit lies in its objectivity and concreteness. Unlike human-annotated feedback or learned reward models, which can be subjective or prone to biases, execution-driven feedback offers verifiable signals about the code’s performance. This allows for more reliable evaluation and facilitates the identification of specific weaknesses in the code’s logic or implementation. It enables a more precise and actionable feedback loop, guiding the code generation model towards producing not just correct, but also efficient and robust code. However, it’s crucial to acknowledge that relying solely on execution-driven feedback might neglect aspects of code quality like readability and maintainability. A balanced approach, combining both execution-driven feedback and other evaluation metrics, is needed for a comprehensive assessment of code generation models.
Tree-Structured Exploration#
The concept of “Tree-Structured Exploration” in the context of code generation is a powerful approach that goes beyond linear reasoning. Instead of exploring solutions sequentially, a tree structure allows for parallel exploration of multiple solution paths. This inherent parallelism is crucial for handling complex problems where a single, linear path may easily lead to a dead end. Each node in the tree represents an intermediate state in the code generation process, branching out to explore alternative reasoning steps and code implementations. This structured approach facilitates the evaluation of different algorithmic strategies, allowing the model to identify superior solutions more efficiently. By combining this tree search with execution feedback, the model can dynamically refine its search strategy, pruning unproductive branches while expanding promising ones. The outcome is a more robust and efficient code generation process, capable of tackling complex coding tasks that would be intractable for traditional, linear methods. The use of beam search further enhances efficiency, allowing the algorithm to maintain multiple trajectories while prioritizing the most promising paths. This approach ultimately leads to improved code correctness and runtime efficiency.
Ablation Study Analysis#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a code generation model, this might involve removing execution feedback, in-depth reasoning, or the process reward model. Analyzing the results reveals the relative importance of each component. For instance, if removing execution feedback significantly reduces performance, it highlights the importance of using execution results to ground and verify the model’s reasoning. Similarly, if removing the reasoning component impacts accuracy, it shows the necessity of a structured approach for complex problem-solving. The ablation study helps to understand the model’s inner workings and the interplay between its different parts. By carefully designing and interpreting the ablation experiments, researchers can gain valuable insights about the strengths and weaknesses of their model, guiding future improvements and informing design choices. The quantitative results are crucial, showing the impact of removing each component on metrics such as accuracy and efficiency. This analysis helps to pinpoint areas for further development, refine model architecture, and ultimately enhance code generation capabilities.
Scalability and Limitations#
A research paper’s section on “Scalability and Limitations” would critically examine the system’s ability to handle increasing data volumes and complexities. Scalability would address whether the model’s performance degrades gracefully or catastrophically with larger inputs, exploring resource usage (computational time and memory) and the potential for parallelization or distributed computing. Limitations would expose inherent weaknesses. This could involve discussing the model’s sensitivity to specific data types or distributions, its vulnerability to adversarial attacks, or any failure modes under extreme conditions. The discussion should also explore the model’s generalizability beyond its training data, the ethical implications of biased outputs, and the practical challenges related to deployment and maintenance.
More visual insights#
More on figures

🔼 The figure illustrates the Outcome-Refining Process Supervision (ORPS) framework. The framework uses a language model to iteratively generate and refine code solutions. The process starts with a problem statement and the model generates an initial reasoning chain and code. This solution is then executed, and feedback is collected on its correctness. This feedback is used to guide the next steps. The framework uses beam search to explore multiple solution trajectories simultaneously. Each state in the search tree includes the reasoning process up to that point, the generated code, and an associated reward score reflecting the progress made towards a correct solution. The model acts as both programmer (generating code) and critic (evaluating and refining solutions), leading to more robust and efficient code generation.
read the caption
Figure 2: Outcome-Refining Process Supervision framework overview. A language model serves as both programmer and critic in a step-by-step reasoning process. Through beam search, the framework maintains multiple solution trajectories, where each state contains reasoning chains, code implementations, and step reward.

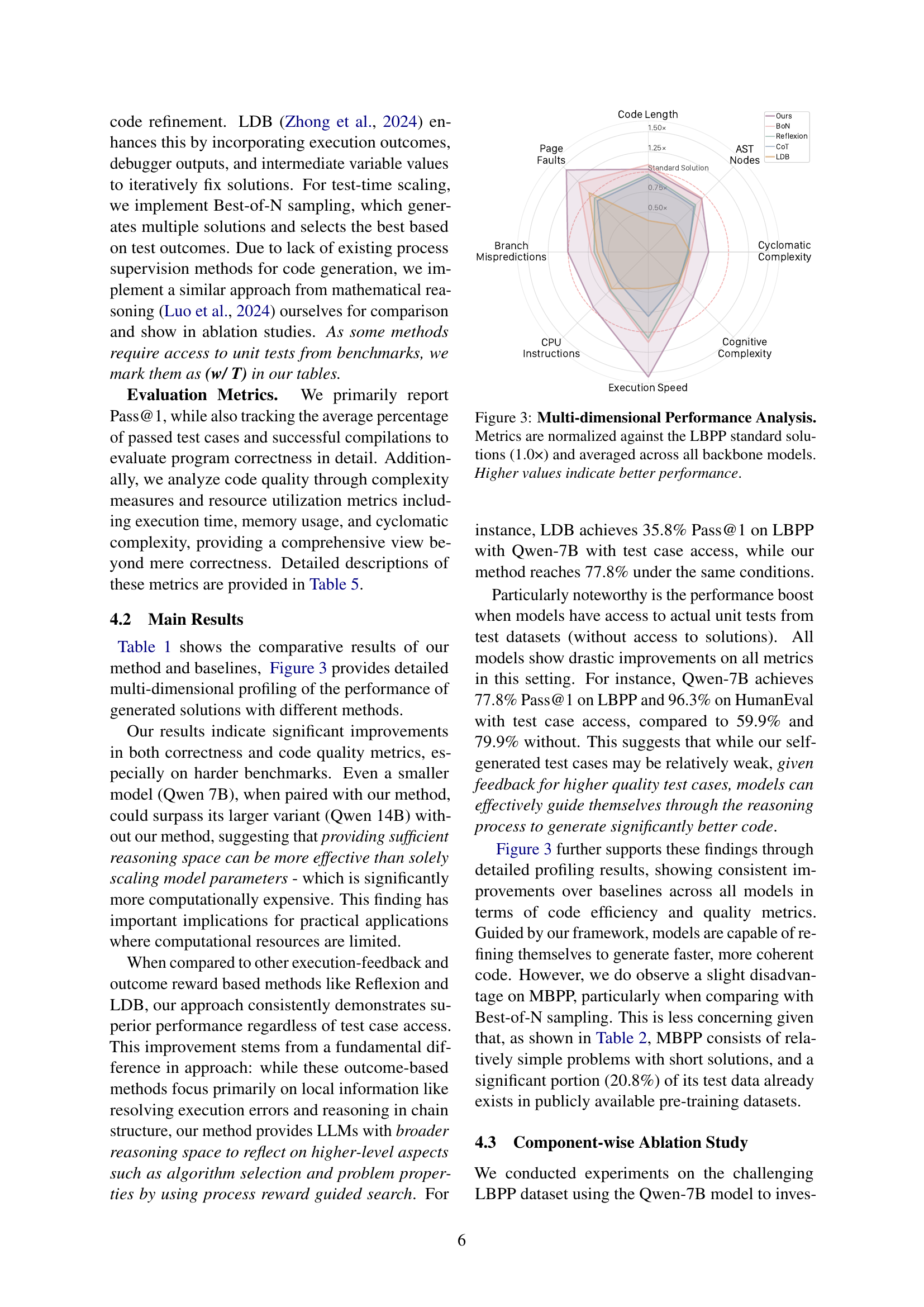
🔼 This figure presents a multi-dimensional performance comparison of different code generation methods on the LBPP benchmark. Each metric (code length, AST nodes, cyclomatic complexity, cognitive complexity, execution speed, branch mispredictions, page faults, and CPU instructions) is normalized relative to the standard LBPP solutions (set to 1.0x) to facilitate comparison. The results are averaged across multiple backbone models. Higher values on each metric indicate better performance, signifying improved code quality and efficiency.
read the caption
Figure 3: Multi-dimensional Performance Analysis. Metrics are normalized against the LBPP standard solutions (1.0×) and averaged across all backbone models. Higher values indicate better performance.

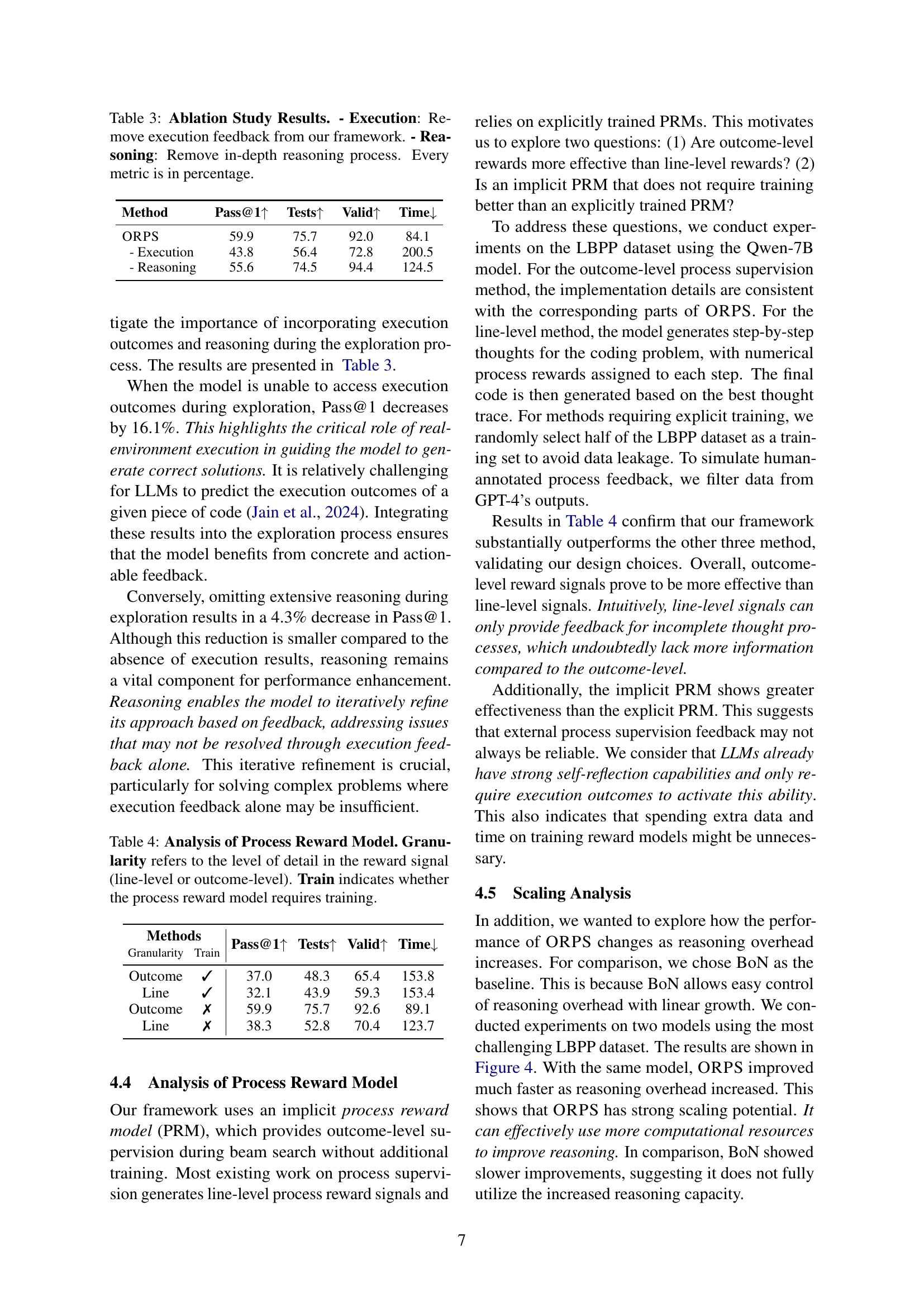
🔼 This figure demonstrates the impact of varying inference budgets on the performance of the Outcome-Refining Process Supervision (ORPS) method and baseline methods on the LBPP benchmark. The x-axis represents the inference budget, and the y-axis represents the Pass@1 score (percentage of problems where the model generates code that passes all test cases). The lines represent different model architectures. The key takeaway is that ORPS consistently outperforms baseline methods across a wide range of computational resources, showcasing its robustness and efficiency.
read the caption
Figure 4: Performance vs. Inference Budget. Pass@1 scores on LBPP with varying inference budgets. Our method maintains superior performance across different computational constraints.

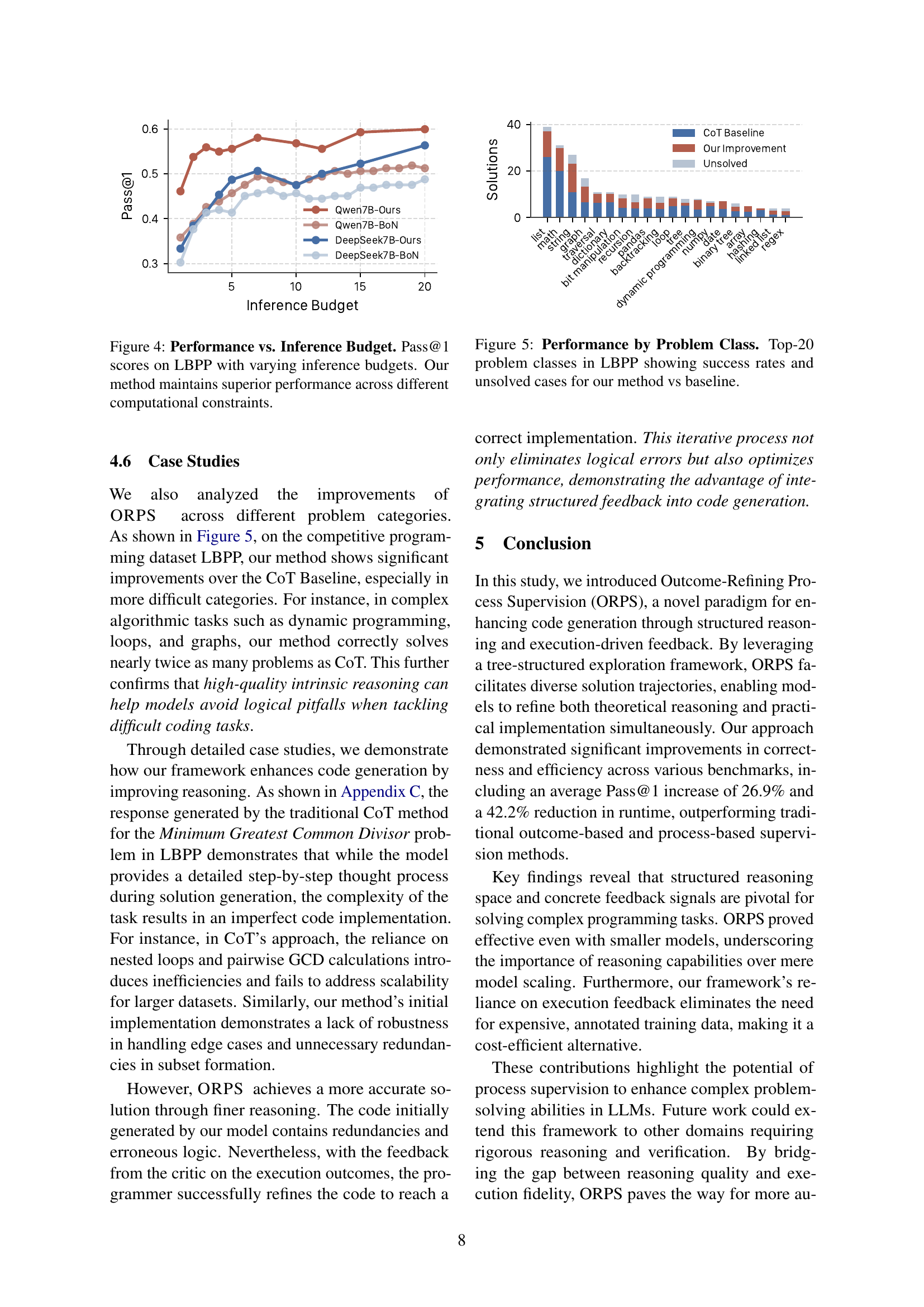
🔼 This figure compares the performance of the proposed Outcome-Refining Process Supervision (ORPS) method against a baseline method across the top 20 problem classes in the LBPP dataset. The bars represent the success rate (percentage of problems solved correctly) for each method within each problem class. It visually demonstrates the relative strengths and weaknesses of ORPS compared to the baseline, especially highlighting problem categories where ORPS shows a significant improvement or where both methods struggle.
read the caption
Figure 5: Performance by Problem Class. Top-20 problem classes in LBPP showing success rates and unsolved cases for our method vs baseline.
More on tables
🔼 This table presents a comparative overview of three programming benchmarks (LBPP, HumanEval, and MBPP) used in the paper’s evaluation. For each benchmark, it details the number of programming problems, unit tests, the average and maximum length of solution code, the percentage of code contamination (data leakage from pre-training corpora), the general difficulty level (basic or competitive), and the task type (functions, algorithms, or function completion). This information is crucial for understanding the characteristics of the datasets and how they might influence the performance of different code generation models.
read the caption
Table 2: Dataset Statistics. Characteristics of the programming benchmarks used in evaluation.
| Method | Pass@1↑ | Tests↑ | Valid↑ | Time↓ |
|---|---|---|---|---|
| ORPS | 59.9 | 75.7 | 92.0 | 84.1 |
| - Execution | 43.8 | 56.4 | 72.8 | 200.5 |
| - Reasoning | 55.6 | 74.5 | 94.4 | 124.5 |
🔼 This table presents the results of an ablation study conducted to evaluate the impact of two key components in the Outcome-Refining Process Supervision (ORPS) framework: execution feedback and in-depth reasoning. It compares the performance of the complete ORPS model against two variants: one where execution feedback is removed, and another where the in-depth reasoning process is removed. The performance metrics, all expressed as percentages, include the success rate (Pass@1), the average percentage of test cases passed, and the percentage of valid solutions generated. The time metric represents the relative execution time compared to a standard solution.
read the caption
Table 3: Ablation Study Results. - Execution: Remove execution feedback from our framework. - Reasoning: Remove in-depth reasoning process. Every metric is in percentage.
| Category | Metric | Description |
|---|---|---|
| Dynamic Execution Profiling | ||
| Time Enabled | Total CPU time spent executing the code, measured in nanoseconds. Lower values indicate more efficient execution and better algorithmic optimization. | |
| Instruction Count | Number of CPU instructions executed during runtime. Reflects computational efficiency, with lower counts suggesting more optimized code paths and better algorithm implementation. | |
| Branch Misses | Frequency of incorrect branch predictions during execution. Lower values indicate better code predictability and CPU pipeline efficiency, resulting in faster execution times. | |
| Page Faults | Number of times the program needs to access virtual memory. Fewer page faults suggest better memory management and more efficient memory access patterns. | |
| Static Analysis | ||
| Code Length | Total number of lines in the source code. Generally, shorter code length indicates more concise solutions while maintaining readability and functionality. | |
| AST Node Count | Number of nodes in the Abstract Syntax Tree. Measures structural complexity of the code, with fewer nodes suggesting simpler and more maintainable implementation. | |
| Cyclomatic Complexity | Quantifies the number of linearly independent paths through the code. Lower values indicate easier-to-maintain and test code, reducing potential bug sources. | |
| Cognitive Complexity | Measures how difficult the code is to understand, based on control flow structures and nesting. Lower scores suggest more readable and maintainable code that is easier to debug. |
🔼 This table presents an ablation study comparing different process reward model setups within the Outcome-Refining Process Supervision framework. It examines the impact of reward signal granularity (line-level vs. outcome-level feedback) and whether the process reward model requires explicit training on the model’s performance. Metrics such as Pass@1 (percentage of solutions passing all test cases), Tests (average number of test cases passed), Valid (percentage of solutions that compile and execute), and Time (relative execution time) are used to assess the effectiveness of each setup.
read the caption
Table 4: Analysis of Process Reward Model. Granularity refers to the level of detail in the reward signal (line-level or outcome-level). Train indicates whether the process reward model requires training.
Full paper#