↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Procedural Content Generation (PCG) excels at creating high-quality 3D assets but suffers from the difficulty of controlling the desired output through parameter tuning. Inverse PCG aims to automatically find optimal parameters given input conditions, yet existing methods struggle with lengthy sampling processes or lack controllability. This hinders efficient 3D asset creation for various applications.
This paper introduces DI-PCG, which tackles these challenges. It uses a lightweight diffusion transformer model that directly learns the mapping between image conditions and PCG parameters. The model’s efficiency is highlighted, requiring minimal training time and resources while effectively producing high-fidelity 3D assets. DI-PCG surpasses existing methods in accuracy and generalization to real-world images, offering a promising approach for efficient I-PCG and high-quality 3D asset creation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces DI-PCG, a novel and efficient method for inverse procedural content generation (I-PCG). It addresses the limitations of existing I-PCG methods by using a diffusion model, resulting in significant speed-ups and improved generalizability. This opens new avenues for research in efficient image-to-3D generation and high-quality 3D asset creation, crucial for various applications such as gaming and film production.
Visual Insights#

🔼 This figure showcases the capabilities of DI-PCG, a diffusion-based inverse procedural content generation method. Given various input images (the ‘condition images’), DI-PCG successfully identifies the optimal parameters to feed into procedural 3D model generators. These generators then produce high-fidelity 3D models. Note that the textures and materials used in the final 3D models are randomly selected by the procedural generators themselves; this is purely for visualization purposes and does not impact the accuracy of the parameter estimation.
read the caption
Figure 1: Given condition images, DI-PCG can accurately estimate suitable parameters of procedural generators, resulting high fidelity 3D asset creation. Textures and materials are randomly assigned by the procedural generators for visualizations.
🔼 This table presents a quantitative comparison of DI-PCG’s performance against several state-of-the-art 3D reconstruction and generation methods on a subset of ShapeNet chair models and DI-PCG’s test set. The comparison uses three metrics: Chamfer Distance (CD), Earth Mover’s Distance (EMD), and F-score. Lower CD and EMD values indicate better accuracy in reconstructing the 3D chair models, while a higher F-score represents better overall performance.
read the caption
Table 1: Quantitative comparisons on the test split of DI-PCG and the selected ShapeNet chair subset.
In-depth insights#
Inverse PCG Problem#
The inverse procedural content generation (PCG) problem tackles the challenge of automatically determining the optimal parameters for a procedural generator given a desired output. Traditional PCG methods typically involve extensive manual tuning, which is time-consuming and inefficient. The inverse PCG approach aims to automate this process, making PCG more accessible and scalable. This is achieved by formulating the problem as an optimization task: finding the parameters that minimize the difference between the generated content and the target. Various techniques are explored, including sampling-based methods (e.g., Markov Chain Monte Carlo) and neural network-based approaches. Sampling methods, while theoretically sound, often suffer from high computational cost and limited ability to explore the parameter space effectively. Neural networks, on the other hand, offer the potential for faster inference but may struggle with generalization and lack of controllability. A key aspect of successful inverse PCG is handling the complex relationships between the parameters and the resulting output, which is often non-linear and high-dimensional. Research continues to refine both sampling and neural network strategies, integrating techniques like diffusion models to improve efficiency and quality of parameter estimation. Ultimately, the goal of inverse PCG is to bridge the gap between the creative vision and the automated generation process, enabling the creation of high-quality 3D assets in an efficient and user-friendly manner.
Diffusion Model for PCG#
Employing diffusion models for procedural content generation (PCG) offers a novel approach to address the limitations of traditional methods. Diffusion models’ inherent ability to learn complex data distributions makes them well-suited for PCG tasks, enabling the generation of diverse and high-quality 3D assets. Unlike traditional methods that often rely on handcrafted rules or extensive parameter tuning, diffusion models learn the underlying patterns from data, facilitating more efficient and intuitive content creation. A key advantage is the potential for improved controllability, as diffusion models can be conditioned on various inputs (e.g., images, text) to guide the generation process. Furthermore, the stochastic nature of diffusion models allows for exploration of a wider range of design possibilities compared to deterministic approaches. However, challenges remain. The computational cost associated with training diffusion models can be substantial, particularly for high-dimensional data such as 3D models. Additionally, ensuring that the generated content adheres to specific constraints or requirements needs careful consideration. Further research is needed to optimize the efficiency and controllability of diffusion models in the context of PCG, potentially through the development of more efficient architectures or novel training strategies. The integration of diffusion models with other PCG techniques, such as grammar-based methods, also presents opportunities to create even more sophisticated and flexible systems for content generation.
DI-PCG Architecture#
The DI-PCG architecture centers on a lightweight diffusion transformer model trained to directly predict procedural content generation (PCG) parameters from input images. This differs significantly from traditional inverse PCG methods, which often rely on iterative sampling or complex neural networks. Directly treating parameters as the denoising target within a diffusion framework allows for efficient and effective parameter estimation. The model incorporates a cross-attention mechanism to integrate visual features extracted from the input image, enabling image-conditioned parameter generation. This architecture’s efficiency stems from its relatively small parameter count, leading to faster training and inference times. Furthermore, the use of a pre-trained visual feature extractor enhances the model’s generalizability, facilitating high-quality 3D asset creation from diverse image inputs. The self-contained nature of the training process, relying solely on the target procedural generator, eliminates the need for external datasets and simplifies implementation.
Qualitative & Quantitative Results#
A robust assessment of a research paper necessitates a thorough analysis of its qualitative and quantitative results. Qualitative results offer a nuanced understanding through visual inspection, case studies, or in-depth descriptions of observed phenomena. This section would showcase compelling examples of successful 3D model generation from input images or sketches, highlighting the model’s ability to capture fine details and generate realistic textures. It would likely illustrate successes across various object categories to prove its versatility. Conversely, quantitative results delve into the numerical aspects using metrics like Chamfer distance or F-score. These metrics would evaluate the accuracy of the model’s parameter estimations and assess the quality of generated 3D models compared to ground truth or other state-of-the-art techniques. A detailed ablation study would further dissect the model’s performance under different conditions, exploring variations in dataset sizes, input types, and model architecture to determine the key factors contributing to its success or limitations. Ideally, this section would provide a balanced perspective, presenting both strengths and weaknesses, leading to a well-rounded conclusion.
Future of Inverse PCG#
The future of Inverse Procedural Content Generation (I-PCG) is bright, driven by advancements in several key areas. Improved neural network architectures will lead to more accurate and robust parameter estimation, handling complex, high-dimensional parameter spaces with greater efficiency and fewer training iterations. The integration of large language models (LLMs) holds immense potential, enabling natural language descriptions as input conditions for generating 3D assets, thus bridging the gap between human intent and procedural generation. Furthermore, research into hybrid approaches combining neural networks with traditional optimization techniques promises to overcome the limitations of each method individually, leading to faster convergence and more accurate results. Development of novel loss functions tailored to specific PCG applications will further enhance the precision and controllability of I-PCG systems. Finally, expanding the range of supported procedural generators will broaden the applications of I-PCG to new domains. The focus will shift to generating more complex, detailed and realistic 3D models tailored to diverse uses in gaming, film, architecture, and beyond.
More visual insights#
More on figures

🔼 This figure illustrates the DI-PCG framework. The left panel shows a procedural generator that takes parameters as input and produces 3D shapes. The parameters are randomly sampled to generate a variety of shapes. The right panel shows how DI-PCG uses a denoising diffusion model to learn the relationship between images and the procedural generator’s parameters. Given a condition image, DI-PCG uses DINOv2 to extract image features, which are then fed into the diffusion model via cross-attention to guide the generation of parameters. These parameters are then transformed back to their original range before being used by the generator to create high-quality 3D assets with clean geometry and meshing.
read the caption
Figure 2: Overview of DI-PCG. (Left) The procedural generator consists of programs and parameters, and can be randomly sampled to produce various shapes. (Right) To control it with images, DI-PCG trains a denoising diffusion model directly upon canonicalized generator parameters, using DINOv2 to extract condition image features and inject them via cross attention. The resulting parameters are projected back to original ranges and then fed into the generator, delivering high-quality 3D generation with neat geometry and meshing.

🔼 Figure 3 showcases the qualitative results of the DI-PCG model for generating 3D models of chairs, tables, and vases. For each object category, the figure displays a series of input images sourced from the internet and the corresponding 3D models generated by DI-PCG. This visualization demonstrates DI-PCG’s ability to generate high-fidelity 3D assets from a range of diverse image conditions, highlighting its effectiveness in image-to-3D translation and inverse procedural content generation.
read the caption
Figure 3: Qualitative results for chair, table, and vase generations. Input images are collected from the internet.

🔼 This figure shows a qualitative comparison of DI-PCG against other state-of-the-art 3D reconstruction and generation methods. The comparison uses the same input image for each method to highlight the differences in generated 3D chair models. Baselines include Shap-E, SDFusion, Michelangelo, CraftsMan, and InstantMesh. The figure demonstrates DI-PCG’s ability to generate high-fidelity 3D models that accurately reflect the input image, while the baselines show various shortcomings in terms of alignment, detail preservation, or overall model quality.
read the caption
Figure 4: Qualitative comparisons of DI-PCG with baselines.

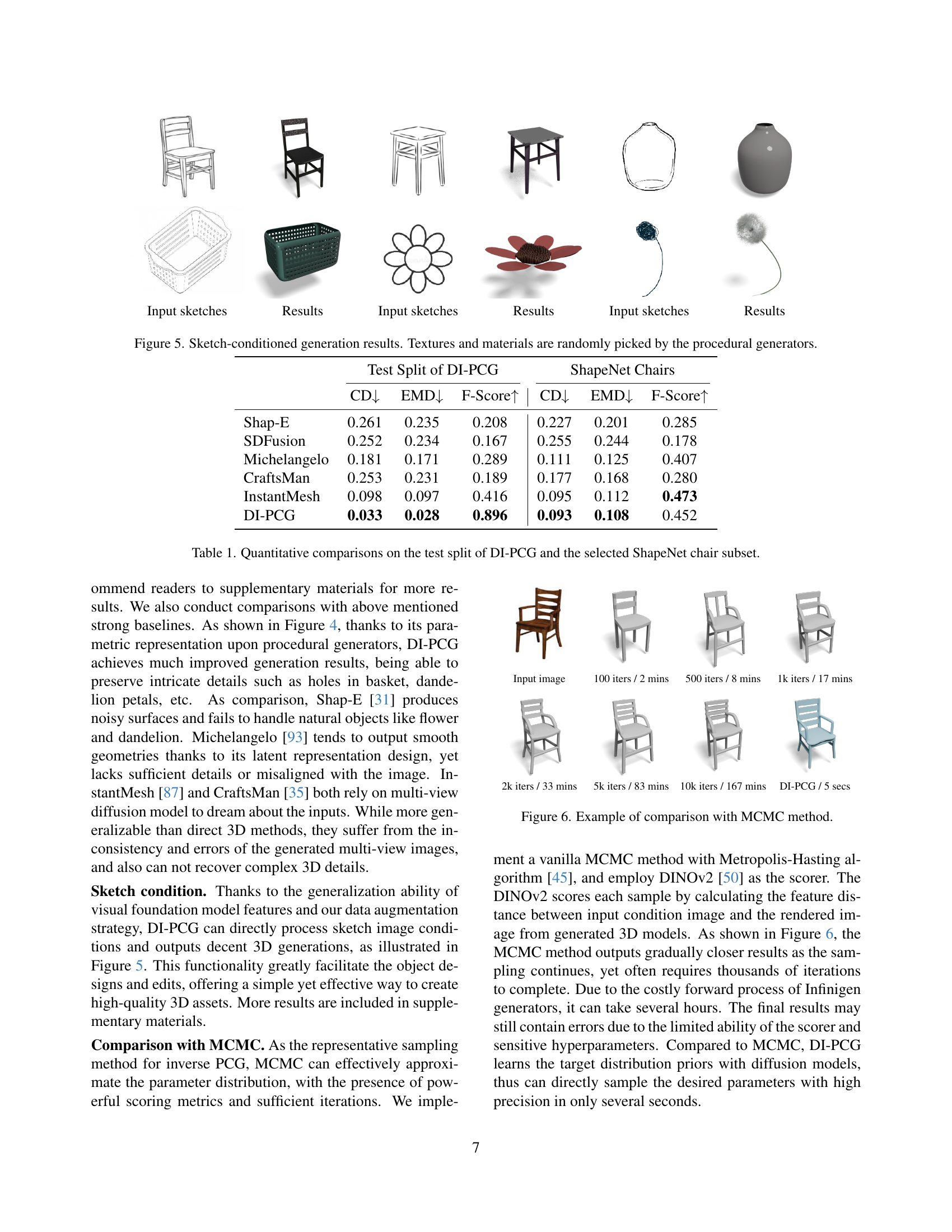
🔼 This figure showcases the results of 3D model generation using sketches as input conditions. The models are created by a procedural generator, meaning they are algorithmically constructed based on rules and parameters. Importantly, the textures and materials applied to the 3D models are chosen randomly by the procedural generator, demonstrating the system’s ability to produce diverse results even with the same basic sketch input.
read the caption
Figure 5: Sketch-conditioned generation results. Textures and materials are randomly picked by the procedural generators.

🔼 This figure compares the results of the proposed DI-PCG method to a Markov Chain Monte Carlo (MCMC) method for inverse procedural content generation. It shows how the quality of 3D model generation improves with more iterations in MCMC, but at significantly higher time cost. DI-PCG, in contrast, produces comparable results in only a few seconds.
read the caption
Figure 6: Example of comparison with MCMC method.

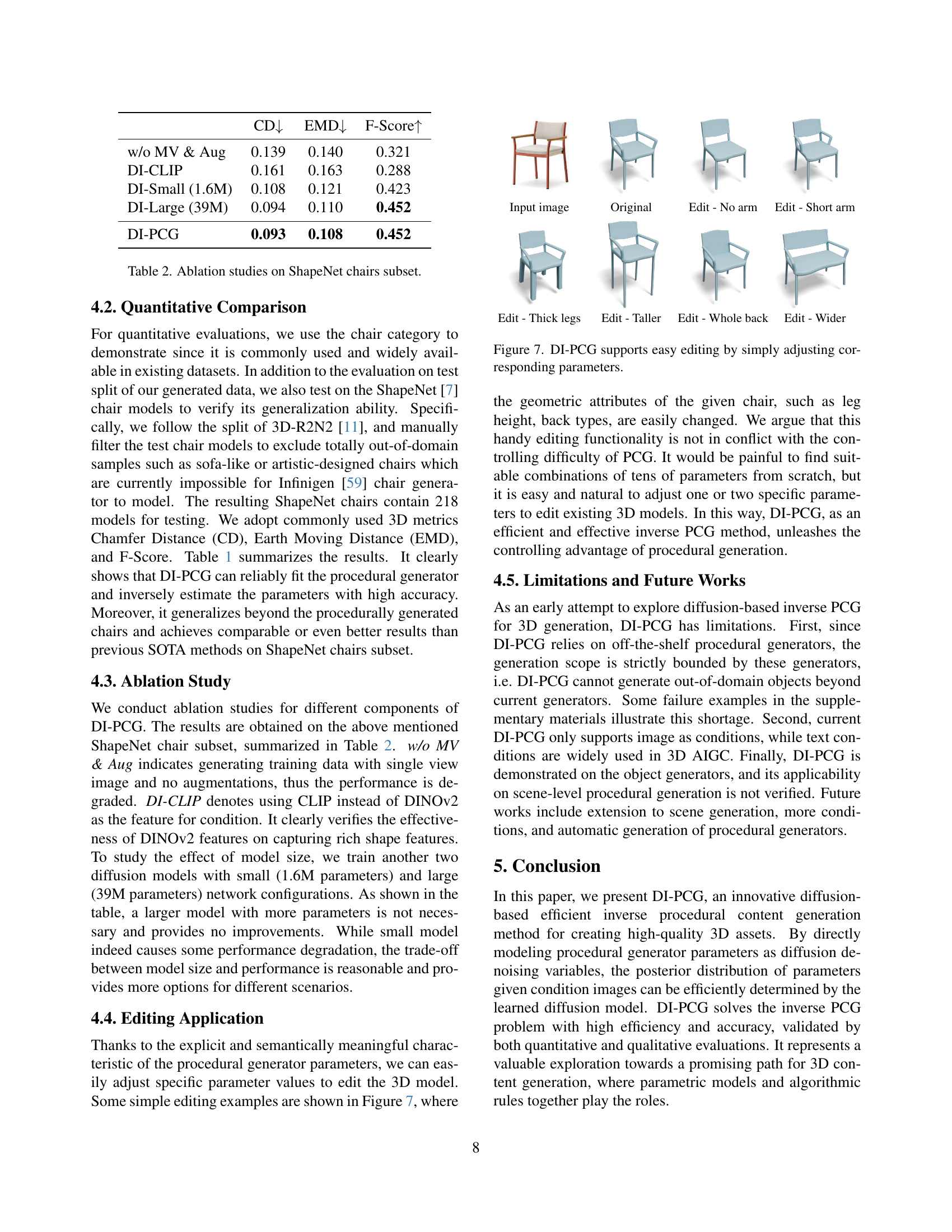
🔼 Figure 7 shows how easy it is to edit 3D models generated by DI-PCG by simply modifying the corresponding parameters of the procedural generator. The example shows various modifications applied to a chair model, illustrating changes such as leg thickness, height, presence of armrests, and overall width, all achieved by adjusting specific parameters within the generator. This highlights the ease of control offered by DI-PCG and its potential for efficient design and customization.
read the caption
Figure 7: DI-PCG supports easy editing by simply adjusting corresponding parameters.
Full paper#