↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current cross-modal generation models often rely on complex mappings from noise to target data, using conditioning mechanisms. This approach can be computationally expensive and lacks flexibility. Also, Classifier-free guidance, while enhancing quality, is difficult to integrate in these models. These limitations hinder progress towards efficient and flexible cross-modal media generation.
CrossFlow overcomes these challenges by directly learning a mapping between modalities using flow matching. This eliminates the need for both noise and conditioning mechanisms. The authors introduce a method for enabling Classifier-free guidance which significantly improves the quality of generated images. Moreover, CrossFlow demonstrates excellent scalability and allows for interesting latent arithmetic, making it a powerful new tool for cross-modal and intra-modal media generation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces CrossFlow, a novel and surprisingly simple framework for cross-modal generation that outperforms existing methods. It offers improved scalability, enables classifier-free guidance without noise or conditioning, and opens new avenues for latent manipulation in cross-modal tasks. This work significantly advances the field and inspires future research on efficient and effective cross-modal media generation.
Visual Insights#

🔼 The figure illustrates the CrossFlow framework, a novel approach for cross-modality evolution. It directly transforms data from one modality (e.g., text) to another (e.g., image) using flow matching, without the need for additional conditioning mechanisms like cross-attention. This is achieved through a simple vanilla transformer architecture, resulting in comparable performance to state-of-the-art models on various tasks, including text-to-image generation and other cross-modal transformations. The figure highlights the framework’s simplicity and generalizability across diverse applications.
read the caption
Figure 1: We propose CrossFlow, a general and simple framework that directly evolves one modality to another using flow matching with no additional conditioning. This is enabled using a vanilla transformer without cross-attention, achieving comparable performance with state-of-the-art models on (a) text-to-image generation, and (b) various other tasks, without requiring task specific architectures.
| Method | #Params (B) | #Steps (K) | FID ↓ | CLIP ↑ |
|---|---|---|---|---|
| Standard FM (Baseline) | 1.04 | 300 | 10.79 | 0.29 |
| CrossFlow (Ours) | 0.95 | 300 | 10.13 | 0.29 |
🔼 This table compares the performance of the proposed CrossFlow model against a standard flow matching model that uses cross-attention. Both models were trained using identical settings (hyperparameters, datasets, training duration). The results show that CrossFlow achieves slightly better performance than the baseline model in terms of zero-shot FID (Fréchet Inception Distance) score at 30,000 samples, indicating superior image generation quality. However, both models exhibit comparable performance when evaluated using the CLIP (Contrastive Language–Image Pre-training) score.
read the caption
Table 1: Comparison between our CrossFlow and standard flow matching with cross-attention. Both models are trained with the same settings. We find that our model slightly outperforms standard flow matching baseline in terms of zero-shot FID-30K and achieves comparable performance on the CLIP score.
In-depth insights#
CrossFlow Framework#
The proposed CrossFlow framework offers a novel approach to cross-modal generation by directly mapping one modality’s distribution to another’s, eliminating the need for noise distributions and conditioning mechanisms commonly used in diffusion models. This paradigm shift leverages variational autoencoders (VAEs) to regularize input distributions, enabling efficient and effective cross-modal flow matching even without cross-attention. CrossFlow’s simplicity and generalizability are highlighted by its ability to outperform existing methods on multiple tasks (text-to-image, image captioning, depth estimation, and super-resolution) without task-specific architectures. The framework also uniquely enables latent arithmetic, allowing for semantically meaningful edits in the output space by performing arithmetic operations on the encoded latent representations. This innovative approach, scalable with model size and training steps, promises significant advances in cross-modal media generation and opens up new possibilities for manipulating and synthesizing media across various modalities.
VE & CFG Methods#
The effectiveness of the proposed CrossFlow framework hinges on two crucial components: Variational Encoders (VEs) and Classifier-Free Guidance (CFG). VEs play a critical role in bridging the gap between disparate input and target data distributions. By encoding the source modality (e.g., text) into a latent space with the same shape as the target modality (e.g., images), VEs ensure compatibility for flow matching. This regularization of the source distribution is shown to be essential for high-quality generation. The use of a VAE for training the VE further enhances performance. In contrast to simply minimizing the reconstruction error, the contrastive loss in the VAE is shown to better capture semantic meaning leading to improved results. The second key element, CFG with an indicator, addresses the challenge of adapting CFG, a technique typically used with conditional models, to CrossFlow’s unconditional approach. By introducing a binary indicator during training, CFG is effectively incorporated without the need for explicit conditioning inputs, significantly boosting generation quality and fidelity. The authors elegantly sidestep the complexity of existing cross-modal methods while achieving improved results and scalability. The combination of VEs and CFG demonstrates a highly effective and novel strategy for enhancing CrossFlow’s performance.
T2I Experiments#
A hypothetical ‘T2I Experiments’ section in a research paper would likely detail the experimental setup and results of text-to-image (T2I) generation experiments. This would involve specifying the datasets used (e.g., COCO, LAION-5B), the metrics employed to assess generated image quality (e.g., FID, Inception Score, CLIP score, human evaluation), and the baselines against which the proposed model is compared (e.g., other diffusion models, GANs). Crucially, the section would describe the training process, including details about model architecture, hyperparameters, training data preprocessing, and any regularization techniques. The results would present quantitative comparisons with baselines, showcasing improvements in various metrics and potentially including qualitative examples of generated images. A thorough analysis of the results would be essential, highlighting the strengths and weaknesses of the proposed method and offering insights into its performance characteristics. This might include discussions of its ability to handle various text prompts, generate high-fidelity images, maintain consistency across generations, and demonstrate other desirable qualities of T2I models. The experiment section would conclude with a summary of the findings, emphasizing the significance and limitations of the work in the context of existing research.
Multimodal Mapping#
Multimodal mapping, in the context of the research paper, refers to the process of learning a direct transformation between different modalities of data, such as text and images. Traditional methods often involve an intermediate step, like mapping both modalities to a shared latent space or using noise as a bridge. CrossFlow’s innovation lies in directly mapping one modality to another, bypassing the need for noise or a shared latent space. This simplifies the architecture while potentially enabling more efficient and effective learning. The effectiveness of this direct mapping relies on the use of variational encoders to regularize the source distribution, ensuring compatibility with flow matching, and introducing a classifier-free guidance mechanism. The results demonstrate the generalizability of the approach, with CrossFlow achieving competitive or superior performance across diverse tasks like text-to-image generation, image captioning, depth estimation, and image super-resolution. The paper highlights a paradigm shift, demonstrating the potential for significant advancements in cross-modal media generation through simplified and more direct multimodal mapping techniques.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of CrossFlow is crucial, especially for high-resolution and complex cross-modal tasks. This involves investigating more efficient architectures and training strategies. Extending CrossFlow to handle more modalities beyond text and image, such as audio and 3D data, could significantly broaden its applicability. Investigating the theoretical underpinnings of CrossFlow is essential to understand its capabilities and limitations. This includes studying the properties of the latent space and the effects of different encoders and flow matching methods. Finally, developing applications of CrossFlow in diverse areas like video editing, virtual reality, and generative art, could showcase its real-world potential. Ultimately, a deeper exploration of these avenues could lead to breakthroughs in the field of cross-modal media generation.
More visual insights#
More on figures

🔼 CrossFlow is a framework for cross-modal generation that directly maps one modality to another using flow matching without additional conditioning. The figure illustrates the architecture of CrossFlow for text-to-image generation. It uses a Text Variational Encoder (VE) to convert text embeddings from a language model into a latent representation (z0). This latent representation is then evolved using a standard flow matching model into an image latent space (z1) from which the final image is generated. This process bypasses the need for noise distributions and explicit conditioning mechanisms typically found in diffusion or flow-matching models.
read the caption
Figure 2: CrossFlow Architecture. CrossFlow enables direct evolution between two different modalities. Taking text-to-image generation as an example, our T2I model comprises two main components: a Text Variational Encoder and a standard flow matching model. At inference time, we utilize the Text Variational Encoder to extract the text latent z0∈ℝh×w×csubscript𝑧0superscriptℝℎ𝑤𝑐z_{0}\in\mathbb{R}^{h\times w\times c}italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_h × italic_w × italic_c end_POSTSUPERSCRIPT from text embedding x∈ℝn×d𝑥superscriptℝ𝑛𝑑x\in\mathbb{R}^{n\times d}italic_x ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d end_POSTSUPERSCRIPT produced by any language model. Then we directly evolve this text latent into the image space to generate image latent z1∈ℝh×w×csubscript𝑧1superscriptℝℎ𝑤𝑐z_{1}\in\mathbb{R}^{h\times w\times c}italic_z start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_h × italic_w × italic_c end_POSTSUPERSCRIPT.

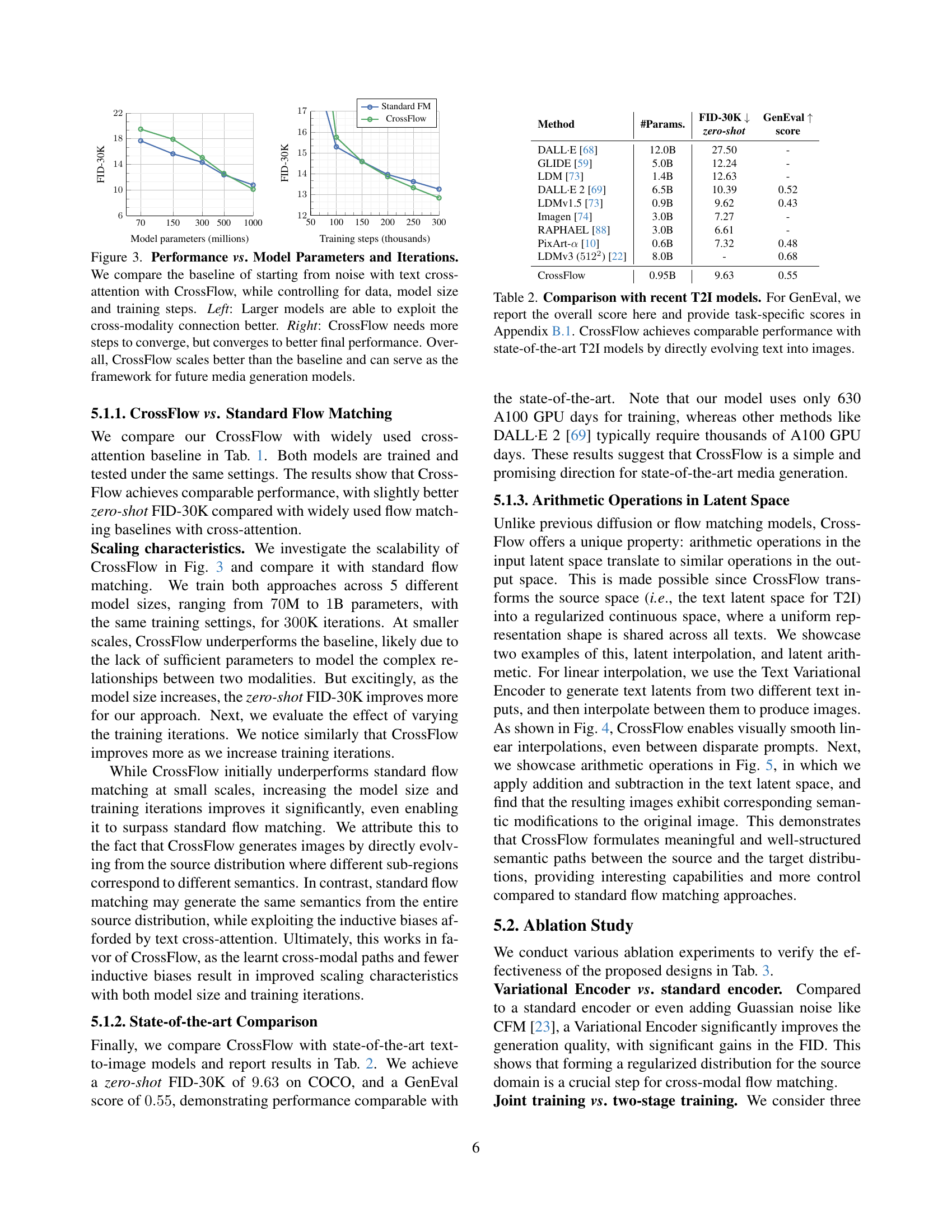
🔼 This figure compares the performance of CrossFlow and a standard flow matching model (baseline) for text-to-image generation. The experiment controls for the amount of training data used, model size (number of parameters), and number of training steps. The left panel shows how performance (measured by FID-30K) improves with larger model sizes for both methods, but CrossFlow demonstrates better scaling and higher performance at larger sizes. The right panel shows how performance changes as a function of training steps. CrossFlow requires more training steps to converge, but ultimately achieves better performance than the baseline model, again demonstrating superior scaling properties. In summary, this figure illustrates that CrossFlow is more efficient in terms of scaling than the baseline method.
read the caption
Figure 3: Performance vs. Model Parameters and Iterations. We compare the baseline of starting from noise with text cross-attention with CrossFlow, while controlling for data, model size and training steps. Left: Larger models are able to exploit the cross-modality connection better. Right: CrossFlow needs more steps to converge, but converges to better final performance. Overall, CrossFlow scales better than the baseline and can serve as the framework for future media generation models.

🔼 This figure demonstrates the smooth transitions achievable with CrossFlow when linearly interpolating between two text-based latent representations. The interpolation showcases seamless changes in various aspects of the generated images, including object orientation, color composition, shapes, backgrounds, and even object types. The visual effect highlights the model’s ability to navigate the latent space smoothly and predictably. Note that due to space constraints, only a subset of the interpolations are displayed here; the full set is included in Appendix C (Fig. 10 and Fig. 11).
read the caption
Figure 4: CrossFlow provides visually smooth interpolations in the latent space. We show images generated by linear interpolation between the first (left) and second (right) text latents. CrossFlow enables visually smooth transformations of object direction, composite colors, shapes, background scenes, and even object categories. Please zoom in for better visualization. For brevity, we display only 7 interpolating images here; additional interpolating images can be found in Appendix C (Fig. 10 and Fig. 11).

🔼 This figure demonstrates the novel capability of CrossFlow to perform arithmetic operations directly within the latent space of text embeddings. A Variational Encoder first maps input text into a latent representation (z0). Then, arithmetic operations (addition and subtraction) are performed on these latent vectors. The results of these operations are then used to generate new images, which reflect the semantic changes induced by the arithmetic. The images generated, along with their corresponding latent codes (z0), are shown to illustrate how simple arithmetic manipulations in the latent space lead to meaningful alterations in the generated images.
read the caption
Figure 5: CrossFlow allows arithmetic in text latent space. Using the Text Variational Encoder (VE), we first map the input text into the latent space z0subscript𝑧0z_{0}italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT. Arithmetic operations are then performed in this latent space, and the resulting latent representation is used to generate the corresponding image. The latent code z0subscript𝑧0z_{0}italic_z start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT used to generate each image is provided at the bottom.

🔼 This figure shows how CrossFlow directly evolves text into images for text-to-image generation. It contrasts with traditional methods that learn a complex mapping from Gaussian noise to the target image distribution. CrossFlow learns a direct mapping from the distribution of one modality (text) to the distribution of another (image), simplifying the process and eliminating the need for noise or additional conditioning mechanisms.
read the caption
(a)

🔼 This figure shows the various tasks that CrossFlow can perform, highlighting its versatility and generalizability. It demonstrates the ability of CrossFlow to directly evolve one modality (e.g., text) into another (e.g., image) without requiring task-specific architectures. The various tasks shown include text-to-image generation, image captioning, monocular depth estimation, and image super-resolution. Each example visually showcases the successful transformation between modalities using the CrossFlow framework.
read the caption
(b)

🔼 This figure shows the CrossFlow architecture. It is a general framework for cross-modal flow matching. The figure illustrates how CrossFlow directly evolves one modality (e.g., text) to another (e.g., image) using flow matching, without the need for cross-attention or a conditioning mechanism. A variational encoder processes the input data, ensuring the source distribution is compatible with the target distribution. A standard flow matching model, using a vanilla transformer, is then used to transform the source modality into the target modality. This architecture is shown to be efficient and effective across a range of tasks.
read the caption
(c)

🔼 This figure demonstrates the generalizability of the CrossFlow framework by showcasing its performance on various cross-modal and intra-modal tasks. These include text-to-image generation, image captioning, depth estimation, and image super-resolution. Each subfigure shows example results, illustrating that CrossFlow can handle diverse media types and achieve state-of-the-art or comparable performance without requiring task-specific architectures.
read the caption
(d)

🔼 This figure demonstrates the impact of different training strategies on the performance of the model. It compares three approaches: (1) jointly training the variational encoder (VE) and flow matching model from the start; (2) pre-training the VE and then training the flow matching model; and (3) pre-training the VE and then jointly fine-tuning both models. The results show that jointly training both components from the beginning yields the best performance, highlighted by the lowest FID score and highest CLIP score, indicating the best balance between visual fidelity and semantic alignment.
read the caption
(e)
More on tables
| Method | #Params. | FID-30K ↓ | GenEval ↑ | |
|---|---|---|---|---|
| DALL·E [68] | 12.0B | 27.50 | - | |
| GLIDE [59] | 5.0B | 12.24 | - | |
| LDM [73] | 1.4B | 12.63 | - | |
| DALL·E 2 [69] | 6.5B | 10.39 | 0.52 | |
| LDMv1.5 [73] | 0.9B | 9.62 | 0.43 | |
| Imagen [74] | 3.0B | 7.27 | - | |
| RAPHAEL [88] | 3.0B | 6.61 | - | |
| PixArt-α [10] | 0.6B | 7.32 | 0.48 | |
| LDMv3 (512²) [22] | 8.0B | - | 0.68 | |
| CrossFlow | 0.95B | 9.63 | 0.55 |
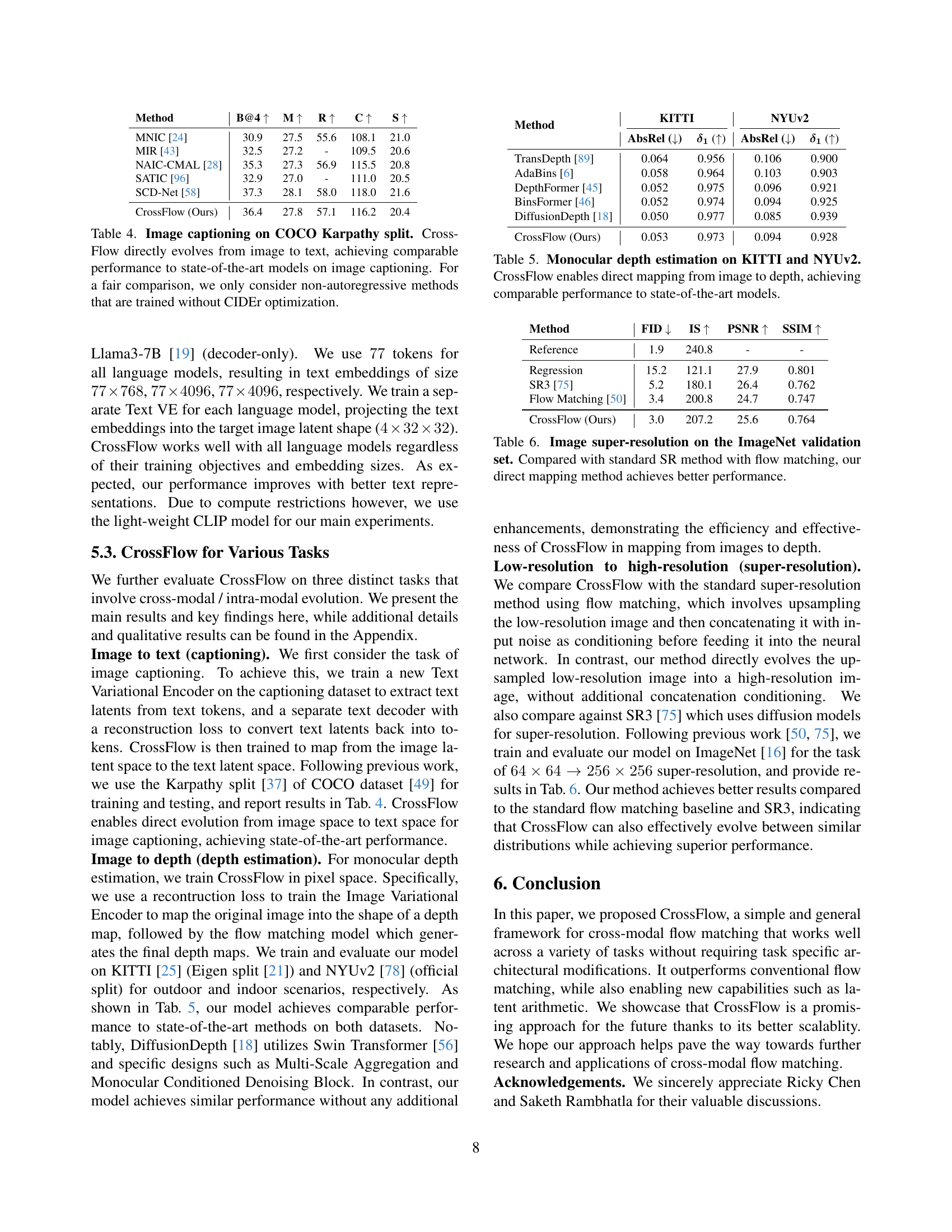
🔼 Table 2 compares the performance of the proposed CrossFlow model against other state-of-the-art text-to-image (T2I) generation models. The comparison is based on two metrics: FID-30K (Frechet Inception Distance, a measure of image quality) and GenEval (a more holistic metric assessing various aspects of text-image alignment). The table highlights that CrossFlow, despite its simpler architecture, achieves comparable performance to significantly larger and more complex models. More detailed GenEval results broken down by specific subtasks are available in Section B.1 of the paper.
read the caption
Table 2: Comparison with recent T2I models. For GenEval, we report the overall score here and provide task-specific scores in Sec. B.1. CrossFlow achieves comparable performance with state-of-the-art T2I models by directly evolving text into images.
| Text encoder | FID ↓ | CLIP ↑ |
|---|---|---|
| Encoder | 66.65 | 0.20 |
| Encoder + noise | 59.91 | 0.21 |
| Variational Encoder | 40.78 | 0.23 |
🔼 This ablation study analyzes the impact of different design choices in CrossFlow on text-to-image generation performance. Using the smallest model (70 million parameters), the study evaluates various components: the type of text encoder (Variational Encoder vs. standard encoder), the training objective function (reconstruction loss vs. contrastive loss), the application of Classifier-Free Guidance (CFG), different large language models (LLMs), and the training strategy (joint vs. separate training of encoder and flow matching model). Zero-shot FID-10K and CLIP scores are reported to quantify performance. The final configurations used in the CrossFlow model are highlighted.
read the caption
Table 3: Ablation study on Text Variational Encoder, training objective, CFG, language models, and training strategy. We conduct ablation study on our smallest model (70M), reporting zero-shot FID-10K and CLIP scores. Final settings used for CrossFlow are underlined. AG: Autoguidance. *: results without applying CFG.
| Loss | FID ↓ | CLIP ↑ |
|---|---|---|
| T-T Recon. | 40.78 | 0.23 |
| T-T Contrast. | 34.67 | 0.24 |
| I-T Contrast. | 33.41 | 0.24 |
🔼 Table 4 presents a comparison of different image captioning models on the COCO Karpathy dataset split. The table highlights the performance of CrossFlow, a novel approach that directly maps image data to text, against several state-of-the-art methods. To ensure a fair comparison, only non-autoregressive models trained without CIDEr optimization are included in the comparison. The results demonstrate that CrossFlow achieves comparable performance to existing top-tier models, highlighting its effectiveness in image captioning tasks.
read the caption
Table 4: Image captioning on COCO Karpathy split. CrossFlow directly evolves from image to text, achieving comparable performance to state-of-the-art models on image captioning. For a fair comparison, we only consider non-autoregressive methods that are trained without CIDEr optimization.
| Method | FID ↓ | CLIP ↑ |
|---|---|---|
| No guidance | 33.41 | 0.24 |
| AG | 26.36 | 0.25 |
| CFG indicator | 24.33 | 0.26 |
🔼 Table 5 presents a comparison of CrossFlow’s performance on monocular depth estimation against other state-of-the-art methods. The results are shown for two benchmark datasets: KITTI and NYUv2. Metrics used for evaluation include Absolute Relative Error (AbsRel) and the δi metric (percentage of pixels with depth error greater than i times the ground truth). Lower AbsRel and higher δi values indicate better performance. The table demonstrates that CrossFlow, despite its relatively simple architecture, achieves comparable accuracy to more complex models, showcasing its effectiveness in directly mapping images to depth.
read the caption
Table 5: Monocular depth estimation on KITTI and NYUv2. CrossFlow enables direct mapping from image to depth, achieving comparable performance to state-of-the-art models.
| Model | FID ↓ | CLIP ↑ | |
|---|---|---|---|
| CLIP (0.4B) | 24.33 | 0.26 | |
| T5-XXL (11B) | 22.28 | 0.27 | |
| Llama3 (7B) | 21.20 | 0.27 |
🔼 Table 6 presents a comparison of image super-resolution results on the ImageNet validation set. It contrasts the performance of a standard super-resolution (SR) method using flow matching with the authors’ novel ‘direct mapping’ approach. The results demonstrate that the direct mapping method proposed in the paper outperforms the standard flow-matching-based SR technique.
read the caption
Table 6: Image super-resolution on the ImageNet validation set. Compared with standard SR method with flow matching, our direct mapping method achieves better performance.
| Train strategy | FID ↓ | CLIP ↑ |
|---|---|---|
| 2-stage separate training | 32.55 | 0.24 |
| Joint training | 24.33 | 0.26 |
| 2-stage w/ joint finetuning | 23.79 | 0.26 |
🔼 Table 7 presents a comparison of the CrossFlow model’s performance on the GenEval benchmark against several state-of-the-art text-to-image generation models, including LDM-XL and DALL-E 2. The results demonstrate that CrossFlow achieves comparable performance, showcasing its effectiveness and efficiency as a simpler and promising approach for high-quality media generation.
read the caption
Table 7: GenEval comparisons. Our model achieves comparable performance to state-of-the-art models such as LDM-XL and DALL·E 2, suggesting that CrossFlow is a simple and promising direction for state-of-the-art media generation.
| Method | B@4 ↑ | M ↑ | R ↑ | C ↑ | S ↑ |
|---|---|---|---|---|---|
| MNIC [24] | 30.9 | 27.5 | 55.6 | 108.1 | 21.0 |
| MIR [43] | 32.5 | 27.2 | - | 109.5 | 20.6 |
| NAIC-CMAL [28] | 35.3 | 27.3 | 56.9 | 115.5 | 20.8 |
| SATIC [96] | 32.9 | 27.0 | - | 111.0 | 20.5 |
| SCD-Net [58] | 37.3 | 28.1 | 58.0 | 118.0 | 21.6 |
| CrossFlow (Ours) | 36.4 | 27.8 | 57.1 | 116.2 | 20.4 |
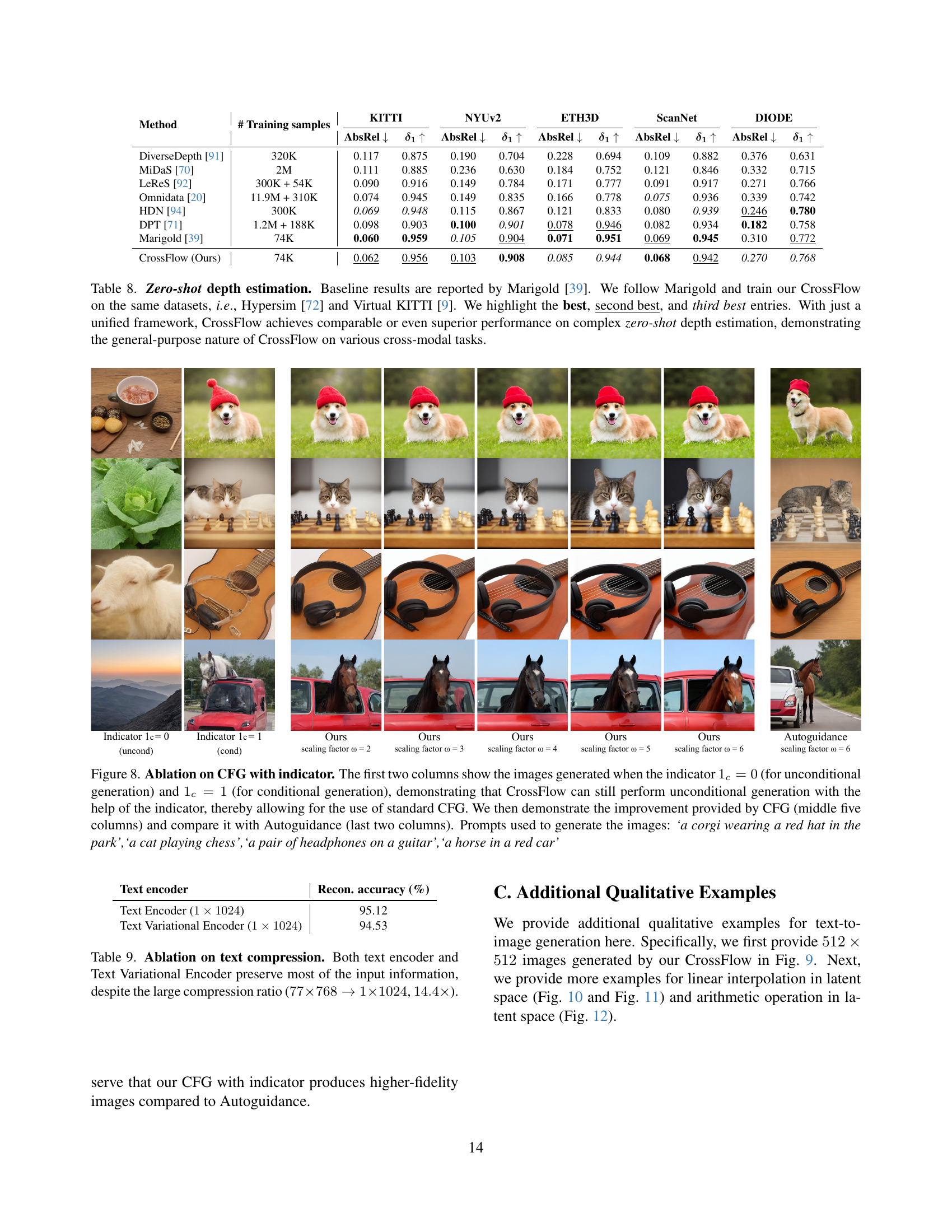
🔼 This table presents a comparison of zero-shot depth estimation performance across different methods. The results are evaluated on five datasets (KITTI, NYUv2, ETH3D, ScanNet, DIODE), and the metrics used are Absolute Relative Error (AbsRel) and the δ1 (81) metric. The authors’ CrossFlow model is compared to several baselines, including results reported by Marigold [39], showing comparable or better performance with CrossFlow’s unified framework approach. The best, second-best, and third-best results for each dataset are highlighted.
read the caption
Table 8: Zero-shot depth estimation. Baseline results are reported by Marigold [39]. We follow Marigold and train our CrossFlow on the same datasets, i.e., Hypersim [72] and Virtual KITTI [9]. We highlight the best, second best, and third best entries. With just a unified framework, CrossFlow achieves comparable or even superior performance on complex zero-shot depth estimation, demonstrating the general-purpose nature of CrossFlow on various cross-modal tasks.
| Method | KITTI | NYUv2 | ||
|---|---|---|---|---|
| TransDepth [89] | 0.064 | 0.956 | 0.106 | 0.900 |
| AdaBins [6] | 0.058 | 0.964 | 0.103 | 0.903 |
| DepthFormer [45] | 0.052 | 0.975 | 0.096 | 0.921 |
| BinsFormer [46] | 0.052 | 0.974 | 0.094 | 0.925 |
| DiffusionDepth [18] | 0.050 | 0.977 | 0.085 | 0.939 |
| CrossFlow (Ours) | 0.053 | 0.973 | 0.094 | 0.928 |
🔼 This table presents an ablation study comparing a standard text encoder against a variational text encoder in a text compression task. The goal was to determine if either method could effectively reduce the dimensionality of text embeddings from 77x768 to 1x1024 while preserving information. The results show that both approaches maintain high reconstruction accuracy despite the significant compression ratio of 14.4 times.
read the caption
Table 9: Ablation on text compression. Both text encoder and Text Variational Encoder preserve most of the input information, despite the large compression ratio (77×768→1×1024→777681102477\times 768\rightarrow 1\times 102477 × 768 → 1 × 1024, 14.4×14.4\times14.4 ×).
Full paper#