↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current instruction-based image editing methods heavily rely on supervised learning, requiring datasets of image-instruction-edited image triplets. These datasets are either created by existing methods, introducing biases, or manually labeled, which is costly and limits diversity. This reliance on supervised learning restricts the scalability and generalizability of these models.
UIP2P tackles these issues by introducing Cycle Edit Consistency (CEC). CEC enforces consistency by applying forward and reverse edits, leveraging CLIP embeddings for semantic alignment and ensuring image coherence. This allows UIP2P to train on real image-caption pairs or image-caption-edit triplets, eliminating the need for ground-truth edited images. The results show UIP2P outperforms state-of-the-art supervised methods in terms of accuracy, precision, and scalability, demonstrating its efficacy across a broader range of editing tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UIP2P, a novel unsupervised method for instruction-based image editing. This addresses the limitations of existing supervised methods that rely on expensive and biased training data. The unsupervised nature of UIP2P makes it more scalable and versatile, opening new avenues for research in image manipulation and other related fields. It’s highly relevant to current trends in AI, specifically in the area of instruction-following models and large-scale image generation, potentially impacting various applications like creative content generation and image restoration.
Visual Insights#

🔼 Figure 1 showcases the results of unsupervised instruction-based image editing using the proposed UIP2P method compared to the InstructPix2Pix approach. The figure demonstrates the superior performance of UIP2P in terms of edit precision, coherence, and preservation of the original image structure across both real-world (a and b) and synthetic (c and d) image examples. Each row presents an original image, the result of editing with InstructPix2Pix, and the result of editing with UIP2P, illustrating the improvement in accuracy and consistency. The different examples highlight UIP2P’s ability to handle various types of edits, including adding elements to a scene, transforming objects, and making global changes to the image’s appearance while maintaining overall scene integrity.
read the caption
Figure 1: Unsupervised InstructPix2Pix. Our approach achieves more precise and coherent edits while preserving the structure of the scene. UIP2P outperforms state-of-the-art models in both real images (a. and b.) and synthetic images (c. and d.).
| Input Caption | Edit Instruction | Edited Caption | Reverse Instruction |
|---|---|---|---|
| A man wearing a denim jacket | make the jacket a rain coat | A man wearing a rain coat | |
| A sofa in the living room | add pillows | A sofa in the living room with pillows | remove the pillows |
| … | … | … | … |
| Person on the cover of a magazine | make the person a cat | Cat on the cover of the magazine | |
| A tourist rests against a concrete wall | give him a backpack | A tourist with a backpack rests against a concrete wall | remove his backpack |
| … | … | … | … |
🔼 This table presents examples of input captions, edit instructions, corresponding edited captions, and generated reverse instructions. The data demonstrates the capability of Large Language Models (LLMs) to generate coherent reverse instructions for image editing tasks. This eliminates the need for manually edited images in the training data, making the process more efficient and scalable. The examples are drawn from both the InstructPix2Pix (IP2P) dataset and the combined CC3M and CC12M datasets (referred to as CCXM). The LLMs used for generating text are GEMINI Pro and GEMMA2.
read the caption
Table 1: Reverse Instruction Generation. Our method generates reverse instructions for the IP2P dataset, eliminating the need for manually edited images. Additionally, edit instructions, edited captions, and reverse instructions are generated for CC3M and CC12M datasets—denoted as CCXM. The texts are generated by LLMs such as GEMINI Pro, and GEMMA2.
In-depth insights#
Unsupervised Editing#
Unsupervised image editing presents a significant advancement in AI, overcoming limitations of supervised methods that rely on large, painstakingly created datasets of image-edit pairs. The core challenge in unsupervised editing lies in training a model to understand and execute edits without explicit examples of what constitutes a “good” edit. This necessitates the development of novel loss functions and training strategies that can implicitly guide the model towards producing high-quality and coherent results. Cycle consistency, where forward and reverse edits cancel each other out, becomes a crucial component in evaluating the quality of edits generated. By incorporating this principle, the model is trained to create reversible edits that preserve the integrity of the original image, implicitly learning the semantics of image manipulation. The successful implementation of unsupervised editing hinges on the ability to leverage large language models (LLMs) to generate diverse and descriptive edit instructions. This allows for a wider range of edits to be trained on, improving generalization. This approach enables training on datasets comprising real image-caption pairs, greatly expanding the scope and eliminating biases associated with pre-existing edit datasets. The key benefit of unsupervised editing is its scalability and flexibility, as it eliminates the dependency on expensive and time-consuming data acquisition processes.
Cycle Consistency#
Cycle consistency, in the context of image editing, is a powerful constraint that significantly improves the quality and coherence of edits. It leverages the idea of reversibility: if you apply an edit and then its inverse, you should ideally return to the original image. This constraint is particularly valuable in unsupervised settings, where ground truth edited images are unavailable for training. By enforcing cycle consistency, the model learns to make edits that are precise and localized, preventing unwanted side effects or unintended changes in other areas of the image. This approach allows for more robust and generalizable image editing models, capable of handling a broader range of instructions, without relying on large, often biased, datasets of ground truth edits. Attention consistency, often used in conjunction, further enhances this by ensuring that the model focuses on the same regions during both forward and reverse edits, thus improving the accuracy and precision of the editing process. The core idea is to learn a mapping between images and instructions that is consistent even when the mapping is reversed, leading to highly realistic and semantically correct results.
CLIP-Based Alignment#
CLIP-based alignment, in the context of image editing, is a crucial technique for bridging the semantic gap between textual instructions and visual modifications. It leverages the power of CLIP (Contrastive Language–Image Pre-training) to embed both text and images into a shared semantic space, enabling the model to understand the intended edits. This alignment is not merely about matching image features to words, but rather about establishing a meaningful relationship between the conceptual content of the instructions and the resulting modifications. For example, ‘make the sky blue’ not only involves changing pixel colors but also implies understanding the context of a sky within an image. Effective CLIP-based alignment ensures that the model doesn’t just execute low-level changes but also understands the high-level intent. The success of such an approach relies heavily on the quality and diversity of the CLIP embeddings, the architecture of the image editing model (i.e., how it integrates CLIP’s output), and the effectiveness of the loss functions used to train the model on aligning these embeddings. In essence, CLIP-based alignment ensures that image edits are faithful to the user’s instructions, leading to higher quality and more intuitive image editing experiences. It forms the core of instruction-based image editing, allowing for more precise and coherent edits that preserve the structure and overall semantics of the original image.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of image editing, this would involve disabling individual loss functions (e.g., CLIP direction loss, attention map consistency loss) to evaluate their impact on the overall performance. The key insight from this is to understand which components are essential and which are redundant or even detrimental. By carefully analyzing the effects of removing each component, researchers can gain a deeper understanding of the model’s architecture and identify areas for improvement. For instance, if removing a particular loss function leads to a significant drop in performance, it highlights the crucial role of that component in achieving high-quality edits. Conversely, if its removal has little effect, it may suggest redundancy, enabling the model to be streamlined for greater efficiency. Analyzing the results of this systematic process is critical for assessing the model’s robustness, interpretability, and potential for optimization. The results can guide future development by suggesting improvements to the model architecture and informing decisions about resource allocation.
Real-World Datasets#
The use of real-world datasets is critical for evaluating the generalizability and robustness of any image editing model. Unlike synthetic or curated datasets, real-world data encompasses the unpredictability and complexity of natural images, including diverse lighting conditions, occlusions, and variations in object appearance. A model trained solely on synthetic data might perform well on that specific data but fail to generalize to real-world scenarios. Therefore, using real-world datasets for evaluation provides a more accurate assessment of a model’s practical applicability. Furthermore, real-world datasets can reveal biases or limitations present in the model’s training process, such as a tendency to over-edit certain regions or struggle with particular image types. These insights are invaluable for improving the model’s performance and mitigating potential drawbacks, making the utilization of real-world datasets in the assessment stage essential for creating practical and trustworthy image editing models. Benchmarking against established real-world datasets is key to comparing model performance fairly and objectively with previous models.
More visual insights#
More on figures

🔼 Figure 2 illustrates the limitations of the Prompt-to-Prompt method used to generate the InstructPix2Pix dataset. The figure showcases three instances where the method introduces biases into the editing process. (a) Attribute-entangled edits: Modifying a specific attribute (the lady’s dress) unintentionally alters other aspects of the image (the background). This highlights the limitations of the model in isolating edits to specific regions. (b) Scene-entangled edits: Editing one part of a scene (transforming a cottage into a castle) unintentionally affects other elements within that scene. This shows the challenges of performing local edits without impacting other parts of the scene. (c) Global scene changes: A simple instruction (converting the image to black and white) results in a drastic global alteration, revealing a lack of control over the scope of edits.
read the caption
Figure 2: Examples of biases introduced by Prompt-to-Prompt in the InstructPix2Pix dataset. Each example shows an input image and its corresponding edited image (generated by Prompt-to-Prompt) along with the associated edit instruction. (a) Attribute-entangled edits: modifying the lady’s dress also unintentionally changes the background. (b) Scene-entangled edits: transforming the cottage into a castle affects surrounding elements. (c) Global scene changes: converting the image to black and white alters the entire scene.

🔼 The figure illustrates the training process of the Unsupervised Instruction-based Image Editing via Cycle Edit Consistency (UIP2P) model. The process begins with an input image and a forward instruction (e.g., ‘add a mountain range’). The UIP2P model, using InstructPix2Pix (IP2P) as a base, generates an edited image reflecting the forward instruction. Then, a reverse instruction (e.g., ‘remove the mountain range’) is applied to the edited image. The model’s success is measured by its ability to reconstruct the original input image from this reverse process. This cycle of forward and reverse edits enforces Cycle Edit Consistency (CEC), a key element of the UIP2P training strategy. The figure shows the flow of data and instructions through the model, highlighting the key components (CLIP embedding, forward/reverse attention maps, and the final loss functions) contributing to the learning process and achieving high-fidelity results.
read the caption
Figure 3: Overview of the UIP2P training framework. The model learns instruction-based image editing by utilizing forward and reverse instructions. Starting with an input image and a forward instruction, the model generates an edited image using IP2P. A reverse instruction is then applied to reconstruct the original image, enforcing Cycle Edit Consistency (CEC).

🔼 Figure 4 presents a qualitative comparison of UIP2P against several state-of-the-art instruction-based image editing methods across various editing tasks. It showcases the superior performance of UIP2P by visually demonstrating its ability to accurately execute diverse editing instructions, such as changing object colors, adding or removing elements, and modifying the overall scene, while simultaneously preserving visual consistency and image integrity. Each row displays an example with the input image, the instruction, and the generated output from each method, highlighting the differences in accuracy, coherence, and visual quality.
read the caption
Figure 4: Qualitative Examples. UIP2P performance is shown across various tasks and datasets, compared to InstructPix2Pix, MagicBrush, HIVE, MGIE, and SmartEdit. Our method demonstrates either comparable or superior results in terms of accurately applying the requested edits while preserving visual consistency.

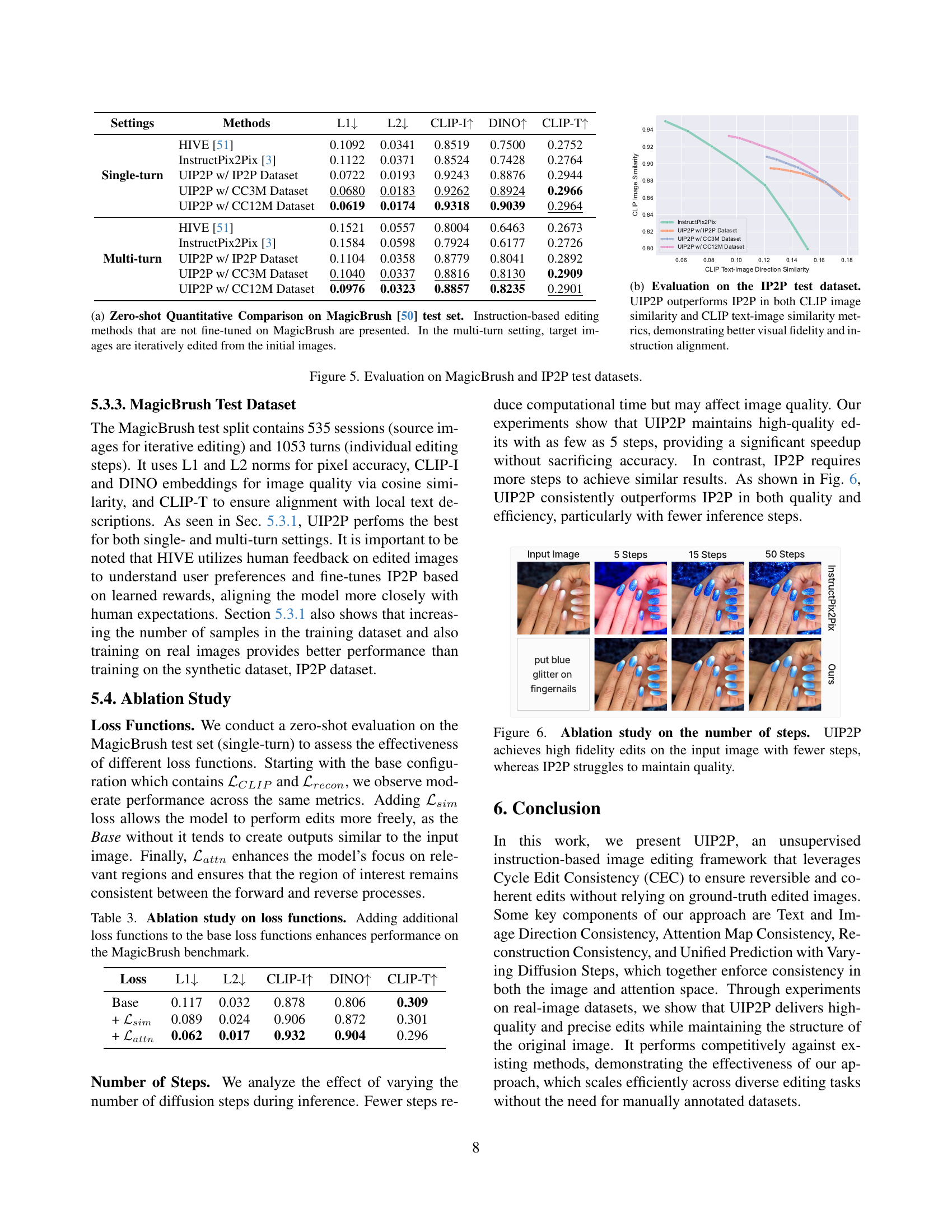
🔼 This figure presents a quantitative comparison of different instruction-based image editing methods on the MagicBrush test set. The methods compared were not specifically fine-tuned on the MagicBrush dataset. The single-turn results show the performance of each method in one editing pass. The multi-turn results illustrate performance when the same method is repeatedly applied to iteratively refine the image. The comparison uses metrics to assess the quality of the editing and alignment with the given instructions. These metrics help to evaluate how well each method performs zero-shot edits, meaning without being trained specifically on the MagicBrush dataset.
read the caption
(a) Zero-shot Quantitative Comparison on MagicBrush [50] test set. Instruction-based editing methods that are not fine-tuned on MagicBrush are presented. In the multi-turn setting, target images are iteratively edited from the initial images.

🔼 This figure shows a quantitative comparison of UIP2P and InstructPix2Pix (IP2P) on the IP2P test dataset. Two key metrics are used to evaluate the models: CLIP image similarity, measuring how visually similar the edited image is to the original, and CLIP text-image similarity, assessing how well the edits align with the given textual instructions. The results demonstrate that UIP2P surpasses IP2P in both metrics, indicating improved visual fidelity and better adherence to the instructions during image editing.
read the caption
(b) Evaluation on the IP2P test dataset. UIP2P outperforms IP2P in both CLIP image similarity and CLIP text-image similarity metrics, demonstrating better visual fidelity and instruction alignment.

🔼 Figure 5 presents a quantitative comparison of the UIP2P model against several baselines on two distinct test datasets: MagicBrush and InstructPix2Pix (IP2P). The left panel displays numerical results, showing the performance of different methods across multiple metrics (L1, L2, CLIP image similarity, DINO similarity, and CLIP text-image similarity). These metrics assess various aspects of image editing quality including pixel-wise difference, semantic alignment, and overall fidelity. The right panel shows a graph specifically illustrating the performance on the IP2P test set, highlighting the improvements achieved by UIP2P in both CLIP image similarity and CLIP text-image direction similarity. This visualization helps to understand the model’s ability to preserve image details while accurately reflecting the semantic changes specified in the textual instruction.
read the caption
Figure 5: Evaluation on MagicBrush and IP2P test datasets.

🔼 This ablation study compares UIP2P and InstructPix2Pix (IP2P) by varying the number of diffusion steps used during image editing. The results show that UIP2P maintains high-fidelity edits even with a significantly smaller number of steps (e.g., 5 steps), while IP2P requires considerably more steps (e.g., 50 steps) to achieve comparable results. This demonstrates UIP2P’s superior efficiency and ability to produce high-quality edits with reduced computational cost.
read the caption
Figure 6: Ablation study on the number of steps. UIP2P achieves high fidelity edits on the input image with fewer steps, whereas IP2P struggles to maintain quality.
More on tables
| Models | (Q1) | (Q2) |
|---|---|---|
| IP2P | 8% | 12% |
| MagicBrush | 17% | 18% |
| HIVE | 14% | 13% |
| MGIE | 20% | 19% |
| SmartEdit | 19% | 18% |
| UIP2P | 22% | 20% |
🔼 This table presents the results of a user study conducted to evaluate the performance of six different image editing methods. Participants were asked to select their top two preferred methods based on two criteria: (Q1) how well the edit matched the instruction and intended location, and (Q2) how accurately the edit was applied to the intended area. The table shows the percentage of times each method was selected as a top performer for each criterion. This allows for a comparison of the methods’ accuracy and effectiveness across various image editing tasks.
read the caption
Table 2: User Study.
| Settings | Methods | L1 ↓ | L2 ↓ | CLIP-I ↑ | DINO ↑ | CLIP-T ↑ |
|---|---|---|---|---|---|---|
| Single-turn | HIVE [51] | 0.1092 | 0.0341 | 0.8519 | 0.7500 | 0.2752 |
| InstructPix2Pix [3] | 0.1122 | 0.0371 | 0.8524 | 0.7428 | 0.2764 | |
| UIP2P w/ IP2P Dataset | 0.0722 | 0.0193 | 0.9243 | 0.8876 | 0.2944 | |
| UIP2P w/ CC3M Dataset | 0.0680 | 0.0183 | 0.9262 | 0.8924 | 0.2966 | |
| UIP2P w/ CC12M Dataset | 0.0619 | 0.0174 | 0.9318 | 0.9039 | 0.2964 | |
| Multi-turn | HIVE [51] | 0.1521 | 0.0557 | 0.8004 | 0.6463 | 0.2673 |
| InstructPix2Pix [3] | 0.1584 | 0.0598 | 0.7924 | 0.6177 | 0.2726 | |
| UIP2P w/ IP2P Dataset | 0.1104 | 0.0358 | 0.8779 | 0.8041 | 0.2892 | |
| UIP2P w/ CC3M Dataset | 0.1040 | 0.0337 | 0.8816 | 0.8130 | 0.2909 | |
| UIP2P w/ CC12M Dataset | 0.0976 | 0.0323 | 0.8857 | 0.8235 | 0.2901 |
🔼 This ablation study investigates the impact of individual loss functions on the overall performance of the model on the MagicBrush benchmark. It starts with a base model using only two loss functions and then progressively adds other loss functions (Lsim and Lattn) to evaluate their contributions to improving the model’s performance. The results, measured by L1, L2, CLIP-I, DINO, and CLIP-T metrics, show how each added loss function enhances the performance, indicating the effectiveness of the proposed multi-loss function approach.
read the caption
Table 3: Ablation study on loss functions. Adding additional loss functions to the base loss functions enhances performance on the MagicBrush benchmark.
| Loss | L1 ↓ | L2 ↓ | CLIP-I ↑ | DINO ↑ | CLIP-T ↑ |
|---|---|---|---|---|---|
| Base | 0.117 | 0.032 | 0.878 | 0.806 | 0.309 |
| + ℒsim | 0.089 | 0.024 | 0.906 | 0.872 | 0.301 |
| + ℒattn | 0.062 | 0.017 | 0.932 | 0.904 | 0.296 |
🔼 This table demonstrates the diversity and flexibility of the reverse instruction dataset used in the UIP2P model. It shows four different edits applied to two example input captions, highlighting the model’s capacity to handle diverse and complex image transformations. Each example shows an input caption, an edit instruction, the resulting edited caption, and the instruction to reverse the edit, illustrating the cycle edit consistency (CEC) framework.
read the caption
Table 4: Examples of Four Possible Edits for Two Different Input Captions. Our dataset generation process showcases the flexibility of the reverse instruction dataset by demonstrating multiple transformations for the same caption.
| Input Caption | Edit Instruction | Edited Caption | Reverse Instruction |
|---|---|---|---|
| A dog sitting on a couch | change the dog’s color to brown | A brown dog sitting on a couch | change the dog’s color back to white |
| add a ball next to the dog | A dog sitting on a couch with a ball | remove the ball | |
| remove the dog | An empty couch | add the dog back | |
| move the dog to the floor | A dog sitting on the floor | move the dog back to the couch | |
| A car parked on the street | change the car color to red | A red car parked on the street | change the car color back to black |
| add a bicycle next to the car | A car parked on the street with a bicycle | remove the bicycle | |
| remove the car | An empty street | add the car back | |
| move the car to the garage | A car parked in the garage | move the car back to the street |
🔼 Table 5 presents a quantitative comparison of different image editing methods on the MagicBrush test dataset. It evaluates the performance of these methods across various metrics, including L1, L2, CLIP-I, DINO, and CLIP-T, providing a comprehensive assessment of their accuracy, visual fidelity, and semantic alignment. The table is divided into single-turn and multi-turn settings. In single-turn, the edits are performed in a single step. In the multi-turn setting, edits are applied iteratively, refining the image across multiple steps. The best results in each metric are highlighted in bold, offering a clear comparison of model performance across different scenarios.
read the caption
Table 5: Quantitative comparison on MagicBrush [50] test set. In the multi-turn setting, target images are iteratively edited from the initial source images. Best results are in bold.
Full paper#