↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
High-resolution image generation using diffusion transformers is slow due to the quadratic complexity of attention mechanisms. This significantly limits real-time applications and scalability. Existing efficient attention methods have limitations when applied to pre-trained models, hindering wider adoption.
The proposed CLEAR method uses a convolution-like local attention mechanism to linearize pre-trained diffusion transformers. This reduces computational complexity by 99.5% and boosts generation speed by 6.3 times for 8K images. Remarkably, it achieves comparable performance to the original model while demonstrating excellent zero-shot generalization and multi-GPU parallel inference capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation because it significantly accelerates high-resolution image generation using diffusion transformers. It addresses a critical bottleneck in current models, opening avenues for real-time and interactive applications. Its linear attention mechanism provides a highly efficient alternative, and its findings on cross-model and plugin generalizability are valuable for broader applications.
Visual Insights#

🔼 This figure showcases high-resolution images generated using the FLUX.1-dev model, enhanced with the CLEAR method. Each image’s dimensions are specified in the top right corner (width x height). The diverse range of images demonstrates the model’s ability to generate detailed and visually appealing outputs across various resolutions. The specific text prompts used to generate each image can be found in the appendix of the paper.
read the caption
Figure 1: Ultra-resolution results generated by the linearized FLUX.1-dev model with our approach CLEAR. Resolution is marked on the top-right corner of each result in the format of width×\times×height. Corresponding prompts can be found in the appendix.
| Method | Locality | Formulation | High-Rank Attention Maps | Feature Integrity |
|---|---|---|---|---|
| Linear Attention [12, 38, 65, 30] | Yes | No | No | Yes |
| Sigmoid Attention [48] | Yes | No | Yes | Yes |
| PixArt-Sigma [6] | Yes | Yes | Yes | No |
| Agent Attention [20] | Maybe | Yes | Yes | No |
| Strided Attention [7] | No | Yes | Yes | Yes |
| Swin Transformer [39] | Yes | Yes | No | Yes |
| Neighborhood Attention [21] | Yes | Yes | Yes | Yes |
🔼 This table categorizes several efficient attention mechanisms based on four key aspects that are essential for successfully linearizing pre-trained Diffusion Transformers (DiTs). These four crucial factors are locality, formulation consistency, high-rank attention maps, and feature integrity. Each method is evaluated based on whether it satisfies each of these four criteria (Yes/No/Maybe). This helps to understand which existing methods are suitable for linearizing pre-trained DiTs and highlights the specific design choices that are needed.
read the caption
Table 1: Summary of existing efficient attention mechanisms based on the four factors crucial for linearizing DiTs.
In-depth insights#
Linear DiT#
The concept of a “Linear DiT” suggests a significant advancement in diffusion transformer models. Standard DiTs suffer from quadratic complexity due to their attention mechanisms, limiting their scalability to high-resolution images. A Linear DiT directly addresses this limitation by employing linear attention mechanisms. This would drastically reduce computational costs and memory requirements, making the model significantly faster and more efficient, enabling processing of much larger images and potentially leading to improved generation quality. The research likely explores novel linear attention designs that preserve the representational power of the standard attention mechanism, and might discuss the trade-offs between computational efficiency and generation quality. Fine-tuning strategies are also crucial; methods to efficiently adapt a pre-trained DiT to a linear architecture with minimal performance loss are likely a core aspect of the work. Overall, a Linear DiT represents a key step toward more practical and scalable high-resolution image generation with diffusion transformers.
CLEAR’s Design#
CLEAR’s design is a convolution-like local attention mechanism for linearizing pre-trained diffusion transformers. It addresses the quadratic complexity of standard attention by limiting each query’s interaction to a local window of key-value tokens, achieving linear complexity with respect to image resolution. Locality is crucial; it leverages the inherent local dependencies in image data exploited by pre-trained models. The design also emphasizes formulation consistency, maintaining the softmax-based formulation of scaled dot-product attention for stability. The use of high-rank attention maps and preserving feature integrity are also essential to successful linearization, preventing information loss and maintaining image quality. This combination of design elements allows CLEAR to effectively transfer knowledge from a pre-trained DiT to a student model with linear complexity, resulting in significant speed and efficiency gains while maintaining comparable performance to the teacher model.
Empirical Results#
The Empirical Results section of a research paper is crucial for validating the claims made in the paper. A thoughtful analysis should go beyond simply stating the results. It should discuss the methodology used to collect the data, highlighting any limitations or potential biases. A good analysis will compare the results to those of similar studies, explaining any discrepancies and providing potential explanations. The statistical significance of findings should be clearly stated. Furthermore, the interpretation should connect back to the research questions and hypotheses, demonstrating how the findings support or refute them. It is also essential to discuss unexpected findings and their implications for future research. Finally, visualizations such as charts and graphs are important for communicating the results effectively and should be of high quality and easily understood. In short, the analysis must be thorough, objective, and insightful, providing a clear and compelling narrative that supports the overall conclusions of the research.
High-Res Scaling#
High-resolution image generation presents significant challenges for diffusion models. Scaling up resolution quadratically increases computational cost, rendering naive approaches impractical. Strategies for efficient high-res scaling often involve multi-scale processing or coarse-to-fine refinement, progressively building detail upon lower-resolution representations. However, these methods can compromise image coherence or introduce artifacts. An ideal approach would maintain linear complexity while preserving fine-grained detail and visual fidelity. This necessitates attention mechanisms that effectively leverage local information while efficiently handling long-range dependencies. Innovative architectures may be needed, potentially inspired by convolutional methods, to achieve this balance between efficiency and quality. Furthermore, addressing memory limitations, especially crucial at high resolutions, remains a central challenge. Successfully addressing high-res scaling will be key to broader adoption of diffusion models in demanding applications.
Future Work#
Future research could explore extending CLEAR’s applicability to diverse DiT architectures beyond the FLUX series. Investigating its performance with different pre-training datasets and evaluating its robustness across a wider range of image generation tasks would be beneficial. Addressing the computational overhead of text token aggregation in multi-GPU inference is crucial for maximizing efficiency at scale. This involves optimizing the text token processing for better parallelisation, potentially by leveraging more sophisticated techniques. Furthermore, deepening the analysis of the relationship between the size of the local window (r) and the overall image quality could lead to more effective hyperparameter tuning strategies. Finally, developing optimized CUDA kernels tailored to CLEAR’s unique sparse attention patterns would unlock its full hardware acceleration potential, resulting in faster and more efficient high-resolution image generation.
More visual insights#
More on figures

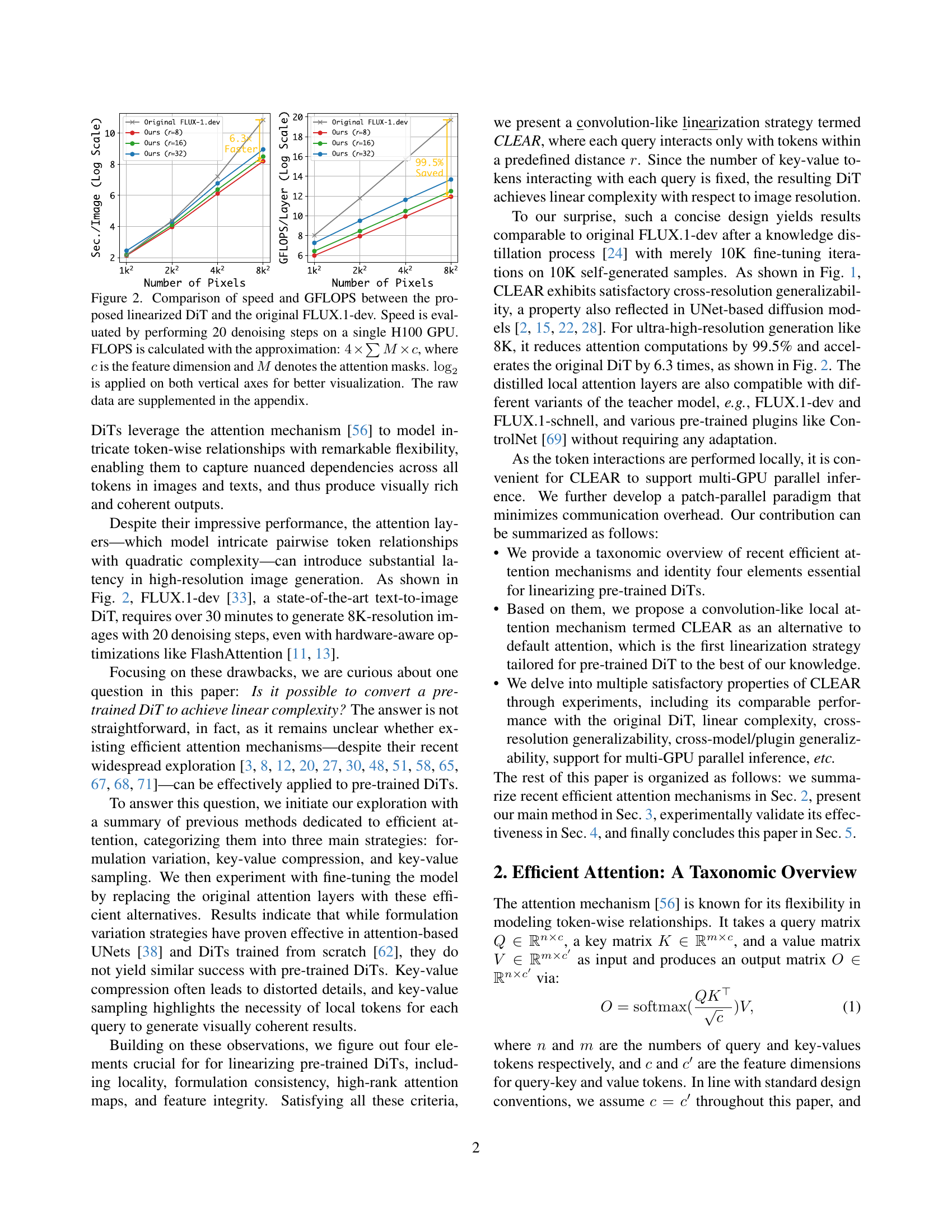
🔼 This figure compares the speed and computational cost (GFLOPS) of the proposed linearized Diffusion Transformer (DiT) model with the original FLUX.1-dev model. The speed is determined by measuring the time it takes to perform 20 denoising steps using a single NVIDIA H100 GPU. The GFLOPS (floating-point operations per second) calculation is an approximation using the formula 4 * ΣM * c, where ‘c’ is the feature dimension, and ‘M’ represents the attention masks. The logarithmic scale (log2) is used for both axes to enhance the visualization of the results. Raw data is available in the paper’s appendix.
read the caption
Figure 2: Comparison of speed and GFLOPS between the proposed linearized DiT and the original FLUX.1-dev. Speed is evaluated by performing 20 denoising steps on a single H100 GPU. FLOPS is calculated with the approximation: 4×∑M×c4𝑀𝑐4\times\sum M\times c4 × ∑ italic_M × italic_c, where c𝑐citalic_c is the feature dimension and M𝑀Mitalic_M denotes the attention masks. log2subscript2\log_{2}roman_log start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT is applied on both vertical axes for better visualization. The raw data are supplemented in the appendix.

🔼 This figure displays the results of different efficient attention mechanisms applied to the FLUX-1.dev model for image generation. Each method’s output image is shown, resulting from the same prompt: ‘A small blue plane sitting on top of a field’. This visualization allows for a qualitative comparison of the image quality and detail produced by each attention mechanism, highlighting the strengths and weaknesses of each approach in the context of pre-trained diffusion transformers.
read the caption
Figure 3: Preliminary results of various efficient attention methods on FLUX-1.dev. The prompt is “A small blue plane sitting on top of a field”.

🔼 This figure visualizes attention maps generated by different attention heads during an intermediate step in the denoising process of a diffusion model. Each attention map highlights the relationships between different tokens (representing image patches or text embeddings) within the model’s input. The visualization demonstrates that the attention mechanism in pre-trained diffusion transformers (DiTs) primarily focuses on local relationships, with most significant attention scores concentrated within a small spatial neighborhood of each query token. This observation supports the argument made by the authors that local attention patterns are key to successfully converting pretrained DiTs to linear complexity.
read the caption
Figure 4: Visualization of attention maps by various heads for an intermediate denoising step. Attention in pre-trained DiTs is largely conducted in a local fashion.

🔼 This figure demonstrates the importance of local features for image generation in diffusion transformers. Two experiments are shown: one where remote features (those far from the query token) are perturbed, and another where local features are perturbed. Perturbing remote features has minimal effect on the generated image quality. However, altering local features causes significant distortion, highlighting the crucial role of local feature interactions in preserving image quality. The experiment uses rotary position embedding to manipulate features, and the results are consistent with those presented in Figure 3.
read the caption
Figure 5: We try perturbing remote and local features respectively through clipping the relative distances required for rotary position embedding. Perturbing remote features has no obvious impact on image quality, whereas altering local features results in significant distortion. The text prompt and the original generation result are consistent with Fig. 3.

🔼 This figure illustrates the CLEAR (Convolution-like Linearization) method for efficient attention in Diffusion Transformers (DiTs). It shows how text queries in a text-image joint attention module access information from all text and image tokens, whereas image queries only interact with tokens within a localized circular window around them. This localized approach reduces the computational complexity of attention, making the model more efficient, especially for high-resolution images.
read the caption
Figure 6: Illustration of the proposed convolution-like linearization strategy for pre-trained DiTs. In each text-image joint attention module, text queries aggregate information from all text and image tokens, while each image token gathers information only from tokens within a local circular window.

🔼 This figure illustrates a method for enhancing multi-GPU parallel inference in the CLEAR model. Instead of each GPU processing all image tokens, each text query is only assigned tokens from its corresponding patch (a portion of the total image assigned to that GPU). This reduces communication overhead. After each GPU processes its patch, the attention results are averaged across all GPUs before generating the final image, effectively enabling high-quality image generation with significantly faster computation speed.
read the caption
Figure 7: To enhance multi-GPU parallel inference, each text query aggregates only the key-value tokens from the patch managed by its assigned GPU, then averages the attention results across all GPUs, which also generates high-quality images.

🔼 Figure 8 showcases qualitative comparisons between images generated by the original FLUX-1.dev model and its linearized version using the CLEAR method. The figure visually demonstrates the effectiveness of CLEAR in preserving image quality and detail while significantly reducing computational cost. Each image pair shares the same prompt, enabling a direct comparison of the outputs from both models. This allows for a clear assessment of the impact of CLEAR on the final image quality and visual fidelity.
read the caption
Figure 8: Qualitative examples by the linearized FLUX-1.dev models with CLEAR and the original model.

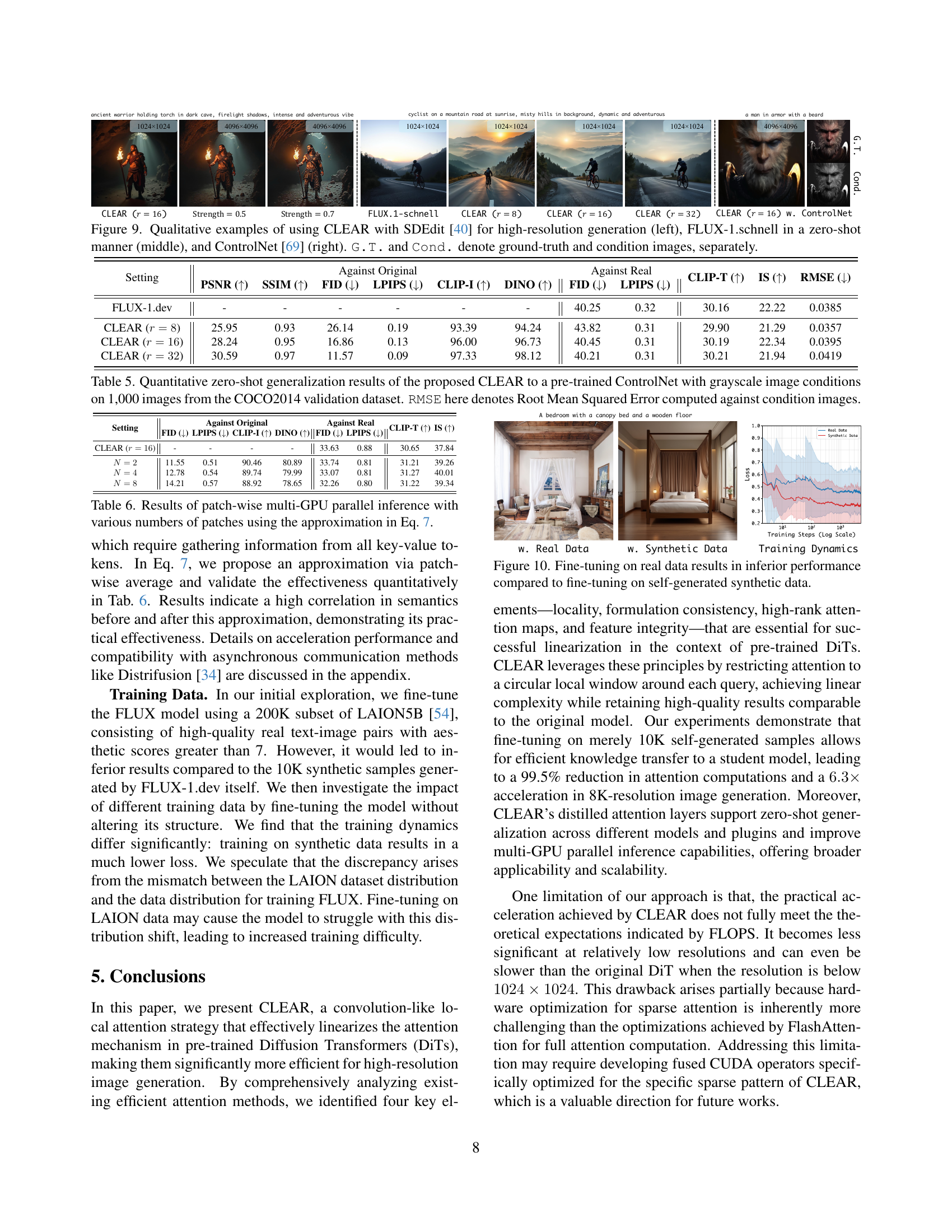
🔼 Figure 9 demonstrates the versatility of CLEAR, showcasing its application in three scenarios. The leftmost part illustrates CLEAR’s ability to enhance high-resolution image generation when combined with SDEdit [40], a method for upscaling images. The central section shows CLEAR’s zero-shot generalization capabilities, seamlessly integrating with FLUX-1.schnell without any additional training. Finally, the right side exhibits CLEAR’s compatibility with ControlNet [69], a plugin that allows for image-guided generation. Accompanying each scenario are ground truth (G.T.) and condition images for comparison.
read the caption
Figure 9: Qualitative examples of using CLEAR with SDEdit [40] for high-resolution generation (left), FLUX-1.schnell in a zero-shot manner (middle), and ControlNet [69] (right). G.T. and Cond. denote ground-truth and condition images, separately.

🔼 This figure shows a comparison of the training loss curves for fine-tuning a diffusion model using real data versus synthetic data generated by the model itself. The graph clearly illustrates that fine-tuning with synthetic data leads to significantly lower training loss and faster convergence compared to training with real data. This indicates that using self-generated synthetic data as training examples is more effective for optimizing and linearizing pre-trained diffusion transformers.
read the caption
Figure 10: Fine-tuning on real data results in inferior performance compared to fine-tuning on self-generated synthetic data.

🔼 This figure shows the training loss curves for several efficient attention mechanisms compared to the baseline FLUX-1.dev model. It illustrates the convergence speed and overall performance of different attention methods during the fine-tuning process on 10K self-generated samples for 10K iterations. The plot allows for a visual comparison of how effectively each attention mechanism learns to perform image denoising in a diffusion model.
read the caption
Figure 11: Training dynamics of various efficient attention alternatives on FLUX-1.dev.

🔼 Figure 12 demonstrates the compatibility of the CLEAR method with different high-resolution inference pipelines. It shows examples of images generated using the linearized diffusion transformers produced by CLEAR, and processed with image upscaling techniques like SDEdit and I-Max, demonstrating the effectiveness of CLEAR in generating high-resolution images through various pipelines.
read the caption
Figure 12: The linearized DiTs by CLEAR are compatible with various pipelines dedicated for high-resolution inference. The prompt is shown in Fig. 15.

🔼 Figure 13 presents a qualitative comparison of image generation results between the original FLUX-1.dev and Stable Diffusion 3.5-Large models and their corresponding versions modified with CLEAR (a proposed linearization technique). The top row shows results from FLUX-1.dev, while the bottom row displays results from Stable Diffusion 3.5-Large. For each model, the left-hand side shows images generated by the original model, whereas the right-hand side presents images generated by the CLEAR-linearized version. This visual comparison highlights the similarity in image quality between the original and linearized models, showcasing the effectiveness of CLEAR in maintaining performance while reducing computational complexity. The prompts used to generate these images are detailed in Figure 16.
read the caption
Figure 13: Qualitative comparisons on FLUX-1.dev (top) and SD3.5-Large (bottom). The left subplots are results by the original models while the right ones are by the CLEAR linearized models. Prompts are listed in Fig. 16.
More on tables
| Formulation | Consistency |
|---|
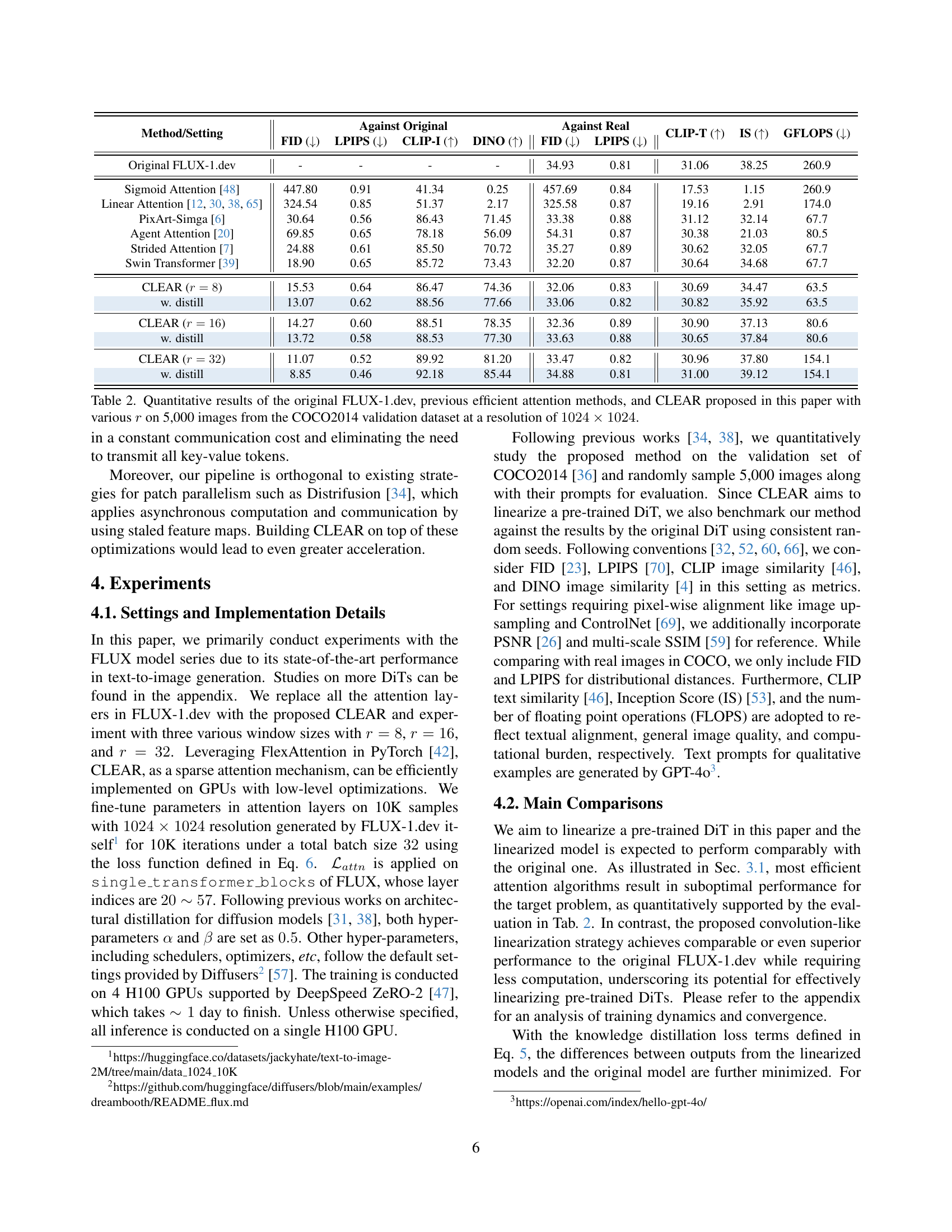
🔼 Table 2 presents a quantitative comparison of different text-to-image generation models. It evaluates the performance of the original FLUX-1.dev model against several other efficient attention mechanisms, including the proposed CLEAR method. The evaluation is performed using 5,000 images from the COCO2014 validation set, all at a resolution of 1024x1024 pixels. The results are presented in terms of several metrics: FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), CLIP-I (CLIP Image Similarity), DINO (DINO Image Similarity), and GFLOPS (floating point operations per second). Different values for the parameter ‘r’ (radius of the local attention window in the CLEAR method) are used to assess its performance. This allows analysis of the trade-off between computational efficiency and image quality across different model variations.
read the caption
Table 2: Quantitative results of the original FLUX-1.dev, previous efficient attention methods, and CLEAR proposed in this paper with various r𝑟ritalic_r on 5,000 images from the COCO2014 validation dataset at a resolution of 1024×1024102410241024\times 10241024 × 1024.
| High-Rank | Attention Maps |
|---|
🔼 This table presents a quantitative comparison of image generation performance between the original FLUX-1.dev model and the proposed CLEAR model at different resolutions (2048x2048 and 4096x4096). It shows the FID, LPIPS, CLIP-I, DINO, PSNR and SSIM scores for each model and different values of the radius parameter (r) used in the CLEAR model. These metrics assess the quality and fidelity of the generated images against ground truth images and the original model. The table helps demonstrate the effectiveness of CLEAR in producing high-resolution images while maintaining visual quality and reducing computational cost.
read the caption
Table 3: Quantitative results of the original FLUX-1.dev and our CLEAR with various r𝑟ritalic_r on 1,000 images from the COCO2014 validation dataset at resolutions of 2048×2048204820482048\times 20482048 × 2048 and 4096×4096409640964096\times 40964096 × 4096.
| Feature | Integrity |
|---|
🔼 This table presents the results of a zero-shot generalization experiment. The CLEAR (Convolution-like Linearization for Efficient Attention) layers, trained on the FLUX-1.dev model, were applied without further training to the FLUX-1.schnell model. The table evaluates the performance of this zero-shot transfer by comparing key metrics such as FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), CLIP-I (CLIP Image Similarity), and DINO (DINO Image Similarity) against the original FLUX-1.schnell model and the ground truth. This demonstrates the ability of the CLEAR method to generalize across different models.
read the caption
Table 4: Quantitative zero-shot generalization results to FLUX-1.schnell using CLEAR layers trained on FLUX-1.dev.
| Method/Setting | Against Original | Against Real | CLIP-T (↑) | IS (↑) | GFLOPS (↓) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Original FLUX-1.dev | - | - | - | - | 34.93 | 0.81 | 31.06 | 38.25 | 260.9 | |
| Sigmoid Attention [48] | 447.80 | 0.91 | 41.34 | 0.25 | 457.69 | 0.84 | 17.53 | 1.15 | 260.9 | |
| Linear Attention [12, 38, 65, 30] | 324.54 | 0.85 | 51.37 | 2.17 | 325.58 | 0.87 | 19.16 | 2.91 | 174.0 | |
| PixArt-Simga [6] | 30.64 | 0.56 | 86.43 | 71.45 | 33.38 | 0.88 | 31.12 | 32.14 | 67.7 | |
| Agent Attention [20] | 69.85 | 0.65 | 78.18 | 56.09 | 54.31 | 0.87 | 30.38 | 21.03 | 80.5 | |
| Strided Attention [7] | 24.88 | 0.61 | 85.50 | 70.72 | 35.27 | 0.89 | 30.62 | 32.05 | 67.7 | |
| Swin Transformer [39] | 18.90 | 0.65 | 85.72 | 73.43 | 32.20 | 0.87 | 30.64 | 34.68 | 67.7 | |
| CLEAR (r=8) | 15.53 | 0.64 | 86.47 | 74.36 | 32.06 | 0.83 | 30.69 | 34.47 | 63.5 | |
| w. distill | 13.07 | 0.62 | 88.56 | 77.66 | 33.06 | 0.82 | 30.82 | 35.92 | 63.5 | |
| CLEAR (r=16) | 14.27 | 0.60 | 88.51 | 78.35 | 32.36 | 0.89 | 30.90 | 37.13 | 80.6 | |
| w. distill | 13.72 | 0.58 | 88.53 | 77.30 | 33.63 | 0.88 | 30.65 | 37.84 | 80.6 | |
| CLEAR (r=32) | 11.07 | 0.52 | 89.92 | 81.20 | 33.47 | 0.82 | 30.96 | 37.80 | 154.1 | |
| w. distill | 8.85 | 0.46 | 92.18 | 85.44 | 34.88 | 0.81 | 31.00 | 39.12 | 154.1 |
🔼 This table presents the results of a zero-shot generalization experiment. The model CLEAR, which uses a convolution-like local attention mechanism, is evaluated on its ability to work with a pre-trained ControlNet plugin. The experiment uses grayscale images as input conditions, and the performance is assessed using standard metrics for image generation: FID, LPIPS, CLIP-I, DINO, CLIP-T, IS, and RMSE. The metrics compare the generated images to both the original images and to the grayscale condition images. The RMSE (Root Mean Squared Error) specifically measures the difference between the generated image and the grayscale condition image. The data is based on 1,000 images from the COCO2014 validation dataset, and the table demonstrates that CLEAR generalizes well to the ControlNet plugin without any fine-tuning on the new dataset.
read the caption
Table 5: Quantitative zero-shot generalization results of the proposed CLEAR to a pre-trained ControlNet with grayscale image conditions on 1,000 images from the COCO2014 validation dataset. RMSE here denotes Root Mean Squared Error computed against condition images.
| Setting | PSNR (↑) | SSIM (↑) | FID (↓) | LPIPS (↓) | CLIP-I (↑) | DINO (↑) | CLIP-T (↑) | IS (↑) | GFLOPS (↓) |
|---|---|---|---|---|---|---|---|---|---|
| –1024×1024→2048×2048– | |||||||||
| FLUX-1.dev | - | - | - | - | - | - | 31.11 | 24.53 | 3507.9 |
| CLEAR (r=8) | 27.57 | 0.91 | 13.55 | 0.12 | 98.97 | 98.37 | 31.09 | 25.05 | 246.2 |
| CLEAR (r=16) | 27.60 | 0.92 | 13.43 | 0.12 | 98.97 | 98.34 | 31.08 | 25.46 | 352.6 |
| CLEAR (r=32) | 28.95 | 0.94 | 10.87 | 0.10 | 99.23 | 98.82 | 31.09 | 25.48 | 724.3 |
| –2048×2048→4096×4096– | |||||||||
| FLUX-1.dev | - | - | - | - | - | - | 31.29 | 24.36 | 53604.4 |
| CLEAR (r=8) | 26.19 | 0.87 | 20.87 | 0.22 | 98.02 | 96.56 | 31.16 | 25.87 | 979.3 |
| CLEAR (r=16) | 26.98 | 0.88 | 16.20 | 0.19 | 98.48 | 97.64 | 31.25 | 25.13 | 1433.2 |
| CLEAR (r=32) | 27.70 | 0.90 | 13.56 | 0.17 | 98.72 | 98.21 | 31.20 | 24.81 | 3141.7 |
🔼 This table presents the results of a multi-GPU parallel inference experiment using the CLEAR method. The experiment varies the number of image patches distributed across multiple GPUs. A key aspect is the use of an approximation (Equation 7 from the paper) to aggregate attention results from each GPU for text tokens, which is crucial for efficient parallel processing. The table shows the effect of this approximation on the performance of the model as the number of GPUs increases, demonstrating the scalability of the CLEAR approach for high-resolution image generation.
read the caption
Table 6: Results of patch-wise multi-GPU parallel inference with various numbers of patches using the approximation in Eq. 7.
| Setting | Against Original | Against Real | CLIP-T (↑) | IS (↑) | ||||
|---|---|---|---|---|---|---|---|---|
| FID (↓) | LPIPS (↓) | CLIP-I (↑) | DINO (↑) | FID (↓) | LPIPS (↓) | |||
| — | — | — | — | — | — | — | — | — |
| FLUX-1.dev | - | - | - | - | 29.19 | 0.83 | 31.53 | 36.41 |
| CLEAR (r=8) | 13.62 | 0.62 | 88.91 | 78.36 | 33.51 | 0.81 | 31.35 | 38.42 |
| CLEAR (r=16) | 12.51 | 0.58 | 90.43 | 81.32 | 34.43 | 0.82 | 31.38 | 39.66 |
| CLEAR (r=32) | 12.43 | 0.57 | 90.70 | 82.61 | 33.57 | 0.83 | 31.48 | 39.68 |
🔼 This table provides the detailed numerical data used to generate Figure 2 in the paper. Figure 2 visually compares the speed and computational cost (GFLOPS) of the proposed linearized DiT model with the original FLUX-1-dev model across different image resolutions. This table offers the underlying raw data points used to create that figure, allowing for a more precise and detailed understanding of the performance improvements achieved through linearization. The data includes the execution time in seconds per image and the GFLOPS per layer for each model and resolution.
read the caption
Table 7: Raw data for Fig. 2 on efficiency comparisons.
| Setting | PSNR (↑) | SSIM (↑) | FID (↓) | LPIPS (↓) | CLIP-I (↑) | DINO (↑) | Against Real FID (↓) | Against Real LPIPS (↓) | CLIP-T (↑) | IS (↑) | RMSE (↓) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FLUX-1.dev | - | - | - | - | - | - | 40.25 | 0.32 | 30.16 | 22.22 | 0.0385 |
| CLEAR (r=8) | 25.95 | 0.93 | 26.14 | 0.19 | 93.39 | 94.24 | 43.82 | 0.31 | 29.90 | 21.29 | 0.0357 |
| CLEAR (r=16) | 28.24 | 0.95 | 16.86 | 0.13 | 96.00 | 96.73 | 40.45 | 0.31 | 30.19 | 22.34 | 0.0395 |
| CLEAR (r=32) | 30.59 | 0.97 | 11.57 | 0.09 | 97.33 | 98.12 | 40.21 | 0.31 | 30.21 | 21.94 | 0.0419 |
🔼 This table presents a quantitative comparison of the performance of the original Stable Diffusion 3.5-Large (SD3.5-Large) model and its version linearized using the CLEAR method. The evaluation is based on 5,000 images from the COCO2014 validation dataset, all at a resolution of 1024x1024 pixels. The comparison uses several metrics to assess both the visual quality and the efficiency of the models. These metrics likely include FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), CLIP (Contrastive Language–Image Pre-training) scores for image-text similarity, and potentially others to evaluate generation quality. Furthermore, it likely includes computational metrics such as GFLOPS (floating-point operations per second) indicating the computational efficiency of each model.
read the caption
Table 8: Quantitative results of the original SD3-Large and its linearized version by CLEAR proposed in this paper on 5,000 images from the COCO2014 validation dataset at a resolution of 1024×1024102410241024\times 10241024 × 1024.
| Setting | Against Original | Against Real | CLIP-T (↑) | IS (↑) | ||
|---|---|---|---|---|---|---|
| FID (↓) | LPIPS (↓) | CLIP-I (↑) | DINO (↑) | FID (↓) | LPIPS (↓) | |
| — | — | — | — | — | — | — |
| CLEAR (r=16) | - | - | - | - | 33.63 | 0.88 |
| N=2 | 11.55 | 0.51 | 90.46 | 80.89 | 33.74 | 0.81 |
| N=4 | 12.78 | 0.54 | 89.74 | 79.99 | 33.07 | 0.81 |
| N=8 | 14.21 | 0.57 | 88.92 | 78.65 | 32.26 | 0.80 |
🔼 This table presents a quantitative evaluation of CLEAR’s zero-shot generalization capabilities when used with a pre-trained ControlNet model. Two types of conditional images were tested: tiled images and blurred images. The evaluation is performed on 1000 images from the COCO2014 validation set. The metrics used include FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), CLIP-I (CLIP Image Similarity), DINO (DINO Image Similarity), and RMSE (Root Mean Squared Error), which is computed against the conditional images. This shows how well CLEAR maintains image quality and alignment with the ControlNet when it has not been specifically trained for these conditions. Lower FID and LPIPS scores indicate better visual quality compared to the original, higher CLIP-I and DINO scores indicate better similarity, while a lower RMSE indicates better alignment with the condition image.
read the caption
Table 9: Quantitative zero-shot generalization results of the proposed CLEAR to a pre-trained ControlNet with tiled image conditions and blur image conditions on 1,000 images from the COCO2014 validation dataset. RMSE here denotes Root Mean Squared Error computed against condition images.
| Setting | Running Time (Sec. / 50 Steps) | TFLOPS / Layer | ||||||
|---|---|---|---|---|---|---|---|---|
| 1024x1024 | 2048x2048 | 4096x4096 | 8192x8192 | 1024x1024 | 2048x2048 | 4096x4096 | 8192x8192 | |
| Setting | ||||||||
| FLUX-1.dev | 4.45 | 20.90 | 148.97 | 1842.48 | 0.26 | 3.51 | 53.60 | 847.73 |
| CLEAR (r=8) | 4.40 | 15.67 | 69.41 | 293.50 | 0.06 | 0.25 | 0.98 | 3.92 |
| CLEAR (r=16) | 4.56 | 17.19 | 83.13 | 360.83 | 0.09 | 0.35 | 1.43 | 5.79 |
| CLEAR (r=32) | 5.45 | 19.95 | 109.57 | 496.22 | 0.15 | 0.72 | 3.14 | 13.09 |
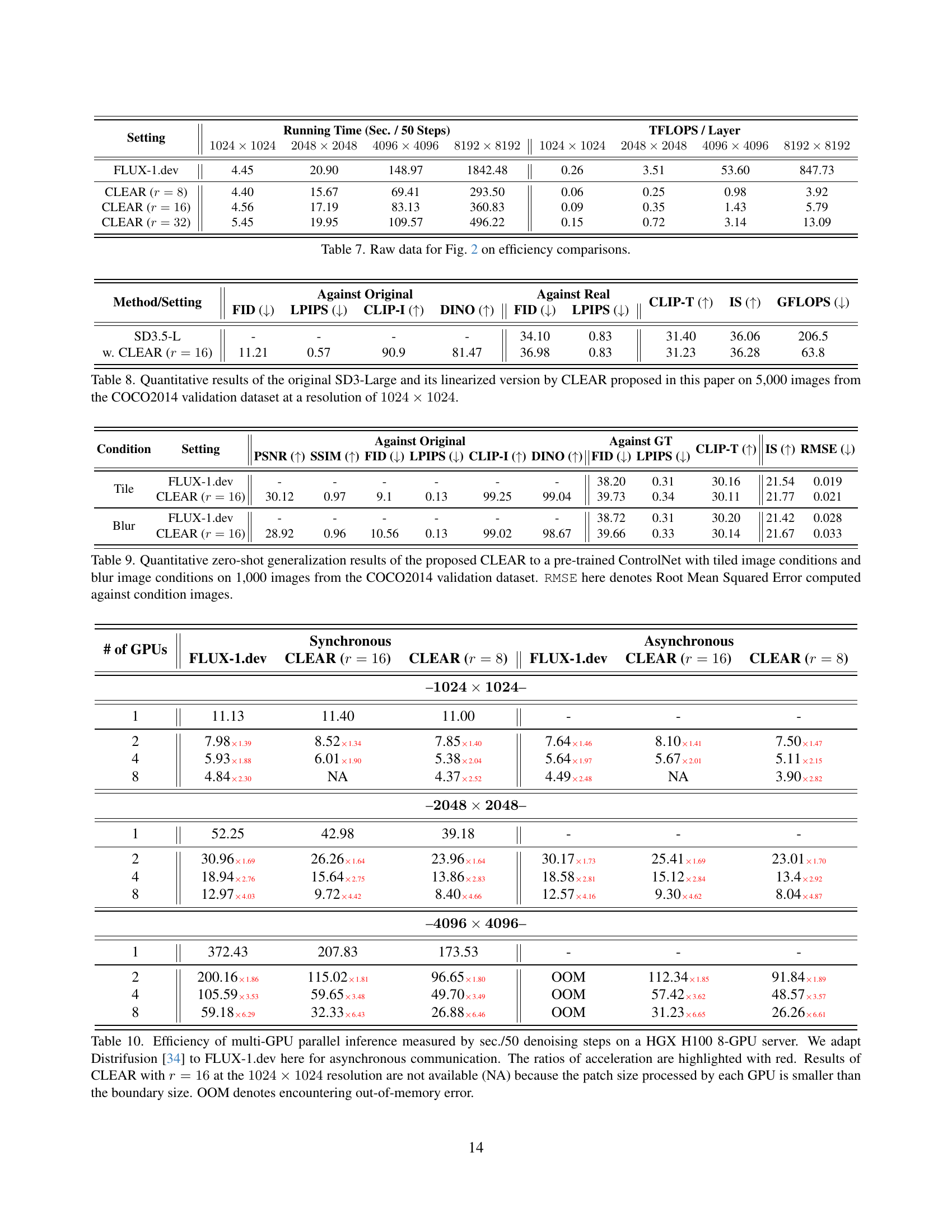
🔼 This table presents a performance comparison of multi-GPU parallel inference for image generation using different models and settings. The metric is the time taken (in seconds) to complete 50 denoising steps. The models compared include the original FLUX-1.dev model and its variants using the CLEAR method with different radius values (r=8, r=16, r=32). The experiments were conducted on an 8-GPU HGX H100 server, employing asynchronous communication as implemented in Distrifusion [34]. The table shows the speedup achieved by using multiple GPUs. Note that results for the CLEAR method with r=16 at a resolution of 1024x1024 are not provided because, at this resolution, the patch size was smaller than the GPU boundary size. ‘OOM’ indicates cases where the memory capacity of the GPU was exceeded. Speedup factors are highlighted in red.
read the caption
Table 10: Efficiency of multi-GPU parallel inference measured by sec./50 denoising steps on a HGX H100 8-GPU server. We adapt Distrifusion [34] to FLUX-1.dev here for asynchronous communication. The ratios of acceleration are highlighted with red. Results of CLEAR with r=16𝑟16r=16italic_r = 16 at the 1024×1024102410241024\times 10241024 × 1024 resolution are not available (NA) because the patch size processed by each GPU is smaller than the boundary size. OOM denotes encountering out-of-memory error.
Full paper#