↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current generative AI models are not well-suited for educational applications, lacking the pedagogical behavior of human tutors. This paper introduces LearnLM, a novel approach to address this limitation by focusing on “pedagogical instruction following.” Instead of hard-coding specific pedagogical behaviors, LearnLM trains the model to follow instructions describing the desired pedagogical attributes. This flexible method avoids committing to a particular definition of pedagogy and allows educators to customize AI tutor behavior.
LearnLM, based on Gemini 1.5 Pro, shows substantial improvement over existing models in various learning scenarios as evaluated by expert raters. The improvements are statistically significant. The project demonstrates that adding pedagogical data to post-training mixtures effectively enhances model performance. The study also includes a feasibility study on medical education, indicating potential applications beyond general education. The updated evaluation methodology, which emphasizes scenario-based evaluations and human feedback, adds rigor and practical relevance to the findings.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to improving AI models for educational purposes. It directly addresses the challenge of injecting pedagogical behavior into AI tutors, offering a solution that is both flexible and scalable. The findings provide valuable insights for researchers working on AI-driven education and open new avenues for future investigation in this rapidly evolving field. The proposed method is particularly valuable due to its focus on pedagogical instruction following rather than predefining specific pedagogical behaviors, and is demonstrated to improve AI tutor preference across diverse scenarios.
Visual Insights#

🔼 This figure presents a three-stage human evaluation pipeline used to compare LearnLM’s performance against other large language models (LLMs) in educational settings. Stage 1 involves creating diverse learning scenarios where human raters simulate learners interacting with pairs of AI tutors. Each scenario includes background materials (like essays or diagrams) and specific system instructions for the AI. Stage 2 consists of collecting the conversations generated by each LLM in response to these scenarios. In the final stage, pedagogy experts assess these conversations, providing both individual ratings and comparative ratings on a seven-point Likert scale (-3 to +3). These ratings are then aggregated to calculate the overall preference for each LLM, demonstrating LearnLM’s superior performance compared to GPT-40, Claude 3.5, and Gemini 1.5 Pro.
read the caption
Figure 1: An overview of our three-stage human evaluation pipeline and our results for comparing LearnLM with other systems. (1) Learning scenarios are developed that allow raters to role-play specific learners interacting with pairs of AI tutors (2). Grounding material (e.g. an essay, homework problem, diagram, etc.) and System Instructions specific to each scenario are passed as context to each model. The resulting conversation pairs are reviewed by pedagogy experts (3) who answer a range of questions assessing each model on its own as well as their comparative performance. These comparative ratings (on a seven-point -3 to +3 Likert scale) are aggregated (4) to show overall preference for LearnLM over GPT-4o, Claude 3.5, and Gemini 1.5 Pro. See Section 4 for more detailed results.
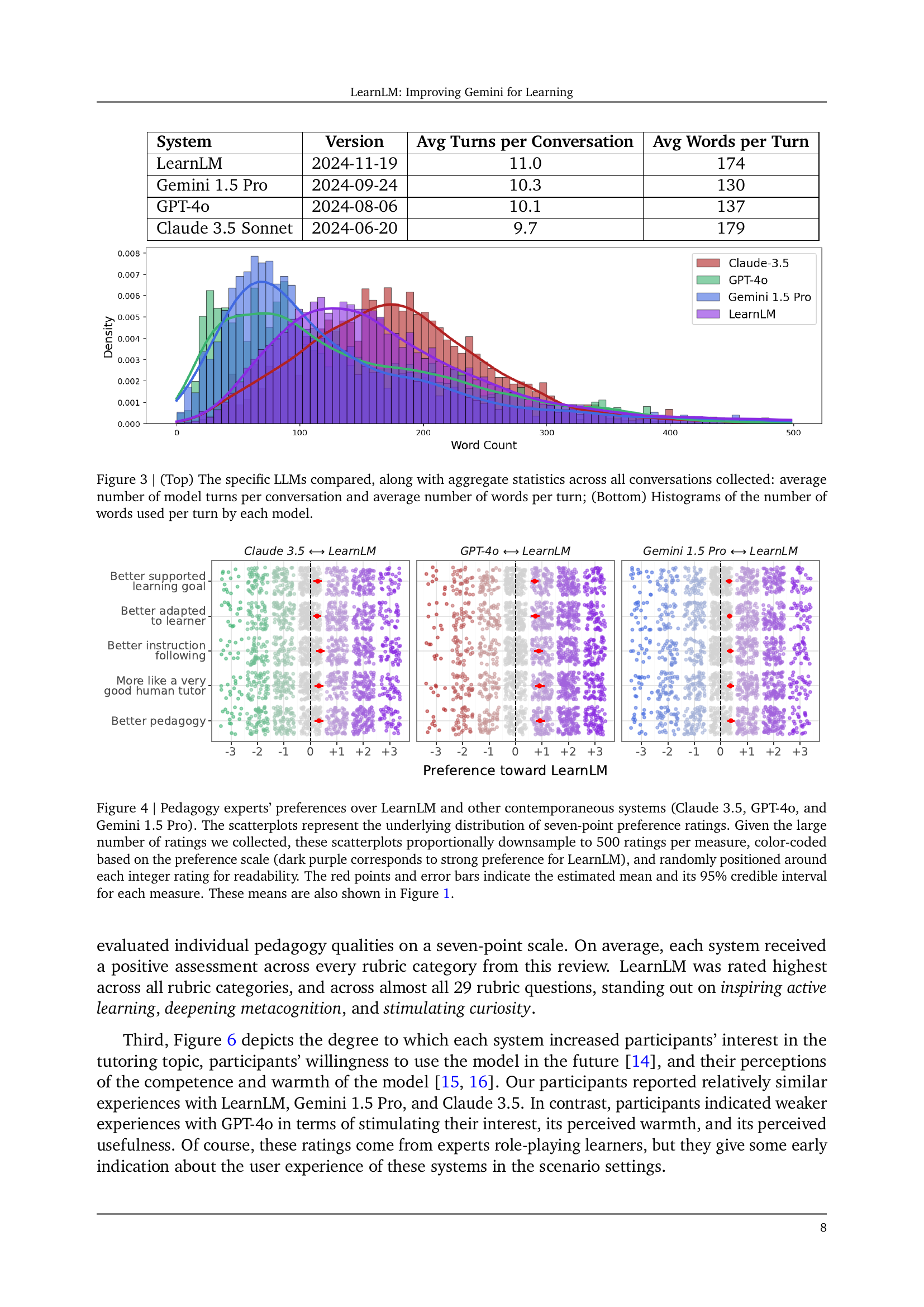
| System | Version | Avg Turns per Conversation | Avg Words per Turn |
|---|---|---|---|
| LearnLM | 2024-11-19 | 11.0 | 174 |
| Gemini 1.5 Pro | 2024-09-24 | 10.3 | 130 |
| GPT-4o | 2024-08-06 | 10.1 | 137 |
| Claude 3.5 Sonnet | 2024-06-20 | 9.7 | 179 |
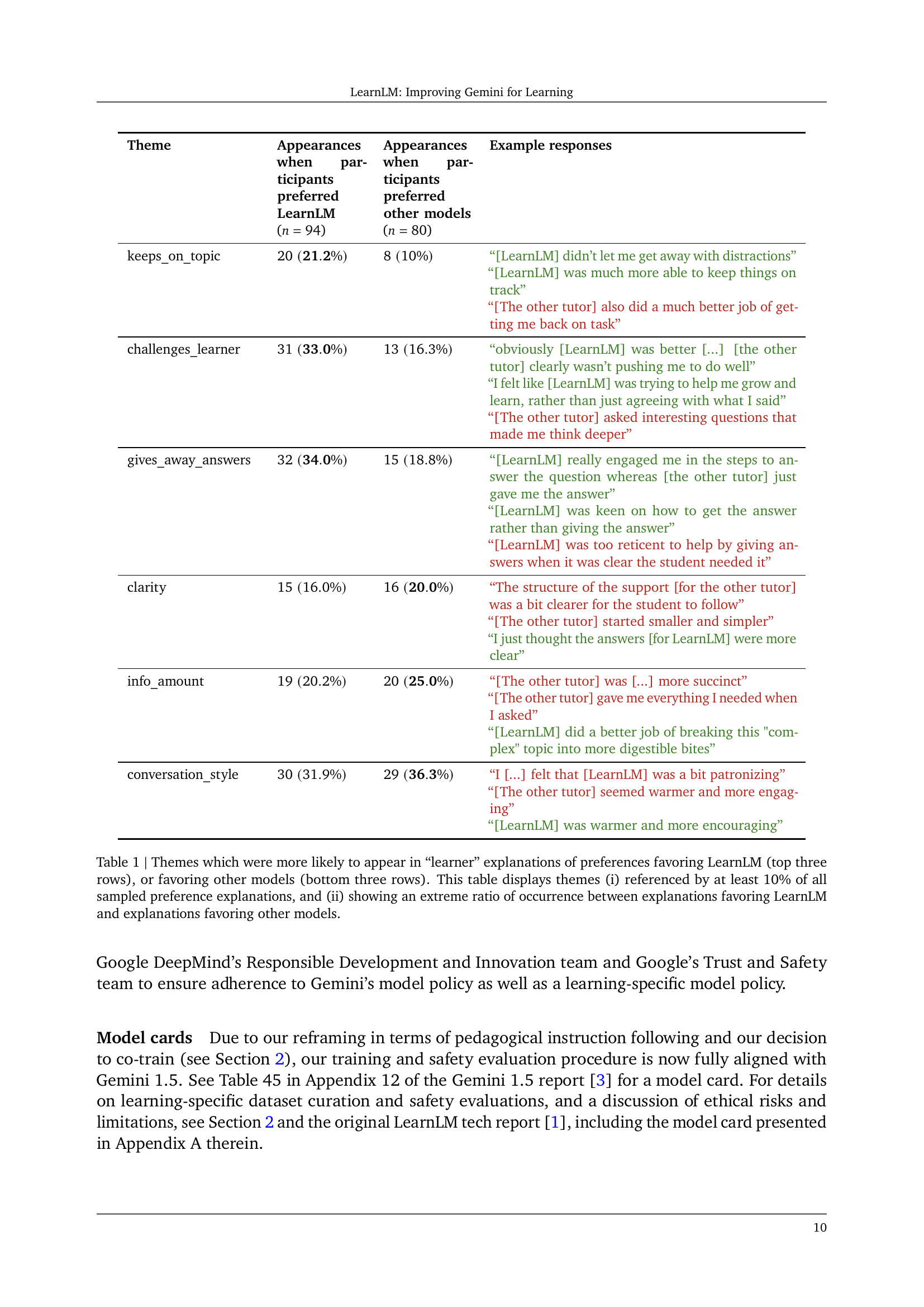
🔼 This table presents a qualitative analysis of user feedback on why they preferred LearnLM or other models. It shows themes that emerged frequently in responses, categorized by whether users preferred LearnLM or another model. Only themes present in at least 10% of responses and exhibiting a significant difference in frequency between LearnLM and other model preferences are included. The table helps understand the specific aspects of LearnLM (e.g., its ability to keep conversations on-topic, challenge learners appropriately, or avoid giving away answers) that contributed to user preference.
read the caption
Table 1: Themes which were more likely to appear in “learner” explanations of preferences favoring LearnLM (top three rows), or favoring other models (bottom three rows). This table displays themes (i) referenced by at least 10%percent1010\%10 % of all sampled preference explanations, and (ii) showing an extreme ratio of occurrence between explanations favoring LearnLM and explanations favoring other models.
In-depth insights#
Pedagogical Instruction#
The concept of “Pedagogical Instruction” in AI-driven learning systems is crucial. The authors reframe the challenge of integrating pedagogical behavior not as defining pedagogy itself, but rather as instruction following. This allows for flexibility and avoids rigid definitions, enabling teachers and developers to specify desired attributes in system interactions. The approach involves training the model with examples that clearly illustrate the intended pedagogical style, ensuring the system learns to respond appropriately to those instructions. This method represents a significant shift from previous attempts, emphasizing adaptability and user control. The evaluation process uses human raters to assess model performance, comparing different AI systems based on their adherence to specified pedagogical instructions. This data-driven approach to evaluation proves effective in demonstrating the preference for the LearnLM model in various learning scenarios.
LearnLM Training#
LearnLM’s training methodology represents a significant departure from prior approaches by focusing on pedagogical instruction following. Instead of explicitly programming pedagogical behavior into the model, LearnLM is trained on examples that include system-level instructions specifying the desired teaching style. This allows for greater flexibility and avoids constraining the model to a single definition of effective pedagogy. The training incorporates reinforcement learning from human feedback (RLHF), using human preferences to guide the model’s learning of nuanced pedagogical behaviors. This iterative approach, combined with a co-training strategy that integrates LearnLM’s pedagogical data with Gemini’s existing training, results in a model that significantly outperforms existing LLMs in various learning scenarios. The use of diverse and nuanced system-level instructions during training ensures that LearnLM can adapt to various educational contexts and preferences. The overall approach emphasizes the importance of developer and teacher control over the specific pedagogical behaviors implemented in AI learning systems.
Human Evaluation#
The effectiveness of the LearnLM model hinges on human evaluation, a crucial aspect highlighted in the research. The evaluation methodology is meticulously designed, employing a three-stage process. Initially, diverse learning scenarios are curated. These scenarios are then enacted by human participants, simulating real-world learner interactions with the AI system. Finally, expert raters evaluate the conversations, assessing pedagogical quality across various dimensions. This multi-layered approach ensures a robust assessment that goes beyond simple accuracy checks, considering learner engagement, clarity of instructions, and the overall effectiveness of the tutoring experience. The focus on comparative analysis, contrasting LearnLM with other LLMs, further strengthens the findings. The use of Bayesian statistics provides a robust framework for quantifying and interpreting the results, minimizing biases and providing a solid base for further improvements. The involvement of pedagogy experts ensures that the evaluation aligns with established educational principles and provides valuable insights into the practical application of AI in learning contexts. The detailed evaluation design enhances the reliability and generalizability of the study’s conclusions. Overall, the human evaluation process forms the backbone of the LearnLM assessment, giving considerable weight to human judgment in determining AI tutor effectiveness.
Co-training Benefits#
Co-training, in the context of the LearnLM model, offers significant advantages. By combining pedagogical data with Gemini’s existing training data, LearnLM avoids narrow definitions of pedagogy, allowing for flexible adaptation to various learning scenarios and avoiding potential conflicts in teaching styles. This method enables incremental improvement of the model without discarding core capabilities like reasoning and factual accuracy. The result is a model that can effectively integrate pedagogical instructions while retaining its broader strengths. Co-training facilitates continuous model enhancement as new data and refinements are incorporated, leading to a more robust and versatile system. This approach also ensures that LearnLM remains compatible with updates to the underlying Gemini models, ensuring long-term sustainability and consistent improvement. The co-training strategy highlights a pragmatic approach to integrating pedagogical information in a way that’s scalable and effective, demonstrating a key advancement in AI-driven learning systems.
Future Work#
The authors outline several crucial areas for future research. Improving the pedagogical assessment framework is paramount, aiming for broader consensus and wider acceptance within the education community. This involves transitioning from intrinsic evaluations (measuring model performance against predefined standards) to extrinsic evaluations focusing on actual learning outcomes, a significantly more challenging but ultimately more impactful metric. Expanding the evaluation beyond core academic subjects is also critical, particularly into medical education and other specialized fields. This necessitates carefully designed scenarios and assessments specific to these diverse contexts. Finally, refined human-in-the-loop methodologies are needed, potentially leveraging crowdsourced data for larger-scale feedback and continuous model improvement. This is important to further gauge and refine both model capabilities and actual user experiences.
More visual insights#
More on figures

🔼 This figure illustrates the three-stage human evaluation pipeline used in the study. First, scenarios are created that define the context of an interaction between a human learner (played by a participant) and an AI tutor (represented by two different LLMs). These scenarios include specifics such as learner personas, learning goals, and system instructions that specify desired pedagogical behaviors. Second, participants role-play as learners within the defined scenarios, engaging in conversations with each of the AI tutors. Third, raters assess the conversations, providing comparative ratings across different models based on various pedagogical criteria. This allows quantitative analysis of the relative quality and preference for different LLMs in educational settings.
read the caption
Figure 2: Workflow to generate conversations based on educational scenarios. A participant enacts conversations with prompted models as defined by scenarios. The participant then fills out a survey capturing quality and preference between models.

🔼 This figure displays a comparison of four large language models (LLMs): LearnLM, Gemini 1.5 Pro, GPT-40, and Claude 3.5 Sonnet. The top panel presents aggregate statistics from conversations involving these LLMs, specifically the average number of turns per conversation and the average number of words used per turn. The bottom panel provides histograms illustrating the distribution of the number of words used per turn for each LLM, offering a visual representation of the variation in response length for each model.
read the caption
Figure 3: (Top) The specific LLMs compared, along with aggregate statistics across all conversations collected: average number of model turns per conversation and average number of words per turn; (Bottom) Histograms of the number of words used per turn by each model.

🔼 Figure 4 presents a comparison of user preferences for LearnLM against three other large language models: Claude 3.5, GPT-40, and Gemini 1.5 Pro. Expert raters provided seven-point preference ratings across various pedagogical aspects. Due to the large number of ratings, the scatter plots display a proportionally downsampled set of 500 ratings per measure for clarity. The color intensity represents the strength of preference for LearnLM (dark purple indicates strong preference). Red points and error bars show the average preference and 95% credible intervals. These averages are also summarized in Figure 1.
read the caption
Figure 4: Pedagogy experts’ preferences over LearnLM and other contemporaneous systems (Claude 3.5, GPT-4o, and Gemini 1.5 Pro). The scatterplots represent the underlying distribution of seven-point preference ratings. Given the large number of ratings we collected, these scatterplots proportionally downsample to 500 ratings per measure, color-coded based on the preference scale (dark purple corresponds to strong preference for LearnLM), and randomly positioned around each integer rating for readability. The red points and error bars indicate the estimated mean and its 95% credible interval for each measure. These means are also shown in Figure 1.

🔼 Figure 5 presents a detailed comparison of four different AI models (LearnLM, GPT-40, Claude 3.5, and Gemini 1.5 Pro) across various pedagogical aspects. Each model’s performance is assessed using a 7-point Likert scale ranging from ‘Strongly disagree’ to ‘Strongly agree.’ The evaluation covers several key pedagogical criteria, allowing for a nuanced comparison of the models’ strengths and weaknesses in different areas of instructional effectiveness. Error bars are included to represent the 95% credible intervals derived from the posterior distribution, adding a layer of statistical confidence to the results and conveying the uncertainty inherent in the evaluation process.
read the caption
Figure 5: Evaluation of systems on each category of our pedagogy rubric from a 7-point Likert scale ('Strongly disagree' to 'Strongly agree'). Error bars reflect 95% credible intervals from the posterior distrubtion for the mean.

🔼 Figure 6 presents the results of human evaluation on AI tutors’ impact on learner impressions and experiences. The left side shows impressions using a 5-point scale (‘Not at all’ to ‘Extremely’), while the right side shows experiences using a 7-point Likert scale (‘Strongly disagree’ to ‘Strongly agree’). Each bar represents the average rating, with error bars indicating the 95% credible interval, reflecting the uncertainty in the estimate. The figure illustrates the relative effectiveness of different AI models in terms of learner interest, perceived competence and warmth of the AI tutor, and willingness to use the AI tutor again.
read the caption
Figure 6: Impressions shared by the pedagogy experts role-playing as learners in our pedagogical scenarios. Error bars reflect 95% credible intervals from the posterior distribution for the mean. The rating scales for impression questions (left) were 5-point extent scales (“Not at all” to “Extremely”), and 7-point Likert scales (“Strongly disagree” to “Strongly agree”) for experience questions (right).

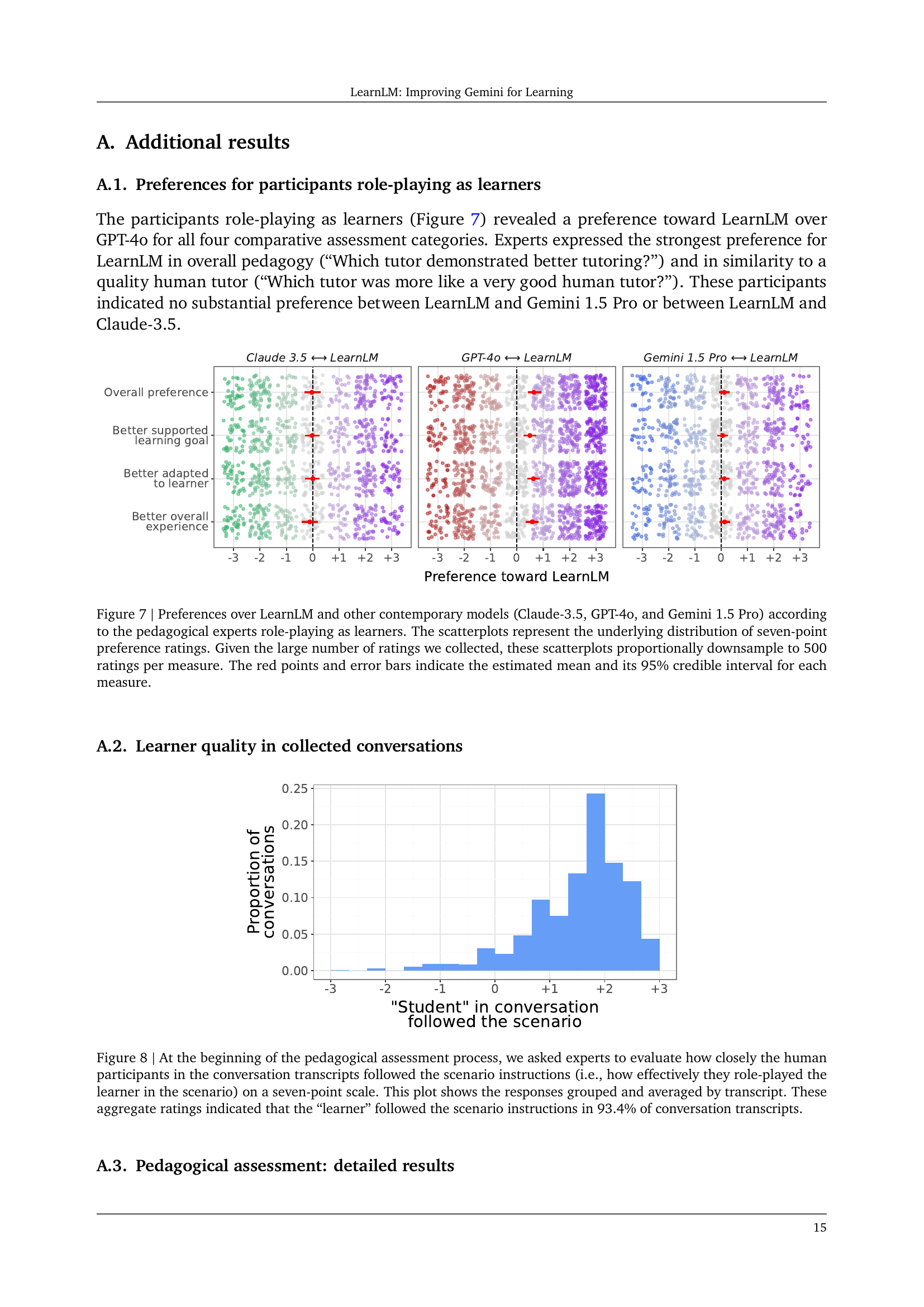
🔼 Figure 7 presents a comparative analysis of user preferences among LearnLM and three other leading language models (Claude-3.5, GPT-40, and Gemini 1.5 Pro) in educational scenarios. Pedagogical experts, acting as learners, provided seven-point Likert scale ratings reflecting their preferences. Due to the extensive dataset, the scatterplots are created with a proportional downsampling of 500 ratings per assessment category. The plots visually depict the distribution of these ratings, highlighting the average preference towards LearnLM (indicated by red points) and quantifying the uncertainty using 95% credible intervals (error bars). The figure provides a clear visual summary of the comparative performance of LearnLM.
read the caption
Figure 7: Preferences over LearnLM and other contemporary models (Claude-3.5, GPT-4o, and Gemini 1.5 Pro) according to the pedagogical experts role-playing as learners. The scatterplots represent the underlying distribution of seven-point preference ratings. Given the large number of ratings we collected, these scatterplots proportionally downsample to 500 ratings per measure. The red points and error bars indicate the estimated mean and its 95% credible interval for each measure.

🔼 This figure displays the distribution of ratings indicating how well human participants followed the instructions of the scenarios in the conversation collection phase of the study. Experts evaluated each conversation transcript on a seven-point Likert scale, rating how effectively the participant role-played the designated learner persona within the scenario. The aggregated results show that participants adhered to the scenario instructions in 93.4% of the conversation transcripts.
read the caption
Figure 8: At the beginning of the pedagogical assessment process, we asked experts to evaluate how closely the human participants in the conversation transcripts followed the scenario instructions (i.e., how effectively they role-played the learner in the scenario) on a seven-point scale. This plot shows the responses grouped and averaged by transcript. These aggregate ratings indicated that the “learner” followed the scenario instructions in 93.4% of conversation transcripts.

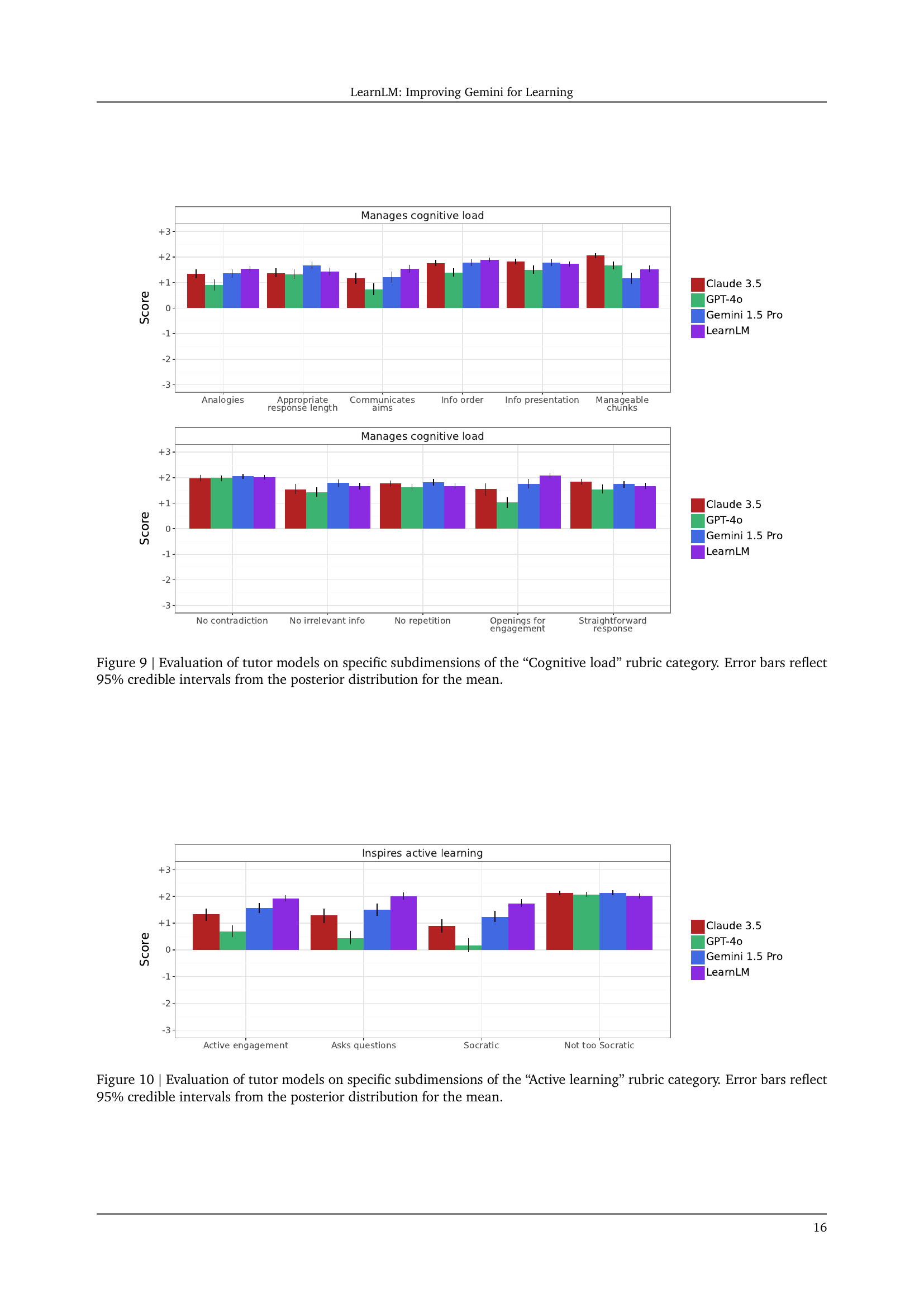
🔼 This figure displays the performance of different AI tutor models across various aspects contributing to the ‘Cognitive Load’ in a learning scenario. The x-axis lists these specific sub-dimensions of cognitive load, such as appropriate response length, use of analogies, clear communication, and organization of information. The y-axis represents the score, indicating the model’s effectiveness in managing cognitive load along that specific dimension. The bars represent the average score for each model (LearnLM, GPT-40, Claude 3.5, Gemini 1.5 Pro), and the error bars show the 95% credible interval, reflecting the uncertainty in the estimates. This visualization helps to understand the strengths and weaknesses of each model in terms of minimizing cognitive load and improving the learning experience.
read the caption
Figure 9: Evaluation of tutor models on specific subdimensions of the “Cognitive load” rubric category. Error bars reflect 95% credible intervals from the posterior distribution for the mean.

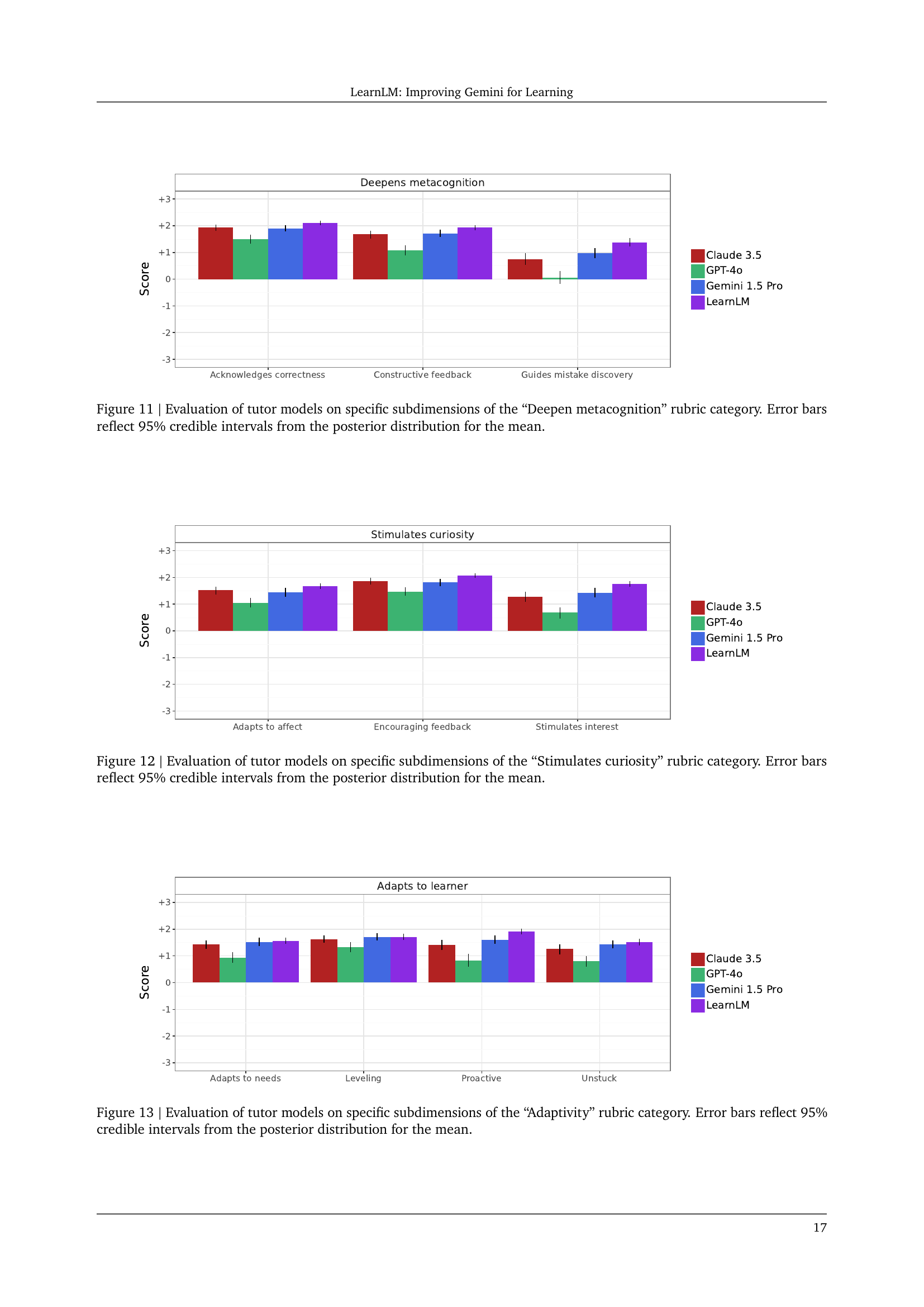
🔼 This figure displays the results of evaluating different large language models (LLMs) as AI tutors, focusing on their ability to inspire active learning. The evaluation used a rubric with several subdimensions, such as asking questions, providing opportunities for active engagement, and utilizing a Socratic approach. The figure presents the average scores for each LLM on each subdimension, with error bars showing the 95% credible intervals, reflecting the uncertainty in the estimates. This helps to visualize which models performed better in different facets of active learning.
read the caption
Figure 10: Evaluation of tutor models on specific subdimensions of the “Active learning” rubric category. Error bars reflect 95% credible intervals from the posterior distribution for the mean.
More on tables
| Theme | Appearances when participants preferred LearnLM (n=94) | Appearances when participants preferred other models (n=80) | Example responses |
|---|---|---|---|
| keeps_on_topic | 20 (21.2%) | 8 (10%) | “[LearnLM] didn’t let me get away with distractions” [LearnLM] was much more able to keep things on track “[The other tutor] also did a much better job of getting me back on task” |
| challenges_learner | 31 (33.0%) | 13 (16.3%) | “obviously [LearnLM] was better […] [the other tutor] clearly wasn’t pushing me to do well” “I felt like [LearnLM] was trying to help me grow and learn, rather than just agreeing with what I said” “[The other tutor] asked interesting questions that made me think deeper” |
| gives_away_answers | 32 (34.0%) | 15 (18.8%) | “[LearnLM] really engaged me in the steps to answer the question whereas [the other tutor] just gave me the answer” “[LearnLM] was keen on how to get the answer rather than giving the answer” “[LearnLM] was too reticent to help by giving answers when it was clear the student needed it” |
| clarity | 15 (16.0%) | 16 (20.0%) | “The structure of the support [for the other tutor] was a bit clearer for the student to follow” “[The other tutor] started smaller and simpler” “I just thought the answers [for LearnLM] were more clear” |
| conversation_style | 30 (31.9%) | 29 (36.3%) | “I […] felt that [LearnLM] was a bit patronizing” “[The other tutor] seemed warmer and more engaging” “[LearnLM] was warmer and more encouraging” |
🔼 This table lists the questions asked of participants after each conversation in the conversation collection phase of the study. It details the questions’ content and the format of responses (e.g., Likert scale, open-ended text). The goal is to understand participants’ experiences with the AI tutors.
read the caption
Table 6: Conversation-level questions within the conversation collection study
| Scenario 1 | ||||
|---|---|---|---|---|
| Subject area | Computer science | |||
| Subtopic | Introduction to Python | |||
| Interaction setting | Classroom | |||
| Learning goal | Homework Help | |||
| Grounding materials | https://storage.googleapis.com/arcade-external-pdfs/f421aaa1-f724-474a-bebf-3d50999ebd42/m6_eval_grounding/Python%20sample.pdf | |||
| Learner persona | - Rejects or unenthusiastically accepts tutor’s invitations without feedback |
Provides relevant but minimal responses to questions
Follows most instructions but does not elaborate
Does not “show work”
Does not pose questions
Seeks to receive answers or solutions to topical questions (transactional) | | Initial learner query | ``` def analyze_text(text): vowels = 0 consonants = 0 uppercase = 0 lowercase = 0
for char in text: if char in “aeiou”: vowels += 1 else: consonants += 1
if char.isupper(): uppercase += 1 elif char.islower(): lowercase += 1
print(“Vowels:”, vowels) print(“Consonants:”, consonants) print(“Uppercase:”, uppercase) print(“Lowercase:”, lowercase)
Get user input#
text = input(“Enter some text: “)
Analyze the text#
analyze_text(text)
| **Conversation plan** | You are a student in an introduction to Python course. **You were recently assigned the task of writing a piece of code** that can elicit a text input then report back on the numbers of vowels, consonants, uppercase, and lowercase letters. When you run the code, you get no error messages. But when you input “Am I a better coder than Steve Jobs?”, the numbers in the output don’t seem correct. You simply don’t understand what went wrong, so you ask your AI tutor for help. You paste your code in with your initial query, seeking a quick fix without doing a lot of work.
<br>
<br>Your code does not have capital vowels in your in operator. See if the tutor helps you notice that your code is counting punctuation marks as letters and then give you hints to fix your code. |
| **System instructions** | You are a helpful assistant serving as a teaching assistant in an intro programming course (in python).
<br>You keep your answers brief and to the point, and instead of giving away answers directly you try to guide the student to the solution. Be encouraging and positive, and always try to help the student understand the concepts.
<br>You should always respond as if you are messaging with the student.
<br>Accordingly, make sure to pay attention to the context of the conversation and the student’s current understanding of the material.
Lastly, as I said before, keep it brief/concise to avoid overwhelmingly the student.
<br>
<br>The student is generally working on a programming assignment (or assignments) where they need to take a string input from the user, and then loop over that inputted string to provide some metrics about the text (like how many vowels, consonants, upper case, lower case letters, etc.).
<br>
<br>If they ask you about how to do this, you should guide them to a solution without giving away the answer and/or code directly.
<br>
<br>You must be very careful to NOT help the student cheat, or give them solutions directly.
<br>
Again, if you give too much information to the student, and/or don’t help them learn for themselves, I’ll have to fire you, because you are being a bad tutor (and helping the student cheat).|
🔼 This table details the questions asked to participants after they completed a pair of conversations within a scenario, comparing their experiences with two different tutors. It outlines the questions used to assess preferences and overall experiences. The response format for each question is specified, providing a detailed look into the comparative evaluation process.
read the caption
Table 7: Comparative questions within the conversation collection study
| Scenario 2 | |
|---|---|
| Subject area | English |
| Subtopic | Literature |
| Interaction setting | Classroom |
| Learning goal | Teach me X |
| Grounding materials | (none) |
| Learner persona | • Poses multiple queries unrelated to the learning objective • Steers conversation toward non-academic topics • Challenges or debates the tutor in an adversarial manner • Seeks to shift the topic (disinterested) |
| Initial learner query | Explain the significance of Yorick’s skull in “Hamlet”. Be quick. |
| Conversation plan | You are a high school student who had to read Hamlet for class and have a discussion about the significance of the skull for class tomorrow. You want to be prepared for this discussion. You are not intrinsically motivated and found Hamlet dry and hard to understand. |
| System instructions | Tutor me at an appropriate level, adapting to my responses. Make a plan based on the learning goal of the conversation. Guide me through this plan and help me learn about the topic. Do not overwhelm me with too much information at once. Wrap up this conversation once I have shown evidence of understanding. |
🔼 Table 8 presents the updated rubric used for evaluating the pedagogical aspects of conversations between AI tutors and learners. It lists 29 rubric dimensions or sub-dimensions, along with the specific question used to assess each dimension during the pedagogical assessment phase. Each dimension is categorized under a broader rubric category (e.g., Cognitive Load, Active Learning, Metacognition) providing a structured way to evaluate various aspects of AI tutor’s performance in supporting learning.
read the caption
Table 8: Updated rubric dimensions for conversation-level pedagogical assessment.
| Scenario 3 | |
|---|---|
| Subject area | Math |
| Subtopic | Algebra |
| Interaction setting | Self-Taught |
| Learning goal | Practice |
| Grounding materials | (none) |
| Learner persona | * Offers some direction regarding the learning, but generally takes the tutor’s lead |
Answers tutor’s questions with care
“Shows work” when prompted
Asks relevant but superficial questions (low “depth of knowledge”)
Seeks to acquire and retain knowledge about the topic (instrumental) | | Initial learner query | Given the polynomials:
P(x) = 2x^3 - 5x^2 + 3x - 1
Q(x) = x^2 + 4x - 2
Perform the following operations:
Addition: Find P(x) + Q(x) Multiplication: Find P(x) * Q(x) | | Conversation plan | You are a student who wishes to practice solving math problems. Your teacher often calls on students at random to solve problems in front of the whole class, and this makes you nervous. You aren’t certain about the concepts and processes, and you’d like to learn so you won’t be embarrassed in class because English is not your primary language. However, you are reluctant to ask questions in your math lessons, so you turn to an AI tutor. Still, your confidence is quite low.
See if the tutor can recognize your emotional unsteadiness and offer encouragement, especially when you make mistakes, and if it adjusts its English level to meet yours. | | System instructions | You are a tutor that excels in promoting active learning. Active learning occurs when learners do something beyond merely listening or reading to acquire and retain information. Rather, active learning requires students to think critically through a process of comparison, analysis, evaluation, etc. You encourage active learning by asking probing and guiding questions.
Active learning also occurs when students work through complex questions and problems step by step. As such, you don’t solve problems for your students, but you offer scaffolds and hints as needed throughout the process.
Active learning can be difficult, and students may get frustrated. Knowing this, you meet your student where they are in their development, celebrate their student’s successes, and share encouraging feedback when they make errors.|
🔼 This table presents the rubric used for comparative pedagogical assessment. It lists several criteria for evaluating the quality of AI tutors, including better pedagogy, similarity to a human tutor, instruction following, adaptation to the learner, and support for learning goals. Each criterion is associated with a specific question used to assess the AI tutor’s performance against that criterion.
read the caption
Table 9: Rubric for comparative pedagogical assessment
Full paper#