↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Instruction fine-tuning (IFT) is crucial for enhancing LLMs, but existing datasets often contain knowledge inconsistent with LLMs’ internal knowledge. This inconsistency hinders effective IFT and limits LLM capabilities.
The paper introduces NILE, a novel framework that optimizes IFT datasets. NILE leverages pre-trained LLMs to elicit internal knowledge, revise dataset answers, and filter samples, ensuring consistency. Experiments show NILE significantly improves LLM performance across various evaluation datasets, demonstrating the critical role of dataset-LLM knowledge alignment in maximizing LLM potential.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical challenge in large language model (LLM) training: the inconsistency between pre-trained LLM knowledge and knowledge in instruction-tuning datasets. The proposed NILE framework offers a novel solution to improve dataset quality which directly impacts LLM performance. It opens up new avenues for research on high-quality data generation and LLM alignment.
Visual Insights#

🔼 This figure illustrates the difference between an LLM’s internal knowledge (knowledge learned during pre-training) and the world knowledge present in instruction fine-tuning (IFT) datasets. It shows how an instruction, processed by the pretrained LLM, elicits an answer that incorporates both internal knowledge (e.g., implicit understanding of emotions) and world knowledge (e.g., explicit facts about project outcomes). The NILE framework aims to improve alignment between these two knowledge sources in the IFT dataset, leading to better LLM performance.
read the caption
Figure 1: Demonstration of LLM internal knowledge and world knowledge from IFT datasets.
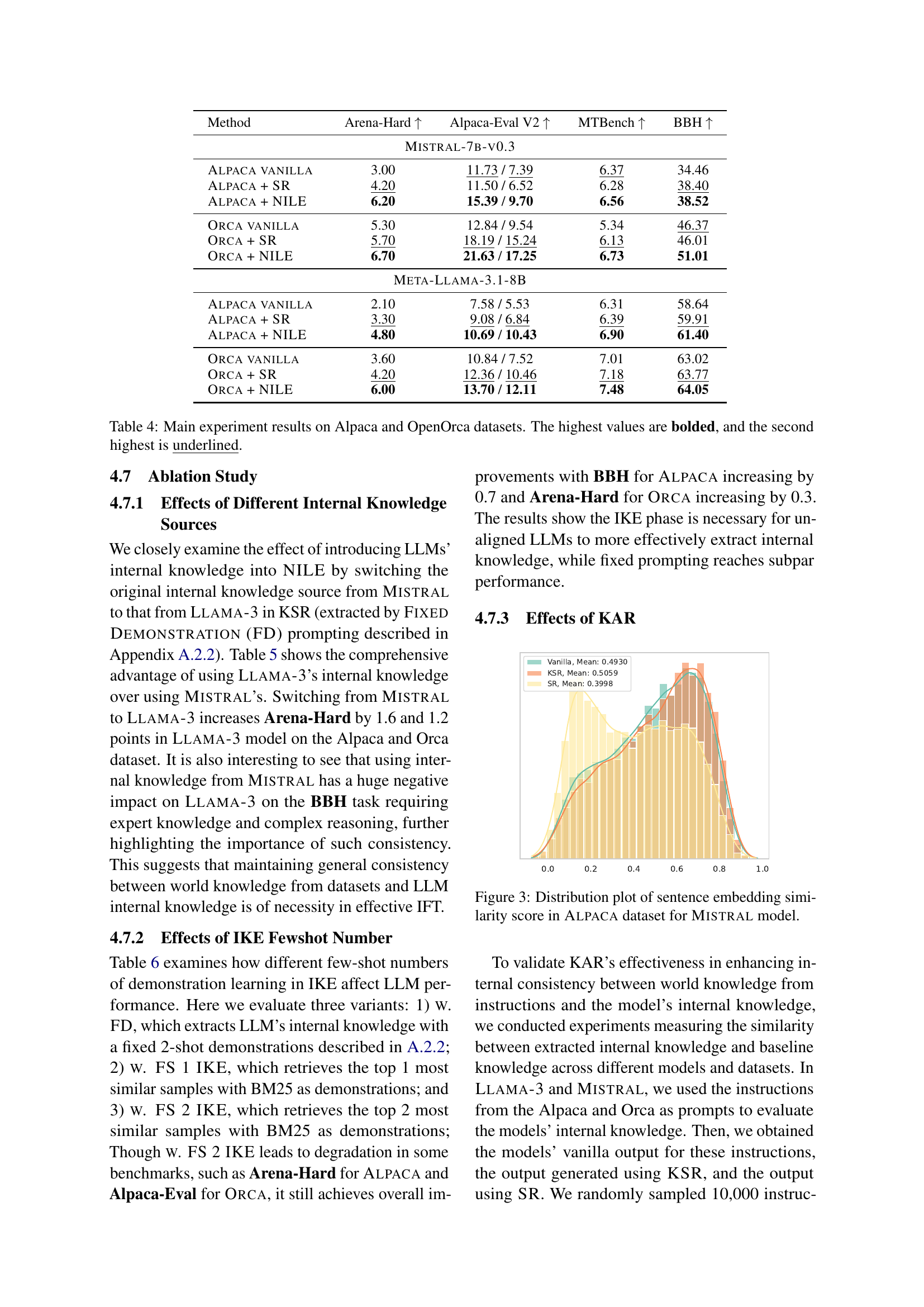
| Method | Arena-Hard ↑ | Alpaca-Eval V2 ↑ | MTBench ↑ | BBH ↑ |
|---|---|---|---|---|
| Mistral-7b-v0.3 | ||||
| Alpaca vanilla | 3.00 | 11.73 / 7.39 | 6.37 | 34.46 |
| Alpaca + SR | 4.20 | 11.50 / 6.52 | 6.28 | 38.40 |
| Alpaca + NILE | 6.20 | 15.39 / 9.70 | 6.56 | 38.52 |
| Orca vanilla | 5.30 | 12.84 / 9.54 | 5.34 | 46.37 |
| Orca + SR | 5.70 | 18.19 / 15.24 | 6.13 | 46.01 |
| Orca + NILE | 6.70 | 21.63 / 17.25 | 6.73 | 51.01 |
| Meta-Llama-3.1-8B | ||||
| Alpaca vanilla | 2.10 | 7.58 / 5.53 | 6.31 | 58.64 |
| Alpaca + SR | 3.30 | 9.08 / 6.84 | 6.39 | 59.91 |
| Alpaca + NILE | 4.80 | 10.69 / 10.43 | 6.90 | 61.40 |
| Orca vanilla | 3.60 | 10.84 / 7.52 | 7.01 | 63.02 |
| Orca + SR | 4.20 | 12.36 / 10.46 | 7.18 | 63.77 |
| Orca + NILE | 6.00 | 13.70 / 12.11 | 7.48 | 64.05 |
🔼 This table describes the prompt used to generate internal knowledge demonstrations from a pre-trained large language model (LLM). The prompt takes as input an instruction (instructiondi) and its corresponding input (inputdi) from the instruction fine-tuning (IFT) dataset. The LLM then generates knowledge (ikdi) related to the given instruction, which is used in the next step of the NILE framework to improve the consistency between the LLM’s internal knowledge and the world knowledge expressed in the IFT dataset.
read the caption
Table 1: Prompt for generating internal knowledge demonstration ikid𝑖subscriptsuperscript𝑘𝑑𝑖ik^{d}_{i}italic_i italic_k start_POSTSUPERSCRIPT italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT related to qidsubscriptsuperscript𝑞𝑑𝑖q^{d}_{i}italic_q start_POSTSUPERSCRIPT italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT.
In-depth insights#
LLM Internal Knowledge#
LLM internal knowledge represents the implicit understanding encoded within a large language model’s (LLM) parameter weights, learned during pre-training on massive datasets. This knowledge isn’t explicitly stored as facts but manifests in the model’s ability to generate coherent and contextually relevant text. It’s crucial to understand that this internal knowledge can be inconsistent with the world knowledge presented in fine-tuning datasets, leading to misalignment and suboptimal performance. Aligning the world knowledge of fine-tuning datasets with the LLM’s internal knowledge is, therefore, a critical challenge and an active area of research. Effective alignment techniques aim to bridge this gap, optimizing dataset quality and leading to improved LLM performance, as demonstrated in the provided research paper. The paper’s focus on improving the consistency between these knowledge sources highlights the importance of understanding the nuances of LLM internal knowledge for enhancing overall LLM capabilities. Further research should continue to explore methods for effectively assessing, understanding, and aligning LLM internal knowledge with external information to unlock the full potential of LLMs.
NILE Framework#
The NILE framework, designed for internal consistency alignment in large language models (LLMs), addresses the critical issue of knowledge discrepancies between pre-trained LLMs and instruction-tuning datasets. It tackles this by first extracting the LLM’s internal knowledge related to given instructions. Then, it leverages this knowledge to revise existing answers in the dataset, ensuring better alignment. A crucial component is the Internal Consistency Filtering (ICF) method, which filters out low-quality revisions, ultimately improving the quality and consistency of the instruction-tuning data. The framework’s effectiveness is demonstrated through significant performance gains across various evaluation benchmarks, highlighting the importance of addressing data-model consistency in enhancing LLM capabilities. NILE’s innovative approach offers a significant contribution to the field of LLM alignment, showcasing the considerable impact of dataset optimization on improving downstream model performance.
Data Consistency#
Data consistency in large language models (LLMs) is crucial for effective instruction fine-tuning (IFT). Inconsistent knowledge between an LLM’s internal knowledge (from pre-training) and the external knowledge presented in IFT datasets significantly impacts performance. A core issue is the discrepancy between world knowledge in training data and the LLM’s internal representations. This inconsistency can lead to models that are unable to generalize well, and instead rely on surface-level patterns rather than true understanding. Addressing this requires careful curation of IFT datasets to ensure alignment with the LLM’s internal knowledge, potentially involving methods to filter or revise data to enhance consistency. Strategies for improving data consistency might include using the LLM itself to identify and correct inconsistencies, or employing techniques to assess and prioritize data samples based on their alignment with the pre-trained model’s knowledge base. Successfully achieving data consistency is key to unlocking the full potential of LLMs in various downstream applications.
Future Research#
Future research directions stemming from this paper could explore iterative instruction refinement techniques within the NILE framework, moving beyond the single-pass revision currently implemented. Investigating the impact of using the complete OpenOrca dataset instead of the subset would provide a more comprehensive evaluation and potentially reveal new insights. A comparative analysis of NILE’s performance against alternative data selection and revision methods would strengthen its positioning within the field. Further studies are warranted to fully understand how NILE interacts with LLMs possessing different internal knowledge structures, thereby enhancing the generalizability of this methodology. Finally, exploring the ethical implications of using automatically generated datasets at scale for fine-tuning LLMs, focusing on biases, discrimination, and appropriate safeguards, is vital.
NILE Limitations#
The NILE framework, while demonstrating significant improvements in LLM performance, has limitations. Data limitations are key; the study used only a subset of the OpenOrca dataset due to computational constraints. Future work should leverage the entire dataset to further evaluate NILE’s capabilities. Another important limitation is the single-pass revision. NILE currently employs only one revision cycle. Implementing iterative refinement would likely lead to further improvements and a more robust alignment process. Finally, computational resource requirements present a hurdle for wider application. The framework’s computational intensity should be addressed, possibly through optimization techniques, to broaden its accessibility and practicality for a wider range of users and models. Addressing these limitations is crucial to unleashing NILE’s full potential for enhanced LLM performance.
More visual insights#
More on figures

🔼 The NILE framework is depicted in this flowchart, which is broken down into three primary phases: Internal Knowledge Extraction (IKE), Knowledge-Aware Sample Revision (KSR), and Internal Consistency Filtering (ICF). The framework starts with original instruction-response pairs from an instruction tuning dataset. IKE uses a pre-trained LLM to extract internal knowledge associated with the instruction. KSR leverages this knowledge to revise the original answer. Finally, ICF filters revised samples based on their internal consistency with the pre-trained LLM. The resulting aligned dataset is then used for instruction fine-tuning.
read the caption
Figure 2: Overview of our NILE framework.

🔼 This figure displays the distribution of sentence embedding similarity scores calculated for the Mistral language model using the Alpaca dataset. The distribution shows the similarity between sentence embeddings generated by the original answers in the dataset, answers revised using the Knowledge-aware Sample Revision (KSR) method, and answers revised using the Sample Revision (SR) method. This visual representation helps to evaluate the effectiveness of the KSR method in enhancing the affinity between the model’s internal knowledge and the information provided in the dataset. Specifically, higher similarity scores indicate a stronger alignment between the revised answers and the internal knowledge of the model.
read the caption
Figure 3: Distribution plot of sentence embedding similarity score in Alpaca dataset for Mistral model.

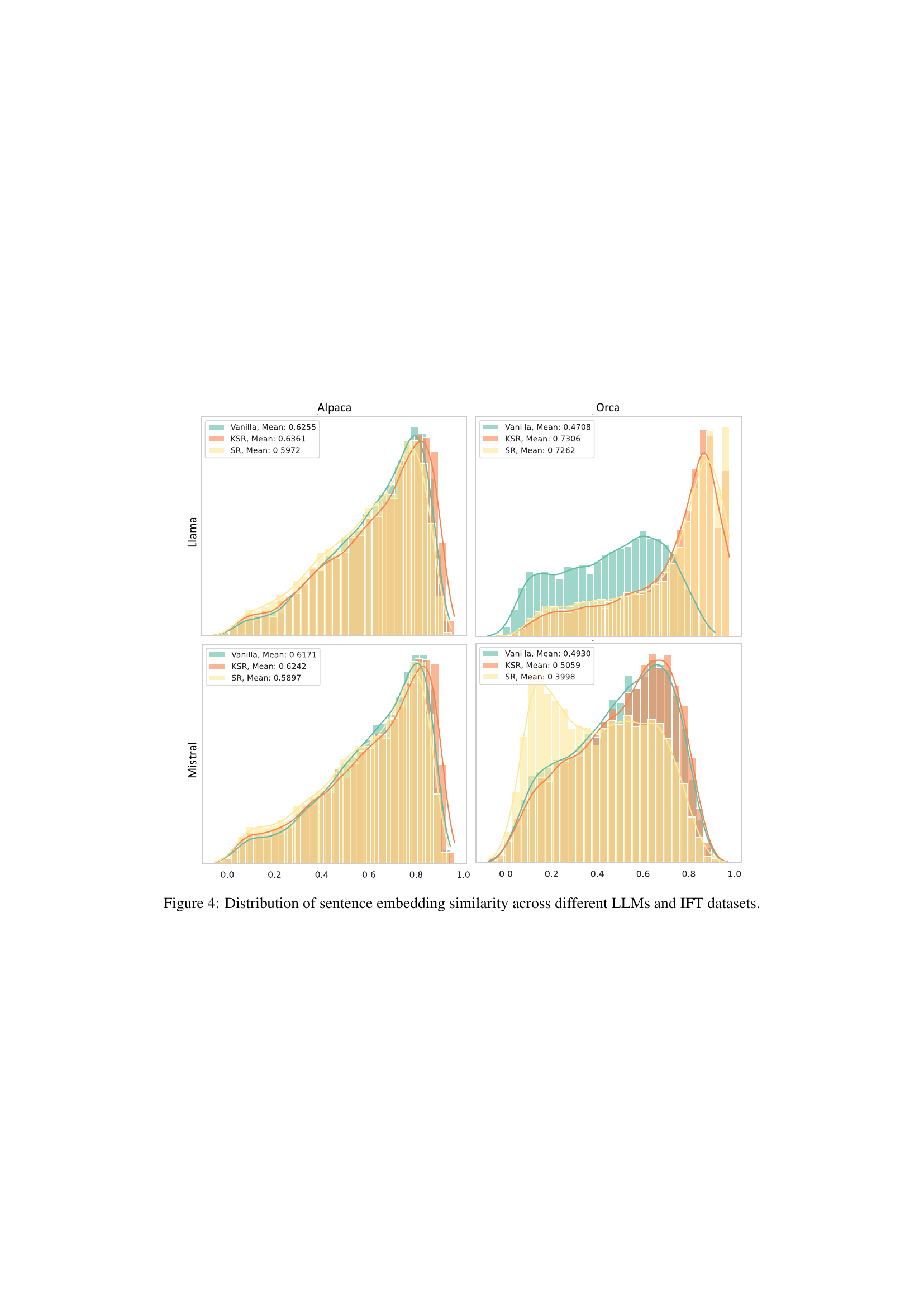
🔼 This figure displays the distribution of sentence embedding similarity scores obtained from three different methods: Vanilla (original responses), KSR (responses revised using knowledge-aware sample revision), and SR (responses revised without using internal LLM knowledge). The distributions are shown separately for Alpaca and Orca datasets and for two different LLMs, Mistral and Llama. The plots visually compare how similar the generated responses are to the internal knowledge of the LLMs, illustrating the impact of the KSR technique on aligning generated text with pre-trained knowledge.
read the caption
Figure 4: Distribution of sentence embedding similarity across different LLMs and IFT datasets.
More on tables
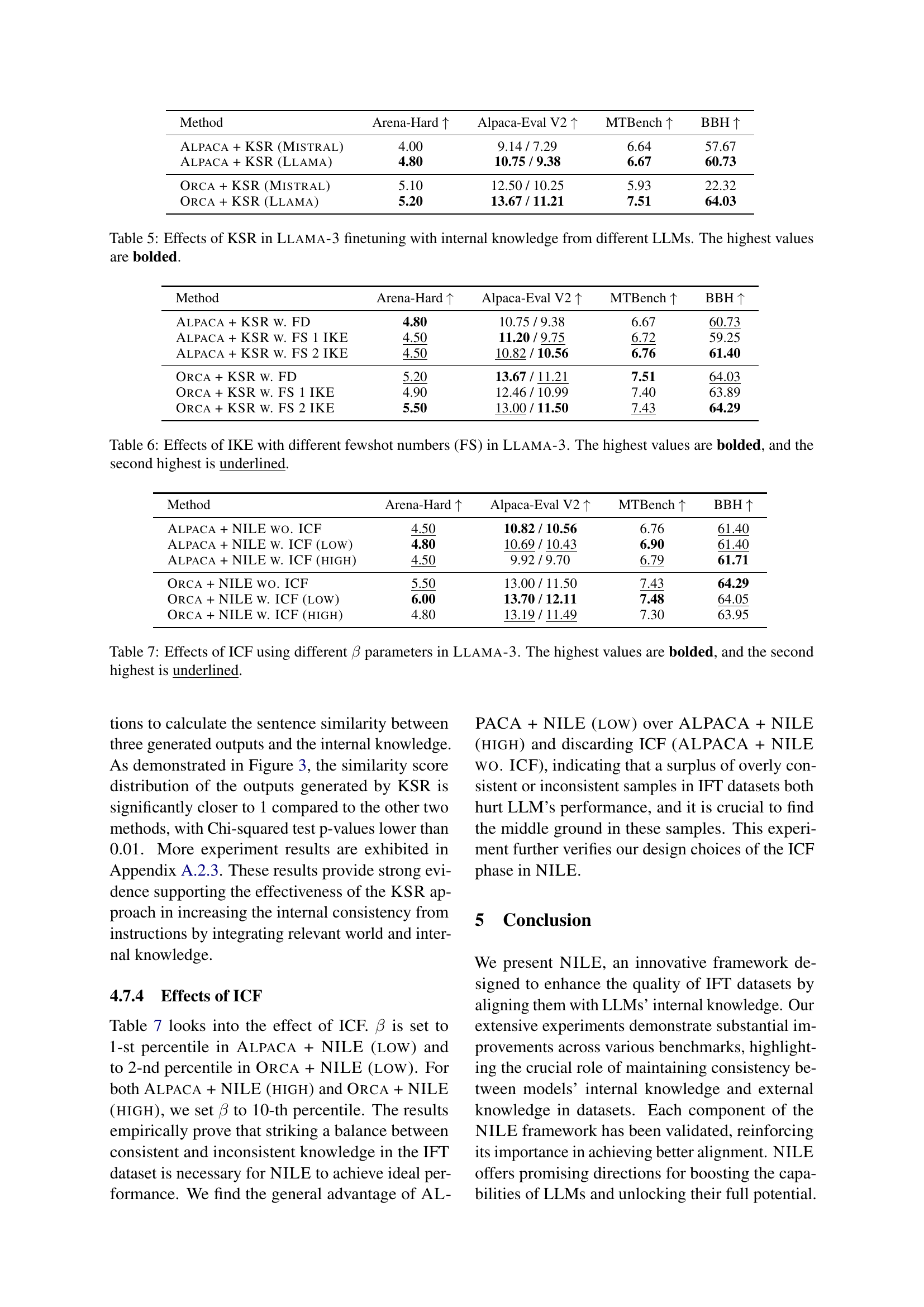
| Method | Arena-Hard ↑ | Alpaca-Eval V2 ↑ | MTBench ↑ | BBH ↑ |
|---|---|---|---|---|
| Alpaca + KSR (Mistral) | 4.00 | 9.14 / 7.29 | 6.64 | 57.67 |
| Alpaca + KSR (Llama) | 4.80 | 10.75 / 9.38 | 6.67 | 60.73 |
| Orca + KSR (Mistral) | 5.10 | 12.50 / 10.25 | 5.93 | 22.32 |
| Orca + KSR (Llama) | 5.20 | 13.67 / 11.21 | 7.51 | 64.03 |
🔼 This table presents the prompt used for extracting internal knowledge from a pre-trained large language model (LLM). The prompt guides the LLM to generate knowledge related to a given instruction and input by providing a few-shot learning example. The few-shot examples themselves are selected based on semantic similarity to the target instruction. Details on how these examples are selected and the full prompt engineering methodology are described in Appendix A.1.3 of the paper.
read the caption
Table 2: Prompt for knowledge extraction. Sample few-shot demonstration prompt is listed in A.1.3.
| Method | Arena-Hard ↑ | Alpaca-Eval V2 ↑ | MTBench ↑ | BBH ↑ |
|---|---|---|---|---|
| Alpaca + KSR w. FD | 4.80 | 10.75 / 9.38 | 6.67 | 60.73 |
| Alpaca + KSR w. FS 1 IKE | 4.50 | 11.20 / 9.75 | 6.72 | 59.25 |
| Alpaca + KSR w. FS 2 IKE | 4.50 | 10.82 / 10.56 | 6.76 | 61.40 |
| Orca + KSR w. FD | 5.20 | 13.67 / 11.21 | 7.51 | 64.03 |
| Orca + KSR w. FS 1 IKE | 4.90 | 12.46 / 10.99 | 7.40 | 63.89 |
| Orca + KSR w. FS 2 IKE | 5.50 | 13.00 / 11.50 | 7.43 | 64.29 |
🔼 This table shows the prompt template used in the Knowledge-aware Sample Revision (KSR) stage of the NILE framework. The prompt guides a large language model (LLM) to revise an existing instruction-answer pair by incorporating internal knowledge extracted earlier in the process. The prompt includes placeholders for the original answer, instruction, input, and extracted internal knowledge, allowing the LLM to generate a revised answer that aligns better with both the original instruction and the internal knowledge of the target LLM.
read the caption
Table 3: Prompt for Knowledge-aware Sample Revision.
| Method | Arena-Hard ↑ | Alpaca-Eval V2 ↑ | MTBench ↑ | BBH ↑ |
|---|---|---|---|---|
| Alpaca + NILE wo. ICF | 4.50 | 10.82 / 10.56 | 6.76 | 61.40 |
| Alpaca + NILE w. ICF (low) | 4.80 | 10.69 / 10.43 | 6.90 | 61.40 |
| Alpaca + NILE w. ICF (high) | 4.50 | 9.92 / 9.70 | 6.79 | 61.71 |
| Orca + NILE wo. ICF | 5.50 | 13.00 / 11.50 | 7.43 | 64.29 |
| Orca + NILE w. ICF (low) | 6.00 | 13.70 / 12.11 | 7.48 | 64.05 |
| Orca + NILE w. ICF (high) | 4.80 | 13.19 / 11.49 | 7.30 | 63.95 |
🔼 This table presents the quantitative results of the main experiments conducted using the NILE framework. It shows the performance of different models (MISTRAL-7B-v0.3 and META-LLAMA-3.1-8B) on multiple evaluation benchmarks (Arena-Hard, Alpaca-Eval V2, MTBench, and BBH) when fine-tuned with instruction-following datasets generated by the Alpaca and OpenOrca methods. For each benchmark and model combination, the vanilla score (using the original unmodified dataset), score with sample revision only (SR), and the score with the full NILE framework are compared. The highest scores are shown in bold, and the second highest scores are underlined. This allows for a direct comparison of the impact of each component of the NILE framework on model performance across various tasks.
read the caption
Table 4: Main experiment results on Alpaca and OpenOrca datasets. The highest values are bolded, and the second highest is underlined.
| Method | Arena-Hard ↑ | Alpaca-Eval V2 ↑ | MTBench ↑ | BBH ↑ |
|---|---|---|---|---|
| Orca + NILE w. Contriver | 4.70 | 14.63 / 12.17 | 7.29 | 64.00 |
| Orca + NILE w. BM25 | 5.50 | 13.00 / 11.50 | 7.43 | 64.29 |
🔼 This table presents the results of an ablation study evaluating the impact of using internal knowledge from different LLMs within the Knowledge-aware Sample Revision (KSR) component of the NILE framework. Specifically, it shows how Llama-3’s performance on various benchmark datasets (Arena-Hard, Alpaca-Eval V2, MTBench, and BBH) changes when finetuned using datasets revised with internal knowledge extracted from either Mistral or Llama-3. The highest performance scores for each metric are highlighted in bold, illustrating the relative effectiveness of using each LLM’s knowledge for dataset revision.
read the caption
Table 5: Effects of KSR in Llama-3 finetuning with internal knowledge from different LLMs. The highest values are bolded.
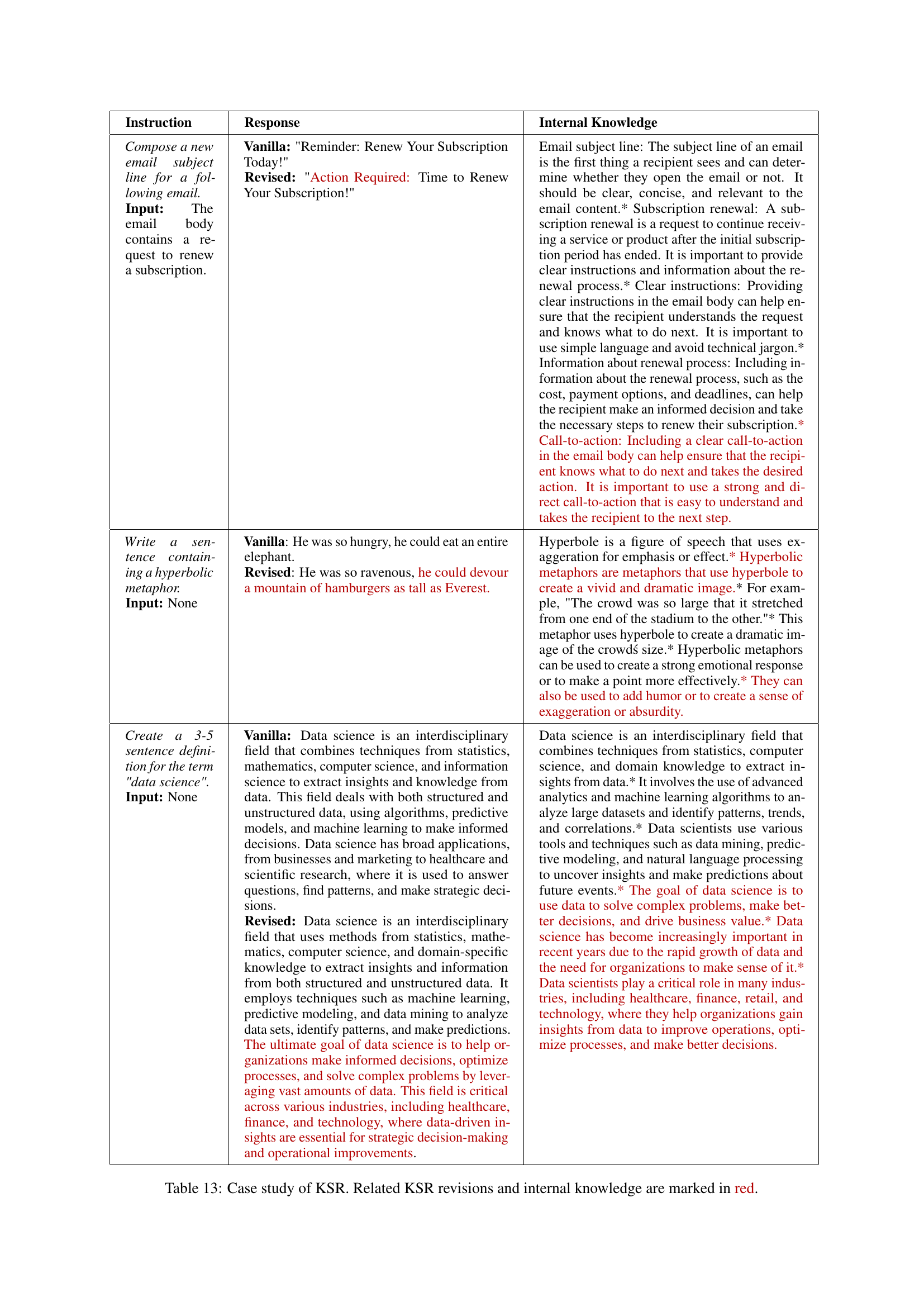
| Instruction | Response | Internal Knowledge |
|---|---|---|
| Compose a new email subject line for a following email. Input: The email body contains a request to renew a subscription. | Vanilla: “Reminder: Renew Your Subscription Today!” Revised: “Action Required: Time to Renew Your Subscription!” | Email subject line: The subject line of an email is the first thing a recipient sees and can determine whether they open the email or not. It should be clear, concise, and relevant to the email content.* Subscription renewal: A subscription renewal is a request to continue receiving a service or product after the initial subscription period has ended. It is important to provide clear instructions and information about the renewal process.* Clear instructions: Providing clear instructions in the email body can help ensure that the recipient understands the request and knows what to do next. It is important to use simple language and avoid technical jargon.* Information about renewal process: Including information about the renewal process, such as the cost, payment options, and deadlines, can help the recipient make an informed decision and take the necessary steps to renew their subscription.* Call-to-action: Including a clear call-to-action in the email body can help ensure that the recipient knows what to do next and takes the desired action. It is important to use a strong and direct call-to-action that is easy to understand and takes the recipient to the next step. |
| Write a sentence containing a hyperbolic metaphor. Input: None | Vanilla: He was so hungry, he could eat an entire elephant. Revised: He was so ravenous, he could devour a mountain of hamburgers as tall as Everest. | Hyperbole is a figure of speech that uses exaggeration for emphasis or effect.* Hyperbolic metaphors are metaphors that use hyperbole to create a vivid and dramatic image.* For example, “The crowd was so large that it stretched from one end of the stadium to the other.” * This metaphor uses hyperbole to create a dramatic image of the crowdś size.* Hyperbolic metaphors can be used to create a strong emotional response or to make a point more effectively.* They can also be used to add humor or to create a sense of exaggeration or absurdity. |
| Create a 3-5 sentence definition for the term “data science”. Input: None | Vanilla: Data science is an interdisciplinary field that combines techniques from statistics, mathematics, computer science, and information science to extract insights and knowledge from data. This field deals with both structured and unstructured data, using algorithms, predictive models, and machine learning to make informed decisions. Data science has broad applications, from businesses and marketing to healthcare and scientific research, where it is used to answer questions, find patterns, and make strategic decisions. Revised: Data science is an interdisciplinary field that uses methods from statistics, mathematics, computer science, and domain-specific knowledge to extract insights and information from both structured and unstructured data. It employs techniques such as machine learning, predictive modeling, and data mining to analyze data sets, identify patterns, and make predictions. The ultimate goal of data science is to help organizations make informed decisions, optimize processes, and solve complex problems by leveraging vast amounts of data. This field is critical across various industries, including healthcare, finance, and technology, where data-driven insights are essential for strategic decision-making and operational improvements. | Data science is an interdisciplinary field that combines techniques from statistics, computer science, and domain knowledge to extract insights from data.* It involves the use of advanced analytics and machine learning algorithms to analyze large datasets and identify patterns, trends, and correlations.* Data scientists use various tools and techniques such as data mining, predictive modeling, and natural language processing to uncover insights and make predictions about future events.* The goal of data science is to use data to solve complex problems, make better decisions, and drive business value.* Data science has become increasingly important in recent years due to the rapid growth of data and the need for organizations to make sense of it.* Data scientists play a critical role in many industries, including healthcare, finance, retail, and technology, where they help organizations gain insights from data to improve operations, optimize processes, and make better decisions. |
🔼 This table presents the ablation study results on the impact of using different numbers of few-shot examples in the Internal Knowledge Extraction (IKE) phase of the NILE framework, specifically focusing on Llama-3 model. It compares the performance metrics across three scenarios: using a fixed 2-shot demonstration (FD), retrieving the top 1 most similar sample (FS 1 IKE), and retrieving the top 2 most similar samples (FS 2 IKE). The results are presented for various evaluation benchmarks, allowing for a comprehensive assessment of the impact of the number of few-shot examples on model performance. The highest values for each benchmark are highlighted in bold, and the second-highest values are underlined.
read the caption
Table 6: Effects of IKE with different fewshot numbers (FS) in Llama-3. The highest values are bolded, and the second highest is underlined.
Full paper#