↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for building figure question-answering (QA) datasets are expensive and time-consuming, hindering progress in visual language model research. Existing synthetic approaches often fall short due to limitations in diversity, quality, and error-prone code generation. This makes it difficult to create large-scale datasets needed for effective model training.
This paper introduces SBS Figures, a novel approach to generate synthetic figure QA data. It utilizes a stage-by-stage pipeline, which ensures high-quality, diverse figures and accurate QA pairs. The method is more efficient, and avoids many common issues, such as code errors, which are common problems with other LLM-based approaches. The researchers demonstrate the effectiveness of their approach by showing that models pre-trained on SBS Figures perform significantly better on various benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the challenge of creating large-scale figure question-answering datasets, a crucial resource for training advanced visual language models. Its novel stage-by-stage synthesis method is highly efficient, and the publicly available dataset and codebase facilitate further research and development in visual reasoning and document understanding.
Visual Insights#

🔼 Figure 1 illustrates the SBS Figures dataset, a newly created large-scale dataset designed for pre-training figure question answering (QA) models. The figure highlights the stage-by-stage generation process used to create the dataset: starting with the generation of diverse data, followed by error-free code for rendering charts using this data and the generation of accurate, dense QA pairs without relying on manual annotations or Optical Character Recognition (OCR). The resulting dataset contains a wide variety of charts (with diverse topics and visual styles), making it well-suited for effective model pre-training and robust generalization to real-world chart data.
read the caption
Figure 1: SBS Figures (Stage-by-Stage Synthetic Figures). We create SBS Figures, a dataset for pre-training figure QA. Our stage-by-stage synthetic dataset creation enables a strong pre-training effect for real-world chart data.
| Dataset | human | aug. | avg |
|---|---|---|---|
| Scratch | 31.28 | 77.76 | 54.42 |
| FigureQA Kahou et al. (2018) | 13.44 | 9.36 | 11.40 |
| DVQA Kafle et al. (2018) | 26.88 | 72.16 | 49.52 |
| PlotQA Methani et al. (2020) | 30.56 | 74.00 | 52.28 |
| SBS Figures (Ours) | 39.44 | 82.24 | 60.84 |
🔼 This table compares the performance of the Donut model when pre-trained on various synthetic datasets, including SBS Figures and other existing datasets like FigureQA, DVQA, and PlotQA. The comparison focuses on the model’s ability to answer questions about figures after pre-training. The results are presented as the average F1 score across human-annotated and augmented datasets to evaluate the pre-training’s effectiveness.
read the caption
Table 1: Comparison of the pre-training effect of SBS Figures with other synthetic datasets. All datasets were trained using the Donut model.
In-depth insights#
Synth Figure QA#
Synthetic Figure QA presents a novel approach to address the challenges in creating large-scale figure question-answering datasets. Traditional methods are labor-intensive, requiring manual annotation of figures and question generation. This technique leverages LLMs to generate both synthetic figures and their corresponding QA pairs, significantly reducing the manual effort. The stage-by-stage generation process—starting with data generation, followed by figure rendering using error-free Python code, and finally, QA pair generation—enables efficient creation of diverse and high-quality data. This approach not only minimizes errors but also allows for control over figure aesthetics and topic diversity. The resulting dataset shows a strong pre-training effect, enabling efficient training of models with limited real-world data, significantly advancing the field of figure understanding.
Stage-wise Pipeline#
A stage-wise pipeline offers a structured approach to complex tasks, breaking them into smaller, manageable steps. This is particularly beneficial in synthetic data generation, where each stage can focus on a specific aspect—such as data generation, figure rendering, and QA pair creation. The modularity promotes efficiency by allowing for code reuse and parallel processing. Error control is significantly enhanced, as errors in one stage are less likely to cascade through the entire pipeline. Iterative refinement is facilitated, permitting adjustments at each stage based on intermediate results. Flexibility is increased allowing modification of individual stages to generate diverse outputs, thereby enhancing the variety and quality of the final synthetic data. Scalability is also improved as each step can be optimized independently, thus making the overall process efficient for massive datasets. However, careful design and coordination are needed between stages to maintain data integrity and ensure that output from one stage seamlessly feeds into the next.
Pre-train Effects#
The research demonstrates a strong pre-training effect when using the synthetically generated SBS Figures dataset. Models pre-trained on SBS Figures significantly outperform those trained from scratch or pre-trained on other synthetic datasets like FigureQA, DVQA, and PlotQA, achieving substantially higher accuracy on real-world figure QA tasks. This highlights the effectiveness of synthetic data in pre-training, particularly when carefully designed to encompass diverse figure types, styles, and comprehensive annotations (including dense QA pairs). The superior performance is not limited to a single model architecture, further solidifying the dataset’s value as a versatile resource for figure understanding. Importantly, the ablation study shows that aspects like figure appearance diversity and QA quality directly impact the pre-training effect, underscoring the importance of a holistic, well-designed synthetic dataset.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper focusing on figure question answering (QA), ablation studies would likely investigate the impact of various elements within a dataset creation pipeline or a model architecture. For example, removing the randomness in figure generation might reveal whether diverse visual styles are crucial for model performance. Similarly, testing the effect of different QA generation techniques (e.g., template-based vs. LLM-generated) helps quantify the value of high-quality, varied questions. Evaluating the influence of data topic diversity would assess whether a broad range of topics improves generalization. Ultimately, ablation studies aim to pinpoint the most critical factors, clarifying the model’s strengths and weaknesses and guiding future improvements by isolating the impact of individual components. Analyzing these results offers a deeper understanding of the model’s behavior, highlighting which aspects of the dataset or architecture are most important for effective figure QA.
Future Work#
Future research directions stemming from this work on SBS Figures could explore several avenues. Improving the diversity and realism of generated figures is crucial; while the current method produces variety, incorporating more nuanced data distributions, chart styles, and real-world data elements could enhance the training effect. Investigating different LLMs and their impact on both figure and QA generation quality is warranted, possibly leading to better performance with less computational cost. The current research focuses on chart figures, and extending it to encompass other data visualization types like maps, diagrams, and images would significantly broaden the scope and impact. Finally, evaluating the robustness of models pre-trained on SBS Figures against noisy or incomplete real-world data is necessary to assess their practical applicability in various real-world document understanding applications. These directions would further establish SBS Figures as a leading resource for advancing the field of figure QA and visual document understanding.
More visual insights#
More on figures

🔼 This figure illustrates the three-stage pipeline used to generate the SBS Figures dataset. The first stage involves generating visualization data (chart type, data topic, numerical data, text, and colors) and representing it in JSON format. The second stage uses pre-defined, error-free Python scripts to create chart images based on the JSON data. The final stage generates accurate and comprehensive question-answer (QA) pairs directly from the JSON data without requiring optical character recognition (OCR). This fully synthetic approach ensures high quality, diverse data, and eliminates the need for manual annotation.
read the caption
Figure 2: Generation pipeline of SBS Figures. SBS Figures was created using a fully synthetic method. First, we generate the visualization data, represented in JSON format, containing complete numbers, text, and colors. Next, we produce figure images from this data using pre-defined, error-free Python scripts. Finally, we generate dense and accurate QA pairs from visualization data without the need for OCR.

🔼 This figure illustrates the three prompt templates used in the SBS Figures generation pipeline. The pipeline is fully automated, creating data, images, and question-answer pairs without human intervention. The templates are designed to elicit specific outputs from a large language model (LLM). The first template generates diverse data topics suitable for visualization. The second template, using few-shot learning (providing examples of the desired JSON format), generates formatted JSON data representing the visualization data (numerical values, labels, etc.). The third template, also using few-shot learning, creates relevant question-answer pairs based on the generated JSON data. The pipeline’s efficiency is enhanced by code that dynamically adjusts prompts and context, optimizing the LLM’s responses.
read the caption
Figure 3: Prompt templates used in the generation pipeline of SBS Figures. We adopt few-shot prompting to ensure consistent formatting for both JSON data and QA generation. To improve efficiency, our pipeline includes code that repeatedly adjusts the context and prompts during the generation process.

🔼 Figure 4 showcases examples from the SBS Figures dataset, highlighting the diversity of visualizations and the complexity of the associated question-answer pairs. Each data point within a figure can have approximately 2,000 variations in visual elements (fonts, colors, markers, etc.). The questions demand sophisticated reasoning skills to accurately answer based on the visualized data.
read the caption
Figure 4: Example of SBS Figures QA pairs. The figures show diverse visual variations, with each data content containing around 2,000 combinations of visual components. Additionally, our pipeline generates dense and precise QA pairs, requiring complex reasoning skills to address the questions.

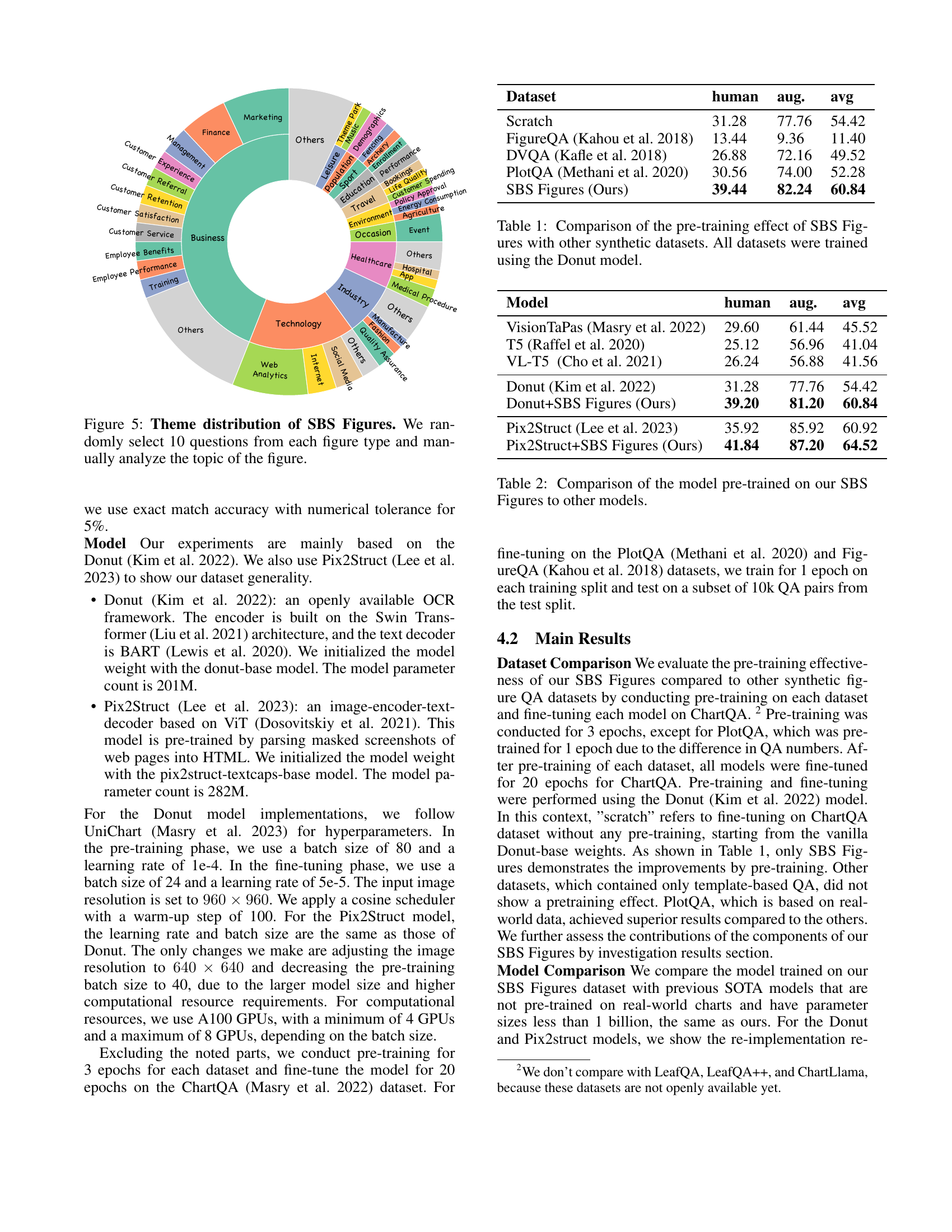
🔼 This figure shows the distribution of themes across different chart types in the SBS Figures dataset. Ten questions were randomly selected for each chart type, and the topics of those questions were manually analyzed and categorized to illustrate the range of subjects covered by the dataset. The visualization is a donut chart, where each segment represents a category of themes (e.g., Business, Healthcare, etc.), and the size of each segment corresponds to the proportion of questions belonging to that theme.
read the caption
Figure 5: Theme distribution of SBS Figures. We randomly select 10 questions from each figure type and manually analyze the topic of the figure.

🔼 Figure 6 presents a qualitative comparison of the performance of a Donut model, both with and without pre-training on the SBS Figures dataset. The figure showcases examples of complex reasoning questions posed to the model, highlighting the model’s ability to answer these questions correctly (green) or incorrectly (red). This visual comparison emphasizes the improvement in performance achieved through pre-training on the SBS Figures dataset.
read the caption
Figure 6: Qualitative Comparison. Our pre-trained Donut model on SBS Figures demonstrates its ability to answer complex reasoning questions. Incorrect answers are highlighted in red, while correct answers are highlighted in green.

🔼 This figure displays a pie chart visualizing the distribution of question types within the SBS Figures dataset. 100 question-answer pairs were randomly sampled from the dataset and manually categorized into various question types to illustrate the range and diversity of question styles covered in the dataset. The different question types represent various levels of complexity and reasoning required to correctly answer the questions.
read the caption
Figure 7: QA distribution of SBS Figures. We randomly selected 100 QAs and manually analyzed their QA types.

🔼 This figure showcases various examples of images and their corresponding question-answer pairs from the SBS Figures dataset. Each example represents a different chart type (e.g., diverging bar chart, vertical bar chart, pie chart, etc.) The images display diverse data visualizations, and the accompanying question-answer pairs demonstrate the complexity and range of reasoning required to accurately interpret the chart data. The questions require more than simple data retrieval, often involving multiple steps of reasoning or comparing different data points across the chart. This figure highlights the diversity and complexity of the data within the SBS Figures dataset.
read the caption
Figure 8: Examples of SBS Figures figure images and QA pairs.
More on tables
| Model | human | aug. | avg |
|---|---|---|---|
| VisionTaPas (Masry et al., 2022) | 29.60 | 61.44 | 45.52 |
| T5 (Raffel et al., 2020) | 25.12 | 56.96 | 41.04 |
| VL-T5 (Cho et al., 2021) | 26.24 | 56.88 | 41.56 |
| Donut (Kim et al., 2022) | 31.28 | 77.76 | 54.42 |
| Donut+SBS Figures (Ours) | 39.20 | 81.20 | 60.84 |
| Pix2Struct (Lee et al., 2023) | 35.92 | 85.92 | 60.92 |
| Pix2Struct+SBS Figures (Ours) | 41.84 | 87.20 | 64.52 |
🔼 This table compares the performance of different models on figure question answering tasks. Specifically, it shows how the performance of two models (Donut and Pix2Struct) changes when they are pre-trained on the SBS Figures dataset compared to their performance when not pre-trained or pre-trained on other datasets. The results are presented for two different splits of the ChartQA dataset (‘human’ and ‘augmented’), representing different difficulty levels of questions. The table highlights the impact of pre-training on SBS Figures on the overall accuracy of the models.
read the caption
Table 2: Comparison of the model pre-trained on our SBS Figures to other models.
| Table 5: (F3) QA quality | Template | Gemma | GPT-3.5 | GPT-4o | |
|---|---|---|---|---|---|
| human | 30.00 | 31.52 | 35.92 | 34.56 | |
| aug. | 77.92 | 79.04 | 80.48 | 81.84 |
🔼 This table presents the results of an experiment evaluating the impact of pre-training with the SBS Figures dataset on the performance of the Donut model on two figure question answering (QA) datasets: PlotQA and FigureQA. The experiment involved pre-training the Donut model on SBS Figures and then fine-tuning it on PlotQA and FigureQA. The table shows the performance (likely accuracy scores) achieved by the model after pre-training with SBS Figures, compared to the performance of a model trained from scratch (without pre-training). This allows for assessing the effectiveness of the SBS Figures dataset as a pre-training resource for improving the model’s ability to answer questions about figures.
read the caption
Table 8: Evaluation of the pre-training effect of SBS Figures on the PlotQA and FigureQA tasks. All pre-training and fine-tuning were conducted using the Donut model.
| Randomize | ✓ | |
|---|---|---|
| human | 33.44 | 35.92 |
| aug. | 80.16 | 80.48 |
🔼 This table presents the results of an experiment evaluating the impact of pre-training with SBS Figures on the UniChart model’s performance in ChartQA reasoning tasks. The UniChart model was trained in two ways: (1) from scratch (without pre-training), and (2) with pre-training using SBS Figures. The experiment was conducted with varying amounts of data from the SBS Figures dataset (10k, 30k, and 50k QA pairs) to assess the influence of the pre-training data volume on the model’s performance. The model’s performance was measured on both the human-annotated and augmented splits of the ChartQA dataset, providing a comprehensive evaluation of the pre-training effect across different data sizes and annotation types.
read the caption
Table 9: Evaluation of the pretraining effect of our SBS Figures for the UniChart reasoning training based on steps. We evaluate on ChartQA dataset (human∣∣\mid∣aug.).
| JSON | QA | |
|---|---|---|
| human | 31.44 | 35.92 |
| aug. | 79.12 | 80.48 |
🔼 This table compares the effectiveness of pre-training on the SBS Figures dataset against other synthetic datasets for figure question answering (QA). It shows the performance results achieved by fine-tuning a Donut model after pre-training on each dataset, using the average F1 score across human and augmented QA splits from the ChartQA dataset. The table highlights the relative improvement in performance provided by pre-training with SBS Figures compared to using other synthetic datasets.
read the caption
Table 10: Comparison of the pre-training effect of SBS Figures with other synthetic datasets. All datasets were trained using the Donut model.
Full paper#