↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current sequential recommendation systems struggle to fully leverage collaborative filtering information, particularly when using large language models (LLMs) that primarily rely on textual data. Many existing approaches inadequately integrate multiple data modalities (text, images, etc.) or fuse ID information too early, hindering optimal recommendation performance. This results in suboptimal utilization of rich contextual and collaborative signals.
To address these limitations, the researchers propose “Molar,” a new framework that incorporates a multimodal large language model (MLLM) to create comprehensive item representations from multiple data sources. Molar uniquely employs a post-alignment mechanism to effectively combine collaborative filtering signals (from ID-based models) with the rich content features generated by the MLLM. This approach ensures accurate personalization and robust performance. Through extensive experiments, the paper demonstrates that Molar outperforms traditional and existing LLM-based methods in recommendation accuracy. The results highlight the effectiveness of combining multimodal information with collaborative filtering signals for enhanced sequential recommendations.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances sequential recommendation systems by effectively integrating multimodal data and collaborative filtering. It introduces a novel framework, Molar, that outperforms existing methods, opening avenues for future research in multimodal LLM applications and personalized recommendation strategies. The post-alignment mechanism is a particularly innovative contribution, offering a new approach to fusing ID-based and content-based recommendations. This work is relevant to ongoing research on LLMs in recommender systems and offers valuable insights for researchers aiming to improve accuracy and robustness in sequential recommendations.
Visual Insights#

🔼 This figure compares existing LLM-based recommendation methods with the proposed Molar method. Panel (a) illustrates a common approach where user and item IDs and text are directly input into the LLM. This approach often underutilizes multimodal data. Panel (b) shows Molar, which first generates rich item representations using an MLLM processing text and other modalities before incorporating ID information via a post-alignment step. This refined approach better balances multimodal and collaborative signals.
read the caption
Figure 1: Comparison of LLM-based recommendation methods and our Molar. (a) Existing methods prematurely integrate ID and text modalities into the LLM, leading to limited utilization of multimodal content features. (b) Our approach first processes text and non-text modalities through the LLM to generate rich multimodal representations and then incorporates ID information via post-alignment, ensuring a better balance between multimodal content and collaborative signals.
| Dataset | Amazon | PixelRec | MovieLens |
|---|---|---|---|
| # User | 993,087 | 50,000 | 6,040 |
| # Item | 301,312 | 82,864 | 3,706 |
| # Interaction | 8,813,442 | 989,476 | 1,000,209 |
🔼 This table presents a summary of the statistics for three datasets used in the paper’s experiments: Amazon, PixelRec, and MovieLens. For each dataset, it shows the number of users, the number of items, and the total number of user-item interactions. This information is crucial for understanding the scale and characteristics of the data used to evaluate the proposed recommendation model.
read the caption
Table 1: Statistics of Datasets.
In-depth insights#
Multimodal Fusion#
Multimodal fusion, in the context of this research paper, appears to be a crucial element for enhancing sequential recommendation systems. The approach centers on combining textual and visual information to generate richer item embeddings, which are then used to model user preferences more effectively. This suggests that a simple concatenation of modalities would be insufficient. Instead, a more sophisticated method is likely used, leveraging the power of a multimodal large language model (MLLM) to understand the interplay between different data types. The MLLM likely doesn’t just aggregate features but also learns complex relationships and interactions between text and image data, generating a more nuanced and comprehensive item representation than either modality could provide independently. This improved representation forms the basis for more accurate and personalized recommendations, by capturing subtle nuances often missed by single-modality approaches. The success hinges on the effectiveness of the MLLM’s multimodal understanding and its ability to generate robust, consistent, and informative embeddings for subsequent processing by the user modeling components.
Collaborative Alignment#
The concept of “Collaborative Alignment” in the context of multimodal LLMs for sequential recommendation is crucial for bridging the gap between content-based and ID-based approaches. It’s a strategy to effectively integrate collaborative filtering signals from traditional ID-based methods with the rich semantic understanding of LLMs. This is achieved by aligning user representations derived from both content (multimodal LLM) and ID (traditional collaborative filtering) models. This alignment isn’t a simple fusion but rather a post-alignment contrastive learning mechanism that ensures both types of signals contribute to a more precise and robust user profile. By aligning these perspectives, the model avoids the limitations of solely relying on either collaborative signals (which can lack contextual understanding) or solely on LLM’s content understanding (which may overlook established user preferences). The result is a more nuanced and effective recommendation system because the model leverages both the strengths of ID-based methods and the power of LLMs to capture detailed user interests and contextual information. Therefore, collaborative alignment is not just a technical detail; it’s a key design principle that directly impacts the system’s accuracy and ability to personalize recommendations.
LLM in RecSys#
The integration of Large Language Models (LLMs) into Recommender Systems (RecSys) represents a paradigm shift, moving beyond traditional collaborative filtering and content-based approaches. LLMs bring the power of natural language processing and multimodal understanding to RecSys, enabling more nuanced and personalized recommendations. Early approaches focused on directly incorporating item IDs and textual descriptions into the LLM, but this often resulted in suboptimal performance due to the inadequate integration of modalities and the overshadowing of collaborative signals. More sophisticated methods leverage LLMs to generate rich multimodal item representations from text and non-textual data, then integrate collaborative filtering information through techniques like post-alignment contrastive learning. This approach ensures a better balance between content understanding and user interaction history, leading to more robust and accurate recommendations. A key challenge is efficiently handling long user interaction sequences without sacrificing performance; hence, techniques like decoupled item and user modeling are emerging. Ultimately, the success of LLMs in RecSys depends on effective integration of their strengths with traditional methods, careful consideration of multimodal data, and addressing computational challenges associated with the scale of LLMs and the data involved.
Molar Framework#
The hypothetical “Molar Framework” for enhanced sequential recommendation, as described in the provided research paper excerpt, is a novel approach that cleverly integrates multimodal large language models (MLLMs) with traditional collaborative filtering techniques. Its core innovation lies in the post-alignment contrastive learning mechanism, which cleverly fuses content-based user representations (derived from the MLLM processing multimodal data) with ID-based user embeddings, thereby leveraging the strengths of both approaches while avoiding the pitfalls of premature fusion. The framework’s architecture involves a Multimodal Item Representation Model (MIRM) to generate comprehensive item embeddings from textual and non-textual features, and a Dynamic User Embedding Generator (DUEG) to effectively model evolving user interests. This design addresses limitations of previous LLM-based approaches by preserving both semantic richness and collaborative filtering signals for superior recommendation accuracy. The proposed framework’s modularity, combined with the post-alignment strategy, enhances robustness and allows for efficient training. The use of multiple fine-tuning objectives within MIRM further strengthens the framework’s ability to capture nuanced user interests and item features.
Future of SR#
The future of sequential recommendation (SR) systems looks bright, driven by several key trends. Multimodality will play a crucial role, moving beyond text-based interactions to integrate visual, audio, and other sensory data for richer user understanding. Large Language Models (LLMs) will continue to be integrated, but more effectively, addressing current limitations like neglecting collaborative filtering information. Future SR systems will likely leverage post-alignment mechanisms to better combine LLM-generated embeddings with traditional collaborative filtering signals, enhancing personalization. Advanced contrastive learning techniques will improve the alignment between content-based and ID-based user representations, leading to more robust and accurate recommendations. Addressing cold-start problems will also be critical, as will developing methods to explain recommendations and foster user trust. Finally, the development of more efficient models is key, reducing computational costs and enabling real-time, large-scale deployment of advanced SR algorithms.
More visual insights#
More on figures
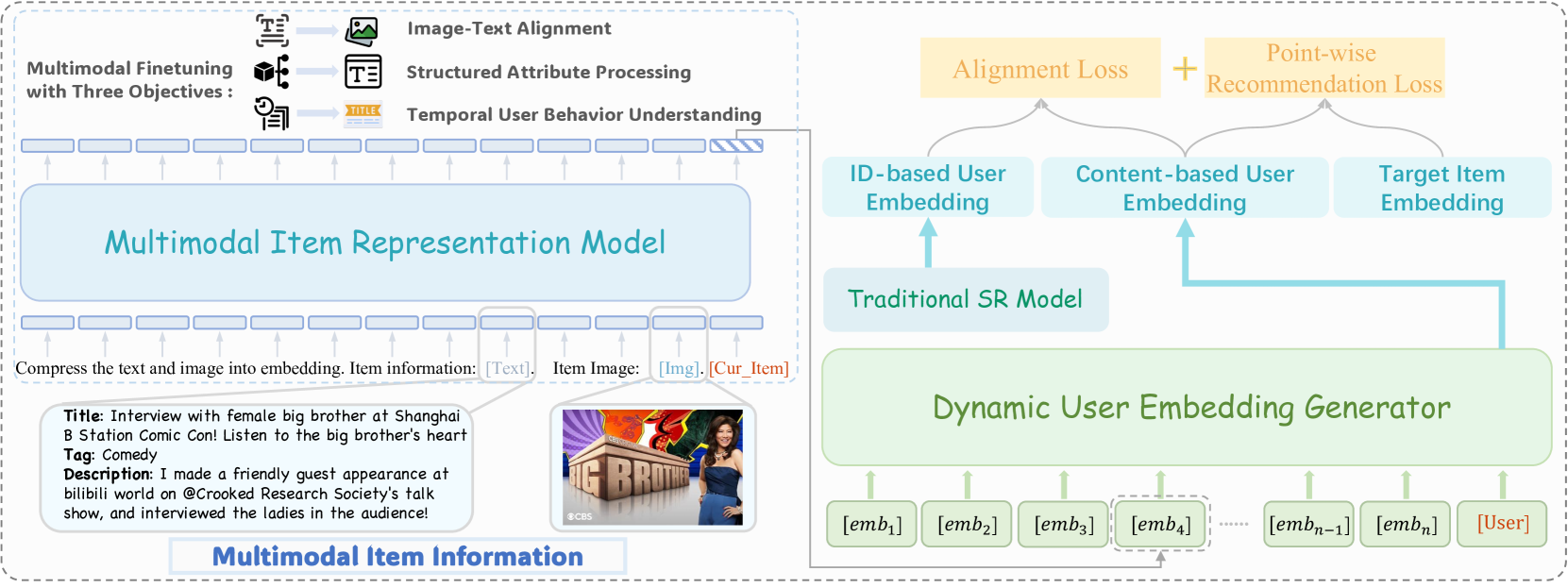
🔼 The figure illustrates the Molar framework, which consists of two main modules: the Multimodal Item Representation Model (MIRM) and the Dynamic User Embedding Generator (DUEG). MIRM processes various types of item information (text, images, etc.) to create a unified embedding for each item. This process involves a fine-tuning step focusing on aligning multimodal features. DUEG generates user embeddings based on the user’s interaction history. Finally, a joint optimization using contrastive learning integrates ID-based and content-based user embeddings to improve recommendation accuracy.
read the caption
Figure 2: Illustration of the Molar framework. The Multimodal Item Representation Model (MIRM) processes multimodal item information to generate item embeddings, while the Dynamic User Embedding Generator (DUEG) models user embeddings based on interaction histories for next-item prediction. First, MIRM is fine-tuned for multimodal feature alignment. Then, a joint optimization framework integrates ID-based and content-based user embeddings using a contrastive learning mechanism to enhance recommendation performance.

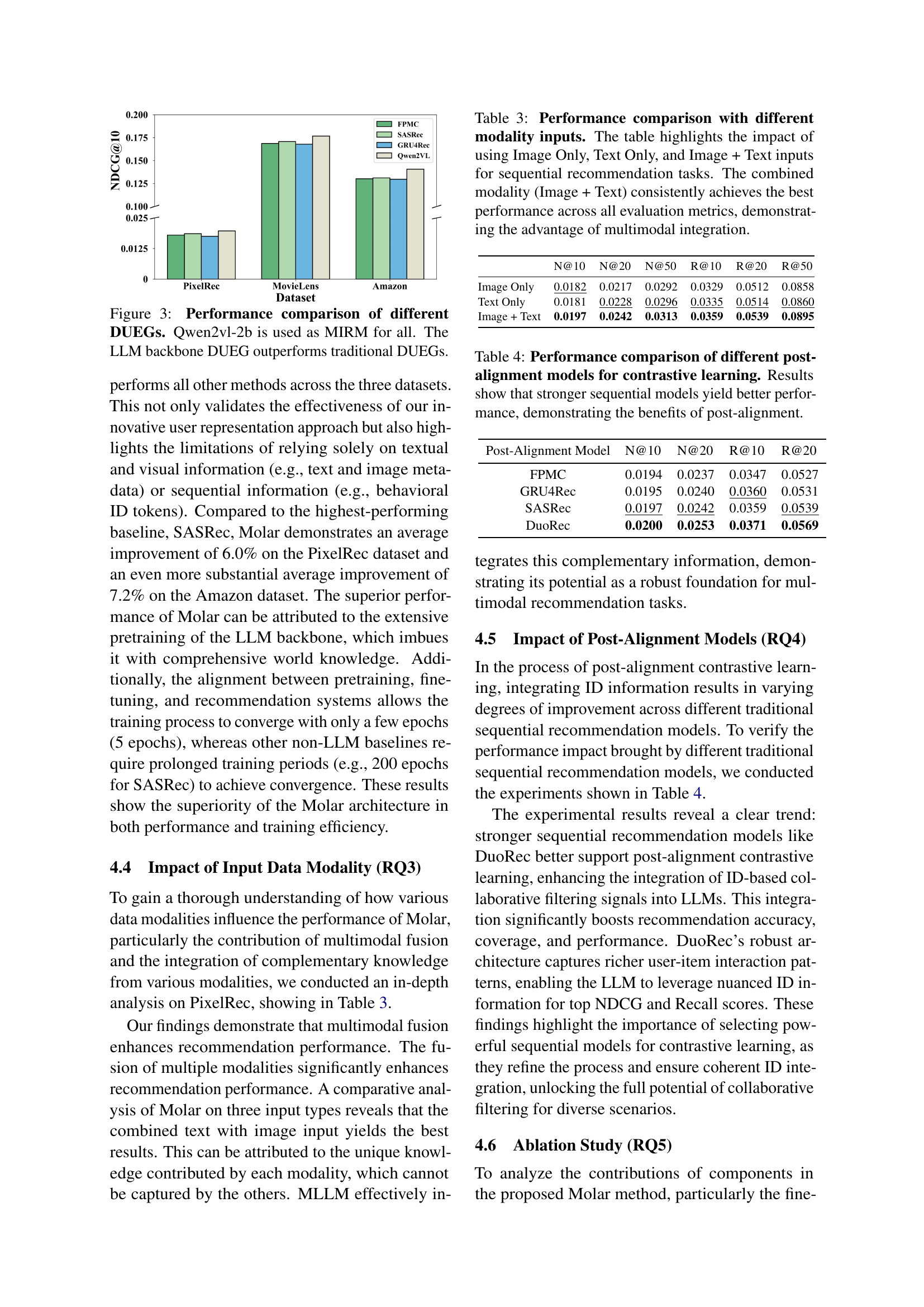
🔼 This figure compares the performance of different Dynamic User Embedding Generators (DUEGs) in a sequential recommendation system. All models use the same Multimodal Item Representation Model (MIRM), which is Qwen2vl-2b. The results show that the DUEG based on a Large Language Model (LLM) significantly outperforms traditional DUEGs (FPMC, SASRec, GRU4Rec), demonstrating the advantage of using LLMs for user representation in this context.
read the caption
Figure 3: Performance comparison of different DUEGs. Qwen2vl-2b is used as MIRM for all. The LLM backbone DUEG outperforms traditional DUEGs.
More on tables
| Methods | Amazon* N@10 | Amazon* N@20 | Amazon* R@10 | Amazon* R@20 | PixelRec* N@10 | PixelRec* N@20 | PixelRec* R@10 | PixelRec* R@20 | Movielens* N@10 | Movielens* N@20 | Movielens* R@10 | Movielens* R@20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Traditional | ||||||||||||
| FPMC | 0.1037 | 0.1059 | 0.1152 | 0.1232 | 0.0107 | 0.0129 | 0.0191 | 0.0290 | 0.0907 | 0.1129 | 0.1708 | 0.2756 |
| GRU4Rec | 0.1029 | 0.1054 | 0.1107 | 0.1190 | 0.0109 | 0.0127 | 0.0189 | 0.0284 | 0.0828 | 0.1081 | 0.1657 | 0.2664 |
| SASRec | 0.1080 | 0.1105 | 0.1188 | 0.1281 | 0.0131 | 0.0149 | 0.0207 | 0.0311 | 0.1116 | 0.1395 | 0.2137 | 0.3245 |
| DuoRec | 0.1281 | 0.1342 | 0.1406 | 0.1616 | 0.0147 | 0.0181 | 0.0241 | 0.0362 | 0.1530 | 0.1790 | 0.2704 | 0.3738 |
| Content-based | ||||||||||||
| SASRecBert | 0.1116 | 0.1130 | 0.1275 | 0.1365 | 0.0131 | 0.0161 | 0.0238 | 0.0357 | 0.1172 | 0.1465 | 0.2244 | 0.3407 |
| SASRecVit | 0.1142 | 0.1187 | 0.1237 | 0.1373 | 0.0126 | 0.0155 | 0.0211 | 0.0317 | 0.1204 | 0.1499 | 0.2295 | 0.3481 |
| SASRecBert+Vit | 0.1164 | 0.1179 | 0.1308 | 0.1437 | 0.0136 | 0.0167 | 0.0210 | 0.0315 | 0.1258 | 0.1567 | 0.2382 | 0.3599 |
| LLM-based | ||||||||||||
| CoLLM | 0.1298 | 0.1344 | 0.1388 | 0.1602 | 0.0173 | 0.0213 | 0.0296 | 0.0444 | 0.1658 | 0.1880 | 0.2895 | 0.4058 |
| HLLM | 0.1285 | 0.1351 | 0.1457 | 0.1668 | 0.0189 | 0.0232 | 0.0352 | 0.0528 | 0.1652 | 0.1933 | 0.2920 | 0.4037 |
| Ours | ||||||||||||
| Molar | 0.1407 | 01478 | 0.1580 | 0.1773 | 0.0197 | 0.0242 | 0.0359 | 0.0539 | 0.1768 | 0.2068 | 0.3124 | 0.4320 |
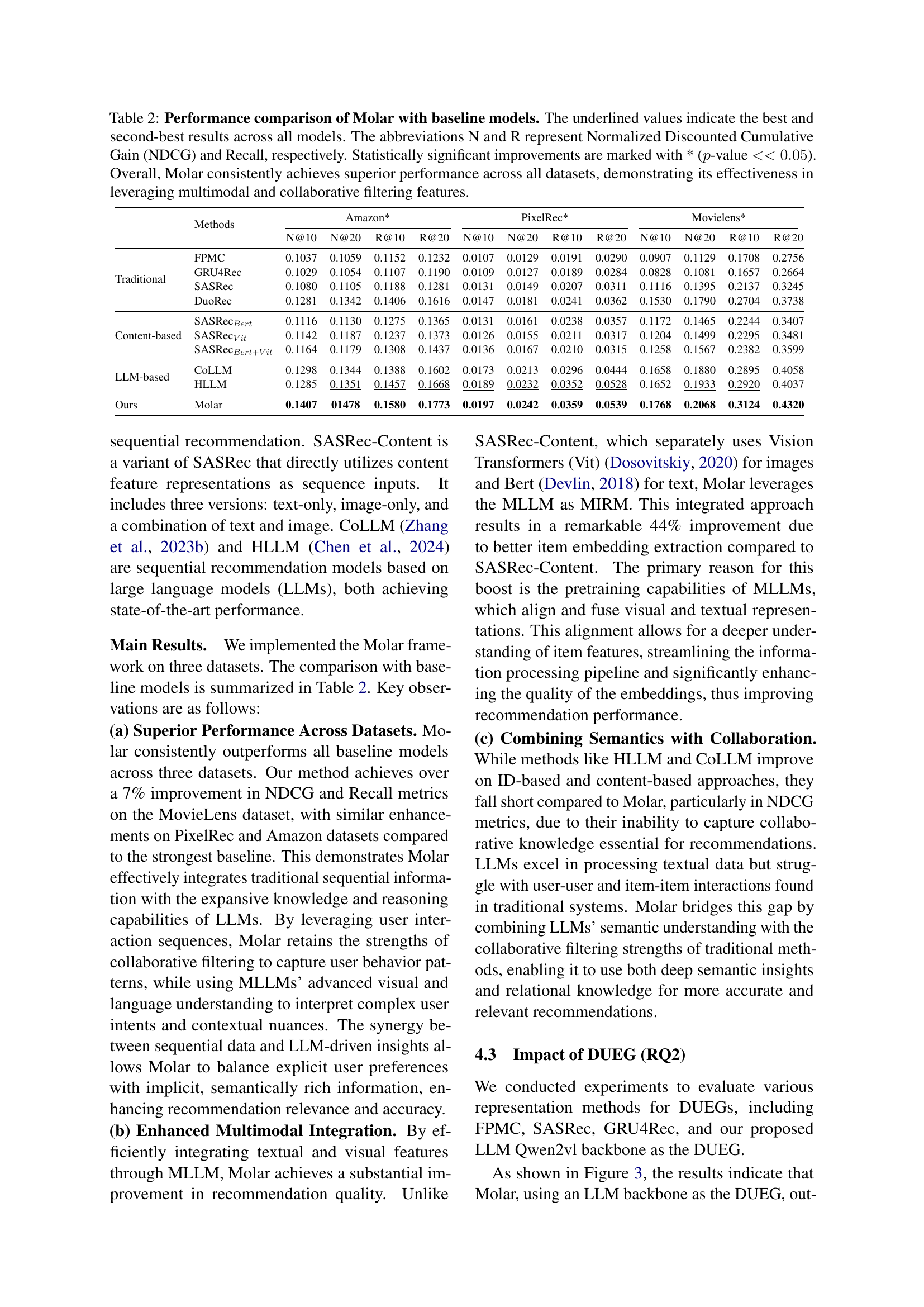
🔼 Table 2 presents a performance comparison of the proposed Molar model against various baseline models for sequential recommendation. The models are evaluated on three datasets using two metrics: Normalized Discounted Cumulative Gain (NDCG@K) and Recall@K, with K=10 and K=20. Underlined values highlight the top two performing models for each metric and dataset. Statistically significant improvements of Molar over the baselines (p<0.05) are marked with an asterisk. The results consistently demonstrate Molar’s superior performance across all datasets, showcasing the benefits of its multimodal and collaborative filtering approach.
read the caption
Table 2: Performance comparison of Molar with baseline models. The underlined values indicate the best and second-best results across all models. The abbreviations N and R represent Normalized Discounted Cumulative Gain (NDCG) and Recall, respectively. Statistically significant improvements are marked with * (p𝑝pitalic_p-value <<0.05much-less-thanabsent0.05<<0.05< < 0.05). Overall, Molar consistently achieves superior performance across all datasets, demonstrating its effectiveness in leveraging multimodal and collaborative filtering features.
| Method | N@10 | N@20 | N@50 | R@10 | R@20 | R@50 |
|---|---|---|---|---|---|---|
| Image Only | 0.0182 | 0.0217 | 0.0292 | 0.0329 | 0.0512 | 0.0858 |
| Text Only | 0.0181 | 0.0228 | 0.0296 | 0.0335 | 0.0514 | 0.0860 |
| Image + Text | 0.0197 | 0.0242 | 0.0313 | 0.0359 | 0.0539 | 0.0895 |
🔼 This table presents a comparison of the performance of a sequential recommendation model using different input modalities: Image Only, Text Only, and a combination of Image + Text. The results show that incorporating both image and text data consistently yields the best performance across various evaluation metrics. This highlights the significant advantage of integrating multimodal information (images and text) in improving the accuracy and effectiveness of sequential recommendation.
read the caption
Table 3: Performance comparison with different modality inputs. The table highlights the impact of using Image Only, Text Only, and Image + Text inputs for sequential recommendation tasks. The combined modality (Image + Text) consistently achieves the best performance across all evaluation metrics, demonstrating the advantage of multimodal integration.
| Post-Alignment Model | N@10 | N@20 | R@10 | R@20 |
|---|---|---|---|---|
| FPMC | 0.0194 | 0.0237 | 0.0347 | 0.0527 |
| GRU4Rec | 0.0195 | 0.0240 | 0.0360 | 0.0531 |
| SASRec | 0.0197 | 0.0242 | 0.0359 | 0.0539 |
| DuoRec | 0.0200 | 0.0253 | 0.0371 | 0.0569 |
🔼 This table presents a comparison of different post-alignment models used in contrastive learning within the Molar framework. It shows how the choice of underlying sequential recommendation model (e.g., FPMC, GRU4Rec, SASRec, DuoRec) affects the performance of the post-alignment process. The results demonstrate that stronger sequential recommendation models lead to better performance, highlighting the effectiveness of this post-alignment contrastive learning technique in improving recommendation accuracy.
read the caption
Table 4: Performance comparison of different post-alignment models for contrastive learning. Results show that stronger sequential models yield better performance, demonstrating the benefits of post-alignment.
| N@10 | N@20 | N@50 | R@10 | R@20 | R@50 | |
|---|---|---|---|---|---|---|
| Full Model | ||||||
| Molar | 0.0197 | 0.0242 | 0.0313 | 0.0359 | 0.0539 | 0.0895 |
| Fine-Tuning Data | ||||||
| w/o IT | 0.0186 | 0.0227 | 0.0298 | 0.0339 | 0.0512 | 0.0841 |
| w/o SA | 0.0189 | 0.0237 | 0.0302 | 0.0349 | 0.0528 | 0.0859 |
| w/o UB | 0.0183 | 0.0220 | 0.0287 | 0.0324 | 0.0495 | 0.0828 |
| w/o ALL | 0.0180 | 0.0219 | 0.0285 | 0.0313 | 0.0479 | 0.0808 |
| Post-Alignment | ||||||
| w/o CL | 0.0182 | 0.0225 | 0.0294 | 0.0325 | 0.0496 | 0.0819 |
🔼 This ablation study investigates the individual contributions of different components within the Molar model using the PixelRec dataset. It assesses the impact of removing each of the three fine-tuning data components (Image-Text, Structured Attributes, User Behavior) on the model’s performance, individually and in combination. Additionally, it evaluates the criticality of the post-alignment contrastive learning module. The results demonstrate the importance of all components for achieving optimal recommendation accuracy; removing any single component leads to a performance decrease. The post-alignment module is also shown to be essential for maintaining high recommendation accuracy.
read the caption
Table 5: Ablation study on the PixelRec dataset. The table evaluates the impact of different fine-tuning data components (Image-Text, Structured Attributes, User Behavior) and the post-alignment module. Results demonstrate that using all fine-tuning components achieves optimal performance, while removing any single component degrades performance. The post-alignment contrastive learning module is shown to be critical for maintaining high recommendation accuracy.
| MLLM Backbone | Training Type | N@10 | N@20 | R@10 | R@20 |
|---|---|---|---|---|---|
| Qwen2-VL-2B | Full-tuning | 0.0197 | 0.0242 | 0.0359 | 0.0539 |
| InternVL2.5-2B[6] | Full-tuning | 0.0191 | 0.0237 | 0.0349 | 0.0521 |
| deepseek-vl-1.3b[7] | Full-tuning | 0.0183 | 0.0225 | 0.0334 | 0.0499 |
| Qwen2-VL-7B | LoRA | 0.0200 | 0.0251 | 0.0369 | 0.0555 |
| Llama-3.2-11B-Vision[8] | LoRA | 0.0194 | 0.0249 | 0.0357 | 0.0542 |
🔼 This table presents a comparison of the performance achieved by Molar using different Multimodal Large Language Model (MLLM) backbones. It shows the results obtained using various MLLMs with different parameter sizes and training methods (full-tuning and LoRA), evaluating the performance using metrics such as NDCG@10, NDCG@20, Recall@10 and Recall@20. The goal is to analyze how the choice of MLLM backbone and training strategy affects the overall performance of the Molar framework.
read the caption
Table 6: Comparison of Different MLLM Backbone.
Full paper#