↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation models struggle to produce coherent videos from multiple sequential prompts, often suffering from unnatural transitions and weak prompt following. Existing methods require substantial training data and computational resources, hindering their practicality.
DiTCtrl, a training-free method, addresses these issues. By analyzing the MM-DiT architecture’s attention mechanism, DiTCtrl employs a KV-sharing strategy and latent blending to achieve smooth semantic transitions between different video segments generated from multiple prompts. This method produces high-quality videos, surpassing existing methods. The introduction of a new benchmark, MPVBench, aids in rigorous evaluation of multi-prompt video generation models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation because it presents DiTCtrl, a novel, training-free method for generating longer videos from multiple prompts. This addresses the limitations of existing models that struggle with coherent multi-prompt video generation. The introduction of MPVBench, a new benchmark for evaluating multi-prompt video generation, further enhances the value of this research. DiTCtrl’s success in achieving state-of-the-art performance without additional training opens up new avenues for research in efficient and flexible video generation.
Visual Insights#
🔼 DiTCtrl, a novel multi-prompt video generation method, is showcased. The figure presents a challenging example: an athlete gracefully gliding through three diverse scenes (ocean, snowy slopes, desert dunes). The method successfully generates a long video with complex motion and dramatic camera angles while maintaining smooth transitions between scenes and accurate semantic consistency with the input text prompts. This demonstrates DiTCtrl’s superior capability in handling multiple, sequential prompts and generating coherent, visually appealing longer videos.
read the caption
Figure 1: The proposed DiTCtrl takes multiple text prompts as input and demonstrates superior capability in generating longer videos with complex motion and smooth transitions as output. In this figure, we showcase a challenging example where an athlete glides through three distinct scenes. Despite the complex subject motion and dramatic camera movement, our method maintains remarkable stability throughout the sequence and seamless semantic transitions that faithfully follow the prompt descriptions.
| Method | CSCV | Motion smoothness | Text-Image similarity |
|---|---|---|---|
| Gen-L-Video | 59.44% | 83.36% | 30.58% |
| FreeNoise | 84.37% | 97.22% | 32.69% |
| FreeNoise+DiT | 78.74% | 97.76% | 30.90% |
| Video-Infinity | 74.97% | 97.31% | 32.35% |
| DiTCtrl(w/o kv-sharing) | 81.79% | 97.35% | 31.37% |
| DiTCtrl(Ours) | 84.90% | 97.80% | 30.68% |
🔼 This table presents a quantitative comparison of different video generation models using the MPVBench benchmark. The metrics used to evaluate the models are CSCV (Clip Similarity Coefficient of Variation), Motion Smoothness, and Text-Image Similarity. CSCV is a novel metric specifically designed for evaluating the smoothness of transitions in multi-prompt video generation. The table highlights the best-performing model for each metric, indicating superior performance in terms of transition quality, motion realism, and alignment between generated videos and their textual descriptions.
read the caption
Table 1: Evaluation metrics. Comparison of performance metrics for various video generation methods as benchmarked by MPVBench. Bold values represent the best performance within each group.
In-depth insights#
MM-DiT Attention#
The analysis of the Multi-Modal Diffusion Transformer (MM-DiT)’s attention mechanism reveals key insights into its functionality for video generation. The research reveals that the 3D full attention in MM-DiT exhibits behaviors similar to cross/self-attention blocks in UNet-like diffusion models, enabling precise semantic control across different prompts through a novel KV-sharing method. This approach leverages the inherent properties of the attention mechanism to maintain semantic consistency and facilitate smooth transitions between video clips generated from sequential prompts. The regional attention pattern analysis further highlights the distinct characteristics of text-to-text, video-to-video, text-to-video, and video-to-text attention regions, providing valuable insights into how these interactions contribute to coherent video generation. This understanding forms the basis for the development of DiTCtrl, a tuning-free multi-prompt video generation method that effectively utilizes MM-DiT’s attention mechanism for generating high-quality videos with complex motions and seamless semantic transitions.
Multi-Prompt Video#
Multi-prompt video generation presents a significant advancement in video synthesis, moving beyond the limitations of single-prompt approaches. The challenge lies in generating coherent and semantically consistent videos where multiple sequential prompts seamlessly transition. Existing methods often struggle with unnatural transitions, requiring extensive training data or complex architectures. A key focus is on developing techniques that ensure smooth transitions between segments evoked by different prompts, maintaining consistent object motion and preventing jarring shifts in style or content. This often necessitates careful attention control mechanisms within the underlying diffusion models, which is critical for achieving high-quality, realistic results. The development of new benchmarks for evaluating multi-prompt video generation is also crucial, providing objective metrics to compare different approaches and guide future research in this area. The integration of attention control and temporal consistency techniques within diffusion transformer architectures are key research directions. Addressing training data requirements and computational costs are also important factors to consider for the widespread adoption of this technology.
KV-Sharing Mechanism#
The KV-Sharing mechanism, as described in the context of multi-prompt video generation, is a technique designed to maintain semantic consistency across different video segments generated from sequential prompts. It leverages the key-value pairs from the attention mechanism of a pre-trained Multi-Modal Diffusion Transformer (MM-DiT) model. By sharing these keys and values between consecutive prompts, the model can effectively query and retrieve relevant visual features from previously generated video clips, ensuring smooth transitions and coherent object motion. This approach avoids the need for additional model training, making it a training-free method. The effectiveness of KV-Sharing lies in its ability to establish a strong connection between the semantic representations of different prompts. Attention masking further enhances this control, allowing for selective focusing on specific objects or regions, promoting alignment of relevant features in different video segments. This technique is particularly important in longer video generation tasks where maintaining consistency across numerous prompts becomes crucial. Overall, the KV-Sharing mechanism represents a novel and effective strategy to tackle the complexities of multi-prompt video generation within the framework of MM-DiT architecture.
Latent Blending#
Latent blending, in the context of video generation, is a crucial technique for achieving seamless transitions between different video segments generated from sequential prompts. It addresses the challenge of creating coherent and natural-looking videos where the changes between scenes are smooth and visually consistent. The core idea is to blend the latent representations of consecutive video segments, rather than directly concatenating pixel values. By operating in the latent space, the method allows for a smoother integration of visual features, reducing the risk of jarring cuts or discontinuities. The blending process often involves a weighting scheme applied across the overlapping frames, with the weights gradually transitioning from one segment’s latent representation to the next. This ensures that the changes in visual information happen progressively, creating a more fluid and visually appealing transition. Furthermore, careful consideration must be given to the alignment of semantic content across different prompts, and latent blending should ideally be combined with other techniques like attention control to enhance the visual coherence and fidelity to the user’s input. The efficacy of latent blending hinges on the choice of the weighting function and the nature of the latent representation, making it a technique with a high degree of flexibility and tunability, allowing for control over the smoothness and nature of the transition.
MPVBench#
The creation of MPVBench as a benchmark for multi-prompt video generation is a significant contribution. Its importance lies in addressing the limitations of existing evaluation metrics which often fail to capture the nuances of multi-prompt video generation. MPVBench’s design incorporates diverse transition types, moving beyond simple scene changes to include more complex variations such as stylistic shifts, camera movements, and location alterations. The inclusion of specialized metrics, likely going beyond simple similarity scores, is crucial for a thorough assessment of video quality, semantic coherence across prompts, and the smoothness of transitions between video segments generated from sequential prompts. This meticulous approach ensures that MPVBench provides a robust and reliable way to evaluate the performance of video generation models designed for multi-prompt scenarios, pushing the field forward by offering a standardized evaluation tool. The benchmark’s impact will likely extend to encouraging further research and innovation in this area, as researchers can now more effectively compare the strengths and weaknesses of various approaches and guide the development of more sophisticated multi-prompt video generation techniques.
More visual insights#
More on figures

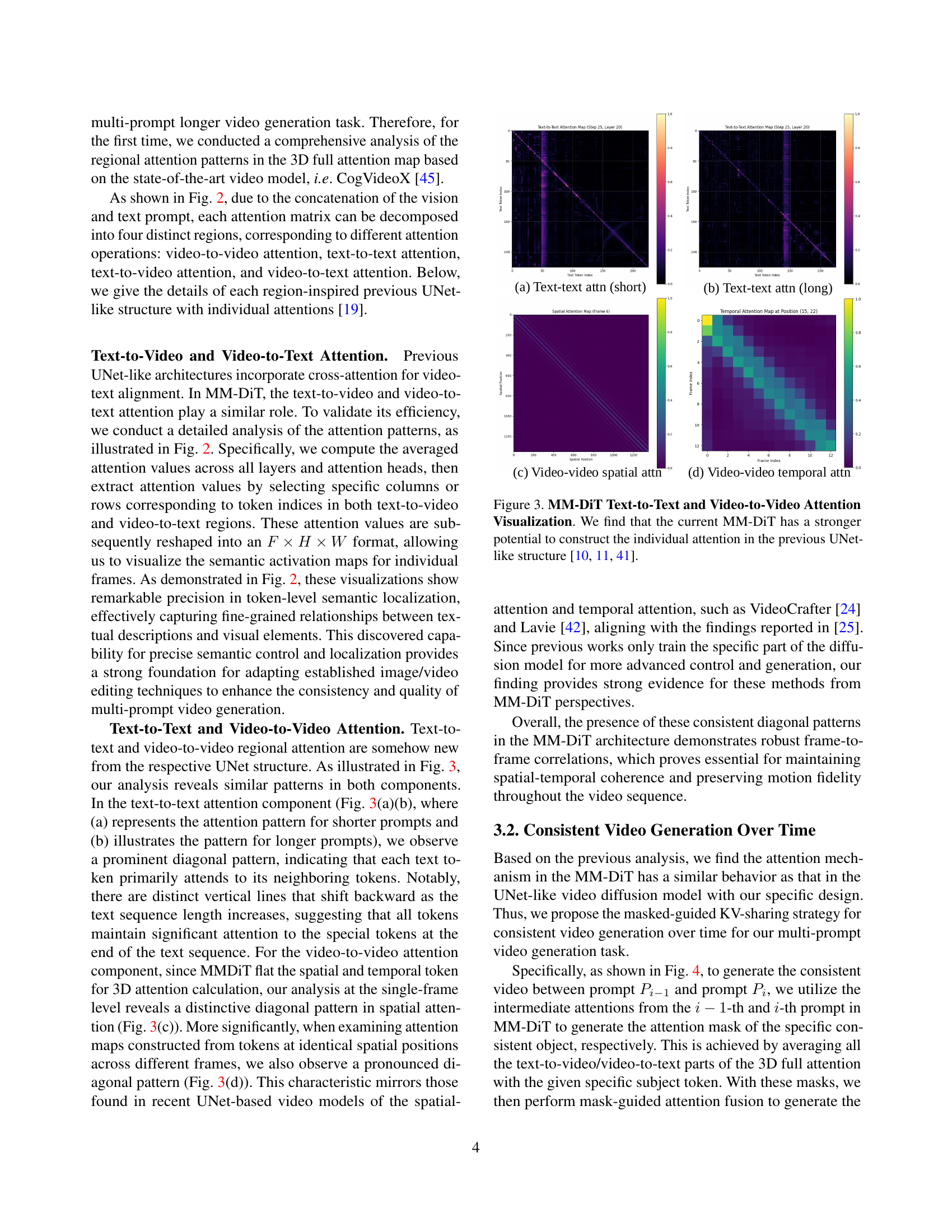
🔼 This figure illustrates the four distinct regions of the attention matrix within the Multi-Modal Diffusion Transformer (MM-DiT) architecture. These regions correspond to text-to-text, text-to-video, video-to-text, and video-to-video attention mechanisms. The analysis focuses on the prompt “a cat watches a black mouse,” demonstrating how each text token highlights a specific response based on the average attention weights from the text-to-video and video-to-text interactions. This visualization helps to understand how the MM-DiT processes both textual and visual information to generate videos.
read the caption
Figure 2: MM-DiT Attention Analysis. We find the attention matrix in MM-DiT attention can be divided into four different regions. As for the prompt of “ a cat watch a black mouse”, each text token shows a high-light response using the average of the text-to-video and video-to-text attention.

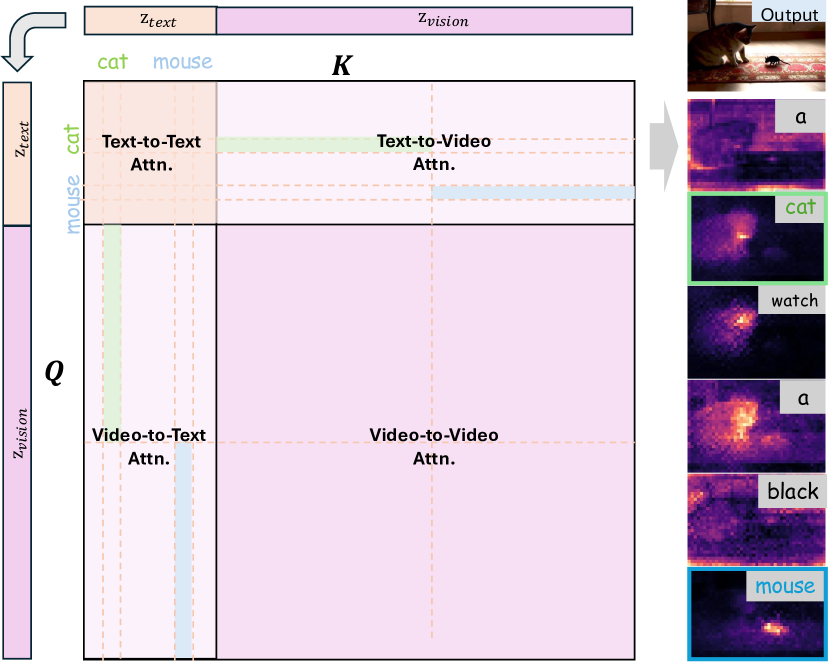
🔼 This figure visualizes the attention mechanisms within the Multi-Modal Diffusion Transformer (MM-DiT) architecture, specifically focusing on the Text-to-Text and Video-to-Video attention components. Unlike traditional UNet architectures which employ separate attention mechanisms, the MM-DiT uses a single 3D full attention process. The visualization reveals distinct diagonal patterns in both the text-to-text and video-to-video attention maps. In the text-to-text attention, the diagonal pattern indicates that each word primarily attends to its neighboring words, reflecting the sequential nature of language. In the video-to-video attention, the diagonal patterns suggest strong correlations between consecutive frames in both spatial and temporal dimensions. These findings indicate that the 3D full attention in MM-DiT behaves similarly to cross/self-attention mechanisms in UNet-like architectures, demonstrating its potential for precise semantic control and manipulation, which is essential for tasks like video editing and multi-prompt video generation.
read the caption
Figure 3: MM-DiT Text-to-Text and Video-to-Video Attention Visualization. We find that the current MM-DiT has a stronger potential to construct the individual attention in the previous UNet-like structure [10, 11, 41].

🔼 DiTCtrl synthesizes content- and motion-consistent videos from multiple prompts. It uses a pre-trained single-prompt model and applies a masked-guided KV-sharing attention mechanism to maintain consistency across prompts. The process involves generating initial latent representations (5 frames), using the first three to create the first video segment from prompt Pi-1, and the last three to create the second video segment from prompt Pi. The overlapping frame is highlighted in pink to show the transition, with blue and green latents distinguishing the segments.
read the caption
Figure 4: Pipeline of the proposed DiTCtrl. Our method tries to synthesize content-consistent and motion-consistent videos based on multi-prompts. The first video is synthesized with source text prompt Pi−1subscript𝑃𝑖1P_{i-1}italic_P start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT. During the denoising process for video synthesis, we convert the full-attention into masked-guided KV-sharing strategy to query video contents from source video 𝒱i−1subscript𝒱𝑖1\mathcal{V}_{i-1}caligraphic_V start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT, so that we can synthesize content-consistent video under the modified target prompt Pisubscript𝑃𝑖P_{i}italic_P start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. Note that initial latents are assumed to be 5 frames. The first three frames are used to generate the contents of Pi−1subscript𝑃𝑖1P_{i-1}italic_P start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT, and the last three frames are used to generate contents of Pisubscript𝑃𝑖P_{i}italic_P start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. The pink latent represents the overlapping frame, while the blue and green latents are used to distinguish different prompt segments.

🔼 This figure illustrates the latent blending strategy used in DiTCtrl for smooth transitions between consecutive video clips generated from different prompts. It shows how the latent representations (features) of overlapping frames from adjacent video segments are blended using a position-dependent weighting function. This function assigns higher weights to frames closer to their respective segments and lower weights to frames at the boundaries, creating a smooth transition between the distinct semantic content of the clips. The strategy ensures a seamless and temporally coherent video, even across different semantic contexts.
read the caption
Figure 5: Latent blending strategy for video transition between video clips.

🔼 Figure 6 presents a qualitative comparison of video generation results from different methods, showcasing the superior performance of the proposed DiTCtrl model. The comparison includes three state-of-the-art methods (Gen-L-Video, Video-Infinity, FreeNoise) and a commercial model (Kling). FreeNoise+DiT represents a modified version of FreeNoise integrated with the CogVideoX architecture, providing a strong baseline for comparison. The figure highlights DiTCtrl’s excellence in text-to-video alignment, temporal coherence, and motion quality, particularly in handling dynamic scenarios with sequential semantic transitions. Each method’s video generation is presented side-by-side for direct visual comparison, enabling an assessment of text-to-video alignment quality, temporal consistency across prompts, and motion accuracy.
read the caption
Figure 6: Generation results on given prompts by our method and baseline models. Kling is the commercial model, and Freenoise+DiT is our implementation of Freenoise on CogVideoX.

🔼 This figure visualizes the results of applying t-distributed stochastic neighbor embedding (t-SNE) dimensionality reduction to CLIP embeddings of video frames. Each point represents a frame from a generated video. The plot shows that videos generated by conventional multi-prompt methods tend to cluster in distinct groups. In contrast, videos generated by the proposed DiTCtrl method form a more continuous distribution. This indicates that DiTCtrl produces videos with smoother transitions between the semantic concepts represented in different prompts, resulting in a more coherent and less jarring overall video experience.
read the caption
Figure 7: T-SNE visualization of CLIP embeddings. Each point represents the CLIP embedding of a single video frame after dimensionality reduction. The visualization demonstrates that conventional multi-prompt videos form distinct clusters, while our method produces a more continuous distribution, indicating smoother semantic transitions.

🔼 This ablation study visualizes the impact of different components within the DiTCtrl model on multi-prompt video generation. The figure shows that the full DiTCtrl model (with mask-guided KV-sharing and latent blending) produces videos with 98 frames that maintain consistent visual coherence across multiple prompts, unlike other methods that generate 105 frames but show inconsistencies or unnatural transitions. The results highlight the importance of each component: mask-guided KV-sharing ensures accurate object tracking, latent blending enables seamless transitions, and both contribute to the overall visual quality and temporal consistency.
read the caption
Figure 8: Ablation Component in DiTCtrl. The first and second rows have 98 frames, while the remaining methods generate 105 frames.

🔼 Figure 9 showcases the capabilities of the proposed DiTCtrl method in generating a longer video from a single prompt. It visually demonstrates that the model can produce a coherent and temporally consistent video sequence extending well beyond the typical length limitations of previous video generation models. The example visualizes the extended length and consistent quality achievable with the method.
read the caption
Figure 9: single prompt longer video generation example.

🔼 This figure illustrates the mask-guided KV-sharing mechanism used in DiTCtrl for multi-prompt video generation. It shows how attention maps from two consecutive prompts (Pi-1 and Pi) are used to generate a mask that guides the attention mechanism in the MM-DiT block. By focusing on specific tokens (like ‘a running horse’), a foreground mask (Mi-1) is created from the Pi-1 prompt and used to guide the attention of the current prompt (Pi), ensuring that the object’s appearance remains consistent across prompts. The resulting foreground-focused attention (Ffore) and background attention (Fback) are combined with the mask to generate the final fused attention (Ffusion) for the current video frame. This ensures a smooth and semantically consistent transition between video segments generated from different prompts.
read the caption
Figure 10: Mask-guided KV-sharing details.

🔼 Figure 11 showcases example video generation results from the DiTCtrl model using multiple prompts. The figure visually demonstrates the model’s ability to generate coherent and smooth transitions between distinct scenes described by sequential prompts. Each row shows a different video generation scenario, illustrating various transitions, such as changes in camera angle, location, or subject actions. The consistent visual quality and smooth transitions highlight DiTCtrl’s effectiveness in handling multi-prompt video generation tasks.
read the caption
Figure 11: More multi-prompt results

🔼 Figure 12 presents three examples of videos generated using DiTCtrl with multiple prompts. Each example showcases a different scene and transitions between them. The first example shows a white SUV transitioning from a dirt road to a snowy path and finally to a starry night scene. The second example depicts a dark knight on a horse transitioning from a grassland, to a snowy field, and finally to a desert. The third example showcases a flower bud transitioning from a closed bud to an open flower in full bloom. These examples highlight DiTCtrl’s ability to generate coherent and visually appealing videos by smoothly transitioning between different scenes and semantic concepts.
read the caption
Figure 12: More multi-prompt results

🔼 This figure displays a comparison of video generation results from several methods for a multi-prompt video generation task focusing on motion and background transitions. The top row shows the results for a prompt sequence depicting a dark knight on horseback in a grassland, then galloping across a snowy field. The bottom row shows a transition from a snowy city street to a sunny city street. The goal is to illustrate how well each method maintains coherence in both the motion of the subject (dark knight/vehicles) and the overall background between scene changes. Each column represents a different method: Kling (commercial), Gen-L-Video, Video-Infinity, FreeNoise, FreeNoise+DiT, and the authors’ proposed DiTCtrl method.
read the caption
Figure 13: Motion and background transition.

🔼 This figure showcases the effectiveness of the proposed DiTCtrl model in generating videos with smooth background transitions. It compares the output of DiTCtrl against several baselines (Kling, Gen-L-Video, Video-Infinity, FreeNoise, and FreeNoise+DiT) on a specific prompt requesting a background transition from a snowy city street to a sunny city street. The comparison highlights DiTCtrl’s superior ability to produce natural and coherent transitions between scenes, unlike the baselines which often exhibit abrupt changes, artifacts, or unnatural motion.
read the caption
Figure 14: Background transition.

🔼 This figure visualizes the results of single-prompt longer video generation. It showcases several example videos, each generated from a single text prompt, demonstrating the model’s capability to produce videos of considerable length while maintaining coherence and visual quality. Each sequence is presented with frames from different stages of the generated video, illustrating the temporal consistency. This demonstrates the effectiveness of the model in generating longer videos exceeding what was previously possible.
read the caption
Figure 15: Visualization of single prompt longer video generation.

🔼 This figure demonstrates the effect of reweighting attention scores in the MM-DiT architecture for video editing. Subfigure (a) shows how reducing attention scores for certain tokens (e.g., ‘pink’) leads to a decrease in the prominence of that color in the generated video, while subfigure (b) shows that increasing attention scores for specific tokens enhances the presence of those features (e.g., ‘snowy’). This illustrates the precise control over semantic aspects that the DiTCtrl method offers for video editing.
read the caption
Figure 16: Reweighting example of Video Editing.

🔼 This figure demonstrates the results of applying the word swap video editing technique. The top row showcases editing where ‘a large bear’ is replaced with ‘a large lion.’ The bottom row shows how changing ‘a white vintage SUV’ to ‘a red vintage SUV’ alters the generated video. Both edits are made using the DiTCtrl method, illustrating the model’s ability to make precise semantic changes in generated videos by swapping text tokens in the prompts, whilst maintaining video consistency and temporal coherence.
read the caption
Figure 17: Word Swap example of Video Editing.

🔼 This figure demonstrates the effectiveness of the proposed mask-guided KV-sharing mechanism. The top row showcases results obtained without this mechanism, revealing inconsistencies in object identity (horse to zebra) and scene transitions (dirt road to snowy road). The bottom row displays results from the full model, incorporating mask-guided KV-sharing. It highlights improved consistency in object identity and scene transitions, demonstrating the method’s ability to maintain visual coherence across multiple prompts.
read the caption
Figure 18: Ablation study of mask-guided KV-sharing results. First row shows our model without mask-guided KV-sharing, while the second row demonstrates our full model with mask-guided KV-sharing. The prompt for (a) transitions from “A powerful horse gallops across a field…” to “A striking zebra leads its herd across the field…”. The prompt for (b) evolves from “A white SUV drives a dirt road…” to “A white SUV powers through snow…”
More on tables
| Method | Overall preference | Motion Consistency | Temporal Alignment | Text Pattern |
|---|---|---|---|---|
| Gen-L-Video | 1.15 | 1.14 | 1.08 | 1.25 |
| FreeNoise | 3.02 | 2.90 | 2.99 | 3.08 |
| FreeNoise+DiT | 3.81 | 3.93 | 3.75 | 3.78 |
| Video-Infinity | 2.90 | 2.85 | 2.91 | 2.98 |
| DiTCtrl(Ours) | 4.11 | 4.17 | 4.26 | 3.91 |
🔼 This table presents the results of a user study comparing the performance of different video generation methods across four key aspects: overall preference, motion pattern, temporal consistency, and text alignment. Participants rated each method on a scale of 1 to 5, with 5 representing the best performance. The table highlights the strengths and weaknesses of each method, providing a qualitative assessment of their video generation capabilities. Bold values indicate the best-performing method for each specific evaluation criterion.
read the caption
Table 2: User study. Human evaluation of different video generation methods across multiple aspects. Scores range from 1 to 5, with higher scores indicating better performance. Bold values represent the best performance within each metric.
| Hyperparameters | |
|---|---|
| base model | CogVideoX-2B |
| sampler | VPSDEDPMPP2MSampler |
| sample step | 50 |
| guidance scale | 6 |
| resolution | 480x720 |
| sampling num frames | 13 |
| overlap size | 6 |
| kv-sharing steps | [2,25] |
| kv-sharing layers | [25,30] |
| threshold | 0.3 |
| λ of CSCV | 10 |
🔼 Table 3 presents the hyperparameters used in the DiTCtrl model. It lists the settings for various aspects of the video generation process, including the base model used (CogVideoX-2B), the sampler employed (VPSDEDPMPP2MSampler), the number of sampling steps, the guidance scale used during training, the resolution of the generated videos, the number of frames in a sampling sequence, the overlap size between consecutive video clips, the parameters for the KV-sharing mechanism, and a threshold value. This information is essential for replicating the experimental setup described in the paper.
read the caption
Table 3: Hyperparameters of DiTCtrl.
| Method | CSCV | Motion smoothness | Text-Image similarity |
|---|---|---|---|
| Isolated | 72.37% | 97.78% | 32.05% |
| DiTCtrl(w/o kv-sharing) | 81.79% | 97.35% | 31.37% |
| DiTCtrl(w/o mask-guided) | 84.92% | 97.76% | 30.66% |
| DiTCtrl(full) | 84.90% | 97.80% | 30.68% |
🔼 This table presents a quantitative ablation study evaluating the impact of different components of the DiTCtrl model on the performance of multi-prompt video generation. Metrics include the Clip Similarity Coefficient of Variation (CSCV), which measures the smoothness of transitions between video segments; Motion Smoothness, assessing the naturalness of object movements; and Text-Image Similarity, evaluating the alignment between video content and the text prompts. The results are compared for four variations of the model: the isolated baseline (no DiTCtrl), DiTCtrl without KV-sharing, DiTCtrl without mask-guided generation, and the full DiTCtrl model. This allows for a precise assessment of the contributions of each component to the overall performance of multi-prompt video generation.
read the caption
Table 4: Comparison of metrics for ablation.
Full paper#