↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-3D and image-to-3D models produce high-quality 3D assets, but these assets typically lack internal structure and are represented as single, fused objects. This limits their use in applications requiring manipulation of individual parts, such as video games or robotics. Existing methods struggle with automatically segmenting 3D objects into meaningful parts and completing occluded parts.
PartGen solves this by employing a novel multi-view diffusion model approach. It first identifies plausible parts by segmenting multi-view images of 3D objects. A second diffusion model then completes the partially visible or occluded parts, accounting for their context within the whole object. This enables accurate 3D reconstruction of each part. The process allows for the generation of multiple plausible segmentations and the completion of entire invisible parts. The method also enables 3D part editing based on text instructions, improving control in 3D object creation. The superior performance is demonstrated on a large dataset of 3D objects and various applications.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel approach to 3D object generation that produces assets composed of meaningful parts, addressing a critical limitation of existing methods. This addresses the need for structured, editable 3D assets in various applications, such as video games, robotics, and embodied AI. The method’s use of multi-view diffusion models offers improved flexibility and control in 3D object creation, paving the way for more advanced and intuitive 3D content generation and manipulation.
Visual Insights#

🔼 PartGen is a system for creating compositional 3D objects. It starts with text, an image, or a pre-existing 3D model. A multi-view diffusion model automatically identifies and segments the object into its constituent parts. A second diffusion model then completes and reconstructs each part in 3D, considering the context of the other parts for accurate assembly. The system also allows for text-based 3D part editing, offering greater control over the final object’s creation.
read the caption
Figure 1: We introduce PartGen, a pipeline that generates compositional 3D objects similar to a human artist. It can start from text, an image, or an existing, unstructured 3D object. It consists of a multi-view diffusion model that identifies plausible parts automatically and another that completes and reconstructs them in 3D, accounting for their context, i.e., the other parts, to ensure that they fit together correctly. Additionally, PartGen enables 3D part editing based on text instructions, enhancing flexibility and control in 3D object creation.
| Method | Automatic mAP50↑ | Automatic mAP75↑ | Seeded mAP50↑ | Seeded mAP75↑ |
|---|---|---|---|---|
| Part123 [44] | 11.5 | 7.4 | 10.3 | 6.5 |
| SAM2† [70] | 20.3 | 11.8 | 24.6 | 13.1 |
| SAM2* [70] | 37.4 | 27.0 | 44.2 | 30.1 |
| SAM2 [70] | 35.3 | 23.4 | 41.4 | 27.4 |
| PartGen (1 sample) | 45.2 | 32.9 | 44.9 | 33.5 |
| PartGen (5 samples) | 54.2 | 33.9 | 51.3 | 32.9 |
| PartGen (10 samples) | 59.3 | 38.5 | 53.7 | 35.4 |
🔼 This table presents the quantitative results of the part segmentation task, comparing the proposed PartGen method with several baselines. The baselines include SAM2, a popular semantic segmentation model, tested in three configurations: (1) original SAM2; (2) SAM2 fine-tuned on the PartGen dataset; and (3) SAM2 fine-tuned for multi-view segmentation. PartGen’s performance is evaluated using three different sampling counts (1, 5, and 10), showing how performance improves with more samples, reflecting the stochastic nature of the approach. The evaluation metrics are mean Average Precision (mAP) at IoU thresholds of 50% and 75%, indicating the accuracy of part segmentation in terms of overlap with ground truth. The results demonstrate that PartGen significantly outperforms the SAM2 baselines.
read the caption
Table 1: Segmentation results. SAM2∗superscriptSAM2\text{SAM2}^{*}SAM2 start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT is fine-tuned our data and SAM2†superscriptSAM2†\text{SAM2}^{{\dagger}}SAM2 start_POSTSUPERSCRIPT † end_POSTSUPERSCRIPT is fine-tuned for multi-view segmentation.
In-depth insights#
Multi-view Diffusion#
Multi-view diffusion models represent a significant advancement in 3D object generation and reconstruction. By leveraging multiple 2D views of an object, these models overcome limitations inherent in single-view approaches. The use of diffusion models enables the generation of plausible and view-consistent part segmentations, accurately capturing the object’s composition. This is particularly crucial when parts of the object are occluded in some views. The multi-view nature ensures the parts generated are not only individually realistic but also seamlessly integrate within the full 3D model. Furthermore, the generative aspect of the approach allows for the completion of occluded parts, even hallucinating entirely missing pieces based on context. This capability greatly improves the quality of 3D reconstructions compared to traditional methods that struggle with missing information. The combination of multi-view consistency, completion, and diffusion models creates a powerful pipeline for various applications, such as part editing, and offers a significant step towards generating truly realistic and usable 3D assets from various input modalities.
Part Segmentation#
The core challenge of Part Segmentation in 3D object processing lies in the inherent ambiguity of defining parts. PartGen cleverly addresses this by framing the problem as a multi-view consistent colorization task. This shifts the focus from precise, deterministic boundaries to a probabilistic representation of plausible part distributions, aligning with the variability inherent in artistic interpretations. Instead of relying on a single, predefined segmentation, PartGen utilizes a diffusion model to generate multiple possible segmentations, thus capturing the nuanced ambiguity that would be missed by a purely deterministic approach. This generative approach allows for more flexible and context-aware segmentations, considering not just the object’s visible surface but also occluded regions. The use of a multi-view framework is crucial, allowing the model to learn relationships between views and produce more consistent and reliable part boundaries, even in challenging cases with occlusions. Overall, PartGen’s approach to Part Segmentation is innovative in its handling of ambiguity, leveraging the power of generative models to produce realistic and diverse results.
3D Part Completion#
The core challenge of 3D part completion lies in reconstructing 3D shapes from incomplete or occluded views. The paper cleverly addresses this by using a multi-view diffusion model, not just to segment parts, but also to complete and generate missing views. This is crucial because directly reconstructing a partially visible part with a standard 3D reconstruction network often fails. The multi-view approach considers contextual information from the entire object, ensuring that completed parts integrate seamlessly. This generative completion is key to handling heavily occluded or even entirely invisible parts, going beyond simple inpainting. The model’s ability to “hallucinate” missing information based on context shows a sophisticated understanding of object composition. This novel approach surpasses standard 3D reconstruction methods and is demonstrated by empirical results showing improved reconstruction quality and coherence.
Compositional Gen#
A hypothetical section titled “Compositional Gen” within a research paper on 3D generation would likely explore methods for creating complex 3D objects by assembling simpler, meaningful parts. This contrasts with monolithic generation approaches that produce a single, fused 3D model lacking inherent structure. Key aspects would include techniques for part segmentation (identifying individual components from a complete object), part completion (generating missing or occluded portions of parts), and part assembly (combining individual parts into a coherent whole). The research might investigate different representation methods for parts, such as implicit neural fields or meshes, and explore how context and relationships between parts influence the final object’s appearance. Advanced techniques could involve generative models capable of learning and modeling the distribution of plausible part compositions, enabling diverse outputs similar to those of human artists. The section would likely emphasize the benefits of compositional generation for downstream tasks like 3D editing and manipulation, where individual parts can be modified independently, offering increased flexibility and control over the final product. Evaluation would focus on assessing the accuracy and realism of generated parts, as well as the overall coherence and quality of the assembled 3D objects.
PartGen Limits#
PartGen, while innovative, faces limitations stemming from its reliance on a curated dataset of artist-created 3D assets. This introduces inherent biases that may affect generated outputs and raise ethical concerns regarding cultural representation. The model’s capacity is currently limited to objects with fewer than 10 parts, potentially hindering its effectiveness in more complex scenarios. Highly intricate scenes, like those with dense foliage, may result in inaccuracies during depth map generation, impacting reconstruction quality. The approach primarily focuses on object-level generation, neglecting scene-level applications, which represent a significant area for future expansion. Addressing these limitations, especially the data bias and scalability challenges, will be crucial for PartGen’s wider applicability and reliability.
More visual insights#
More on figures

🔼 PartGen starts with text, an image, or a 3D model as input. It first generates a multi-view grid image of the object. A diffusion-based segmentation network then identifies the object’s constituent parts, ensuring consistency across multiple views. Each segmented part, along with its context within the entire object, is fed into a multi-view part completion network. This network completes each part’s view, handling occlusions and generating missing information. Finally, a pre-trained 3D reconstruction model uses these completed views to generate the final 3D parts that make up the object.
read the caption
Figure 2: Overview of PartGen. Our method begins with text, single images, or existing 3D objects to obtain an initial grid view of the object. This view is then processed by a diffusion-based segmentation network to achieve multi-view consistent part segmentation. Next, the segmented parts, along with contextual information, are input into a multi-view part completion network to generate a fully completed view of each part. Finally, a pre-trained reconstruction model generates the 3D parts.

🔼 The figure displays examples from the dataset used to train the PartGen model. The dataset consists of 3D objects created by artists and already decomposed into meaningful parts. The decomposition is natural, reflecting how a human artist would separate the object into its constituent components.
read the caption
Figure 3: Training data. We obtain a dataset of 3D objects decomposed into parts from assets created by artists. These come ‘naturally’ decomposed into parts according to the artist’s design.

🔼 This figure displays multiple segmentations of the same 3D object generated by the PartGen model. Each segmentation shows a different plausible decomposition of the object into meaningful parts, demonstrating the model’s ability to capture the variability inherent in how a human artist might segment a similar object. Running the PartGen model multiple times produces a range of segmentations, illustrating the model’s inherent stochasticity and its capacity to generate various interpretations of an object’s constituent parts.
read the caption
Figure 4: Examples of automatic multi-view part segmentations. By running our method several times, we obtain different segmentations, covering the space of artist intents.

🔼 Figure 5 presents qualitative results demonstrating PartGen’s part completion capabilities. The input images (with blue borders) show partially visible or occluded parts of 3D objects. PartGen processes these incomplete parts and generates various plausible completed versions. Notably, even when the input is an ’empty’ part, PartGen intelligently hallucinates internal structures such as sand or the inner workings of a wheel, showcasing its ability to fill in missing information contextually.
read the caption
Figure 5: Qualitative results of part completion. The images with blue borders are the inputs. Our algorithm produces various plausible outputs across different runs. Even if given an empty part, PartGen attempts to generate internal structures inside the object, such as sand or inner wheels.

🔼 Figure 6 showcases PartGen’s versatility across various applications. Panel (a) demonstrates part-aware text-to-3D generation, where textual descriptions are used to create 3D objects composed of distinct, meaningful parts. Panel (b) shows part-aware image-to-3D generation, reconstructing 3D objects from input images while preserving and enhancing their component parts. Finally, panel (c) illustrates 3D decomposition, where an existing unstructured 3D model is intelligently broken down into its constituent parts. Each panel provides examples of the input and the resulting 3D models, highlighting the realistic and meaningful part compositions achieved by PartGen.
read the caption
Figure 6: Examples of applications. PartGen can effectively generate or reconstruct 3D objects with meaningful and realistic parts in different scenarios: a) Part-aware text-to-3D generation; b) Part-aware image-to-3D generation; c) 3D decomposition.

🔼 Figure 7 showcases the application of PartGen for 3D part editing. It demonstrates the model’s ability to modify the appearance and shape of individual parts within a 3D object using only text-based instructions. Three examples are shown, highlighting how different parts (e.g., a t-shirt, hat, cup) can be altered. This illustrates the power of PartGen’s part-level control to enable fine-grained manipulation of 3D assets.
read the caption
Figure 7: 3D part editing. We can edit the appearance and shape of the 3D objects with text prompt.

🔼 Figure 8 demonstrates 3D part editing using a diffusion model. The top half shows examples of training data for this model. Each example includes a 3D object, a mask indicating the part to be edited, the masked image (showing only the part to be edited), and text instructions describing the desired changes. The model learns to fill in the masked area based on the text and the visible context. The bottom half shows how the part captioning pipeline works. A red circle highlights the part for which a caption is needed, guiding a Large Vision-Language Model (LVLM) to generate a suitable caption for that specific part.
read the caption
Figure 8: 3D part editing and captioning examples. The top section illustrates training examples for the editing network, where a mask, a masked image, and text instructions are provided as conditioning to the diffusion network, which fills in the part based on the given textual input. The bottom section demonstrates the input for the part captioning pipeline. Here, a red circle and highlights are used to help the large vision-language model (LVLM) identify and annotate the specific part.

🔼 This figure compares the performance of PartGen against several baselines on the task of 3D part segmentation. The y-axis shows the recall, which is the percentage of correctly identified parts. The x-axis represents the number of top predictions considered (i.e. ranking). The curves show that PartGen (with different sampling strategies: 1, 5, and 10 samples) significantly outperforms the SAM2 baseline and its variants, demonstrating its ability to accurately segment 3D objects into meaningful parts.
read the caption
Figure 9: Recall curve of different methods. Our method achieve better performance comparing with SAM2 and its variants.

🔼 Figure 10 presents supplementary examples showcasing PartGen’s capabilities. It demonstrates the model’s ability to process diverse input types (text, images, or existing 3D scans) and generate or reconstruct high-quality 3D objects composed of distinct, meaningful parts. The examples highlight the model’s versatility and effectiveness in handling complex 3D structures.
read the caption
Figure 10: More examples. Additional examples illustrate that PartGen can process various modalities and effectively generate or reconstruct 3D objects with distinct parts.

🔼 Figure 11 demonstrates the iterative aspect of PartGen. It shows how users can incrementally add new parts to an existing 3D object. The figure showcases a sequence of images, beginning with a simple base object and gradually adding more complex parts. Each step displays the newly added part individually, along with the composite object containing all previously generated parts. This showcases PartGen’s ability to combine results from multiple runs of the pipeline, allowing for flexible and layered 3D model creation.
read the caption
Figure 11: Iteratively adding parts. We show that users can iteratively add parts and combine the results of PartGen pipeline.

🔼 Figure 12 illustrates three failure scenarios encountered during the PartGen pipeline. (a) shows a failure in the multi-view grid generation stage, where inconsistencies in the generated views hinder accurate 3D reconstruction. The generated views of the object lack 3D consistency, resulting in an inaccurate representation. (b) demonstrates a segmentation failure where semantically distinct parts of the object are incorrectly grouped together. The model fails to accurately segment the object into meaningful and separate parts. (c) presents a reconstruction model failure. In this case, the complexity of the object’s geometry leads to inaccuracies in the depth map, impacting the quality of the final 3D reconstruction. The reconstruction model struggles to accurately represent the intricate details of the object due to its complexity, resulting in errors in the generated depth map.
read the caption
Figure 12: Failure Cases. (a) Multi-view grid generation failure, where the generated views lack 3D consistency. (b) Segmentation failure, where semantically distinct parts are incorrectly grouped together. (c) Reconstruction model failure, where the complex geometry of the input leads to inaccuracies in the depth map.
More on tables
| Method | Compl. | Multi-view | Context | View completion J ↑ | 3D reconstruction S ↑ | ||||
|---|---|---|---|---|---|---|---|---|---|
| Oracle (J^=J) | GT | — | — | 1.0 | 0.0 | ∞ | 0.957 | 0.027 | 18.91 |
| PartGen (J^=B(I⊙M,I)) | ✓ | ✓ | ✓ | 0.974 | 0.015 | 21.38 | 0.936 | 0.039 | 17.16 |
| w/o context† (J^=B(I⊙M)) | ✓ | ✓ | ✗ | 0.951 | 0.028 | 16.80 | 0.923 | 0.046 | 14.83 |
| single view‡ (J^v=B(I_v⊙M_v,I_v)) | ✓ | ✗ | ✓ | 0.944 | 0.031 | 15.92 | 0.922 | 0.051 | 13.25 |
| None (J^=I⊙M) | ✗ | — | — | 0.932 | 0.039 | 13.24 | 0.913 | 0.059 | 12.32 |
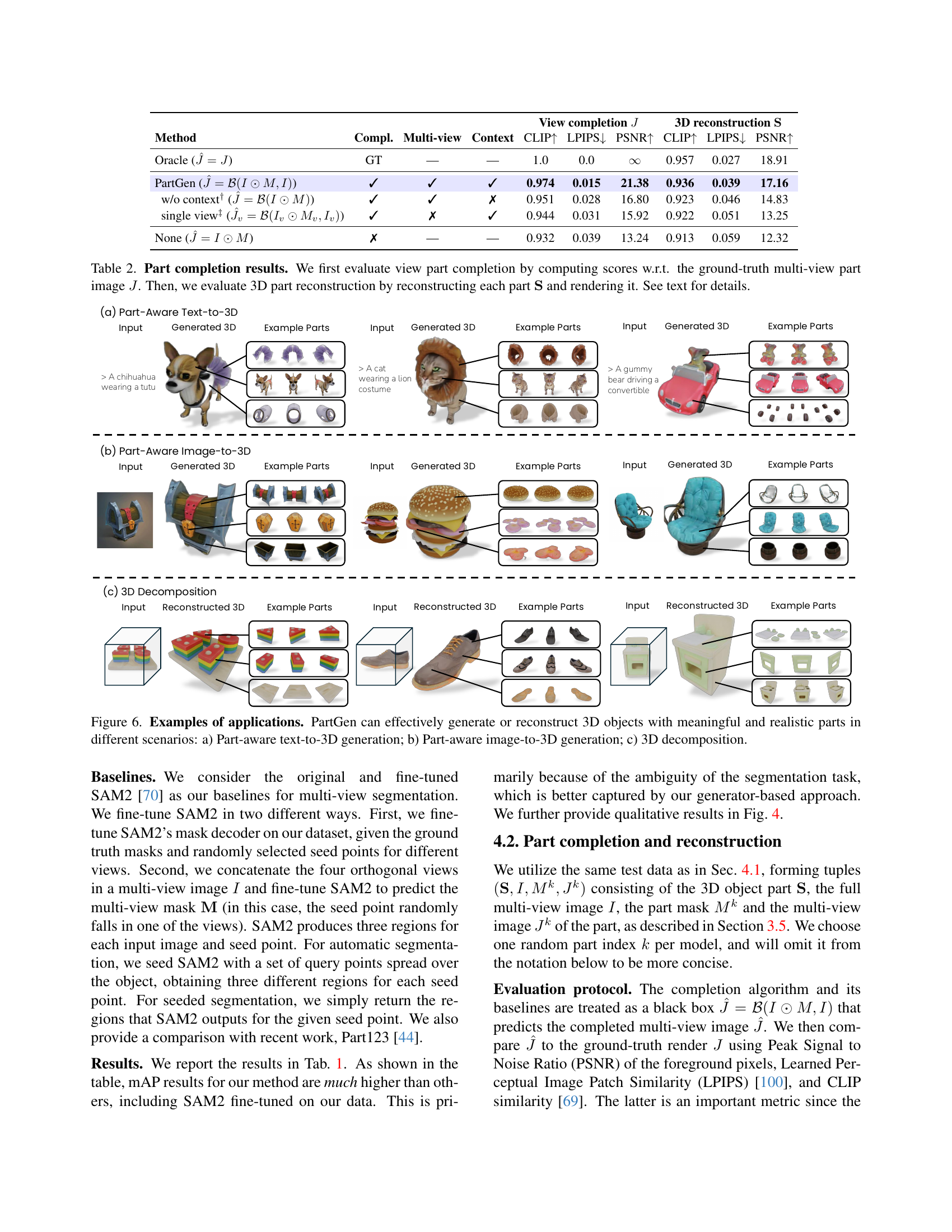
🔼 Table 2 presents a comprehensive evaluation of PartGen’s part completion and 3D reconstruction capabilities. The evaluation is two-fold: first, it assesses the quality of the generated multi-view part images (view completion) by comparing them against ground truth images using metrics like CLIP, LPIPS, and PSNR. Second, it evaluates the accuracy of the 3D reconstruction of each part by reconstructing the 3D model from the completed views and rendering it; then, using the same metrics as above, it compares the rendered images with ground-truth images.
read the caption
Table 2: Part completion results. We first evaluate view part completion by computing scores w.r.t. the ground-truth multi-view part image J𝐽Jitalic_J. Then, we evaluate 3D part reconstruction by reconstructing each part 𝐒𝐒\mathbf{S}bold_S and rendering it. See text for details.
| Method | CLIP ↑ | LPIPS ↓ | PSNR ↑ |
|---|---|---|---|
| PartGen (\hat{\mathbf{L}}=\bigcup_{k}\Phi(\hat{J}_{k})) | 0.952 | 0.065 | 20.33 |
| Unstructured (\hat{\mathbf{L}}=\Phi(I)) | 0.955 | 0.064 | 20.47 |
🔼 This table presents a comparison of the 3D reconstruction quality achieved by directly reconstructing an object as a whole versus reconstructing it from its constituent parts. The results show that the quality of the part-based reconstruction is very similar to the quality of the direct reconstruction, indicating that the model effectively predicts parts that fit together seamlessly to form a complete object.
read the caption
Table 3: Model reassembling result. The quality of 3D reconstruction of the object as a whole is close to that of the part-based compositional reconstruction, which proves that the predicted parts fit together well.
Full paper#