↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) struggle with detailed visual understanding, often compromising overall performance when focusing on specific tasks. Existing methods either develop tool-using approaches or unify visual tasks, but these often negatively impact the model’s broader capabilities.
To overcome this, the paper introduces Task Preference Optimization (TPO), a novel method that leverages differentiable task preferences from fine-grained visual tasks. TPO uses learnable task tokens to connect multiple task-specific heads to the MLLM, significantly improving performance on various visual tasks through multi-task co-training. The experimental results show that TPO achieves a substantial performance boost in MLLMs. This demonstrates TPO’s ability to enhance MLLMs with visual tasks in a scalable fashion, performing comparably to state-of-the-art supervised models.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of current multimodal large language models (MLLMs) in understanding fine-grained visual details. By proposing Task Preference Optimization (TPO), the research offers a novel method to enhance MLLMs’ performance on various visual tasks, thus impacting various applications and pushing the boundaries of multimodal AI. The scalability of TPO across different MLLMs and datasets is also a significant contribution, opening avenues for future research in this rapidly evolving field.
Visual Insights#

🔼 The figure illustrates the Task Preference Optimization (TPO) method. TPO enhances the fine-grained visual understanding capabilities of Multimodal Large Language Models (MLLMs) by incorporating differentiable task preferences. These preferences are derived from dense visual supervision via task-specific heads, which establish connections between multiple task-specific heads and the MLLM. The visual example shows how the model tracks the movement of a cup with a candy underneath, demonstrating the ability to handle fine-grained visual details.
read the caption
Figure 1: TPO uses differentiable task preferences from dense visual supervisions via task-specific heads to enhance MLLMs in fine-grained understanding.
| Task | Samples | Datasets |
|---|---|---|
| Segmentation | 114.6K | MeViS [18], SAMv2 [69] |
| Temporal Grounding | 116.5K | ActivityNet [7], TACoS [70], QVHighlight [39], DiDeMo [27], QuerYD [63], HiREST [107], NLQ [25] |
| Spatial Grounding | 540.0K | Allseeing-V2 [85], Visual Genome [37], RefCOCO [103], RefCOCO+ [103], RefCOCOg [59] |
| Conversation | 3M | YouCook2 [17], ActivityNet [7], VideoChat2-IT [48], ShareGPT-4o [14], LLaVA-Hound-DPO [113], ShareGPT4V [10] |
🔼 This table provides an overview of the datasets used to train the various task heads within the Task Preference Optimization (TPO) framework. It details the specific datasets and the number of samples used for each of the three main visual tasks addressed by TPO: Segmentation, Temporal Grounding, and Spatial Grounding. This information is crucial in understanding the scope and scale of the model’s training data and how this data is used to improve the model’s performance on various vision tasks.
read the caption
Table 1: Overview of Datasets Used in TPO for Various Tasks.
In-depth insights#
Visual Task Alignment#
Visual task alignment in multimodal large language models (MLLMs) is crucial for bridging the gap between general visual understanding and precise, fine-grained perception. Current MLLMs often struggle with tasks requiring detailed visual analysis, such as object tracking, temporal grounding, or referring expression segmentation. The core idea behind visual task alignment is to explicitly incorporate these specific visual tasks into the MLLM’s architecture and training process. This might involve designing specialized task heads or modules that process visual inputs in a task-specific manner. Effective alignment ensures that the MLLM can leverage rich visual cues to generate more accurate and informative responses. The challenge lies in balancing task-specific performance with overall multimodal capabilities. Overly focusing on individual tasks may detrimentally affect the MLLM’s performance on other tasks, necessitating careful optimization strategies. Furthermore, achieving effective alignment requires high-quality, task-specific training data, and may demand innovative training methodologies that can balance both task-specific and general multimodal training.
TPO Optimization#
Task Preference Optimization (TPO) is a novel method designed to enhance multimodal large language models (MLLMs) by aligning them with the nuances of fine-grained visual tasks. TPO leverages differentiable task preferences derived from dense visual supervision via task-specific heads, effectively bridging the gap between MLLM’s general understanding and the precise requirements of specific visual tasks. The method introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM, enabling the model to dynamically activate appropriate heads based on user instructions. The co-training strategy employed within TPO leads to synergistic gains, surpassing single-task training approaches and achieving overall robust performance. This demonstrates TPO’s potential for improving MLLM capabilities in various visual tasks and underscores its scalability across different MLLM architectures and datasets.
Multimodal Gains#
The concept of “Multimodal Gains” in a research paper would explore the synergistic improvements achieved when combining multiple modalities (like text and images) in a model. Significant gains are expected beyond the simple sum of individual modality performances. This section would likely present empirical evidence demonstrating that a multimodal model outperforms unimodal counterparts on various tasks. The analysis might delve into the types of tasks where multimodal learning excels, such as those requiring complex reasoning or contextual understanding. It could also investigate the factors influencing these gains, including the quality of multimodal data, model architecture, and training strategies. A key aspect might be the exploration of how different modalities interact and complement each other, offering unique insights not achievable through individual modalities alone. Finally, this section would probably discuss limitations and suggest avenues for future research focusing on further enhancing multimodal capabilities and addressing any identified shortcomings.
Scalability of TPO#
The scalability of Task Preference Optimization (TPO) is a crucial aspect determining its practical applicability. TPO’s modular design, incorporating task-specific heads and tokens, inherently promotes scalability. Adding new tasks simply involves integrating additional heads and tokens, trained jointly with the existing components, without requiring retraining the entire model. This incremental training approach significantly reduces computational cost compared to retraining from scratch. The method shows evidence of scaling across different MLLMs, implying that the core TPO principles are transferable and adaptable to various architectural designs. Data scalability is another key factor, demonstrated by the improvements observed when increasing the quantity of visual task data. The more task-specific data available, the more effectively the task heads can learn, leading to improved performance. However, future research should focus on evaluating the potential limitations to scalability at extremely large scales and with a vast number of tasks, exploring methods to manage potential computational and memory demands.
Future Directions#
Future research should explore improving the scalability of TPO by addressing limitations in task diversity and data requirements. Investigating the use of unsupervised or self-supervised learning methods alongside human annotations could significantly broaden the applicability and efficiency of TPO. Another crucial area is exploring how TPO interacts with different MLLM architectures and scales. The effects of various LLMs and their sizes on TPO’s performance should be thoroughly analyzed. Finally, examining TPO’s generalization capabilities across diverse unseen tasks and datasets is vital to establish its robustness and adaptability. This could involve testing TPO on a wider range of visual tasks and evaluating its effectiveness in real-world scenarios.
More visual insights#
More on figures

🔼 This figure compares three different learning methods: Preference Optimization (PO), Direct Preference Optimization (DPO), and Task Preference Optimization (TPO). PO uses a reward model to maximize the likelihood of the model’s output given the reward. DPO uses a reference model’s output as a preference signal to guide the main model’s training. TPO uses visual task annotations as preferences, enabling it to incorporate this information through task-specific heads and tokens. The diagram illustrates the data flow in each method, indicating which components are frozen or unfrozen during training. The use of solid and dotted lines visualizes data flow and feedback, respectively. This highlights how TPO incorporates visual task knowledge into the MLLM through jointly maximizing the likelihood of visual task estimations and multimodal dialogue. In essence, the figure shows the evolution of model training techniques from purely likelihood-based methods to methods incorporating user preferences or visual task-specific information, culminating in TPO.
read the caption
Figure 2: Comparison of Learning Method. A solid line indicates data flow, and a dotted line represents feedback. and denote modules that are frozen and unfrozen.
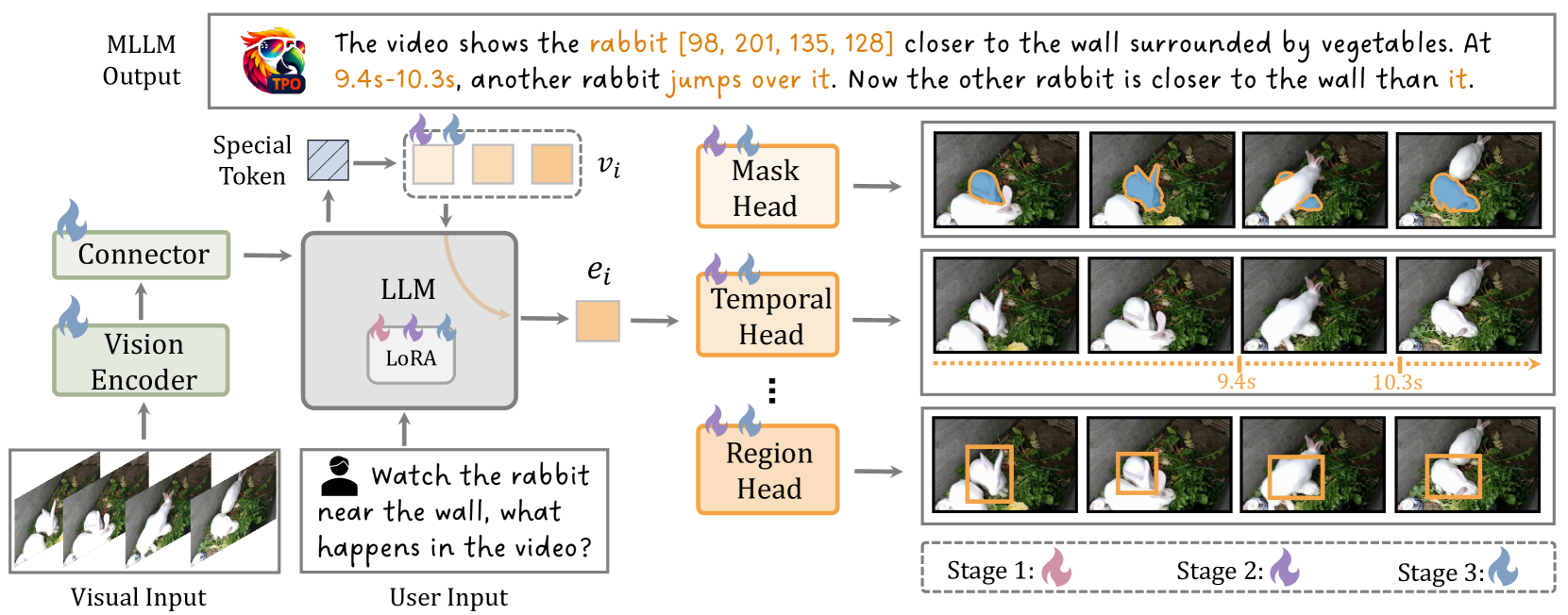
🔼 This figure illustrates the overall architecture of the Task Preference Optimization (TPO) method and its training process. TPO enhances multimodal large language models (MLLMs) by incorporating visual task knowledge. The architecture comprises four key parts: a vision encoder which processes visual input; a connector that integrates visual and textual information; a large language model (LLM) that generates responses; and a series of visual task heads which perform specific visual tasks (like object detection, tracking, etc.). The different colors of the flame symbols indicate which components of the model are updated during each of the three training stages. In essence, the diagram visually depicts how TPO fine-tunes these individual parts jointly to improve MLLM’s multimodal performance and visual task-specific accuracy.
read the caption
Figure 3: Overall Pipeline of TPO. The architecture of Task Preference Optimization (TPO) consists of four main components: (1) a vision encoder, (2) a connector, (3) a large language model, and (4) a series of visual task heads. Differently colored flame symbols indicate which components are unfrozen at various stages of the training process.

🔼 This table presents the results of the Grounded Question Answering (Grounded QA) task. The table compares the performance of several models, including VideoChat-TPO (the proposed method), on several metrics relevant to the task. These metrics likely include accuracy (Acc), intersection over prediction (IoP), and Intersection over Union (IoU) at various thresholds, which measure the model’s ability to both correctly answer questions and accurately locate the relevant visual information within the video.
read the caption
Table 3: Performance on Grounded QA.

🔼 This table presents a quantitative comparison of the model’s performance on several image understanding benchmarks. It compares VideoChat-TPO against other state-of-the-art models on metrics such as accuracy and intersection over union (IoU). The benchmarks likely assess the model’s ability to understand and reason about images, possibly including tasks like image classification, object detection, or visual question answering. The results showcase the improvement achieved by the proposed method, highlighting its effectiveness in improving image understanding capabilities.
read the caption
Table 4: Performance on Image Understanding.

🔼 Table 5 presents the zero-shot performance of moment retrieval models. Zero-shot refers to evaluating the model’s ability to perform the task without any fine-tuning or specific training on the moment retrieval dataset. The table compares the performance of VideoChat-TPO against various other models, some of which use LLMs (large language models) and some which don’t. The models are evaluated using metrics such as recall at various Intersection over Union (IoU) thresholds (e.g., R@0.3, R@0.5, R@0.7). The use of IoU indicates that the model’s success in identifying moments is assessed based on the degree of overlap between the predicted moment and the ground truth moment.
read the caption
Table 5: Zero-Shot Performance on Moment Retrieval.Gray means no LLM.

🔼 This table presents the results of fine-tuning various models on moment retrieval and highlight detection tasks. The performance is measured and compared across different models, including those with and without a large language model (LLM). The ‘Gray’ annotation indicates models that do not utilize an LLM. The table likely shows metrics such as recall (R@k) at different thresholds (e.g., R@0.3, R@0.5, R@0.7), mean Intersection over Union (mIoU), Mean Average Precision (MAP), and HIT@1. This allows for a comprehensive comparison of performance across different models and task types.
read the caption
Table 6: Fine-tuning Performance on Moment Retrieval and Highlight Detection. Gray means no LLM.
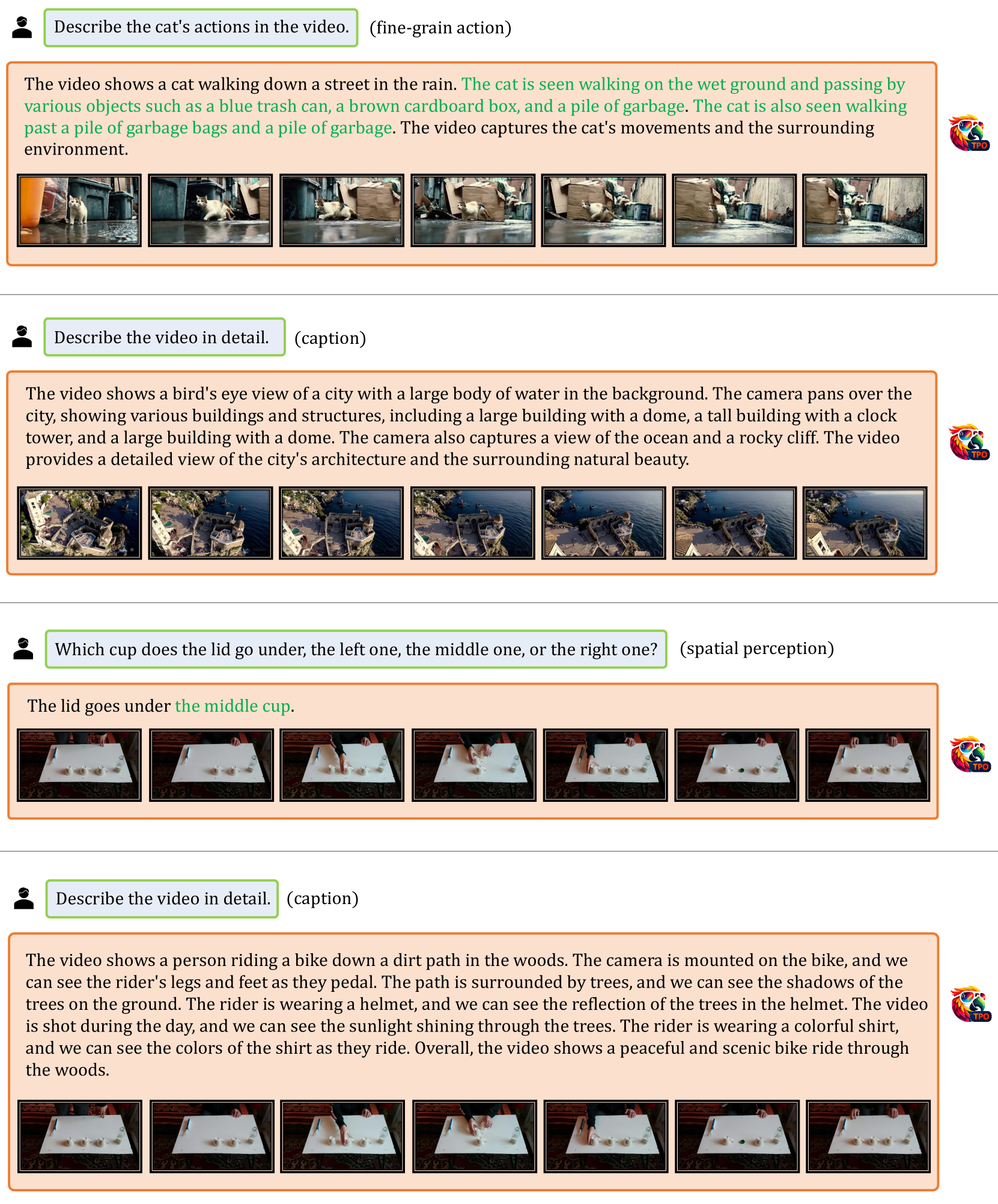
🔼 Table 7 displays the results of the spatial grounding task. Spatial grounding involves localizing objects within an image based on textual descriptions. The table compares the performance of the VideoChat-TPO model against several other methods, including pixel-to-sequence models (VisionLLM-H), pixel-to-embedding approaches (NExT-Chat), and a state-of-the-art expert model (G-DINO). The VideoChat-TPO model, despite employing a simpler task head, achieves comparable or superior performance to the more complex methods, indicating its effectiveness in handling spatial grounding.
read the caption
Table 7: Spatial Grounding Task. ★★\bigstar★ with a refined decoder.
More on tables
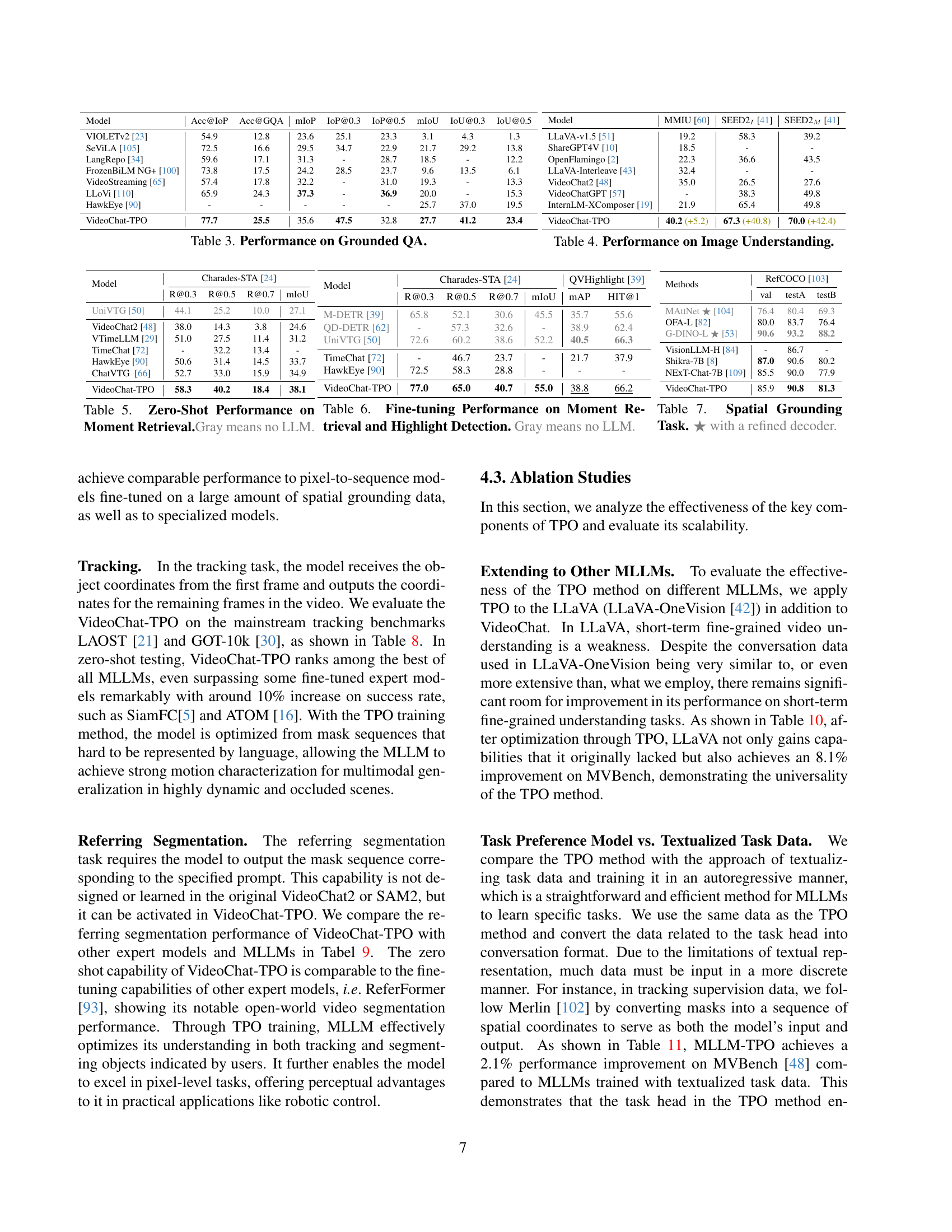
| Model | LLM | Params | Frames | MVBench [48] | VideoMME [22] Overall | VideoMME [22] Short | VideoMME [22] Medium | VideoMME [22] Long | MLVU [117] | M-AVG | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TimeChat [72] | 7B | 96 | 38.5 | 34.3 | 36.9 | 39.1 | 43.1 | 31.8 | 33.9 | 32.1 | 33.6 |
| Video-LLAVA [49] | 7B | 8 | 43.0 | 41.1 | 41.9 | 46.9 | 47.3 | 38.7 | 40.4 | 37.8 | 37.9 |
| ShareGPT4Video [11] | 7B | 16 | 51.2 | 39.9 | 43.6 | 48.3 | 53.6 | 36.3 | 39.3 | 35.0 | 37.9 |
| LLaVA-Next-Video [115] | 7B | 16 | 44.0 | 38.0 | 40.8 | 44.6 | 47.4 | 37.7 | 39.4 | 31.9 | 35.6 |
| ST-LLM [52] | 7B | 64 | 54.9 | 37.9 | 42.3 | 45.7 | 48.4 | 36.8 | 41.4 | 31.3 | 36.9 |
| PLLaVA-34B [97] | 34B | 16 | 58.1 | 40.0 | 35.0 | 47.2 | 36.2 | 38.2 | 35.9 | 34.7 | 32.9 |
| Chat-UniVi [33] | 7B | 64 | 40.8 | 40.6 | 45.9 | 45.7 | 51.2 | 41.3 | 47.3 | 39.1 | 43.4 |
| VideoChat2 (baseline) [48] | 7B | 16 | 60.4 | 39.5 | 43.8 | 48.3 | 52.8 | 37.0 | 39.4 | 33.2 | 39.2 |
| VideoChat-TPO | 7B | 16 | 66.8 (+6.4) | 48.8 (+9.3) | 53.8 (+10.0) | 58.8 | 64.9 | 46.7 | 50.0 | 41.0 | 46.4 |
🔼 This table presents a comparison of the performance of various models on multimodal video understanding benchmarks. The benchmarks include MVBench (Overall, w/o subtitle, w/ subtitle), VideoMME (Short, Medium, Long, AVG, w/o subtitle, w/ subtitle), and MLVU (M-AVG). Models are compared based on their performance using LLMs of the same generation or with 16 input frames. The ‘w/o s.’ and ‘w/ s.’ columns indicate results without and with subtitles, respectively. The M-AVG column shows the mean average score across the MLVU benchmark.
read the caption
Table 2: Performance on Multimodal Video Understanding. We compare our model to others using LLMs of the same generation or 16-frame input. w/o s. indicates without subtitle, while w s. indicates with subtitle. M-AVG refers to the mean average of MLVU.
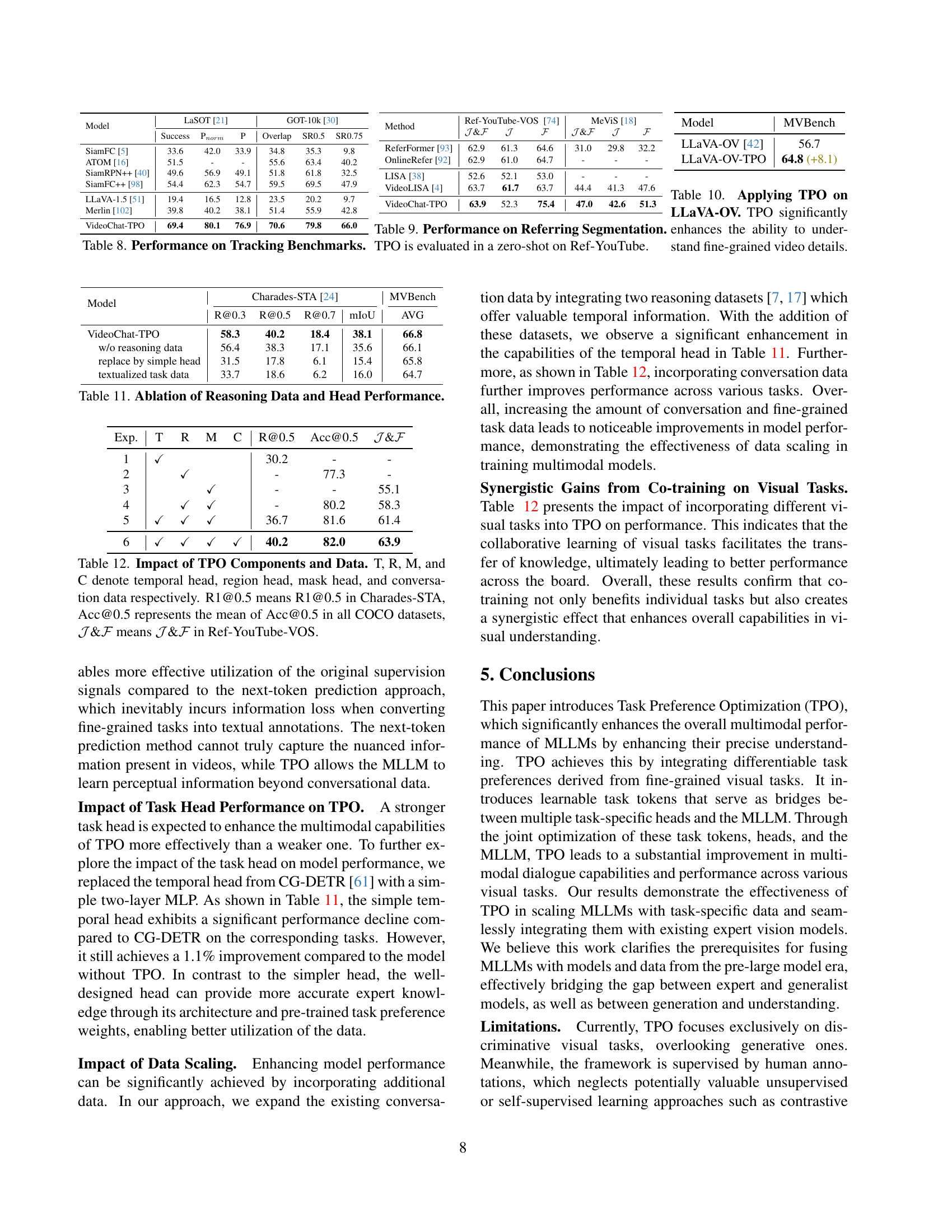
| Model | Acc@IoP | Acc@GQA | mIoP | IoP@0.3 | IoP@0.5 | mIoU | IoU@0.3 | IoU@0.5 |
|---|---|---|---|---|---|---|---|---|
| VIOLETv2 [23] | 54.9 | 12.8 | 23.6 | 25.1 | 23.3 | 3.1 | 4.3 | 1.3 |
| SeViLA [105] | 72.5 | 16.6 | 29.5 | 34.7 | 22.9 | 21.7 | 29.2 | 13.8 |
| LangRepo [34] | 59.6 | 17.1 | 31.3 | - | 28.7 | 18.5 | - | 12.2 |
| FrozenBiLM NG+ [100] | 73.8 | 17.5 | 24.2 | 28.5 | 23.7 | 9.6 | 13.5 | 6.1 |
| VideoStreaming [65] | 57.4 | 17.8 | 32.2 | - | 31.0 | 19.3 | - | 13.3 |
| LLoVi [110] | 65.9 | 24.3 | 37.3 | - | 36.9 | 20.0 | - | 15.3 |
| HawkEye [90] | - | - | - | - | - | 25.7 | 37.0 | 19.5 |
| VideoChat-TPO | 77.7 | 25.5 | 35.6 | 47.5 | 32.8 | 27.7 | 41.2 | 23.4 |
🔼 This table presents an ablation study analyzing the impact of different components and data on the performance of the Task Preference Optimization (TPO) model. Specifically, it investigates the contribution of various visual task heads (temporal, region, mask) and the inclusion of reasoning data on key metrics. The results show the effectiveness of the combined model components and data in achieving high performance.
read the caption
Table 11: Ablation of Reasoning Data and Head Performance.
| Model | MM IU [60] | SEED2I [41] | SEED2M [41] |
|---|---|---|---|
| LLaVA-v1.5 [51] | 19.2 | 58.3 | 39.2 |
| ShareGPT4V [10] | 18.5 | - | - |
| OpenFlamingo [2] | 22.3 | 36.6 | 43.5 |
| LLaVA-Interleave [43] | 32.4 | - | - |
| VideoChat2 [48] | 35.0 | 26.5 | 27.6 |
| VideoChatGPT [57] | - | 38.3 | 49.8 |
| InternLM-XComposer [19] | 21.9 | 65.4 | 49.8 |
| VideoChat-TPO | 40.2 (+5.2) | 67.3 (+40.8) | 70.0 (+42.4) |
🔼 This table presents an ablation study analyzing the impact of different components and data on the performance of the Task Preference Optimization (TPO) method. It shows the results of various model configurations, systematically removing or adding components such as the temporal head (T), region head (R), and mask head (M), as well as including or excluding conversation data (C). The performance is measured using three metrics derived from different datasets: R1@0.5 from Charades-STA (a moment retrieval dataset); Acc@0.5 (average accuracy at IoU threshold of 0.5) across COCO datasets (evaluating region-based tasks); and J&F (Jaccard & F1-score) from Ref-YouTube-VOS (a referring video object segmentation dataset). Each row represents a specific model configuration, indicating which components were included during training. This table helps to understand the contribution of each component and the dataset to the overall model performance.
read the caption
Table 12: Impact of TPO Components and Data. T, R, M, and C denote temporal head, region head, mask head, and conversation data respectively. R1@0.5 means R1@0.5 in Charades-STA, Acc@0.5 represents the mean of Acc@0.5 in all COCO datasets, 𝒥𝒥\mathcal{J}caligraphic_J&ℱℱ\mathcal{F}caligraphic_F means 𝒥𝒥\mathcal{J}caligraphic_J&ℱℱ\mathcal{F}caligraphic_F in Ref-YouTube-VOS.
| Model | Charades-STA [24] | ||||
|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | ||
| — | — | — | — | — | — |
| UniVTG [50] | 44.1 | 25.2 | 10.0 | 27.1 | |
| VideoChat2 [48] | 38.0 | 14.3 | 3.8 | 24.6 | |
| VTimeLLM [29] | 51.0 | 27.5 | 11.4 | 31.2 | |
| TimeChat [72] | - | 32.2 | 13.4 | - | |
| HawkEye [90] | 50.6 | 31.4 | 14.5 | 33.7 | |
| ChatVTG [66] | 52.7 | 33.0 | 15.9 | 34.9 | |
| VideoChat-TPO | 58.3 | 40.2 | 18.4 | 38.1 |
🔼 This table presents the performance of various models on the MVBench benchmark, a challenging dataset designed for evaluating multimodal video understanding capabilities. It showcases the accuracy scores of different models across multiple fine-grained video tasks. The results highlight the strengths and weaknesses of various approaches in terms of temporal perception and reasoning abilities. These scores provide a comprehensive evaluation of the models’ capacity to understand and reason about complex video scenarios.
read the caption
Table 13: Results on MVBench Multi-choice Question Answering.
| Model | Charades-STA [24] | QVHighlight [39] | |||||
|---|---|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | mAP | HIT@1 | ||
| — | — | — | — | — | — | — | — |
| M-DETR [39] | 65.8 | 52.1 | 30.6 | 45.5 | 35.7 | 55.6 | |
| QD-DETR [62] | - | 57.3 | 32.6 | - | 38.9 | 62.4 | |
| UniVTG [50] | 72.6 | 60.2 | 38.6 | 52.2 | 40.5 | 66.3 | |
| TimeChat [72] | - | 46.7 | 23.7 | - | 21.7 | 37.9 | |
| HawkEye [90] | 72.5 | 58.3 | 28.8 | - | - | - | |
| VideoChat-TPO | 77.0 | 65.0 | 40.7 | 55.0 | 38.8 | 66.2 |
🔼 Table 14 presents a quantitative analysis of the Multimodal Multi-Image Understanding (MMIU) benchmark [60]. It evaluates the performance of various models across multiple image understanding tasks. The ‘Overall’ score represents the average performance across all tasks, while other columns likely detail performance on specific sub-tasks within the MMIU benchmark. Accuracy serves as the primary evaluation metric for the table.
read the caption
Table 14: Quantitative results of MMIU [60]. Accuracy is the metric, and the Overall score is computed across all tasks.
| Methods | RefCOCO [103] | |||
|---|---|---|---|---|
| val | testA | testB | ||
| MAttNet ★ [104] | 76.4 | 80.4 | 69.3 | |
| OFA-L [82] | 80.0 | 83.7 | 76.4 | |
| G-DINO-L ★ [53] | 90.6 | 93.2 | 88.2 | |
| VisionLLM-H [84] | - | 86.7 | - | |
| Shikra-7B [8] | 87.0 | 90.6 | 80.2 | |
| NExT-Chat-7B [109] | 85.5 | 90.0 | 77.9 | |
| VideoChat-TPO | 85.9 | 90.8 | 81.3 |
🔼 This table presents the ablation study on the impact of different vision tasks included in the training process of the Task Preference Optimization (TPO) method. It shows the performance of the model when trained with various combinations of tasks: temporal grounding, spatial grounding, and segmentation. The results demonstrate the effect of each task on the overall performance and the synergistic effect when multiple tasks are combined.
read the caption
Table 15: Ablation task datasets.
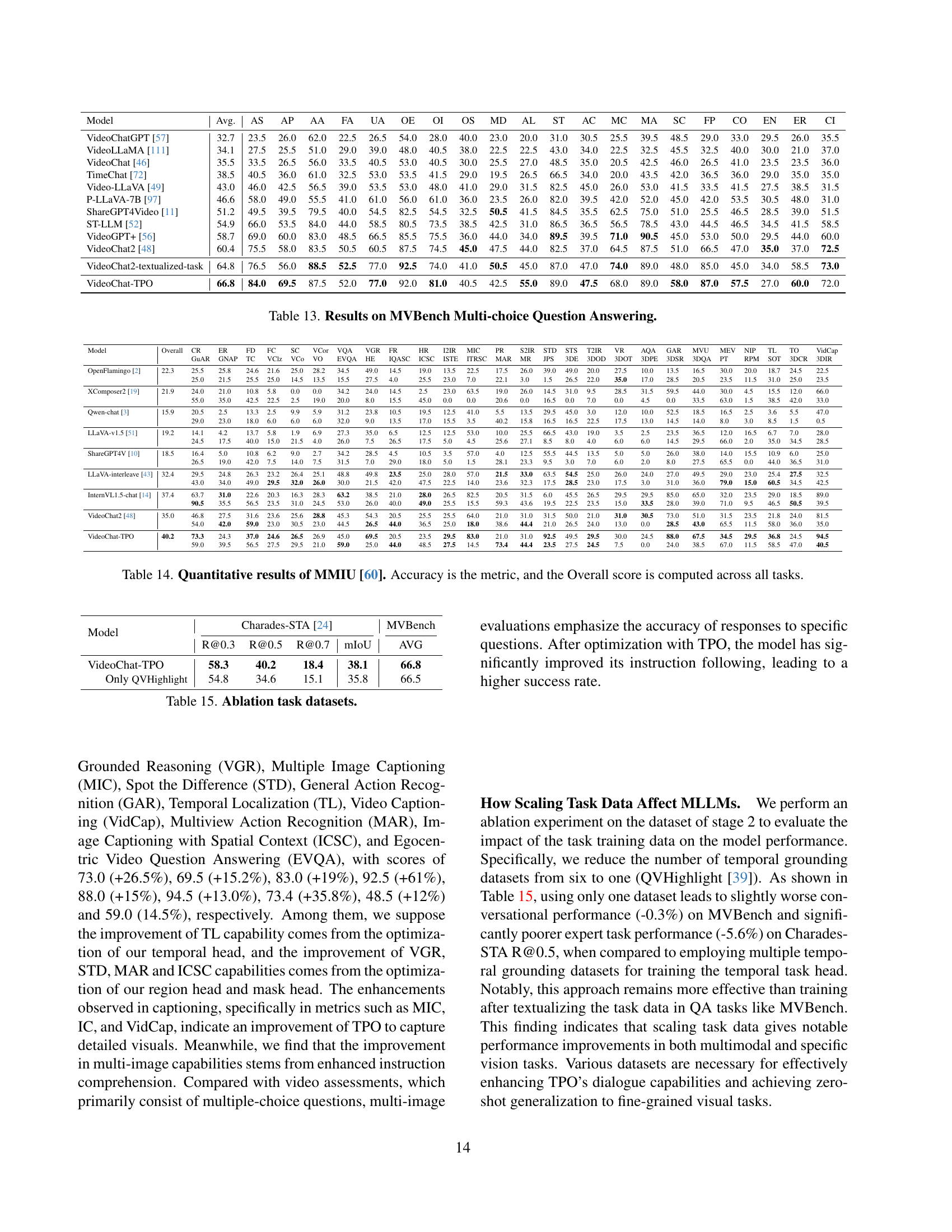
| Model | LaSOT [21] | GOT-10k [30] | ||||
|---|---|---|---|---|---|---|
| Success | Pnorm | P | Overlap | SR0.5 | SR0.75 | |
| — | — | — | — | — | — | — |
| SiamFC [5] | 33.6 | 42.0 | 33.9 | 34.8 | 35.3 | 9.8 |
| ATOM [16] | 51.5 | - | - | 55.6 | 63.4 | 40.2 |
| SiamRPN++ [40] | 49.6 | 56.9 | 49.1 | 51.8 | 61.8 | 32.5 |
| SiamFC++ [98] | 54.4 | 62.3 | 54.7 | 59.5 | 69.5 | 47.9 |
| LLaVA-1.5 [51] | 19.4 | 16.5 | 12.8 | 23.5 | 20.2 | 9.7 |
| Merlin [102] | 39.8 | 40.2 | 38.1 | 51.4 | 55.9 | 42.8 |
| VideoChat-TPO | 69.4 | 80.1 | 76.9 | 70.6 | 79.8 | 66.0 |
🔼 This table details the hyperparameters and training settings used in the Task Preference Optimization (TPO) method, specifically for the VideoChat2 model. It breaks down the configuration across different stages of the training process, outlining learning rates (LR) for various components like the vision encoder, connector, task heads (temporal, region, mask), task tokens, and the Large Language Model (LLM) fine-tuned with LoRA. The table also shows the optimizers used (AdamW), weight decay, input resolution, frame count, LoRA rank and alpha for the LLM, warmup ratio, batch size, epochs, and the numerical precision (DeepSpeed bf16). The different stages reflect the incremental introduction and training of these elements: Stage 1 focuses on task assignment and LoRA training of the LLM; Stage 2 fine-tunes task heads and tokens; and Stage 3 jointly trains all components, including multimodal conversation data.
read the caption
Table 16: Training Settings of VideoChat-TPO. Con. means conversation data and LR means learning rate.
| Method | Ref-YouTube-VOS [74] | MeViS [18] | ||||
|---|---|---|---|---|---|---|
| 𝒥 | ℱ | 𝒥 | ℱ | |||
| ReferFormer [93] | 62.9 | 61.3 | 64.6 | 31.0 | 29.8 | 32.2 |
| OnlineRefer [92] | 62.9 | 61.0 | 64.7 | - | - | - |
| LISA [38] | 52.6 | 52.1 | 53.0 | - | - | - |
| VideoLISA [4] | 63.7 | 61.7 | 63.7 | 44.4 | 41.3 | 47.6 |
| VideoChat-TPO | 63.9 | 52.3 | 75.4 | 47.0 | 42.6 | 51.3 |
🔼 This table details the datasets used for training the Task Preference Optimization (TPO) model. It’s broken down by training stage (1, 2, and 3), with each stage focusing on different aspects of model training. Stage 1 focuses on task assignment, using smaller datasets to teach the model to identify the task type. Stage 2 concentrates on training the visual task heads, utilizing significantly larger datasets for each task. Stage 3 involves multi-task training, combining large datasets for all tasks and incorporating a large multimodal conversation dataset to optimize overall performance and alignment between tasks. Note that temporal grounding is composed of moment retrieval and highlight detection subtasks.
read the caption
Table 17: Training Datasets. The temporal grounding includes two subtasks: moment retrieval and highlight detection.
Full paper#