↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current generative models for graphic design often focus on subtasks and lack consideration for the hierarchical structure inherent in design composition. This leads to suboptimal results and high costs for manual integration. This paper addresses these issues.
The proposed LaDeCo model leverages a layered design approach and large multimodal models to achieve design composition. By sequentially generating design layers based on semantic labels and incorporating previously generated layers into the context, LaDeCo overcomes the limitations of existing methods. The experimental results demonstrate LaDeCo’s effectiveness in generating high-quality designs, outperforming state-of-the-art baselines and showcasing promising applications like resolution adjustment and element filling.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing generative graphic design models by introducing a novel layered design approach. This approach is not only more efficient but also produces high-quality results, exceeding specialized models in certain subtasks. It opens new avenues for research in graphic design automation and multimodal model applications. The layered design principle is a significant contribution, offering a new perspective on tackling complex design problems.
Visual Insights#
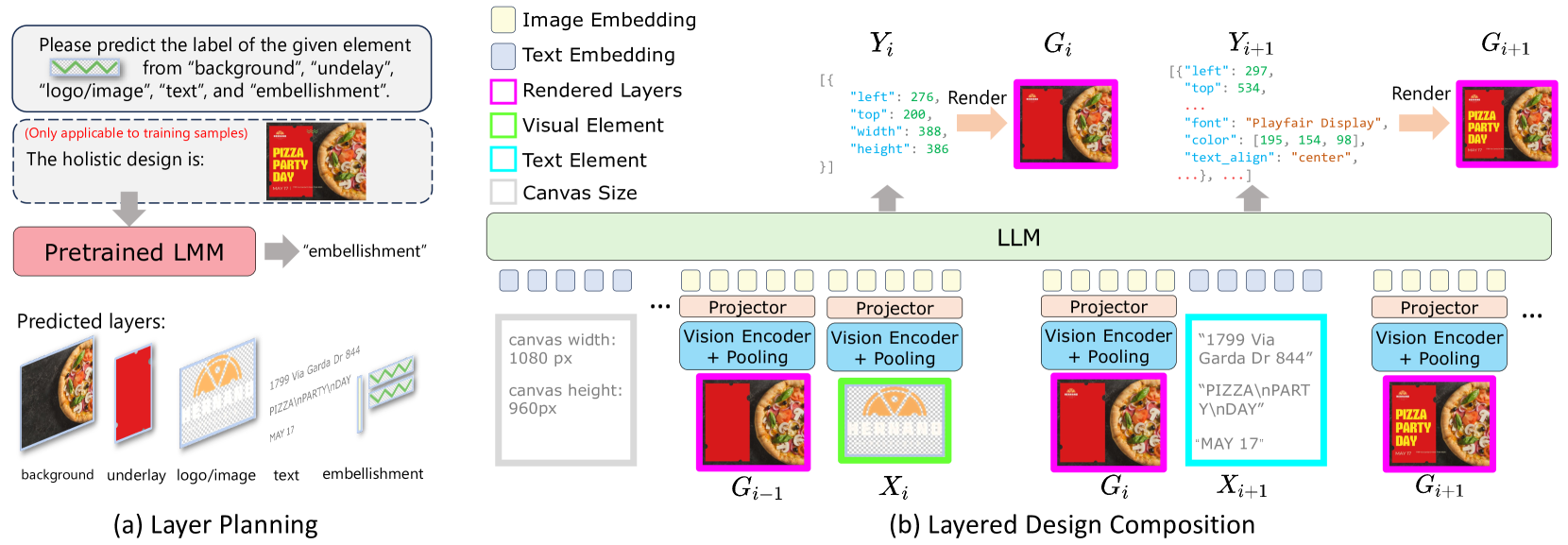
🔼 Figure 1 demonstrates the layered approach of the proposed method for automatic graphic design composition. (a) shows an example of the input: a set of multimodal elements (images, texts, logos, etc.). The algorithm then composes these elements into a balanced and aesthetically pleasing design. (b) illustrates the layered design principle adopted by the method, where the input elements are divided into different layers (background, underlay, logo/image, text, embellishment) according to their semantics. The composition task is performed layer by layer. (c) showcases examples of high-quality graphic designs generated using the proposed method.
read the caption
Figure 1: (a) Given a set of multimodal elements as input, our approach automatically composes them into a cohesive, balanced, and aesthetically pleasing graphic design. (b) Since a holistic design can be divided into different layers according to element semantics, we achieve the design composition task in a layer-by-layer manner. (c) Our approach is able to craft high-quality design pieces.
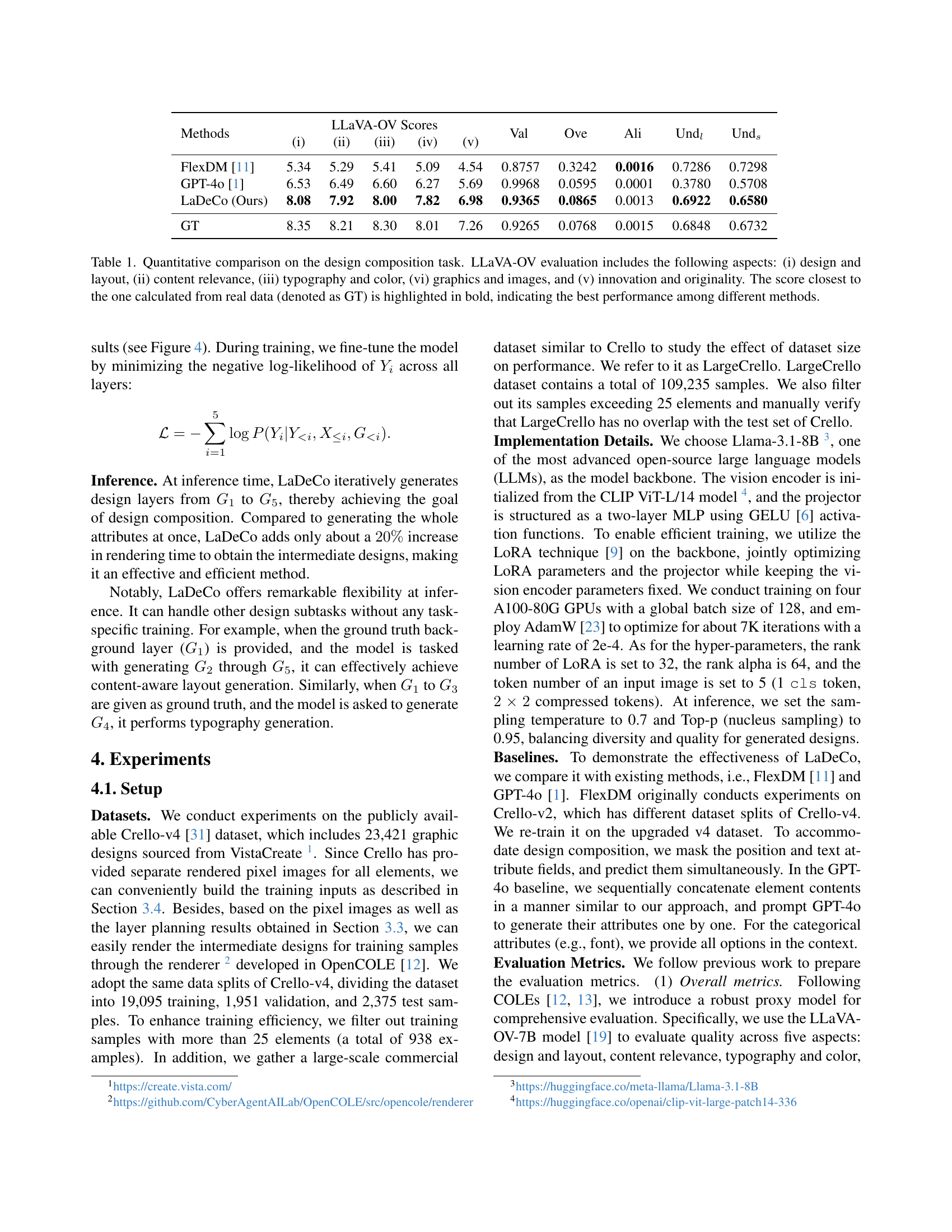
| Methods | (i) | (ii) | (iii) | (iv) | (v) | Val | Ove | Ali | Undl | Unds |
|---|---|---|---|---|---|---|---|---|---|---|
| FlexDM [11] | 5.34 | 5.29 | 5.41 | 5.09 | 4.54 | 0.8757 | 0.3242 | 0.0016 | 0.7286 | 0.7298 |
| GPT-4o [1] | 6.53 | 6.49 | 6.60 | 6.27 | 5.69 | 0.9968 | 0.0595 | 0.0001 | 0.3780 | 0.5708 |
| LaDeCo (Ours) | 8.08 | 7.92 | 8.00 | 7.82 | 6.98 | 0.9365 | 0.0865 | 0.0013 | 0.6922 | 0.6580 |
| GT | 8.35 | 8.21 | 8.30 | 8.01 | 7.26 | 0.9265 | 0.0768 | 0.0015 | 0.6848 | 0.6732 |
🔼 This table presents a quantitative comparison of different methods for automated graphic design composition, using the LLaVA-OV evaluation metric. LLaVA-OV assesses five key aspects of design quality: (i) design and layout, (ii) content relevance, (iii) typography and color, (iv) graphics and images, and (v) innovation and originality. The scores for each method are compared to a ground truth (GT) score derived from human-created designs. The method with the score closest to the GT score for each aspect is highlighted in bold, indicating superior performance in that specific area. Overall, the table allows for a comprehensive comparison of the different methods in terms of their ability to produce high-quality, creative graphic designs.
read the caption
Table 1: Quantitative comparison on the design composition task. LLaVA-OV evaluation includes the following aspects: (i) design and layout, (ii) content relevance, (iii) typography and color, (vi) graphics and images, and (v) innovation and originality. The score closest to the one calculated from real data (denoted as GT) is highlighted in bold, indicating the best performance among different methods.
In-depth insights#
Layered Design#
The concept of ‘Layered Design’ in the context of automated graphic design is a significant contribution. It mimics the human design process, breaking down a complex task into manageable sub-tasks. By tackling design layer by layer—from background to embellishments—it enables a more intuitive and coherent design generation. This layered approach greatly enhances the model’s ability to capture contextual information and make design decisions. Each layer’s output serves as input for the next, promoting a more natural and progressive generation, rather than a holistic, simultaneous approach. This hierarchical structure not only improves the overall quality of designs but also contributes to greater efficiency and flexibility, enabling the model to handle subtasks such as typography and layout generation more effectively. The successful implementation of this layered approach is a key finding of this research, demonstrating its effectiveness and potential for future applications in automated graphic design.
LMM Composition#
The concept of “LMM Composition” in the context of automated graphic design suggests a layered approach leveraging Large Multimodal Models (LMMs). This method is innovative because it breaks down the complex task of design composition into smaller, manageable steps. Instead of directly generating a complete design, the LMM iteratively constructs the design layer by layer, starting with the background and adding subsequent layers (underlay, logo/image, text, embellishments) sequentially. Each layer’s generation utilizes the rendered output of previous layers as context, facilitating a cohesive and coherent final product. This layered approach mirrors human design processes, promoting efficiency and clarity. The method’s strength lies in its ability to handle various design subtasks (e.g., typography generation, layout adjustment) without retraining, demonstrating adaptability and versatility. The use of LMMs enables the system to understand multimodal elements and their relationships, leading to more nuanced and aesthetically pleasing designs. However, future work should investigate the scalability of this method with significantly larger datasets and more complex design scenarios.
LaDeCo Approach#
The LaDeCo approach presents a novel solution to automatic graphic design composition by leveraging a layered design principle within large multimodal models. Instead of tackling the complex task holistically, LaDeCo intelligently decomposes it into smaller, manageable subtasks, focusing on one layer at a time. This layer-wise generation not only streamlines the process but also allows for better context utilization, as preceding layers inform the creation of subsequent ones. The approach incorporates a layer planning module to effectively categorize input elements into their respective semantic layers, ensuring a logical and organized design structure. By utilizing pre-trained language models for layer planning and multimodal models for attribute prediction, LaDeCo demonstrates significant improvements in design composition, surpassing existing methods in both quantitative and qualitative evaluations. Its flexibility extends to handling various design subtasks effectively, such as resolution adjustment and element filling, further highlighting its practicality and versatility.
Experimental Setup#
A robust experimental setup is crucial for validating the proposed LaDeCo model. The selection of the Crello-v4 dataset, while publicly available, presents some limitations. Filtering out samples with more than 25 elements impacts the generalizability of the findings, potentially skewing results towards simpler designs. The use of Llama-3.1-8B as the backbone model, along with the LoRA technique for efficient training, represents a reasonable choice given the need for a powerful yet resource-efficient approach. Comparing against state-of-the-art baselines like FlexDM and GPT-40 provides a valuable context for evaluating LaDeCo’s performance. However, the lack of a more comprehensive benchmark with greater diversity in design complexity and style might limit the scope of the evaluation. The ablation study, varying parameters such as LoRA rank and base model, helps assess the model’s robustness and sensitivity to these choices. The inclusion of a qualitative evaluation alongside quantitative metrics allows for a more holistic assessment, including visual inspection of generated designs and comparison to ground truth. Finally, the extension to a larger dataset (LargeCrello) offers a preliminary exploration of scalability, but more extensive analysis would be needed to fully establish LaDeCo’s capabilities with high-volume data.
Future of Design#
The future of design is inextricably linked to advancements in artificial intelligence and large multimodal models. AI-powered tools are poised to automate many tasks currently performed by human designers, leading to increased efficiency and potentially more creative outputs. Layered design principles, as explored in the paper, offer a structured approach to complex design composition, promising better collaboration between AI and human designers. However, the ethical considerations surrounding AI-generated content, including issues of authorship, bias, and job displacement, necessitate careful consideration and mitigation strategies. Moreover, the potential for AI to democratize design through accessibility and ease of use must be balanced with the need to maintain design quality and uphold human creativity. Ultimately, the most successful future of design will likely involve a symbiotic relationship between human ingenuity and AI augmentation, where AI handles repetitive tasks and supports the creative process, leaving the most complex and nuanced design decisions in the hands of human experts.
More visual insights#
More on figures

🔼 LaDeCo, a layered design composition method, is illustrated in this figure. It begins by using GPT-40 to assign semantic labels (background, underlay, logo/image, text, embellishment) to input elements, determining the layer structure. LaDeCo then uses Large Multimodal Models (LMMs) in a layer-by-layer process. Each layer’s attributes are predicted, and the rendered image of previous layers is incorporated into the LMM’s input for context during subsequent layer generation. This approach breaks down the complex design process into smaller, manageable steps.
read the caption
Figure 2: Illustration of our proposed LaDeCo. First, it utilizes GPT-4o [1] to annotate the semantic labels for input elements. The layer structure is obtained from the predictions. Then LaDeCo fine-tunes LMMs to achieve layered design composition. After generating each layer, the intermediate designs will be rendered as images and fed back into LMMs to guide subsequent layer generation.
🔼 This figure presents a qualitative comparison of graphic designs generated by three different methods: FlexDM, GPT-40, and the proposed LaDeCo approach. For each method, several example designs are shown side-by-side with their corresponding ground truth designs. The comparison highlights the differences in design composition, showcasing the visual quality, aesthetics, and overall effectiveness of each approach in creating visually appealing and balanced graphics. Zooming in is recommended for a detailed examination of the subtle differences in the designs.
read the caption
Figure 3: Qualitative comparison. We also show the ground truth designs for these samples. Please zoom in for a better view.

🔼 This figure shows the intermediate results generated by the LaDeCo model during the layered design composition process. Each subfigure represents a design stage after adding one of the five design layers (background, underlay, logo/image, text, and embellishment). This visualization helps to understand how LaDeCo progressively creates a holistic graphic design in a layer-wise manner.
read the caption
Figure 4: The rendered results of different layers from LaDeCo.

🔼 This figure demonstrates LaDeCo’s ability to adapt to different canvas sizes. The same set of design elements are used as input, but the output designs are adjusted to fit the different canvas dimensions (1080px and 1920px). This showcases LaDeCo’s flexibility and its capacity to generate visually appealing designs regardless of the output resolution.
read the caption
Figure 5: LaDeCo composes the same input elements to designs with different canvas sizes.

🔼 This figure shows how LaDeCo enhances an existing design by adding new elements. The left column displays the original design, the middle column shows the newly added elements, and the right column presents the final, improved design incorporating the new elements. This demonstrates LaDeCo’s ability to integrate new components seamlessly into an existing design for improved visual appeal and coherence.
read the caption
Figure 6: LaDeCo adds new elements on a existing design to achieve a more appealing design.
🔼 Given the same set of input elements, LaDeCo demonstrates its ability to generate multiple distinct and creative graphic designs. This highlights the model’s flexibility and capacity to produce diverse outputs from a single input, showcasing its versatility in design generation.
read the caption
Figure 7: LaDeCo creates diverse designs with the same elements.

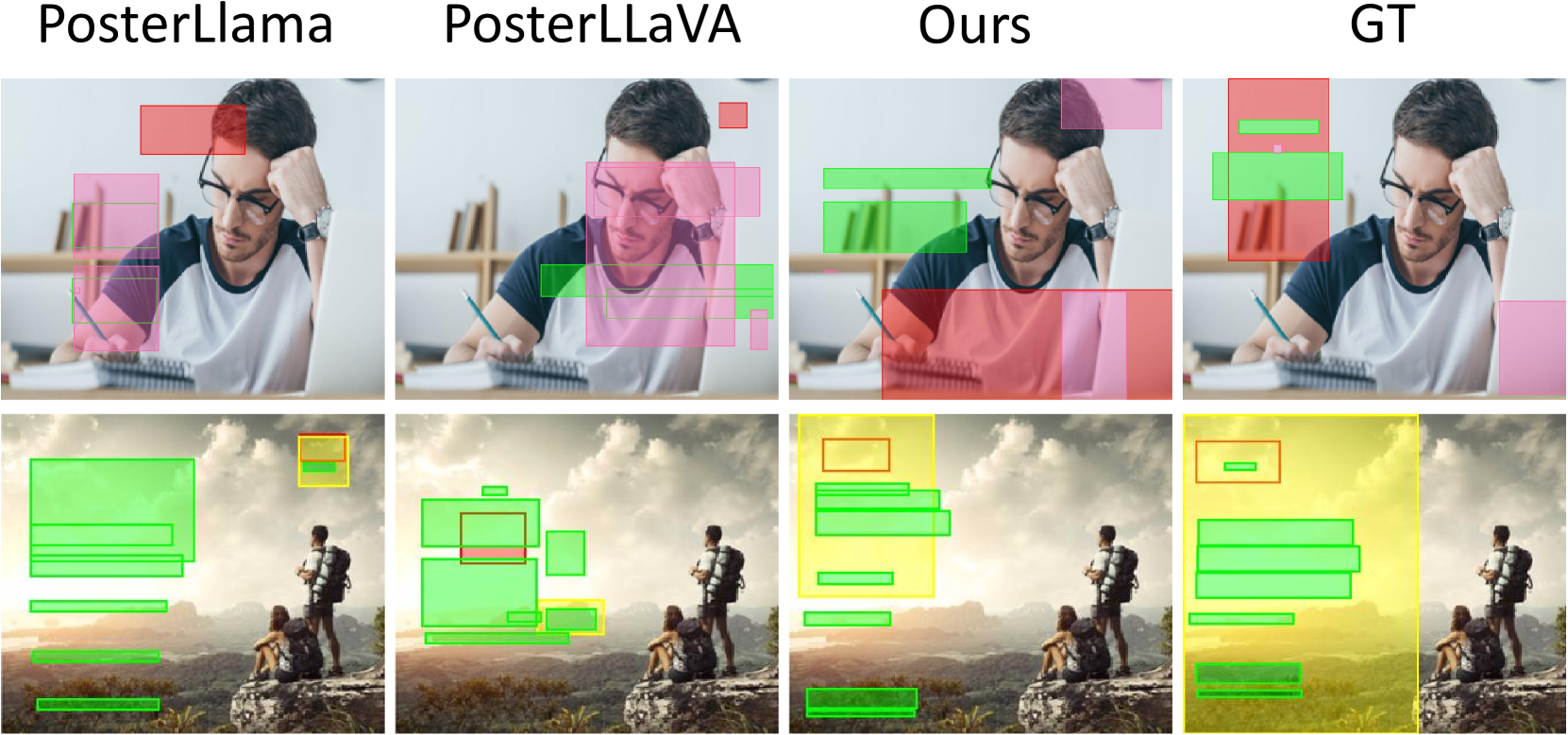
🔼 This figure compares the results of content-aware layout generation from different methods: PosterLlama, PosterLLaVA, LaDeCo, and ground truth (GT). Each design is broken down visually, with colored boxes indicating the different elements. Yellow boxes represent underlays; red boxes represent images; green boxes represent text; and pink boxes represent embellishments. The comparison showcases LaDeCo’s superior ability to generate layouts that effectively utilize the content and positioning of all elements.
read the caption
Figure 8: Qualitative comparison on the content-aware layout generation task. The yellow, red, green, pink boxes represent underlay, image, text, and embellishment elements, respectively.

🔼 This figure presents a qualitative comparison of typography generation results from different methods. It visually showcases the generated typography from FlexDM, OpenCOLE, the proposed LaDeCo approach, and the ground truth. The comparison allows for a visual assessment of the quality and aesthetics of the generated typography from each method.
read the caption
Figure 9: Qualitative comparison on typography generation.
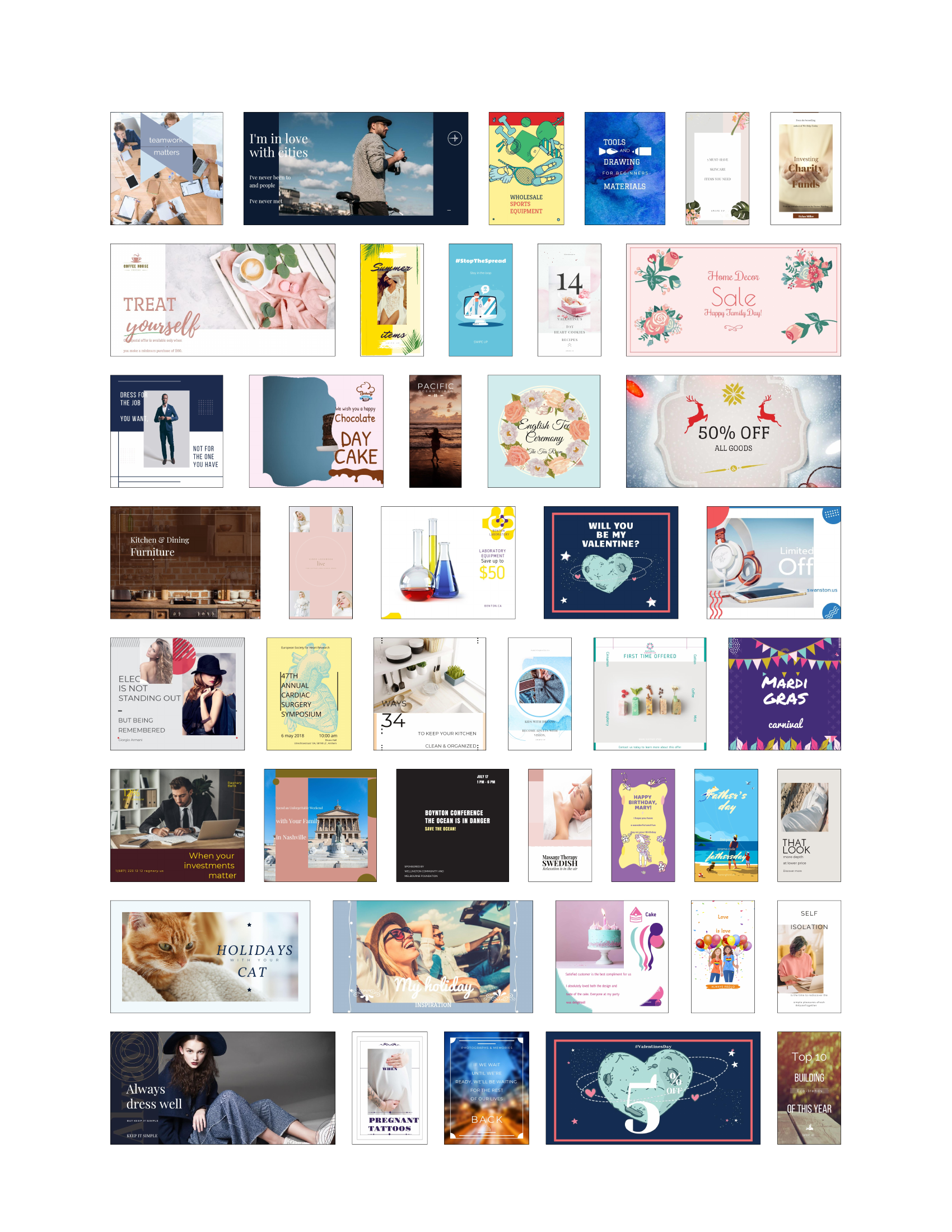
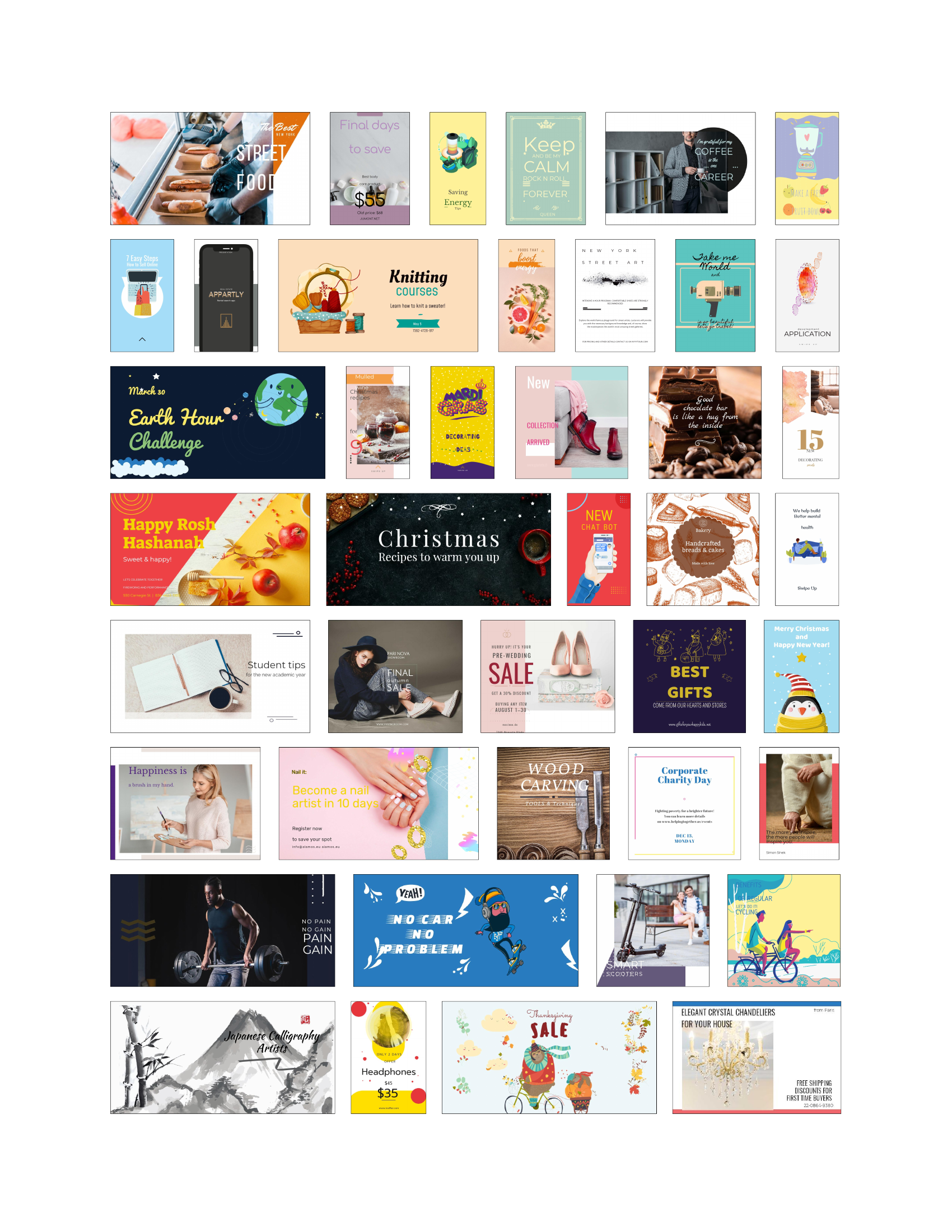
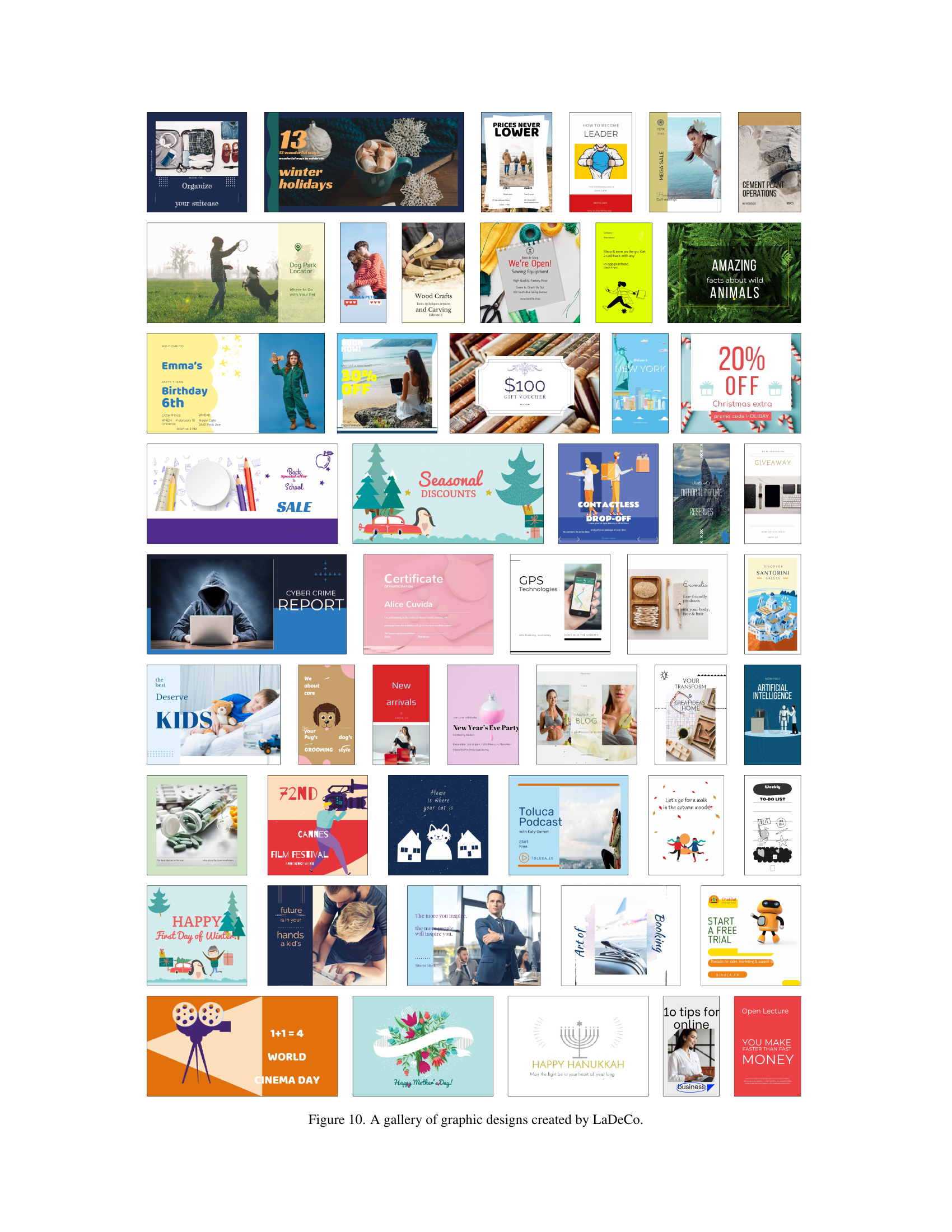
🔼 This figure showcases a diverse range of graphic designs automatically generated by the LaDeCo model. It highlights the model’s ability to create visually appealing and diverse designs by combining various multimodal elements. The designs cover a variety of styles and themes, demonstrating LaDeCo’s flexibility and capacity for high-quality output. The images represent a selection of the model’s capabilities, showcasing its ability to handle different design tasks and input types.
read the caption
Figure 10: A gallery of graphic designs created by LaDeCo.

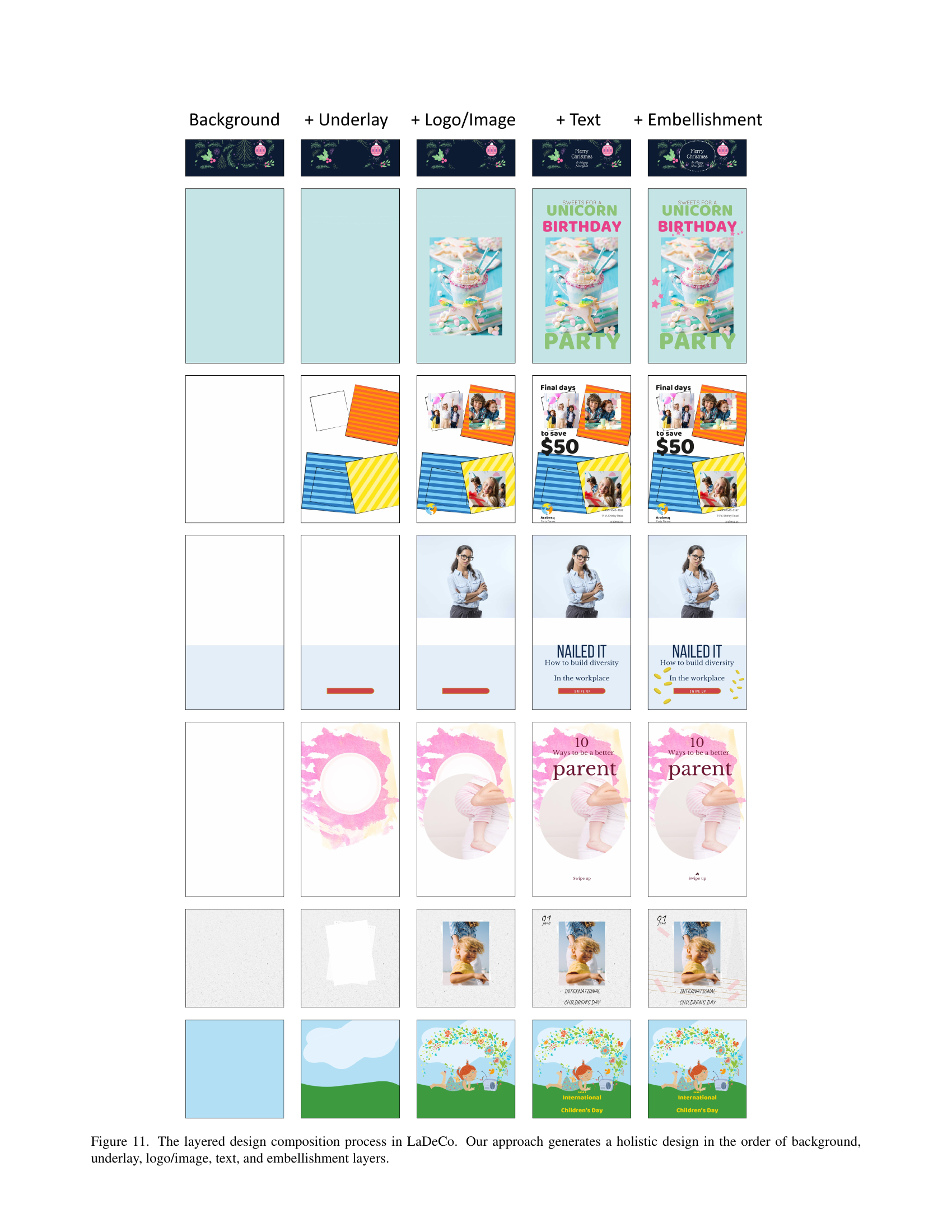
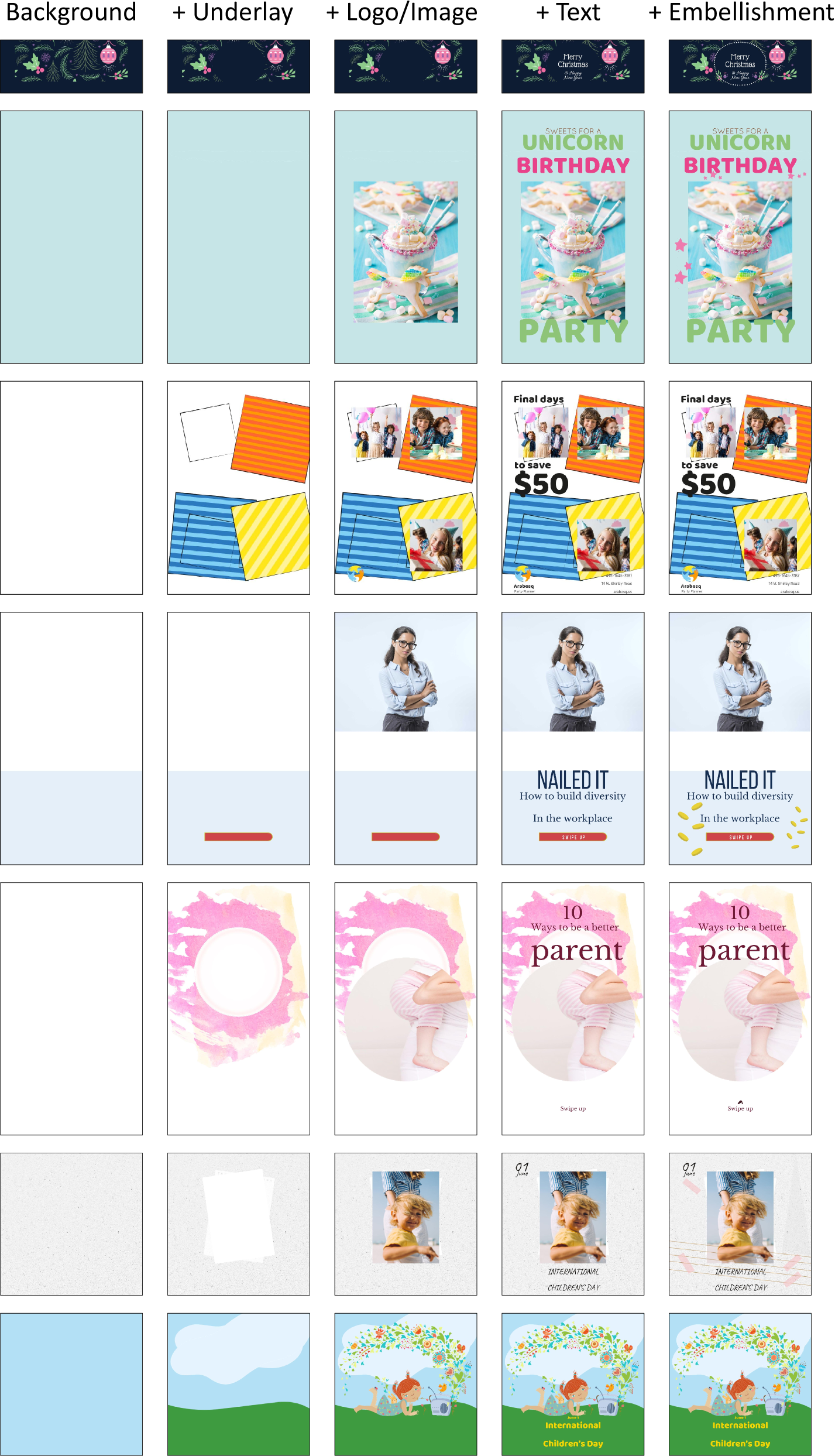
🔼 Figure 11 illustrates the layered design composition process employed by the LaDeCo model. The figure visually depicts how LaDeCo generates a complete graphic design by progressively building up layers. It starts with the background, then adds an underlay, followed by logo/image elements, text, and finally, embellishments. Each row in the figure represents a different design example, showing the sequential addition of layers to create a cohesive final design. This layered approach breaks down the complex design composition task into smaller, more manageable steps.
read the caption
Figure 11: The layered design composition process in LaDeCo. Our approach generates a holistic design in the order of background, underlay, logo/image, text, and embellishment layers.
🔼 This figure displays multiple graphic designs generated by the LaDeCo model using the same set of input elements. It showcases the model’s ability to produce a variety of aesthetically pleasing and cohesive designs by varying the arrangement and attributes of the elements. This demonstrates LaDeCo’s flexibility and creativity in design composition, highlighting its capacity to generate diverse outputs from a single set of inputs.
read the caption
Figure 12: More results to demonstrate that LaDeCo can create diverse designs with the same input.

🔼 This figure showcases LaDeCo’s ability to adapt to various aspect ratios while maintaining design quality. It presents several graphic designs generated by the model, each with differing width-to-height ratios (e.g., 16:9, 9:16). The consistent quality across different aspect ratios highlights LaDeCo’s versatility and robustness in handling diverse design requirements.
read the caption
Figure 13: More results to demonstrate that LaDeCo is able to generate graphic designs with different aspect ratios.
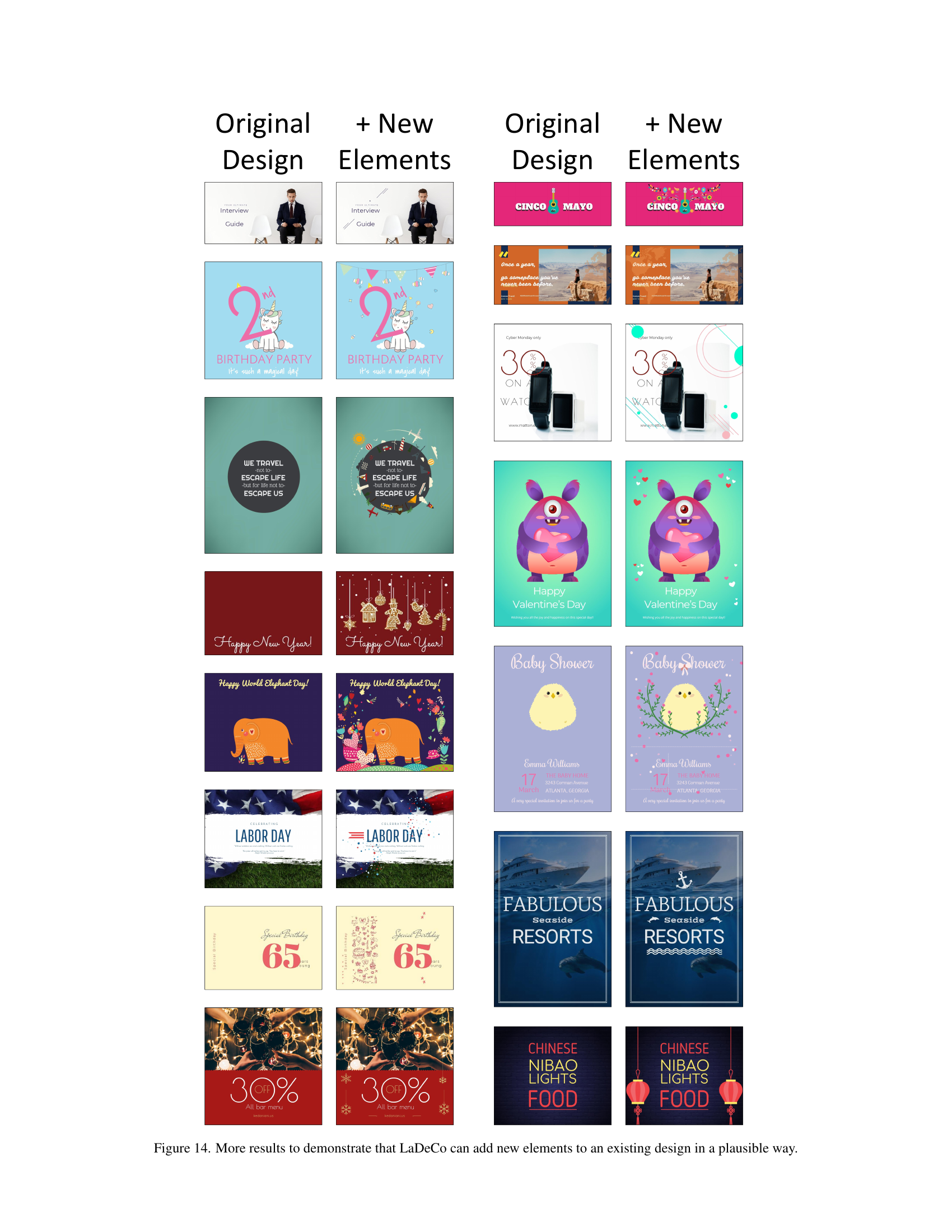
🔼 This figure showcases LaDeCo’s capability to seamlessly integrate new elements into pre-existing designs. It demonstrates the model’s ability to maintain visual coherence and aesthetic appeal while adding new components, highlighting its understanding of design principles and composition rules. Each example shows an original design alongside a version with additional elements added by LaDeCo. The added elements are incorporated in a natural and balanced way, showcasing the model’s ability to avoid visual clutter or disrupting the overall design harmony.
read the caption
Figure 14: More results to demonstrate that LaDeCo can add new elements to an existing design in a plausible way.
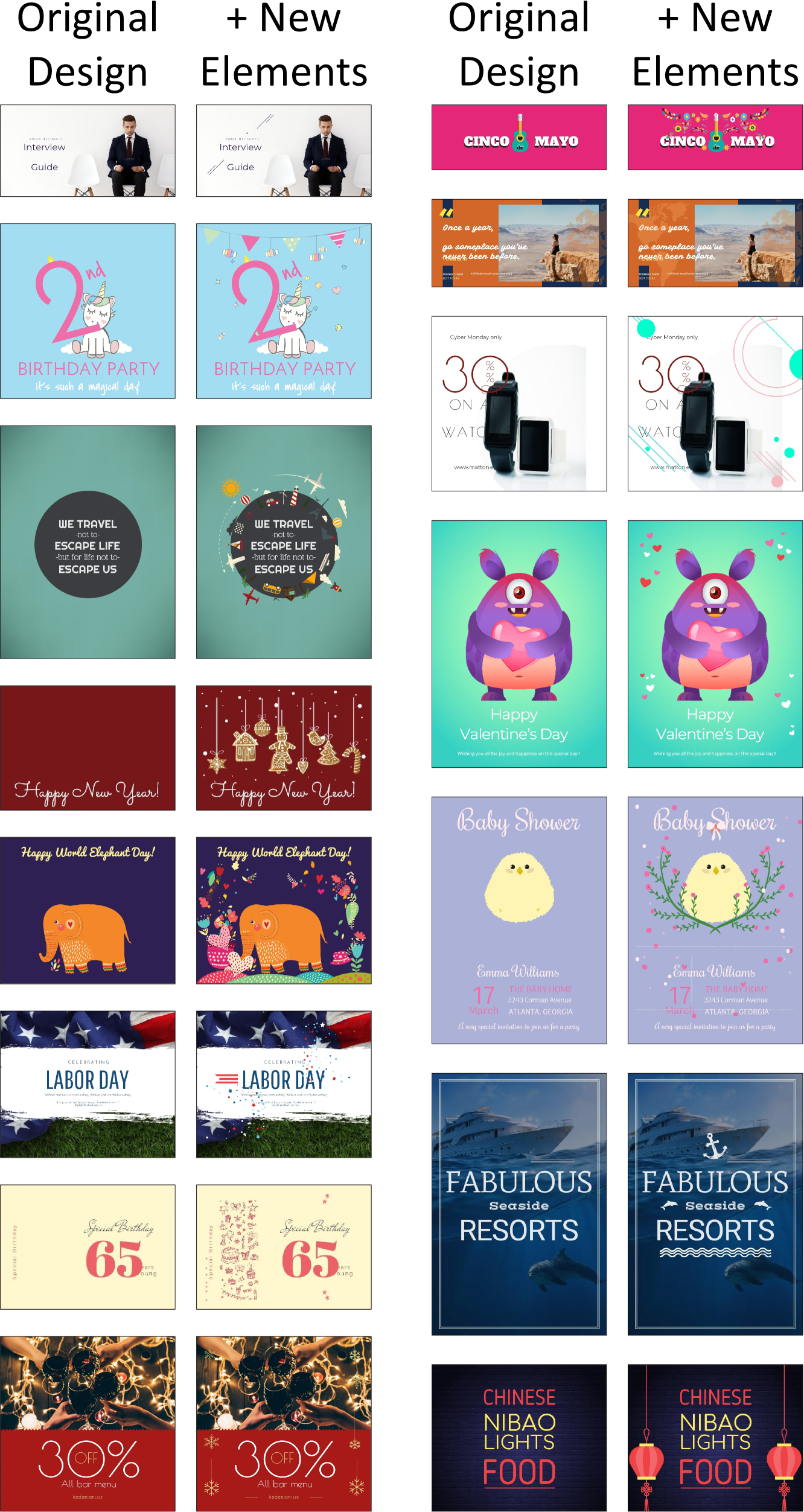
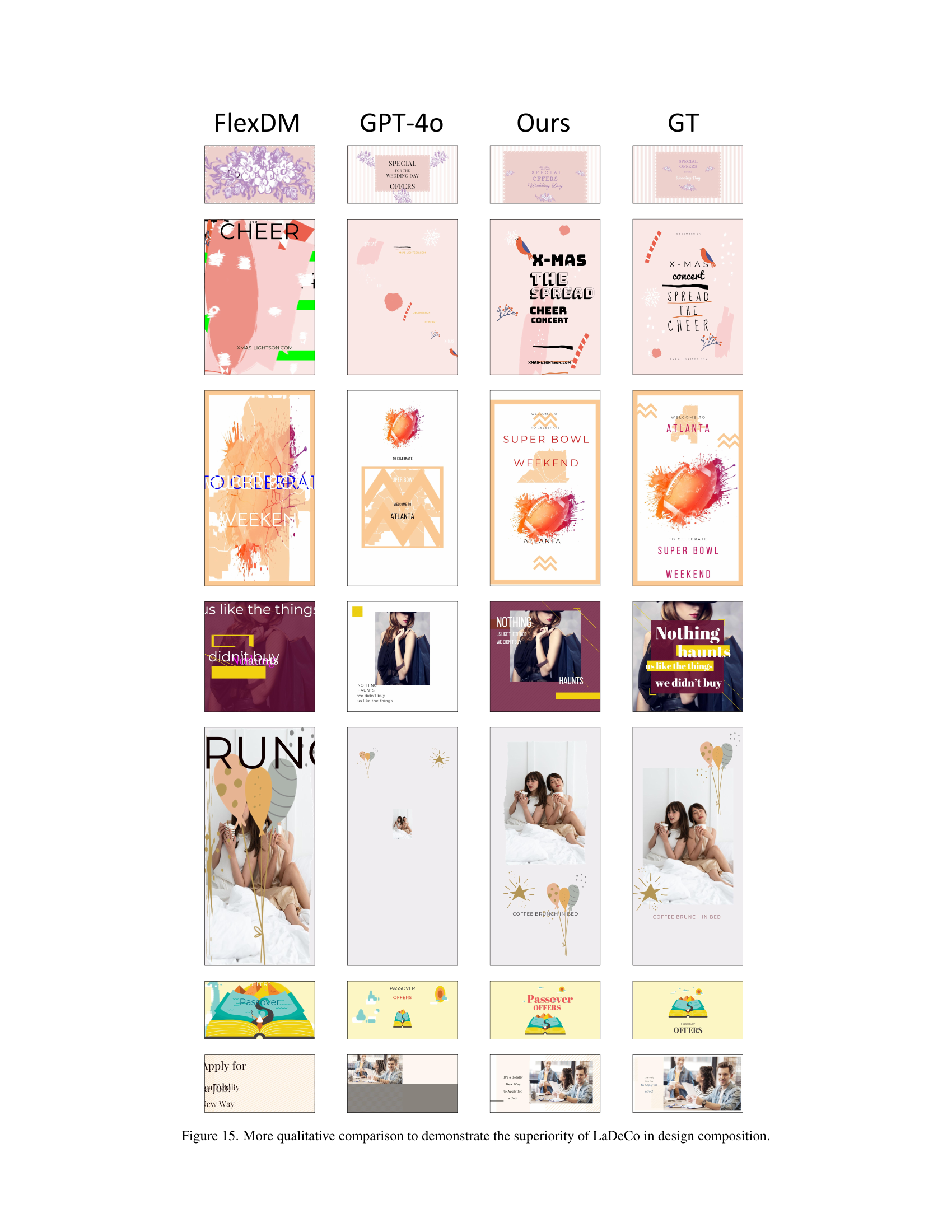
🔼 This figure presents a qualitative comparison of design compositions generated by different methods: FlexDM, GPT-40, LaDeCo (the proposed method), and ground truth (GT). Each row shows four design examples generated by each method for the same input, allowing for a direct visual comparison of the quality and aesthetic appeal of the generated designs. The comparison highlights LaDeCo’s superiority in creating visually appealing and well-composed designs compared to the other methods.
read the caption
Figure 15: More qualitative comparison to demonstrate the superiority of LaDeCo in design composition.
🔼 This figure presents a qualitative comparison of content-aware layout generation results. It showcases examples generated by several different methods: PosterLlama, PosterLLaVA, LaDeCo (the proposed method), and ground truth (GT). Each row shows a different design task, with the generated layouts and the ground truth for that task displayed side-by-side. The visual comparison allows for an assessment of each method’s ability to arrange elements on a canvas, maintaining both visual appeal and the appropriate relative positions of elements according to their content.
read the caption
Figure 16: More qualitative comparison to demonstrate the superiority of LaDeCo in content-aware layout generation.

🔼 Figure 17 presents a qualitative comparison of typography generation results from LaDeCo against two baseline methods: FlexDM and OpenCOLE. The figure showcases several example designs, illustrating that LaDeCo produces superior typography compared to the baselines. Specifically, the comparison highlights LaDeCo’s ability to create visually appealing and readable text layouts within the graphic designs. This demonstrates LaDeCo’s superiority in generating harmonious and effective typography in the context of overall design composition.
read the caption
Figure 17: More qualitative comparison to demonstrate the superiority of LaDeCo in typography generation.
More on tables
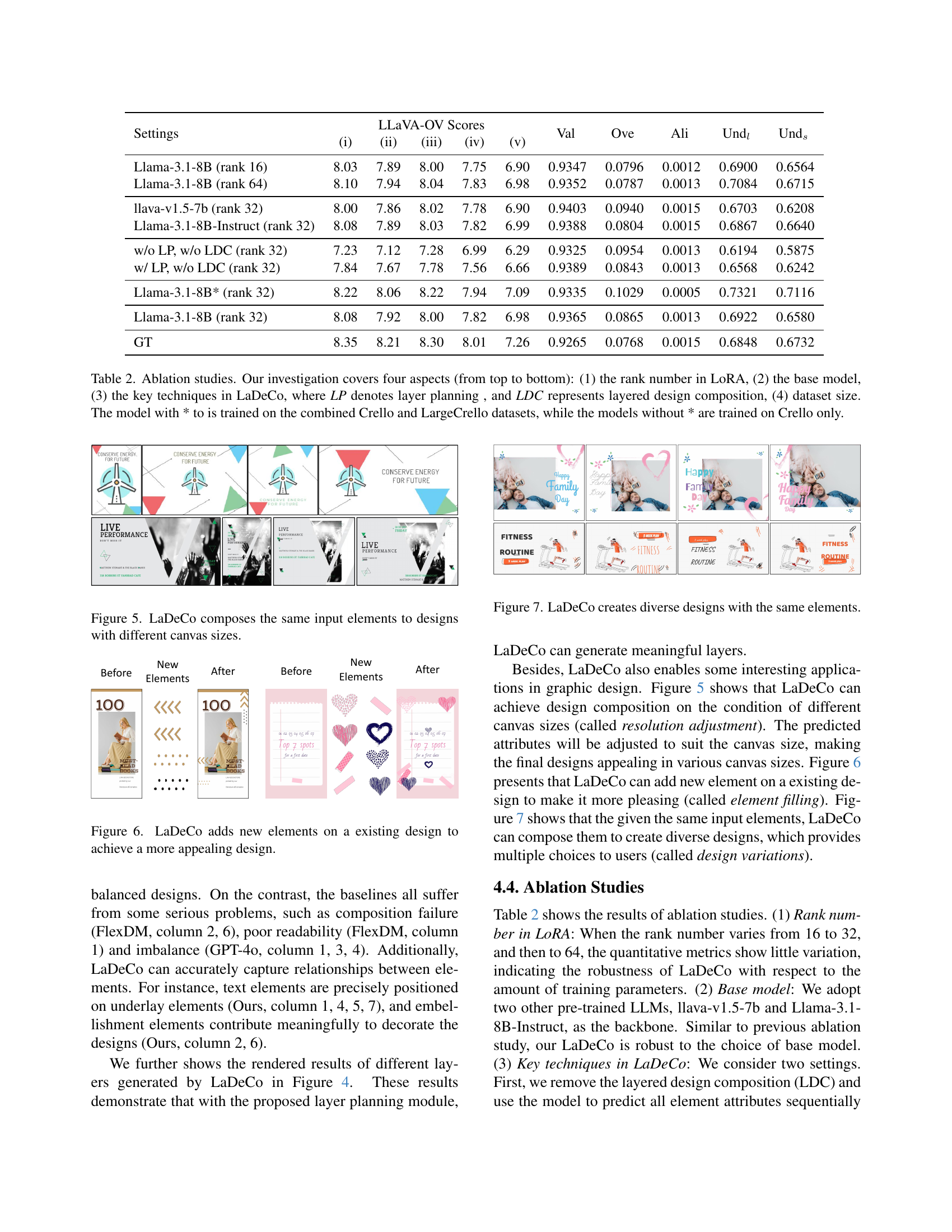
| Settings | (i) | (ii) | (iii) | (iv) | (v) | Val | Ove | Ali | Undl | Unds |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3.1-8B (rank 16) | 8.03 | 7.89 | 8.00 | 7.75 | 6.90 | 0.9347 | 0.0796 | 0.0012 | 0.6900 | 0.6564 |
| Llama-3.1-8B (rank 64) | 8.10 | 7.94 | 8.04 | 7.83 | 6.98 | 0.9352 | 0.0787 | 0.0013 | 0.7084 | 0.6715 |
| llava-v1.5-7b (rank 32) | 8.00 | 7.86 | 8.02 | 7.78 | 6.90 | 0.9403 | 0.0940 | 0.0015 | 0.6703 | 0.6208 |
| Llama-3.1-8B-Instruct (rank 32) | 8.08 | 7.89 | 8.03 | 7.82 | 6.99 | 0.9388 | 0.0804 | 0.0015 | 0.6867 | 0.6640 |
| w/o LP, w/o LDC (rank 32) | 7.23 | 7.12 | 7.28 | 6.99 | 6.29 | 0.9325 | 0.0954 | 0.0013 | 0.6194 | 0.5875 |
| w/ LP, w/o LDC (rank 32) | 7.84 | 7.67 | 7.78 | 7.56 | 6.66 | 0.9389 | 0.0843 | 0.0013 | 0.6568 | 0.6242 |
| Llama-3.1-8B* (rank 32) | 8.22 | 8.06 | 8.22 | 7.94 | 7.09 | 0.9335 | 0.1029 | 0.0005 | 0.7321 | 0.7116 |
| Llama-3.1-8B (rank 32) | 8.08 | 7.92 | 8.00 | 7.82 | 6.98 | 0.9365 | 0.0865 | 0.0013 | 0.6922 | 0.6580 |
| GT | 8.35 | 8.21 | 8.30 | 8.01 | 7.26 | 0.9265 | 0.0768 | 0.0015 | 0.6848 | 0.6732 |
🔼 This table presents the results of ablation studies conducted to analyze the impact of different components of the LaDeCo model on its performance. The study investigates four key aspects: 1) The rank of the LoRA (Low-Rank Adaptation) technique used for efficient fine-tuning of the large language model, varying the rank number to assess its influence. 2) The base language model used, testing different models to evaluate their suitability for the task. 3) The core techniques of LaDeCo, namely, Layer Planning (LP) and Layered Design Composition (LDC), which are systematically removed to understand their individual contributions. 4) The size of the training dataset, comparing the results obtained using only the Crello dataset and a combined Crello and LargeCrello dataset. The asterisk (*) indicates models trained on the larger combined dataset.
read the caption
Table 2: Ablation studies. Our investigation covers four aspects (from top to bottom): (1) the rank number in LoRA, (2) the base model, (3) the key techniques in LaDeCo, where LP denotes layer planning , and LDC represents layered design composition, (4) dataset size. The model with * to is trained on the combined Crello and LargeCrello datasets, while the models without * are trained on Crello only.
| Methods | Val | Ove | Ali | Undl | Unds | Uti | Occ | Rea |
|---|---|---|---|---|---|---|---|---|
| PosterLLaVa [32] | 0.9269 | 0.0685 | 0.0011 | 0.7879 | 0.7375 | 0.4199 | 0.1936 | 0.0747 |
| PosterLlama [27] | 0.8701 | 0.0868 | 0.0014 | 0.8483 | 0.7798 | 0.4115 | 0.1772 | 0.0694 |
| LaDeCo (Ours) | 0.9340 | 0.0805 | 0.0016 | 0.6851 | 0.6540 | 0.4414 | 0.1835 | 0.0768 |
| GT | 0.9265 | 0.0768 | 0.0015 | 0.6848 | 0.6732 | 0.4737 | 0.1628 | 0.0709 |
🔼 This table presents a quantitative comparison of different methods for content-aware layout generation. The metrics used assess various aspects of the generated layouts, comparing them to ground truth (GT) layouts created by human designers. The scores closest to the ground truth values are highlighted in bold, indicating the best-performing method in each metric. This helps to evaluate the accuracy and effectiveness of each approach in creating visually appealing and well-organized layouts.
read the caption
Table 3: Quantitative results on the content-aware layout generation subtask. The score closest to the one calculated from real data (denoted as GT) is highlighted in bold, indicating the best performance among different methods.
Full paper#