↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for training GUI agents rely on human-labeled data or synthetic data from pre-defined tasks, which are expensive and limit data quality and diversity. This paper introduces OS-Genesis, a novel approach that reverses the traditional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis lets agents freely interact with the environment and then retrospectively derives high-quality tasks and trajectories. A reward model ensures high-quality trajectory data.
OS-Genesis significantly outperforms existing methods on challenging benchmarks. It introduces reverse task synthesis, improving data quality and diversity. The results highlight the efficiency and effectiveness of OS-Genesis, demonstrating its ability to improve the performance of GUI agents across various tasks and environments. The approach is particularly valuable in applications where obtaining high-quality human-annotated data is difficult or costly.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical bottleneck in training GUI agents: the lack of high-quality, diverse trajectory data. OS-Genesis offers a novel solution to this problem, paving the way for more efficient and effective GUI automation. This work is highly relevant to the current trends in vision-language models and AI agents, opening new avenues for research in data synthesis and improving the capabilities of autonomous agents in complex digital environments. The code and data are publicly available, enabling broader participation in this field.
Visual Insights#

🔼 This figure illustrates the ideal format of a GUI agent trajectory. It showcases the four key components: a high-level instruction that describes the overall goal of the task (e.g., ‘Mark the ‘Avocado Toast with Egg’ recipe as a favorite in the Broccoli app.’); the environment’s state, including both visual (screenshot) and textual representations of the UI; low-level instructions that break down the task into smaller, actionable steps (e.g., ‘I need to click ‘Avocado Toast with Egg’ to view more details and find the option to mark it as a favorite.’); and finally, the specific actions the agent takes (e.g., CLICK [Avocado Toast with Egg] (698, 528)). This detailed structure is crucial for training high-performing GUI agents.
read the caption
Figure 1: Ideal GUI trajectory format, including High-Level Instructions, States (visual + textual representation), Low-Level Instructions, and Actions.
| Base Model | Strategies | AndroidWorld | AndroidControl-High | AndroidControl-Low | ||
|---|---|---|---|---|---|---|
| GPT-4o | Zero-Shot (M3A) | 23.70 | 53.04 | 69.14 | 69.59 | 80.27 |
| InternVL2-4B | Zero-Shot | 0.00 | 16.62 | 39.96 | 33.69 | 60.65 |
| Task-Driven | 4.02 | 27.37 | 47.08 | 66.48 | 90.37 | |
| Task-Driven w. Self Instruct | 7.14 | 24.95 | 44.27 | 66.70 | 90.79 | |
| OS-Genesis | 15.18 | 33.39 | 56.20 | 73.38 | 91.32 | |
| InternVL2-8B | Zero-Shot | 2.23 | 17.89 | 38.22 | 47.69 | 66.67 |
| Task-Driven | 4.46 | 23.79 | 43.94 | 64.43 | 89.83 | |
| Task-Driven w. Self Instruct | 5.36 | 23.43 | 44.43 | 64.69 | 89.85 | |
| OS-Genesis | 16.96 | 35.77 | 64.57 | 71.37 | 91.27 | |
| Qwen2-VL-7B | Zero-Shot | 0.89 | 28.92 | 61.39 | 46.37 | 72.78 |
| Task-Driven | 6.25 | 38.84 | 58.08 | 71.33 | 88.71 | |
| Task-Driven w. Self Instruct | 9.82 | 39.36 | 58.28 | 71.51 | 89.73 | |
| OS-Genesis | 17.41 | 44.54 | 66.15 | 74.17 | 90.72 |
🔼 This table presents the performance of different models and strategies on two Android-based GUI benchmarks: AndroidControl and AndroidWorld. For each benchmark, the table shows the success rate (SR), indicating the percentage of tasks successfully completed, and the action type accuracy (Type). The action type accuracy measures how well the model’s predicted actions (e.g., CLICK, SCROLL, TYPE) match the ground truth actions needed to complete the tasks. The models compared include various Vision-Language Models (VLMs) trained using different methods such as zero-shot, task-driven, task-driven with self-instruction, and OS-Genesis. The table helps to evaluate the effectiveness of the proposed OS-Genesis data synthesis pipeline.
read the caption
Table 1: Evaluations on AndroidControl and AndroidWorld. SR represents the task success rate. Type measures the exact match score between the predicted action types (e.g., CLICK, SCROLL) and the ground truth.
In-depth insights#
GUI Agent Synthesis#
GUI agent synthesis is a critical area of research focusing on automatically generating agents capable of interacting with graphical user interfaces (GUIs). This involves creating agents that can understand user instructions, plan effective sequences of actions, and execute those actions within a GUI environment to achieve specific goals. A key challenge lies in acquiring sufficient high-quality training data. Traditional approaches, such as manual data collection or generating synthetic data from pre-defined tasks, are often expensive, time-consuming, or limited in diversity. Recent advances, such as the OS-Genesis pipeline, aim to address these limitations by introducing novel techniques like reverse task synthesis. This innovative approach focuses on observing agent-environment interactions, then retrospectively deriving tasks and generating high-quality trajectories. This not only improves data diversity and quality but also reduces the reliance on expensive human annotation. Ultimately, the goal of effective GUI agent synthesis is to create robust and generalizable agents that can perform a wide range of complex GUI tasks automatically and efficiently. Further research should explore more sophisticated techniques for data generation, model training, and evaluation to push the boundaries of autonomous GUI interaction.
Reverse Task Design#
Reverse task design is a fascinating approach to data generation for training AI agents, particularly in complex domains like GUI interaction. Instead of defining tasks upfront and recording agent trajectories, it flips the script, letting the agent explore the environment freely. The key is to retrospectively analyze the agent’s interactions—its actions and resulting state changes—to infer the underlying tasks it implicitly performed. This offers several advantages. First, it allows for greater diversity and unpredictability in the generated data, overcoming limitations of pre-defined tasks, which tend to produce homogenous and limited datasets. Second, it removes the need for human-designed tasks, making the data collection process more scalable and efficient. This is particularly valuable in GUI environments with vast, multifaceted functionalities, which makes exhaustive task definition virtually impossible. However, challenges remain. Effectively extracting meaningful tasks from unstructured agent interactions is computationally difficult and requires robust analysis techniques. Also, evaluating the quality of the synthesized data and ensuring it aligns with realistic user behavior is crucial, which could need further methods. Thus, reverse task design presents both promising possibilities and considerable research challenges in advancing the field of AI agent training. The success of this approach hinges on innovative solutions for both the retrospective task identification and data quality assessment.
Trajectory Reward Model#
The Trajectory Reward Model is a crucial component of the OS-Genesis system, addressing a critical limitation in existing GUI agent training methods. Traditional approaches often discard incomplete or erroneous trajectories, leading to a loss of valuable data. OS-Genesis cleverly uses a reward model to assign scores (1-5) to trajectories based on their completeness and coherence. This graded evaluation allows the system to learn from a wider range of interactions, not just perfectly executed tasks. This nuanced approach improves the training data quality and diversity, especially crucial in complex, dynamic GUI environments where perfect task execution is challenging. The reward model utilizes GPT-40 to assess trajectories considering factors like whether the actions logically progress toward the goal and if the task is ultimately completed. This intelligent scoring system effectively utilizes even incomplete trajectories, increasing data efficiency and enabling the creation of more robust and capable GUI agents. The use of GPT-40 highlights the reliance on powerful language models for such complex tasks, although future iterations might explore the use of more lightweight, potentially open-source alternatives.
Benchmark Analysis#
A thorough benchmark analysis of a GUI agent system necessitates a multi-faceted approach. It should begin by clearly defining the chosen benchmarks and their relevance to real-world GUI interaction tasks. Key performance indicators (KPIs) such as task success rate, action accuracy, and efficiency (time taken, steps involved) must be precisely outlined. The selection of baselines is crucial; these should represent the current state-of-the-art or widely accepted approaches in GUI automation. A direct comparison of the proposed method against these baselines, using statistically significant data, will highlight the advancements achieved. Furthermore, a breakdown of performance across various GUI types (web, mobile, desktop), tasks complexity, and data distributions would offer a richer understanding of the system’s robustness and scalability. Error analysis forms another vital component; a detailed investigation of the types of errors and their frequencies, along with a discussion of their root causes, is essential for identifying areas for future improvements. Finally, qualitative analysis beyond mere numerical results is highly valuable; interpreting the agent’s behavior and decision-making processes through qualitative observations can reveal valuable insights that purely quantitative data might miss.
Future of GUI Agents#
The future of GUI agents hinges on addressing current limitations and exploring new avenues. Improving data efficiency is crucial; current methods for collecting training data are costly and time-consuming. Reverse task synthesis, as explored in this paper, offers a promising approach by generating trajectories through interaction and then retrospectively defining tasks. Enhanced model capabilities are also needed; current VLMs need better integration with GUI environments and improved reasoning abilities to handle complex tasks and interactions. Moreover, robustness and generalization are paramount; agents must be able to handle diverse GUI structures, unforeseen events, and different user interfaces effectively. Safety and ethical considerations must guide future development, ensuring responsible automation and preventing misuse of such powerful tools. Finally, the integration of advanced techniques like reinforcement learning and planning algorithms will be vital to create truly autonomous and intelligent GUI agents capable of complex, real-world interactions.
More visual insights#
More on figures

🔼 This figure illustrates the OS-Genesis data generation process. It starts with an agent freely exploring a GUI environment (like a web browser) without any predefined tasks or human input. This exploration generates a large dataset of triples: an action performed by the agent, the screen’s appearance before the action, and the screen’s appearance after the action. A technique called ‘reverse task synthesis’ then analyzes these triples. It uses them to create low-level instructions describing individual actions and combines those low-level instructions into high-level instructions that represent broader tasks.
read the caption
Figure 2: An overview of how we generate instruction data without relying on predefined tasks or human annotations. OS-Genesis begins with a model-free, interaction-driven traversal in online environments (e.g., a web browser). This process produces massive triples consisting of actions and their corresponding pre- and post-interaction screenshots. Reverse task synthesis leverages these triples to generate low-level instructions and associates them with broader objectives to construct high-level instructions.

🔼 This figure illustrates the OS-Genesis pipeline for generating GUI agent trajectories. It begins with high-level instructions, which are then broken down into a series of low-level instructions. The agent interacts with the GUI environment according to these instructions, generating a trajectory. The trajectory is a sequence of actions and corresponding screenshots, showing the state of the GUI at each step. The final three states (shown in light blue) are fed, along with the low-level instructions, into a Trajectory Reward Model (TRM). The TRM assigns a reward score to the entire trajectory based on the quality and completeness of the task completion. This score is then used to guide future trajectory generation, improving the data quality and diversity.
read the caption
Figure 3: An overview of collecting complete trajectories through exploring high-level instructions generated by reverse task synthesis. Low-level instructions and the last three states of the trajectory (indicated in light blue) are used by the Trajectory Reward Model (TRM) to assign reward scores.

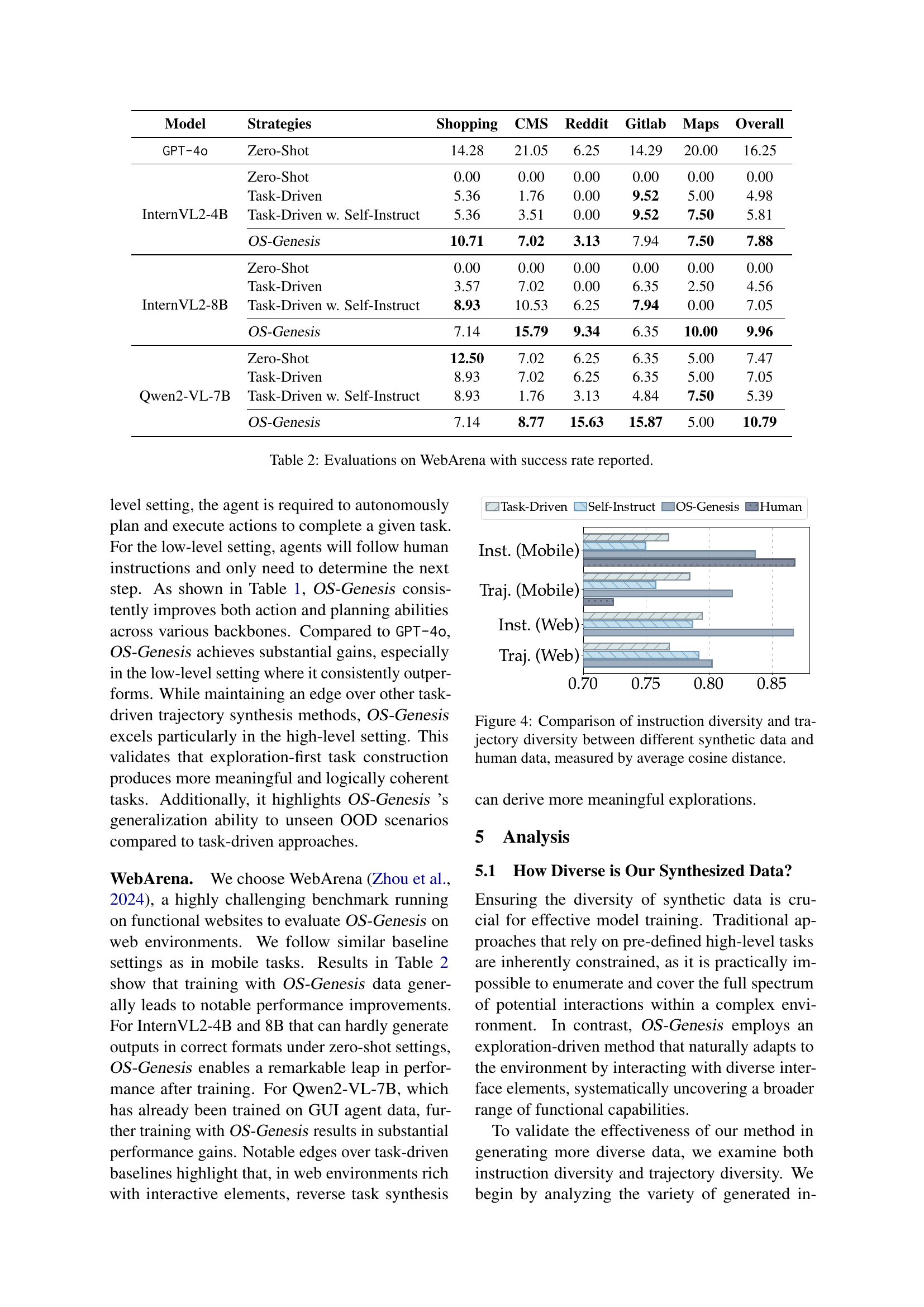
🔼 This figure compares the diversity of instructions and trajectories generated by different methods (OS-Genesis, task-driven, self-instruction) against human-generated data. Diversity is measured using the average cosine distance of embeddings, showing how semantically different the instructions and actions are within each dataset. The graph helps to illustrate whether OS-Genesis produces more diverse and varied trajectories compared to task-driven baselines and how these compare to human data.
read the caption
Figure 4: Comparison of instruction diversity and trajectory diversity between different synthetic data and human data, measured by average cosine distance.

🔼 This figure compares the performance of three different reward modeling strategies: using a trajectory reward model (TRM), using a labeler to filter trajectories, and training without any reward model. The results show that TRM significantly improves performance on high-level tasks, while the labeler-based approach leads to some gains in high-level tasks but at the cost of performance in low-level tasks. Training without a reward model provides consistent improvement across both low and high-level tasks, indicating the value of using any reward model. The y-axis represents the success rate (SR) and action type accuracy (Type) for each task. The x-axis represents different reward modeling strategies.
read the caption
Figure 5: Comparison of different reward modeling strategies.

🔼 This figure shows the performance of GUI agents trained on datasets with varying sizes. The x-axis represents the number of trajectories used for training, while the y-axis represents the success rate of the GUI agents on a specific task (likely the AndroidWorld benchmark). Multiple lines are shown, each representing a different model architecture, demonstrating how different models perform with increasing amounts of training data. The graph helps illustrate the relationship between the amount of training data and the accuracy of the trained agents.
read the caption
Figure 6: Performance of GUI agents trained on datasets of varying scales.
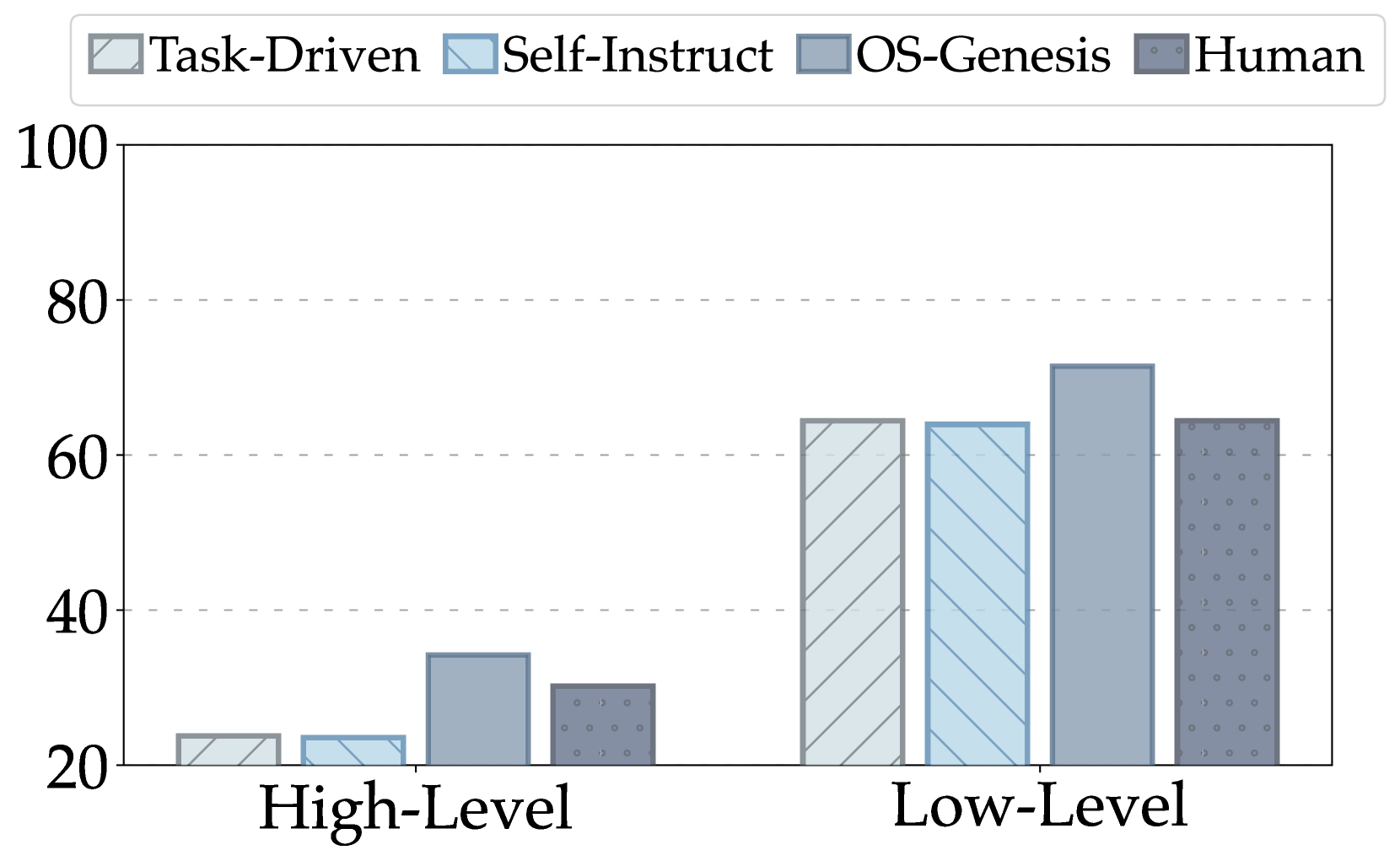
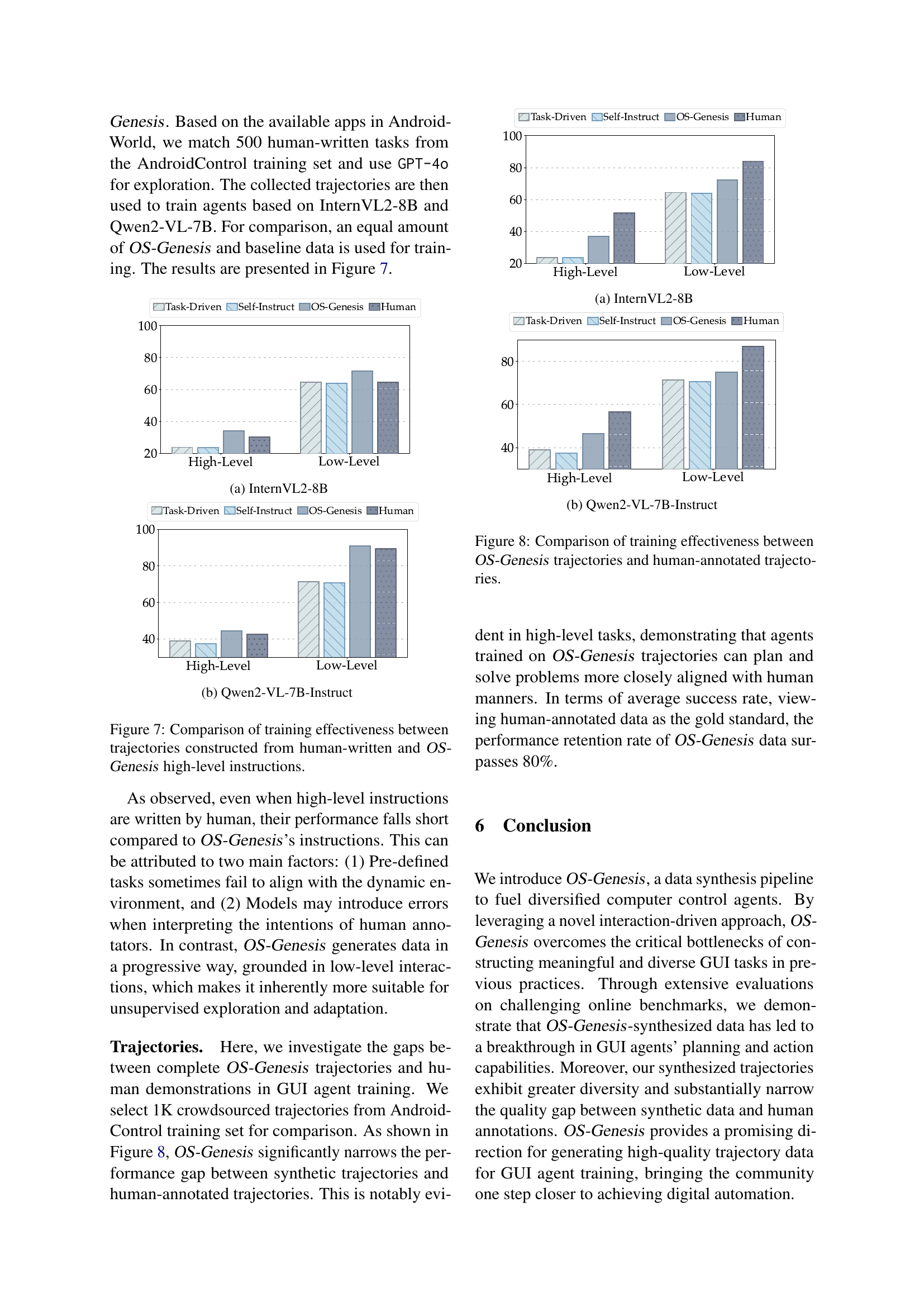
🔼 This figure shows a comparison of the training effectiveness between trajectories generated using OS-Genesis and those from human-annotated data. The results are broken down by high-level and low-level tasks, revealing how each method performs in comparison. The graph visually displays the success rates of agents trained with different data sources across different task complexities.
read the caption
(a) InternVL2-8B

🔼 This figure shows the performance of the Qwen2-VL-7B-Instruct model on the AndroidControl benchmark. The graph displays the success rate (SR) and action type accuracy for both high-level and low-level tasks. Success rate measures the percentage of tasks completed successfully, while action type accuracy reflects how precisely the agent’s actions match the ground truth. The results help evaluate the model’s ability to perform both high-level planning and low-level execution in a challenging GUI interaction environment.
read the caption
(b) Qwen2-VL-7B-Instruct

🔼 This figure compares the performance of models trained using high-level instructions generated in two different ways: human-written instructions and OS-Genesis generated instructions. The x-axis represents the type of task (High-Level or Low-Level). The y-axis shows the success rate of the tasks. The bars represent the performance of models trained on data generated with human-written high-level instructions and OS-Genesis-generated high-level instructions for InternVL2-8B and Qwen2-VL-7B models. The goal is to demonstrate that OS-Genesis’s method of generating instructions produces data leading to comparable or better model performance than using human-written instructions.
read the caption
Figure 7: Comparison of training effectiveness between trajectories constructed from human-written and OS-Genesis high-level instructions.

🔼 This figure (Figure 7) shows a comparison of the training effectiveness between trajectories constructed from human-written instructions and OS-Genesis high-level instructions. The chart displays the success rate (SR) for both high-level and low-level tasks for models trained with each type of data. InternVL2-8B model performance is shown for both instructions types, illustrating the impact of training data quality on model accuracy in various task settings.
read the caption
(a) InternVL2-8B

🔼 This figure shows the results of the AndroidWorld benchmark for the Qwen2-VL-7B-Instruct model. The benchmark measures the success rate (SR) and action type accuracy of GUI agents performing tasks. The figure likely displays a bar chart or similar visualization comparing the performance of Qwen2-VL-7B-Instruct to other models or baselines (such as Zero-Shot, Task-Driven, Self-Instruction, or other versions of the Qwen2 model) on the AndroidWorld tasks, potentially showing significant improvement from the Qwen2 model trained with the OS-Genesis data synthesis method. The y-axis would represent performance metrics (SR and/or Type accuracy), and the x-axis lists different models/methods.
read the caption
(b) Qwen2-VL-7B-Instruct

🔼 This figure compares the effectiveness of training GUI agents using trajectories generated by OS-Genesis versus human-annotated trajectories. It shows that models trained with OS-Genesis data achieve significantly higher performance in both high-level and low-level tasks compared to models trained with human-annotated data. The improved performance highlights OS-Genesis’s ability to produce high-quality, diverse training data that is more effectively utilized by the model.
read the caption
Figure 8: Comparison of training effectiveness between OS-Genesis trajectories and human-annotated trajectories.

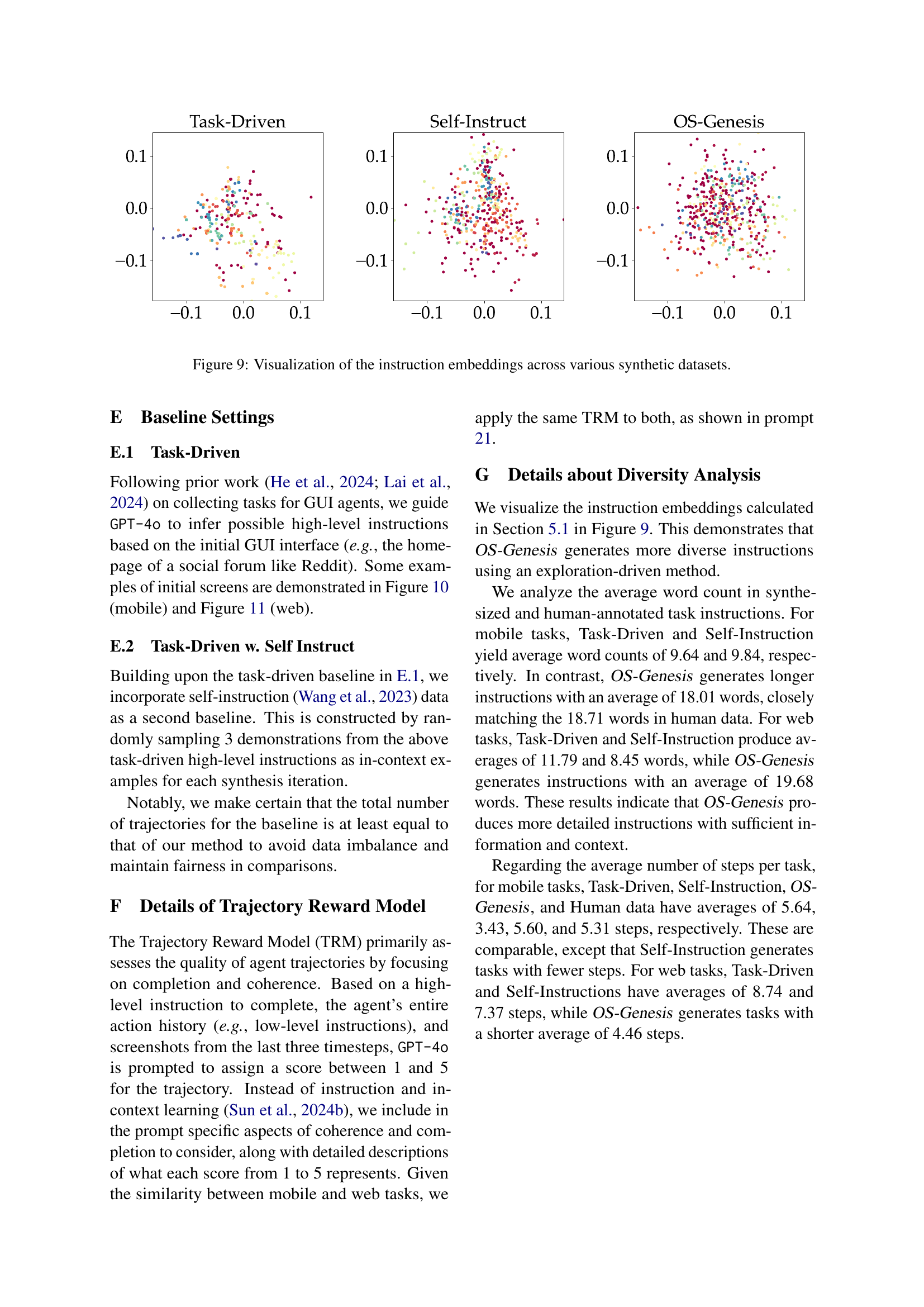
🔼 This figure visualizes the embeddings of instructions generated by different methods for synthesizing GUI agent trajectories. It uses t-SNE to reduce the dimensionality of the instruction embeddings to two dimensions, allowing for visualization. Each point represents an instruction, and the proximity of points suggests semantic similarity. The figure aims to show the diversity of instructions generated by each method (Task-Driven, Self-Instruct, OS-Genesis). The clustering patterns show the degree to which each method generates similar or diverse instructions. This helps demonstrate the impact of different methods on the quality and diversity of training data.
read the caption
Figure 9: Visualization of the instruction embeddings across various synthetic datasets.

🔼 This figure shows a screenshot of the Contacts app’s initial screen on a mobile device. The screenshot displays various features of the Contacts app interface, including options for viewing contacts, accessing voicemail, and managing favorites. The image is used to illustrate the diversity of the GUI environments explored by the OS-Genesis system during its interaction-driven functional discovery phase. It helps contextualize the reverse task synthesis process by showing a typical starting point for agent exploration.
read the caption
(a) Contacts

🔼 The figure shows a screenshot of the ‘Files’ app on a mobile device. It displays a list of files and folders, categorized by type (Images, Audio, Videos, Documents). The interface includes a search bar, options to access Favorites and Recents, and a count of files in the Downloads folder. The visual emphasizes a minimalist design with a focus on file organization.
read the caption
(b) Files

🔼 This image shows a screenshot of the ‘Markor’ mobile application’s interface. The screenshot displays a simple, clean interface with a search bar at the top and several options underneath, including ‘Files’, ‘To-Do’, ‘QuickNote’, and ‘More’. This suggests a basic note-taking or text-editing application.
read the caption
(c) Markor

🔼 This figure displays example screenshots of initial screens from three different mobile applications used to establish task-driven baselines. These starting points are used to instruct agents in completing tasks within the applications, representing the starting point for the task-driven approach where pre-defined tasks direct the agent’s behavior. The image shows three examples of what an agent starts with: A screen showing a list of contacts, one showing a list of files, and a simpler note-taking app.
read the caption
Figure 10: Examples of initial screens employed in building task-driven baselines for mobile tasks.

🔼 This figure shows an example of an initial screen from the CMS (Content Management System) used in building task-driven baselines for web tasks in the OS-Genesis experiment. The image displays a portion of a CMS interface, illustrating the kind of visual input used to generate high-level instructions and explore the environment.
read the caption
(a) CMS

🔼 This image shows a screenshot of the GitLab web interface, used as an example of initial screens employed in building task-driven baselines for web tasks in the OS-Genesis paper. The screenshot displays a typical GitLab project view, likely showing project information, activity, and possibly code repositories.
read the caption
(b) GitLab
More on tables
| Model | Strategies | Shopping | CMS | Gitlab | Maps | Overall | |
|---|---|---|---|---|---|---|---|
| GPT-4o | Zero-Shot | 14.28 | 21.05 | 6.25 | 14.29 | 20.00 | 16.25 |
| InternVL2-4B | Zero-Shot | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Task-Driven | 5.36 | 1.76 | 0.00 | 9.52 | 5.00 | 4.98 | |
| Task-Driven w. Self-Instruct | 5.36 | 3.51 | 0.00 | 9.52 | 7.50 | 5.81 | |
| OS-Genesis | 7.02 | 3.13 | 7.94 | 7.50 | 7.88 | ||
| InternVL2-8B | Zero-Shot | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Task-Driven | 3.57 | 7.02 | 0.00 | 6.35 | 2.50 | 4.56 | |
| Task-Driven w. Self-Instruct | 8.93 | 10.53 | 7.94 | 0.00 | 7.05 | ||
| OS-Genesis | 15.79 | 9.34 | 6.35 | 10.00 | 9.96 | ||
| Qwen2-VL-7B | Zero-Shot | 12.50 | 7.02 | 6.25 | 6.35 | 5.00 | 7.47 |
| Task-Driven | 8.93 | 7.02 | 6.25 | 6.35 | 5.00 | 7.05 | |
| Task-Driven w. Self-Instruct | 8.93 | 1.76 | 3.13 | 4.84 | 7.50 | 5.39 | |
| OS-Genesis | 8.77 | 15.63 | 15.87 | 5.00 | 10.79 |
🔼 This table presents the performance of different models and strategies on the WebArena benchmark. The results show the success rate for each model across various web tasks (Shopping, CMS, Reddit, GitLab, Maps). The strategies compared include zero-shot, task-driven, task-driven with self-instruction, and OS-Genesis.
read the caption
Table 2: Evaluations on WebArena with success rate reported.
| Action | Description |
|---|---|
click | Clicks at the target elements. |
long_press | Presses and holds on the target element. |
type | Types the specified text at the current cursor location. |
scroll | Scrolls in a specified direction on the screen. |
navigate_home | Navigates to the device’s home screen. |
navigate_back | Returns to the previous screen or page. |
open_app | Launches the specified application. |
wait | Agent decides it should wait. |
terminate | Agent decides the task is finished. |
keyboard_enter | Presses the Enter key. |
🔼 This table lists all the actions available to the mobile GUI agent in the OS-Genesis framework. It provides a detailed description of each action type and what it does, including parameters or additional details as needed. This information is crucial for understanding the range of interactions the agent can perform in mobile environments.
read the caption
Table 3: Action space for mobile tasks.
| Action | Description |
|---|---|
click [id] | Clicks on an element with a specific id. |
type [id] [content] | Types the content into the field with id. |
hover [id] | Hovers on an element with id. |
press [key_comb] | Presses the key combination using the keyboard. |
| `scroll [down | up]` |
new_tab | Opens a new tab. |
tab_focus [tab_index] | Switches the current focus to a specific tab. |
close_tab | Closes the current tab. |
goto [url] | Navigates to a specific URL. |
go_back | Navigates to the previous page. |
go_forward | Navigates to the next page. |
🔼 This table lists the various actions that can be performed by agents within the web environment of the OS-Genesis framework. Each action is described, providing a clear understanding of its functionality. This is crucial context for interpreting the results from experiments that utilize these actions, as it explains the range of interactions the agents can undertake.
read the caption
Table 4: Action space for web tasks.
Full paper#