↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-4D methods lack control over the appearance of generated 4D content and often significantly alter the input object when introducing dynamics. This paper introduces 3to4D, a novel method that animates user-provided 3D objects while preserving their visual identity. It uses a two-stage process: first, it creates a static 4D representation of the object, then uses an image-to-video diffusion model to animate the object based on a text prompt.
To improve the realism of the generated animations, 3to4D introduces an incremental viewpoint selection protocol and a masked SDS loss. The incremental viewpoint selection gradually increases the viewpoint diversity during the generation process, which enhances the dynamic motion, while the masked SDS loss focuses the optimization on the relevant parts of the object, maintaining the original identity. This approach allows users to generate high-quality 4D animations that are both visually appealing and consistent with the input object and the text description. The experimental results demonstrate that 3to4D outperforms baseline methods in terms of visual quality and dynamic realism, effectively bridging the gap between static 3D assets and animated 4D content.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel method for animating 3D objects using text prompts, achieving high-quality results while preserving the original object’s identity. This addresses a significant gap in current 4D content generation techniques by allowing users to easily animate their existing 3D assets, opening new avenues for research in virtual worlds, gaming, media, and beyond. The proposed method also introduces technical improvements like an incremental viewpoint selection protocol and masked SDS loss, contributing valuable insights to the broader field of generative modeling.
Visual Insights#

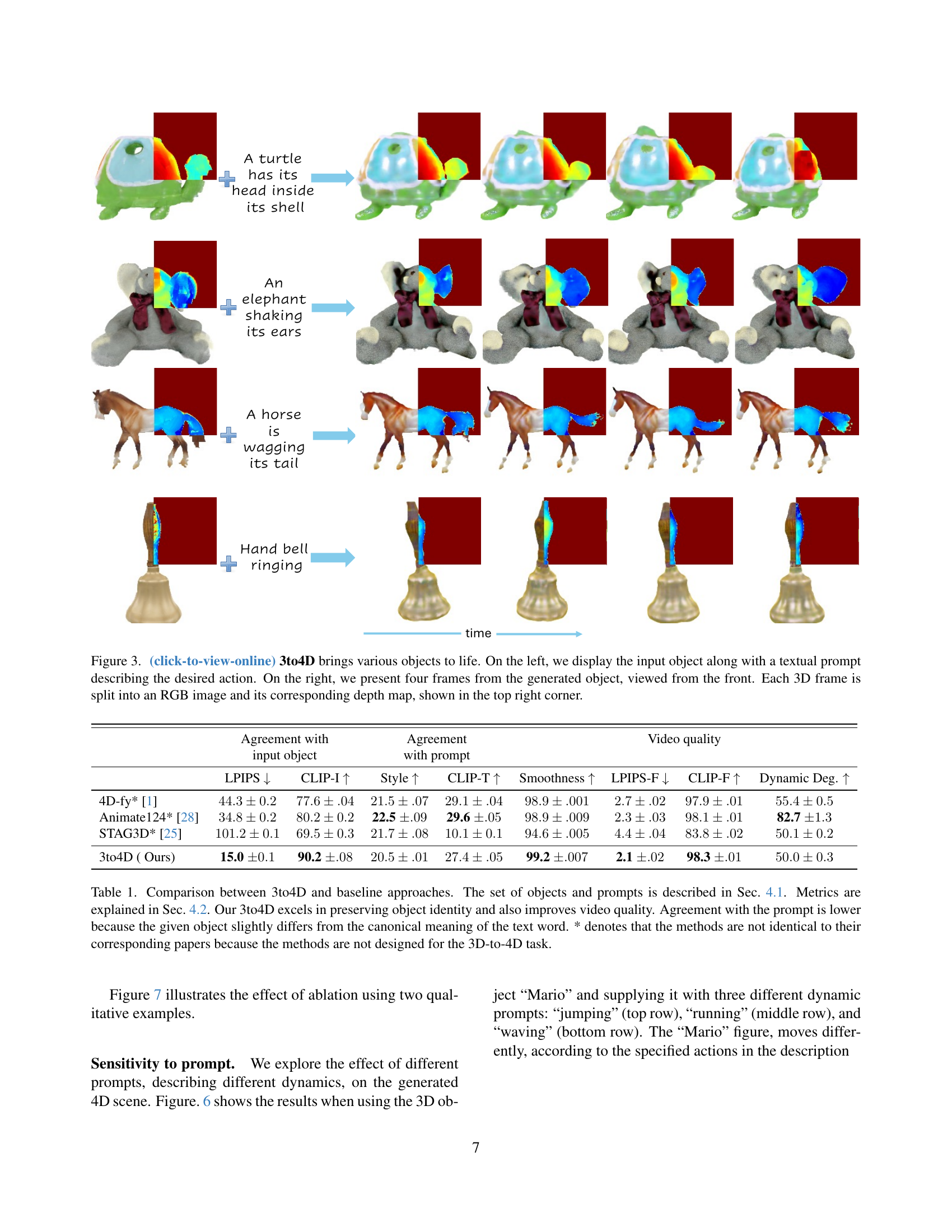
🔼 This figure showcases the capabilities of the 3to4D method. Starting with a static 3D object (shown on the left of each example), a textual prompt is provided to specify the desired animation. The 3to4D system then generates a 4D animation, effectively a short video, which can be viewed from any perspective. The image displays four frames extracted from one such 4D animation; for each frame, the RGB image is shown along with the corresponding depth map in the top right corner. This illustrates how the system animates the provided 3D model according to a natural language description.
read the caption
Figure 1: (Click to view Video online) Our method, 3to4D, takes a static 3D object and a textual prompt describing a desired action. It then adds dynamics to the object based on the prompt to create a 4D animation, essentially a video viewable from any perspective. On the right, we display four 3D frames from the generated 4D animation. Each 3D frame is split into an RGB image and a corresponding depth map on its top right.
| Method | LPIPS ↓ | CLIP-I ↑ | Style ↑ | CLIP-T ↑ | Smoothness ↑ | LPIPS-F ↓ | CLIP-F ↑ | Dynamic Deg. ↑ |
|---|---|---|---|---|---|---|---|---|
| 4D-fy* [1] | 44.3 ± 0.2 | 77.6 ± .04 | 21.5 ± .07 | 29.1 ± .04 | 98.9 ± .001 | 2.7 ± .02 | 97.9 ± .01 | 55.4 ± 0.5 |
| Animate124* [28] | 34.8 ± 0.2 | 80.2 ± 0.2 | 22.5 ± .09 | 29.6 ± .05 | 98.9 ± .009 | 2.3 ± .03 | 98.1 ± .01 | 82.7 ± 1.3 |
| STAG3D* [25] | 101.2 ± 0.1 | 69.5 ± 0.3 | 21.7 ± .08 | 10.1 ± 0.1 | 94.6 ± .005 | 4.4 ± .04 | 83.8 ± .02 | 50.1 ± 0.2 |
| 3to4D (Ours) | 15.0 ± 0.1 | 90.2 ± .08 | 20.5 ± .01 | 27.4 ± .05 | 99.2 ± .007 | 2.1 ± .02 | 98.3 ± .01 | 50.0 ± 0.3 |
🔼 This table compares the performance of the proposed 3to4D method against three baseline methods (4D-fy, Animate124, and STAG3D) on the task of generating 4D animations from 3D objects using text prompts. The comparison is based on several metrics related to the quality of the generated videos, including object identity preservation, agreement with the prompt, and video quality aspects such as smoothness and dynamic content. Note that the baseline methods were adapted for the 3D-to-4D task, as they were not originally designed for this specific purpose.
read the caption
Table 1: Comparison between 3to4D and baseline approaches. The set of objects and prompts is described in Sec. 4.1. Metrics are explained in Sec. 4.2. Our 3to4D excels in preserving object identity and also improves video quality. Agreement with the prompt is lower because the given object slightly differs from the canonical meaning of the text word. * denotes that the methods are not identical to their corresponding papers because the methods are not designed for the 3D-to-4D task.
In-depth insights#
4D Anim. from 3D#
The concept of generating 4D animations directly from 3D models presents a significant advancement in digital content creation. This approach bypasses the traditional two-stage process (first generating a static 3D object, then adding dynamics), which often results in loss of the original object’s identity. Direct 4D animation offers greater control and efficiency. Instead of relying solely on text prompts, which can lead to unpredictable results, using existing 3D models as a base ensures that the generated animation maintains the appearance and geometry of the original. This is crucial for applications requiring precise control over the visual output. Challenges remain in seamlessly integrating motion while preserving the original object’s features. Techniques like employing a static 4D Neural Radiance Field (NeRF) to capture the initial object’s properties, combined with image-to-video diffusion models to add animation, show promise. However, the methods need improvements in handling dynamic movements and maintaining high visual fidelity throughout the animation. Future research should focus on enhancing motion realism and ensuring robust preservation of the input object’s identity.
SDS & Viewpoint#
The paper introduces a novel approach to 4D object animation by combining Score Distillation Sampling (SDS) with an innovative viewpoint selection strategy. SDS loss is crucial for guiding the optimization of the animation process. However, the authors observed that conventional random viewpoint sampling often produces inconsistent and unrealistic motions. To address this, they propose an incremental viewpoint selection protocol. This approach begins with a narrow field of view and gradually expands the range of viewpoints over time. This incremental approach ensures greater consistency between viewpoints, resulting in improved optimization and more dynamic motion generation. This strategy cleverly balances exploration of potential motion variation with stable optimization, enabling the 4D model to learn more realistic movements. The combination of SDS and the new viewpoint strategy allows the system to maintain the identity and visual fidelity of the original 3D object while simultaneously generating compelling and coherent dynamic content. It emphasizes the importance of controlling the sampling process of training data, which directly impacts the quality of the animation.
3to4D: Method#
The core of the 3to4D method lies in its two-stage approach. First, it initializes a static 4D representation from a provided 3D object. This is achieved by training a neural radiance field (NeRF) to accurately capture the object’s visual attributes (RGB, depth, normals) from multiple viewpoints, ensuring consistency across the temporal dimension. Secondly, dynamics are added to this static representation using an image-to-video diffusion model conditioned on the object and a text prompt. Two key innovations are presented to enhance realism and control. An incremental viewpoint selection protocol gradually expands the sampling range during optimization, promoting more dynamic motion. A masked score distillation sampling (SDS) loss leverages attention maps to focus optimization on object-relevant areas, minimizing interference from irrelevant background elements, thus preserving object identity throughout the animation. This refined process results in 4D animations that are temporally coherent, prompt-adherent, and visually faithful to the original 3D object, showcasing a significant improvement over existing methods.
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In the context of this research, an ablation study on a 3D-to-4D animation model would likely investigate the impact of key elements such as the image-to-video diffusion model, the viewpoint selection strategy, and the masked SDS loss. Removing each component in turn, and comparing the results against the full model, reveals how much each contributes to overall performance. Improved motion smoothness, visual quality, and fidelity to the original 3D object would be key metrics. The study would likely show the importance of each element: that the image-to-video model is crucial for creating realistic motion, the viewpoint sampling improves motion dynamism, and the masked SDS loss ensures accurate animation without losing object identity. Significant drops in performance metrics upon removing a component indicate its critical role in the success of the model. The ablation study, therefore, provides valuable insights into the model’s architecture and identifies which components are essential for achieving high-quality 4D animations.
Future Work#
Future work could explore several promising avenues. Improving the handling of complex object interactions and articulated movements is crucial for generating more realistic and nuanced animations. Addressing limitations in handling intricate details, such as fine textures and complex geometries, would enhance visual fidelity. Expanding the approach to handle a broader range of object categories and motion types would broaden the applicability of the system. Investigating alternative neural architectures for representing 4D scenes could lead to improved efficiency and scalability. Exploring different methods for incorporating textual prompts might enable finer control over the generated animation’s style and characteristics. Furthermore, research could focus on developing more robust and efficient training procedures to reduce computational costs and improve the model’s generalization capabilities. Finally, integration with other tools and platforms within virtual and augmented reality environments would unlock new applications and extend the system’s impact.
More visual insights#
More on figures

🔼 Figure 2 illustrates the 3to4D method’s workflow for animating a 3D object using a text prompt. It begins by training a static 4D Neural Radiance Field (NeRF) from the input 3D object to capture its appearance consistently across time. Dynamics are then added using an image-to-video diffusion model and a novel incremental viewpoint selection protocol that gradually expands the sampling range of viewpoints. This enhances motion realism. The process also incorporates a masked Score Distillation Sampling (SDS) loss, leveraging attention maps to focus optimization on the object and prevent unwanted background effects. The model learns to generate animation based on the textual prompt while maintaining the object’s visual identity.
read the caption
Figure 2: Workflow of our 3to4D approach, designed to optimize a 4D radiance field using a neural representation that captures both static and dynamic elements. First, a 4D NeRF is trained to represent the static object (plant, left), having the same input structure at each time step. Then, we introduce dynamics to the 4D NeRF by distilling the prior from a pre-trained image-to-video model. At each SDS step, we select a viewpoint and render both the input object and the 4D NeRF from the same selected viewpoint. These renders, along with the textual prompts, are then fed into the image-to-video model, and the SDS loss is calculated to guide the generation of motion while preserving the object’s identity. The attention-masked SDS, focuses learning on the relevant parts of the object, improving identity preservation.

🔼 This figure showcases the capabilities of the 3to4D model to animate static 3D objects based on textual prompts. The left side displays the initial 3D object along with a descriptive text prompt outlining the desired action (e.g., a blooming plant, a turtle with its head in its shell). The right side presents a sequence of four frames from the resulting 4D animation (video). Each frame is further divided into an RGB image and a depth map in its top-right corner for better visual representation of the 3D scene. The 4D animation shows the object moving realistically based on the prompt.
read the caption
Figure 3: (click-to-view-online) 3to4D brings various objects to life. On the left, we display the input object along with a textual prompt describing the desired action. On the right, we present four frames from the generated object, viewed from the front. Each 3D frame is split into an RGB image and its corresponding depth map, shown in the top right corner.

🔼 Figure 4 presents a comparative analysis of the LPIPS scores achieved by 3to4D and various baseline methods across a comprehensive set of 3D objects. The LPIPS (Learned Perceptual Image Patch Similarity) score serves as a metric to assess the visual similarity between the generated 4D animation and the original 3D input object. The plot visually demonstrates the superior performance of the proposed 3to4D approach, consistently yielding lower LPIPS scores, indicating significantly better preservation of the input object’s identity throughout the generated animation. This enhanced visual fidelity highlights the effectiveness of 3to4D compared to existing text-to-4D generation techniques.
read the caption
Figure 4: Comparison between our method and baselines, across all objects tested. We consistently achieve better LPIPS scores across all objects.

🔼 Figure 5 presents a qualitative comparison of the proposed 3to4D method against three baseline methods (4D-fy, Animate124, and STAG3D) for generating 4D content from a 3D object. For each method, a rendered image of the input 3D object is displayed on the left, followed by the 4D content generated by each method. The figure highlights that while 3to4D successfully maintains the identity and visual features of the input 3D object, the baseline methods produce significantly different outputs, sometimes generating completely different objects. This visually demonstrates 3to4D’s superior ability in preserving object identity while adding dynamic motion compared to existing methods.
read the caption
Figure 5: Qualitative comparison with competing methods. A rendered image of the input object is shown on the left, alongside rendered images from our and other methods. While our method preserves the identity of the input object, all other baselines generate different objects. .
More on tables
| Agreement with input object | Agreement with prompt | Video quality | |
|---|---|---|---|
| LPIPS ↓ | CLIP-I ↑ | Style ↑ | |
| 3to4D (Ours) | 15.0 ± 0.1 | 90.2 ± .08 | 20.5 ± .01 |
| w/o image-to-video | 40.3 ± 0.2 | 76.6 ± 0.1 | 21.1 ± .07 |
| w/o viewpoint selector | 15.0 ± 0.2 | 89.6 ± 0.1 | 18.7 ± 0.1 |
| w/o masked-SDS | 15.8 ± 0.1 | 89.7 ± 0.1 | 18.9 ± 0.1 |
🔼 This ablation study analyzes the impact of each component in the 3to4D model on the overall performance. The table shows the quantitative results of experiments conducted by removing different parts of the method (removing the image-to-video component, removing the viewpoint selector, and removing the masked SDS) and compares the results to the complete 3to4D model. The evaluation metrics used, as described in Section 4.2, assess agreement with the input object, agreement with the prompt, and video quality, providing a comprehensive understanding of each component’s contribution.
read the caption
Table 2: Ablation study. Evaluating the contribution of various components of our method on objects and prompts in Sec. 4.1.
| Method | LPIPS ↓ | CLIP-I ↑ | Style ↑ | CLIP-T ↑ | Smoothness ↑ | LPIPS-F ↓ | CLIP-F ↑ | Dynamic Deg. ↑ |
|---|---|---|---|---|---|---|---|---|
| Uniform | 14.0 ± 0.6 | 90.1 ± 0.5 | 19.0 ± 0.6 | 27.0 ± 0.3 | 99.2 ± 0.02 | 2.1 ± 0.1 | 98.1 ± 0.6 | 52.1 ± 1.9 |
| Four-views | 14.0 ± 0.5 | 90.0 ± 0.4 | 19.3 ± 0.5 | 27.0 ± 0.3 | 99.2 ± 0.02 | 2.1 ± 0.1 | 98.2 ± 0.6 | 51.3 ± 1.5 |
| Sweep | 14.3 ± 0.6 | 90.0 ± 0.5 | 19.6 ± 0.5 | 27.0 ± 0.3 | 99.2 ± 0.02 | 2.2 ± 0.1 | 98.1 ± 0.6 | 53.6 ± 2.3 |
| Incremental (Ours) | 15.0 ± 0.7 | 90.0 ± 0.4 | 20.0 ± 0.5 | 27.3 ± 0.2 | 99.2 ± 0.03 | 2.6 ± 0.1 | 98.1 ± 0.6 | 59.4 ± 2.2 |
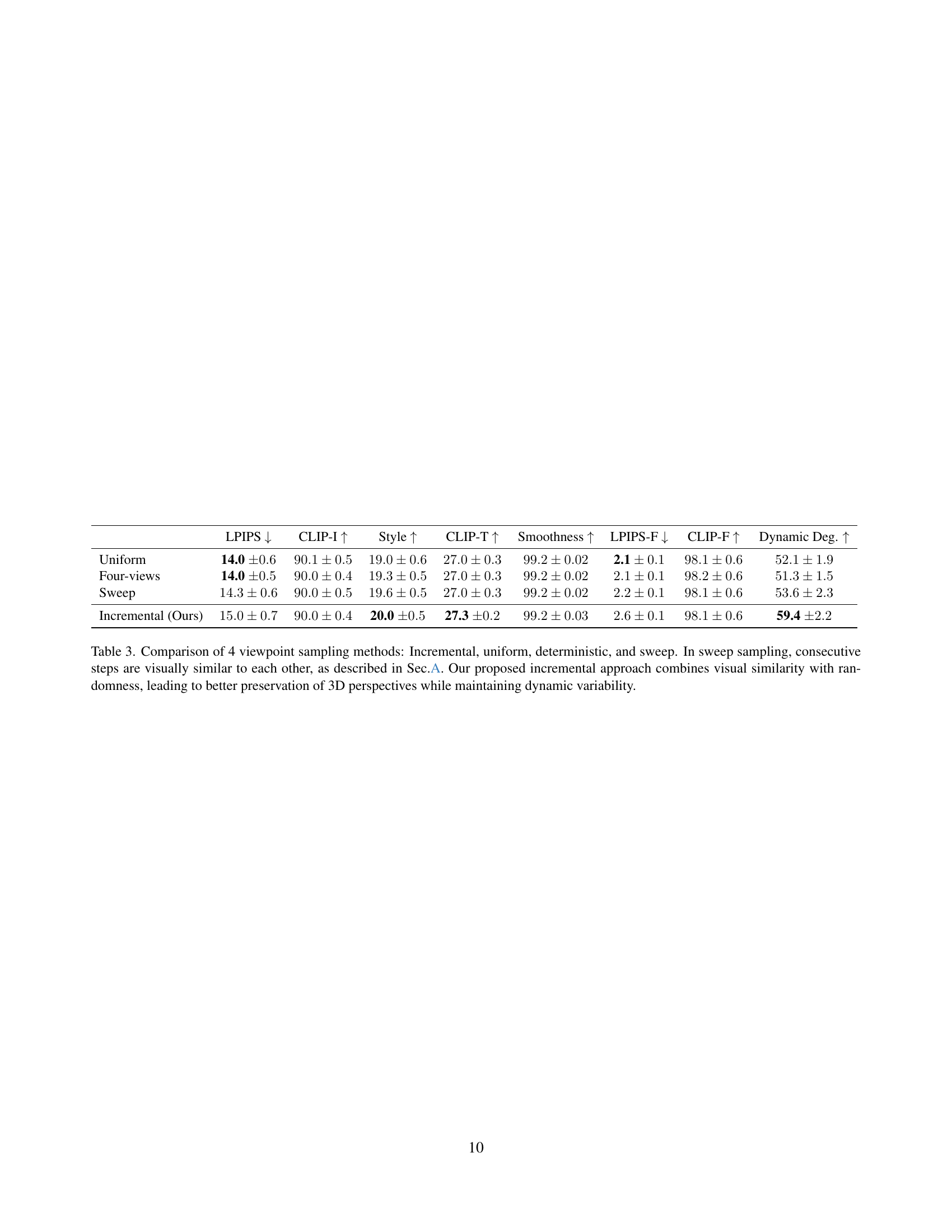
🔼 This table compares four different methods for sampling viewpoints during the generation of 4D animations from 3D models. The methods are: Incremental (the authors’ proposed method), Uniform (random sampling), Deterministic (a systematic sweep), and Sweep (a gradual expansion of the sampling range). The comparison focuses on the impact of the viewpoint sampling strategy on the quality of the generated animations. Key metrics include LPIPS (perceptual similarity), CLIP-I (image-text similarity), Style (textual coherence with visual features), Smoothness (motion continuity), LPIPS-F (frame-to-frame perceptual similarity), and Dynamic Degree (amount of motion). The results show that the Incremental method balances visual similarity with randomness, resulting in a better preservation of 3D object perspective across time while also achieving high dynamic variability compared to the other methods.
read the caption
Table 3: Comparison of 4 viewpoint sampling methods: Incremental, uniform, deterministic, and sweep. In sweep sampling, consecutive steps are visually similar to each other, as described in Sec.A. Our proposed incremental approach combines visual similarity with randomness, leading to better preservation of 3D perspectives while maintaining dynamic variability.
Full paper#