↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-audio (TTA) models struggle with controllability and aligning generated audio to user intent. Creating preference pairs for training is difficult due to the lack of structured mechanisms like those found in large language models (LLMs). Existing methods like using human annotators are expensive and inefficient.
This paper introduces TANGOFLUX, a novel TTA model that addresses these issues using a new framework called CLAP-Ranked Preference Optimization (CRPO). CRPO iteratively generates and refines preference data using the CLAP model, improving alignment. TANGOFLUX significantly outperforms existing models in terms of speed and audio quality, while also being trained on non-proprietary data. The code and models are open-sourced, making it a valuable contribution to the TTA research community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-audio generation due to its introduction of TANGOFLUX, a fast and high-quality model. The novel CRPO framework for data generation and alignment significantly advances the field, addressing existing limitations in preference data creation. The open-sourcing of code and models further accelerates research and facilitates broader adoption of efficient, high-quality TTA models. The work also highlights limitations of existing methods, opening avenues for future investigation into improved training strategies and preference optimization techniques.
Visual Insights#

🔼 The figure illustrates the training pipeline of the TangoFlux model. It consists of two main stages: pre-training and online iterative alignment. Pre-training involves training a base model using a large audio dataset and a language model (WavCaps and AudioCaps). Online iterative alignment refines the pre-trained model by utilizing the CLAP-Ranked Preference Optimization (CRPO) framework. CRPO involves iterative cycles of generating audio samples, ranking them using CLAP, and constructing preference pairs. This process is designed to improve the model’s alignment with textual descriptions, enhancing the quality and fidelity of generated audio. The figure shows the flow of data, prompts, and audio between different model components, highlighting the key steps in the training pipeline.
read the caption
Figure 1: A depiction of the overall training pipeline of TangoFlux.
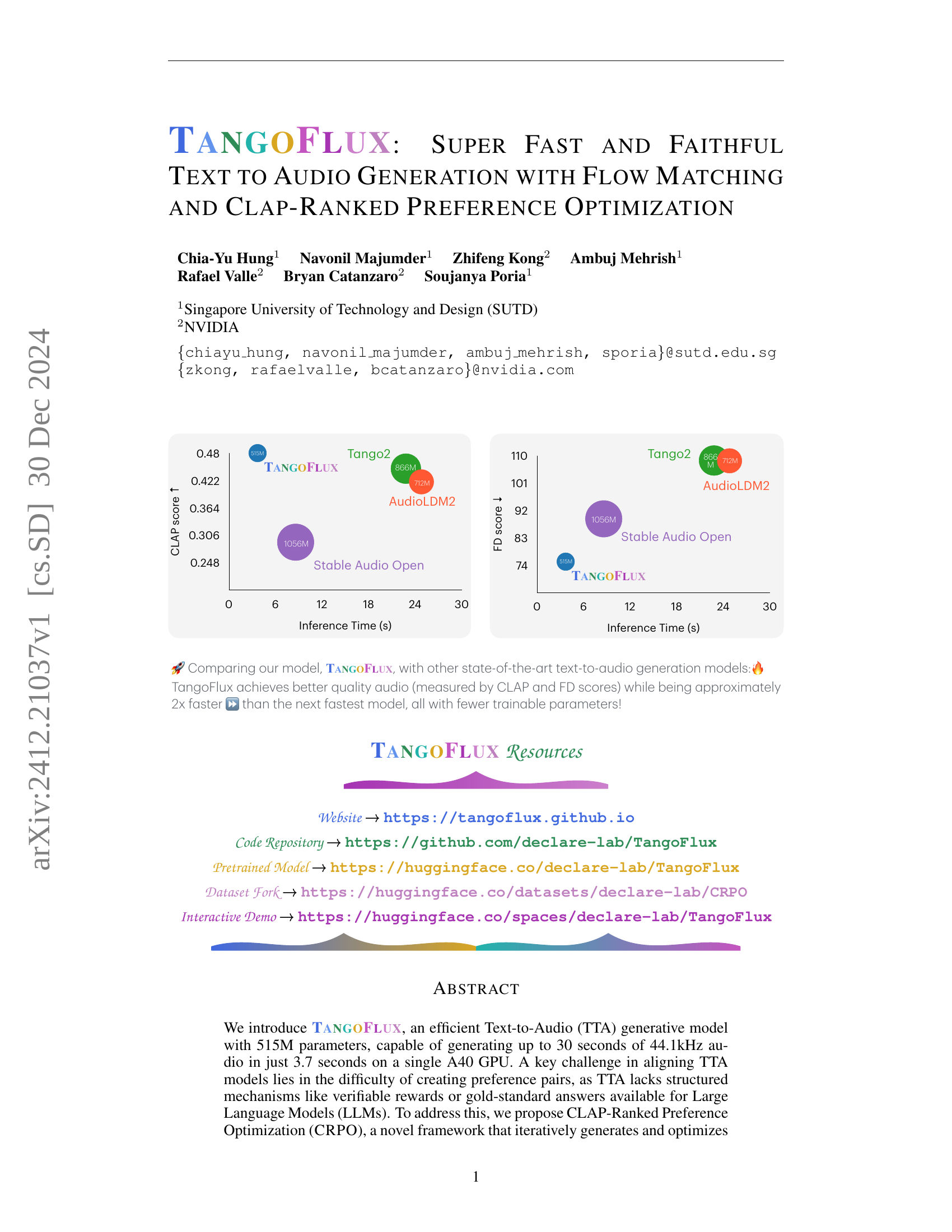
| Model | #Params. | Duration | Steps | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ | IS ↑ | Inference Time (s) |
|---|---|---|---|---|---|---|---|---|
| AudioLDM 2-large | 712M | 10 sec | 200 | 108.3 | 1.81 | 0.419 | 7.9 | 24.8 |
| Stable Audio Open | 1056M | 47 sec | 100 | 89.2 | 2.58 | 0.291 | 9.9 | 8.6 |
| Tango 2 | 866M | 10 sec | 200 | 108.4 | 1.11 | 0.447 | 9.0 | 22.8 |
| TangoFlux-base | 515M | 30 sec | 50 | 80.2 | 1.22 | 0.431 | 11.7 | 3.7 |
| TangoFlux-base | 515M | 30 sec | 50 | 75.1 | 1.15 | 0.480 | 12.2 | 3.7 |
🔼 Table 1 presents a comparison of several text-to-audio (TTA) generation models, evaluating their performance across various metrics. The models are compared based on their output audio length (duration), Frechet Distance (FD), Kullback-Leibler divergence (KL), CLAP score (measuring alignment between audio and text), and Inception Score (IS), a metric for image quality that is sometimes adapted for audio. All inference times were measured using the same A40 GPU for fair comparison. The number of trainable parameters in each model is also provided to give an indication of model complexity. This comprehensive comparison allows for a detailed analysis of the strengths and weaknesses of each model, providing insights for researchers and developers in the field of TTA.
read the caption
Table 1: Comparison of audio generation models across various metrics. Output length represents the duration of the generated audio. Metrics include FDopenl3openl3{}_{\text{openl3}}start_FLOATSUBSCRIPT openl3 end_FLOATSUBSCRIPT for Frechet Distance, KLpasstpasst{}_{\text{passt}}start_FLOATSUBSCRIPT passt end_FLOATSUBSCRIPT for KL divergence, and CLAPscorescore{}_{\text{score}}start_FLOATSUBSCRIPT score end_FLOATSUBSCRIPT for alignment. All inference time is computed on the same A40 GPU. We report the trainable parameters in the #Params column.
In-depth insights#
Fast TTA Generation#
Fast Text-to-Audio (TTA) generation is a crucial area of research, aiming to significantly reduce the inference time without compromising audio quality. Reducing latency is essential for real-time applications and interactive experiences. The speed improvements often come from architectural innovations, such as using efficient transformer blocks, or optimizing existing models with rectified flow matching. Smaller model sizes also contribute to faster generation times, but finding the right balance between model capacity and inference speed is critical. Methods like CLAP-Ranked Preference Optimization (CRPO) can further enhance speed by refining the preference dataset and thus the model’s learning process. However, the trade-off between speed and quality needs careful consideration. While fast generation is beneficial, it shouldn’t come at the cost of significantly degrading the audio quality or the model’s ability to accurately reflect the input text. Therefore, future research should focus on developing techniques that improve speed without sacrificing fidelity, enabling a smoother and more efficient TTA experience.
CRPO: Alignment#
The proposed CLAP-Ranked Preference Optimization (CRPO) method for text-to-audio (TTA) model alignment is a notable contribution addressing the challenge of establishing preference pairs in the absence of readily available gold standards or structured mechanisms, unlike in large language models (LLMs). CRPO cleverly leverages the CLAP model to establish audio preferences by creating ranked lists of generated audio samples based on their alignment to the input text prompt. This offers a computationally efficient and scalable alternative to manual annotation. The iterative nature of CRPO, generating preference pairs and optimizing rectified flows in cycles, promotes continuous improvement and prevents performance saturation seen in offline-only methods. This iterative alignment process is key to enhancing the alignment between generated audio and user intent, making the generated audio more faithful to the input prompt. The framework’s reliance on open-source data and publicly available models makes CRPO highly reproducible, facilitating further research and development in the area of TTA alignment. The effectiveness of CRPO is empirically validated by comparison with existing approaches, demonstrating its superiority in generating higher quality and more relevant audio.
Rectified Flow#
The concept of “Rectified Flow” presents a novel approach to training generative models, particularly relevant in the context of audio generation. It offers a robust alternative to traditional diffusion models, which are often sensitive to noise scheduler choices. The core idea is to learn a vector field that maps samples from a simple prior distribution (e.g., Gaussian) to a complex target distribution, but instead of following a complex path, it utilizes a straight line trajectory from noise to the target distribution. This “rectified” path offers increased stability and efficiency, making it less sensitive to hyperparameter tuning and potentially resulting in faster training times and improved sample quality. This approach likely reduces the computational cost associated with many denoising steps often required in diffusion models, ultimately making the generation of audio more efficient. The choice of rectified flows also presents a simpler approach that is more amenable to optimization strategies, such as preference optimization, further enhancing the quality and alignment of generated audio.
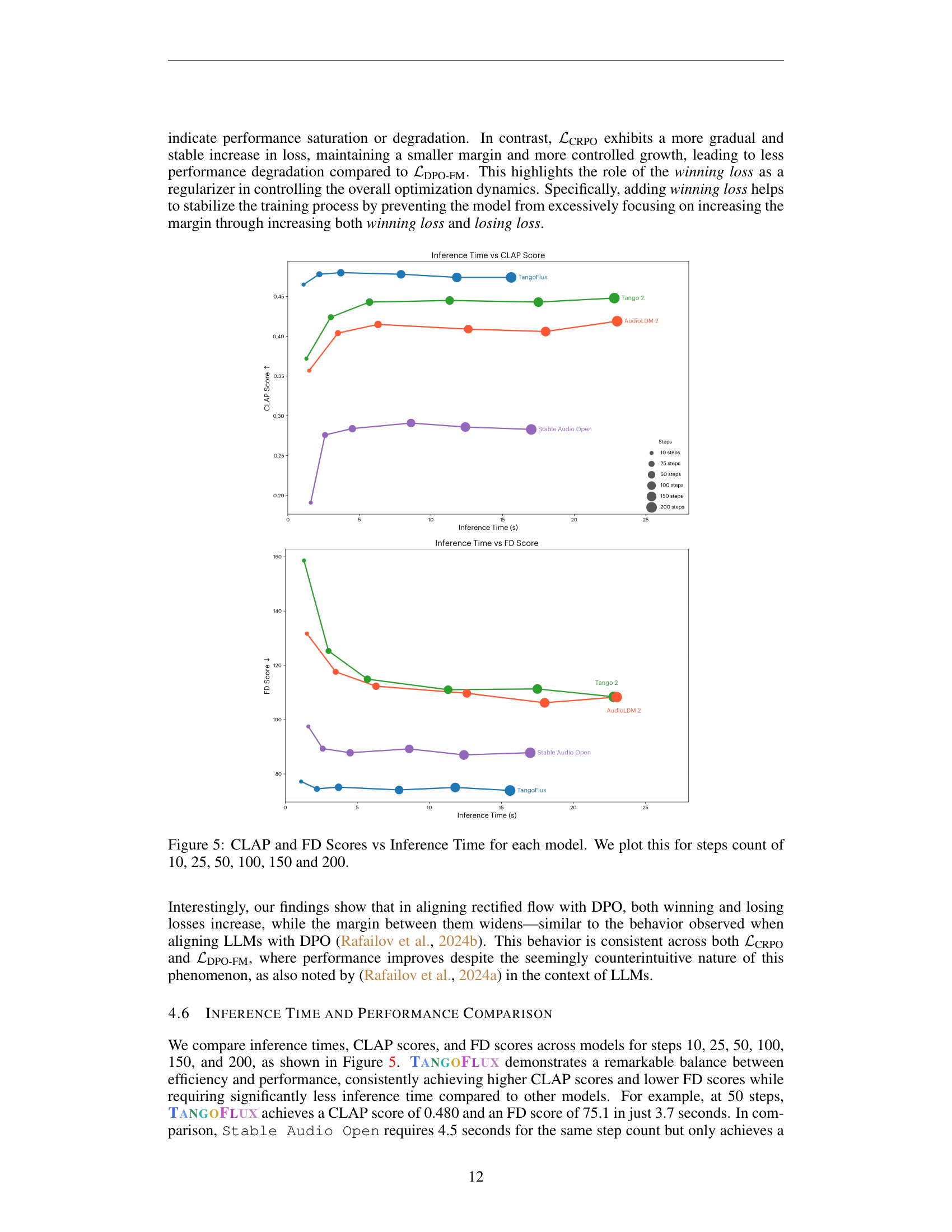
Benchmark Results#
A dedicated ‘Benchmark Results’ section would be crucial for evaluating TANGOFLUX. It should present quantitative comparisons against existing state-of-the-art models using established metrics like CLAP, Frechet Distance (FD), and Inception Score (IS). Crucially, the benchmarks should incorporate a diverse range of audio prompts, including simple and complex descriptions, to thoroughly assess the model’s capabilities. The results should highlight TANGOFLUX’s performance advantages (e.g., higher CLAP scores indicating better alignment, lower FD suggesting improved audio quality, etc.) and should showcase its efficiency gains (faster inference times, smaller model size). Subjective evaluations are also necessary, gathering human feedback on audio quality and relevance, potentially using a multi-faceted scoring system. Visualizations such as graphs or tables are highly recommended to effectively convey these results, enhancing readability and emphasizing key findings.
Future of TTA#
The future of Text-to-Audio (TTA) generation is incredibly promising, driven by ongoing advancements in deep learning and related fields. High-fidelity audio generation will likely become even more realistic and nuanced, potentially indistinguishable from human recordings. This will involve continued refinements in model architectures, training techniques (such as improved preference optimization methods), and the incorporation of more diverse and extensive datasets. We can also anticipate increased controllability and customization options, allowing users to fine-tune parameters like voice tone, emotion, and speaking style to produce highly tailored audio. Real-time, or near real-time, generation is another key area of development, bringing TTA into the realm of interactive applications. The ongoing challenge is to achieve this performance with reduced computational costs, thereby making it more accessible and efficient. Finally, the integration of TTA with other technologies, such as natural language processing and virtual/augmented reality, will unlock new creative and practical applications, ranging from immersive storytelling experiences to personalized learning tools.
More visual insights#
More on figures

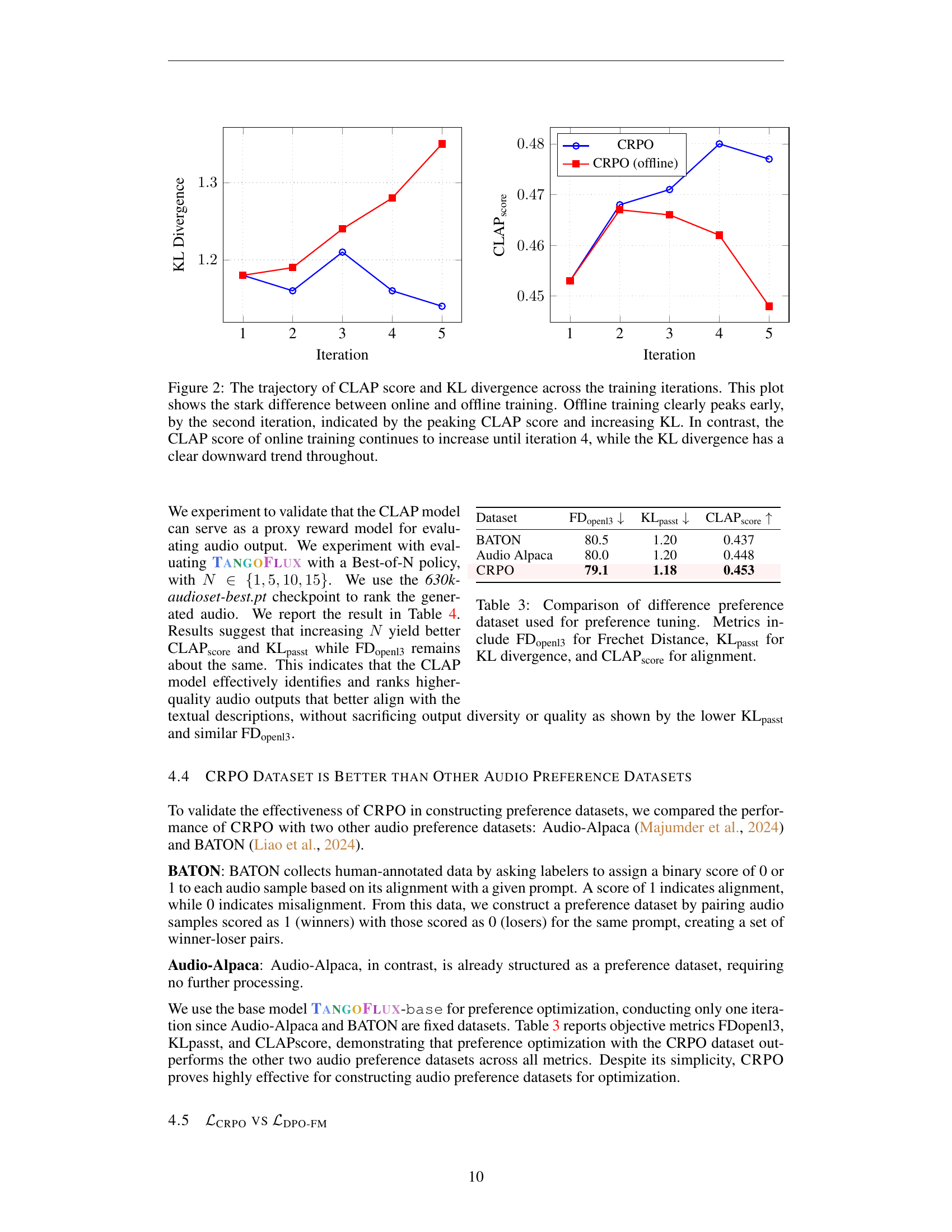
🔼 Figure 2 illustrates the performance of two training methods (online and offline) for a text-to-audio model across multiple iterations. The y-axis shows the CLAP score (a measure of audio quality and relevance to the input text) and KL divergence (a measure of the difference between the generated audio distribution and the target distribution). The x-axis represents the training iteration. The offline training method demonstrates rapid initial improvement, peaking around the second iteration, but then shows diminishing returns with a subsequent decline in CLAP score and an increase in KL divergence. In contrast, the online training method exhibits sustained improvement, with the CLAP score increasing steadily until the fourth iteration and a simultaneous decrease in KL divergence, suggesting a more stable and effective training process.
read the caption
Figure 2: The trajectory of CLAP score and KL divergence across the training iterations. This plot shows the stark difference between online and offline training. Offline training clearly peaks early, by the second iteration, indicated by the peaking CLAP score and increasing KL. In contrast, the CLAP score of online training continues to increase until iteration 4, while the KL divergence has a clear downward trend throughout.

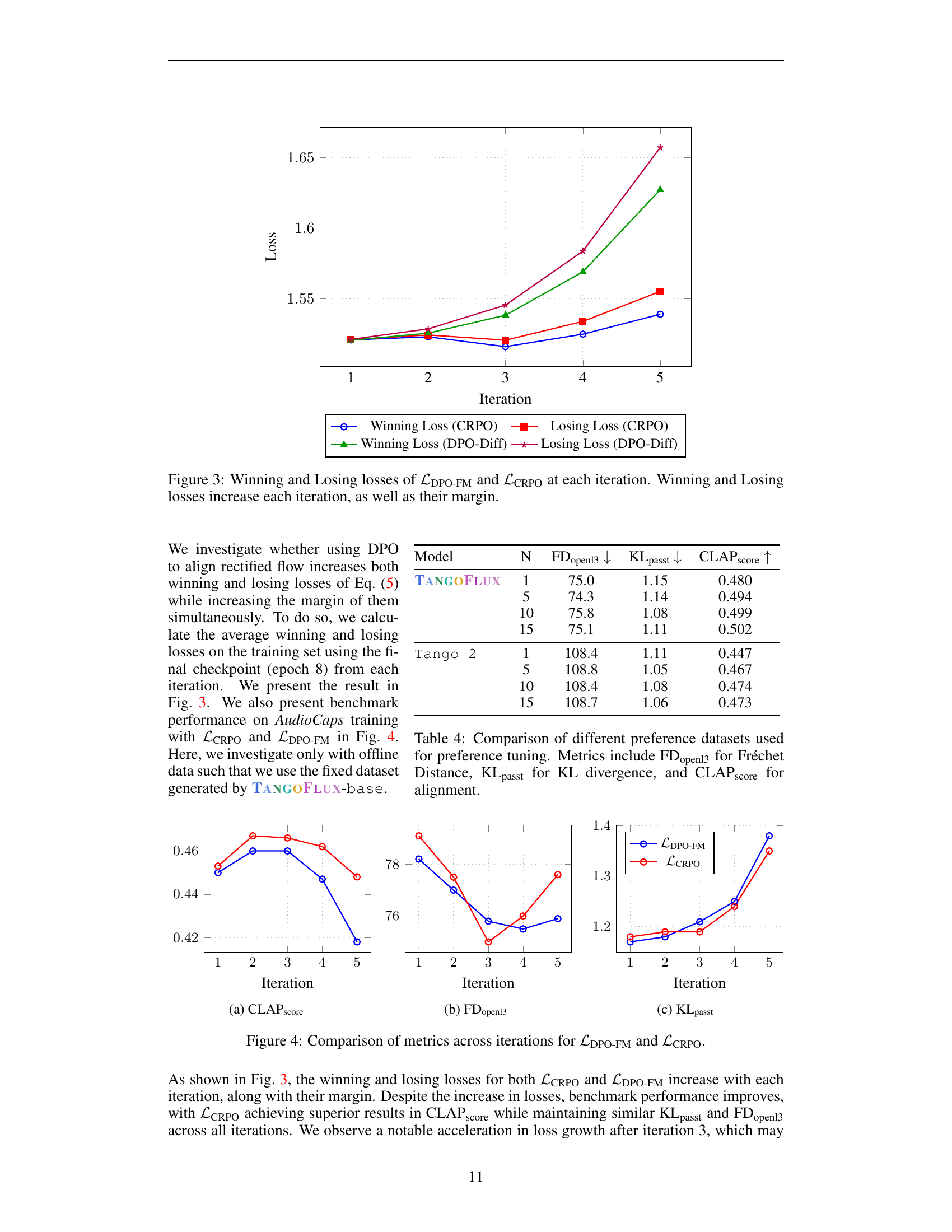
🔼 Figure 3 illustrates the training dynamics of two different loss functions: ℒDPO-FM and ℒCRPO, used for preference optimization in a text-to-audio model. The plot shows how the ‘winning’ and ’losing’ losses (representing the difference in model preference between better and worse audio samples) change over five iterations of training. Notably, both the winning and losing losses increase in magnitude with each training iteration. Importantly, the difference between the winning and losing losses (their margin) also increases, suggesting successful preference alignment with each iteration. This visualization underscores the iterative nature of the proposed preference optimization process and how the chosen loss function affects the training dynamics, leading to improved audio quality.
read the caption
Figure 3: Winning and Losing losses of ℒDPO-FMsubscriptℒDPO-FM\mathcal{L}_{\text{DPO-FM}}caligraphic_L start_POSTSUBSCRIPT DPO-FM end_POSTSUBSCRIPT and ℒCRPOsubscriptℒCRPO\mathcal{L}_{\text{CRPO}}caligraphic_L start_POSTSUBSCRIPT CRPO end_POSTSUBSCRIPT at each iteration. Winning and Losing losses increase each iteration, as well as their margin.

🔼 The figure shows the trajectory of CLAP score and KL divergence across training iterations. The CLAP score is a metric measuring the alignment between generated audio and text descriptions. KL divergence measures the difference between the generated audio distribution and the target distribution. The plot illustrates the performance of two training methods: online CRPO (with new data generated each iteration) and offline CRPO (using the same data repeatedly). The online CRPO shows a steady increase in CLAP scores and a decrease in KL divergence across iterations, indicating improved performance and better alignment. The offline CRPO, in contrast, shows early peaking of the CLAP score and an increase in KL divergence, demonstrating performance saturation and degradation after a few iterations. This highlights the importance of online data generation in the CRPO framework for consistently improving TTA model alignment.
read the caption
(a) CLAPscorescore{}_{\text{score}}start_FLOATSUBSCRIPT score end_FLOATSUBSCRIPT

🔼 Figure 2 shows the trends of two key metrics, the KL divergence and CLAP score, across five iterations of the CLAP-Ranked Preference Optimization (CRPO) process. The blue line represents the CRPO approach with online data generation at each iteration, whereas the red line represents CRPO without online data generation. The KL divergence is a measure of the difference between the generated audio distribution and the true audio distribution, while the CLAP score measures the alignment between the generated audio and text descriptions. As the iterations proceed, the online CRPO consistently exhibits a decreasing KL divergence, signifying improved alignment with the true distribution, while the CLAP score steadily increases, indicating better adherence to the provided textual prompts. In contrast, the offline CRPO approach demonstrates a more erratic behavior, showing early improvement followed by degradation in both metrics after the second iteration. This highlights the importance of incorporating online data generation in CRPO to prevent performance saturation and ensure consistent progress.
read the caption
(b) FDopenl3openl3{}_{\text{openl3}}start_FLOATSUBSCRIPT openl3 end_FLOATSUBSCRIPT
More on tables
| Inference | Time (s) |
|---|
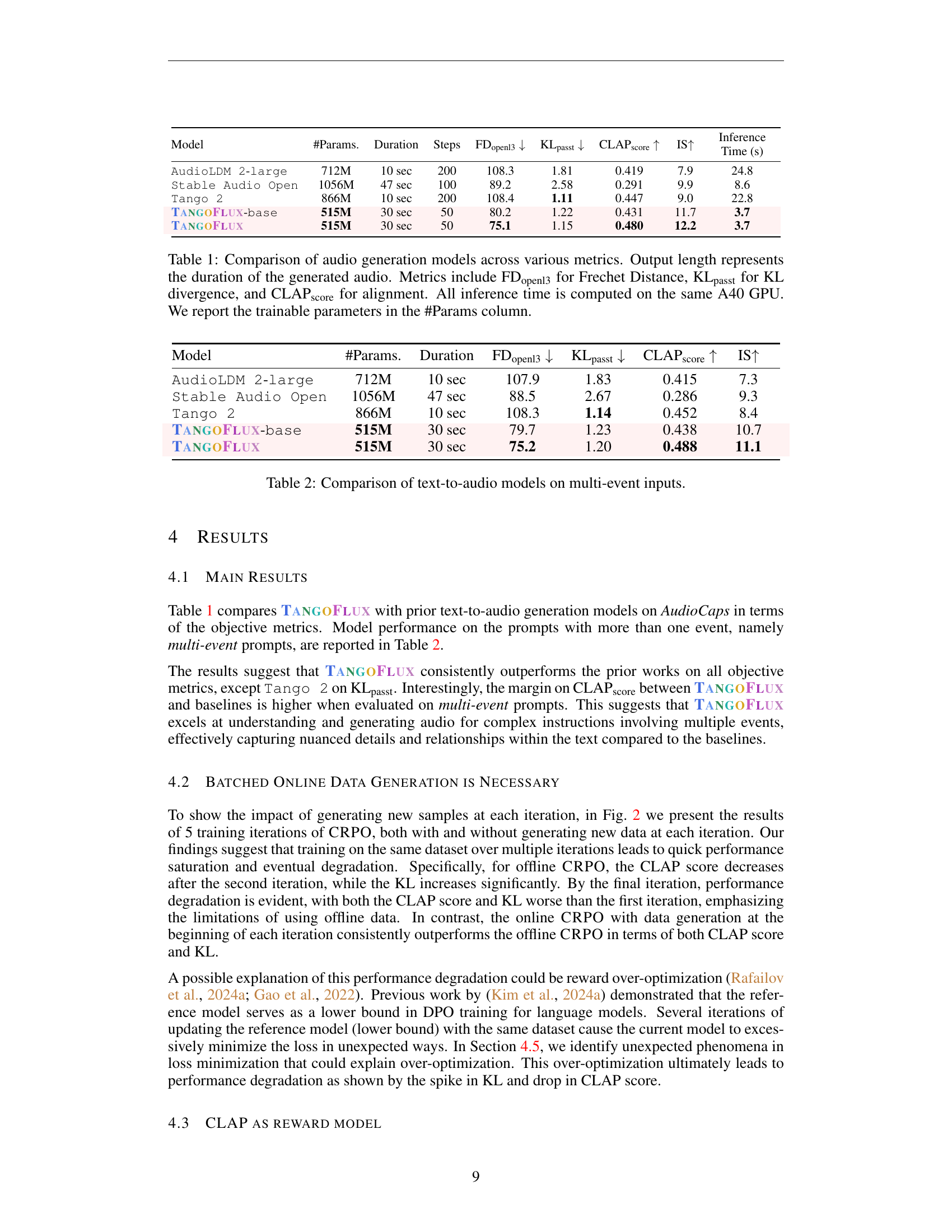
🔼 This table presents a comparison of various text-to-audio models’ performance on audio clips containing multiple events. The models compared are AudioLDM 2-large, Stable Audio Open, Tango 2, TANGOFLUX-base, and TANGOFLUX. For each model, the table lists the number of parameters, the duration of the generated audio, the Fréchet distance (FDopenl3), Kullback-Leibler divergence (KLpasst), CLAP score, and Inception Score (IS). Lower FDopenl3 and KLpasst scores, and higher CLAP and IS scores indicate better performance. This allows for a direct comparison of how well each model handles complex audio scenarios with multiple events.
read the caption
Table 2: Comparison of text-to-audio models on multi-event inputs.
| Model | #Params. | Duration | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ | IS ↑ |
|---|---|---|---|---|---|---|
| AudioLDM 2-large | 712M | 10 sec | 107.9 | 1.83 | 0.415 | 7.3 |
| Stable Audio Open | 1056M | 47 sec | 88.5 | 2.67 | 0.286 | 9.3 |
| Tango 2 | 866M | 10 sec | 108.3 | 1.14 | 0.452 | 8.4 |
| TangoFlux-base | 515M | 30 sec | 79.7 | 1.23 | 0.438 | 10.7 |
| TangoFlux | 515M | 30 sec | 75.2 | 1.20 | 0.488 | 11.1 |
🔼 This table compares the performance of three different preference datasets used to fine-tune a text-to-audio model. The datasets are BATON, Audio-Alpaca, and the novel CRPO dataset proposed in this paper. The comparison is based on three metrics: FDopenl3 (Fréchet distance for measuring the similarity of audio distributions), KLpasst (Kullback-Leibler divergence to quantify the difference between generated and reference audio label distributions), and CLAP score (measuring the alignment of generated audio with text descriptions). Lower FDopenl3 and KLpasst scores and a higher CLAP score indicate better performance. The results show how the choice of preference dataset affects the model’s ability to generate audio that is both high quality and semantically aligned with the input text.
read the caption
Table 3: Comparison of difference preference dataset used for preference tuning. Metrics include FDopenl3openl3{}_{\text{openl3}}start_FLOATSUBSCRIPT openl3 end_FLOATSUBSCRIPT for Frechet Distance, KLpasstpasst{}_{\text{passt}}start_FLOATSUBSCRIPT passt end_FLOATSUBSCRIPT for KL divergence, and CLAPscorescore{}_{\text{score}}start_FLOATSUBSCRIPT score end_FLOATSUBSCRIPT for alignment.
| Dataset | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ |
|---|---|---|---|
| BATON | 80.5 | 1.20 | 0.437 |
| Audio Alpaca | 80.0 | 1.20 | 0.448 |
| CRPO | 79.1 | 1.18 | 0.453 |
🔼 This table presents a comparison of different preference datasets used in the preference tuning process of the TANGOFLUX model. The effectiveness of each dataset is evaluated using three metrics: FDopenl3, a measure of Fréchet distance reflecting the overall similarity between the generated audio and a reference dataset; KLpasst, the Kullback-Leibler divergence indicating how closely the generated audio’s probability distribution matches that of the reference data; and CLAP score, an alignment metric assessing how well the generated audio aligns with its corresponding text prompt. The table facilitates the comparison and allows determining which preference dataset leads to the best model performance in terms of audio quality and alignment with textual input.
read the caption
Table 4: Comparison of different preference datasets used for preference tuning. Metrics include FDopenl3openl3{}_{\text{openl3}}start_FLOATSUBSCRIPT openl3 end_FLOATSUBSCRIPT for Fréchet Distance, KLpasstpasst{}_{\text{passt}}start_FLOATSUBSCRIPT passt end_FLOATSUBSCRIPT for KL divergence, and CLAPscorescore{}_{\text{score}}start_FLOATSUBSCRIPT score end_FLOATSUBSCRIPT for alignment.
| Model | N | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ |
|---|---|---|---|---|
| TangoFlux | 1 | 75.0 | 1.15 | 0.480 |
| 5 | 74.3 | 1.14 | 0.494 | |
| 10 | 75.8 | 1.08 | 0.499 | |
| 15 | 75.1 | 1.11 | 0.502 | |
Tango 2 | 1 | 108.4 | 1.11 | 0.447 |
| 5 | 108.8 | 1.05 | 0.467 | |
| 10 | 108.4 | 1.08 | 0.474 | |
| 15 | 108.7 | 1.06 | 0.473 |
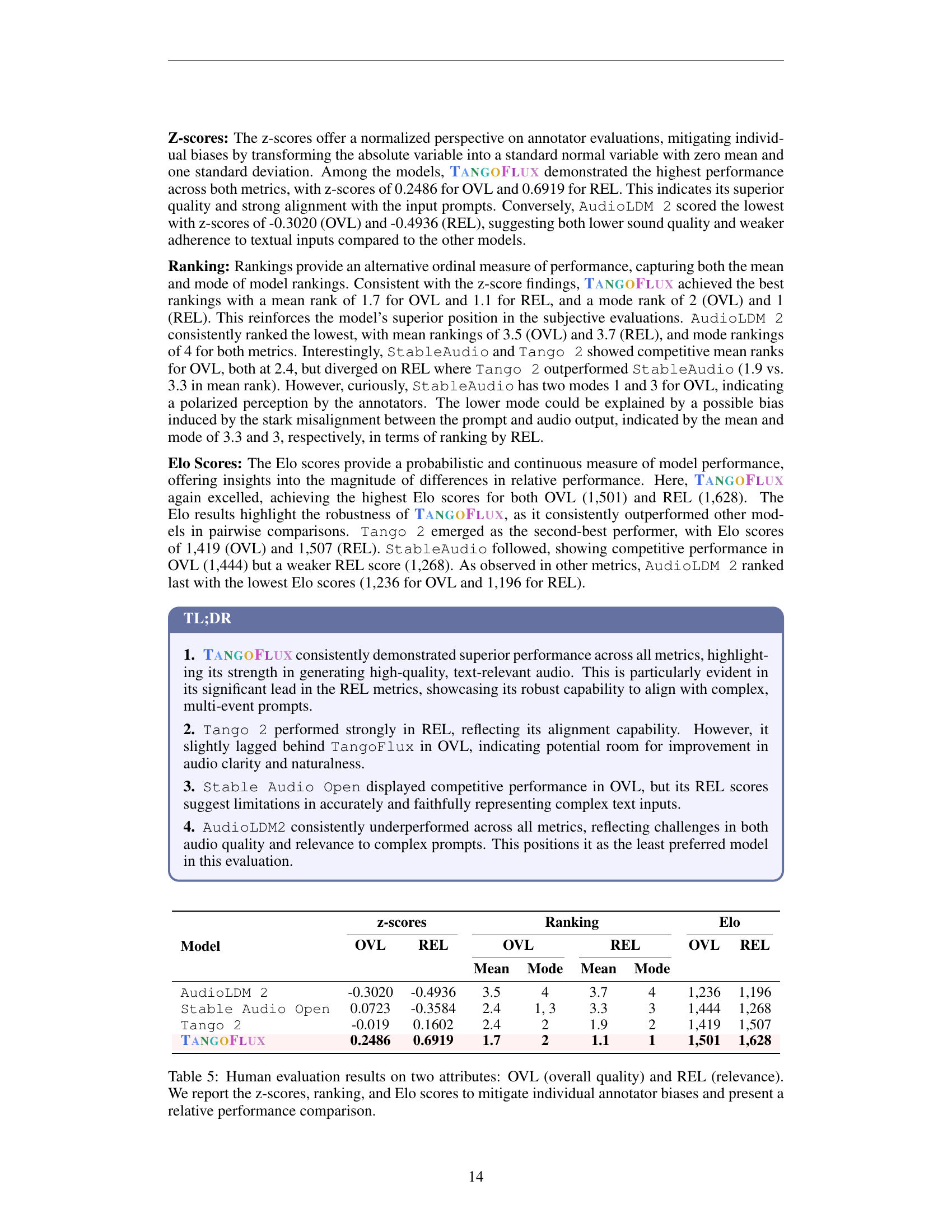
🔼 Table 5 presents the results of a human evaluation assessing two key aspects of audio generated by different models: Overall audio quality (OVL) and Relevance to the text prompt (REL). To account for potential bias from individual assessors, the data is processed in three ways. First, z-scores normalize the ratings, centering them around the average score for each annotator and scaling by their score spread. Next, the models are ranked based on both the average (mean) and most frequent (mode) ranks. Finally, Elo scores, using a pairwise comparison method, provide a continuous measure of each model’s relative strength compared to others. The table displays these three metrics (z-scores, rankings, and Elo scores) for each model and attribute (OVL and REL). This multi-faceted approach allows for a comprehensive and robust comparison of the models, minimizing the effect of individual assessor bias and providing a nuanced understanding of the relative performance of each.
read the caption
Table 5: Human evaluation results on two attributes: OVL (overall quality) and REL (relevance). We report the z-scores, ranking, and Elo scores to mitigate individual annotator biases and present a relative performance comparison.
| Model | z-scores | Ranking | Elo | |
|---|---|---|---|---|
| OVL | REL | OVL | REL | |
| AudioLDM 2 | -0.3020 | -0.4936 | 3.5 | 4 |
| Stable Audio Open | 0.0723 | -0.3584 | 2.4 | 1, 3 |
| Tango 2 | -0.019 | 0.1602 | 2.4 | 2 |
| TangoFlux | 0.2486 | 0.6919 | 1.7 | 2 |
🔼 This table presents the results of experiments conducted on the TANGOFLUX model using different classifier-free guidance (CFG) values. The experiments aimed to analyze the impact of CFG on the model’s performance, specifically focusing on the trade-off between audio fidelity (measured by FDopenl3) and semantic alignment (measured by CLAP score). The table shows that varying the CFG scale affects both metrics, indicating an optimal CFG value that balances these two aspects. Lower CFG values generally improve semantic alignment but may compromise audio quality, while higher values can improve audio quality at the cost of reduced semantic accuracy.
read the caption
Table 6: TangoFlux with different classifier free guidance (CFG) values.
| Model | Steps | CFG | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ |
|---|---|---|---|---|---|
| TangoFlux | 50 | 3.0 | 77.7 | 1.14 | 0.479 |
| 50 | 3.5 | 76.1 | 1.14 | 0.481 | |
| 50 | 4.0 | 74.9 | 1.15 | 0.476 | |
| 50 | 4.5 | 75.1 | 1.15 | 0.480 | |
| 50 | 5.0 | 74.6 | 1.15 | 0.472 |
🔼 Table 7 provides a detailed list of the 50 prompts used in the human evaluation section of the paper. For each prompt, it indicates whether the prompt contains multiple distinct audio events and whether the temporal order of those events matters for accurate audio generation. This table is crucial for understanding the complexity and diversity of the prompts used to assess the models’ abilities, especially in handling scenarios with multiple events.
read the caption
Table 7: Prompts used in human evaluation and their characteristics.
Full paper#