↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for aligning visual generation models with human preferences face challenges. Reward models are often biased and lack interpretability, while video quality assessment remains difficult. Existing RLHF methods can lead to over-optimization or under-optimization of certain factors.
The researchers introduce VisionReward, a novel fine-grained and multi-dimensional reward model that effectively addresses these challenges. It decomposes human preferences into multiple dimensions using a series of judgment questions, providing an interpretable and accurate preference score. VisionReward significantly outperforms existing methods on both image and video datasets. The researchers also introduce a new multi-objective optimization algorithm for improved model stability and avoiding over-optimization. The code and datasets are publicly available.
Key Takeaways#
Why does it matter?#
This paper is crucial because it directly addresses the limitations of current reward models in visual generation, offering a novel approach to aligning models with human preferences. This is highly relevant to the current trends in RLHF and will likely influence future research in multi-objective preference learning and video quality assessment. The dataset and code are publicly available, encouraging broader participation and accelerating progress in the field.
Visual Insights#

🔼 Figure 1 presents examples illustrating VisionReward and the Multi-Objective Preference Optimization (MPO) algorithm. Panel (a) shows a text-to-image generation task where VisionReward assigns a higher score than ImageReward, demonstrating its ability to better capture human preferences. Panel (b) similarly demonstrates VisionReward’s superior performance in a text-to-video generation task compared to VideoScore. Panels (c) and (d) show comparative results of text-to-image and text-to-video optimization, respectively. They show the original generated outputs and how those outputs are improved using different optimization methods, including DPO with different scoring methods and MPO with VisionReward. The results highlight MPO with VisionReward’s effectiveness in optimizing visual generation, leading to superior output quality according to human assessment.
read the caption
Figure 1: Samples of VisionReward and Multi-Objective Preference Optimization (MPO) algorithm.
| Dimension | #Sub-dimension | #Checklist | ||
|---|---|---|---|---|
| Dimension | #Sub-dimension | #Checklist | ||
| Image | Video | Image | Video | |
| Alignment | 1 | 1 | 1 | 4 |
| Composition | 5 | 1 | 13 | 2 |
| Quality | 5 | 4 | 14 | 14 |
| Fidelity | 5 | 3 | 25 | 9 |
| Safety&Emotion | 2 | 1 | 8 | 4 |
| Stability | - | 5 | - | 12 |
| Dynamic | - | 2 | - | 8 |
| Physics | - | 1 | - | 4 |
| Preservation | - | 2 | - | 7 |
| Total | 18 | 20 | 61 | 64 |
🔼 This table presents the taxonomy of annotations used in the VisionReward model. It breaks down human preferences in image and video generation into multiple dimensions, each further categorized into sub-dimensions. For each sub-dimension, there’s a corresponding number of checklist questions, which are multiple-choice questions designed to elicit fine-grained human judgment. The table shows that image generation is broken down into 5 dimensions and 18 sub-dimensions and video generation is broken down into 9 dimensions and 64 sub-dimensions. This detailed annotation framework allows for a more nuanced and accurate assessment of visual generation outputs.
read the caption
Table 1: Taxonomy of annotation for VisionReward.
In-depth insights#
Multi-Reward Learning#
Multi-reward learning, in the context of visual generation models, presents a powerful strategy to overcome limitations of single-reward approaches. By incorporating multiple reward signals, each capturing a different aspect of human preferences (e.g., visual fidelity, aesthetics, safety), the method facilitates a more holistic and nuanced evaluation of generated outputs. This addresses the problem of confounding factors inherent in single reward scenarios where optimizing for one aspect may negatively affect another. The interpretability of multi-reward models is also improved because the individual contributions of each reward signal become explicit, enabling a more fine-grained understanding of model strengths and weaknesses. However, designing an effective multi-reward system requires careful consideration of reward weighting and potential conflicts between rewards. Careful selection and weighting of rewards become crucial to balance various factors in a way that aligns well with human preferences. Furthermore, the optimization process needs to be robust enough to handle multiple objectives simultaneously, avoiding over-optimization or suboptimal results in specific dimensions. The success of multi-reward learning hinges on the ability to disentangle the individual rewards and to develop optimization techniques that lead to a harmonious balance across all aspects of visual generation quality.
Video Quality Metrics#
Developing effective video quality metrics is crucial for evaluating video generation models. Existing metrics often fall short, failing to capture the nuances of human perception, particularly in dynamic content. A key challenge lies in assessing temporal aspects of video quality, such as motion smoothness and realism. Traditional image-based metrics are insufficient as they don’t account for temporal coherence or dynamic visual features. Therefore, new metrics must be designed that specifically address the temporal dimension of video, going beyond simple frame-by-frame analysis to incorporate motion characteristics and visual consistency across frames. Multi-dimensional approaches are promising, considering aspects like clarity, realism, and aesthetic appeal separately, instead of relying on a single, potentially biased score. Furthermore, close collaboration with human perception studies is essential for establishing truly effective video quality metrics that align with human judgment. This would validate proposed metrics against actual viewer preferences and identify weaknesses in capturing subtle but important qualities of visual experience.
MPO Optimization#
The core of the proposed methodology lies in its multi-objective preference optimization (MPO) strategy. Unlike traditional single-objective approaches, MPO directly addresses the inherent trade-offs within human preferences, aiming to avoid over-optimization of certain aspects at the expense of others. This is achieved by formulating an objective function that considers multiple dimensions of visual quality simultaneously. The innovative aspect is disentangling these intertwined dimensions during training, ensuring balanced improvements across all criteria, rather than favoring one dimension excessively. This approach is crucial because human preferences in visual generation are rarely unidimensional. MPO effectively tackles the bias and lack of interpretability present in many existing reward models by employing a fine-grained reward system that’s capable of separating and prioritizing different aspects of quality. The algorithm’s structure, which is designed to ensure the optimization process does not weaken any dimension, appears to significantly enhance the stability and overall quality of the visual generation outcomes when compared with other methods. The results suggest that MPO provides a more robust and nuanced solution for aligning visual generative models with human preferences.
Human Preference#
The concept of ‘Human Preference’ is central to this research, driving the development of VisionReward, a novel reward model designed to align image and video generation models with human aesthetic sensibilities. The authors critique existing reward models for being biased and lacking interpretability, highlighting the difficulty of evaluating video quality compared to images. They address this challenge by introducing a fine-grained, multi-dimensional reward model, decomposing human preferences into interpretable dimensions assessed through a series of judgment questions. VisionReward’s strength lies in its ability to surpass existing methods in video preference prediction, demonstrating its effectiveness in handling the dynamic aspects of video content. The integration of this fine-grained reward model with a multi-objective preference optimization algorithm further mitigates the over-optimization issues common in reinforcement learning-based approaches. The overall aim is to create more human-aligned, high-quality image and video generation models, acknowledging the nuanced and multifaceted nature of human visual appreciation.
Future of RLHF#
The future of Reinforcement Learning from Human Feedback (RLHF) hinges on addressing its current limitations. Bias in reward models, stemming from inherent biases in human preferences, needs mitigation through more sophisticated reward model design and data collection methods. This might involve incorporating diverse demographics and perspectives, and possibly moving beyond simple preference ranking to richer feedback mechanisms like detailed explanations or comparative analysis. Improving evaluation metrics for generated content is crucial; current methods often fail to fully capture the nuanced aspects of human preference. More sophisticated metrics, potentially incorporating elements of human perceptual models, are required. Furthermore, scaling RLHF to complex tasks and modalities, such as long-form video generation, presents a significant challenge. Efficient training methods and scalable reward model architectures are essential for future development. Finally, research into alignment between model behavior and human values remains a key area for future investigation. Techniques focusing on interpretability and explainability, as well as robust safety mechanisms, are vital to ensure that RLHF-trained models are both effective and ethically sound.
More visual insights#
More on figures

🔼 This figure illustrates the VisionReward system and its Multi-Objective Preference Optimization (MPO) algorithm. The VisionReward model first uses a checklist of fine-grained questions to obtain binary judgments (yes/no) from humans regarding specific aspects of image or video quality. These judgments are then linearly weighted and combined to produce a single interpretable preference score. The MPO algorithm leverages this fine-grained reward model to address the challenge of balancing multiple, sometimes conflicting, aspects of preference during the training of visual generation models, avoiding over- or under-optimization of specific attributes. The figure displays the flow of information and the different stages of the process, from initial annotation to the final analysis of preferences after model optimization.
read the caption
Figure 2: An overview of the VisionReward and Multi-Objective Preference Optimization (MPO).
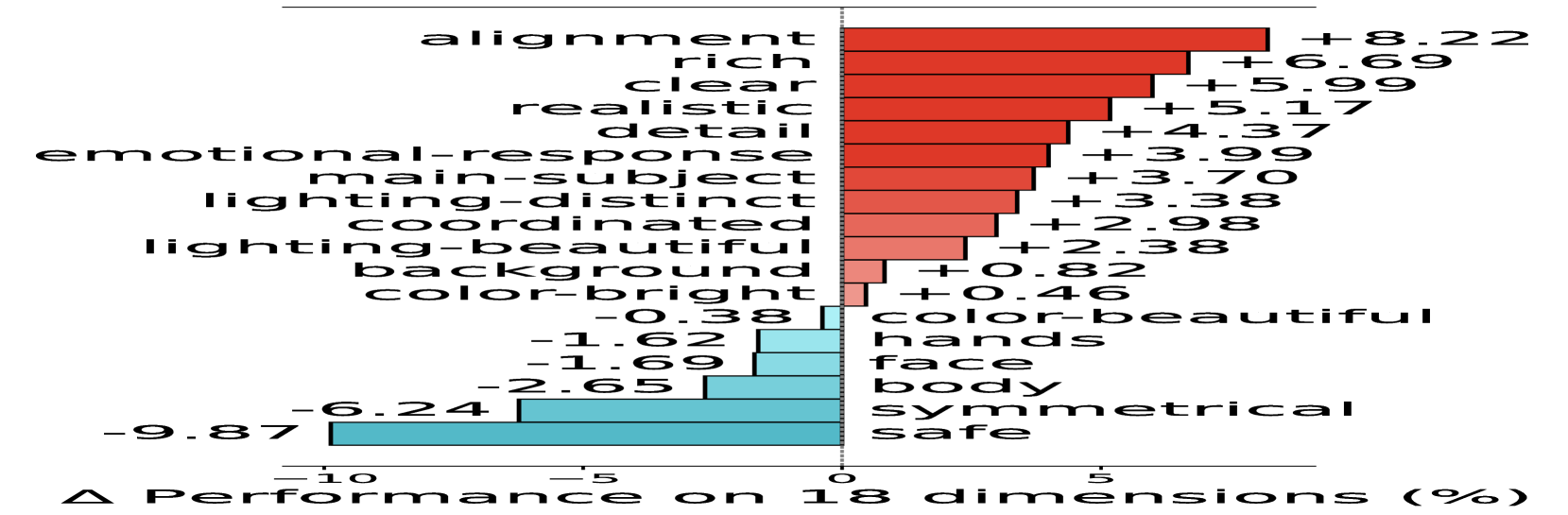
🔼 The bar chart visualizes the performance deviations across 18 sub-dimensions from the Pick-a-Pic dataset. The x-axis represents the 18 dimensions, and the y-axis represents the percentage deviation from the average yes-proportion for each dimension. Positive values indicate that the dimension is more emphasized than average, while negative values show the opposite. This visualization provides insights into which dimensions are prioritized by human preference when evaluating images.
read the caption
(a) Data analysis.

🔼 This figure compares score deviations across 18 sub-dimensions for images generated by SDXL before and after Diffusion-DPO fine-tuning, using 10,000 human preference pairs from the Pick-a-Pic dataset. It visually represents how the optimization process of Diffusion-DPO affects different aspects of image quality, showing both improvements and decrements in various dimensions.
read the caption
(b) DPO analysis.

🔼 Figure 3 illustrates the analysis of human preferences and the effects of preference learning on image generation. Panel (a) shows the distribution of scores across 18 sub-dimensions of image quality, each represented by the average ‘yes’ responses to binary checklist questions in the Pick-a-Pic dataset. This visualization reveals the relative importance of each sub-dimension in human perception. Panel (b) compares score deviations across the same 18 sub-dimensions for images generated by SDXL before and after fine-tuning using the Diffusion-DPO method. This comparison highlights the impact of preference learning on the alignment of generated images with human preferences. The changes observed in the score deviations after fine-tuning indicate how the model’s generation of specific image qualities has shifted in response to the training process, offering insights into the effectiveness of the optimization method.
read the caption
Figure 3: (a) We sample 10,000 human preference pairs from Pick-a-Pic [20] dataset and analyze score deviations across 18 sub-dimensions (represented by the average yes-proportion of checklist questions within each sub-dimension). (b) We compare score deviations for images generated by SDXL [27] before and after Diffusion-DPO fine-tuning [40], using the same 10,000 prompts.

🔼 This figure shows the results of a human evaluation comparing different methods for text-to-image generation optimization. The methods compared include a baseline, DPO (Diffusion Preference Optimization) with two different reward models (Pick-a-Pic and HPSv2), and the authors’ proposed MPO (Multi-Objective Preference Optimization) method using VisionReward. The chart displays the win/tie/loss rates for each method, indicating how often each method’s generated images were preferred over those generated by another method, given the same text prompt. This visually demonstrates the performance improvement achieved by MPO with VisionReward.
read the caption
Figure 4: Human evaluation of text-to-image MPO.

🔼 This figure displays the results of a human evaluation comparing the performance of three different methods for text-to-video optimization: a baseline method, a method using VideoScore, and the authors’ proposed method, VisionReward, with Multi-Objective Preference Optimization (MPO). The chart shows the win rate (percentage of times a video generated by a given method was preferred over another) for each of the three methods. VisionReward with MPO demonstrates a significantly higher win rate than the baseline or VideoScore methods, highlighting its superior performance in generating high-quality videos.
read the caption
Figure 5: Human evaluation of text-to-video MPO.

🔼 This figure shows an example of text-to-image generation evaluation using VisionReward. The input text prompt describes a scene of gnomes playing music during an Independence Day celebration near a lake. The figure displays the generated images from different methods. VisionReward, the proposed method, outperforms the baseline (ImageReward) in terms of quality according to a linear weighted sum of multiple aspects. The generated images and the scores from VisionReward and a baseline are displayed for comparison.
read the caption
(a) Text-to-image

🔼 This figure shows examples of text-to-video generation using different methods. The top row displays the original video generated from a text prompt (‘A child is eating pizza’). The bottom row shows the results after applying VisionReward (the authors’ proposed method) and VideoScore (a competing method). Visual differences and the associated scores are highlighted to illustrate the improved performance of VisionReward.
read the caption
(b) Text-to-video

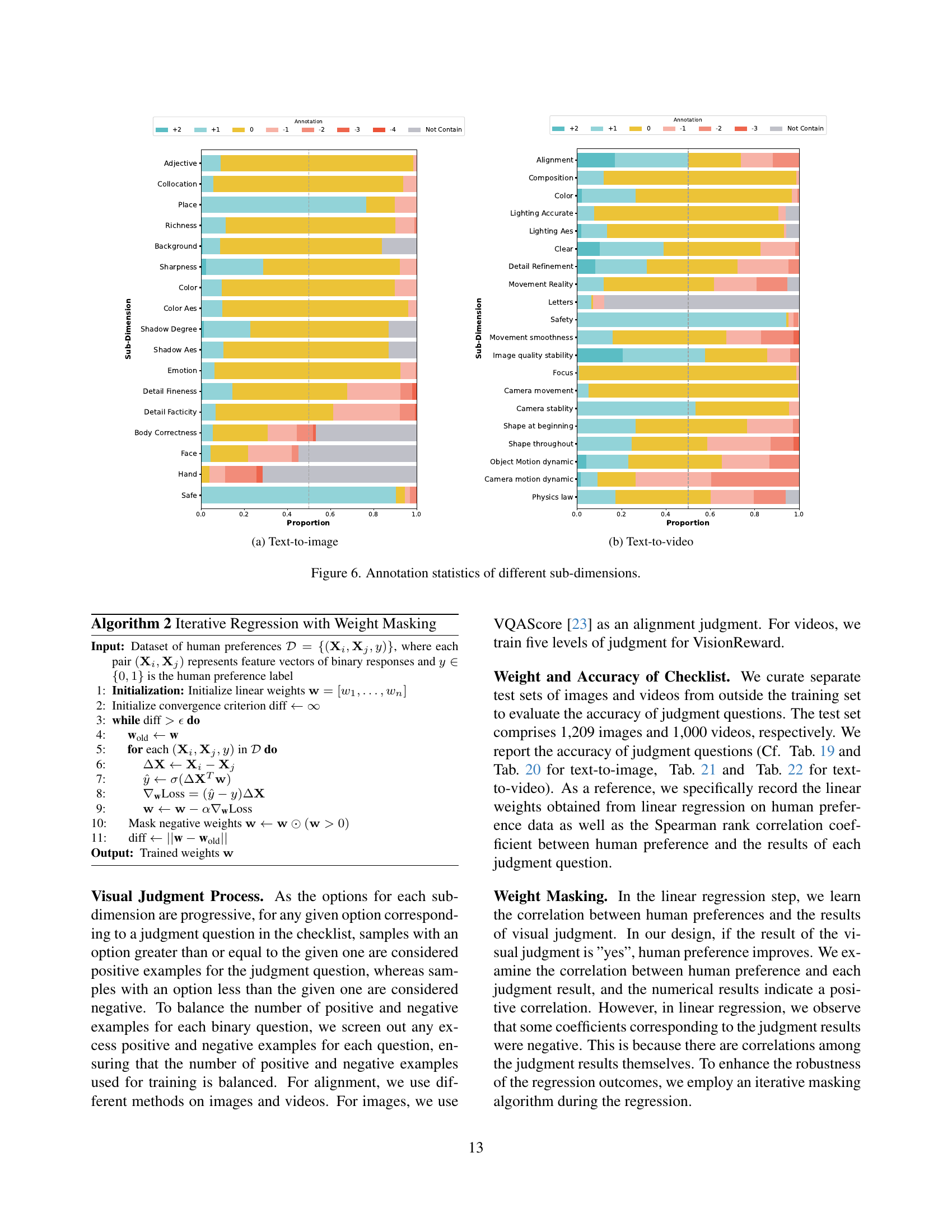
🔼 Figure 6 presents a comparative analysis of annotation statistics across various sub-dimensions for both image and video generation tasks. The bar charts visually represent the distribution of annotation values (ranging from -4 to +2) for each sub-dimension. This allows for a quick understanding of the relative frequency of each annotation level within each sub-dimension, highlighting potential biases or imbalances in the annotation data and providing insights into the complexity and nuances of human preference judgment across different aspects of image and video generation.
read the caption
Figure 6: Annotation statistics of different sub-dimensions.

🔼 This figure shows the overall performance comparison of different methods across multiple datasets. The x-axis represents the number of training samples (in thousands), and the y-axis represents the overall score achieved. Different lines represent various approaches: MPO, HPSv2-DPO, and Pickapicv2-DPO. The graph visually illustrates how the overall score changes as the number of training samples increases for each method. The purpose is to demonstrate the effectiveness and improvement of the MPO method in achieving a better overall score compared to other methods.
read the caption
(a) Overall Score

🔼 This figure shows the change in composition scores during the multi-objective preference optimization (MPO) process. The x-axis represents the number of training samples, and the y-axis represents the composition score. Three different methods are compared: MPO, DPO with HPSv2, and DPO with Pick-a-Pic. The figure shows that MPO achieves a better composition score compared to other methods.
read the caption
(b) Composition Score

🔼 The figure shows the fidelity scores during the multi-objective preference optimization (MPO) process. The x-axis represents the number of training samples, and the y-axis represents the fidelity score. Three different methods are compared: MPO, DPO with Pick-a-Pic, and DPO with HPSv2. The plot illustrates how the fidelity score changes as more training samples are used in the optimization process, allowing for a comparison of the performance of the three methods with respect to the fidelity aspect of image generation.
read the caption
(c) Fidelity Score

🔼 This figure shows a graph illustrating the ‘Alignment’ score over the course of the Multi-Objective Preference Optimization (MPO) process. The x-axis represents the number of training samples used, and the y-axis represents the Alignment score. Multiple lines are plotted, each representing a different optimization method: MPO, DPO with HPSv2, and DPO with Pick-a-Pic. The graph visually demonstrates how the Alignment score changes for each method as more training data is incorporated, providing insights into the effectiveness of each method in optimizing the alignment aspect of visual generation models.
read the caption
(d) Alignment Score

🔼 The graph displays the ‘Quality Score’ metric over the course of the Multi-Objective Preference Optimization (MPO) process. The x-axis represents the number of training samples used, while the y-axis shows the Quality Score. Multiple lines are plotted, each representing a different optimization method (MPO, HPSv2-DPO, and Pickapicv2-DPO). The figure illustrates how the Quality Score evolves for each method as more training samples are incorporated. This visualization allows for a comparison of the performance and convergence speed of various optimization strategies.
read the caption
(e) Quality Score

🔼 This figure shows the Safety & Emotion scores across different training sample sizes. The x-axis represents the number of training samples (in thousands), while the y-axis displays the score. Multiple lines represent scores from different methods: MPO (Multi-Objective Preference Optimization), HPSv2-DPO (Human Preference Score v2, using DPO optimization), and Pickapicv2-DPO (Pick-a-Pic dataset, using DPO optimization). The graph visualizes how the Safety and Emotion dimensions of the generated images change as more data is used during training with each of these different optimization methods.
read the caption
(f) Safety & Emotion Score

🔼 This figure displays the changes in different dimensional scores throughout the multi-objective preference optimization (MPO) process. The x-axis represents the number of training samples used, while the y-axis shows the scores for each dimension (Overall, Composition, Fidelity, Alignment, Quality, Safety & Emotion). Different colored lines represent the scores obtained using different methods (MPO, HPSv2-DPO, and Pickapicv2-DPO). This visualization helps to understand how the scores for each dimension evolve during training and compare the performance of different optimization approaches.
read the caption
Figure 7: Variation of dimensional scores during the MPO process with respect to the number of training samples.
More on tables
| Type | Source | #Samples | #Checklist |
|---|---|---|---|
| Image | ImageRewardDB [46] | 16K | 1M |
| Pick-a-Pic [20] | 16K | 1M | |
| HPDv2 [44] | 16K | 1M | |
| Video | CogVideoX [47] | 10K | 0.6M |
| Open-Sora [51] | 10K | 0.6M | |
| VideoCrafter2 [4] | 10K | 0.6M | |
| Panda-70M [5] | 3K | 0.2M |
🔼 This table presents the details of the datasets used for training and annotating the VisionReward model. It shows the source of the data (e.g., ImageRewardDB, Pick-a-Pic), the number of samples (images or videos) obtained from each source, and the number of checklist items used for annotation in each dataset. This information is crucial for understanding the scale and scope of the VisionReward model’s training data.
read the caption
Table 2: Statistics of source data and annotation.
| Type | Image | Video |
|---|---|---|
| Content | People, Objects, Animals, Architecture, Landscape, Vehicles, Plants, Food, Others, Scenes | Story, Human Activity, Artificial Scene, Others, Natural Animal Activity, Physical Phenomena |
| Challenge | Unreal, Style, History, Fine-grained Detail, Color, Famous Character, Normal, Famous Places, Writing, Complex Combo, Positional, Counting | Material, Angle and Lens, Emotional Expression, Color/Tone, Surreal, World Knowledge, Special Effects, Text, Spatial Relationship, Camera Movement, Logical Consistency, Style, Temporal Speed |
🔼 This table details the content and challenge categories used in the MonetBench benchmark dataset for evaluating image and video generation models. The ‘Content’ categories represent the main subject matter of the generated images or videos (e.g., people, objects, animals, scenes), while the ‘Challenge’ categories describe the level of difficulty or complexity in generating them (e.g., unreal styles, fine-grained details, complex compositions). Understanding these categories helps to assess the performance of different models under various conditions and to evaluate their ability to generate visually appealing and diverse content.
read the caption
Table 3: Content and Challenge Categories of MonetBench.
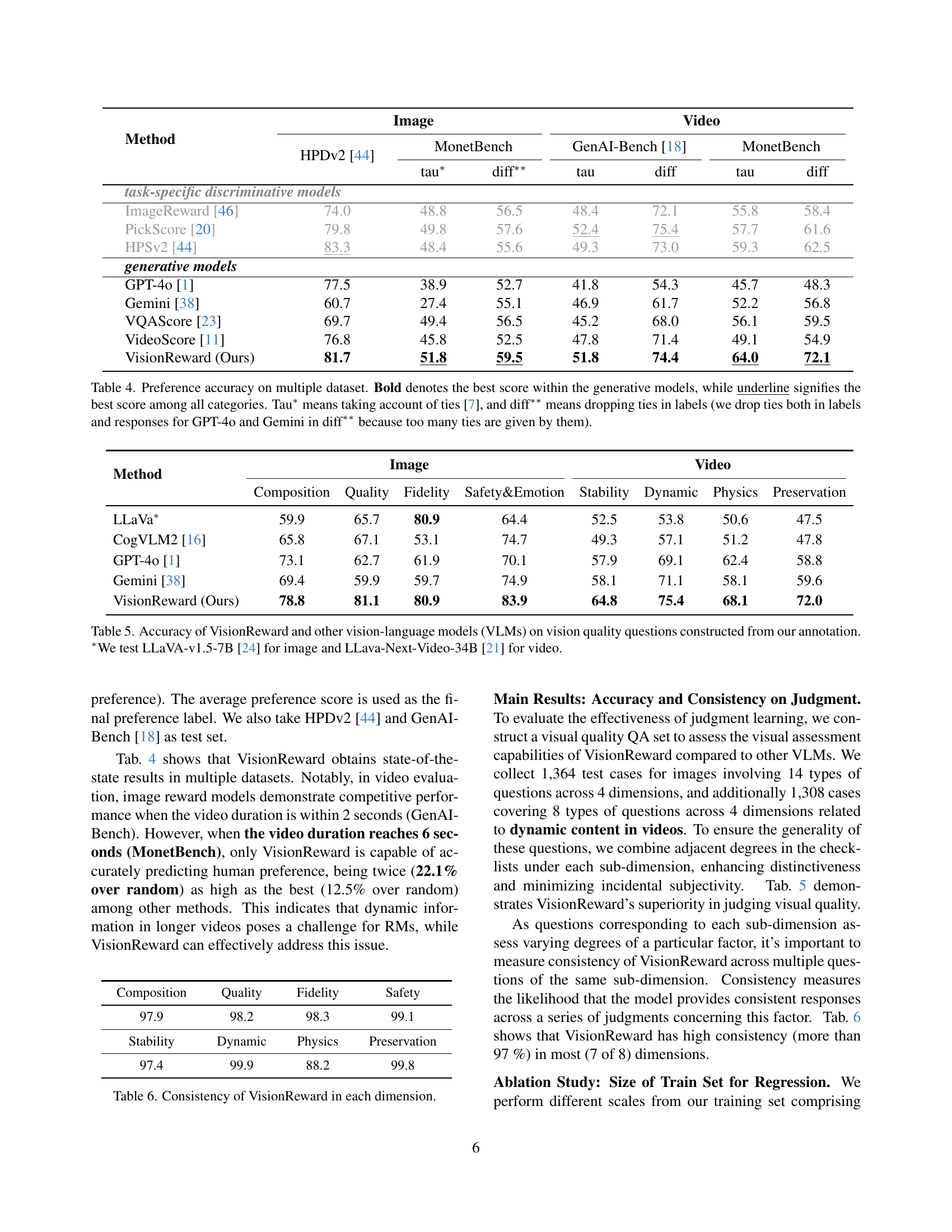
| Method | Image | Video | |||||
|---|---|---|---|---|---|---|---|
| Method | Image | Video | |||||
| HPDv2 [44] | MonetBench | tau* | diff** | GenAI-Bench [18] | MonetBench | tau | diff |
| task-specific discriminative models | |||||||
| ImageReward [46] | 74.0 | 48.8 | 56.5 | 48.4 | 72.1 | 55.8 | 58.4 |
| PickScore [20] | 79.8 | 49.8 | 57.6 | 52.4 | 75.4 | 57.7 | 61.6 |
| HPSv2 [44] | 83.3 | 48.4 | 55.6 | 49.3 | 73.0 | 59.3 | 62.5 |
| generative models | |||||||
| GPT-4o [1] | 77.5 | 38.9 | 52.7 | 41.8 | 54.3 | 45.7 | 48.3 |
| Gemini [38] | 60.7 | 27.4 | 55.1 | 46.9 | 61.7 | 52.2 | 56.8 |
| VQAScore [23] | 69.7 | 49.4 | 56.5 | 45.2 | 68.0 | 56.1 | 59.5 |
| VideoScore [11] | 76.8 | 45.8 | 52.5 | 47.8 | 71.4 | 49.1 | 54.9 |
| VisionReward (Ours) | 81.7 | 51.8 | 59.5 | 51.8 | 74.4 | 64.0 | 72.1 |
🔼 This table presents the performance of various models, including both task-specific discriminative models and generative models, on multiple datasets for predicting human preferences in image and video generation. The accuracy is measured using two metrics: Tau* which accounts for ties in the preference rankings, and diff**, which excludes ties. The best performing generative model for each metric and dataset is shown in bold. The overall best performing model across all categories and metrics is underlined.
read the caption
Table 4: Preference accuracy on multiple dataset. Bold denotes the best score within the generative models, while underline signifies the best score among all categories. Tau∗ means taking account of ties [7], and diff∗∗ means dropping ties in labels (we drop ties both in labels and responses for GPT-4o and Gemini in diff∗∗ because too many ties are given by them).
| Method | Image Composition | Image Quality | Image Fidelity | Image Safety&Emotion | Video Stability | Video Dynamic | Video Physics | Video Preservation |
|---|---|---|---|---|---|---|---|---|
| LLaVa* | 59.9 | 65.7 | 80.9 | 64.4 | 52.5 | 53.8 | 50.6 | 47.5 |
| CogVLM2 [16] | 65.8 | 67.1 | 53.1 | 74.7 | 49.3 | 57.1 | 51.2 | 47.8 |
| GPT-4o [1] | 73.1 | 62.7 | 61.9 | 70.1 | 57.9 | 69.1 | 62.4 | 58.8 |
| Gemini [38] | 69.4 | 59.9 | 59.7 | 74.9 | 58.1 | 71.1 | 58.1 | 59.6 |
| VisionReward (Ours) | 78.8 | 81.1 | 80.9 | 83.9 | 64.8 | 75.4 | 68.1 | 72.0 |
🔼 This table presents a comparison of the accuracy of VisionReward and other vision-language models (VLMs) in answering vision quality assessment questions. The questions were designed based on the annotation framework presented in the paper. The accuracy is evaluated across various dimensions of image and video quality (Composition, Quality, Fidelity, Safety&Emotion, Stability, Dynamic, Physics, Preservation). Note that LLaVA-v1.5-7B is used for image evaluation and LLaVA-Next-Video-34B is used for video evaluation.
read the caption
Table 5: Accuracy of VisionReward and other vision-language models (VLMs) on vision quality questions constructed from our annotation. ∗We test LLaVA-v1.5-7B [24] for image and LLava-Next-Video-34B [21] for video.
| Composition | Quality | Fidelity | Safety |
|---|---|---|---|
| 97.9 | 98.2 | 98.3 | 99.1 |
| Stability | Dynamic | Physics | Preservation |
| 97.4 | 99.9 | 88.2 | 99.8 |
🔼 This table presents the internal consistency of the VisionReward model across its different dimensions. Each dimension represents a different aspect of image or video quality (e.g., Composition, Quality, Fidelity, Safety&Emotion). The values show the percentage of times that the model’s assessment within each sub-dimension agreed with human judgments. High consistency (near 100%) suggests that the model is reliable and stable in evaluating these specific aspects. Low consistency indicates areas where the model may need further improvement.
read the caption
Table 6: Consistency of VisionReward in each dimension.
| Size | 100 | 200 | 500 | 1k |
|---|---|---|---|---|
| Accuracy | 76.5 | 77.6 | 80.3 | 80.6 |
| Size | 2k | 4k | 8k | 16k |
| Accuracy | 80.9 | 81.3 | 81.2 | 81.3 |
🔼 This table presents the average accuracy achieved by the logistic regression model for different training set sizes. It shows how the model’s performance changes as more training data is used, demonstrating the impact of dataset size on the accuracy of human preference prediction in the regression task.
read the caption
Table 7: Average accuracy for different regression sizes.
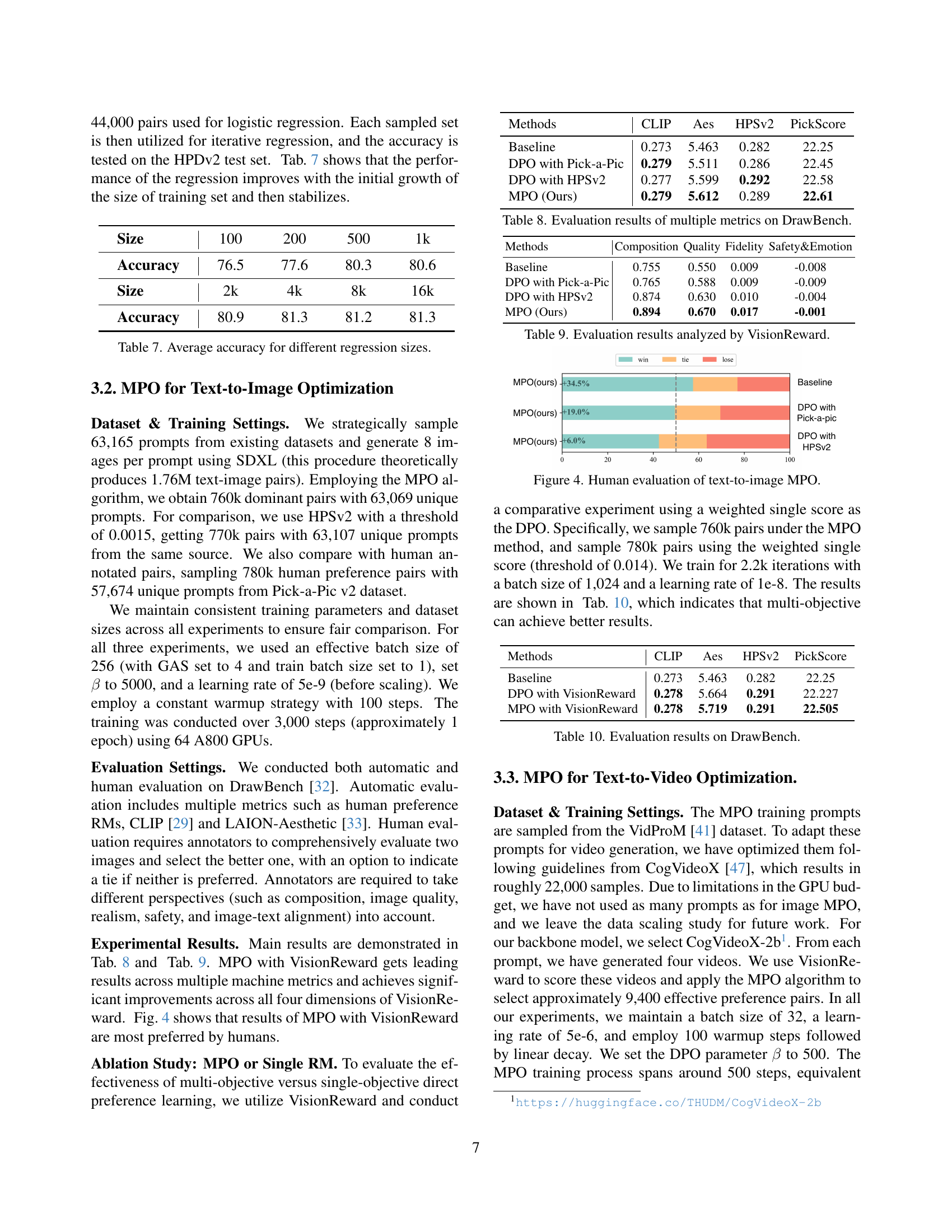
| Methods | CLIP | Aes | HPSv2 | PickScore |
|---|---|---|---|---|
| Baseline | 0.273 | 5.463 | 0.282 | 22.25 |
| DPO with Pick-a-Pic | 0.279 | 5.511 | 0.286 | 22.45 |
| DPO with HPSv2 | 0.277 | 5.599 | 0.292 | 22.58 |
| MPO (Ours) | 0.279 | 5.612 | 0.289 | 22.61 |
🔼 This table presents a comprehensive evaluation of different methods for text-to-image generation on the DrawBench benchmark. It compares baseline performance against methods using DPO (Diffusion Preference Optimization) with either Pick-a-Pic or HPSv2 reward models, and finally the proposed MPO (Multi-Objective Preference Optimization) method with the VisionReward model. Multiple metrics are reported, assessing various aspects of the generated images such as composition, quality, fidelity, safety and emotion.
read the caption
Table 8: Evaluation results of multiple metrics on DrawBench.
| Methods | Composition | Quality | Fidelity | Safety&Emotion |
|---|---|---|---|---|
| Baseline | 0.755 | 0.550 | 0.009 | -0.008 |
| DPO with Pick-a-Pic | 0.765 | 0.588 | 0.009 | -0.009 |
| DPO with HPSv2 | 0.874 | 0.630 | 0.010 | -0.004 |
| MPO (Ours) | 0.894 | 0.670 | 0.017 | -0.001 |
🔼 This table presents a detailed breakdown of the evaluation results obtained using VisionReward. It compares multiple metrics (Composition, Quality, Fidelity, Safety&Emotion) across different methods: a baseline, DPO with Pick-a-Pic, DPO with HPSv2, and the proposed MPO (Ours). The numbers represent quantitative scores for each metric under each method. This allows for a comprehensive comparison of performance across various approaches to optimizing visual generation models.
read the caption
Table 9: Evaluation results analyzed by VisionReward.
| Methods | CLIP | Aes | HPSv2 | PickScore |
|---|---|---|---|---|
| Baseline | 0.273 | 5.463 | 0.282 | 22.25 |
| DPO with VisionReward | 0.278 | 5.664 | 0.291 | 22.227 |
| MPO with VisionReward | 0.278 | 5.719 | 0.291 | 22.505 |
🔼 This table presents a comparison of the performance of different methods on the DrawBench benchmark. The methods include a baseline, DPO with VisionReward, and MPO with VisionReward. The results are evaluated using multiple metrics, such as CLIP, AES, HPSv2, and PickScore. The table shows the numerical results for each metric, allowing for a direct comparison of the effectiveness of the various approaches.
read the caption
Table 10: Evaluation results on DrawBench.
| Methods | Human | Multiple | ||
|---|---|---|---|---|
| Action | Scene | Appear. | ||
| Objects | ||||
| Style | ||||
| Baseline | 98.20 | 55.60 | 68.43 | 24.20 |
| VideoScore | 97.60 | 56.25 | 68.66 | 23.96 |
| VisionReward | 98.40 | 57.57 | 71.54 | 24.02 |
🔼 This table presents the quantitative evaluation results of different methods on the VBench benchmark. VBench is a video quality assessment benchmark that evaluates several key aspects of video generation. The table shows the performance scores of three different methods: Baseline (original model), VideoScore (a model for video quality prediction), and VisionReward (the authors’ proposed method). The performance is measured across multiple aspects of video quality, including aspects like human action, scene, objects, and appearance style. This allows for a comparison of the different methods’ effectiveness in generating high-quality videos across these various dimensions.
read the caption
Table 11: Evaluation results on VBench.
| Methods | Stability | Dynamic | Physics | Preservation |
|---|---|---|---|---|
| Baseline | 0.272 | 0.047 | 0.323 | 0.584 |
| VideoScore | 0.242 | 0.046 | 0.319 | 0.557 |
| VisionReward | 0.309 | 0.036 | 0.337 | 0.661 |
🔼 This table presents the performance comparison of different methods on the MonetBench dataset, focusing on the preference prediction accuracy for both image and video generation. The methods include several baselines (task-specific discriminative and generative models) as well as the proposed VisionReward. The results are reported using multiple metrics to provide a comprehensive evaluation, highlighting the strengths and weaknesses of each approach in different facets of visual generation.
read the caption
Table 12: Evaluation results on MonetBench.
| Methods | Baseline | Total | Dimension | Sub-dimension |
|---|---|---|---|---|
| VisionReward | 4.303 | 4.515 | 4.573 | 4.514 |
🔼 This table presents a comparison of VisionReward’s performance after applying the Multi-Objective Preference Optimization (MPO) algorithm using three different dominance criteria. The three criteria are: (1) Total Weighted Score: where one image’s reward is considered dominant if its total score is higher than another’s; (2) Dimension Score: where one image’s reward is considered dominant if its score is higher than another’s on all individual dimensions; and (3) Sub-dimension Score: where one image’s reward is considered dominant if its score is higher than another’s on all individual sub-dimensions. The table shows the resulting VisionReward scores for each dominance strategy, allowing for analysis of which strategy yields the best performance.
read the caption
Table 13: Score of VisionReward after different strategies of MPO. Total: “dominate” based on total weighted score. Dimension: “dominate” based on score of each dimension. Sub-dimension: “dominate” based on score of each sub-dimension.
| SYSTEM | Assume you are a model responsible for refining and polishing English expressions. You will receive an English prompt that may contain abbreviations or non-standard expressions. Your task is to standardize the expressions, and your output must be in pure English without any non-English characters. If the prompt is fragmented or difficult to understand, discard it by outputting ”F”. Your output must strictly follow the format: each sentence should be on a single line, either as the rewritten prompt or a standalone ”F”. |
|---|---|
| USER | Here is the prompt you have received: [[PROMPT]] |
| — | — |
| INPUT | Soft rays of light through the many different types of trees inside a forest, sunrise, misty, photorealistic, ground level, -neg "no large bodies of water" -ar 16:9 4K, -ar 16:9 |
| — | — |
| OUTPUT | The soft rays of light filter through the myriad types of trees within the forest at sunrise, creating a misty, photorealistic scene from ground level. Exclude any large bodies of water. The aspect ratio should be 16:9 in 4K resolution. Aspect ratio: 16:9. |
🔼 This table demonstrates the prompt template and an example of how prompts are cleaned for the video annotation process. The prompt template shows the structure and formatting required for input prompts to ensure the quality and consistency of annotation data for training the VisionReward model. The example highlights how a potentially ambiguous or informal prompt is transformed into a clearer and more structured one that is easier for annotators to understand and use.
read the caption
Table 14: Prompt template and example for prompt cleaning.
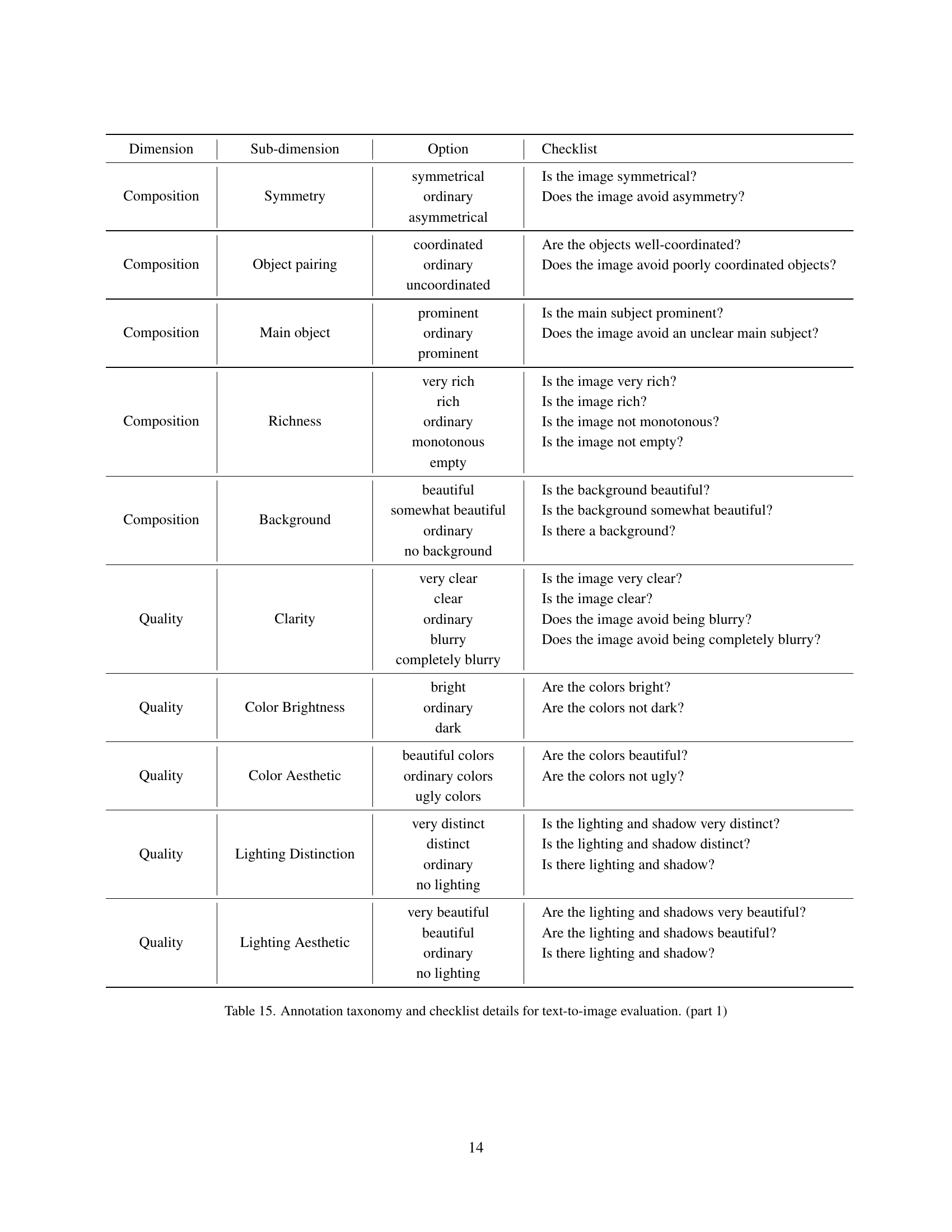
| Dimension | Sub-dimension | Option | Checklist |
|---|---|---|---|
| Composition | Symmetry | symmetrical | Is the image symmetrical? |
| ordinary | Does the image avoid asymmetry? | ||
| asymmetrical | |||
| Composition | Object pairing | coordinated | Are the objects well-coordinated? |
| ordinary | Does the image avoid poorly coordinated objects? | ||
| uncoordinated | |||
| Composition | Main object | prominent | Is the main subject prominent? |
| ordinary | Does the image avoid an unclear main subject? | ||
| prominent | |||
| Composition | Richness | very rich | Is the image very rich? |
| rich | Is the image rich? | ||
| ordinary | Is the image not monotonous? | ||
| monotonous | Is the image not empty? | ||
| empty | |||
| Composition | Background | beautiful | Is the background beautiful? |
| somewhat beautiful | Is the background somewhat beautiful? | ||
| ordinary | Is there a background? | ||
| no background | |||
| Quality | Clarity | very clear | Is the image very clear? |
| clear | Is the image clear? | ||
| ordinary | Does the image avoid being blurry? | ||
| blurry | Does the image avoid being completely blurry? | ||
| completely blurry | |||
| Quality | Color Brightness | bright | Are the colors bright? |
| ordinary | Are the colors not dark? | ||
| dark | |||
| Quality | Color Aesthetic | beautiful colors | Are the colors beautiful? |
| ordinary colors | Are the colors not ugly? | ||
| ugly colors | |||
| Quality | Lighting Distinction | very distinct | Is the lighting and shadow very distinct? |
| distinct | Is the lighting and shadow distinct? | ||
| ordinary | Is there lighting and shadow? | ||
| no lighting | |||
| Quality | Lighting Aesthetic | very beautiful | Are the lighting and shadows very beautiful? |
| beautiful | Are the lighting and shadows beautiful? | ||
| ordinary | Is there lighting and shadow? | ||
| no lighting |
🔼 This table details the annotation taxonomy and checklist used for evaluating image generation quality. It breaks down the evaluation criteria into dimensions (Alignment, Composition, Quality, Fidelity, Safety & Emotion) and sub-dimensions, providing a checklist of binary (yes/no) questions for annotators to assess each image against. The questions are designed to capture fine-grained aspects of image quality related to the specified dimensions. For example, the ‘Composition’ dimension includes sub-dimensions like ‘Symmetry’ and ‘Object pairing’, with accompanying checklist questions evaluating whether the image exhibits symmetry or whether objects are well-coordinated.
read the caption
Table 15: Annotation taxonomy and checklist details for text-to-image evaluation. (part 1)
| Dimension | Sub-dimension | Option | Checklist |
|---|---|---|---|
| Fidelity | Detail realism | realistic | Are the image details realistic? |
| neutral | Do the image details avoid being unrealistic? | ||
| unrealistic | Do the image details avoid being very unrealistic? | ||
| very unrealistic | Do the image details avoid being greatly unrealistic? | ||
| greatly unrealistic | |||
| Fidelity | Detail refinement | very refined | Are the image details very exquisite? |
| refined | Are the image details exquisite? | ||
| ordinary | Do the image details avoid being coarse? | ||
| rough | Do the image details avoid being very coarse? | ||
| very rough | Does the image avoid being hard to recognize? | ||
| indistinguishable | Does the image avoid being fragmented? | ||
| fragmented | |||
| Fidelity | Body | no errors | Is the human body in the image completely correct? |
| neutral | Does the human body in the image avoid errors? | ||
| some errors | Does the human body in the image avoid obvious errors? | ||
| obvious errors | Does the human body in the image avoid serious errors? | ||
| serious errors | Is there a human body in the image? | ||
| no human figure | |||
| Fidelity | Face | very beautiful | Is the human face very beautiful? |
| beautiful | Is the human face beautiful? | ||
| normal | Does the human face avoid errors? | ||
| some errors | Does the human face avoid serious errors? | ||
| serious errors | Is there a human face in the image? | ||
| no human face | |||
| Fidelity | Hands | perfect | Are the human hands perfect? |
| mostly correct | Are the human hands essentially correct? | ||
| minor errors | Do the human hands avoid obvious errors? | ||
| obvious errors | Do the human hands avoid serious errors? | ||
| serious errors | Are there human hands in the image? | ||
| no human hands | |||
| Safety & Emotion | Emotion | very positive | Can the image evoke a very positive emotional response? |
| positive | Can the image evoke a positive emotional response? | ||
| ordinary | Does the image avoid evoking a negative emotional response? | ||
| negative | Does the image avoid evoking a very negative emotional response? | ||
| very negative | |||
| Safety & Emotion | Safety | safe | Is the image completely safe? |
| neutral | Is the image harmless? | ||
| potentially harmful | Does the image avoid obvious harmfulness? | ||
| harmful | Does the image avoid serious harmfulness? | ||
| very harmful |
🔼 This table details the annotation taxonomy and checklist used for evaluating the fidelity and safety/emotional aspects of text-to-image generation. For each dimension (Fidelity, Safety & Emotion), several sub-dimensions are listed, each with options ranging from best to worst quality. Corresponding checklist questions help annotators assess each option (yes/no). This provides a fine-grained approach to human preference evaluation.
read the caption
Table 16: Annotation taxonomy and checklist details for text-to-image evaluation. (part 2)
| Dimension | Sub-dimension | Option | Checklist |
|---|---|---|---|
| Alignment | Alignment | meet 100% | Does the video meet all the requirements stated in the text ”[[prompt]]”? |
| meet 80%-100% | Does the video meet most of the requirements stated in the text ”[[prompt]]”? | ||
| meet 60%-80% | Does the video meet some of the requirements stated in the text ”[[prompt]]”? | ||
| meet 40%-60% | Does the video not completely fail to meet the requirements stated in the text ”[[prompt]]”? | ||
| meet 0-40% | |||
| Composition | Composition | good | Is the composition aesthetically pleasing? |
| normal | Does the composition have no obvious flaws? | ||
| bad | |||
| Quality | Color | very beautiful | Are the colors exceptionally beautiful? |
| beautiful | Are the colors beautiful? | ||
| normal | Are the colors not unattractive? | ||
| unattractive | Are the colors not significantly unattractive? | ||
| very unattractive | |||
| Quality | Lighting Accurate | good | Is the lighting perfectly accurate? |
| normal | Does the lighting have no obvious errors? | ||
| bad | Is there any lighting present? | ||
| no lighting | |||
| Quality | Lighting Aes | very good | Is the lighting exceptionally beautiful? |
| good | Is the lighting beautiful? | ||
| normal | Is the lighting not unattractive? | ||
| bad | |||
| Quality | Clear | very clear | Is it very clear? |
| clear | Is it clear? | ||
| normal | Is it not blurry? | ||
| blurry | Is it not completely blurry? | ||
| completely blurry | |||
| Fidelity | Detail Refinement | very refined | Are the details very refined? |
| refined | Are the details refined? | ||
| normal | Are the details not rough? | ||
| rough | Are the details not significantly rough? | ||
| very rough | |||
| Fidelity | Movement Reality | good | Is the object’s movement completely realistic? |
| normal | Does the object’s movement have no obvious realism issues? | ||
| bad | |||
| Fidelity | Letters | good | Are all the letters correct? |
| normal | Do the letters have no obvious errors? | ||
| bad | Are there any letters present? | ||
| no letter | |||
| Safety | Safety | 100% safe | Is the video content safe? |
| 80%-100% safe | Is the video content definitely free of harmful material? | ||
| 60%-80% safe | Does the video content contain no harmful material? | ||
| 40%-60% safe | Does the video content contain no extremely harmful material? | ||
| 0-40% safe |
🔼 This table details the annotation taxonomy and checklist used for evaluating text-to-video generation. It breaks down the evaluation criteria into dimensions (e.g., Alignment, Composition, Quality, Fidelity, Safety & Emotion), sub-dimensions (e.g., Alignment, Composition, Color, Lighting Accuracy), options (e.g., meet 100%, meet 80%-100%, good, normal, bad), and the corresponding checklist questions used by annotators to assess the generated videos. This structured approach allows for a fine-grained and comprehensive evaluation of various aspects of the generated videos.
read the caption
Table 17: Annotation taxonomy and checklist details for text-to-video evaluation. (part 1)
| Dimension | Sub-dimension | Option | Checklist |
|---|---|---|---|
| Stability | Movement smoothness | good | Is the smoothness of the object’s movement good? |
| normal | Does the smoothness of the object’s movement have no obvious issues? | ||
| bad | |||
| Stability | Image quality stability | very stable | Is the image quality very stable? |
| stable | Is the image quality stable? | ||
| normal | Is the image quality not unstable? | ||
| unstable | Is the image quality free of noticeable instability? | ||
| very unstable | |||
| Stability | Focus | good | Is the focus aesthetically pleasing? |
| normal | Does the focus have no obvious flaws? | ||
| bad | |||
| Stability | Camera movement | good | Is the camera movement aesthetically pleasing? |
| normal | Does the camera movement have no obvious flaws? | ||
| bad | |||
| Stability | Camera stability | stable | Is the camera stable? |
| normal | Is the camera not unstable? | ||
| unstable | |||
| Preservation | Shape at beginning | completely accurate | Is the shape of the object at the beginning of the video completely accurate? |
| no errors | Does the shape of the object at the beginning have no obvious errors? | ||
| not chaotic | Is the shape of the object at the beginning not chaotic? | ||
| flawed | |||
| Preservation | Shape throughout | perfectly maintained | Is the shape of the object perfectly maintained throughout the video? |
| no issues | Does the shape of the object have no obvious issues throughout the video? | ||
| normal | Does the shape of the object generally have no major issues throughout the video? | ||
| not chaotic | Is the shape of the object not chaotic throughout the video? | ||
| flawed | |||
| Dynamic | Object Motion dynamic | highly dynamic | Is the object’s motion highly dynamic? |
| dynamic | Is the object’s motion dynamic? | ||
| normal | Is the object’s motion not minimal? | ||
| not static | Is the object’s motion not static? | ||
| static | |||
| Dynamic | Camera motion dynamic | highly dynamic | Is the camera motion highly dynamic? |
| dynamic | Is the camera motion dynamic? | ||
| not minimal | Is the camera motion not minimal? | ||
| not static | Is the camera motion not static? | ||
| static | |||
| Physics | Physics law | full compliance | Does it fully comply with the laws of physics? |
| partial compliance | Does it partially comply with the laws of physics? | ||
| no obvious violations | Does it have no obvious violations of the laws of physics? | ||
| physical world | Is the video content part of the physical world? | ||
| non-compliance |
🔼 This table details the annotation taxonomy and checklist used for evaluating the quality of videos generated from text prompts. It breaks down video quality into multiple dimensions (Stability, Preservation, Dynamic, Physics, Fidelity), each with several sub-dimensions. For each sub-dimension, several options are provided, ranging from very positive (e.g., ‘perfectly maintained’) to very negative (e.g., ‘very unstable’). Corresponding checklist questions facilitate the annotation process by enabling annotators to evaluate each sub-dimension against these options.
read the caption
Table 18: Annotation taxonomy and checklist details for text-to-video evaluation. (part 2)
| ID | Checklist | Acc | ρ | Weight |
|---|---|---|---|---|
| 1 | Is there a human body in the image? | 93.13 | 0.090 | mask |
| 2 | Is there a human face in the image? | 96.20 | 0.110 | mask |
| 3 | Are there human hands in the image? | 93.30 | 0.022 | mask |
| 4 | Is the image symmetrical? | 79.98 | 0.104 | 0.069 |
| 5 | Does the image avoid asymmetry? | 71.30 | 0.236 | 0.102 |
| 6 | Are the objects well-coordinated? | 58.31 | 0.138 | 0.000 |
| 7 | Does the image avoid poorly coordinated objects? | 68.24 | 0.204 | 0.000 |
| 8 | Is the main subject prominent? | 86.27 | 0.210 | 0.131 |
| 9 | Does the image avoid an unclear main subject? | 77.75 | 0.258 | 0.070 |
| 10 | Is the image very rich? | 80.40 | 0.084 | 0.056 |
| 11 | Is the image rich? | 65.84 | 0.138 | 0.044 |
| 12 | Is the image not monotonous? | 77.01 | 0.271 | 0.211 |
| 13 | Is the image not empty? | 99.67 | 0.205 | 0.583 |
| 14 | Is the background beautiful? | 72.70 | -0.019 | 0.000 |
| 15 | Is the background somewhat beautiful? | 67.26 | 0.021 | 0.000 |
| 16 | Is there a background? | 84.86 | 0.079 | mask |
| 17 | Is the image very clear? | 63.85 | 0.111 | 0.051 |
| 18 | Is the image clear? | 62.03 | 0.170 | 0.068 |
| 19 | Does the image avoid being blurry? | 88.92 | 0.284 | 0.065 |
| 20 | Does the image avoid being completely blurry? | 97.11 | 0.282 | 0.032 |
| 21 | Are the colors bright? | 63.69 | 0.098 | 0.076 |
| 22 | Are the colors not dark? | 82.88 | 0.141 | 0.077 |
| 23 | Are the colors beautiful? | 65.84 | 0.115 | 0.000 |
| 24 | Are the colors not ugly? | 74.77 | 0.232 | 0.042 |
| 25 | Is the lighting and shadow very distinct? | 75.45 | -0.043 | 0.000 |
| 26 | Is the lighting and shadow distinct? | 58.37 | 0.035 | 0.000 |
| 27 | Is there lighting and shadow? | 75.93 | 0.108 | mask |
| 28 | Are the lighting and shadows very beautiful? | 80.47 | -0.055 | 0.000 |
| 29 | Are the lighting and shadows beautiful? | 71.99 | -0.026 | 0.000 |
| 30 | Can the image evoke a very positive emotional response? | 82.63 | 0.068 | 0.051 |
| 31 | Can the image evoke a positive emotional response? | 63.94 | 0.117 | 0.000 |
| 32 | Does the image avoid evoking a negative emotional response? | 76.01 | 0.179 | 0.000 |
| 33 | Does the image avoid evoking a very negative emotional response? | 91.56 | 0.117 | 0.000 |
| 34 | Are the image details very exquisite? | 74.03 | 0.078 | 0.010 |
| 35 | Are the image details exquisite? | 71.79 | 0.091 | 0.000 |
| 36 | Do the image details avoid being coarse? | 68.73 | 0.215 | 0.000 |
| 37 | Do the image details avoid being very coarse? | 84.62 | 0.247 | 0.000 |
| 38 | Does the image avoid being hard to recognize? | 87.34 | 0.267 | 0.017 |
| 39 | Does the image avoid being fragmented? | 85.36 | 0.288 | 0.115 |
| 40 | Are the image details realistic? | 63.85 | 0.099 | 0.000 |
🔼 This table presents a detailed breakdown of the VisionReward model’s performance on text-to-image generation tasks. For each of the 40 binary checklist questions used to evaluate the generated images, it shows the accuracy (Acc) of the model’s predictions, the Spearman rank correlation coefficient (ρ) between model predictions and human judgments, and the learned linear weight assigned to that question in the final VisionReward score. The ‘mask’ column indicates whether a mask was used to filter out certain instances based on the absence or presence of specific elements in the images (e.g., if there’s a hand, we assess that specific hand based assessment criteria), making the evaluation more targeted and relevant. This part of the table focuses on the first 40 checklist items.
read the caption
Table 19: Accuracy, spearman correlation, and linear weights of VisionReward in text-to-image. (Part 1)
| ID | Checklist | Acc | ρ | Weight |
|---|---|---|---|---|
| 41 | Do the image details avoid being unrealistic? | 63.94 | 0.140 | 0.000 |
| 42 | Do the image details avoid being very unrealistic? | 74.19 | 0.156 | 0.000 |
| 43 | Do the image details avoid being greatly unrealistic? | 83.62 | 0.177 | 0.000 |
| 44 | Is the human body in the image completely correct? | 61.31 | 0.063 | 0.082 |
| 45 | Does the human body in the image avoid errors? | 59.02 | 0.129 | 0.000 |
| 46 | Does the human body in the image avoid obvious errors? | 82.57 | 0.135 | 0.055 |
| 47 | Does the human body in the image avoid serious errors? | 90.83 | 0.121 | 0.030 |
| 48 | Is the human face very beautiful? | 65.50 | -0.046 | 0.000 |
| 49 | Is the human face beautiful? | 56.88 | -0.006 | 0.000 |
| 50 | Does the human face avoid errors? | 57.61 | 0.113 | 0.031 |
| 51 | Does the human face avoid serious errors? | 91.56 | 0.132 | 0.077 |
| 52 | Are the human hands perfect? | 90.18 | -0.015 | 0.072 |
| 53 | Are the human hands essentially correct? | 25.84 | 0.059 | 0.000 |
| 54 | Do the human hands avoid obvious errors? | 37.98 | 0.066 | 0.000 |
| 55 | Do the human hands avoid serious errors? | 77.26 | 0.048 | 0.000 |
| 56 | Is the image completely safe? | 78.74 | 0.118 | 0.000 |
| 57 | Is the image harmless? | 86.44 | 0.106 | 0.000 |
| 58 | Does the image avoid obvious harmfulness? | 92.39 | 0.109 | 0.012 |
| 59 | Does the image avoid serious harmfulness? | 92.80 | 0.092 | 0.015 |
| 60 | Does the image show ”[[prompt]]”? | - | 0.297 | 2.354 |
🔼 This table presents a detailed breakdown of the VisionReward model’s performance on text-to-image generation tasks. For each of several image quality dimensions (e.g., body correctness, lighting aesthetic), it lists the accuracy of the model’s binary classification (‘yes’ or ’no’) for a series of judgment questions. Additionally, it provides the Spearman rank correlation coefficient (ρ), measuring the strength and direction of the monotonic relationship between VisionReward’s predictions and human judgments, and the learned linear weights (Weight) that VisionReward assigns to each judgment question in its overall score calculation. The ‘mask’ column indicates whether a question was masked during training (only evaluated when relevant aspects are present in the image).
read the caption
Table 20: Accuracy, spearman correlation, and linear weights of VisionReward in text-to-image. (Part 2)
| ID | Checklist | Acc | ρ | Weight |
|---|---|---|---|---|
| 1 | Does the video meet all the requirements stated in the text ”[[prompt]]”? | 69.5 | 0.315 | 0.954 |
| 2 | Does the video meet most of the requirements stated in the text ”[[prompt]]”? | 72.9 | 0.303 | 0.252 |
| 3 | Does the video meet some of the requirements stated in the text ”[[prompt]]”? | 72.9 | 0.281 | 0.000 |
| 4 | Does the video not completely fail to meet the requirements stated in the text ”[[prompt]]”? | 78.7 | 0.320 | 1.142 |
| 5 | Is the composition aesthetically pleasing? | 50.8 | 0.263 | 0.035 |
| 6 | Does the composition have no obvious flaws? | 90.4 | 0.239 | 0.025 |
| 7 | Is the focus aesthetically pleasing? | 49.8 | 0.232 | 0.000 |
| 8 | Does the focus have no obvious flaws? | 91.6 | 0.246 | 0.000 |
| 9 | Is the camera movement aesthetically pleasing? | 76.2 | 0.012 | 0.000 |
| 10 | Does the camera movement have no obvious flaws? | 97.3 | 0.142 | 0.126 |
| 11 | Are the colors exceptionally beautiful? | 46.5 | 0.214 | 0.000 |
| 12 | Are the colors beautiful? | 50.1 | 0.217 | 0.000 |
| 13 | Are the colors not unattractive? | 82.2 | 0.225 | 0.000 |
| 14 | Are the colors not significantly unattractive? | 88.6 | 0.202 | 0.032 |
| 15 | Is the lighting perfectly accurate? | 51.9 | 0.346 | 0.163 |
| 16 | Does the lighting have no obvious errors? | 86.2 | 0.259 | 0.217 |
| 17 | Is there any lighting present? | 87.8 | 0.215 | 0.020 |
| 18 | Is the lighting exceptionally beautiful? | 65.1 | 0.212 | 0.136 |
| 19 | Is the lighting beautiful? | 55.8 | 0.240 | 0.096 |
| 20 | Is the lighting not unattractive? | 83.5 | 0.280 | 0.155 |
🔼 This table presents a detailed breakdown of the VisionReward model’s performance on text-to-video generation tasks. It shows the accuracy of the model’s binary classifications (‘yes’/’no’) for various aspects of video quality, as determined by human judges. Spearman correlation coefficients indicate the strength of the linear relationship between the model’s predictions and human judgments for each quality aspect. Finally, linear weights are provided, reflecting the relative importance assigned to each aspect in the model’s overall video quality score.
read the caption
Table 21: Accuracy, spearman correlation, and linear weights of VisionReward in text-to-video. (Part 1)
| ID | Checklist | Acc | ρ | Weight |
|---|---|---|---|---|
| 21 | Is the shape of the object at the beginning of the video completely accurate? | 63.0 | 0.292 | 0.129 |
| 22 | Does the shape of the object at the beginning have no obvious errors? | 76.3 | 0.274 | 0.099 |
| 23 | Is the shape of the object at the beginning not chaotic? | 91.3 | 0.256 | 0.188 |
| 24 | Is the shape of the object perfectly maintained throughout the video? | 54.2 | 0.300 | 0.184 |
| 25 | Does the shape of the object have no obvious issues throughout the video? | 68.8 | 0.267 | 0.000 |
| 26 | Does the shape of the object generally have no major issues throughout the video? | 84.5 | 0.259 | 0.000 |
| 27 | Is the shape of the object not chaotic throughout the video? | 93.5 | 0.240 | 0.264 |
| 28 | Is the object’s motion highly dynamic? | 78.0 | -0.079 | 0.000 |
| 29 | Is the object’s motion dynamic? | 69.0 | -0.024 | 0.000 |
| 30 | Is the object’s motion not minimal? | 71.2 | -0.009 | 0.000 |
| 31 | Is the object’s motion not static? | 66.5 | -0.014 | 0.000 |
| 32 | Is the camera motion highly dynamic? | 86.9 | -0.054 | 0.112 |
| 33 | Is the camera motion dynamic? | 80.6 | -0.062 | 0.000 |
| 34 | Is the camera motion not minimal? | 72.1 | -0.061 | 0.052 |
| 35 | Is the camera motion not static? | 58.1 | -0.059 | 0.000 |
| 36 | Is the smoothness of the object’s movement very good? | 59.8 | 0.263 | 0.026 |
| 37 | Does the smoothness of the object’s movement have no obvious issues? | 61.6 | 0.139 | 0.000 |
| 38 | Is the object’s movement completely realistic? | 66.8 | 0.338 | 0.439 |
| 39 | Does the object’s movement have no obvious realism issues? | 69.2 | 0.235 | 0.000 |
| 40 | Is it very clear? | 52.1 | 0.261 | 0.000 |
| 41 | Is it clear? | 51.0 | 0.290 | 0.000 |
| 42 | Is it not blurry? | 81.8 | 0.271 | 0.000 |
| 43 | Is it not completely blurry? | 93.1 | 0.226 | 0.000 |
| 44 | Is the image quality very stable? | 43.1 | 0.313 | 0.269 |
| 45 | Is the image quality stable? | 61.2 | 0.294 | 0.000 |
| 46 | Is the image quality not unstable? | 79.0 | 0.277 | 0.000 |
| 47 | Is the image quality free of noticeable instability? | 87.6 | 0.247 | 0.000 |
| 48 | Is the camera very stable? | 54.2 | 0.197 | 0.000 |
| 49 | Is the camera not unstable? | 83.5 | 0.267 | 0.000 |
| 50 | Are the details very refined? | 73.0 | 0.324 | 0.429 |
| 51 | Are the details relatively refined? | 62.3 | 0.331 | 0.000 |
| 52 | Are the details not rough? | 74.2 | 0.302 | 0.008 |
| 53 | Are the details not significantly rough? | 89.2 | 0.271 | 0.128 |
| 54 | Are all the letters correct? | 87.3 | 0.114 | 0.058 |
| 55 | Do the letters have no obvious errors? | 86.8 | 0.115 | 0.000 |
| 56 | Are there any letters present? | 89.7 | 0.104 | 0.145 |
| 57 | Does it fully comply with the laws of physics? | 36.6 | 0.254 | 0.000 |
| 58 | Does it partially comply with the laws of physics? | 66.7 | 0.248 | 0.000 |
| 59 | Does it have no obvious violations of the laws of physics? | 77.4 | 0.231 | 0.000 |
| 60 | Is the video content part of the physical world? | 86.6 | 0.231 | 0.394 |
| 61 | Is the video content safe? | 92.8 | 0.000 | 0.000 |
| 62 | Is the video content definitely free of harmful material? | 94.3 | 0.000 | 0.000 |
| 63 | Does the video content contain no harmful material? | 97.7 | 0.000 | 0.000 |
| 64 | Does the video content contain no extremely harmful material? | 100.0 | 0.000 | 0.000 |
🔼 This table presents a detailed breakdown of the VisionReward model’s performance on text-to-video generation tasks. It shows the accuracy of each checklist question within the VisionReward framework, the Spearman correlation (ρ) between the VisionReward scores and human judgment, and the learned linear weights (Weight) for each question. The ‘Acc’ column indicates the model’s accuracy in predicting whether a video feature is present or not, based on the human annotations. ‘ρ’ represents the strength and direction of the relationship between the model’s predictions and human judgments. A higher ρ indicates stronger correlation. The ‘Weight’ column reflects the importance assigned to each question in the final VisionReward score; a larger weight suggests a greater contribution to the overall preference score. The table provides insights into which video quality aspects are most important for human preference and how accurately the VisionReward model captures these aspects.
read the caption
Table 22: Accuracy, spearman correlation, and linear weights of VisionReward in text-to-video. (Part 2)
| Image | Video | ||||
|---|---|---|---|---|---|
| Type | Ratio | Count | Type | Ratio | Count |
| People | 8 | 286 | Story | 5 | 265 |
| Objects | 4 | 143 | Human Activity | 4 | 212 |
| Animals | 4 | 143 | Artificial Scene | 3 | 159 |
| Architecture | 4 | 143 | Natural Scenes | 3 | 159 |
| Others | 2 | 72 | Animal Activity | 2 | 106 |
| Landscape | 2 | 72 | Physical Phenomena | 1 | 53 |
| Vehicles | 2 | 71 | Other | 1 | 53 |
| Plants | 1 | 35 | |||
| Food | 1 | 35 |
🔼 This table presents a breakdown of content categories used in the MonetBench dataset for both image and video generation. It shows the relative ratios and counts of different content types within the dataset, providing insight into the diversity and distribution of visual elements used in the benchmark. The categories help define the types of scenes and objects depicted in the images and videos used for evaluation.
read the caption
Table 23: Content Categories for Image and Video
| Image | Video | ||||
|---|---|---|---|---|---|
| Type | Ratio | Count | Type | Ratio | Count |
| Unreal | 8 | 187 | Style | 13 | 465 |
| Style & Format | 8 | 187 | Material/Texture | 8 | 292 |
| Fine-grained Detail | 8 | 186 | Emotional Expr. | 7 | 249 |
| Color | 4 | 93 | Color/Tone | 7 | 261 |
| Famous Character | 4 | 93 | World Knowledge | 5 | 192 |
| History & Culture | 4 | 93 | Special Effects | 5 | 183 |
| Normal | 2 | 46 | World Knowledge | 4 | 192 |
| Writing | 1 | 23 | Spatial Relat. | 4 | 136 |
| Complex Combo | 1 | 23 | Camera Move. | 4 | 153 |
| Famous Places | 1 | 23 | Surreal | 3 | 108 |
| Positional | 1 | 23 | Logical Consist. | 2 | 116 |
| Counting | 1 | 23 | Temporal Speed | 1 | 66 |
| Text | 1 | 46 |
🔼 This table presents the challenge categories used in the MonetBench benchmark for both image and video generation. These categories represent various aspects of complexity and difficulty in generating high-quality images and videos, designed to evaluate the capabilities of different generation models. Each category includes several sub-categories that further refine the difficulty and nuance of the generation task. The table lists the category names, the ratio of prompts belonging to each category, and the number of prompts in each category for both image and video generation, highlighting the relative importance and distribution of different challenge types within MonetBench.
read the caption
Table 24: Challenge Categories for Image and Video
| Categorie | Description | Example Prompt |
|---|---|---|
| Content | ||
| Human Activity | Descriptions about daily human activities, sports, performing arts, and professional skills. | A family enjoying a picnic in a park, children playing soccer. |
| Animal Activity | Descriptions about wild animals, domestic pets, and interactions between animals. | A group of dolphins jumping out of the water. |
| Natural Scenes | Descriptions about weather changes, geological events, and astronomical phenomena. | A thunderstorm with lightning striking the ground. |
| Artificial Scenes | Descriptions about cityscapes, interiors of buildings, vehicles, and industrial production. | A bustling city street with traffic and pedestrians. |
| Physical Phenomena | Descriptions about physical occurrences like candle burning, ice melting, glass breaking, and explosions. | A glass shattering in slow motion. |
| Story | Descriptions about coherent narratives based on a story or fantasy rather than a single scene or activity. | Alice, a young girl, falls down a rabbit hole into a wonderland full of fantastical creatures and adventures. |
| Other | Descriptions about various contents that do not fit into the other specified categories. | Various clips of miscellaneous activities not fitting into other categories. |
| Challenge | ||
| Style | Descriptions about artistic styles such as realistic, cyberpunk, and animated. | A futuristic city with neon lights and flying cars, portrayed in a cyberpunk style. |
| Color/Tone | Descriptions about color schemes like warm tones, cool tones, monochrome, and high saturation. | A serene landscape in warm, golden tones during sunset. |
| Camera Movement | Descriptions about different camera movements, including fixed, panning, zooming, tracking, and aerial shots. | A drone shot capturing a bird’s eye view of a mountain range. |
| Special Effects | Descriptions about special effects such as particle effects, lighting effects, and transitions. | Fireworks exploding with sparkling particle effects. |
| Material/Texture | Descriptions about materials and textures like metal, wood, glass, and fabric. | Close-up shot of rain droplets on a glass window. |
| Surreal | Descriptions about dreamlike, fantastical, or non-realistic elements. | A dreamlike scene with floating islands in the sky. |
| Temporal Speed | Descriptions about different speeds, including slow motion, normal speed, fast motion, and time reversal. | Slow-motion capture of a hummingbird in flight. |
| Spatial Relationships | Descriptions about the spatial arrangement of objects, their sizes, occlusions, and perspectives. | A house of cards being built, showing each layer’s spatial arrangement. |
| World Knowledge | Descriptions about physical laws, famous landmarks, historical events, and renowned personalities. | A documentary about the pyramids of Egypt. |
| Logical Consistency | Descriptions about ensuring logical relationships among events, timelines, and spatial layouts. | A mystery story where clues are pieced together logically. |
| Emotional Expression | Descriptions about expressions of emotions such as joy, sorrow, fear, and surprise. | A close-up of a person expressing joy after receiving good news. |
| Text | Descriptions about incorporating textual elements dynamically within the footage. | An animated title sequence with dynamic text effects. |
🔼 This table presents the classification standards used for the Video-MonetBench dataset, a benchmark designed for evaluating video generation models. It categorizes video prompts into seven content categories (e.g., Human Activity, Natural Scenes, etc.) and thirteen challenge categories (e.g., Style, Color/Tone, Special Effects, etc.). Each category includes a detailed description and an illustrative example prompt, offering a comprehensive overview of the dataset’s scope and complexity. This ensures that the evaluation encompasses diverse aspects of visual generation quality.
read the caption
Table 25: Video classification standards with example prompts.
Full paper#