↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Consistent image editing across various images is a challenging task due to factors like object poses, lighting conditions, and diverse environments. Existing methods often struggle with maintaining uniformity and high quality. Some approaches rely on learning-based methods, needing paired training data and often resulting in inconsistent edits. Others use implicit correspondence, which is less accurate and struggles with variations between images.
This paper introduces Edicho, a training-free solution that uses explicit image correspondence to guide the editing process. The key components are an attention manipulation module and a classifier-free guidance denoising strategy, both leveraging the pre-estimated correspondence. Edicho demonstrates effectiveness in consistent cross-image editing across diverse settings, offering a plug-and-play solution compatible with most diffusion-based editing methods. The training-free nature and superior consistency compared to existing approaches are significant contributions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, training-free method for consistent image editing across multiple images. This addresses a significant challenge in computer vision, enabling various applications such as creating visual narratives, marketing materials, and personalized content. The training-free aspect makes it widely accessible and adaptable, opening avenues for future research in cross-image editing techniques and customization.
Visual Insights#

🔼 This figure demonstrates the capabilities of the Edicho model. Given two input images (unedited versions), Edicho performs consistent zero-shot editing across both images. The results show the model’s ability to precisely edit different image components: small parts (left column), larger objects (middle column), and entire scene edits (right column). The consistency is achieved through the use of explicit correspondence between the images, ensuring that the edits are harmoniously applied in each image.
read the caption
Figure 1: Given two images in the wild, Edicho generates consistent editing versions of them in a zero-shot manner. Our approach achieves precise consistency for editing parts (left), objects (middle), and the entire images (right) by leveraging explicit correspondence.
| Method | TA ↑ | EC ↑ |
|---|---|---|
| AF [45] | 0.3082 | 0.8569 |
| AD [12] | 0.2981 | 0.8320 |
| PBE [58] | 0.2969 | 0.8683 |
| Ours | 0.3176 | 0.8931 |
🔼 This table presents a quantitative comparison of different image editing methods, evaluating their performance on both local (inpainting) and global (image translation) editing tasks. The evaluation metrics used are Text Alignment (TA) and Editing Consistency (EC), following the approach of Custom Diffusion [31]. Higher scores indicate better performance. The methods compared include Adobe Firefly, Anydoor, Paint-by-Example, MasaCtrl, StyleAligned, Cross-Image Attention, and the authors’ proposed method. The results provide a numerical assessment of each method’s ability to generate consistent and textually aligned edits.
read the caption
Table 1: Quantitative results respectively on local and global editing. We follow Custom Diffusion [31] to evaluate various methods on text alignment (TA) and editing consistency (EC).
In-depth insights#
Wild Image Edits#
The concept of “Wild Image Edits” points to a significant challenge and opportunity in image editing: handling inconsistencies across diverse, real-world images. The ‘wild’ aspect emphasizes the variability in lighting, backgrounds, viewpoints, and object poses, making consistent editing across multiple images incredibly difficult. Traditional per-image editing techniques fail in this scenario because they lack the ability to establish and maintain uniformity across different image contexts. A successful approach to wild image edits requires robust methods for establishing correspondences between images, accurately transferring edits while preserving image quality and handling variations in appearance. Explicit correspondence prediction, as opposed to relying on implicit methods derived from attention features, seems to be a promising technique for achieving precise and consistent edits, even across significantly different images. The ability to leverage pre-trained models and incorporate explicit correspondences into the editing process, while maintaining efficiency, would represent a major advance. Successful wild image edits represent a substantial step towards more realistic and versatile image manipulation, impacting various fields from marketing to creative content generation.
Diffusion Model Use#
The research paper leverages diffusion models as the foundation for image editing. It moves beyond simply applying diffusion models to individual images and instead focuses on achieving consistent edits across multiple images. This is a significant departure from previous methods that often result in inconsistencies due to varying factors like lighting, pose, or environment. The authors cleverly utilize a training-free approach, relying on explicit correspondence estimations between images to guide the diffusion process. This approach makes the method readily adaptable to diverse image datasets without extensive retraining, a key advantage over learning-based alternatives. The use of diffusion models is instrumental in handling the complex transformations involved in image editing, allowing for generation of highly realistic and consistent results. Explicit correspondence estimation, a crucial element of the workflow, allows for precise feature transfer and avoids the inconsistencies often arising from reliance on implicit or approximate correspondence. The combination of diffusion models and explicit correspondence forms the core innovation enabling consistent cross-image editing.
Explicit Correspondence#
The concept of “Explicit Correspondence” in image editing is crucial for achieving consistent results across multiple images. It represents a paradigm shift from methods relying on implicit correspondences derived from attention mechanisms. Implicit methods often struggle with variations in pose, lighting, and background, leading to inconsistencies. Explicit correspondence, however, directly predicts and leverages feature correspondences between images before the editing process. This allows for a more precise and controlled transfer of edits, ensuring uniformity across diverse images. By directly aligning features based on pre-computed correspondences, the method avoids the inherent instability and inaccuracy often associated with relying on implicitly derived relationships. This training-free approach is particularly valuable as it enhances the efficiency and adaptability of existing diffusion models. The improved consistency makes it suitable for a wide range of applications, including creating harmonized sets of images for marketing or consistent edits in multi-image narratives.
Consistent Editing#
Consistent image editing, a crucial aspect in computer vision, aims to replicate edits across multiple images while maintaining uniformity. Challenges arise from variations in object poses, lighting, and environments. Existing methods often struggle with this, producing inconsistent results due to reliance on implicit correspondence or per-image processing. Explicit correspondence, using techniques that directly map features between images, offers a significant advantage. This approach enables precise transfer of edits, resulting in higher quality and consistency compared to methods relying on implicit feature alignment. Training-free methods, based on diffusion models, further enhance the efficiency and applicability of consistent editing. By leveraging explicit correspondences, these methods can be easily adapted to various diffusion-based editing models. The combination of explicit correspondence and training-free techniques proves to be a powerful approach for achieving high-quality and consistent image edits across diverse, real-world scenarios.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of consistent image editing, this would involve progressively disabling key features—such as explicit correspondence prediction, the correspondence-guided attention mechanism, or the classifier-free guidance (CFG) with correspondence—to isolate their effects on the model’s performance. By observing how performance metrics (e.g., quantitative measures of editing consistency and text alignment, qualitative assessments of edit quality) degrade with each ablation, researchers gain valuable insight into the relative importance of each component. A well-designed ablation study is crucial for understanding the model’s inner workings and identifying which components are essential for achieving consistent image edits across diverse images. The results highlight which features contribute most significantly to the model’s success and indicate areas for potential improvement or simplification. It helps determine whether a complex model is truly necessary or if a simpler, more efficient version can be developed while maintaining performance.
More visual insights#
More on figures

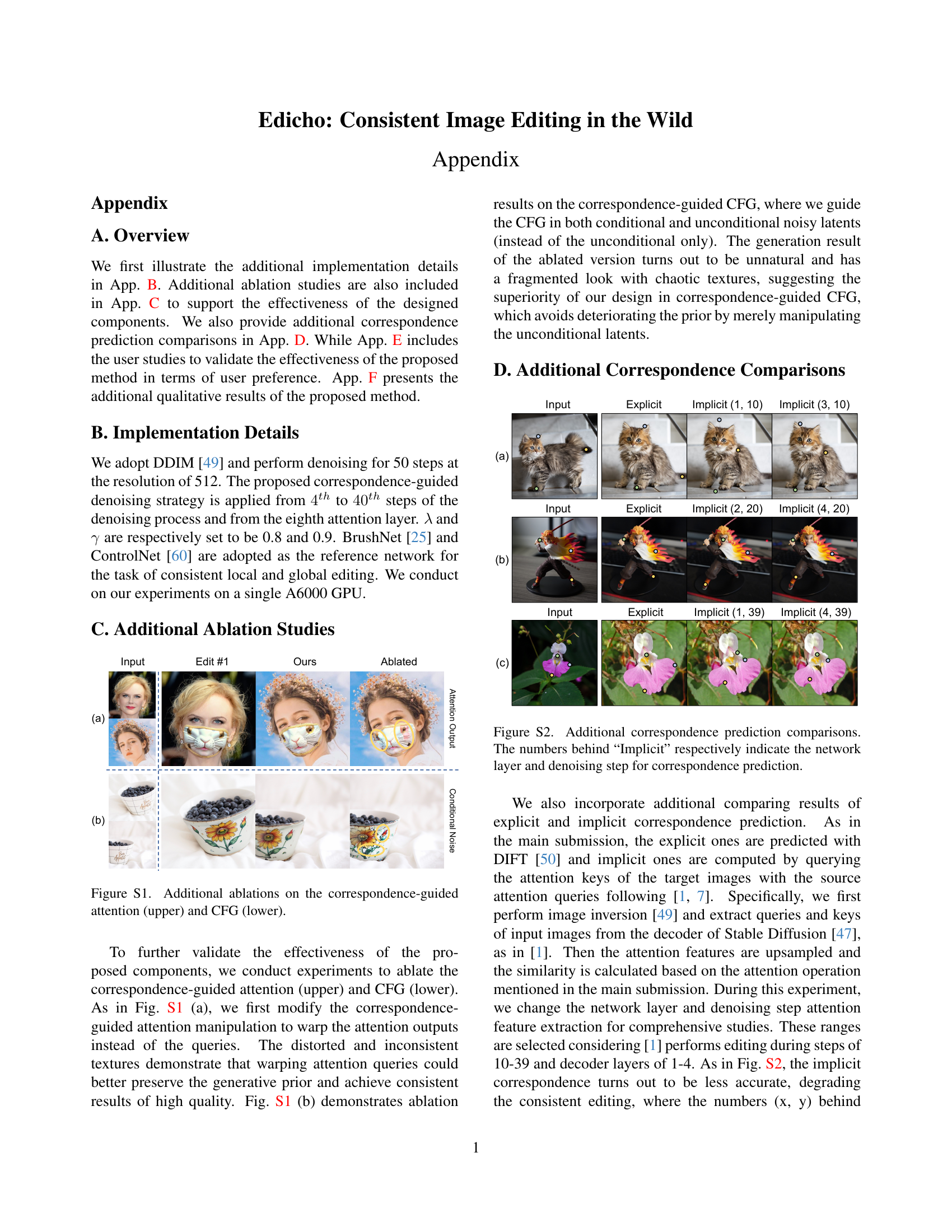
🔼 Figure 2 shows a comparison of implicit versus explicit correspondence prediction methods for images from diverse, real-world sources. The left column shows the input images. The middle column demonstrates the results using an explicit correspondence prediction method. The rightmost columns show results using implicit methods. The implicit method is less accurate and its results are less consistent as the denoising step and network layer change. This highlights the advantage of the explicit method, which produces more stable and accurate correspondence.
read the caption
Figure 2: Comparisons of the implicit and our explicit correspondence prediction for the images in the wild. The implicit correspondence from cross-image attention calculation is less accurate and unstable with the change of denoising steps and network layers.

🔼 Edicho’s framework for consistent image editing involves two main steps. First, explicit correspondence between input images is predicted using extractors. Then, this pre-computed correspondence is integrated into pre-trained diffusion models to guide the denoising process at two levels: (a) attention features and (b) noisy latents within the Classifier-free Guidance (CFG) method. This dual-level approach ensures consistency across multiple images.
read the caption
Figure 3: Framework of Edicho. To achieve consistent editing, we first predict the explicit correspondence with extractors for the input images. The pre-computed correspondence is injected into the pre-trained diffusion models and guide the denoising in the two levels of (a) attention features and (b) noisy latents in CFG.

🔼 Figure 4 presents a qualitative comparison of local image editing results using four different methods: the proposed approach, Adobe Firefly, Anydoor, and Paint-by-Example. The figure showcases several examples where a small area of the input image has been edited. The inpainted areas are highlighted in red to clearly distinguish the modified portions from the original image. This comparison highlights the differences in the quality and consistency of the inpainting performed by each method when editing various types of images, including faces, animals, and shoes.
read the caption
Figure 4: Qualitative comparisons on local editing with Adobe Firefly (AF) [45], Anydoor (AD) [12], and Paint-by-Example (PBE) [58]. The inpainted areas of the inputs are highlighted in red.

🔼 Figure 5 presents a qualitative comparison of global image editing results using four different methods: the proposed method and three existing methods, MasaCtrl (MC) [7], StyleAligned (SA) [18], and Cross-Image-Attention (CIA) [1]. Each row shows the input image and the results generated by each method for a specific editing task, using the same text prompt for all methods. This allows for a visual comparison of the consistency and quality of the edits across different approaches. The figure demonstrates how the proposed method achieves more consistent and natural-looking results than the existing baselines.
read the caption
Figure 5: Qualitative comparisons on global editing with MasaCtrl (MC) [7], StyleAligned (SA) [18], and Cross-Image-Attention (CIA) [1].

🔼 This figure shows the ablation study results for the proposed method, Edicho. It compares the performance of Edicho with and without two key components: (a) correspondence-guided attention manipulation (Corr-Attention) and (b) correspondence-guided classifier-free guidance (Corr-CFG). The images visually demonstrate the impact of removing each component on the quality and consistency of the image editing results. By comparing the edited images with and without these components, we can assess their individual contributions to the overall performance of the Edicho method.
read the caption
Figure 6: Ablation studies on the (a) correspondence-guided attention manipulation (Corr-Attention) and (b) correspondence-guided CFG (Corr-CFG).

🔼 This figure demonstrates the application of consistent image editing to enable customized image generation. The top row shows the results of consistent editing applied to a set of images. These edited images are then used as input for a customization technique (DreamBooth [48]), which fine-tunes a generative model to learn the new concepts represented in the edited images. The bottom row showcases the customized generations produced by the fine-tuned model, highlighting how consistent editing improves the quality and consistency of the newly generated images.
read the caption
Figure 7: With outputs from our consistent editing method (upper) and the customization [48] techniques, customized generation (lower) could be achieved by injecting the edited concepts into the generative model.

🔼 This figure demonstrates the application of the Edicho method to 3D reconstruction. The Edicho method, having performed consistent image editing, utilizes the neural regressor Dust3R to generate 3D models. This is achieved by matching corresponding 2D points across multiple edited images, mapping them into a common 3D space to create a 3D representation of the edited scene. The figure visually displays this process, showing input images, the consistent edits, and the resulting 3D reconstructions.
read the caption
Figure 8: We adopt the neural regressor Dust3R [55] for 3D reconstruction based on the edits by matching the 2D points in a 3D space.

🔼 Figure 9 showcases the versatility of the proposed consistent image editing method. Panel (a) presents examples of consistent inpainting, where missing parts of images are filled in a way that maintains consistency across multiple images. Panel (b) demonstrates consistent image translation, where the style or content of images is transformed consistently across multiple images. Finally, panel (c) illustrates how the method produces consistent edits across an entire set of three images.
read the caption
Figure 9: Diverse results of consistent image inpainting (a) and translation (b) by the proposed method. Editing results for an image set of three images are demonstrated in (c).

🔼 This figure shows the results of ablation studies conducted to evaluate the effectiveness of the correspondence-guided attention and correspondence-guided classifier-free guidance (CFG) mechanisms proposed in the paper. The upper part displays the impact of modifying the correspondence-guided attention mechanism by warping attention outputs instead of queries. The lower part shows the results of removing the correspondence-guided CFG, in which only the unconditional noisy latents are guided instead of both the conditional and unconditional latents. The results demonstrate that warping attention queries is essential for maintaining high-quality and consistent edits, while using correspondence guidance in both conditional and unconditional branches is crucial for preserving the generative priors and obtaining coherent edits.
read the caption
Figure S1: Additional ablations on the correspondence-guided attention (upper) and CFG (lower).

🔼 Figure S2 compares different methods for predicting image correspondences. It shows three examples of image pairs, each processed with an explicit correspondence method and two implicit methods. The implicit methods vary in the network layer and denoising step used for correspondence prediction, highlighting how these choices impact the accuracy of the predictions.
read the caption
Figure S2: Additional correspondence prediction comparisons. The numbers behind “Implicit” respectively indicate the network layer and denoising step for correspondence prediction.

🔼 Figure S3 shows a comparison of explicit and implicit correspondence prediction methods using attention visualization. It presents three examples, each displaying an input image alongside visualizations of explicit correspondence, and implicit correspondence at different network layers and denoising steps. Dashed circles highlight areas with the highest attention weights in the implicit methods. This visualization demonstrates the difference in accuracy and consistency between the explicit and implicit approaches in predicting correspondences.
read the caption
Figure S3: Additional correspondence prediction results with attention visualization. Regions with the highest attention weights are outlined with dashed circles.

🔼 This figure presents the results of user studies comparing the performance of Edicho against other methods in both local and global image editing tasks. Participants rated the results based on criteria such as consistency of edits across multiple images, overall quality of the generated images, and how well the edits adhered to the given instructions. The bar charts illustrate the percentage of participants who preferred Edicho for each task, showing a significant preference for Edicho over competing methods.
read the caption
Figure S4: User study results of consistent local editing (left) and global editing (right).
Full paper#