↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Adapting large language models (LLMs) to new languages is computationally expensive and often requires substantial amounts of high-quality training data, which can be difficult to acquire. Existing methods often involve retraining the entire model, which is resource-intensive and time-consuming. This limits the accessibility of multilingual LLMs, especially to researchers with limited resources.
This research introduces a novel method called Learned Embedding Propagation (LEP) that efficiently addresses these issues. LEP avoids the need for extensive instruction-tuning by employing an innovative embedding propagation technique. This approach significantly reduces both the computational cost and data requirements for language adaptation, allowing for more efficient and accessible development of multilingual LLMs. Experiments show LEP achieves comparable performance to existing state-of-the-art methods, even exceeding them in some cases.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, cost-effective method for adapting large language models to new languages. This is crucial given the high computational cost of traditional methods and the increasing demand for multilingual LLMs. The Learned Embedding Propagation (LEP) technique offers a significant advancement, enabling researchers to adapt models with minimal disruption of existing knowledge, thus opening new avenues for efficient multilingual model development and reducing the barrier to entry for researchers with limited computational resources.
Visual Insights#

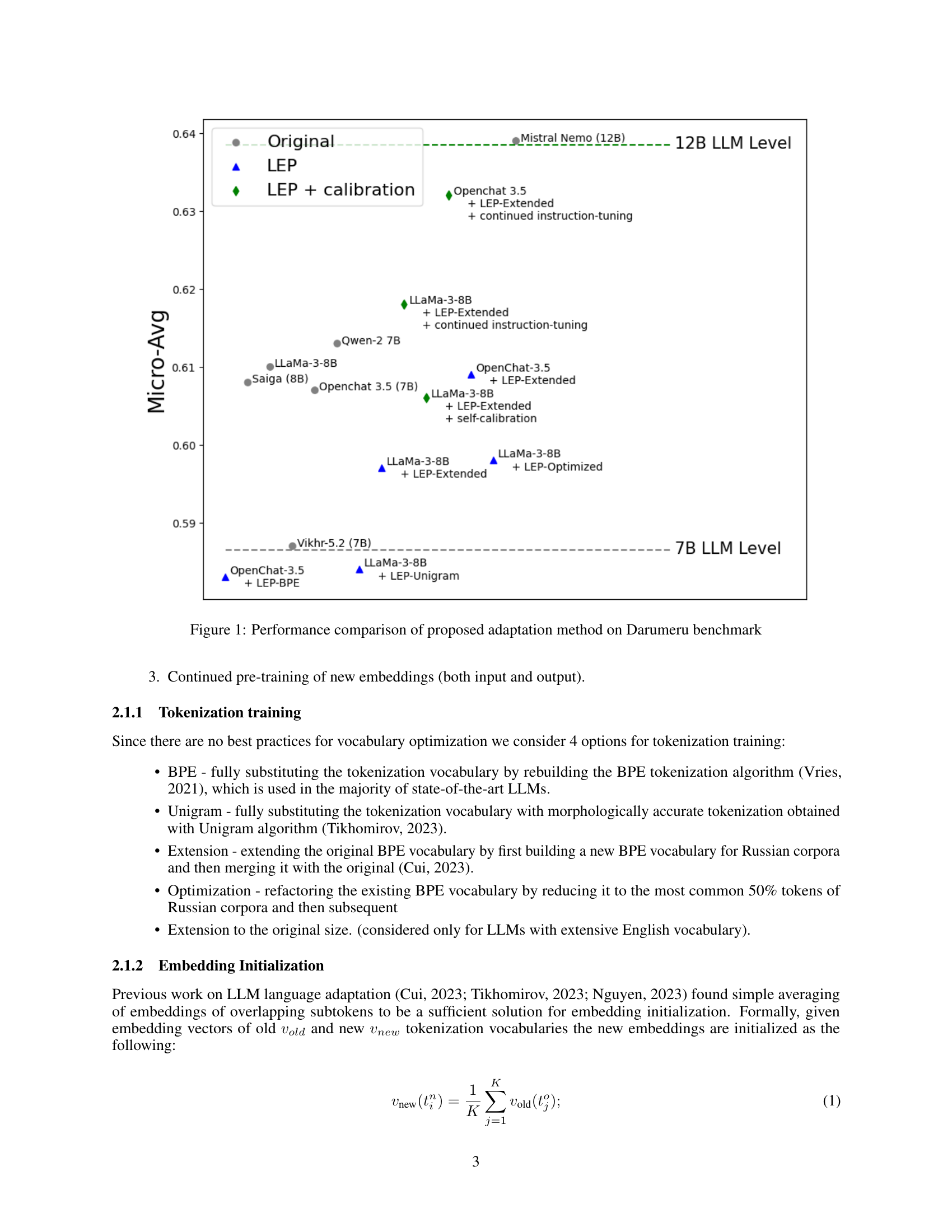
🔼 This figure displays the performance comparison results of the proposed Learned Embedding Propagation (LEP) method against several other state-of-the-art LLMs on the Darumeru benchmark. The benchmark focuses on evaluating text generation robustness, particularly for Russian language adaptation. The graph showcases the Micro-Avg scores (a combined metric) for different models, including the original models (LLaMa-3-8B and Mistral-7B), the models adapted using the LEP method with various configurations and calibration methods, as well as several other existing open-source and closed-source LLMs for reference. This allows for a direct comparison to see how the LEP method performs relative to other techniques.
read the caption
Figure 1: Performance comparison of proposed adaptation method on Darumeru benchmark
| Model | Micro-Avg | DaruMMLU | DaruMERA | DaruSum | DaruCopy (EN) | DaruCopy (RU) |
|---|---|---|---|---|---|---|
| Openchat 3.5 (Mistral-7B) | 0,607 | 0,543 | 0,526 | 0,322 | 0,999 | 0,917 |
| LLaMa-3-8B (Instruct) | 0,610 | 0,571 | 0,510 | 0,322 | 1,000 | 0,972 |
| Saiga (LLaMa-3-8B) | 0,608 | 0,574 | 0,514 | 0,320 | 0,995 | 0,939 |
| Vikhr-5.2 (Mistral-7B) | 0,587 | 0,494 | 0,573 | 0,308 | 0,959 | 0,693 |
| Qwen-2 7B | 0,613 | 0,624 | 0,548 | 0,300 | 0,938 | 0,842 |
| Mistral Nemo (12B) | 0,639 | 0,592 | 0,576 | 0,320 | 0,998 | 0,924 |
| Ours | ||||||
| Openchat 3.5 + LEP-Extended + calibration (best) | 0,632↑ | 0,541 | 0,563↑ | 0,321 | 1,000 | 0,989↑ |
| LLaMa-3-8B (Instruct) + LEP-Extended + calibration (best) | 0,618↑ | 0,565↓ | 0,521↑ | 0,339↑ | 1,000 | 0,984↑ |
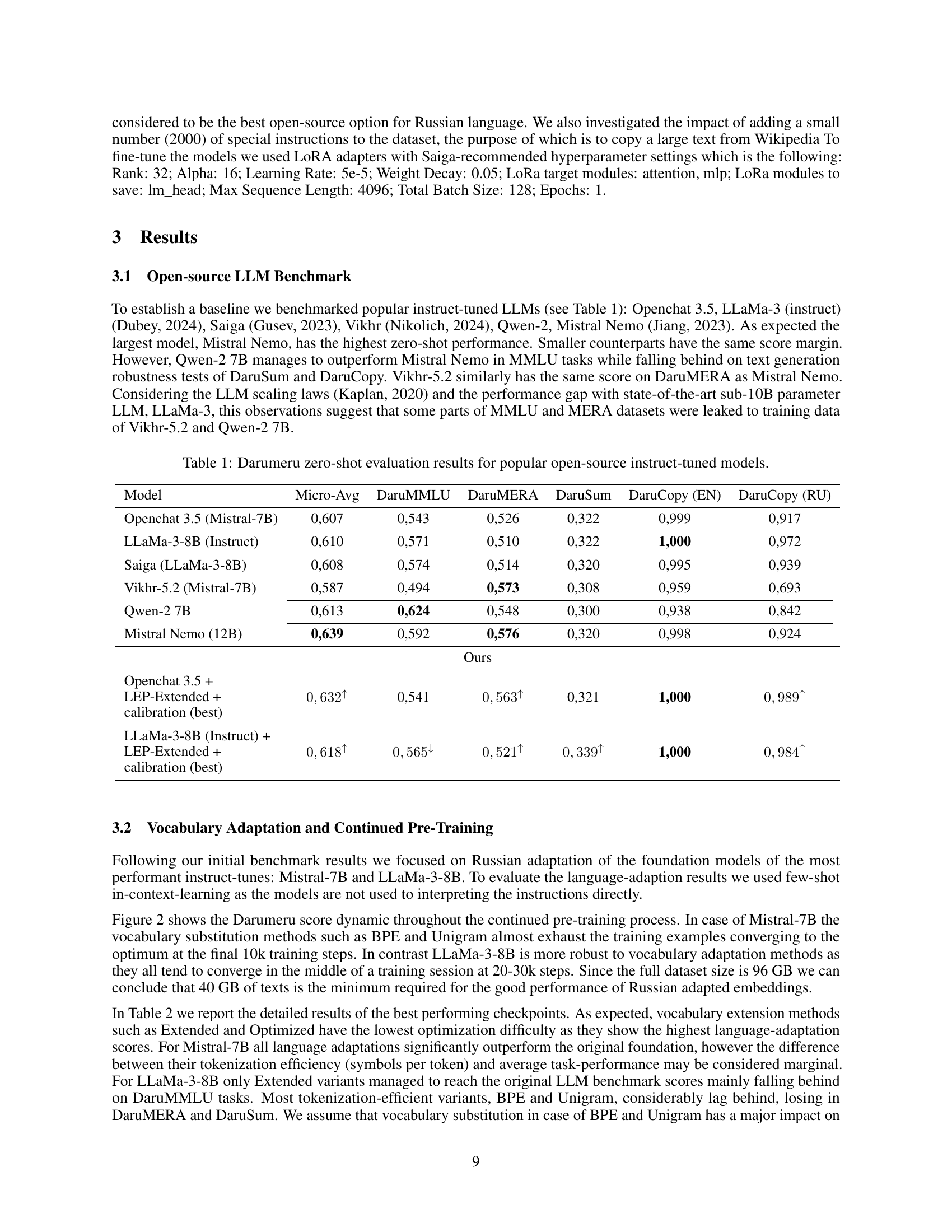
🔼 This table presents the zero-shot performance of several popular open-source, instruction-tuned large language models (LLMs) on the Darumeru benchmark. Darumeru is a newly developed benchmark designed to evaluate Russian language capabilities, encompassing a variety of tasks including multiple-choice questions, text comprehension, text summarization, and text generation. The table shows the average performance across all Darumeru sub-tasks (Micro-Avg) and individual task scores for each LLM.
read the caption
Table 1: Darumeru zero-shot evaluation results for popular open-source instruct-tuned models.
In-depth insights#
LEP: Core Method#
The core of the Learned Embedding Propagation (LEP) method lies in its innovative approach to adapting Large Language Models (LLMs) for new languages. Instead of computationally expensive and data-intensive traditional methods like instruction-tuning, LEP leverages an embedding propagation technique. This involves cleverly transferring knowledge from an existing, well-trained LLM into a new, language-specific model by manipulating its embedding layer. This is a significant departure from full LLM adaptation, reducing training data requirements and computational costs. The method elegantly bypasses the need for extensive instruction-tuning data by directly integrating new language knowledge into the existing model. Key to LEP’s efficiency is its minimal disruption of the existing LLM knowledge, enabling adaptation without a complete retraining process. The effectiveness hinges upon the careful alignment of embeddings between the original and adapted models, achieved through various sophisticated initialization strategies and propagation techniques. The method’s novelty lies in its cost-effective and efficient adaptation pipeline, promising improvements in task solving for language adaptation while maintaining or exceeding performance benchmarks set by contemporary LLMs.
Russian LLM Adapt#
Adapting Large Language Models (LLMs) for Russian presents unique challenges due to the language’s rich morphology and relatively smaller digital footprint compared to English. A thoughtful approach to Russian LLM adaptation should consider several key aspects. Vocabulary optimization is crucial, as standard tokenization techniques may not capture the nuances of Russian morphology effectively. Methods like byte-pair encoding (BPE) might need adjustments or alternatives explored to handle word inflections better. Pre-training on high-quality Russian corpora is essential to imbue the model with adequate linguistic knowledge. The availability of such data is a limiting factor, necessitating careful data curation and the potential use of techniques to augment available data. Embedding initialization strategies significantly impact adaptation effectiveness. Simply averaging existing embeddings is an option but might not be sufficient. More sophisticated approaches might involve transfer learning from other multilingual models or training new embeddings that capture Russian-specific semantic relations. Finally, evaluation needs to be tailored to the specific characteristics of Russian. Existing English-centric benchmarks are unlikely to provide a complete picture of the model’s capabilities in Russian. Therefore, constructing a specialized Russian evaluation benchmark is essential. This benchmark should ideally cover a wide range of tasks relevant to real-world applications to thoroughly gauge the adapted model’s performance.
Benchmark: Darumeru#
The Darumeru benchmark, a crucial component of the research, addresses limitations in existing Russian-language LLMs evaluation. Its novel design provides access to evaluation data labels, unlike previous benchmarks, allowing for offline analysis and detailed error classification. This is vital for understanding LLM performance beyond simple ranking and for improving model training. Darumeru incorporates a diverse range of datasets encompassing various tasks such as question answering, text summarization, and text generation. This multifaceted approach offers a more comprehensive assessment of LLM capabilities, especially in terms of both text comprehension and generation robustness. The framework’s compatibility with various LLM types further enhances its value for broad applicability and comparison across different models. The inclusion of specific tasks such as DaruCopy (evaluating the ability of LLMs to accurately replicate text inputs) and DaruSum (assessing summarization capabilities) shows a thoughtful approach towards a comprehensive evaluation that goes beyond the typical zero-shot evaluation methods.
Calibration & Tuning#
The concept of “Calibration & Tuning” in the context of large language models (LLMs) centers on refining the model’s behavior to achieve optimal performance. Calibration focuses on aligning the model’s confidence scores with its actual accuracy. A well-calibrated model provides reliable confidence estimates, which are crucial for applications where trust and certainty are paramount. Miscalibration, where confidence doesn’t reflect performance, can lead to erroneous decision-making. Tuning, on the other hand, involves adjusting the model’s parameters using additional data or techniques to improve its performance on specific tasks. This can involve fine-tuning existing parameters or adding new layers. Effective tuning requires careful consideration of the data used, the tuning methodology employed, and evaluation metrics for assessing improvements. The interplay between calibration and tuning is significant; well-tuned models may still need calibration to ensure reliable confidence estimations. Optimizing both calibration and tuning can significantly boost LLM reliability and make them more suitable for real-world deployment in sensitive application domains.
LEP Limitations#
The Learned Embedding Propagation (LEP) method, while innovative, presents several limitations. Firstly, its reliance on both instructional and foundational LLM versions is a significant constraint. Not all models offer this dual availability, limiting LEP’s applicability. Secondly, the effectiveness of LEP may be challenged with languages employing hieroglyphs, where the lack of shared tokens between original and new vocabularies could hinder embedding alignment. Thirdly, the amount of transferred knowledge might be insufficient for optimal performance. While LEP successfully adapts the model, further continuous pretraining might be needed to achieve complete language acquisition. Finally, the LEP method’s dependence on the quality of the original LLM’s inherent knowledge, as determined by the instructional dataset used, influences its final performance. Models trained on high-quality proprietary data might show a more substantial performance gap after LEP adaptation than models with less sophisticated initial training data.
More visual insights#
More on figures

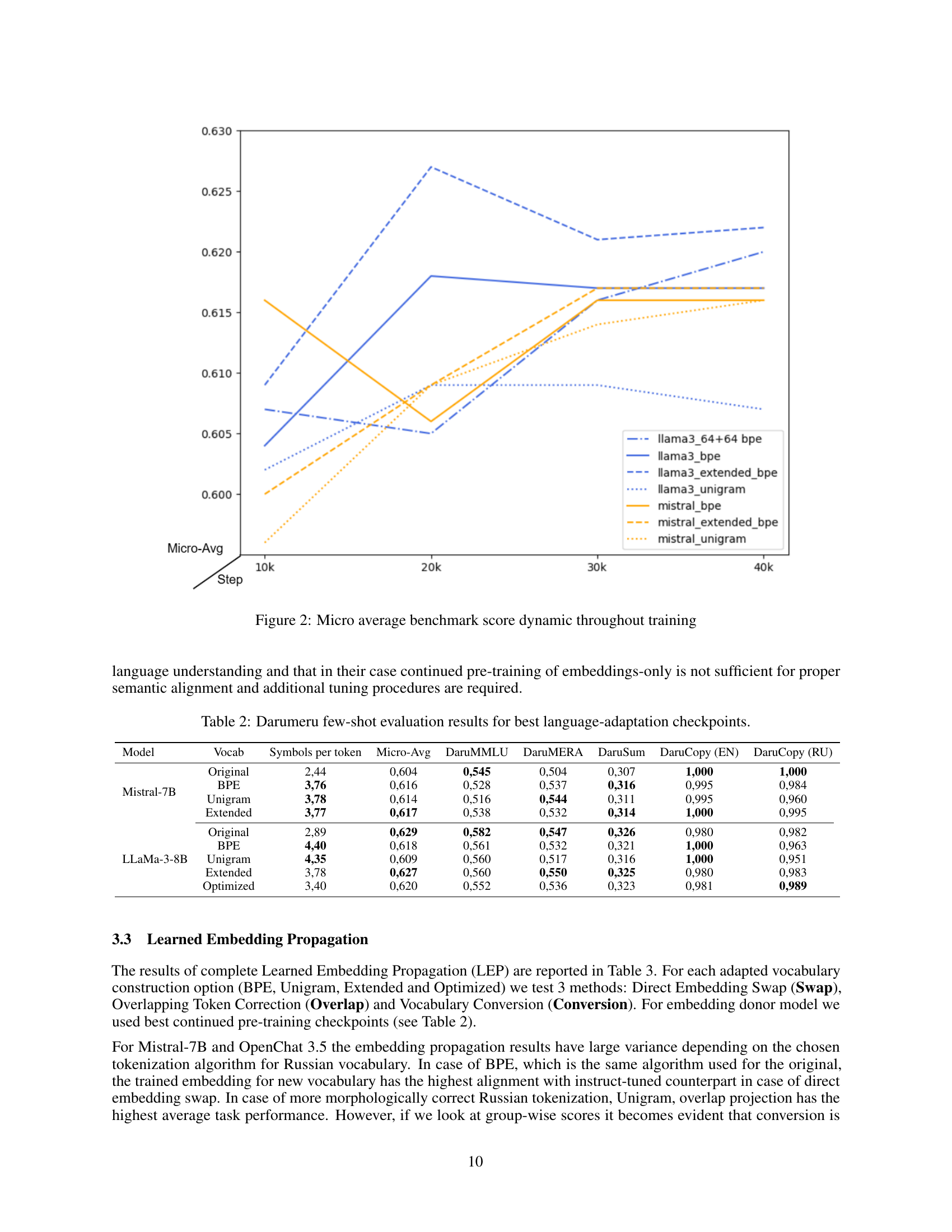
🔼 Figure 2 presents a line graph illustrating the change in the micro-average benchmark score across various training steps. The benchmark score, a composite metric representing overall performance, is plotted against the number of training steps. Multiple lines are shown, each representing a different combination of LLM model (LLaMa-3-8B or Mistral-7B) and vocabulary optimization technique (BPE, Unigram, Extended, or Optimized). This visualization allows for comparison of the training progress and performance achieved by various model and vocabulary combinations during the continued pre-training phase.
read the caption
Figure 2: Micro average benchmark score dynamic throughout training

🔼 This figure shows an example demonstrating the performance improvements of the proposed Learned Embedding Propagation (LEP) method. Three model outputs are shown, comparing the original OpenChat-3.5 model’s response to the same prompt against outputs from the LEP-adapted model and the LEP-adapted model after further self-calibration. The example highlights how the LEP method improves the model’s understanding and accuracy in handling phraseological units and nuanced language, showcasing the effectiveness of the approach.
read the caption
Figure 3: An example of generation using the OpenChat-3.5 model and its adapted versions.
More on tables
| Model | Vocab | Symbols per token | Micro-Avg | DaruMMLU | DaruMERA | DaruSum | DaruCopy (EN) | DaruCopy (RU) |
|---|---|---|---|---|---|---|---|---|
| Mistral-7B | Original | 2,44 | 0,604 | 0,545 | 0,504 | 0,307 | 1,000 | 1,000 |
| BPE | 3,76 | 0,616 | 0,528 | 0,537 | 0,316 | 0,995 | 0,984 | |
| Unigram | 3,78 | 0,614 | 0,544 | 0,311 | 0,995 | 0,960 | ||
| Extended | 3,77 | 0,617 | 0,532 | 0,314 | 1,000 | 0,995 | ||
| LLaMa-3-8B | Original | 2,89 | 0,629 | 0,582 | 0,547 | 0,326 | 0,980 | 0,982 |
| BPE | 4,40 | 0,618 | 0,532 | 0,321 | 1,000 | 0,963 | ||
| Unigram | 4,35 | 0,609 | 0,517 | 0,316 | 1,000 | 0,951 | ||
| Extended | 3,78 | 0,627 | 0,550 | 0,325 | 0,980 | 0,983 | ||
| Optimized | 3,40 | 0,620 | 0,552 | 0,536 | 0,323 | 0,981 | 0,989 |
🔼 This table presents the results of a few-shot evaluation on the Darumeru benchmark, which assesses the performance of language models on various tasks. Specifically, it shows the performance of different language adaptation methods for two large language models (LLMs), Mistral-7B and LLaMa-3-8B, after vocabulary optimization and continued pre-training. The metrics include Micro-Avg (average across all tasks), DaruMMLU, DaruMERA, DaruSum, DaruCopy (EN), and DaruCopy (RU), representing different benchmark subtasks focused on language understanding and generation capabilities. The table compares the original LLM’s performance with the performance after applying four distinct vocabulary adaptation techniques (BPE, Unigram, Extended, Optimized). Each method’s performance is quantified by the average score across all benchmark tasks, offering a comprehensive comparison of the efficacy of each approach for Russian language adaptation.
read the caption
Table 2: Darumeru few-shot evaluation results for best language-adaptation checkpoints.
| Vocab | LEP method | Micro-Avg | DaruMMLU | DaruMERA | DaruSum | DaruCopy (En) | DaruCopy (Ru) |
|---|---|---|---|---|---|---|---|
| OpenChat-3.5 | |||||||
| BPE | Swap | 0,587 | 0,528 | 0,526 | 0,277 | 0,988 | 0,829 |
| BPE | Overlap | 0,584 | 0,525 | 0,523 | 0,281 | 0,986 | 0,818 |
| BPE | Conversion | 0,583 | 0,526 | 0,524 | 0,284 | 0,993 | 0,791 |
| Unigram | Swap | 0,556 | 0,517 | 0,517 | 0,282 | 0,985 | 0,614 |
| Unigram | Overlap | 0,572 | 0,514 | 0,534 | 0,297 | 0,981 | 0,680 |
| Unigram | Conversion | 0,565 | 0,515 | 0,519 | 0,301 | 0,999 | 0,651 |
| Extended | Swap | 0,608 | 0,535 | 0,540 | 0,298 | 0,999 | 0,907 |
| Extended | Overlap | 0,607 | 0,535 | 0,539 | 0,307 | 0,999 | 0,898 |
| Extended | Conversion | 0,609 | 0,535 | 0,541 | 0,306 | 0,999 | 0,909 |
| LLaMa-3-8B (instruct) | |||||||
| BPE | Swap | 0,565 | 0,544 | 0,486 | 0,317 | 0,999 | 0,729 |
| BPE | Overlap | 0,569 | 0,546 | 0,489 | 0,314 | 0,999 | 0,753 |
| BPE | Conversion | 0,570 | 0,546 | 0,490 | 0,318 | 0,999 | 0,754 |
| Unigram | Swap | 0,582 | 0,545 | 0,488 | 0,313 | 0,999 | 0,865 |
| Unigram | Overlap | 0,580 | 0,545 | 0,482 | 0,314 | 0,999 | 0,876 |
| Unigram | Conversion | 0,584 | 0,545 | 0,488 | 0,315 | 0,994 | 0,889 |
| Extended | Swap | 0,592 | 0,557 | 0,498 | 0,319 | 0,969 | 0,921 |
| Extended | Overlap | 0,597 | 0,556 | 0,504 | 0,321 | 0,964 | 0,936 |
| Extended | Conversion | 0,597 | 0,556 | 0,501 | 0,318 | 0,994 | 0,921 |
| Optimized | Swap | 0,594 | 0,554 | 0,499 | 0,327 | 0,970 | 0,928 |
| Optimized | Overlap | 0,586 | 0,553 | 0,495 | 0,323 | 0,925 | 0,925 |
| Optimized | Conversion | 0,598 | 0,555 | 0,500 | 0,324 | 0,995 | 0,928 |
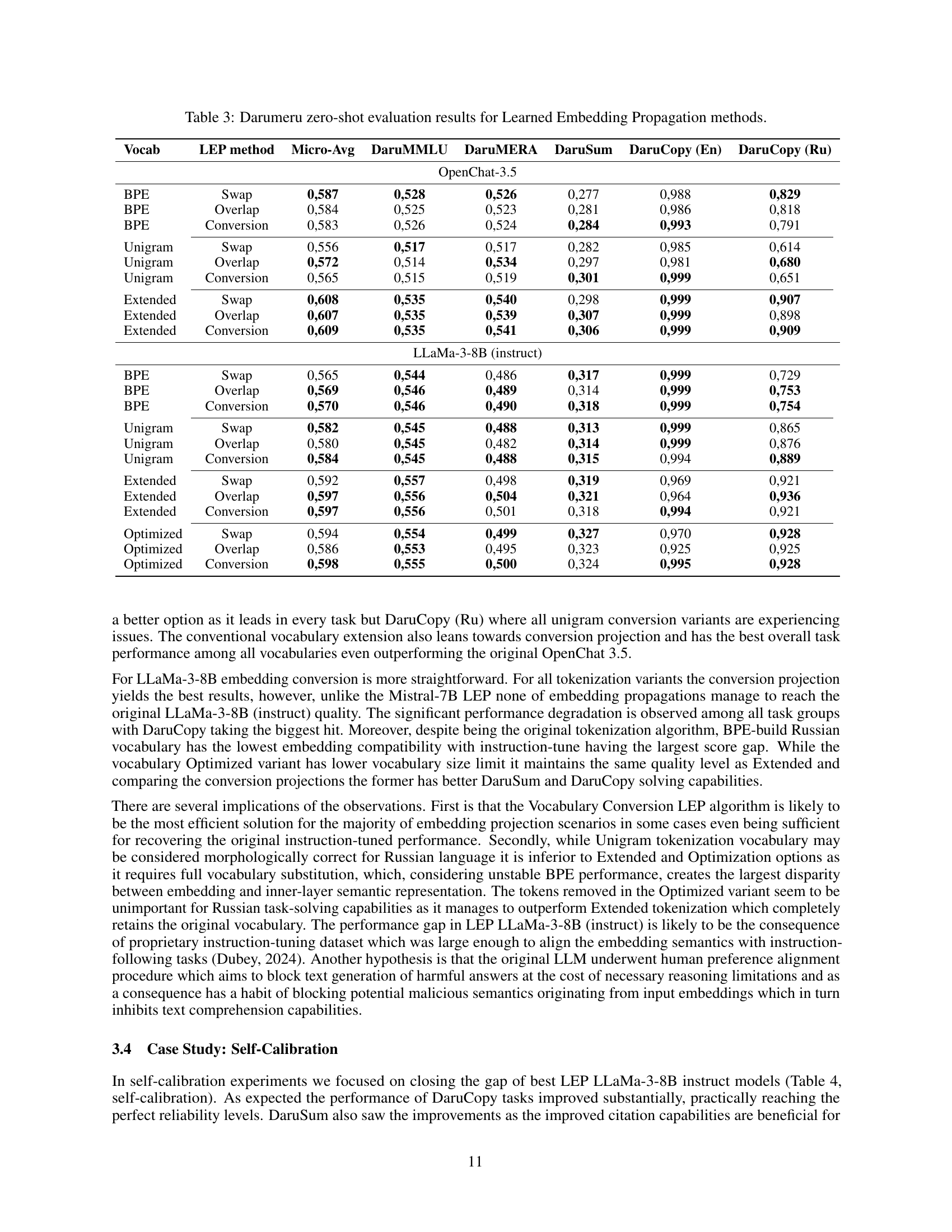
🔼 This table presents the results of a zero-shot evaluation using the Darumeru benchmark. The evaluation focuses on assessing the performance of the Learned Embedding Propagation (LEP) method for adapting language models. Different vocabulary adaptation techniques (BPE, Unigram, Extended, Optimized) are combined with three LEP methods (Swap, Overlap, Conversion). The results show the micro-averaged scores across multiple sub-benchmarks of Darumeru (DaruMMLU, DaruMERA, DaruSum, DaruCopy(EN), DaruCopy(RU)), providing a comprehensive comparison of the effectiveness of various LEP strategies under different vocabulary conditions for both OpenChat 3.5 and LLaMa-3-8B models.
read the caption
Table 3: Darumeru zero-shot evaluation results for Learned Embedding Propagation methods.
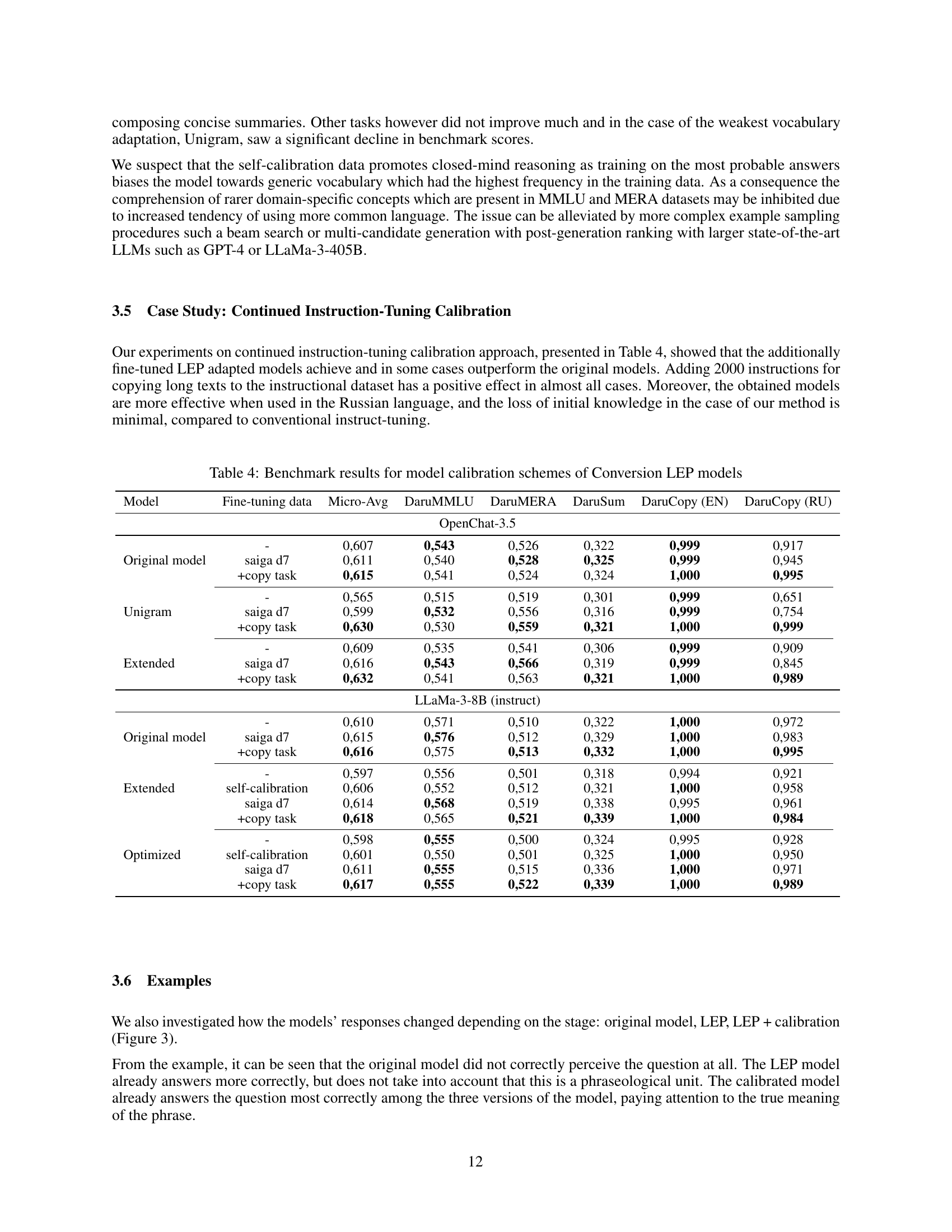
| Model | Fine-tuning data | Micro-Avg | DaruMMLU | DaruMERA | DaruSum | DaruCopy (EN) | DaruCopy (RU) |
|---|---|---|---|---|---|---|---|
| OpenChat-3.5 | |||||||
| Original model | - | 0,607 | 0,543 | 0,526 | 0,322 | 0,999 | 0,917 |
| saiga d7 | 0,611 | 0,540 | 0,528 | 0,325 | 0,999 | 0,945 | |
| +copy task | 0,615 | 0,541 | 0,524 | 0,324 | 1,000 | 0,995 | |
| Unigram | - | 0,565 | 0,515 | 0,519 | 0,301 | 0,999 | 0,651 |
| saiga d7 | 0,599 | 0,556 | 0,316 | 0,999 | 0,754 | ||
| +copy task | 0,630 | 0,559 | 0,321 | 1,000 | 0,999 | ||
| Extended | - | 0,609 | 0,535 | 0,541 | 0,306 | 0,999 | 0,909 |
| saiga d7 | 0,616 | 0,566 | 0,319 | 0,999 | 0,845 | ||
| +copy task | 0,632 | 0,563 | 0,321 | 1,000 | 0,989 | ||
| LLaMa-3-8B (instruct) | |||||||
| Original model | - | 0,610 | 0,571 | 0,510 | 0,322 | 1,000 | 0,972 |
| saiga d7 | 0,615 | 0,512 | 0,329 | 1,000 | 0,983 | ||
| +copy task | 0,616 | 0,513 | 0,332 | 1,000 | 0,995 | ||
| Extended | - | 0,597 | 0,556 | 0,501 | 0,318 | 0,994 | 0,921 |
| self-calibration | 0,606 | 0,552 | 0,512 | 0,321 | 1,000 | 0,958 | |
| saiga d7 | 0,614 | 0,519 | 0,338 | 0,995 | 0,961 | ||
| +copy task | 0,618 | 0,565 | 0,521 | 0,339 | 1,000 | 0,984 | |
| Optimized | - | 0,598 | 0,555 | 0,500 | 0,324 | 0,995 | 0,928 |
| self-calibration | 0,601 | 0,550 | 0,501 | 0,325 | 1,000 | 0,950 | |
| saiga d7 | 0,611 | 0,515 | 0,336 | 1,000 | 0,971 | ||
| +copy task | 0,617 | 0,555 | 0,522 | 0,339 | 1,000 | 0,989 |
🔼 This table presents the benchmark results comparing different model calibration methods applied to the Conversion LEP (Learned Embedding Propagation) models. It evaluates the performance of these models across several benchmarks (DaruMMLU, DaruMERA, DaruSum, DaruCopy (EN), and DaruCopy (RU)) to assess their effectiveness in language understanding and text generation tasks. The table shows the performance of the original model and then compares it to the results obtained using the Saiga dataset with and without an additional copy task. The results help analyze the impact of calibration techniques on the models’ overall performance and the influence of the additional copy task.
read the caption
Table 4: Benchmark results for model calibration schemes of Conversion LEP models
Full paper#