↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many current text embedding models using large language models (LLMs) are heavily focused on English, which limits their usefulness for other languages. This is a problem because many languages lack the large amounts of training data needed for effective LLMs. This paper introduces a new method called LUSIFER that aims to solve this problem.
LUSIFER is a unique zero-shot approach which leverages a multilingual encoder and a LLM-based embedding model. It uses a minimal set of trainable parameters to effectively transfer the multilingual encoder’s understanding to the embedding model. Experiments across 123 diverse datasets and 14 languages showed that LUSIFER significantly enhances multilingual performance, especially for low-resource languages. The results demonstrate that the method is very effective without requiring any additional multilingual training data.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the significant limitation of existing LLM-based embedding models, which primarily focus on English. LUSIFER’s zero-shot multilingual approach, which doesn’t require multilingual training data, opens new avenues for research in cross-lingual applications and low-resource language settings. Its introduction of a comprehensive multilingual benchmark further facilitates future research advancements in embedding techniques.
Visual Insights#

🔼 This figure illustrates the architecture and training process of the LUSIFER model. The left panel shows how a multilingual encoder is aligned with an English-centric Large Language Model (LLM) using only English data and a small number of trainable parameters. This alignment step allows the LLM to process multilingual information without explicit multilingual training. The center panel depicts the end-to-end fine-tuning of the model’s representation through contrastive learning using LoRA on English text embedding tasks. Finally, the right panel demonstrates the inference stage where the fully trained LUSIFER model successfully processes various text embedding tasks across multiple languages.
read the caption
Figure 1: Overview of LUSIFER. Left: Align a multilingual encoder with the target English-centric LLM only using English data and a minimal set of trainable parameter. Center: End-to-end representation finetune through contrastive learning on English text-embedding tasks using LoRA. Right: During inference, LUSIFER successfully processes text-embedding tasks across multiple languages.
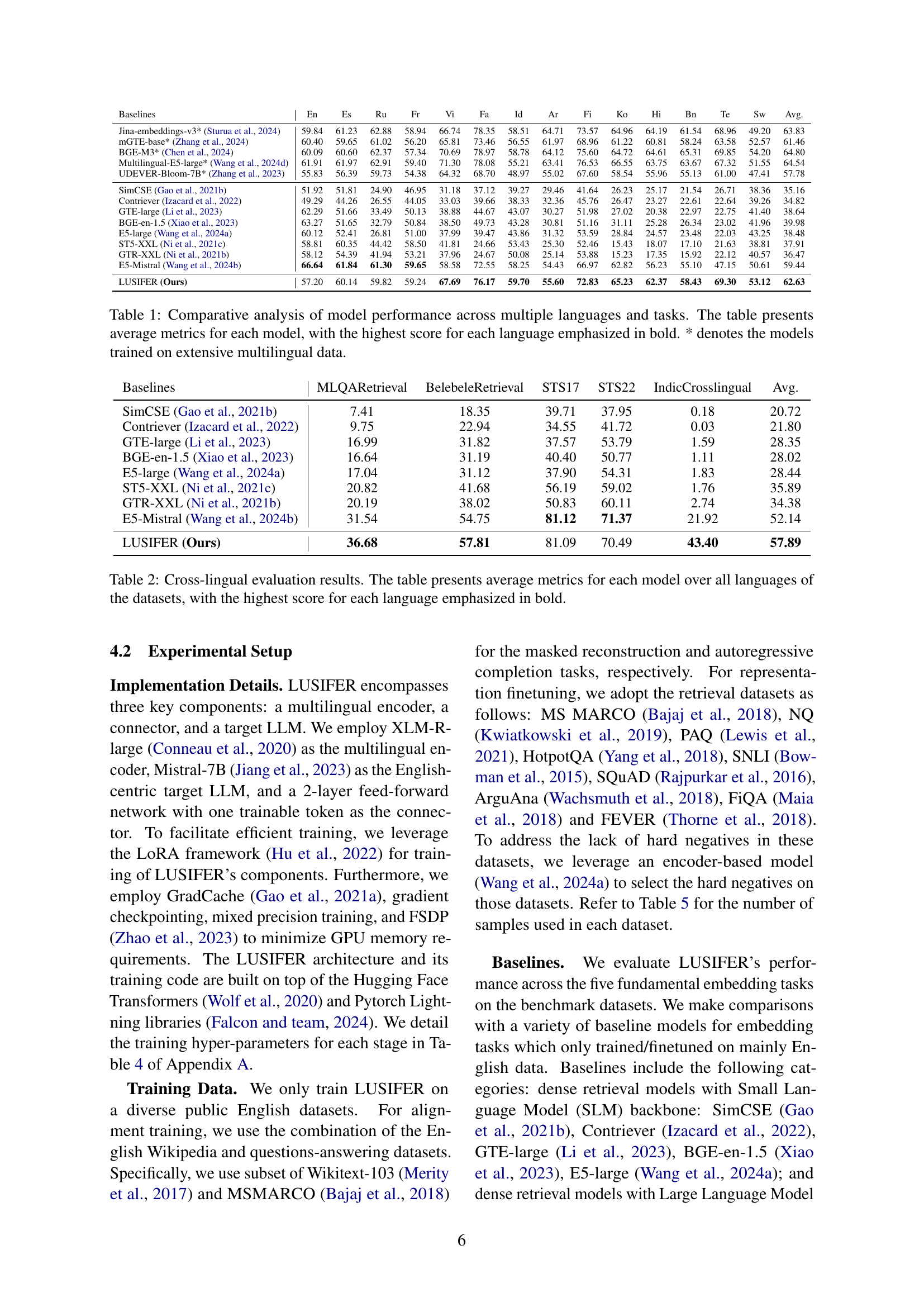
| Baselines | En | Es | Ru | Fr | Vi | Fa | Id | Ar | Fi | Ko | Hi | Bn | Te | Sw | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jina-embeddings-v3* Sturua et al. (2024) | 59.84 | 61.23 | 62.88 | 58.94 | 66.74 | 78.35 | 58.51 | 64.71 | 73.57 | 64.96 | 64.19 | 61.54 | 68.96 | 49.20 | 63.83 |
| mGTE-base* Zhang et al. (2024) | 60.40 | 59.65 | 61.02 | 56.20 | 65.81 | 73.46 | 56.55 | 61.97 | 68.96 | 61.22 | 60.81 | 58.24 | 63.58 | 52.57 | 61.46 |
| BGE-M3* Chen et al. (2024) | 60.09 | 60.60 | 62.37 | 57.34 | 70.69 | 78.97 | 58.78 | 64.12 | 75.60 | 64.72 | 64.61 | 65.31 | 69.85 | 54.20 | 64.80 |
| Multilingual-E5-large* Wang et al. (2024d) | 61.91 | 61.97 | 62.91 | 59.40 | 71.30 | 78.08 | 55.21 | 63.41 | 76.53 | 66.55 | 63.75 | 63.67 | 67.32 | 51.55 | 64.54 |
| UDEVER-Bloom-7B* Zhang et al. (2023) | 55.83 | 56.39 | 59.73 | 54.38 | 64.32 | 68.70 | 48.97 | 55.02 | 67.60 | 58.54 | 55.96 | 55.13 | 61.00 | 47.41 | 57.78 |
| SimCSE Gao et al. (2021b) | 51.92 | 51.81 | 24.90 | 46.95 | 31.18 | 37.12 | 39.27 | 29.46 | 41.64 | 26.23 | 25.17 | 21.54 | 26.71 | 38.36 | 35.16 |
| Contriever Izacard et al. (2022) | 49.29 | 44.26 | 26.55 | 44.05 | 33.03 | 39.66 | 38.33 | 32.36 | 45.76 | 26.47 | 23.27 | 22.61 | 22.64 | 39.26 | 34.82 |
| GTE-large Li et al. (2023) | 62.29 | 51.66 | 33.49 | 50.13 | 38.88 | 44.67 | 43.07 | 30.27 | 51.98 | 27.02 | 20.38 | 22.97 | 22.75 | 41.40 | 38.64 |
| BGE-en-1.5 Xiao et al. (2023) | 63.27 | 51.65 | 32.79 | 50.84 | 38.50 | 49.73 | 43.28 | 30.81 | 51.16 | 31.11 | 25.28 | 26.34 | 23.02 | 41.96 | 39.98 |
| E5-large Wang et al. (2024a) | 60.12 | 52.41 | 26.81 | 51.00 | 37.99 | 39.47 | 43.86 | 31.32 | 53.59 | 28.84 | 24.57 | 23.48 | 22.03 | 43.25 | 38.48 |
| ST5-XXL Ni et al. (2021c) | 58.81 | 60.35 | 44.42 | 58.50 | 41.81 | 24.66 | 53.43 | 25.30 | 52.46 | 15.43 | 18.07 | 17.10 | 21.63 | 38.81 | 37.91 |
| GTR-XXL Ni et al. (2021b) | 58.12 | 54.39 | 41.94 | 53.21 | 37.96 | 24.67 | 50.08 | 25.14 | 53.88 | 15.23 | 17.35 | 15.92 | 22.12 | 40.57 | 36.47 |
| E5-Mistral Wang et al. (2024b) | 66.64 | 61.84 | 61.30 | 59.65 | 58.58 | 72.55 | 58.25 | 54.43 | 66.97 | 62.82 | 56.23 | 55.10 | 47.15 | 50.61 | 59.44 |
| LUSIFER (Ours) | 57.20 | 60.14 | 59.82 | 59.24 | 67.69 | 76.17 | 59.70 | 55.60 | 72.83 | 65.23 | 62.37 | 58.43 | 69.30 | 53.12 | 62.63 |
🔼 This table presents a comprehensive comparison of various embedding models’ performance across multiple languages and tasks. The average performance metrics for each model are shown, with the best-performing model for each language highlighted in bold. The models marked with an asterisk (*) were trained using extensive multilingual data, differentiating them from those trained primarily on English data. This allows for a direct comparison between models trained with and without the benefit of multilingual training data. The table provides a clear picture of the relative strengths and weaknesses of different models when handling various languages and embedding tasks.
read the caption
Table 1: Comparative analysis of model performance across multiple languages and tasks. The table presents average metrics for each model, with the highest score for each language emphasized in bold. * denotes the models trained on extensive multilingual data.
In-depth insights#
Zero-shot Multilingualism#
Zero-shot multilingualism represents a significant advancement in natural language processing, aiming to enable language models to handle multiple languages without explicit training data for each. This approach is particularly valuable for low-resource languages lacking extensive parallel corpora. The core idea revolves around leveraging transfer learning mechanisms, where knowledge gained from high-resource languages is transferred to low-resource ones. A key challenge lies in creating a language-agnostic representation space, where the model can understand semantic meaning irrespective of the surface language. Successful zero-shot multilingual models demonstrate the power of pre-trained language models and their ability to generalize across linguistic boundaries. However, limitations remain, particularly concerning performance compared to fully supervised multilingual systems. Future research should focus on enhancing cross-lingual transferability, improving the handling of morphologically diverse languages, and developing more robust evaluation metrics that account for the nuances of low-resource settings.
LLM-based Embedding#
LLM-based embedding represents a significant advancement in text embedding, leveraging the powerful semantic understanding capabilities of large language models (LLMs). Unlike traditional methods, LLM-based approaches bypass the need for explicit feature engineering, relying instead on the inherent contextual knowledge encoded within the LLM. This results in embeddings that capture richer semantic relationships and nuanced contextual information, leading to superior performance across various downstream tasks. However, a major limitation is the dominance of English in current LLM training data, resulting in biased performance for other languages. Therefore, research into multilingual LLM-based embeddings is crucial for broadening the applicability of this technology and addressing the challenge of embedding low-resource languages effectively. Future advancements will likely focus on developing more robust multilingual models, exploring novel training techniques, and creating comprehensive benchmark datasets that adequately evaluate performance across diverse languages and tasks.
LUSIFER Architecture#
LUSIFER’s architecture is ingeniously designed to bridge the gap between multilingual understanding and specialized embedding tasks. It leverages a multilingual encoder (like XLM-R) to capture semantic information across various languages, thus creating a language-agnostic universal space. This space is then connected to an English-centric LLM-based embedding model via a minimal, learnable connector. This connector acts as a bridge, effectively transferring the multilingual encoder’s understanding to the LLM without requiring extensive multilingual training data. The architecture’s effectiveness stems from the ability to transfer the universal representations to a space readily processed by the LLM, thereby allowing the LLM to grasp semantics regardless of the language of origin. This zero-shot approach is key, offering a significant advantage in handling low-resource languages, where traditional multilingual training data is scarce. The use of LoRA (Low-Rank Adaptation) further enhances efficiency, minimizing the number of trainable parameters.
Benchmarking Results#
A dedicated section on “Benchmarking Results” within a research paper would ideally present a thorough comparative analysis of the proposed method against existing state-of-the-art techniques. This would involve a clear description of the benchmark datasets used, ensuring diversity across languages and task types (e.g., classification, retrieval, clustering). Quantitative results, presented as precision, recall, F1-score, or similar metrics, should be meticulously tabulated and visualized to highlight performance differences. Crucially, the analysis must interpret the results, explaining any performance discrepancies and providing insight into the strengths and weaknesses of the proposed method. A discussion comparing the computational efficiency and resource requirements of the various approaches would also be valuable, This section would then conclude by highlighting the significance of the findings, placing them within the broader context of the research area and suggesting directions for future work.
Future Research#
Future research directions stemming from this LUSIFER model could explore expanding the multilingual encoder’s capabilities to encompass a wider array of languages, especially those with limited resources. Investigating alternative alignment strategies beyond the feed-forward connector, such as attention-based mechanisms or transformer networks, could potentially enhance the accuracy and efficiency of the multilingual transfer process. A detailed analysis of the trade-off between model size and multilingual performance would be valuable, considering the computational cost of larger LLMs. Furthermore, applying LUSIFER to other downstream NLP tasks beyond the five primary embedding tasks explored in the paper (classification, clustering, reranking, retrieval, and STS) would broaden the model’s application and impact. Finally, a comprehensive study examining the robustness of LUSIFER to various noise levels and data imbalances would further solidify its reliability and generalizability across diverse real-world scenarios.
More visual insights#
More on figures

🔼 This figure provides a comprehensive overview of the benchmark datasets used in the paper to evaluate multilingual embedding models. It illustrates the five main embedding tasks (classification, clustering, retrieval, reranking, and semantic textual similarity (STS)) and the 123 diverse datasets used for evaluation across 14 languages. The datasets are categorized by task, allowing for a clear visualization of the benchmark’s scope and the distribution of tasks across languages. Cross-lingual datasets, where queries and documents are in different languages, are highlighted with a blue shade, emphasizing their importance in assessing cross-lingual capabilities.
read the caption
Figure 2: Overview of tasks and datasets in our benchmark. Crosslingual datasets are marked with a blue shade.

🔼 This figure presents a comparison of the performance of LUSIFER and several baseline models on classification tasks. The figure likely shows the performance metrics (such as accuracy or F1-score) achieved by each model across multiple languages. It likely visualizes the relative strengths and weaknesses of LUSIFER compared to other state-of-the-art multilingual embedding models, particularly showcasing its ability to enhance performance without the need for explicit multilingual training data. The models’ performances are likely displayed using a radar chart, where each axis represents a different language and the length of each spoke on the chart indicates the model’s performance.
read the caption
(a) Classification tasks

🔼 This figure displays a comparison of the performance of LUSIFER and various baseline models on clustering tasks. It visually represents the effectiveness of each model’s ability to group similar data points together accurately. The plot likely shows a performance metric (e.g., V-measure) across different languages, providing insights into the cross-lingual capabilities of each model. LUSIFER is expected to demonstrate improvements, particularly for medium and low-resource languages.
read the caption
(b) Clustering tasks

🔼 This figure (Figure 3) presents a comparison of LUSIFER’s performance against various baseline models on classification and clustering tasks. It visually represents the average performance across multiple languages for both task types, highlighting LUSIFER’s improvements, particularly for languages with limited resources. The visualization likely uses a radar chart or similar plot type to compare performance across different languages on each task. It showcases LUSIFER’s superior multilingual capabilities compared to existing models.
read the caption
Figure 3: Performance comparison of LUSIFER and baseline models on Classification and Clustering tasks.

🔼 This figure displays a comparison of the performance of the LUSIFER model against several baseline models across various reranking tasks. The results are likely presented visually, possibly as a bar chart or line graph, showing the performance scores (e.g., Mean Average Precision, MAP) for each model on each task. This allows for a direct visual comparison of LUSIFER’s effectiveness in reranking compared to established methods.
read the caption
Figure 4: Performance comparison of LUSIFER and baseline models on Reranking tasks.

🔼 This figure shows a comparison of LUSIFER and baseline models’ performance on retrieval tasks. The radar chart visualizes the average performance across multiple datasets and languages, illustrating LUSIFER’s strengths and weaknesses in comparison to existing methods. Each axis represents a specific retrieval task or language, and the radial distance from the center indicates the performance score. This visualization helps to understand the relative strengths and weaknesses of LUSIFER across different retrieval scenarios and languages.
read the caption
(a) Retrieval tasks

🔼 This figure displays a comparison of LUSIFER’s performance against various baseline models across different Semantic Textual Similarity (STS) tasks. The plot likely uses a radar chart or similar visualization to show the relative performance of each model on multiple STS datasets. Each axis represents a different STS task, and the distance from the center to the point on each axis indicates the model’s performance on that specific task. This allows for a direct comparison of the models’ strengths and weaknesses across the range of STS tasks.
read the caption
(b) STS tasks

🔼 This figure presents a comparison of LUSIFER’s performance against several baseline models across two key natural language processing tasks: Retrieval and Semantic Textual Similarity (STS). The results are visualized to show the relative performance of LUSIFER and each baseline model across different languages. This allows for a clear evaluation of LUSIFER’s effectiveness in improving multilingual representation capabilities, particularly for languages with limited resources.
read the caption
Figure 5: Performance comparison of LUSIFER and baseline models on Retrieval and STS tasks.
More on tables
| Baselines | MLQARetrieval | BelebeleRetrieval | STS17 | STS22 | IndicCrosslingual | Avg. |
|---|---|---|---|---|---|---|
| SimCSE Gao et al. (2021b) | 7.41 | 18.35 | 39.71 | 37.95 | 0.18 | 20.72 |
| Contriever Izacard et al. (2022) | 9.75 | 22.94 | 34.55 | 41.72 | 0.03 | 21.80 |
| GTE-large Li et al. (2023) | 16.99 | 31.82 | 37.57 | 53.79 | 1.59 | 28.35 |
| BGE-en-1.5 Xiao et al. (2023) | 16.64 | 31.19 | 40.40 | 50.77 | 1.11 | 28.02 |
| E5-large Wang et al. (2024a) | 17.04 | 31.12 | 37.90 | 54.31 | 1.83 | 28.44 |
| ST5-XXL Ni et al. (2021c) | 20.82 | 41.68 | 56.19 | 59.02 | 1.76 | 35.89 |
| GTR-XXL Ni et al. (2021b) | 20.19 | 38.02 | 50.83 | 60.11 | 2.74 | 34.38 |
| E5-Mistral Wang et al. (2024b) | 31.54 | 54.75 | 81.12 | 71.37 | 21.92 | 52.14 |
| LUSIFER (Ours) | 36.68 | 57.81 | 81.09 | 70.49 | 43.40 | 57.89 |
🔼 This table presents a comprehensive evaluation of various embedding models’ performance on cross-lingual retrieval tasks. It shows average metrics across multiple languages, highlighting the best performing model for each language in bold. This evaluation is crucial for assessing the models’ ability to generalize to languages beyond those heavily represented in their training data.
read the caption
Table 2: Cross-lingual evaluation results. The table presents average metrics for each model over all languages of the datasets, with the highest score for each language emphasized in bold.
| Baselines | En | Es | Ru | Fr | Vi | Fa | Id | Ar | Fi | Ko | Hi | Bn | Te | Sw | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LUSIFER (Full) | 57.20 | 60.14 | 59.82 | 59.24 | 67.69 | 76.17 | 59.70 | 55.60 | 72.83 | 65.23 | 62.37 | 58.43 | 69.30 | 53.12 | 62.63 | |
| LUSIFER (Connector Only) | 35.53 | 33.98 | 42.95 | 33.54 | 35.68 | 57.86 | 35.55 | 27.60 | 48.72 | 34.45 | 47.57 | 41.85 | 46.50 | 34.66 | 44.18 | |
| LUSIFER (Frozen Multilingual Encoder) | 50.99 | 58.77 | 58.30 | 52.73 | 62.24 | 75.88 | 58.11 | 41.66 | 70.75 | 59.53 | 62.48 | 55.53 | 66.24 | 49.12 | 58.74 | |
| LUSIFER (Alignment Only) | 43.32 | 38.94 | 45.12 | 36.75 | 41.96 | 64.60 | 38.38 | 33.07 | 52.78 | 38.08 | 53.06 | 47.84 | 48.34 | 40.03 | 44.45 | |
| LUSIFER (Representation Finetuning Only) | 49.71 | 58.76 | 58.08 | 51.01 | 62.11 | 74.01 | 57.32 | 40.95 | 68.47 | 57.81 | 59.74 | 53.53 | 63.39 | 47.03 | 57.28 |
🔼 This table presents the results of an ablation study conducted on the LUSIFER model. It systematically removes components of the model’s architecture (the connector, multilingual encoder, alignment training, and representation finetuning) to determine their individual contributions to the overall performance. The table shows average metrics across multiple languages for each configuration, with the best result for each language highlighted in bold. This allows for a clear understanding of the relative importance of each LUSIFER component in achieving its enhanced multilingual capabilities.
read the caption
Table 3: Ablation study results of LUSIFER’s components. The table presents average metrics for each model, with the highest score for each language emphasized in bold.
| Hyperparameter | Alignment Training | Representation Finetuning |
|---|---|---|
| Batch size | 256 | 256 |
| Learning rate | 1.5e-4 | 5e-5 |
| Learning rate scheduler | cosine | cosine |
| Learning rate warm-up ratio | 0.1 | 0.1 |
| Weight decay | 0.01 | 0.01 |
| Grad norm clipping | 1.0 | 1.0 |
| Epochs | 2 | 1 |
| Optimizer | AdamW | AdamW |
| Float precision | bf16-mixed | bf16-mixed |
| LoRA rank | 16 | 16 |
| LoRA alpha | 32 | 32 |
| Random mask ratio | 0.5 | - |
| Number of hardnegatives | - | 7 |
🔼 This table details the hyperparameters used in the two-stage training process of the LUSIFER model. The first stage focuses on aligning the multilingual encoder’s representations with the target LLM’s embedding space, while the second stage fine-tunes the model’s representations using contrastive learning on English data. For each stage, the table specifies hyperparameters such as batch size, learning rate, learning rate scheduler, weight decay, gradient norm clipping, epochs, optimizer, and float precision. It also includes hyperparameters specific to the Low-Rank Adaptation (LoRA) technique used for efficient training.
read the caption
Table 4: Training hyperparameters for each stage.
| Stage | Dataset | Number of Samples |
|---|---|---|
| Alignment Training | Wikitext-103 Merity et al. (2017) | 100,000 |
| MSMARCO Bajaj et al. (2018) | 100,000 | |
| Representation Finetuning | MS MARCO Bajaj et al. (2018) | 100,000 |
| FEVER Thorne et al. (2018) | 100,000 | |
| PAQ Lewis et al. (2021) | 100,000 | |
| SNLI Bowman et al. (2015) | 100,000 | |
| HotpotQA Yang et al. (2018) | 97,800 | |
| SQuAD Rajpurkar et al. (2016) | 97,400 | |
| FiQA Maia et al. (2018) | 6,420 | |
| NQ Kwiatkowski et al. (2019) | 3,420 | |
| ArguAna Wachsmuth et al. (2018) | 1,280 |
🔼 This table details the number of samples used for training the LUSIFER model in each dataset. The count includes both positive and negative samples used during the training process. This information is crucial for understanding the scale of the training data and its potential impact on model performance.
read the caption
Table 5: Number of samples used in each dataset for training. The number of negative samples is included in the total number of samples.
| Es Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| AmazonReviewsClassification | 42.69 | 50.41 |
| MassiveIntentClassification | 69.67 | 68.93 |
| MassiveScenarioClassification | 74.63 | 73.41 |
| MTOPIntentClassification | 72.16 | 80.13 |
| MultilingualSentimentClassification | 87.91 | 91.01 |
| TweetSentimentClassification | 49.73 | 58.55 |
| SpanishNewsClassification | 89.5 | 87.81 |
| PawsXPairClassification | 61.19 | 62.82 |
| XNLI | 77.34 | 60.49 |
| SpanishNewsClusteringP2P | 42.28 | 43.85 |
| MLSUMClusteringP2P | 47.54 | 44.36 |
| MLSUMClusteringS2S | 47.11 | 41.56 |
| SIB200ClusteringS2S | 31.01 | 44.42 |
| MultiEURLEXMultilabelClassification | 6.16 | 3.87 |
| BelebeleRetrieval | 83.92 | 81.4 |
| MintakaRetrieval | 48.77 | 18.17 |
| STS17 | 87.18 | 80.84 |
| STS22 | 71.79 | 70.66 |
| STSBenchmarkMultilingualSTS | 84.31 | 79.89 |
| Avg. | 61.84 | 60.14 |
🔼 This table presents a detailed comparison of the performance of the E5-Mistral and LUSIFER models on Spanish language benchmark datasets. It breaks down the results for each individual dataset, showing the scores achieved by each model across various tasks, allowing for a granular analysis of model performance in a specific language.
read the caption
Table 6: Detailed results of E5-Mistral and LUSIFER on the Spanish benchmark datasets.
| En Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| AmazonCounterfactualClassification | 78.69 | 72.45 |
| AmazonPolarityClassification | 95.91 | 94.3 |
| AmazonReviewsClassification | 55.79 | 55.46 |
| Banking77Classification | 88.23 | 87.33 |
| EmotionClassification | 49.77 | 74 |
| ImdbClassification | 94.78 | 92.52 |
| MassiveIntentClassification | 80.57 | 75.64 |
| MassiveScenarioClassification | 82.39 | 78 |
| MTOPDomainClassification | 96.12 | 96.81 |
| MTOPIntentClassification | 86.11 | 87.34 |
| ToxicConversationsClassification | 69.59 | 82.84 |
| TweetSentimentExtractionClassification | 63.72 | 72.74 |
| SprintDuplicateQuestions | 95.66 | 90.99 |
| TwitterSemEval2015 | 81.62 | 68.49 |
| TwitterURLCorpus | 87.75 | 85.35 |
| ArxivClusteringP2P | 50.45 | 35.6 |
| ArxivClusteringS2S | 45.5 | 22.25 |
| BiorxivClusteringP2P | 43.53 | 39.93 |
| BiorxivClusteringS2S | 40.24 | 29.3 |
| MedrxivClusteringP2P | 38.19 | 41.2 |
| MedrxivClusteringS2S | 37.45 | 35.53 |
| RedditClustering | 57.71 | 39.94 |
| RedditClusteringP2P | 66.49 | 53.4 |
| StackExchangeClustering | 73.1 | 46.41 |
| StackExchangeClusteringP2P | 45.91 | 39.7 |
| TwentyNewsgroupsClustering | 54.31 | 38.5 |
| AskUbuntuDupQuestions | 66.98 | 60.56 |
| MindSmallReranking | 32.6 | 24.55 |
| SciDocsRR | 86.33 | 34.94 |
| StackOverflowDupQuestions | 54.91 | 46.04 |
| ArguAna | 61.88 | 74.15 |
| ClimateFEVER | 38.4 | 29.24 |
| CQADupstackTexRetrieval | 42.97 | 23.22 |
| DBPedia | 48.9 | 17.98 |
| FEVER | 87.8 | 82.77 |
| FiQA2018 | 56.62 | 14.91 |
| HotpotQA | 75.7 | 49.04 |
| MSMARCO | 43.1 | 56.43 |
| NFCorpus | 38.59 | 5.48 |
| NQ | 63.5 | 42.95 |
| QuoraRetrieval | 89.62 | 89.1 |
| SCIDOCS | 16.27 | 5.53 |
| SciFact | 76.41 | 66.09 |
| Touche2020 | 26.39 | 6.33 |
| TRECCOVID | 87.33 | 18.22 |
| STS12 | 79.65 | 74.26 |
| STS13 | 88.43 | 84.2 |
| STS14 | 84.54 | 77.5 |
| STS15 | 90.42 | 84.95 |
| STS16 | 87.68 | 82.21 |
| STS17 | 91.75 | 81.67 |
| STS22 | 67.28 | 71.25 |
| BIOSSES | 82.64 | 84.22 |
| SICK-R | 80.76 | 78 |
| STSBenchmark | 88.6 | 84.18 |
| SummEval | 31.4 | 32.36 |
| Avg. | 67.69 | 57.20 |
🔼 This table presents a detailed comparison of the performance of two models, E5-Mistral and LUSIFER, on various English language benchmark datasets. It breaks down the results for each dataset, showing the accuracy scores achieved by each model on different tasks, including classification, clustering, retrieval, reranking, and semantic textual similarity (STS). This allows for a granular analysis of the strengths and weaknesses of each model on specific tasks and datasets.
read the caption
Table 7: Detailed results of E5-Mistral and LUSIFER on the English benchmark datasets.
| Ru Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| GeoreviewClassification | 46.92 | 43.79 |
| HeadlineClassification | 76.52 | 79.26 |
| InappropriatenessClassification | 59.35 | 63.15 |
| KinopoiskClassification | 60.67 | 60.57 |
| MassiveIntentClassification | 72.06 | 71.29 |
| MassiveScenarioClassification | 76.64 | 74.49 |
| RuReviewsClassification | 64.10 | 67.40 |
| RuSciBenchGRNTIClassification | 60.19 | 59.51 |
| RuSciBenchOECDClassification | 46.30 | 46.41 |
| GeoreviewClusteringP2P | 69.87 | 59.20 |
| RuSciBenchGRNTIClusteringP2P | 52.96 | 55.00 |
| RuSciBenchOECDClusteringP2P | 46.54 | 49.95 |
| TERRA | 57.45 | 54.24 |
| RiaNewsRetrieval | 71.39 | 49.61 |
| RuBQRetrieval | 38.04 | 43.48 |
| RuSTSBenchmarkSTS | 81.79 | 78.20 |
| STS22 | 61.32 | 61.44 |
| Avg. | 61.30 | 59.82 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, across various tasks and datasets within the Russian language benchmark. For each dataset, it shows the scores achieved by both models, offering a granular view of their relative strengths and weaknesses in different aspects of embedding tasks within the Russian language.
read the caption
Table 8: Detailed results of E5-Mistral and LUSIFER on the Russian benchmark datasets.
| Fr Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| AmazonReviewsClassification | 43.36 | 49.96 |
| MTOPIntentClassification | 70.39 | 79.14 |
| MassiveIntentClassification | 71.12 | 70.88 |
| MassiveScenarioClassification | 74.68 | 73.96 |
| TweetSentimentClassification | 50.23 | 62.62 |
| SIB200Classification | 72.45 | 79.51 |
| FrenchBookReviews | 46.77 | 48.07 |
| PawsXPairClassification | 62.15 | 65.93 |
| RTE3 | 88.45 | 87.62 |
| XNLI | 76.60 | 62.75 |
| MasakhaNEWSClusteringP2P | 50.96 | 48.59 |
| MasakhaNEWSClusteringS2S | 52.08 | 63.12 |
| MLSUMClusteringP2P | 42.69 | 42.70 |
| MLSUMClusteringS2S | 42.60 | 41.51 |
| HALClusteringS2S | 24.21 | 24.16 |
| SIB200ClusteringS2S | 29.94 | 43.30 |
| MultiEURLEXMultilabelClassification | 5.00 | 3.51 |
| BelebeleRetrieval | 84.66 | 83.76 |
| MintakaRetrieval | 52.60 | 18.88 |
| OpusparcusPC | 94.58 | 90.63 |
| STS17 | 84.66 | 82.19 |
| SICKFr | 79.12 | 74.22 |
| STS22 | 76.50 | 73.77 |
| STSBenchmarkMultilingualSTS | 83.98 | 78.42 |
| SummEvalFr | 31.38 | 31.91 |
| Avg. | 59.65 | 59.24 |
🔼 This table presents a detailed comparison of the performance of two models, E5-Mistral and LUSIFER, across various French language benchmark datasets. It breaks down the results for each specific dataset and task, providing a granular view of each model’s strengths and weaknesses in the French language.
read the caption
Table 9: Detailed results of E5-Mistral and LUSIFER on the French benchmark datasets.
| Vi Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| MassiveIntentClassification | 66.36 | 71.38 |
| MassiveScenarioClassification | 70.69 | 74.82 |
| MultilingualSentimentClassification | 69.30 | 81.30 |
| SIB200Classification | 70.20 | 78.58 |
| VieStudentFeedbackClassification | 73.02 | 77.39 |
| XNLI | 71.32 | 61.30 |
| SIB200ClusteringS2S | 32.93 | 46.79 |
| BelebeleRetrieval | 79.20 | 85.51 |
| MLQARetrieval | 32.43 | 54.61 |
| VieQuADRetrieval | 20.35 | 45.20 |
| Avg. | 58.58 | 67.69 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, across various Vietnamese benchmark datasets. It breaks down the results for each model on specific tasks, offering a granular view of their relative strengths and weaknesses in the Vietnamese language. The metrics used likely reflect the performance on different embedding tasks (e.g., classification, clustering, retrieval, etc.). The table allows for a precise assessment of each model’s effectiveness in handling the nuances of the Vietnamese language.
read the caption
Table 10: Detailed results of E5-Mistral and LUSIFER on the Vietnamese benchmark datasets.
| Fa Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| MassiveScenarioClassification | 76.37 | 77.94 |
| MassiveIntentClassification | 71.98 | 73.32 |
| MultilingualSentimentClassification | 80.07 | 80.54 |
| FarsTail | 63.49 | 67.98 |
| WikipediaRerankingMultilingual | 75.60 | 78.75 |
| WikipediaRetrievalMultilingual | 67.77 | 78.49 |
| Avg. | 72.55 | 76.17 |
🔼 This table presents a detailed comparison of the performance of two models, E5-Mistral and LUSIFER, on various benchmark datasets for the Farsi language. It breaks down the results for each dataset, showing the scores achieved by each model on specific tasks. This allows for a granular analysis of the relative strengths and weaknesses of each model in handling the nuances of the Farsi language, contributing to a comprehensive evaluation of multilingual embedding capabilities.
read the caption
Table 11: Detailed results of E5-Mistral and LUSIFER on the Farsi benchmark datasets.
| Id Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| IndonesianMongabayConservationClassification | 24.72 | 25.27 |
| MassiveIntentClassification | 69.51 | 71.38 |
| MassiveScenarioClassification | 72.89 | 74.62 |
| SIB200Classification | 80.88 | 80.44 |
| indonli | 50.00 | 50.22 |
| SIB200ClusteringS2S | 46.46 | 47.50 |
| BelebeleRetrieval | 81.10 | 87.56 |
| SemRel24STS | 40.40 | 40.57 |
| Avg. | 58.25 | 59.70 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, across various Indonesian benchmark datasets. It breaks down the results for each task (classification, clustering, retrieval, reranking, and semantic textual similarity) to provide a comprehensive evaluation of each model’s strengths and weaknesses on Indonesian language data. The inclusion of multiple datasets allows for a more robust assessment of the models’ generalizability and performance across various scenarios.
read the caption
Table 12: Detailed results of E5-Mistral and LUSIFER on the Indonesian benchmark datasets.
| Ar Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| TweetEmotionClassification | 53.74 | 49.03 |
| ArEntail | 77.63 | 84.15 |
| XNLI | 68.00 | 58.58 |
| MintakaRetrieval | 17.15 | 16.59 |
| MLQARetrieval | 28.32 | 47.90 |
| STS17 | 75.13 | 71.44 |
| STS22 | 61.01 | 61.54 |
| Avg. | 54.43 | 55.60 |
🔼 This table presents a detailed comparison of the performance of two models, E5-Mistral and LUSIFER, on Arabic language benchmark datasets. It breaks down the results for various tasks such as classification, clustering, retrieval, reranking, and semantic textual similarity (STS). Each task will have associated metrics to show the numerical performance results of the models. This allows for a granular understanding of each model’s strengths and weaknesses when processing Arabic text.
read the caption
Table 13: Detailed results of E5-Mistral and LUSIFER on the Arabic benchmark datasets.
| Fi Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| FinToxicityClassification | 53.78 | 62.23 |
| MassiveIntentClassification | 64.15 | 70.77 |
| MassiveScenarioClassification | 67.79 | 75.02 |
| MultilingualSentimentClassification | 72.42 | 83.59 |
| SIB200Classification | 66.57 | 77.06 |
| WikipediaRerankingMultilingual | 86.85 | 82.65 |
| BelebeleRetrieval | 73.89 | 85.18 |
| WikipediaRetrievalMultilingual | 71.90 | 82.94 |
| OpusparcusPC | 91.41 | 91.63 |
| FinParaSTS | 20.97 | 17.24 |
| Avg. | 66.97 | 72.83 |
🔼 This table presents a detailed comparison of the performance of the E5-Mistral and LUSIFER models on a range of benchmark datasets specifically designed for the Finnish language. It provides a granular view of each model’s effectiveness across various tasks, offering insights into their strengths and weaknesses when processing Finnish text data. The results are crucial for evaluating the multilingual capabilities of the models, especially in a language with potentially limited resources.
read the caption
Table 14: Detailed results of E5-Mistral and LUSIFER on the Finnish benchmark datasets.
| Ko Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| MassiveIntentClassification | 70.42 | 69.79 |
| MassiveScenarioClassification | 75.12 | 75.60 |
| KorSarcasmClassification | 57.64 | 55.28 |
| SIB200Classification | 72.70 | 77.89 |
| KorHateSpeechMLClassification | 8.49 | 7.54 |
| PawsXPairClassification | 53.10 | 54.97 |
| KLUE-TC | 60.58 | 63.95 |
| SIB200ClusteringS2S | 31.04 | 46.58 |
| Ko-StrategyQA | 63.81 | 68.66 |
| BelebeleRetrieval | 80.09 | 84.69 |
| KLUE-STS | 83.48 | 84.17 |
| KorSTS | 79.28 | 78.36 |
| STS17 | 80.97 | 80.55 |
| Avg. | 62.82 | 65.23 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, on a range of Korean benchmark datasets. Each dataset represents a different type of natural language processing task (classification, clustering, etc.). The table allows readers to assess the relative strengths and weaknesses of each model on various tasks, highlighting how well each model performs in the context of a specific Korean dataset.
read the caption
Table 15: Detailed results of E5-Mistral and LUSIFER on the Korean benchmark datasets.
| Hi Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| MTOPIntentClassification | 68.84 | 79.93 |
| SentimentAnalysisHindi | 58.98 | 73.92 |
| MassiveIntentClassification | 64.69 | 71.01 |
| MassiveScenarioClassification | 69.71 | 75.42 |
| SIB200Classification | 68.43 | 75.98 |
| TweetSentimentClassification | 37.70 | 40.78 |
| XNLI | 65.04 | 60.26 |
| IndicReviewsClusteringP2P | 40.04 | 42.40 |
| SIB200ClusteringS2S | 27.32 | 45.62 |
| WikipediaRerankingMultilingual | 85.22 | 78.17 |
| BelebeleRetrieval | 69.73 | 66.76 |
| MintakaRetrieval | 18.60 | 21.53 |
| MLQARetrieval | 35.37 | 54.54 |
| WikipediaRetrievalMultilingual | 74.62 | 75.25 |
| IndicCrosslingualSTS | 42.30 | 58.97 |
| SemRel24STS | 73.14 | 77.34 |
| Avg. | 56.23 | 62.37 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, across various Hindi language benchmark datasets. The datasets cover a range of tasks including classification, clustering, reranking, retrieval, and semantic textual similarity (STS). For each dataset, the table shows the average performance score achieved by each model. This allows for a granular assessment of the relative strengths and weaknesses of both models in the context of Hindi language processing.
read the caption
Table 16: Detailed results of E5-Mistral and LUSIFER on the Hindi benchmark datasets.
| Bn Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| BengaliDocumentClassification | 50.78 | 48.00 |
| BengaliHateSpeechClassification | 54.67 | 51.43 |
| MassiveIntentClassification | 59.51 | 66.65 |
| MassiveScenarioClassification | 64.57 | 70.91 |
| XNLIV2 | 63.66 | 60.01 |
| IndicReviewsClusteringP2P | 38.20 | 45.68 |
| SIB200ClusteringS2S | 23.88 | 43.96 |
| WikipediaRerankingMultilingual | 82.66 | 76.39 |
| BelebeleRetrieval | 60.17 | 55.77 |
| IndicQARetrieval | 56.59 | 68.06 |
| WikipediaRetrievalMultilingual | 71.05 | 72.47 |
| IndicCrosslingualSTS | 35.42 | 41.86 |
| Avg. | 55.10 | 58.43 |
🔼 This table presents a detailed comparison of the performance of two embedding models, E5-Mistral and LUSIFER, on a series of benchmark datasets specifically for the Bengali language. It offers a granular view of their performance across various tasks, providing insights into their strengths and weaknesses in handling the Bengali language.
read the caption
Table 17: Detailed results of E5-Mistral and LUSIFER on the Bengali benchmark datasets.
| Te Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| IndicNLPNewsClassification | 89.46 | 98.90 |
| IndicSentimentClassification | 61.53 | 90.63 |
| MassiveIntentClassification | 47.34 | 68.69 |
| MassiveScenarioClassification | 51.67 | 74.17 |
| SIB200Classification | 46.23 | 74.56 |
| TeluguAndhraJyotiNewsClassification | 67.40 | 76.24 |
| IndicReviewsClusteringP2P | 34.02 | 43.62 |
| SIB200ClusteringS2S | 10.81 | 42.11 |
| BelebeleRetrieval | 42.46 | 80.32 |
| IndicQARetrieval | 33.67 | 57.61 |
| IndicCrosslingualSTS | 8.36 | 43.76 |
| SemRel24STS | 72.83 | 80.99 |
| Avg. | 47.15 | 69.30 |
🔼 This table presents a detailed comparison of the performance of the E5-Mistral and LUSIFER models on a range of Telugu language benchmark datasets. It breaks down the results for each model across various embedding tasks, offering a granular view of their relative strengths and weaknesses on this specific language. The results may include metrics like accuracy, precision, recall, F1-score, and others depending on the specific tasks in the benchmark.
read the caption
Table 18: Detailed results of E5-Mistral and LUSIFER on the Telugu benchmark datasets.
| Sw Datasets | E5-Mistral | LUSIFER |
|---|---|---|
| AfriSentiClassification | 39.67 | 46.47 |
| MasakhaNEWSClassification | 72.96 | 74.79 |
| MassiveIntentClassification | 52.84 | 52.79 |
| MassiveScenarioClassification | 61.09 | 58.59 |
| SwahiliNewsClassification | 63.95 | 61.56 |
| XNLI | 58.86 | 57.82 |
| MasakhaNEWSClusteringP2P | 34.15 | 36.95 |
| MasakhaNEWSClusteringS2S | 21.34 | 35.97 |
| Avg. | 50.61 | 53.12 |
🔼 This table presents a detailed comparison of the performance of two models, E5-Mistral and LUSIFER, on a series of benchmark datasets specifically designed for the Swahili language. The datasets encompass various natural language processing tasks, allowing for a comprehensive evaluation of each model’s capabilities in understanding and processing Swahili text. The results offer insights into the strengths and weaknesses of each model in handling the nuances of the Swahili language, providing valuable information for researchers and developers working with multilingual natural language processing models.
read the caption
Table 19: Detailed results of E5-Mistral and LUSIFER on the Swahili benchmark datasets.
Full paper#