TL;DR#
Large Language Models (LLMs) often generate incorrect code, and using LLM-generated unit tests to identify correct code solutions isn’t always reliable because LLMs confidently produce inaccurate unit tests. This paper explores the impact of increasing the number of unit tests used in the evaluation process. The main challenge is that current methods for evaluating LLM-generated code often rely on a limited number of unit tests which may not be representative of the code’s overall correctness. This leads to unreliable reward signals in training and lower overall accuracy.
The paper introduces CodeRM-8B, a novel unit test generator to improve the quality of reward signals by dynamically increasing the number of unit tests used based on problem difficulty. Experiments show that scaling unit tests, particularly using CodeRM-8B, significantly improves the accuracy of selecting correct code solutions across various models and benchmarks, leading to substantial performance gains (e.g., 18.43% improvement for Llama3-8B on HumanEval Plus). The study also demonstrates that this approach is especially effective for more challenging problems. The paper contributes significantly to the field by proposing efficient and high-quality unit test scaling which helps to improve the reliability of reward signals and enhances the performance of LLM-based code generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in code generation and large language models (LLMs). It addresses the problem of unreliable reward signals in LLM-based code generation, caused by LLMs’ tendency to confidently make mistakes. CodeRM-8B, a novel unit test generator proposed in the paper, significantly improves the accuracy of identifying correct solutions, especially for challenging problems, by scaling the number of unit tests. This work is important because it advances the state-of-the-art in LLM-based code generation and paves the way for more reliable and efficient code generation systems. Furthermore, the introduction of dynamic unit test scaling, which adapts the number of unit tests based on problem difficulty, opens new avenues for optimizing computational resources in LLM applications.
Visual Insights#

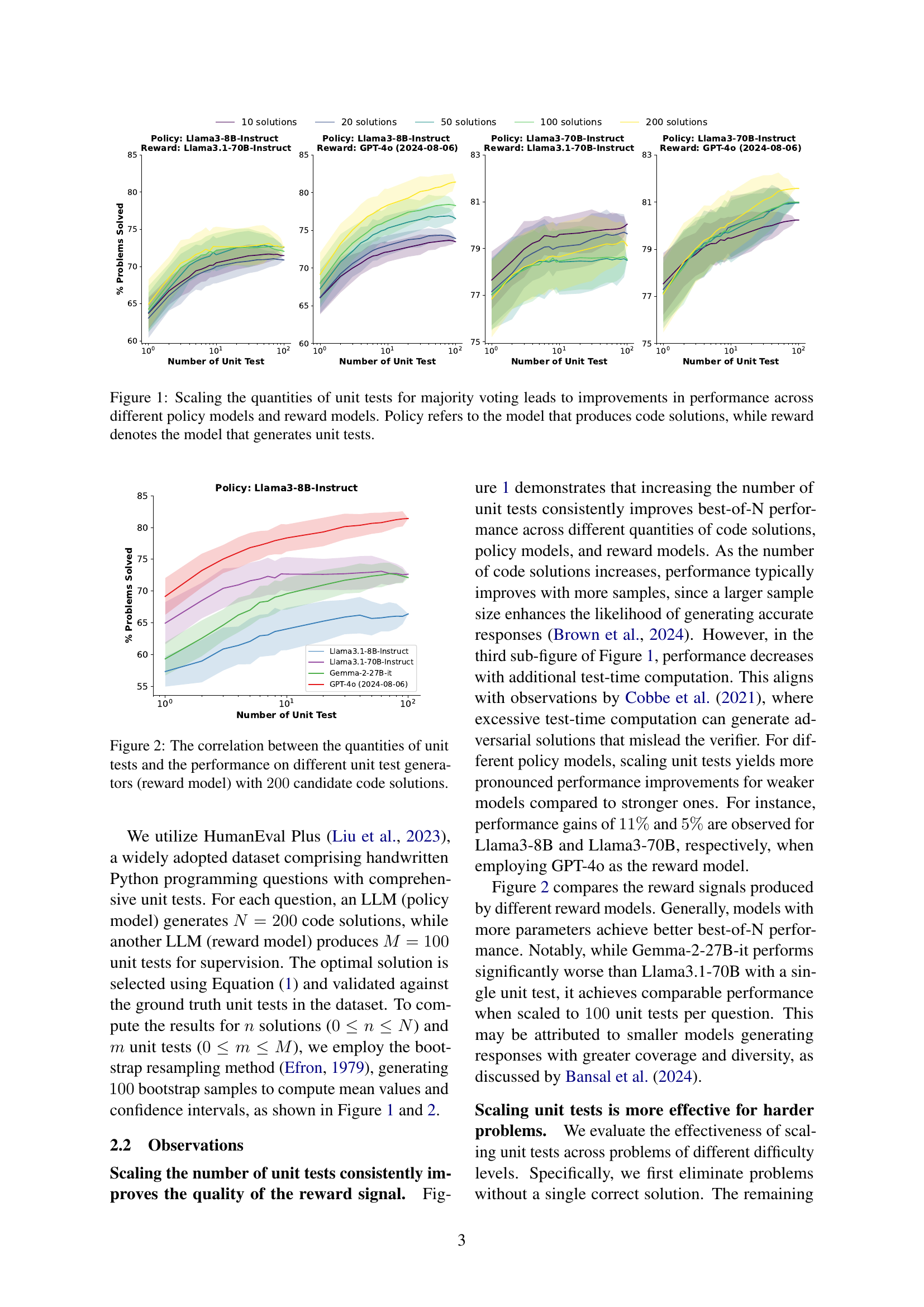
🔼 This figure displays the results of an experiment investigating the impact of scaling the number of unit tests on the performance of a majority voting system for selecting optimal code solutions. Multiple lines are shown, each representing a different combination of a model generating code solutions (the ‘policy’ model) and a model generating unit tests (the ‘reward’ model). The x-axis represents the number of unit tests used, and the y-axis shows the percentage of problems solved correctly. The results demonstrate that increasing the number of unit tests generally improves the accuracy of identifying correct solutions, regardless of the specific policy and reward models used. This improvement is more pronounced for larger numbers of code solution candidates.
read the caption
Figure 1: Scaling the quantities of unit tests for majority voting leads to improvements in performance across different policy models and reward models. Policy refers to the model that produces code solutions, while reward denotes the model that generates unit tests.
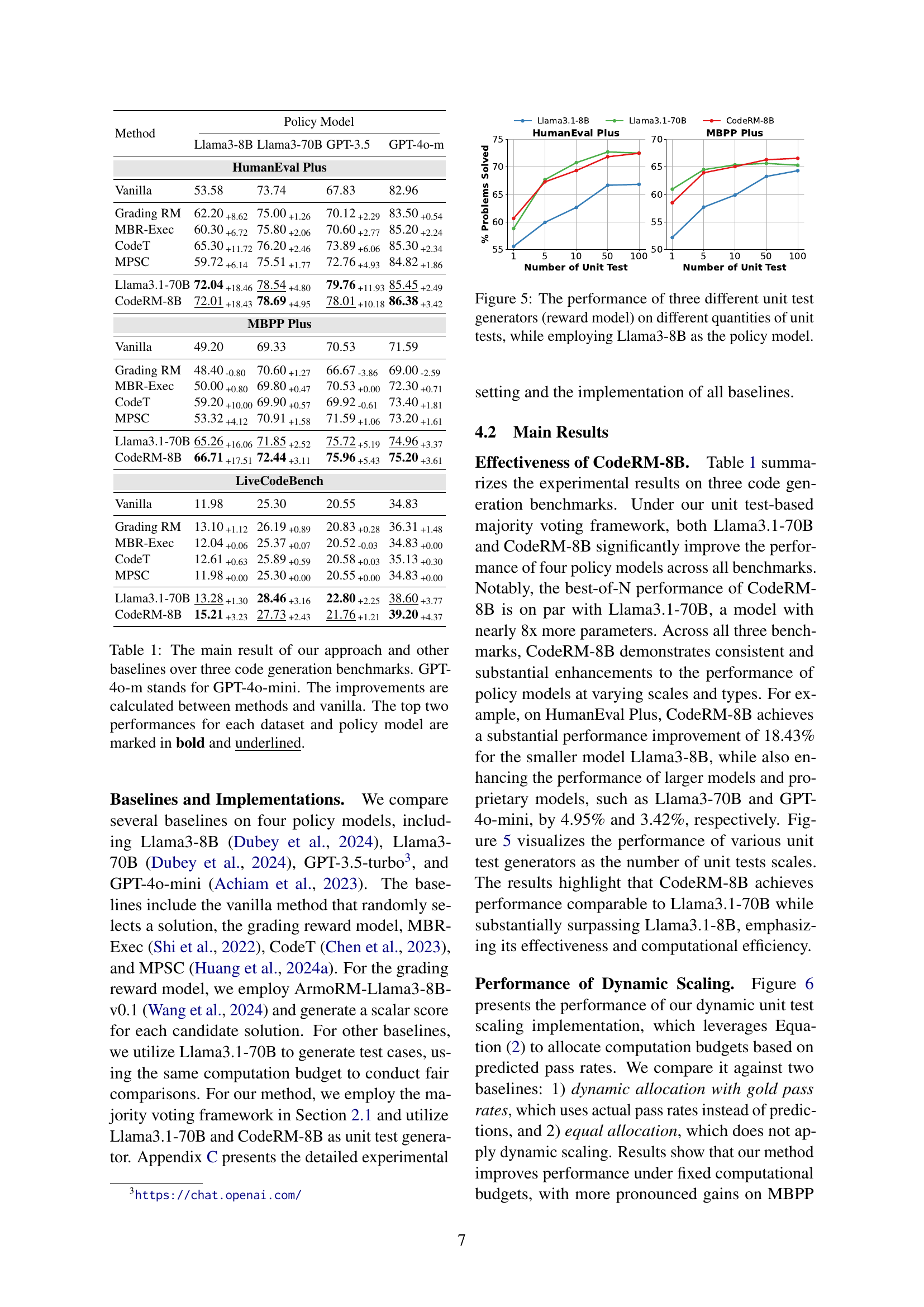
| Method | Llama3-8B | Llama3-70B | GPT-3.5 | GPT-4o-m |
|---|---|---|---|---|
| HumanEval Plus | ||||
| Vanilla | 53.58 | 73.74 | 67.83 | 82.96 |
| Grading RM | 62.20 +8.62 | 75.00 +1.26 | 70.12 +2.29 | 83.50 +0.54 |
| MBR-Exec | 60.30 +6.72 | 75.80 +2.06 | 70.60 +2.77 | 85.20 +2.24 |
| CodeT | 65.30 +11.72 | 76.20 +2.46 | 73.89 +6.06 | 85.30 +2.34 |
| MPSC | 59.72 +6.14 | 75.51 +1.77 | 72.76 +4.93 | 84.82 +1.86 |
| Llama3.1-70B | 72.04 +18.46 | 78.54 +4.80 | 79.76 +11.93 | 85.45 +2.49 |
| CodeRM-8B | 72.01 +18.43 | 78.69 +4.95 | 78.01 +10.18 | 86.38 +3.42 |
| MBPP Plus | ||||
| Vanilla | 49.20 | 69.33 | 70.53 | 71.59 |
| Grading RM | 48.40 -0.80 | 70.60 +1.27 | 66.67 -3.86 | 69.00 -2.59 |
| MBR-Exec | 50.00 +0.80 | 69.80 +0.47 | 70.53 +0.00 | 72.30 +0.71 |
| CodeT | 59.20 +10.00 | 69.90 +0.57 | 69.92 -0.61 | 73.40 +1.81 |
| MPSC | 53.32 +4.12 | 70.91 +1.58 | 71.59 +1.06 | 73.20 +1.61 |
| Llama3.1-70B | 65.26 +16.06 | 71.85 +2.52 | 75.72 +5.19 | 74.96 +3.37 |
| CodeRM-8B | 66.71 +17.51 | 72.44 +3.11 | 75.96 +5.43 | 75.20 +3.61 |
| LiveCodeBench | ||||
| Vanilla | 11.98 | 25.30 | 20.55 | 34.83 |
| Grading RM | 13.10 +1.12 | 26.19 +0.89 | 20.83 +0.28 | 36.31 +1.48 |
| MBR-Exec | 12.04 +0.06 | 25.37 +0.07 | 20.52 -0.03 | 34.83 +0.00 |
| CodeT | 12.61 +0.63 | 25.89 +0.59 | 20.58 +0.03 | 35.13 +0.30 |
| MPSC | 11.98 +0.00 | 25.30 +0.00 | 20.55 +0.00 | 34.83 +0.00 |
| Llama3.1-70B | 13.28 +1.30 | 28.46 +3.16 | 22.80 +2.25 | 38.60 +3.77 |
| CodeRM-8B | 15.21 +3.23 | 27.73 +2.43 | 21.76 +1.21 | 39.20 +4.37 |
🔼 This table presents a comparison of the performance of various methods for code generation across three different benchmarks: HumanEval Plus, MBPP Plus, and LiveCodeBench. The methods compared include a baseline (vanilla) and several other approaches (Grading RM, MBR-Exec, CodeT, MPSC, Llama3.1-70B and the authors’ proposed CodeRM-8B). Performance is evaluated using four different Language Models (LLMs) as policy models (Llama3-8B, Llama3-70B, GPT-3.5, and GPT-40-mini). The table shows the percentage of problems solved by each method, with improvements over the vanilla method calculated and highlighted for the top-performing methods on each dataset. GPT-40-mini is noted separately from the main GPT-40 model.
read the caption
Table 1: The main result of our approach and other baselines over three code generation benchmarks. GPT-4o-m stands for GPT-4o-mini. The improvements are calculated between methods and vanilla. The top two performances for each dataset and policy model are marked in bold and underlined.
In-depth insights#
Unit Test Scaling#
The concept of ‘Unit Test Scaling’ in the context of code reward modeling involves increasing the number of unit tests used to evaluate code generated by large language models (LLMs). The core idea is that more tests lead to a more robust and reliable assessment of code correctness, improving the quality of reward signals used to train and refine the LLMs. Scaling unit tests offers a potential solution to the problem of LLMs confidently producing incorrect code, which is a major challenge in the field. The paper explores this hypothesis through experimentation, demonstrating a positive correlation between the number of tests and the accuracy of identifying correct solutions. However, the scalability and efficiency of generating and running many unit tests are important practical considerations. The research suggests that focusing scaling efforts on more challenging problems offers the greatest performance improvements, motivating a dynamic scaling approach. Dynamic scaling adjusts the number of unit tests based on problem difficulty, enabling efficient resource allocation. This dynamic strategy and the development of a high-quality, lightweight unit test generator are key contributions aimed at making unit test scaling a practical and effective technique for enhancing LLM code generation performance.
CodeRM-8B Model#
The hypothetical “CodeRM-8B Model” presented in the research paper appears to be a lightweight yet effective unit test generator designed to improve the performance of large language models (LLMs) in code generation tasks. The model’s core function is to efficiently produce high-quality unit tests, which act as reward signals to evaluate the correctness of LLM-generated code. A key innovation highlighted is the dynamic scaling of unit tests, adapting the number of tests generated based on the perceived difficulty of a given programming problem. This dynamic scaling is intended to improve efficiency, focusing computational resources on more complex scenarios where scaling unit tests offers greater improvements in the accuracy of evaluating generated code. The paper likely details the model’s architecture, training data, and evaluation metrics. Overall, CodeRM-8B is positioned as a solution to address challenges related to LLM-generated unit tests often being unreliable due to LLM biases; leading to poor reward signals and reduced performance in code generation tasks. The model’s effectiveness is probably supported by experimental results demonstrating significant performance gains across various LLMs and benchmark datasets.
Dynamic Scaling#
The concept of ‘dynamic scaling’ in the context of a research paper likely refers to adaptively adjusting certain parameters or resources based on the characteristics of the input or the current state. This contrasts with static scaling, where parameters remain fixed. In a code generation model, dynamic scaling might involve adjusting the number of unit tests generated depending on the problem’s complexity. More difficult problems may warrant more unit tests to improve accuracy and the quality of feedback signals used to select the best code solution. This approach optimizes resource usage while maintaining performance, avoiding excessive computation for simpler problems and ensuring sufficient analysis for harder ones. Dynamic scaling can also apply to computation time or model capacity. The effectiveness of dynamic scaling depends on the accuracy of a problem-difficulty classifier, which predicts how challenging a task is. A robust classifier enables the algorithm to efficiently allocate resources, improving overall efficiency and performance. Therefore, ‘dynamic scaling’ in this research signifies an intelligent, resource-aware approach for enhancing performance and efficiency in machine learning or other computational contexts.
Quality Metrics#
Defining comprehensive quality metrics for unit tests within the context of code generation is crucial for evaluating the effectiveness of LLMs. Metrics should go beyond simple pass/fail rates and delve into the informativeness of the tests. Factors like code coverage, fault detection capability, and the diversity of test cases generated are essential for a holistic assessment. For example, a high pass rate with limited code coverage might indicate weak tests that fail to thoroughly exercise the code’s functionality. Conversely, a low pass rate coupled with high coverage could point to an LLM struggling with complex code generation. Therefore, a robust metric suite should include coverage metrics, identifying the proportion of code executed by the test suite. It should also encompass fault-detection metrics, measuring the ability of the tests to reveal bugs in the generated code. Considering the diversity metric helps capture the range of scenarios covered by tests. The balance between these metrics is important. A high-quality unit test suite is characterized by good coverage, high fault detection, and sufficient diversity, achieving a balance between breadth and depth of code analysis.
Future Research#
Future research directions stemming from this dynamic unit test scaling work could explore several promising avenues. Improving the problem difficulty classifier is crucial; a more accurate classifier would enable more precise resource allocation, maximizing efficiency gains. Investigating alternative resource allocation strategies beyond the greedy approach, such as reinforcement learning or optimization techniques, could further enhance performance. The study could also explore the impact of different unit test generation strategies and examine whether other methods for generating high-quality unit tests could surpass those presented here. A deeper dive into the interplay between model size, unit test quantity, and problem difficulty is warranted. Understanding how these factors interact to influence performance could inform the development of more robust and scalable code generation techniques. Finally, applying this dynamic scaling approach to different code generation tasks beyond those studied here, exploring broader applications such as code completion or program repair, would broaden the impact and applicability of this research.
More visual insights#
More on figures

🔼 This figure shows the relationship between the number of unit tests used and the success rate of identifying the best code solution among 200 candidates. Different large language models (LLMs) were used as ‘reward models’ to generate the unit tests. The results illustrate how the quality of the reward signal, and thus the accuracy of selecting the optimal solution, improves with an increasing number of unit tests.
read the caption
Figure 2: The correlation between the quantities of unit tests and the performance on different unit test generators (reward model) with 200200200200 candidate code solutions.

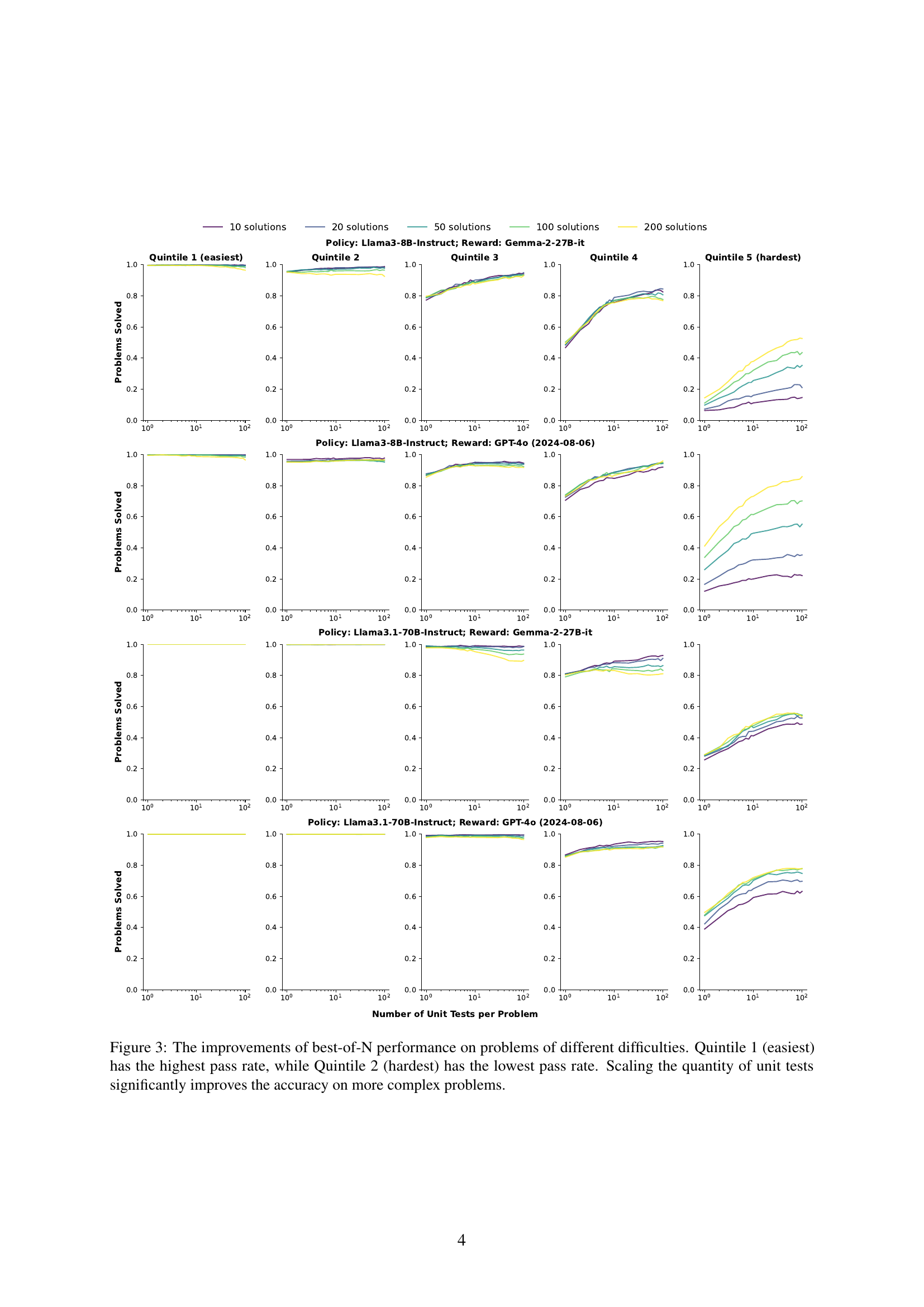
🔼 Figure 3 illustrates how increasing the number of unit tests affects the success rate of solving coding problems with varying difficulty levels. The problems are categorized into five quintiles based on their difficulty, with Quintile 1 representing the easiest problems (highest pass rate) and Quintile 5 representing the hardest problems (lowest pass rate). The graph shows that as the number of unit tests increases, the problem-solving accuracy improves significantly for all difficulty levels. However, the improvement is more substantial for the harder problems (Quintiles 4 and 5), demonstrating the effectiveness of scaling unit tests, particularly in tackling more challenging tasks.
read the caption
Figure 3: The improvements of best-of-N performance on problems of different difficulties. Quintile 1 (easiest) has the highest pass rate, while Quintile 2 (hardest) has the lowest pass rate. Scaling the quantity of unit tests significantly improves the accuracy on more complex problems.
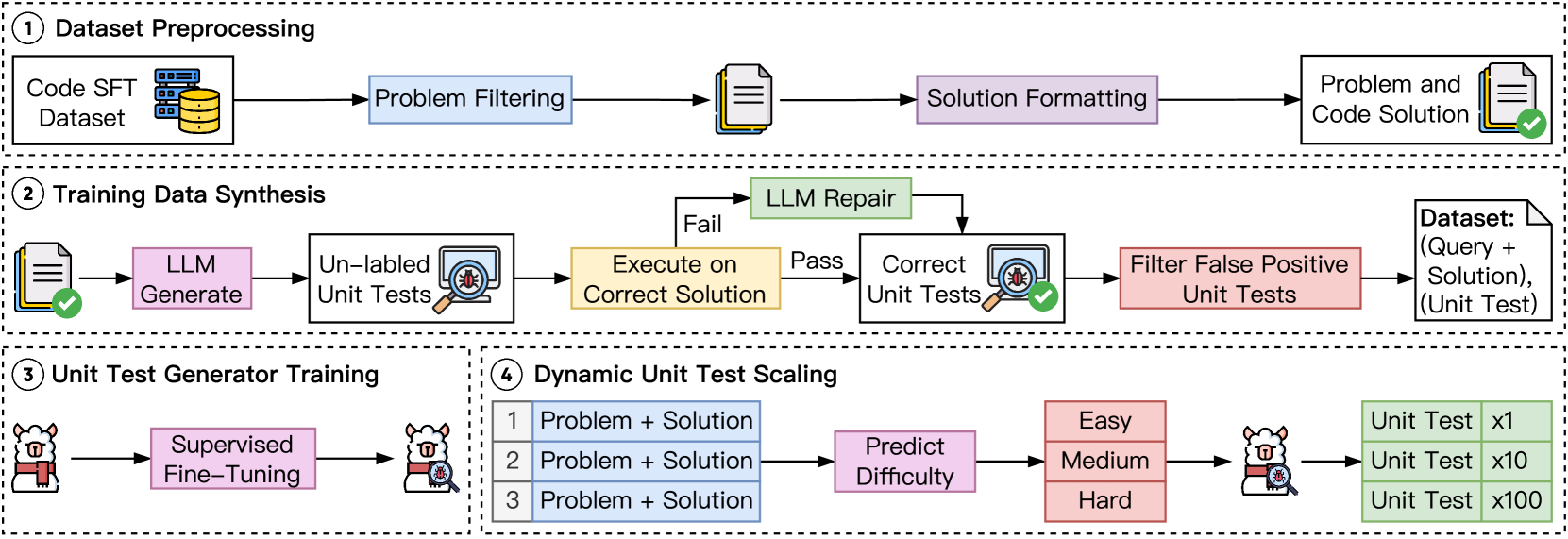
🔼 This figure illustrates the process of CodeRM-8B, a system for efficient and high-quality unit test scaling. It begins with dataset preprocessing and unit test generation to create high-quality synthetic training data. This data is used to train a lightweight unit test generator. Subsequently, a dynamic unit test scaling mechanism is employed to adjust the number of unit tests based on problem difficulty, thus enhancing efficiency. The overall system aims to improve the accuracy and efficiency of identifying correct code solutions by generating a sufficient and adaptive number of unit tests.
read the caption
Figure 4: Overview for efficient and high-quality unit test scaling. First, we train a lightweight unit test generator based on high-quality synthetic data. Subsequently, we employ dynamic unit test scaling to further improve efficiency.

🔼 This figure illustrates the impact of scaling the number of unit tests on the performance of different unit test generators. The experiment uses Llama3-8B as the code generation model (policy model), while three different LLMs serve as unit test generators (reward models). The x-axis represents the number of unit tests used, and the y-axis shows the percentage of problems solved. The results demonstrate how the performance of each reward model changes as the number of unit tests increases. This analysis helps to understand the effect of scaling unit tests on the quality of reward signals used for selecting accurate code solutions.
read the caption
Figure 5: The performance of three different unit test generators (reward model) on different quantities of unit tests, while employing Llama3-8B as the policy model.

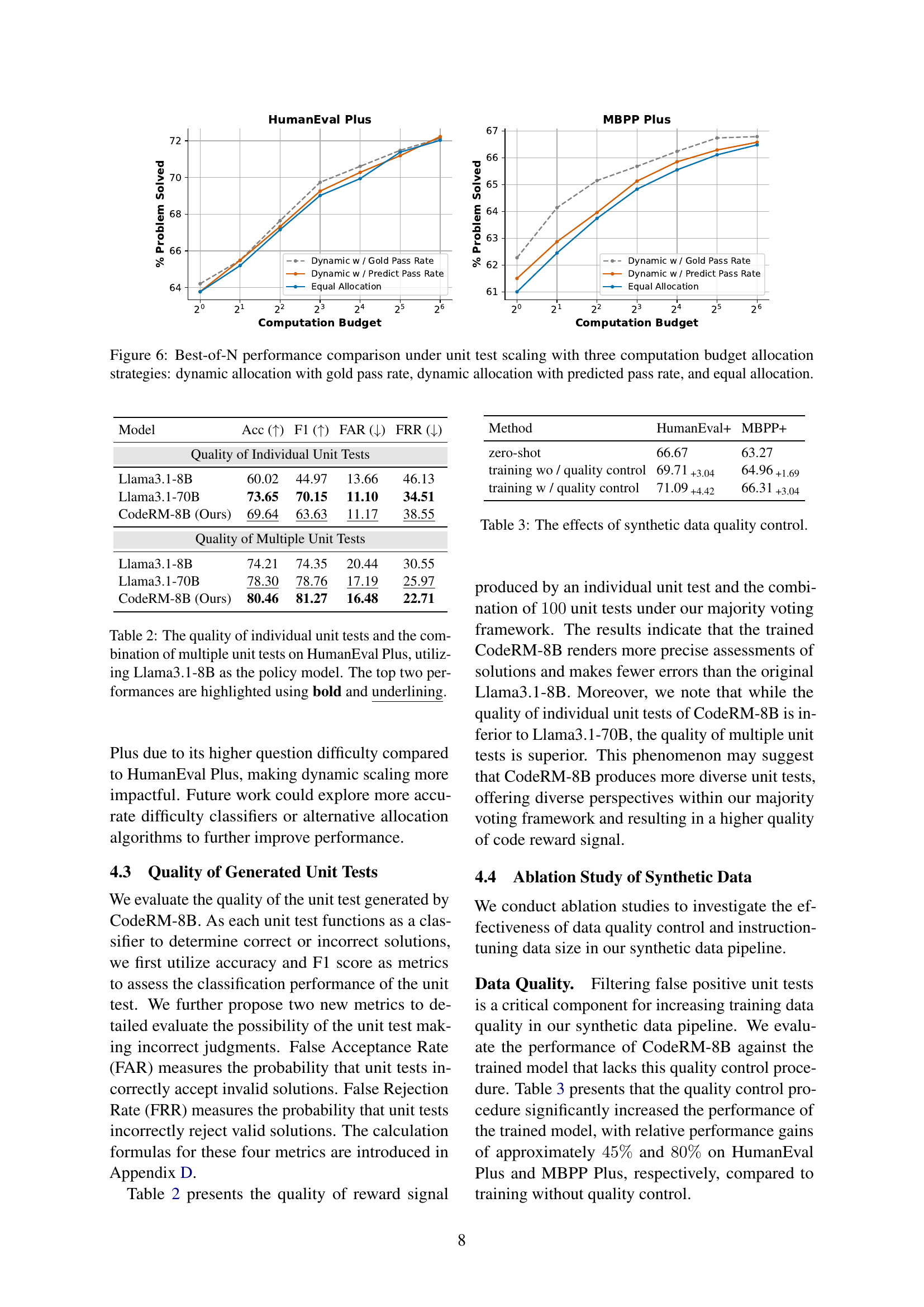
🔼 Figure 6 illustrates the performance comparison of three different computation budget allocation strategies in a best-of-N scenario, where N is the number of code solutions generated by a language model. The three strategies are: 1) Dynamic allocation with gold pass rate, which uses the actual pass rates of solutions to guide resource allocation; 2) Dynamic allocation with predicted pass rate, which utilizes a predicted pass rate of solutions to determine resource allocation; and 3) Equal allocation, which distributes the computation budget evenly among all problems. The figure demonstrates the impact of these strategies on the success rate (y-axis) as the computation budget (x-axis) increases, showing how the different methods affect performance and resource utilization on two different benchmarks, HumanEval Plus and MBPP Plus.
read the caption
Figure 6: Best-of-N performance comparison under unit test scaling with three computation budget allocation strategies: dynamic allocation with gold pass rate, dynamic allocation with predicted pass rate, and equal allocation.

🔼 This figure demonstrates the impact of the size of the training dataset on the performance of the CodeRM-8B model. It shows that increasing the size of the training data leads to significant improvements in the model’s performance on both the HumanEval Plus and MBPP Plus benchmarks. This highlights the importance of high-quality and sufficiently large datasets in achieving optimal performance for unit test generation models.
read the caption
Figure 7: The effects of data size.

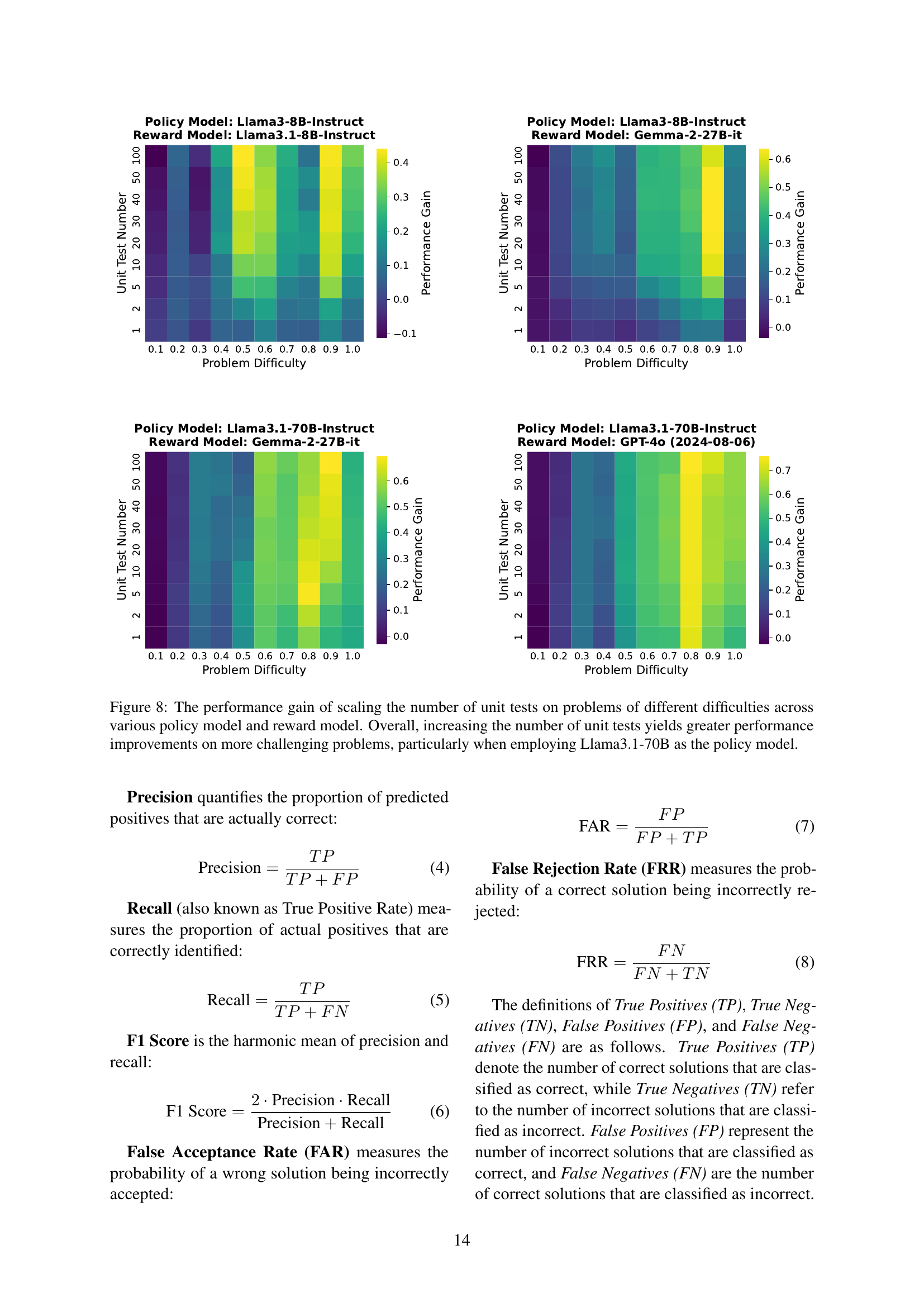
🔼 Figure 8 presents a detailed analysis of how scaling the number of unit tests impacts performance on problems with varying difficulty levels. The results are shown across four different combinations of policy models (which generate code solutions) and reward models (which generate unit tests). The x-axis represents the problem’s difficulty, ranging from easiest to hardest. The y-axis shows the performance gain achieved by increasing the number of unit tests, with each line representing a different number of tests. The heatmap visualization clearly illustrates that the performance gains from scaling unit tests are significantly higher for more challenging problems. This effect is particularly pronounced when using the Llama3.1-70B model as the policy model.
read the caption
Figure 8: The performance gain of scaling the number of unit tests on problems of different difficulties across various policy model and reward model. Overall, increasing the number of unit tests yields greater performance improvements on more challenging problems, particularly when employing Llama3.1-70B as the policy model.

🔼 This figure shows an example from the training data used to train the unit test generator. The example includes the instructions given to the large language model (LLM), the code that the LLM was asked to test, and the resulting unit test code that the LLM generated. The instructions specify the task: to generate unit tests for a given function (here,
expected_strangle_return). The code shows the function definition, which calculates the expected return of a financial strategy called a ‘strangle.’ The unit test code then demonstrates testing various scenarios (positive, negative, and zero return) to ensure the function performs correctly under different conditions. The example highlights the expected input parameters and the expected return values for each test case.read the caption
Figure 9: An example of the training data for the unit test generator.
More on tables
| Model | Acc ( | F1 ( | FAR ( | FRR ( |
|---|---|---|---|---|
| Llama3.1-8B | 60.02 | 44.97 | 13.66 | 46.13 |
| Llama3.1-70B | 73.65 | 70.15 | 11.10 | 34.51 |
| CodeRM-8B (Ours) | 69.64 | 63.63 | 11.17 | 38.55 |
| Llama3.1-8B | 74.21 | 74.35 | 20.44 | 30.55 |
| Llama3.1-70B | 78.30 | 78.76 | 17.19 | 25.97 |
| CodeRM-8B (Ours) | 80.46 | 81.27 | 16.48 | 22.71 |
🔼 This table presents a quantitative evaluation of the quality of unit tests generated by different models. It compares the performance of individual unit tests and the combined effect of multiple unit tests (using a majority voting approach) in identifying correct code solutions on the HumanEval Plus benchmark. The results are specifically shown for Llama3.1-8B as the model generating code solutions (policy model). The table highlights metrics such as accuracy, F1-score, false acceptance rate (FAR), and false rejection rate (FRR) to illustrate the effectiveness of the unit test generation models. The top two performing models are highlighted for each metric.
read the caption
Table 2: The quality of individual unit tests and the combination of multiple unit tests on HumanEval Plus, utilizing Llama3.1-8B as the policy model. The top two performances are highlighted using bold and underlining.
| Method | HumanEval+ | MBPP+ |
|---|---|---|
| zero-shot | 66.67 | 63.27 |
| training wo / quality control | 69.71+3.04 | 64.96+1.69 |
| training w / quality control | 71.09+4.42 | 66.31+3.04 |
🔼 This table presents the results of an ablation study evaluating the impact of synthetic data quality control on the performance of the CodeRM-8B model. It shows the effects of applying quality control during the creation of synthetic training data for the unit test generator, comparing metrics (Accuracy, F1-score, False Acceptance Rate (FAR), False Rejection Rate (FRR)) with and without the quality control step. The comparison is done using the Llama3.1-8B and Llama3.1-70B models, showcasing how quality control enhances the reliability and precision of the generated unit tests.
read the caption
Table 3: The effects of synthetic data quality control.
| Hyperparameters | Value |
|---|---|
| Temperature | 0.8 |
| Top P | 0.95 |
| Frequency Penalty | 0 |
| Presence Penalty | 0 |
🔼 This table lists the hyperparameters used for tuning the large language models (LLMs) employed in the paper. These parameters control aspects of the LLMs’ behavior during both code solution generation and unit test generation. Specifically, it shows the values set for temperature, top-p (nucleus sampling), frequency penalty, and presence penalty. These parameters influence the randomness and creativity of the model’s output, and the values chosen reflect a balance between exploration and exploitation.
read the caption
Table 4: The hyperparameters of LLMs for solution and unit test generation.
Full paper#