TL;DR#
Current mobile GUI agent research lacks a comprehensive evaluation platform for real-world tasks. Existing datasets often focus on static frame evaluations, failing to capture the dynamic and interactive nature of real-world mobile usage, leading to a disconnect between evaluation and real-world performance.
Android Agent Arena (A3) tackles these issues by introducing a new evaluation platform. A3 offers a diverse set of tasks based on real-world scenarios, using 21 widely used third-party apps, enabling compatibility with agents trained on any dataset. A3 also introduces a novel automated evaluation method leveraging the capabilities of business-level LLMs, significantly reducing the need for manual effort. The LLM-based evaluation approach enables scalability and reduces the requirement for coding expertise, allowing for a more extensive and efficient evaluation process.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing mobile GUI agent evaluation platforms. A3 offers a more comprehensive and interactive evaluation platform, including meaningful tasks, a flexible action space, and an automated evaluation process, advancing research and development in the field. Its novel evaluation method using LLMs offers significant scalability for future work. This is highly relevant to the current trend of developing more robust and adaptable AI agents for real-world applications.
Visual Insights#

🔼 Android Agent Arena (A3) is an evaluation platform for mobile GUI agents. It includes over 200 tasks across 21 popular apps, categorized by task type (operation, single-frame query, multi-frame query) and difficulty (easy, medium, hard). A3 uses two evaluation methods to assess agent performance in realistic scenarios.
read the caption
Figure 1: Overview of Android Agent Arena. A3 contains over 200 tasks from 21 widely used apps. Tasks are categorized into operation, single-frame query and multi-frame query based on the task goal. Tasks are also split into three difficulty levels based on the human operation steps. A3 also integrates two evaluation methods for different use cases.
| Name | Eval Mode | # Tasks | # General Apps | Operation | Inf. Query |
|---|---|---|---|---|---|
| AitW | static | - | - | ✓ | ✗ |
| AndroidControl | static | - | - | ✓ | ✗ |
| AMEX | static | - | - | ✓ | ✗ |
| AndroidArena | dynamic | 221 | 4 | ✓ | ✗ |
| Mobile-Env | dynamic | 74 | 5 | ✓ | ✗ |
| AndroidWorld | dynamic | 116 | 15 | ✓ | ✗ |
| B-Moca | dynamic | 131 | 4 | ✓ | ✗ |
| AndroidLab | dynamic | 138 | 5 | ✓ | ✓ |
| A3 (Our) | dynamic | 201 | 21 | ✓ | ✓ |
🔼 This table compares several existing datasets and benchmarks for evaluating GUI agents, highlighting key characteristics such as evaluation method (static or dynamic), the number of tasks and general-purpose apps included, and whether they support operational instructions and information queries. It notes that 15 of AndroidWorld’s apps come from F-Droid, an open-source app repository. This provides context on the scope and diversity of each benchmark, allowing researchers to choose the most appropriate tools for their needs.
read the caption
Table 1: GUI related datasets and benchmarks. 15 general apps of AndroidWorld are from F-Droid.
In-depth insights#
Mobile GUI Agent#
Mobile GUI agents represent a significant advancement in AI, aiming to bridge the gap between human users and mobile devices through autonomous task completion. Their reliance on multimodal large language models (MLLMs) allows them to interact with applications beyond simple API calls, enabling more complex and dynamic interactions. However, the evaluation of these agents presents challenges. Existing datasets often rely on static frame evaluations, failing to capture the dynamic nature of real-world mobile interactions. This limitation necessitates the development of more comprehensive and interactive evaluation platforms capable of assessing agents in real-world settings, considering task complexity, multi-step actions, and adaptability to unforeseen outcomes. The development of such platforms, along with robust benchmarks, is critical for advancing research and development in this promising area of AI.
A3 Benchmark#
An A3 benchmark, in the context of mobile GUI agent evaluation, would ideally offer a comprehensive and dynamic assessment of agent capabilities. It should move beyond static image-based evaluations, incorporating realistic, multi-step tasks reflecting real-world user scenarios. A strong benchmark needs diverse tasks, spanning various app types and complexities, including operation tasks, single-frame queries, and multi-frame queries. The ability to measure an agent’s ability to handle unexpected situations and adapt to changing app states is also critical. The benchmark should also provide scalable and automated evaluation methods, ideally leveraging LLM capabilities to reduce manual effort and allow for continuous expansion of the benchmark’s scope. Finally, a good A3 benchmark would facilitate transparent and reproducible evaluations, allowing researchers to easily compare their agent’s performance with others and identify key areas for future improvement.
LLM Evaluation#
Evaluating Large Language Models (LLMs) is crucial for advancing the field. Robust evaluation necessitates going beyond simple accuracy metrics, encompassing aspects like reasoning, bias, toxicity, and factual consistency. Benchmark datasets play a vital role, yet their design must carefully consider the diversity of tasks and potential biases, ensuring generalizability. Human evaluation remains important for nuanced judgments, though it’s resource-intensive. Automated metrics offer scalability, but may not capture the subtle complexities of human language understanding. Developing comprehensive evaluation frameworks requires a multi-faceted approach, integrating both automated and human assessments across diverse datasets and tasks. The ultimate goal is a rigorous and transparent evaluation process, enabling fair comparison and driving future LLM development.
Real-World Tasks#
The concept of “Real-World Tasks” in the context of mobile GUI agent evaluation is crucial. Existing benchmarks often fall short by focusing on static, simplified tasks that don’t reflect the dynamic and complex nature of real user interactions. Real-world tasks should encompass a wide range of activities and difficulty levels, involving multiple steps, diverse app interactions, and unpredictable outcomes. The evaluation metrics must go beyond simple success/failure, considering factors like efficiency, robustness to unexpected events, and the ability to handle ambiguous or incomplete instructions. A robust evaluation framework for real-world tasks would greatly advance the field of mobile GUI agents, leading to more capable and useful AI assistants. This necessitates creating datasets that capture the rich tapestry of actual user scenarios, and implementing sophisticated evaluation methods that are context-aware and capable of evaluating an agent’s overall problem-solving skills in the face of real-world complexities.
Future work#
Future research directions stemming from this Android Agent Arena (A3) project could focus on several key areas. Improving the robustness and adaptability of agents is crucial; current agents struggle with unexpected events and changing app states. Further work should investigate more sophisticated action planning and reasoning capabilities, perhaps through enhanced LLM integration. A3 currently relies on a limited set of apps; expanding the scope to include a more diverse range of real-world applications would significantly enhance its realism and usefulness. Finally, developing more nuanced evaluation metrics beyond simple success/failure rates is necessary to capture the intricacies of agent performance in complex, dynamic tasks. This could involve analyzing intermediate steps, resource usage, and the quality of interactions with the interface.
More visual insights#
More on figures

🔼 The Android Agent Arena (A3) system architecture consists of three main components: a controller, a translator, and an evaluator. The controller interacts directly with the Android device, managing actions such as screen captures, XML data retrieval, and sending commands. The translator mediates between the agent and the device, converting agent actions into device-compatible commands and vice-versa. The evaluator assesses the agent’s performance by comparing the final state of the device to the task’s expected outcome, providing a quantitative measure of success. This modular design allows for flexibility and easy integration with different agents and evaluation methods.
read the caption
Figure 2: Overview of Android Agent Arena. A3 contains controller, evaluator, and translator. The controller is responsible for controlling and getting the state of the device. The translator is responsible for translating the device function and the agent messages. The evaluator is responsible for the final evaluation.

🔼 Figure 3 shows the distribution of tasks within the Android Agent Arena (A3) dataset. The top pie chart displays the breakdown of tasks into three categories: Operation, Single-Frame Query, and Multi-Frame Query. The bottom pie chart illustrates the difficulty levels of the tasks, categorized as Easy, Medium, and Hard. This visualization helps understand the task diversity and complexity within the A3 dataset, providing insights into the range of challenges that mobile GUI agents are evaluated on.
read the caption
Figure 3: Distribution of tasks in A3. The above subfigure is the distribution by categories and the bottom subfigure is the distribution by difficulty levels.

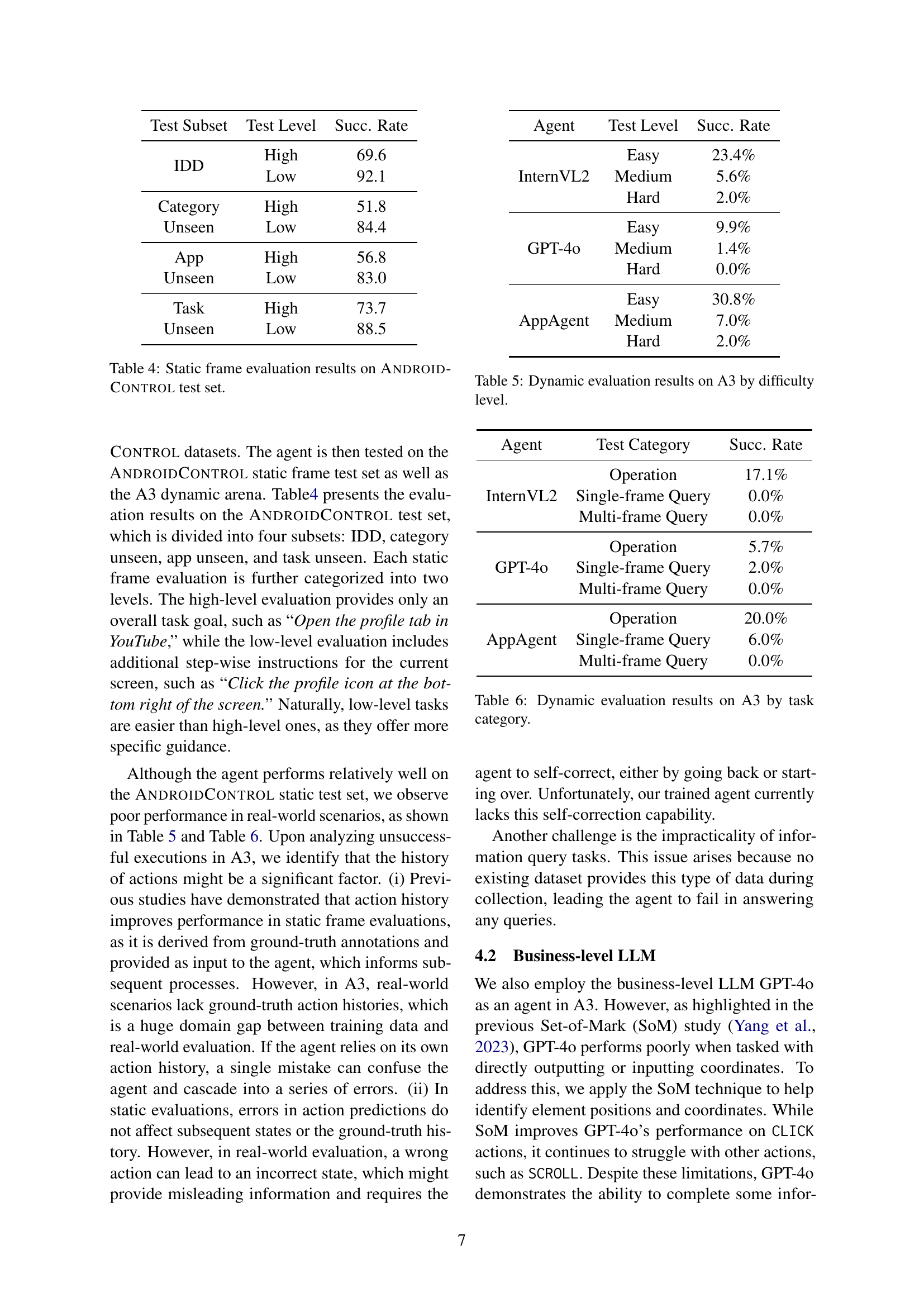
🔼 The figure shows a screenshot sequence illustrating an error case during the execution of a task in the Android Agent Arena (A3) system. Steps 1 and 2 of the task, ‘Search ‘Linear Algebra’ on Coursera,’ are correctly executed by the agent. However, the agent initiates typing in the search bar before ensuring the search bar is selected, causing the system to remain unresponsive to further actions. Consequently, the agent is stuck in a loop of continuously typing and waiting, failing to complete the task.
read the caption
Figure 4: Step 1 and Step 2 are correct, however, the agent starts typing before the search bar is clicked or selected, so the process sticks at this situation and the agent keeps typing and waiting.

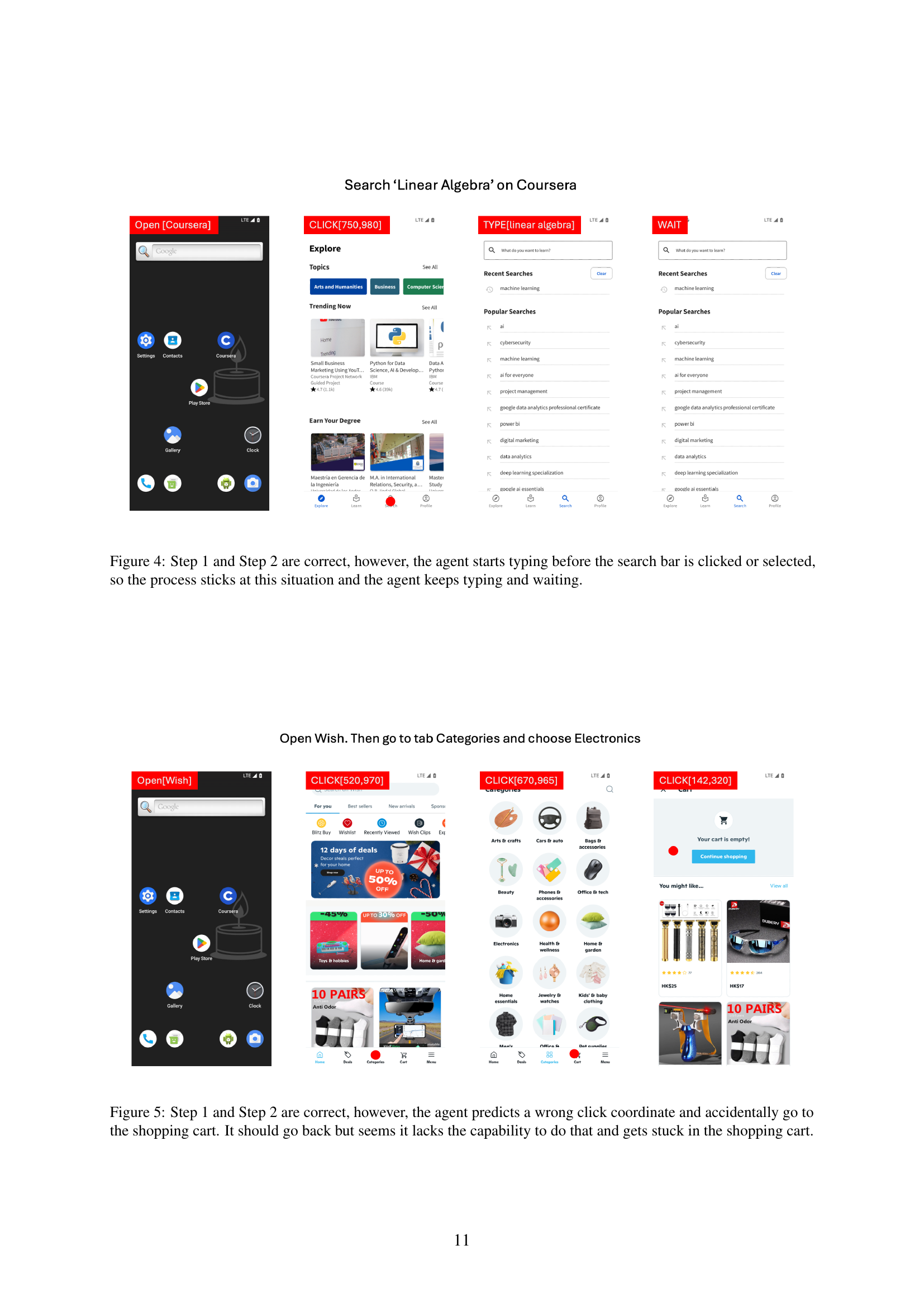
🔼 Figure 5 shows an example of a failure case during the execution of a task in the Android Agent Arena (A3) evaluation platform. Steps 1 and 2 of the task were completed successfully by the AI agent. However, in step 3, the agent incorrectly predicted the coordinates for a click action, resulting in an unintended navigation to the shopping cart instead of the desired location. The agent lacks the ability to recover from this error and correct its course, leaving it stuck in the shopping cart and unable to proceed with the task.
read the caption
Figure 5: Step 1 and Step 2 are correct, however, the agent predicts a wrong click coordinate and accidentally go to the shopping cart. It should go back but seems it lacks the capability to do that and gets stuck in the shopping cart.
More on tables
| LLM | Correct Func. | Wrong Line |
|---|---|---|
| GPT-4o | 24% | 27% |
🔼 This table presents the results of using GPT-40 to automatically generate evaluation functions for tasks in the Android Agent Arena (A3) dataset. It shows the percentage of generated evaluation functions that were completely correct and the percentage of lines within those functions that contained errors. These percentages are based on assessments by coding experts, providing a measure of the model’s ability to generate accurate and functional code for automated task evaluation.
read the caption
Table 2: The capability of GPT-4o to directly generate evaluation function. “Correct Func.” represents the percentage of correct files over all generated files. “Wrong Line” represents the percentage of incorrect lines over all code generated. The evaluation is collected from coding experts.
| LLM | Eval Correct |
|---|---|
| GPT-4o | 84% |
| Gemini 1.5 Pro | 80% |
🔼 This table presents the accuracy of using Large Language Models (LLMs) for automated evaluation of tasks in the Android Agent Arena. Fifty tasks were evaluated using LLMs, and the results were then checked by human evaluators for correctness. The ‘Eval Correct’ column indicates the percentage of times the LLM’s evaluation matched the human evaluator’s judgment.
read the caption
Table 3: The correctness of LLM evaluation by human validation from 50 tasks. “Eval Correct” represents the correctness of LLM evaluation results determined by human.
| Test Subset | Test Level | Succ. Rate |
|---|---|---|
| IDD | High | 69.6 |
| IDD | Low | 92.1 |
| Category | High | 51.8 |
| Unseen | Low | 84.4 |
| App | High | 56.8 |
| Unseen | Low | 83.0 |
| Task | High | 73.7 |
| Unseen | Low | 88.5 |
🔼 This table presents the results of static frame evaluations performed on the AndroidControl test set. The test set is divided into four subsets: IDD, Category Unseen, App Unseen, and Task Unseen. Each subset represents a different aspect of unseen data, allowing for a comprehensive evaluation of generalization capabilities. Further, the evaluations are categorized into high-level and low-level, reflecting variations in task instruction detail (high-level provides only the overall task goal, while low-level adds additional, step-by-step instructions). The success rates for each subset and level are reported to show the performance of the tested agent under various scenarios.
read the caption
Table 4: Static frame evaluation results on AndroidControl test set.
| Agent | Test Level | Succ. Rate |
|---|---|---|
| InternVL2 | Easy | 23.4% |
| Medium | 5.6% | |
| Hard | 2.0% | |
| GPT-4o | Easy | 9.9% |
| Medium | 1.4% | |
| Hard | 0.0% | |
| AppAgent | Easy | 30.8% |
| Medium | 7.0% | |
| Hard | 2.0% |
🔼 This table presents the results of dynamic evaluations performed on the Android Agent Arena (A3) platform. The evaluations assess the success rate of different agents (InternVL2, GPT-40, AppAgent) across various difficulty levels (Easy, Medium, Hard) for completing tasks. The success rate represents the percentage of tasks successfully completed by each agent at each difficulty level. This provides a measure of how well each agent performs in dynamic, real-world settings.
read the caption
Table 5: Dynamic evaluation results on A3 by difficulty level.
| Agent | Test Category | Succ. Rate |
|---|---|---|
| InternVL2 | Operation | 17.1% |
| Single-frame Query | 0.0% | |
| Multi-frame Query | 0.0% | |
| GPT-4o | Operation | 5.7% |
| Single-frame Query | 2.0% | |
| Multi-frame Query | 0.0% | |
| AppAgent | Operation | 20.0% |
| Single-frame Query | 6.0% | |
| Multi-frame Query | 0.0% |
🔼 This table presents the success rates of three different agents (InternVL2, GPT-40, and AppAgent) on the Android Agent Arena (A3) platform. The agents are evaluated on three distinct task categories: Operation, Single-frame Query, and Multi-frame Query, representing different levels of complexity. The success rate indicates the percentage of tasks successfully completed by each agent within each category. This provides a comparative analysis of agent performance across various task types.
read the caption
Table 6: Dynamic evaluation results on A3 by task category.
Full paper#