TL;DR#
Fine-grained action recognition (FAR) is a challenging task due to the need for detailed annotations and substantial data for training. Existing large language models often fail to accurately recognize fine-grained actions. This paper addresses the challenges of FAR by focusing on semi-supervised learning to reduce the need for extensive labeled data. This is particularly important because labeling fine-grained actions is time-consuming and requires expert knowledge.
The paper introduces SeFAR, a novel framework that incorporates several innovative designs to tackle the challenges of semi-supervised FAR. These designs include dual-level temporal element modeling to capture visual details, a strong augmentation strategy involving moderate temporal perturbation, and an adaptive regulation method to stabilize the learning process. The experimental results demonstrate that SeFAR outperforms existing methods on multiple datasets, showcasing its effectiveness and potential for broader applications in video understanding.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of semi-supervised fine-grained action recognition (FAR), a crucial aspect of video understanding with significant real-world applications. The proposed SeFAR framework offers a novel approach to handle the scarcity of labeled data in FAR, a common limitation in many computer vision tasks. Its innovative design and strong performance open up exciting avenues for future research in semi-supervised learning and multimodal understanding.
Visual Insights#

🔼 This figure shows two examples of fine-grained actions from the FineGym dataset. The top example is labeled as ‘pike sole circle backward with 0.5 turn to handstand.’ The bottom example is labeled as ‘…1 turn…’ indicating a similar but distinct action. The figure highlights the challenge of fine-grained action recognition by showing that popular large language models (LLMs) struggle to distinguish between these visually similar actions. Four specific LLMs are tested on the bottom example to demonstrate this difficulty: GPT-4V, VideoChat2, VideoLLaVA, and InternLM-XComposer-2.5.
read the caption
Figure 1: Fine-grained Action Instances. The two samples are drawn from the FineGym (Shao et al. 2020a) dataset, specifically the “pike sole circle backward with 0.5 turn to handstand” at the top and the “… 1 turn …” at the bottom. We further test popular MLLMs on the bottom instance for both coarse-grained and fine-grained: GPT-4V (OpenAI 2024), VideoChat2 (Li et al. 2024), VideoLLaVA (Lin et al. 2023), and InternLM-XComposer-2.5 (Zhang et al. 2024).
| 2.5 Method | Backbone | Input | ImgNet | Params | #F | Epoch | Gym99 5% | Gym99 10% | Gym288 5% | Gym288 10% | Diving 5% | Diving 10% |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 MemDPC (ECCV’20) [Han, Xie, and Zisserman 2020] | 3D-ResNet-18 | V | ✗ | 15.4M | 16 | 500 | 10.8 | 24.1 | 14.5 | 21.3 | 54.3 | 62.0 |
| LTG (CVPR’22) [Xiao et al. 2022] | 3D-ResNet-18 | VG | ✗ | 68.3M | 8 | 180 | 34.3 | 45.8 | 16.2 | 38.7 | 59.8 | 64.3 |
| SVFormer (CVPR’23) [Xing et al. 2023] | ViT-B | V | ✓ | 121.4M | 8 | 30 | 31.4 | 47.9 | 21.3 | 39.6 | 59.1 | 70.8 |
| SeFAR-S (Ours) | VIT-S | V | ✓ | 31.2M | 8 | 30 | 36.7 | 56.3 | 27.8 | 46.9 | 72.2 | 78.4 |
| SeFAR-B (Ours) | VIT-B | V | ✓ | 122.1M | 8 | 30 | 39.0 | 56.9 | 28.3 | 48.1 | 72.8 | 80.9 |
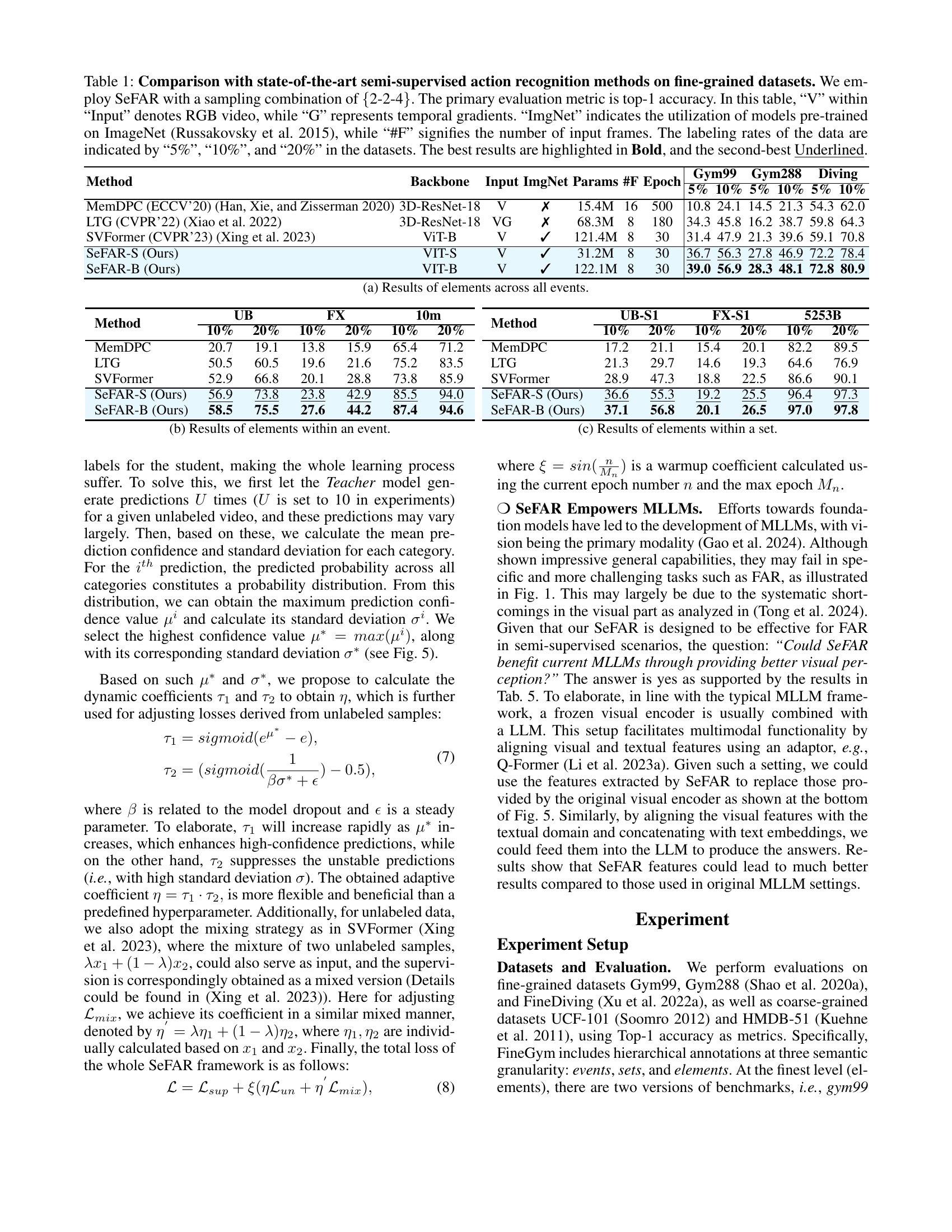
🔼 Table 1 presents a comparison of SeFAR’s performance against other state-of-the-art semi-supervised action recognition methods on fine-grained datasets. The key metric used for comparison is top-1 accuracy. Different experimental settings are considered, including variations in the input data (RGB video, temporal gradients), the use of ImageNet pre-trained models, the number of input frames processed, and different data labeling rates (5%, 10%, 20%). SeFAR uses a specific sampling combination of {2-2-4}. The table highlights the best and second-best results for easy identification.
read the caption
Table 1: Comparison with state-of-the-art semi-supervised action recognition methods on fine-grained datasets. We employ SeFAR with a sampling combination of {2-2-4}. The primary evaluation metric is top-1 accuracy. In this table, “V” within “Input” denotes RGB video, while “G” represents temporal gradients. “ImgNet” indicates the utilization of models pre-trained on ImageNet (Russakovsky et al. 2015), while “#F” signifies the number of input frames. The labeling rates of the data are indicated by “5%”, “10%”, and “20%” in the datasets. The best results are highlighted in Bold, and the second-best Underlined.
In-depth insights#
Semi-Supervised FAR#
Semi-supervised Fine-grained Action Recognition (FAR) tackles the challenge of recognizing detailed actions within short video segments using limited labeled data. This approach is crucial because annotating fine-grained actions is expensive and time-consuming. The core idea is to leverage both labeled and unlabeled data to train a model capable of distinguishing subtle differences between similar actions. This involves innovative techniques such as dual-level temporal element modeling to capture both local details and global context of the actions, and moderate temporal perturbation to create stronger augmentations while preserving temporal dynamics. Furthermore, adaptive regulation helps stabilize the training process, particularly when dealing with uncertain pseudo-labels generated from the unlabeled data. The efficacy of this approach is demonstrated by achieving state-of-the-art results on various benchmarks. This research significantly advances the field by enabling more efficient and scalable training of fine-grained action recognition models.
Dual-Level Modeling#
Dual-level modeling, in the context of semi-supervised fine-grained action recognition, is a crucial technique for effectively capturing the multifaceted nature of human actions. It acknowledges that actions possess both fine-grained details and broader contextual information. Instead of relying on a single representation, dual-level modeling incorporates two levels of temporal feature extraction: one focusing on short, highly detailed segments within an action, and the other focusing on longer, more contextual segments. This approach is particularly useful in distinguishing subtle differences between actions. The fine-grained level captures the nuances of movement, allowing the model to identify minute changes that may differentiate similar actions. The contextual level provides a broader understanding of the overall action, enabling the model to contextualize the fine-grained details within the overall flow of the movement. This dual approach improves the model’s robustness to variations in execution and provides a more holistic understanding of the action, leading to improved performance in fine-grained action recognition tasks. The successful implementation of dual-level modeling highlights the importance of considering both the micro and macro aspects of temporal information, a concept crucial for accurately classifying complex, fine-grained human actions.
Temporal Perturbation#
Temporal perturbation, as a data augmentation technique in the context of semi-supervised fine-grained action recognition, is a crucial innovation. It addresses the challenge of learning from limited labeled data by strategically introducing moderate distortions to the temporal dimension of video clips. Unlike traditional spatial augmentations that can disrupt critical temporal information within actions, temporal perturbation focuses on altering the temporal order of fine-grained elements within the video, leaving the temporal context largely untouched. This approach ensures that the model learns to recognize actions based on the sequence of events rather than relying on specific spatial features. The careful balance between preserving temporal context and introducing moderate perturbations is key. Too much perturbation could lead to model instability and hinder learning, whereas insufficient perturbation might not sufficiently improve robustness. The effectiveness of temporal perturbation is validated by its contribution to state-of-the-art results and by ablation studies demonstrating the improvement in performance. The method’s adaptability and its capacity to enhance the understanding of fine-grained actions further underscores its importance in tackling the challenges of data scarcity in semi-supervised learning within the action recognition field. The choice to reverse the order of the fine-grained elements, as opposed to more disruptive methods, showcases a thoughtful consideration of the inherent temporal dynamics within actions, demonstrating both effectiveness and efficiency.
Adaptive Regulation#
The concept of ‘Adaptive Regulation’ in the context of semi-supervised fine-grained action recognition is crucial for handling the inherent instability of the learning process. The high uncertainty in predictions from the teacher model, especially when dealing with subtle differences in fine-grained actions, can easily lead to unreliable pseudo-labels and learning instability. The proposed adaptive regulation mechanism addresses this by dynamically adjusting loss weights based on the confidence and variance of the teacher’s predictions. High-confidence predictions receive increased weight, while predictions with high variance are down-weighted, thus stabilizing the learning process. This is particularly important in semi-supervised scenarios where the limited labeled data makes the learning process more prone to collapse. By incorporating this adaptive weighting, the framework ensures robust learning even with unstable teacher predictions, resulting in improved model performance. The adaptive regulation mechanism represents a significant contribution to semi-supervised learning, providing a more reliable and stable approach to fine-grained action recognition, which is prone to high uncertainty in pseudo-label generation.
MLLM Enhancement#
The paper explores enhancing Multimodal Large Language Models (MLLMs) for fine-grained action recognition (FAR). A core contribution is the SeFAR framework, which significantly improves MLLM performance by acting as a superior visual encoder. Instead of relying solely on pre-trained visual encoders within the MLLM architecture, SeFAR’s features are integrated, leading to substantial accuracy gains in FAR tasks. This demonstrates that specialized, semi-supervised training focused on detailed temporal dynamics is crucial for accurate fine-grained action understanding. The results suggest that while MLLMs offer general capabilities, they may lack the specific visual processing needed for domain-specific tasks like FAR. SeFAR successfully bridges this gap, highlighting the potential of combining specialized models with general-purpose foundation models to improve performance on challenging tasks requiring high accuracy and detailed semantic understanding.
More visual insights#
More on figures

🔼 SeFAR, a semi-supervised framework for fine-grained action recognition, is depicted. It uses a teacher-student model setup. Unlabeled video data undergoes two types of augmentations: weak and strong. Weak augmentations feed into the teacher model to generate pseudo-labels. Strong augmentations (using moderate temporal perturbation) are applied to the student model. A dual-level temporal modeling technique captures visual detail at multiple granularities. Adaptive regulation stabilizes the training process by adjusting the loss function based on teacher model confidence. The final training loss is a weighted combination of supervised and unsupervised losses.
read the caption
Figure 2: Overview of SeFAR pipeline. We target Semi-supervised FAR, assuming most input samples are unlabeled. During unsupervised learning, SeFAR adopts dual-level temporal elements modeling and performs augmentation in two manners (‘Weak’ vs. ‘Strong’). Strongly augmented/distorted samples by moderate temporal perturbation are used by the student model, while the teacher model offers pseudo-labels based on weakly augmented samples. Consistency is enforced through loss minimization (ℒunsubscriptℒ𝑢𝑛\mathcal{L}_{un}caligraphic_L start_POSTSUBSCRIPT italic_u italic_n end_POSTSUBSCRIPT). The unsupervised loss is further adjusted by our proposed Adaptive Regulation. The framework is trained with a weighted combination of supervised ℒsupsubscriptℒ𝑠𝑢𝑝\mathcal{L}_{sup}caligraphic_L start_POSTSUBSCRIPT italic_s italic_u italic_p end_POSTSUBSCRIPT and unsupervised ℒunsubscriptℒ𝑢𝑛\mathcal{L}_{un}caligraphic_L start_POSTSUBSCRIPT italic_u italic_n end_POSTSUBSCRIPT losses.

🔼 Figure 3(a) illustrates the adaptive regulation method used to stabilize the training process in SeFAR. The Teacher model makes multiple predictions for each unlabeled video, and the distribution of these predictions is analyzed. The variability in predictions is higher for fine-grained actions (more challenging to distinguish) compared to coarse-grained actions. An adaptive coefficient (η) is calculated based on the mean and variance of the predictions. This coefficient adjusts the loss function, reducing the impact of less certain predictions and thus stabilizing the training. Figure 3(b) shows how SeFAR’s fine-grained features are integrated into a Multimodal Large Language Model (MLLM) architecture. SeFAR acts as an improved visual encoder within the MLLM framework.
read the caption
Figure 3: (a) For K𝐾Kitalic_K unlabeled videos, the Teacher model predicts each video multiple times to capture the distribution of predictions, which shows less variability on coarse-grained data and more on fine-grained data. An adaptive coefficient η𝜂\etaitalic_η is calculated from the mean and variance of the distribution to stabilize training. (b) MLLM construction pipeline with SeFAR’s fine-grained features.

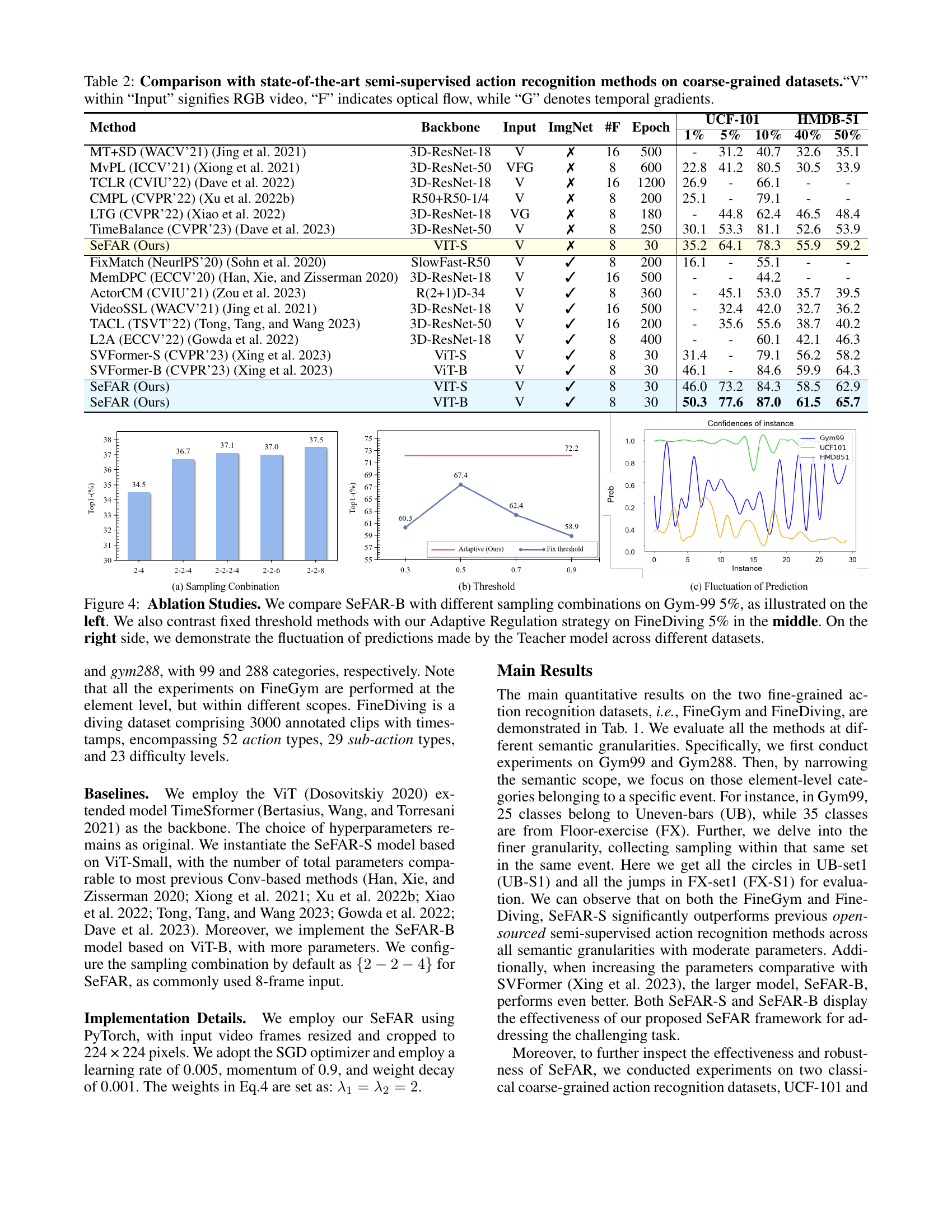
🔼 This figure presents ablation studies conducted on the SeFAR-B model. The left panel compares the performance of SeFAR-B with various sampling combinations on the Gym-99 dataset (with 5% labeled data). The middle panel contrasts the performance of SeFAR-B using a fixed threshold method versus the adaptive regulation approach, again on the FineDiving dataset (also with 5% labeled data). The right panel shows how much the predictions of the teacher model fluctuate across different datasets, illustrating the model’s consistency.
read the caption
Figure 4: Ablation Studies. We compare SeFAR-B with different sampling combinations on Gym-99 5%, as illustrated on the left. We also contrast fixed threshold methods with our Adaptive Regulation strategy on FineDiving 5% in the middle. On the right side, we demonstrate the fluctuation of predictions made by the Teacher model across different datasets.

🔼 This figure shows two plots illustrating the relationship between the teacher model’s prediction performance and its uncertainty. The left plot shows the relationship between the teacher model’s prediction accuracy and its confidence score. Higher confidence scores are associated with higher accuracy. The right plot shows the relationship between prediction accuracy and the standard deviation of the teacher model’s predictions. Lower standard deviations (indicating less uncertainty) are associated with higher prediction accuracy. These plots demonstrate the model’s uncertainty and its relation to the prediction accuracy, supporting the use of adaptive regulation in the SeFAR framework.
read the caption
Figure 5: The relationship between the Teacher model’s prediction accuracy and its confidence (left), as well as its standard deviation (right).

🔼 This figure displays examples from the Gym-QA dataset, which is a multiple-choice question-answering dataset derived from the FineGym dataset. Each example shows a video still along with a multiple-choice question about the action performed in the video. The questions focus on fine-grained action recognition, requiring detailed understanding of subtle differences in the actions. The aim is to evaluate the capabilities of Multimodal Large Language Models (MLLMs) in this challenging fine-grained action recognition task.
read the caption
Figure 6: Examples of Gym-QA

🔼 Figure 7 shows examples of the Gym-New dataset, which is a subset of the FineGym dataset specifically curated for evaluating the impact of temporal directionality on action recognition. It consists of pairs of actions that are essentially the reverse of each other, like ‘salto forward stretched with 2 twists’ and ‘salto backward stretched with 2 twists.’ These pairs highlight the challenges of temporal understanding in fine-grained action recognition, where the direction of the movement significantly impacts the action’s semantic meaning.
read the caption
Figure 7: Examples of Gym-New

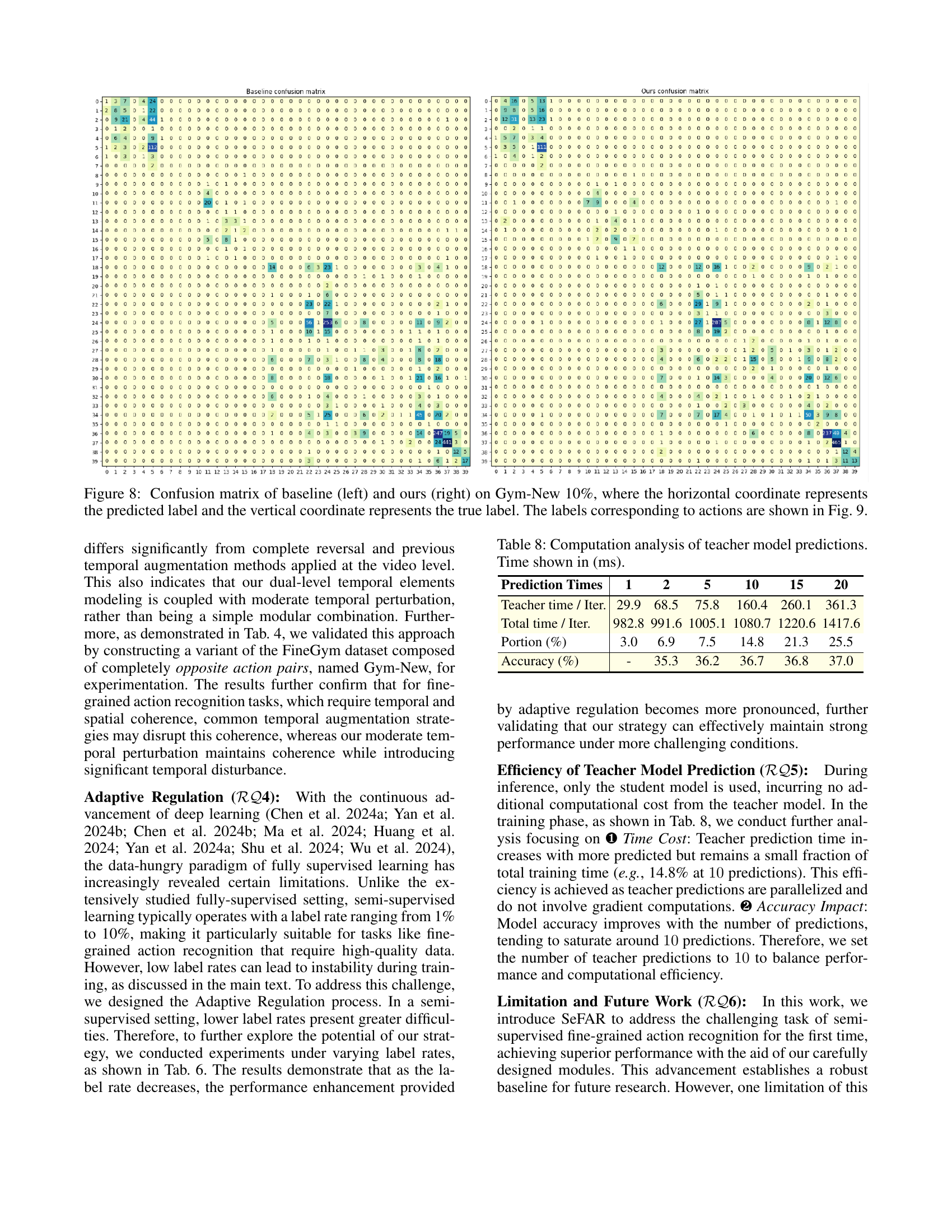
🔼 This figure displays two confusion matrices, one for a baseline model and one for the SeFAR model, both evaluated on the Gym-New dataset using 10% of the labeled data. Each matrix visualizes the performance of the respective model by showing the counts of true positive and false positive classifications across all action categories within Gym-New. The horizontal axis represents the predicted action labels, and the vertical axis represents the true action labels. The color intensity corresponds to the frequency of a specific prediction. Darker colors represent more frequent correct predictions (diagonal elements), while lighter colors represent incorrect predictions. By comparing the two matrices, one can assess the improvement in prediction accuracy achieved by the SeFAR model.
read the caption
Figure 8: Confusion matrix of baseline (left) and ours (right) on Gym-New 10%, where the horizontal coordinate represents the predicted label and the vertical coordinate represents the true label. The labels corresponding to actions are shown in Fig. 9.

🔼 This figure shows a table that lists the labels for actions included in the Gym-New dataset, which is a subset of the FineGym dataset used for evaluating fine-grained action recognition models. The labels are categorized by the apparatus used (Uneven Bars, Floor Exercise, Balance Beam) and provide more detailed descriptions of actions than coarser-grained categories. Each action is given a unique numerical ID. This detailed labeling is crucial for the fine-grained nature of the Gym-New dataset and the specific evaluation tasks within the paper.
read the caption
Figure 9: Labels corresponding to actions in Gym-New.
More on tables
| Method | UB (10%) | UB (20%) | FX (10%) | FX (20%) | 10m (10%) | 10m (20%) |
|---|---|---|---|---|---|---|
| 2.5 Method | UB | FX | 10m | |||
| 10% | 20% | 10% | 20% | 10% | 20% | |
| 2 MemDPC | 20.7 | 19.1 | 13.8 | 15.9 | 65.4 | 71.2 |
| LTG | 50.5 | 60.5 | 19.6 | 21.6 | 75.2 | 83.5 |
| SVFormer | 52.9 | 66.8 | 20.1 | 28.8 | 73.8 | 85.9 |
| SeFAR-S (Ours) | 56.9 | 73.8 | 23.8 | 42.9 | 85.5 | 94.0 |
| SeFAR-B (Ours) | 58.5 | 75.5 | 27.6 | 44.2 | 87.4 | 94.6 |
| 2.5 |
🔼 This table presents the performance of different semi-supervised action recognition methods on fine-grained datasets. It shows the top-1 accuracy achieved by each method across various data subsets (5%, 10%, and 20% labeled data) for three different fine-grained action recognition tasks: Gym99, Gym288 (both gymnastics), and Diving. The results are broken down into (a) results considering all actions across the entire dataset and (b) results examining elements only within a single event. It allows for a comparison of performance across different methods under varying data conditions and action complexities.
read the caption
(a) Results of elements across all events.
| Method | UB-S1 (10%) | UB-S1 (20%) | FX-S1 (10%) | FX-S1 (20%) | 5253B (10%) | 5253B (20%) |
|---|---|---|---|---|---|---|
| 2.5 Method | UB-S1 | FX-S1 | 5253B | |||
| 10% | 20% | 10% | 20% | 10% | 20% | |
| MemDPC | 17.2 | 21.1 | 15.4 | 20.1 | 82.2 | 89.5 |
| LTG | 21.3 | 29.7 | 14.6 | 19.3 | 64.6 | 76.9 |
| SVFormer | 28.9 | 47.3 | 18.8 | 22.5 | 86.6 | 90.1 |
| SeFAR-S (Ours) | 36.6 | 55.3 | 19.2 | 25.5 | 96.4 | 97.3 |
| SeFAR-B (Ours) | 37.1 | 56.8 | 20.1 | 26.5 | 97.0 | 97.8 |
| 2.5 |
🔼 This table presents the results of experiments conducted on the elements within a specific event in the FineGym dataset. It shows the performance of different semi-supervised action recognition methods in terms of Top-1 accuracy, using various labeling rates (10% and 20%). The methods are evaluated on two different event subsets: Uneven Bars (UB) and Floor Exercise (FX). The table provides a detailed breakdown of the performance within each event, offering a more granular understanding of the methods’ accuracy than the overall results across all events.
read the caption
(b) Results of elements within an event.
| Method | Backbone | Input | ImgNet | #F | Epoch | UCF-101 1% | UCF-101 5% | UCF-101 10% | HMDB-51 40% | HMDB-51 50% |
|---|---|---|---|---|---|---|---|---|---|---|
| 2.5 Method | UCF-101 1% | UCF-101 5% | UCF-101 10% | HMDB-51 40% | HMDB-51 50% | |||||
| — | — | — | — | — | — | — | — | — | — | — |
| 2 MT+SD (WACV’21) [Jing et al. 2021] | 3D-ResNet-18 | V | ✗ | 16 | 500 | - | 31.2 | 40.7 | 32.6 | 35.1 |
| MvPL (ICCV’21) [Xiong et al. 2021] | 3D-ResNet-50 | VFG | ✗ | 8 | 600 | 22.8 | 41.2 | 80.5 | 30.5 | 33.9 |
| TCLR (CVIU’22) [Dave et al. 2022] | 3D-ResNet-18 | V | ✗ | 16 | 1200 | 26.9 | - | 66.1 | - | - |
| CMPL (CVPR’22) [Xu et al. 2022b] | R50+R50-1/4 | V | ✗ | 8 | 200 | 25.1 | - | 79.1 | - | - |
| LTG (CVPR’22) [Xiao et al. 2022] | 3D-ResNet-18 | VG | ✗ | 8 | 180 | - | 44.8 | 62.4 | 46.5 | 48.4 |
| TimeBalance (CVPR’23) [Dave et al. 2023] | 3D-ResNet-50 | V | ✗ | 8 | 250 | 30.1 | 53.3 | 81.1 | 52.6 | 53.9 |
| SeFAR (Ours) | VIT-S | V | ✗ | 8 | 30 | 35.2 | 64.1 | 78.3 | 55.9 | 59.2 |
| 1.6 FixMatch (NeurlPS’20) [Sohn et al. 2020] | SlowFast-R50 | V | ✓ | 8 | 200 | 16.1 | - | 55.1 | - | - |
| MemDPC (ECCV’20) [Han, Xie, and Zisserman 2020] | 3D-ResNet-18 | V | ✓ | 16 | 500 | - | - | 44.2 | - | - |
| ActorCM (CVIU’21) [Zou et al. 2023] | R(2+1)D-34 | V | ✓ | 8 | 360 | - | 45.1 | 53.0 | 35.7 | 39.5 |
| VideoSSL (WACV’21) [Jing et al. 2021] | 3D-ResNet-18 | V | ✓ | 16 | 500 | - | 32.4 | 42.0 | 32.7 | 36.2 |
| TACL (TSVT’22) [Tong, Tang, and Wang 2023] | 3D-ResNet-50 | V | ✓ | 16 | 200 | - | 35.6 | 55.6 | 38.7 | 40.2 |
| L2A (ECCV’22) [Gowda et al. 2022] | 3D-ResNet-18 | V | ✓ | 8 | 400 | - | - | 60.1 | 42.1 | 46.3 |
| SVFormer-S (CVPR’23) [Xing et al. 2023] | ViT-S | V | ✓ | 8 | 30 | 31.4 | - | 79.1 | 56.2 | 58.2 |
| SVFormer-B (CVPR’23) [Xing et al. 2023] | ViT-B | V | ✓ | 8 | 30 | 46.1 | - | 84.6 | 59.9 | 64.3 |
| SeFAR (Ours) | VIT-S | V | ✓ | 8 | 30 | 46.0 | 73.2 | 84.3 | 58.5 | 62.9 |
| SeFAR (Ours) | VIT-B | V | ✓ | 8 | 30 | 50.3 | 77.6 | 87.0 | 61.5 | 65.7 |
🔼 This table presents the performance of different semi-supervised action recognition methods on fine-grained datasets, specifically focusing on the ’element’ level within a particular ‘set’ of actions. The results are shown for different labeling rates (10% and 20%), illustrating how well each method can distinguish between fine-grained action variations within a constrained set of similar actions.
read the caption
(c) Results of elements within a set.
| 2.5 Dual-Ele | Mod-Perturb | Ada-Reg | Gym99 | Gym288 | Diving |
|---|---|---|---|---|---|
| 2 ✗ | ✗ | ✗ | 32.6 | 22.7 | 60.4 |
| ✓ | ✗ | ✗ | 34.8 | 25.4 | 64.6 |
| ✓ | ✓ | ✗ | 35.9 | 26.6 | 67.4 |
| ✓ | ✓ | ✓ | 36.7 | 27.8 | 72.2 |
| 2.5 |
🔼 Table 2 presents a comparison of the SeFAR model’s performance against other state-of-the-art semi-supervised action recognition methods on standard, coarse-grained datasets (UCF101 and HMDB51). The table details each method’s backbone network architecture, the type of input data used (RGB video, optical flow, or temporal gradients), whether ImageNet pre-training was employed, the number of frames processed, the number of training epochs, and the top-1 accuracy achieved at various labeling rates (1%, 5%, 10%, 40%, and 50%). This allows for a comprehensive evaluation of SeFAR’s effectiveness compared to existing techniques in semi-supervised learning for action recognition.
read the caption
Table 2: Comparison with state-of-the-art semi-supervised action recognition methods on coarse-grained datasets.“V” within “Input” signifies RGB video, “F” indicates optical flow, while “G” denotes temporal gradients.
| 2.5 Perturbation | S/O | Gym99 | Gym288 | Diving | G.-New | Sth.-Sth. |
|---|---|---|---|---|---|---|
| 2 Spatial-only | 34.2 | 24.4 | 67.9 | 45.6 | 39.4 | |
| Slow (T-Drop) | S | 35.6 | 25.2 | 68.6 | 45.0 | 41.2 |
| All shuffle | O | 35.2 | 26.3 | 69.0 | 45.5 | 41.9 |
| Local-shuffle | O | 36.4 | 27.6 | 71.9 | 45.3 | 43.3 |
| Warping | O | 35.9 | 24.7 | 68.2 | 44.8 | 40.8 |
| T-Half | O | 36.0 | 24.8 | 68.4 | 44.8 | 42.1 |
| All reverse | O | 36.3 | 27.3 | 71.2 | 45.9 | 42.7 |
| Mod-Perturb | O | 36.7 | 27.8 | 72.2 | 46.2 | 44.9 |
| 2.5 |
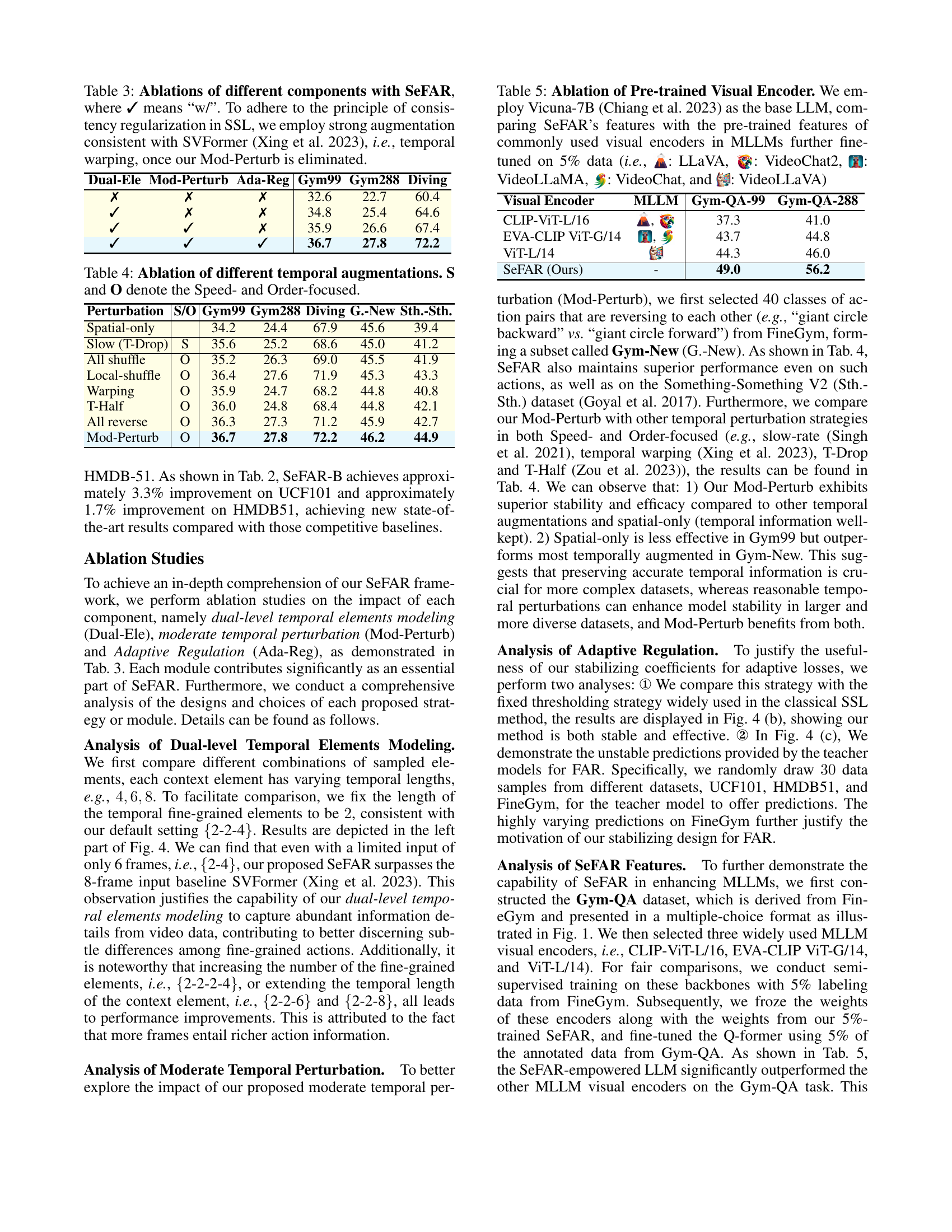
🔼 This table presents the ablation study of different components in the SeFAR model. It shows the performance of the model on three fine-grained action recognition datasets (Gym99, Gym288, Diving) when removing one component at a time. The components analyzed are: dual-level temporal elements modeling, moderate temporal perturbation (Mod-Perturb), and adaptive regulation (Ada-Reg). The baseline uses temporal warping as strong augmentation, consistent with SVFormer (another model), but uses different components in SeFAR to analyze each.
read the caption
Table 3: Ablations of different components with SeFAR, where ✓ means “w/”. To adhere to the principle of consistency regularization in SSL, we employ strong augmentation consistent with SVFormer (Xing et al. 2023), i.e., temporal warping, once our Mod-Perturb is eliminated.
| Visual Encoder | MLLM | Gym-QA-99 | Gym-QA-288 |
|---|---|---|---|
| 2.5 Visual Encoder | MLLM | Gym-QA-99 | Gym-QA-288 |
| 2 CLIP-ViT-L/16 | https://arxiv.org/html/2501.01245/LLaVA.png, https://arxiv.org/html/2501.01245/VideoChat2.png | 37.3 | 41.0 |
| EVA-CLIP ViT-G/14 | https://arxiv.org/html/2501.01245/VideoLLaMA.png, https://arxiv.org/html/2501.01245/VideoChat.png | 43.7 | 44.8 |
| ViT-L/14 | https://arxiv.org/html/2501.01245/VideoLLaMA.png | 44.3 | 46.0 |
| SeFAR (Ours) | - | 49.0 | 56.2 |
| 2.5 |
🔼 This table presents the results of ablation experiments conducted to evaluate the impact of different temporal augmentation techniques on the performance of the SeFAR model. Specifically, it examines the effects of variations in speed and order of temporal augmentations on three fine-grained action recognition datasets: FineGym (FX), FineGym (10m), and FineDiving (5253B). The results are analyzed to determine the optimal temporal augmentation strategy for enhancing the model’s ability to accurately recognize fine-grained actions.
read the caption
Table 4: Ablation of different temporal augmentations. S and O denote the Speed- and Order-focused.
| Method | FineDiving | ||||
|---|---|---|---|---|---|
| 2.5 Method | 1% | 3% | 5% | 7% | 10% |
| 2 SeFAR w/o Ada-Reg | 61.5 | 64.6 | 67.2 | 69.7 | 73.4 |
| SeFAR | 66.3 | 69.5 | 72.2 | 74.6 | 78.4 |
| Increase (%) | 7.8%↑ | 7.6%↑ | 7.4%↑ | 7.0%↑ | 6.8%↑ |
| 2.5 |
🔼 This table presents an ablation study on the impact of different pre-trained visual encoders on the performance of a multimodal large language model (MLLM) for fine-grained action recognition. The base MLLM used is Vicuna-7B. The experiment compares the performance when using SeFAR’s extracted visual features against features from several commonly used pre-trained visual encoders in MLLMs (LLaVA, VideoChat2, VideoLLaMA, VideoChat, and VideoLLaVA). These visual encoders were further fine-tuned on 5% of the data. The results are evaluated on two fine-grained action recognition tasks, Gym-QA-99 and Gym-QA-288.
read the caption
Table 5: Ablation of Pre-trained Visual Encoder. We employ Vicuna-7B (Chiang et al. 2023) as the base LLM, comparing SeFAR’s features with the pre-trained features of commonly used visual encoders in MLLMs further fine-tuned on 5% data (i.e., : LLaVA, : VideoChat2, : VideoLLaMA, : VideoChat, and : VideoLLaVA)
| 2.5 Perturbation | Speed/Order | FX | 10m | UB-S1 | 5253B |
|---|---|---|---|---|---|
| 2 Slow-rate | Speed | 22.4 | 81.2 | 35.6 | 92.8 |
| T-Drop | Speed | 22.4 | 81.2 | 35.6 | 92.8 |
| All shuffle | Order | 23.5 | 82.8 | 36.1 | 93.5 |
| Local-shuffle | Order | 23.0 | 84.1 | 36.5 | 94.9 |
| Warping | Order | 23.4 | 81.9 | 34.7 | 92.9 |
| T-Half | Order | 23.3 | 83.0 | 35.3 | 93.4 |
| All reverse | Order | 23.6 | 83.7 | 35.5 | 95.1 |
| Mod-Perturb | Order | 23.8 | 85.5 | 36.6 | 96.4 |
| 2.5 |
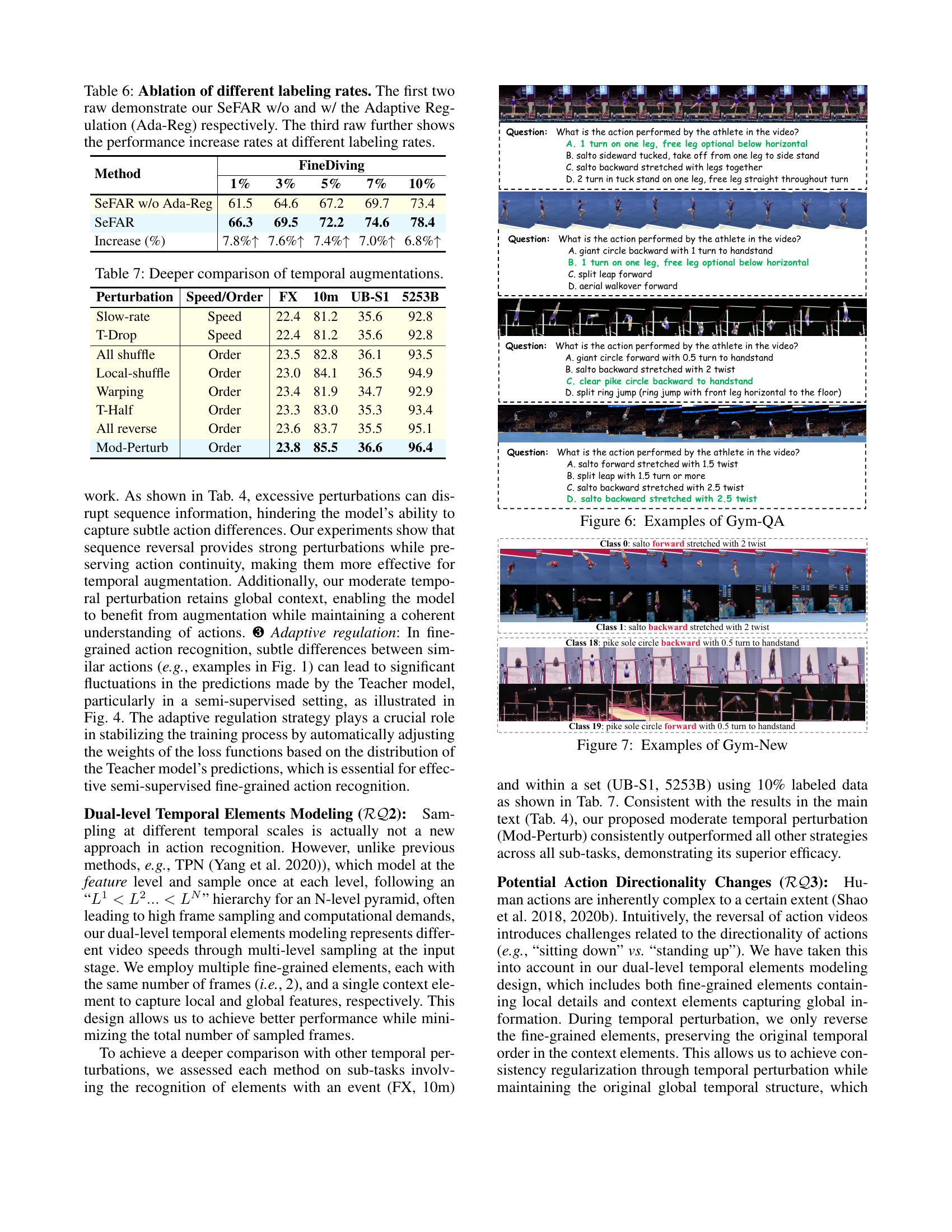
🔼 This table presents an ablation study on the effect of different data labeling rates on the performance of the SeFAR model. It shows the model’s performance with and without the Adaptive Regulation module at various labeling rates (1%, 3%, 5%, 7%, and 10%). The last row quantifies the performance improvement achieved by including the Adaptive Regulation module at each labeling rate.
read the caption
Table 6: Ablation of different labeling rates. The first two raw demonstrate our SeFAR w/o and w/ the Adaptive Regulation (Ada-Reg) respectively. The third raw further shows the performance increase rates at different labeling rates.
| Prediction Times | 1 | 2 | 5 | 10 | 15 | 20 |
|---|---|---|---|---|---|---|
| 2.5 Teacher time / Iter. | 29.9 | 68.5 | 75.8 | 160.4 | 260.1 | 361.3 |
| Total time / Iter. | 982.8 | 991.6 | 1005.1 | 1080.7 | 1220.6 | 1417.6 |
| Portion (%) | 3.0 | 6.9 | 7.5 | 14.8 | 21.3 | 25.5 |
| Accuracy (%) | - | 35.3 | 36.2 | 36.7 | 36.8 | 37.0 |
🔼 This table presents a deeper comparison of different temporal augmentation techniques used in the SeFAR model. It compares the performance of various augmentation strategies (‘Slow-rate’, ‘T-Drop’, ‘All shuffle’, ‘Local-shuffle’, ‘Warping’, ‘T-Half’, ‘All reverse’, ‘Mod-Perturb’) across three different subsets of the FineGym dataset (FX, 10m, UB-S1, 5253B). The table shows the Top-1 accuracy achieved by each augmentation method on each subset, categorized by whether speed or order was affected. This allows for analysis of the impact of different augmentation types on the model’s ability to correctly identify actions.
read the caption
Table 7: Deeper comparison of temporal augmentations.
Full paper#