TL;DR#
Existing video restoration methods struggle with high-resolution, long videos due to computational constraints of self-attention mechanisms. Patch-based approaches are slow, and attention designs lead to performance degradation when dealing with resolutions different from those used during training. Diffusion-based models show promise but also face limitations in generation and sampling efficiency.
SeedVR solves these issues with a novel diffusion transformer architecture using shifted window attention. This design enables efficient processing of arbitrary-length and resolution videos. The casual video autoencoder further improves training and inference efficiency. Extensive experiments demonstrate SeedVR’s superior performance and speed across various benchmarks, making it a strong baseline for future VR research.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing video restoration methods by proposing SeedVR, a novel diffusion transformer that efficiently handles videos of arbitrary length and resolution. SeedVR’s superior performance on various benchmarks, especially in real-world scenarios, makes it a significant advancement in the field. This work also opens new avenues for large-scale training of diffusion models for video processing and inspires future research in efficient attention mechanisms for high-resolution video tasks.
Visual Insights#

🔼 Figure 1 presents a comparative analysis of SeedVR’s speed and performance against other state-of-the-art video restoration methods. SeedVR achieves superior visual quality, exhibiting finer details and enhanced realism. Notably, despite having significantly more parameters (2.48B) than most competitors, SeedVR operates over twice as fast. Furthermore, it demonstrates comparable efficiency to the Stable Diffusion Upscaler, even with a fivefold increase in model size. This highlights SeedVR’s efficiency and superior restoration capabilities.
read the caption
Figure 1: Speed and performance comparisons. SeedVR demonstrates impressive restoration capabilities, offering fine details and enhanced visual realism. Despite its 2.48B parameters, SeedVR is over 2×2\times2 × faster than existing diffusion-based video restoration approaches [80, 64, 20]. With delicate designs, SeedVR is as efficient as the Stable Diffusion Upscaler [2], even with five times the parameter count. (Zoom-in for best view)
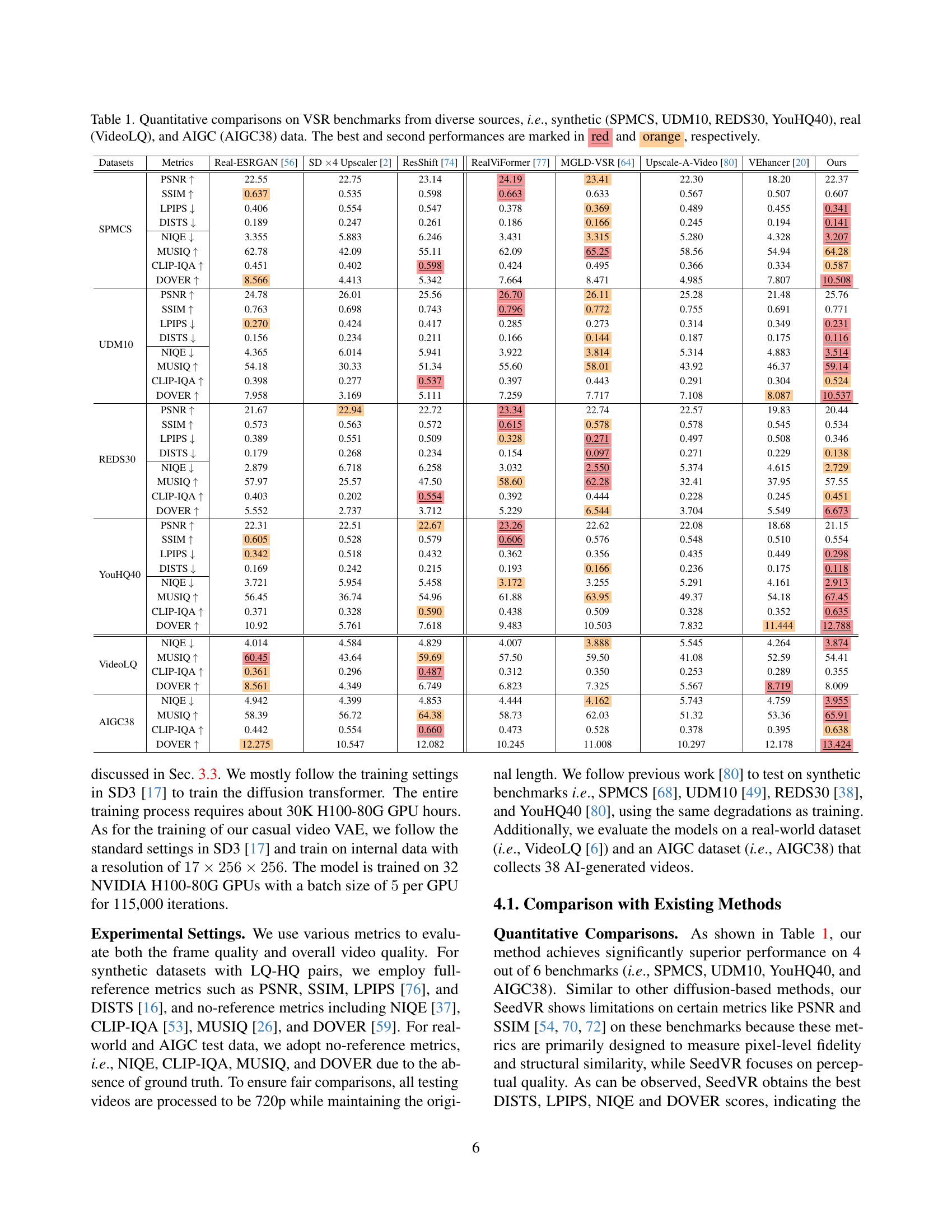
🔼 Table 1 presents a quantitative comparison of various Video Super-Resolution (VSR) methods across six benchmark datasets. These datasets encompass diverse sources and types of video degradation: synthetic data (SPMCS, UDM10, REDS30, and YouHQ40), real-world data (VideoLQ), and AI-generated content (AIGC38). The table evaluates the performance of each method using several metrics, including Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and others. The best and second-best results for each metric and dataset are highlighted in red and orange, respectively, providing a clear visual representation of comparative performance across different VSR approaches and video degradation types.
read the caption
Table 1: Quantitative comparisons on VSR benchmarks from diverse sources, i.e., synthetic (SPMCS, UDM10, REDS30, YouHQ40), real (VideoLQ), and AIGC (AIGC38) data. The best and second performances are marked in red and orange, respectively.
In-depth insights#
SeedVR: Background#
SeedVR’s background likely involves a discussion of existing video restoration techniques and their limitations. It would likely cover traditional methods like CNN-based approaches and their struggles with long-range dependencies, especially in high-resolution videos. The limitations of patch-based methods, their computational costs, and the artifacts they produce, would also be discussed. Diffusion models, while promising for image restoration, also present challenges in video restoration. SeedVR’s background would highlight the significant computational expense and resolution constraints of existing diffusion-based video restoration approaches due to full-attention mechanisms. It would also contextualize the choice of a diffusion transformer architecture, potentially emphasizing its ability to handle longer sequences and higher resolutions compared to earlier methods. The section might also briefly touch upon the use of attention mechanisms in existing models, the limitations of smaller window sizes, and the necessity for a design that can efficiently process arbitrarily sized videos and maintain high quality. Finally, the prior art related to causal video autoencoders and progressive training techniques could be discussed, setting the stage for SeedVR’s innovative approach.
Swin-MMDiT: Design#
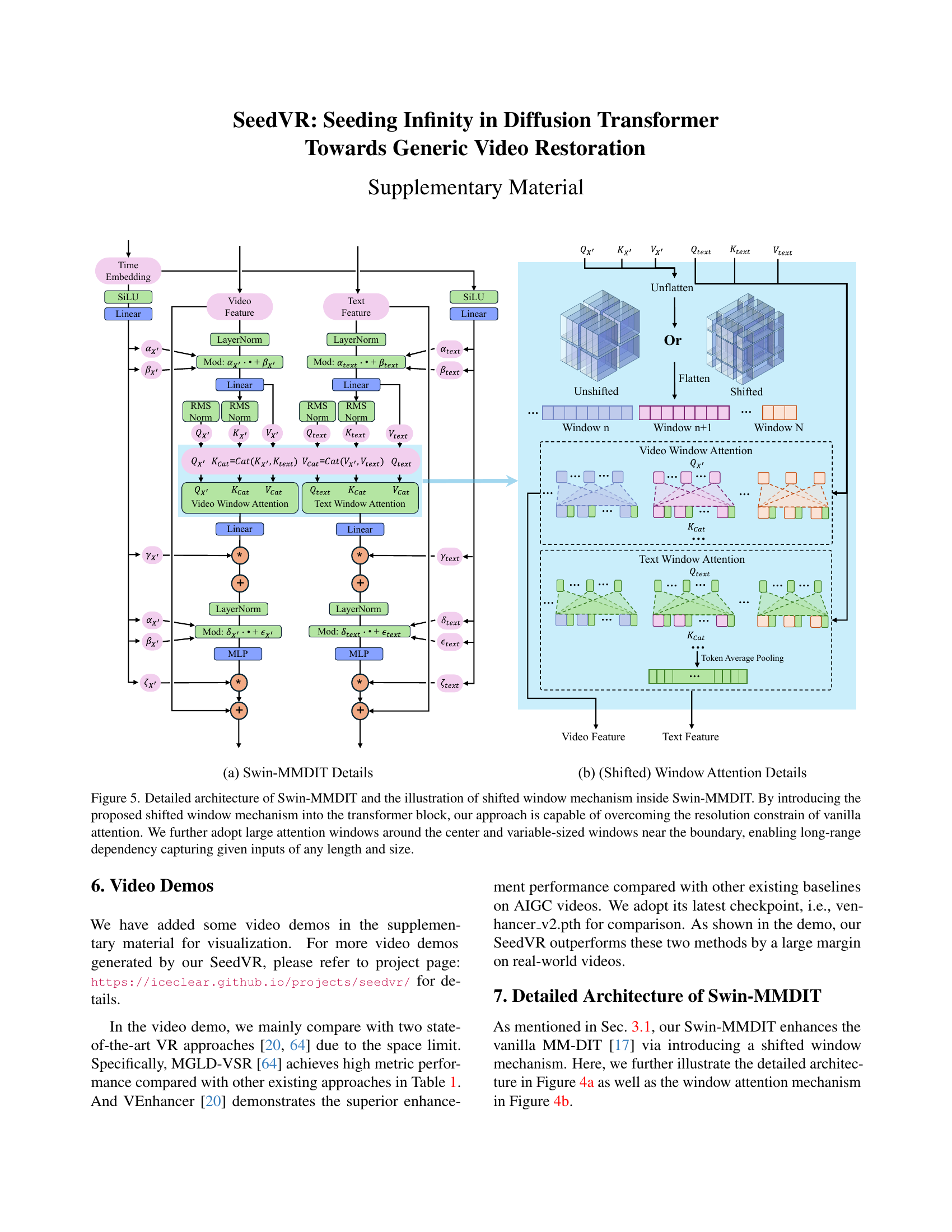
The Swin-MMDiT design is a crucial innovation in SeedVR, addressing the limitations of traditional full-attention mechanisms in diffusion transformers for video restoration. It replaces full self-attention with a more computationally efficient window-based attention, specifically using Swin Transformer’s shifted window approach. This allows SeedVR to handle arbitrarily sized videos without the quadratic complexity associated with full attention. A key enhancement is the use of significantly larger attention windows (64x64) in a compressed latent space, enabling the model to capture long-range dependencies within the video sequences. To address uneven window sizes near boundaries, a 3D rotary position embedding is employed, maintaining consistent attention across various input resolutions. By combining these techniques, Swin-MMDiT offers a scalable and efficient architecture well-suited for high-resolution video restoration tasks, overcoming the major challenges in existing methods.
Casual VAE: Impact#
The conceptual heading ‘Casual VAE: Impact’ invites exploration of a causal variational autoencoder’s effects within a video restoration framework. A causal VAE, by incorporating temporal dependencies in its encoding, likely results in more efficient video compression compared to standard autoencoders. This efficiency translates to faster training times and lower computational costs during video restoration. Moreover, a causal approach may lead to improved reconstruction quality, as temporal information is preserved, enhancing the consistency and coherence of the restored video. The impact likely extends beyond computational advantages. By better capturing temporal relationships, the causal VAE could facilitate more effective temporal alignment and artifact removal, particularly beneficial in handling real-world videos with varied degradation types. In essence, a causal VAE’s impact is multifaceted, affecting training efficiency, reconstruction quality, and the overall performance of the video restoration system. Its effectiveness depends critically on its architectural design and training data, demanding further investigation into its strengths and weaknesses.
Large-Scale Training#
The section on ‘Large-Scale Training’ highlights the challenges and strategies employed to train a robust video restoration model. The authors acknowledge the difficulty of training on massive, high-resolution video datasets, a problem often limiting the generalization capabilities of existing models. Their approach involves a mixed dataset of images and videos, leveraging the model’s flexibility to learn from diverse data sources. To enhance efficiency, they implement pre-computation of latents and text embeddings, significantly accelerating training times. A crucial aspect is the progressive growing of resolution and duration, starting with low-resolution, short videos and gradually increasing complexity. This technique is combined with the injection of noise to the condition, aiming to bridge the gap between synthetic and real-world degradation patterns. These multifaceted strategies showcase a commitment to large-scale training methodologies, ultimately contributing to SeedVR’s superior performance and generalization on various benchmarks.
Future of SeedVR#
The future of SeedVR looks promising, building upon its strengths in handling arbitrary video resolutions and lengths. Further research could focus on improving sampling efficiency, potentially through advancements in diffusion model architectures or optimization techniques. Scaling SeedVR to even larger datasets and higher resolutions would further enhance its capabilities for generating realistic and high-quality video restorations. Exploring different types of video degradation and developing more robust training strategies would broaden its applicability to real-world scenarios. Integration with other AI models, such as those focused on video editing or generation, could unlock new creative applications. Finally, addressing the computational cost, particularly for very high-resolution or long videos, will be crucial for widespread adoption. Improving the model’s understanding of temporal dependencies and enhancing its ability to maintain fine details over extended sequences are key areas for continued development.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture of SeedVR, focusing on its Swin-MMDiT block. This block improves upon traditional transformer blocks by incorporating a shifted window attention mechanism. This addresses the limitations of standard attention mechanisms, which struggle with high-resolution videos and varying input lengths. The shifted window approach uses large windows in the center of the input for long-range dependencies and smaller, variable-sized windows at the edges to handle boundaries effectively. This design allows SeedVR to efficiently process videos of any length and resolution, a key advantage over previous methods.
read the caption
Figure 2: Model architecture and the details of Swin-MMDIT of SeedVR. Our approach introduces a shifted window mechanism into the transformer block, bypassing the resolution constrain of vanilla attention. We further adopt large attention windows around the center and variable-sized windows near the boundary, enabling long-range dependency capturing given inputs of any length and size.

🔼 Figure 3 illustrates the architecture of the causal video variational autoencoder (CVVAE) employed in SeedVR. Unlike approaches that simply adapt image autoencoders for video, SeedVR’s CVVAE is specifically designed for video processing. It incorporates spatial and temporal compression to efficiently handle long videos, improving both training speed and the quality of the video reconstruction.
read the caption
Figure 3: The model architecture of casual video autoencoder. In contrast to naively inflating an existing image autoenoder, we redesign a casual video VAE with spatial-temporal compression capability to achieve a strong reconstruction capability.
More on tables
| Methods | Params (M) | Temporal Compression | Spatial Compression | Latent Channel | PSNR ↑ | SSIM ↑ | LPIPS ↓ | rFVD ↓ |
|---|---|---|---|---|---|---|---|---|
| SD 2.1 [45] | 83.7 | - | 8 | 4 | 29.50 | 0.9050 | 0.0998 | 8.14 |
| VEnhancer [20] | 97.7 | - | 8 | 4 | 30.81 | 0.9356 | 0.0751 | 11.10 |
| Cosmos [44] | 90.2 | 4 | 8 | 16 | 32.34 | 0.9484 | 0.0847 | 13.02 |
| OpenSora [79] | 393.3 | 4 | 8 | 4 | 27.70 | 0.8893 | 0.1661 | 47.04 |
| OpenSoraPlan v1.3 [28] | 147.3 | 4 | 8 | 16 | 30.41 | 0.9280 | 0.0976 | 27.70 |
| CogVideoX [66] | 215.6 | 4 | 8 | 16 | 34.30 | 0.9650 | 0.0623 | 6.06 |
| Ours | 250.6 | 4 | 8 | 16 | 33.83 | 0.9643 | 0.0517 | 1.85 |
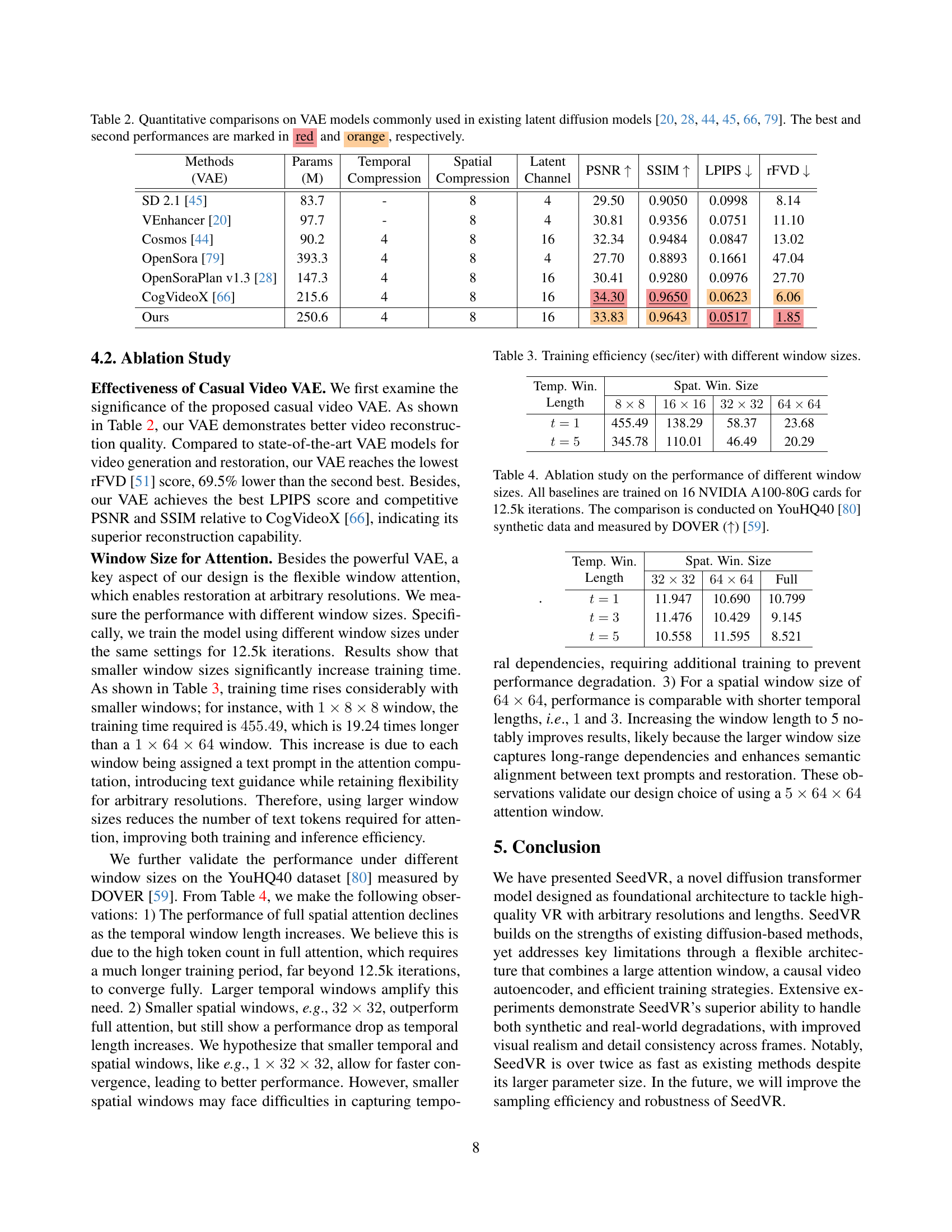
🔼 This table presents a quantitative comparison of various Variational Autoencoder (VAE) models frequently used in existing latent diffusion models. The comparison focuses on key metrics such as PSNR, SSIM, LPIPS, and rFVD, providing a detailed performance evaluation across different VAEs. The best and second-best results for each metric are highlighted in red and orange, respectively, for easy identification.
read the caption
Table 2: Quantitative comparisons on VAE models commonly used in existing latent diffusion models [45, 20, 44, 79, 28, 66]. The best and second performances are marked in red and orange, respectively.
| Temp. Win. | Spat. Win. Size | Spat. Win. Size | Spat. Win. Size | Spat. Win. Size | Length |
|---|---|---|---|---|---|
| 8 × 8 | 16 × 16 | 32 × 32 | 64 × 64 | 455.49 | t = 1 |
| 138.29 | |||||
| 58.37 | |||||
| 23.68 | |||||
| 8 × 8 | 16 × 16 | 32 × 32 | 64 × 64 | 345.78 | t = 5 |
| 110.01 | |||||
| 46.49 | |||||
| 20.29 |
🔼 This table presents the training time, measured in seconds per iteration, for the SeedVR model with various window sizes. Different window sizes in spatial and temporal dimensions were used during training. The results demonstrate a significant increase in training time as the window sizes decrease, highlighting the efficiency of using larger windows for training.
read the caption
Table 3: Training efficiency (sec/iter) with different window sizes.
Full paper#