TL;DR#
Latent diffusion models excel at generating high-fidelity images but face an optimization challenge. Increasing the feature dimension in visual tokenizers improves reconstruction but significantly degrades generation performance, requiring larger models and more training. Existing solutions either compromise reconstruction quality or necessitate extensive computational resources. This presents a trade-off between visual detail and generation quality.
This paper introduces VA-VAE, which aligns the latent space with pre-trained vision foundation models during training. This approach resolves the optimization dilemma by effectively structuring the latent space, thereby enhancing generation performance in high-dimensional tokenizers. By integrating VA-VAE with an improved DiT baseline (LightningDiT), the authors achieve state-of-the-art performance on ImageNet 256x256 generation with a remarkable 21x speedup in convergence.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on latent diffusion models because it directly addresses a significant limitation, the optimization dilemma between reconstruction and generation quality. The proposed VA-VAE method offers a practical solution that enhances training efficiency and model performance, opening new avenues for improving high-resolution image generation and accelerating convergence in diffusion models. It provides a new baseline (LightningDiT) and a new understanding of the optimization problem that is relevant to the broader field of AI.
Visual Insights#

🔼 This figure illustrates the optimization dilemma in latent diffusion models. As the dimensionality (’d’) of the visual tokenizer increases (while maintaining a fixed downsampling rate ‘f’), the reconstruction quality improves (lower rFID values), as shown by the decreasing rFID values from left to right. However, this improvement in reconstruction comes at the cost of significantly reduced generation quality, indicated by the increasing gFID values. This trade-off is clearly demonstrated across three different tokenizer specifications, all evaluated under a fixed computational budget on the ImageNet 256x256 dataset. This highlights the challenge of balancing reconstruction and generation performance when designing latent diffusion models.
read the caption
Figure 1: Optimization dilemma within latent diffusion models. In latent diffusion models, increasing the dimension of the visual tokenizer enhances detail reconstruction but significantly reduces generation quality. (In tokenizer specification, “f” and “d” represent the downsampling rate and dimension, respectively. All results are evaluated on ImageNet 256×\times×256 dataset with a fixed compute budget during diffusion model training.)
| Training Trick | Training Sample | Epoch | FID-50k ↓ |
|---|---|---|---|
| DiT-XL/2 [29] | 400k × 256 | 80 | 19.50 |
| Training Strategies | |||
| + Rectified Flow [23] | 400k × 256 | 80 | 17.20 |
| + batchsize × 4 & lr × 2 | 100k × 1024 | 80 | 16.59 |
| + AdamW β₂=0.95 [1] | 100k × 1024 | 80 | 16.61 |
| + Logit Normal Sampling [7] | 100k × 1024 | 80 | 13.99 |
| + Velocity Direction Loss [41] | 100k × 1024 | 80 | 12.52 |
| Architecture Improvements | |||
| + SwiGLU FFN [34] | 100k × 1024 | 80 | 10.10 |
| + RMS Norm [44] | 100k × 1024 | 80 | 9.25 |
| + Rotary Pos Embed [35] | 100k × 1024 | 80 | 7.13 |
| + patch size=1 & VA-VAE (Sec. 3) | 100k × 1024 | 80 | 4.29 |
🔼 This table presents the performance improvements achieved by LightningDiT, an enhanced version of Diffusion Transformers (DiT). Using the SD-VAE (Stable Diffusion Variational Autoencoder) tokenizer, LightningDiT achieves a Fréchet Inception Distance (FID) score of 7.13 on the ImageNet dataset for class-conditional image generation. This represents a significant improvement, as it uses 94% fewer training samples compared to the original DiT model. The table further highlights that the exceptional performance of the original DiT model can be replicated by incorporating advanced architectural and training strategies, as demonstrated by the results within the table.
read the caption
Table 1: Performance of LightningDiT. With SD-VAE [33], LightningDiT achieves FID-50k=7.13 on ImageNet class-conditional generation, using 94% fewer training samples compared to the original DiT [29]. We show that the original DiT can also achieve exceptional performance by leveraging advanced design techniques.
In-depth insights#
Latent Space Alignment#
Latent space alignment, in the context of generative models, is a crucial technique for improving the quality and efficiency of image generation. It focuses on aligning the latent space of a variational autoencoder (VAE) or tokenizer with a pre-trained vision foundation model. This alignment ensures that the latent representations learned by the VAE are meaningful and consistent with the knowledge encoded in the foundation model. The benefits are two-fold: Firstly, it solves the optimization dilemma often encountered in high-dimensional latent spaces, where increasing the dimensionality improves reconstruction quality but negatively impacts generation. By aligning the latent space, the model can leverage the pre-trained model’s established feature representations to better guide the generation process. Secondly, the alignment leads to faster convergence during training, since the model starts with a more informative representation, requiring fewer iterations to achieve comparable performance. In essence, latent space alignment acts as a regularization technique, guiding the learning process and preventing the latent space from drifting into regions that are not useful for generation.
VF Loss Mechanism#
The Vision Foundation model alignment Loss (VF Loss) is a crucial component of the VA-VAE framework, designed to address the optimization dilemma in latent diffusion models. VF Loss cleverly guides the learning process of high-dimensional visual tokenizers by aligning their latent representations with those of pre-trained vision foundation models. This alignment isn’t a simple initialization; it’s a continuous process during training. The loss function comprises two key components: marginal cosine similarity loss and marginal distance matrix similarity loss. The cosine similarity component directly aligns corresponding features between the tokenizer’s output and the foundation model’s output, while the distance matrix component ensures alignment between the overall distribution of features. A margin mechanism is incorporated to prevent over-regularization, ensuring flexibility while maintaining alignment. The adaptive weighting strategy dynamically balances the VF loss with the standard reconstruction and KL losses, ensuring stable training. By leveraging the knowledge encoded in pre-trained models, the VF loss effectively structures the high-dimensional latent space, improving training convergence and enabling enhanced generative performance without requiring significant increases in model size or training time. This addresses the core issue of learning effectively within these spaces, promoting balance between reconstruction accuracy and generation quality.
DiT Optimization#
The optimization of Diffusion Transformers (DiTs) presents a significant challenge, particularly concerning the balance between reconstruction and generation capabilities. Increasing the dimensionality of visual tokens improves reconstruction quality but severely hinders generation performance, creating an optimization dilemma. Existing solutions either involve computationally expensive scaling of model parameters or compromise reconstruction accuracy to achieve faster convergence. This paper introduces Vision foundation model Aligned Variational AutoEncoder (VA-VAE), which aligns the latent space of the visual tokenizer with pretrained vision models. This alignment regularizes the high-dimensional latent space, promoting efficient learning and mitigating the inherent trade-off between reconstruction and generation. The integration of VA-VAE with improved training strategies and architectural designs in a system called LightningDiT demonstrates state-of-the-art performance on ImageNet 256x256 generation and significantly faster convergence speed compared to the original DiT. The core contribution lies in effectively resolving the optimization dilemma, enabling high-quality image generation without the need for excessively large models or extensive training.
High-Dim Tokenizers#
The concept of “High-Dim Tokenizers” in the context of latent diffusion models is crucial for achieving high-fidelity image generation. Increasing the dimensionality of visual tokens within the tokenizer improves the model’s ability to capture fine-grained details during reconstruction. However, this improvement comes at a cost: higher-dimensional spaces necessitate larger, more complex diffusion models and require significantly more training iterations to achieve comparable generative performance. This creates an optimization dilemma; prioritizing reconstruction quality leads to suboptimal generation, and vice versa. The core challenge lies in the difficulty of learning effectively within these unconstrained, high-dimensional latent spaces. The paper addresses this dilemma through alignment with pre-trained vision foundation models, providing a principled approach to guide the learning process and effectively expand the reconstruction-generation frontier without the need for excessive computational resources.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the VA-VAE framework is crucial, potentially through more sophisticated alignment techniques or by investigating alternative vision foundation models. A deeper investigation into the interplay between the tokenizer and the diffusion model is warranted, aiming to create a more synergistic relationship for enhanced performance. Exploring different loss functions and training strategies could further optimize the convergence speed and the quality of generated images. Finally, extending the methodology to video generation and other high-dimensional data modalities would represent a significant advancement. The potential for wider applications across various computer vision tasks, leveraging the enhanced reconstruction-generation capabilities of the proposed approach, should also be actively investigated. These directions collectively aim to improve both the efficiency and the performance of latent diffusion models, making them more practical and versatile for diverse real-world applications.
More visual insights#
More on figures
🔼 This figure illustrates the trade-off between reconstruction and generation capabilities in latent diffusion models, a key challenge in model design. The x-axis represents reconstruction quality (measured by rFID, with lower values indicating better reconstruction), and the y-axis represents generation quality (measured by gFID, with lower values representing better generation). The plot shows that increasing the dimensionality of the visual tokenizer improves reconstruction but significantly harms generation. The introduction of VA-VAE (Vision foundation model Aligned Variational AutoEncoder), however, shifts this trade-off, expanding the range of achievable performance. By aligning latent spaces with pre-trained vision foundation models, VA-VAE enhances the quality of high-dimensional latent representations, improving generation without sacrificing reconstruction capabilities.
read the caption
Figure 2: Reconstruction-generation frontier of latent diffusion models. VA-VAE improves the feature distribution of high-dimensional latent. Through alignment with vision foundation models, we expand the frontier between reconstruction and generation in latent diffusion models.
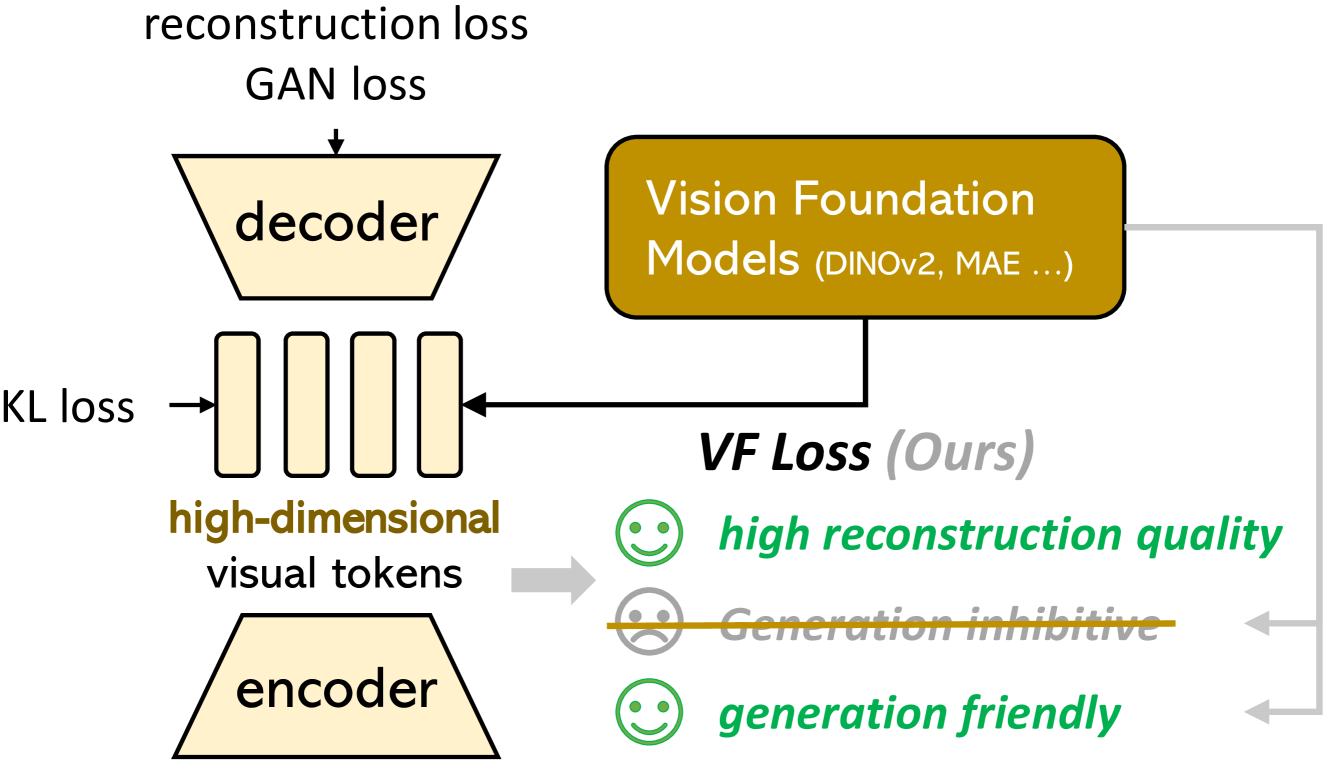
🔼 This figure illustrates the architecture of the Vision Foundation model Aligned Variational Autoencoder (VA-VAE). The VA-VAE addresses the optimization dilemma in latent diffusion models by incorporating pre-trained vision foundation models into the training process of the high-dimensional visual tokenizer. The vision foundation model guides the learning of the latent representations, enabling the tokenizer to achieve superior reconstruction quality without sacrificing generation performance. The figure shows how the encoder of the VA-VAE receives input, processes it through the vision foundation model, and incorporates this information into the learning process, resulting in better aligned high-dimensional visual tokens.
read the caption
Figure 3: The proposed Vision foundation model Aligned VAE (VA-VAE). Vision foundation models are used to guide the training of high-dimensional visual tokenizers, effectively mitigating the optimization dilemma and improve generation performance.
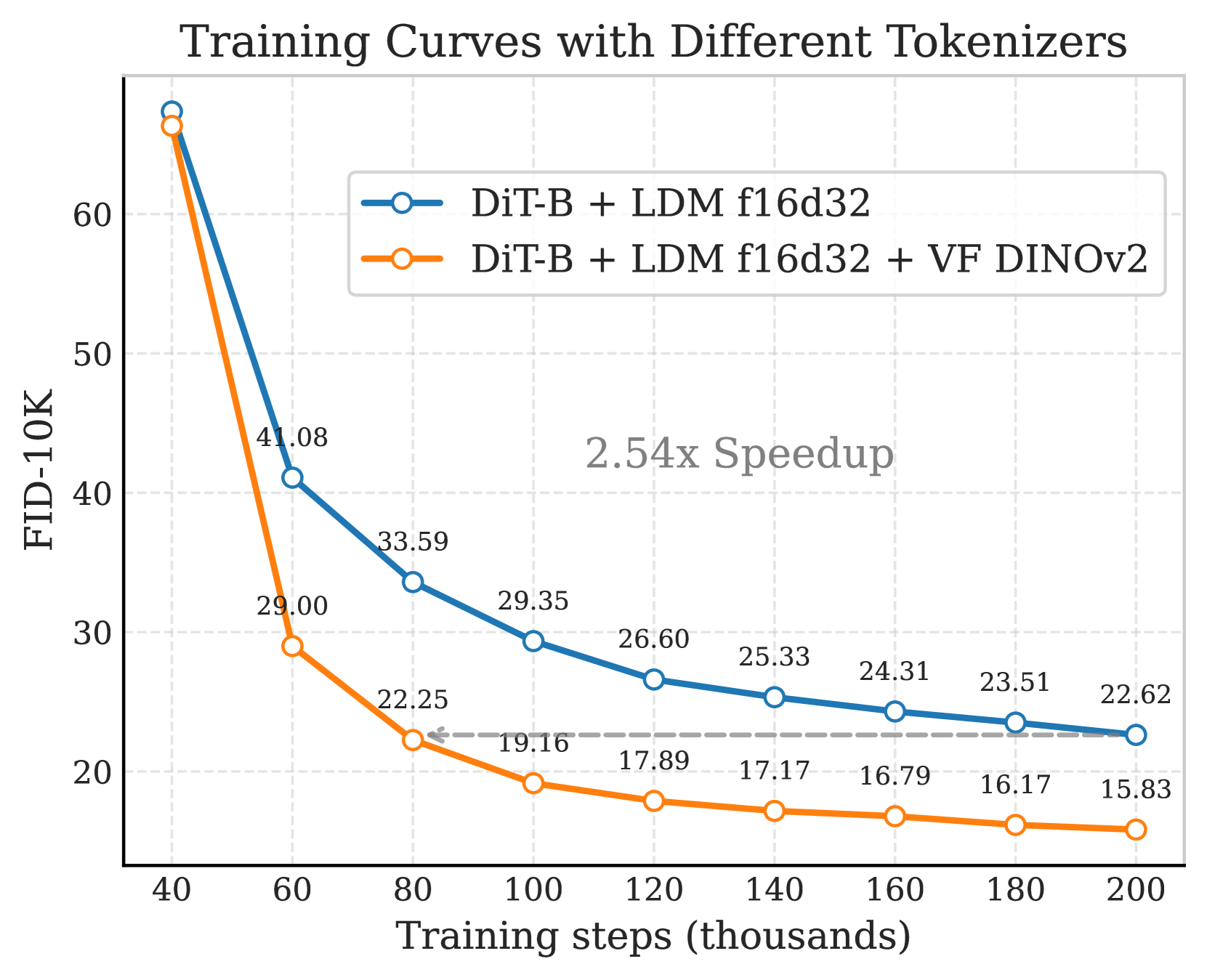
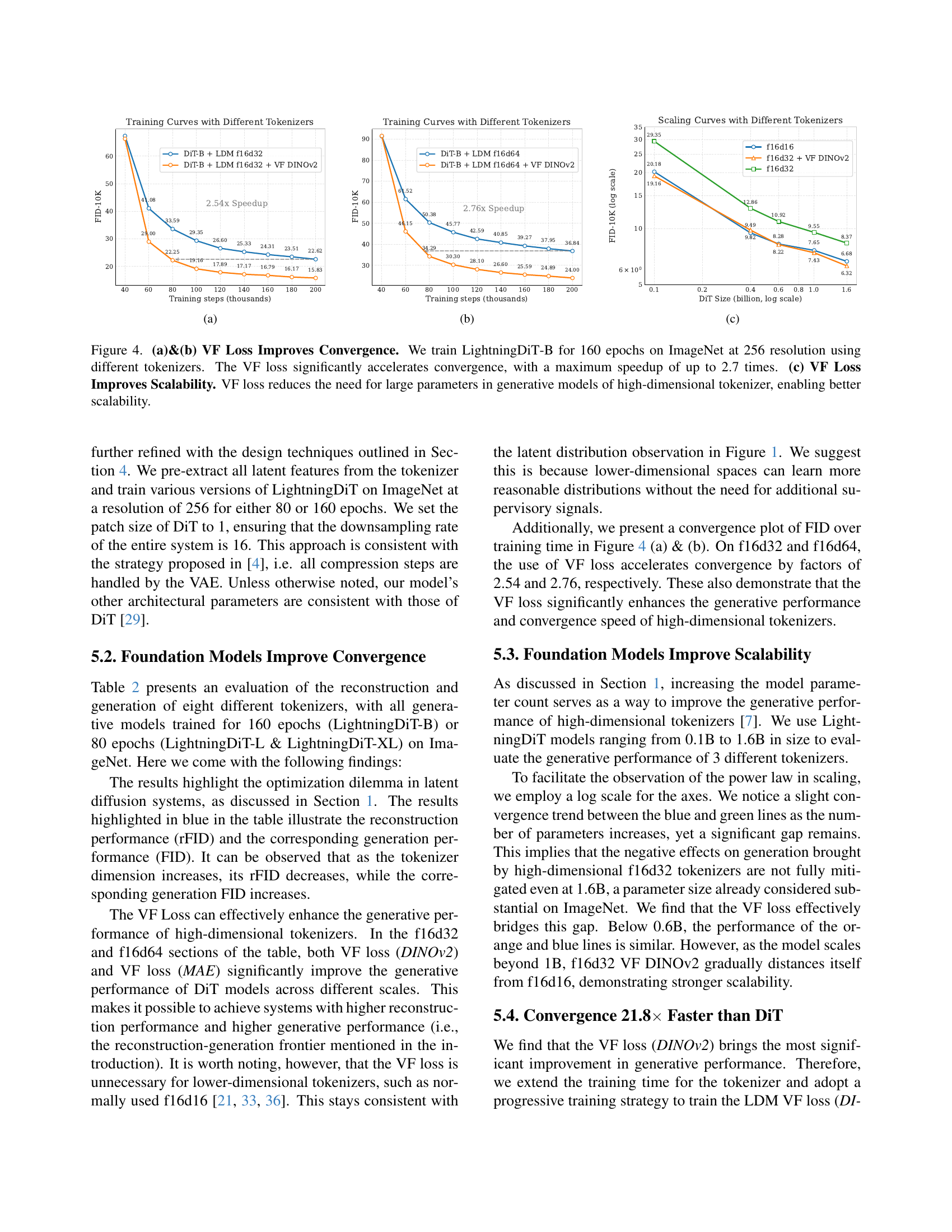
🔼 The figure shows training curves for FID scores of different models with varying tokenizer specifications. The curves demonstrate that using Vision Foundation Model (VFM) alignment significantly improves convergence speed, reducing the number of training steps needed to reach a comparable FID score. Models without VFM alignment (baseline) show slower convergence, particularly with higher-dimensional tokenizers (f16d64). In contrast, those with VFM alignment converge much faster. This highlights that aligning latent space with pretrained vision foundation models improves the efficiency of training high-dimensional latent diffusion models.
read the caption
(a)

🔼 This figure shows the training curves of FID (Fréchet Inception Distance) scores for various models, demonstrating the impact of the proposed Vision Foundation model Aligned Variational AutoEncoder (VA-VAE). The models were trained using different tokenizers (f16d32 and f16d64), both with and without VA-VAE. The plot shows the training curves for FID score on the y-axis and the number of training steps on the x-axis. The curves demonstrate a significant reduction in FID score with VA-VAE, indicating faster convergence speed during training and improved performance.
read the caption
(b)

🔼 This figure shows how the FID score changes with the increase of the model size (number of parameters) for three different tokenizers: f16d16, f16d32 (with and without VF DINOv2 loss), and f16d64 (with and without VF DINOv2 loss). The x-axis is the model size on a logarithmic scale, representing the increasing model capacity. The y-axis is the FID score (a lower score is better), indicating the image generation quality. The plot demonstrates how VF DINOv2 loss significantly improves the scalability of high-dimensional tokenizers (f16d32 and f16d64), enabling better performance even with smaller models. The f16d16 tokenizer shows relatively stable performance regardless of model size, indicating that VF loss is not needed for lower dimensions.
read the caption
(c)

🔼 Figure 4 demonstrates the impact of the Vision Foundation model alignment Loss (VF Loss) on the training convergence and scalability of the LightningDiT model. Subfigures (a) and (b) compare training curves (FID score over training steps) for LightningDiT-B trained with different tokenizers (f16d32 and f16d64) both with and without VF Loss. The results show that VF Loss significantly accelerates the convergence speed, achieving up to a 2.7x speedup. Subfigure (c) illustrates the impact of VF Loss on scalability by showing FID scores for models of varying sizes (parameter counts) using different tokenizers. This graph shows VF Loss reduces the need for extremely large models to achieve good performance with higher-dimensional tokenizers.
read the caption
Figure 4: (a)&(b) VF Loss Improves Convergence. We train LightningDiT-B for 160 epochs on ImageNet at 256 resolution using different tokenizers. The VF loss significantly accelerates convergence, with a maximum speedup of up to 2.7 times. (c) VF Loss Improves Scalability. VF loss reduces the need for large parameters in generative models of high-dimensional tokenizer, enabling better scalability.

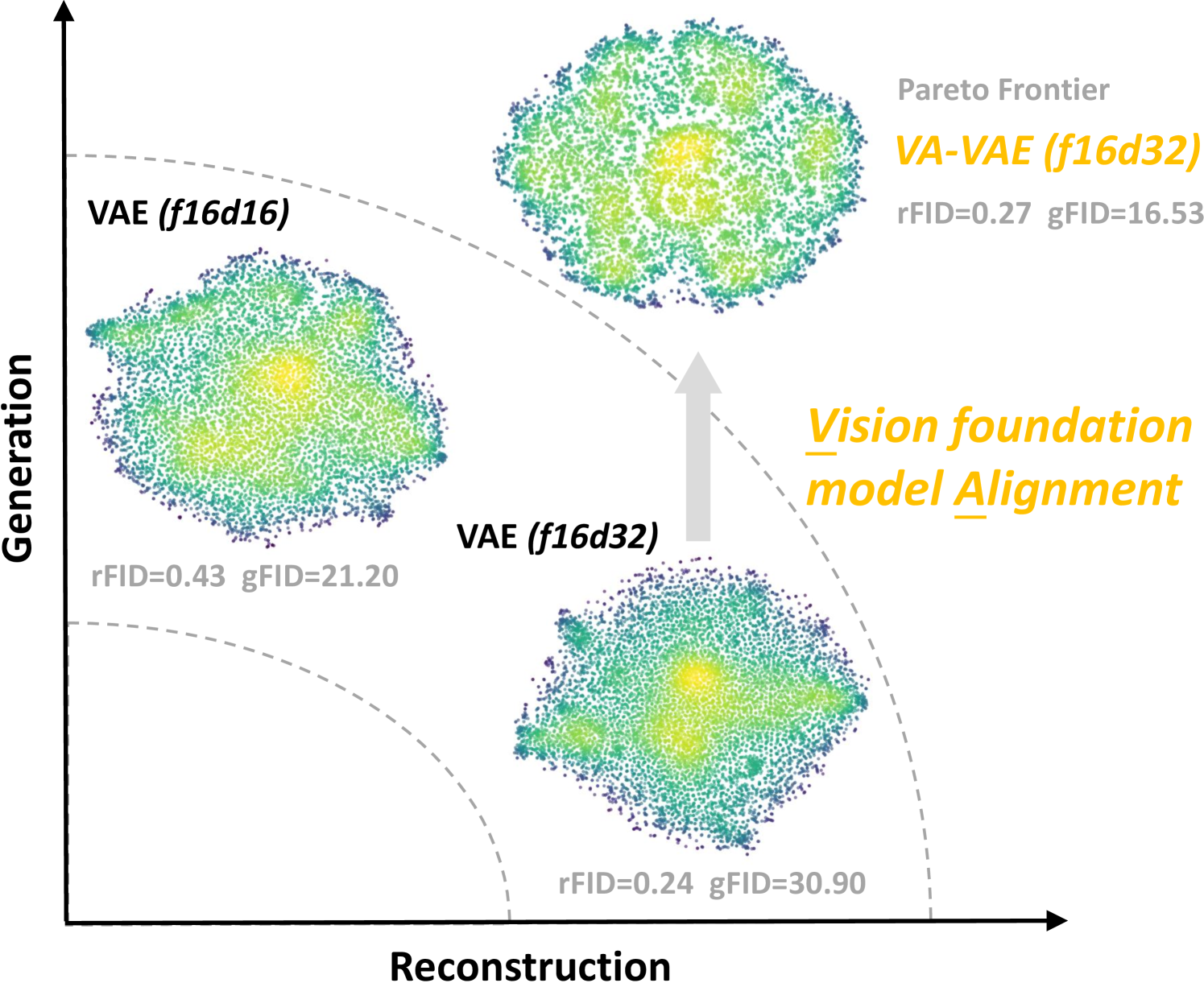
🔼 This figure showcases sample images generated by the proposed latent diffusion model, LightningDiT-XL, utilizing the Vision foundation model Aligned Variational AutoEncoder (VA-VAE). The model was trained on the ImageNet dataset at a 256x256 resolution. The images demonstrate the model’s ability to generate high-fidelity and diverse images across various categories. The figure visually represents the quality and variety achievable with the improved system.
read the caption
Figure 5: Visualization Results. We visualize our latent diffusion system with proposed VA-VAE together with LightningDiT-XL trained on ImageNet 256×256256256256\times 256256 × 256 resolution.
More on tables
| Tokenizer | Spec. | Reconstruction Performance | Generation Performance (FID-10K)↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Tokenizer | Spec. | rFID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | LightningDiT-B | LightningDiT-L | LightningDiT-XL | |
| LDM [33] | 0.49 | 26.10 | 0.132 | 0.72 | 16.24 | 9.49 | 8.28 | ||
| LDM+VF loss (MAE) [15] | 0.51 | 26.01 | 0.137 | 0.71 | 16.86 (+0.62) | 10.93 (+1.44) | 9.19 (+0.91) | ||
| LDM+VF loss (DINOv2) [28] | 0.55 | 25.29 | 0.147 | 0.69 | 15.79 (-0.45) | 10.02 (+0.53) | 8.71 (+0.43) | ||
| LDM [33] | 0.26 | 28.59 | 0.089 | 0.80 | 22.62 | 12.86 | 10.92 | ||
| LDM+VF loss (MAE) [15] | 0.28 | 28.33 | 0.091 | 0.80 | 19.89 (-2.73) | 11.51 (-1.35) | 9.92 (-1.00) | ||
| LDM+VF loss (DINOv2) [28] | 0.28 | 27.96 | 0.096 | 0.79 | 15.82 (-6.80) | 9.82 (-3.04) | 8.22 (-2.70) | ||
| LDM [33] | 0.17 | 31.03 | 0.055 | 0.88 | 36.83 | 20.73 | 17.24 | ||
| LDM+VF loss (MAE) [15] | 0.15 | 31.03 | 0.054 | 0.87 | 23.58 (-13.25) | 14.40 (-6.33) | 11.69 (-5.55) | ||
| LDM+VF loss (DINOv2) [28] | 0.14 | 30.71 | 0.055 | 0.87 | 24.00 (-12.83) | 14.95 (-5.78) | 11.98 (-5.26) |
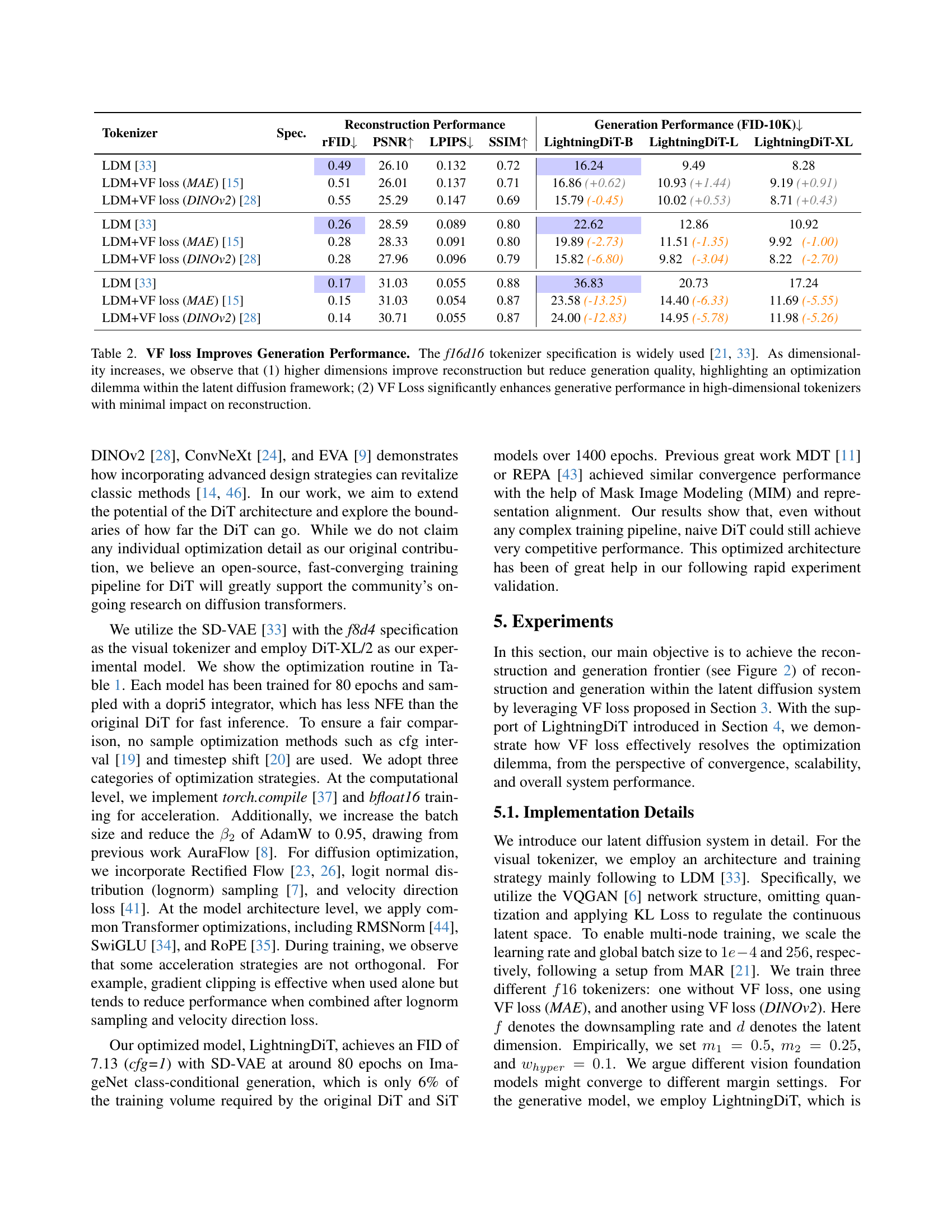
🔼 This table investigates the impact of increasing the dimensionality of visual tokenizers in latent diffusion models and the effect of incorporating Vision Foundation model alignment loss (VF Loss). It shows that while higher dimensionality improves reconstruction quality (measured by rFID, PSNR, LPIPS, SSIM), it simultaneously hurts the generation quality (measured by FID). This demonstrates an optimization dilemma. The table then presents results showing how VF Loss significantly improves the generation performance (FID) of high-dimensional tokenizers while maintaining comparable reconstruction quality, effectively mitigating this dilemma.
read the caption
Table 2: VF loss Improves Generation Performance. The f16d16 tokenizer specification is widely used [33, 21]. As dimensionality increases, we observe that (1) higher dimensions improve reconstruction but reduce generation quality, highlighting an optimization dilemma within the latent diffusion framework; (2) VF Loss significantly enhances generative performance in high-dimensional tokenizers with minimal impact on reconstruction.
| Method | Tokenizer | rFID | gFID | #params | sFID | IS | Pre. | Rec. | gFID | sFID | IS | Pre. | Rec. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AutoRegressive (AR) | ||||||||||||||
| MaskGIT [2] | MaskGiT | 2.28 | 555 | 227M | 6.18 | - | 182.1 | 0.80 | 0.51 | - | - | - | - | |
| LlamaGen [36] | VQGAN† | 0.59 | 300 | 3.1B | 9.38 | 8.24 | 112.9 | 0.69 | 0.67 | 2.18 | 5.97 | 263.3 | 0.81 | 0.58 |
| VAR [38] | - | - | 350 | 2.0B | - | - | - | - | - | 1.80 | - | 365.4 | 0.83 | 0.57 |
| MagViT-v2 [42] | - | - | 1080 | 307M | 3.65 | - | 200.5 | - | - | 1.78 | - | 319.4 | - | - |
| MAR [21] | LDM† | 0.53 | 800 | 945M | 2.35 | - | 227.8 | 0.79 | 0.62 | 1.55 | - | 303.7 | 0.81 | 0.62 |
| Latent Diffusion Models | ||||||||||||||
| MaskDiT [45] | SD-VAE [33] | 0.61 | 1600 | 675M | 5.69 | 10.34 | 177.9 | 0.74 | 0.60 | 2.28 | 5.67 | 276.6 | 0.80 | 0.61 |
| DiT [29] | SD-VAE [33] | 0.61 | 1400 | 675M | 9.62 | 6.85 | 121.5 | 0.67 | 0.67 | 2.27 | 4.60 | 278.2 | 0.83 | 0.57 |
| SiT [26] | SD-VAE [33] | 0.61 | 1400 | 675M | 8.61 | 6.32 | 131.7 | 0.68 | 0.67 | 2.06 | 4.50 | 270.3 | 0.82 | 0.59 |
| FasterDiT [41] | SD-VAE [33] | 0.61 | 400 | 675M | 7.91 | 5.45 | 131.3 | 0.67 | 0.69 | 2.03 | 4.63 | 264.0 | 0.81 | 0.60 |
| MDT [11] | SD-VAE [33] | 0.61 | 1300 | 675M | 6.23 | 5.23 | 143.0 | 0.71 | 0.65 | 1.79 | 4.57 | 283.0 | 0.81 | 0.61 |
| MDTv2 [12] | SD-VAE [33] | 0.61 | 1080 | 675M | - | - | - | - | - | 1.58 | 4.52 | 314.7 | 0.79 | 0.65 |
| REPA [43] | 800 | 675M | 5.90 | - | - | - | - | 1.42 | 4.70 | 305.7 | 0.80 | 0.65 | ||
| LightningDiT | VA-VAE | 0.28 | 64 | 675M | 5.14 | 4.22 | 130.2 | 0.76 | 0.62 | 2.11 | 4.16 | 252.3 | 0.81 | 0.58 |
| 800 | 675M | 2.17 | 4.36 | 205.6 | 0.77 | 0.65 | 1.35 | 4.15 | 295.3 | 0.79 | 0.65 |
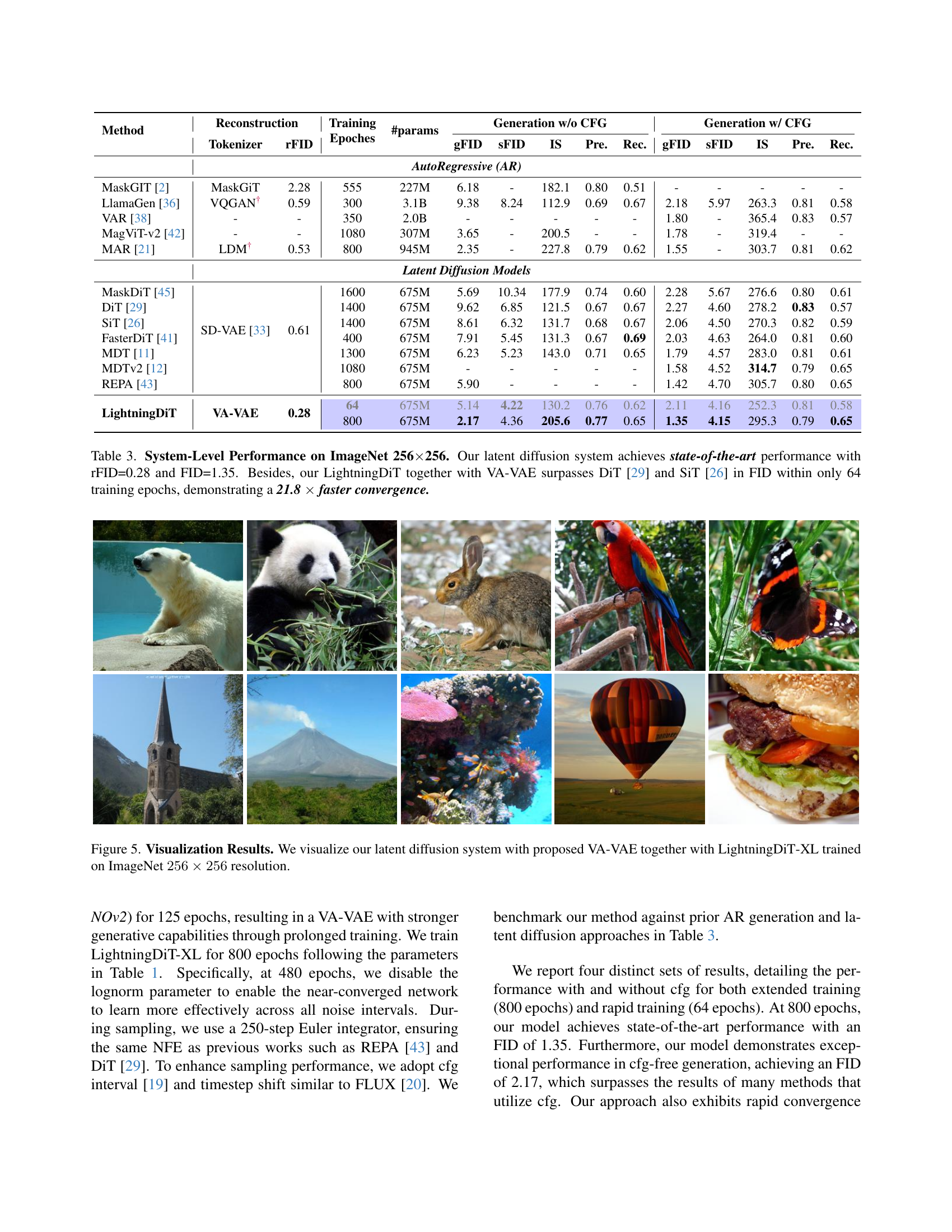
🔼 This table presents a comprehensive comparison of the system-level performance of various latent diffusion models on the ImageNet 256x256 dataset. Key metrics evaluated include reconstruction quality (rFID), generation quality (FID, IS, and Precision/Recall), and training efficiency (training epochs and number of parameters). The table highlights the superior performance of the proposed LightningDiT model combined with VA-VAE, demonstrating state-of-the-art results in terms of both generation quality (FID of 1.35) and training speed (achieving comparable performance to existing models in a fraction of the training time, specifically 64 epochs compared to others, indicating a more than 21 times speedup). The comparison includes both autoregressive and latent diffusion models, allowing for a comprehensive assessment of the proposed method’s advantages.
read the caption
Table 3: System-Level Performance on ImageNet 256×\times×256. Our latent diffusion system achieves state-of-the-art performance with rFID=0.28 and FID=1.35. Besides, our LightningDiT together with VA-VAE surpasses DiT [29] and SiT [26] in FID within only 64 training epochs, demonstrating a 21.8 ×\times× faster convergence.
| Model Type | rFID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | gFID↓ |
|---|---|---|---|---|---|
| naive | 0.26 | 28.59 | 0.089 | 0.80 | 22.62 |
| DINOv2 [28] | 0.28 | 27.96 | 0.096 | 0.79 | 15.82 |
| MAE [15] | 0.28 | 28.33 | 0.091 | 0.80 | 19.89 |
| SAM [18] | 0.26 | 28.31 | 0.091 | 0.80 | 19.80 |
| CLIP [32] | 0.33 | 28.39 | 0.091 | 0.80 | 18.93 |
🔼 This ablation study investigates the effect of different vision foundation models on the performance of the Vision Foundation Model Aligned Variational AutoEncoder (VA-VAE). The table compares the generative performance (measured by FID score) when using different pre-trained models (DINOv2, MAE, CLIP, and SAM) to guide the training of the VA-VAE. The results demonstrate that the choice of foundation model significantly impacts the quality of image generation, with DINOv2 showing the best performance.
read the caption
Table 4: Ablation on Foundation Models. We evaluate the impact of different VF losses on generative performance. Our results show that DINOv2 achieves the highest generative performance.
| Loss Type | rFID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | gFID↓ |
|---|---|---|---|---|---|
| NaN | 0.26 | 28.59 | 0.089 | 0.80 | 22.62 |
| full | 0.28 | 27.96 | 0.096 | 0.79 | 15.82 |
| mcos loss | 0.27 | 28.52 | 0.090 | 0.80 | 21.87 |
| mdistmat loss | 0.27 | 28.24 | 0.090 | 0.80 | 17.74 |
| margin | 0.27 | 28.07 | 0.093 | 0.79 | 17.77 |
🔼 This table presents an ablation study analyzing the impact of different components within the Vision Foundation model alignment Loss (VF Loss) on the generative performance of the LightningDiT-B model. It compares the reconstruction and generation performance metrics (rFID, PSNR, LPIPS, SSIM, and gFID) using different configurations of the VF loss. Specifically, it examines the effects of removing the marginal cosine similarity loss (mcos), the marginal distance matrix similarity loss (mdms), and the margin term from the loss function, providing insights into the contribution of each component to the overall performance.
read the caption
Table 5: Ablation Study of VF Loss Formulations: Comparison of different configurations on generative performance metrics using LightningDiT-B.
| Tokenizer | VF Loss | density ↓ | gini coefficient ↓ | normalized entropy ↑ | gFID (DiT-B) ↓ |
|---|---|---|---|---|---|
| f16d32 | NaN | 0.263 | 0.145 | 0.995 | 22.62 |
| MAE | 0.193 | 0.101 | 0.997 | 19.89 | |
| DINOv2 | 0.178 | 0.096 | 0.998 | 15.82 | |
| f16d64 | NaN | 0.296 | 0.166 | 0.994 | 36.83 |
| MAE | 0.256 | 0.143 | 0.995 | 23.58 | |
| DINOv2 | 0.251 | 0.141 | 0.996 | 24.00 |
🔼 This table explores the relationship between the uniformity of feature distributions in latent spaces of different visual tokenizers and their impact on generative model performance. Uniformity is assessed using two metrics: kernel density estimation standard deviation and Gini coefficient. The results suggest a positive correlation between a more uniform latent space (lower standard deviation and Gini coefficient) and better generative performance (lower FID score). This indicates that well-structured, uniformly distributed latent spaces learned by the vision foundation model improve the quality of generated images.
read the caption
Table 6: Relationship between uniformity and generative performance: We evaluate the uniformity of feature distribution. Results indicate a possible positive correlation between the uniformity of feature distribution and generative performance.
Full paper#